VFA训练自定义VOC格式数据集
修改configs/vfa/voc/vfa_split1/vfa_r101_c4_8xb4_voc-split1_10shot-fine-tuning.py中lr学习率,max_iter迭代次数,load_from为上一步所生成latest.pth文件路径。修改configs/vfa/voc/vfa_split1/vfa_r101_c4_8xb4_voc-split1_base-training.
论文链接:arxiv.org/pdf/2301.13411.pdf
一、环境配置
1、创建环境
conda create -n vfa python=3.8 -y #创建名为vfa的环境
conda activate vfa #激活环境2、安装pytorch
这里我安装的是torch1.7.1 + cuda110
pytorch官网:PyTorch
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=11.0 -c pytorch3、安装mmfewshot框架包
pip install openmim
mim install mmcv-full==1.3.12
# 安装 mmclassification mmdetection
mim install mmcls==0.15.0
mim install mmdet==2.16.0
#安装 mmfewshot
mim install mmfewshot==0.1.04、安装VFA
python setup.py develop二、数据集准备
(1)本人数据集配置:总共3个类别,其中taoguan和naizhangxianjia为基类,birdnest为新类
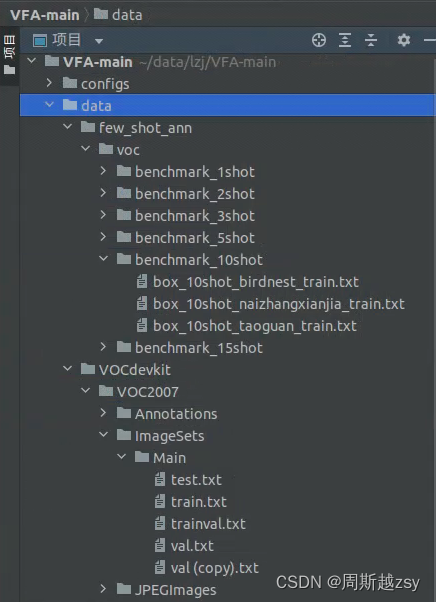
(2)数据集结构说明:
data/few_shot_ann/voc/benchmark_{实例数量}shot 下储存第二阶段迁移训练图像 txt文件,文件名称命名为 box_{实例数量}shot_{类别名称}_train.txt ;
data/VOCdevkit/VOC2007/Annotations下储存所有图像xml格式标签文件(所有=基类+新类);data/VOCdevkit/VOC2007/ImageSets/Main储存所有图像训练、验证、测试txt文件;
data/VOCdevkit/VOC2007/JPEGImages下储存所有图像
三、数据集训练与测试
(1)基础训练
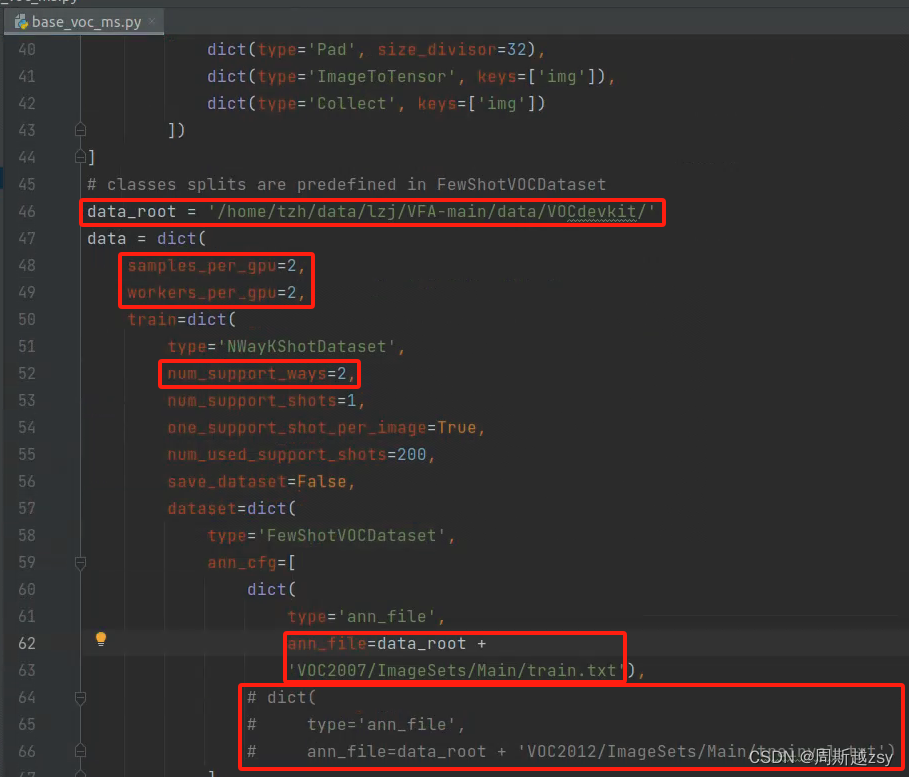
修改configs/_base_/datasets/nway_kshot/base_voc_ms.py
data_root为数据集根路径,sample_per_gpu为batchsize参数,num_support_ways为基类类别数量,ann_file为对应自己数据集txt路径
本人数据集中无voc2012文件夹,故相关代码都注释掉了,避免后续跑代码报错
修改configs/_base_/datasets/models/faster_rcnn_r50_caffe_c4.py中num_classes为所有类别数量(所有=基类 + 新类)

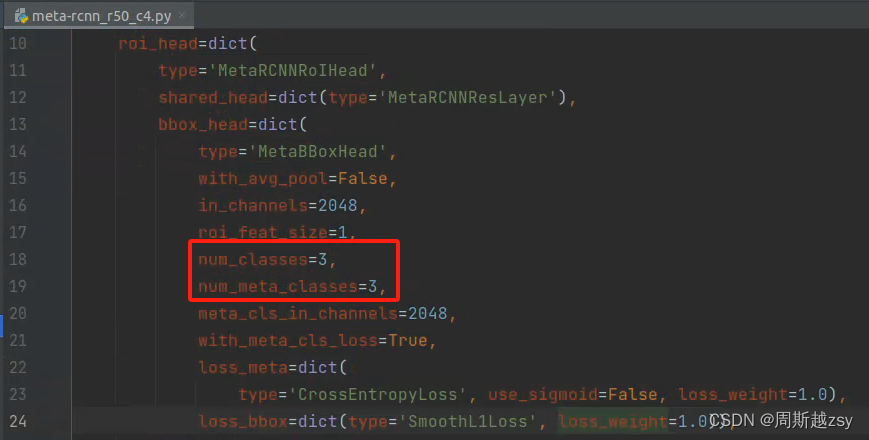
修改configs/vfa/voc/meta-rcnn_r50_c4.py中num_classes和num_meta_classes为所有类别数量
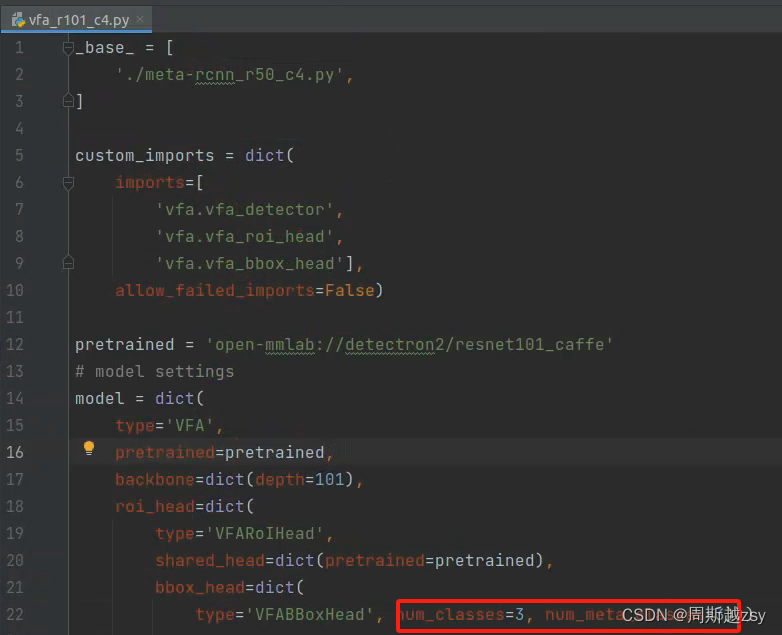
修改configs/vfa/voc/vfa_r101_c4.py中num_classes和num_meta_classes为所有类别数量
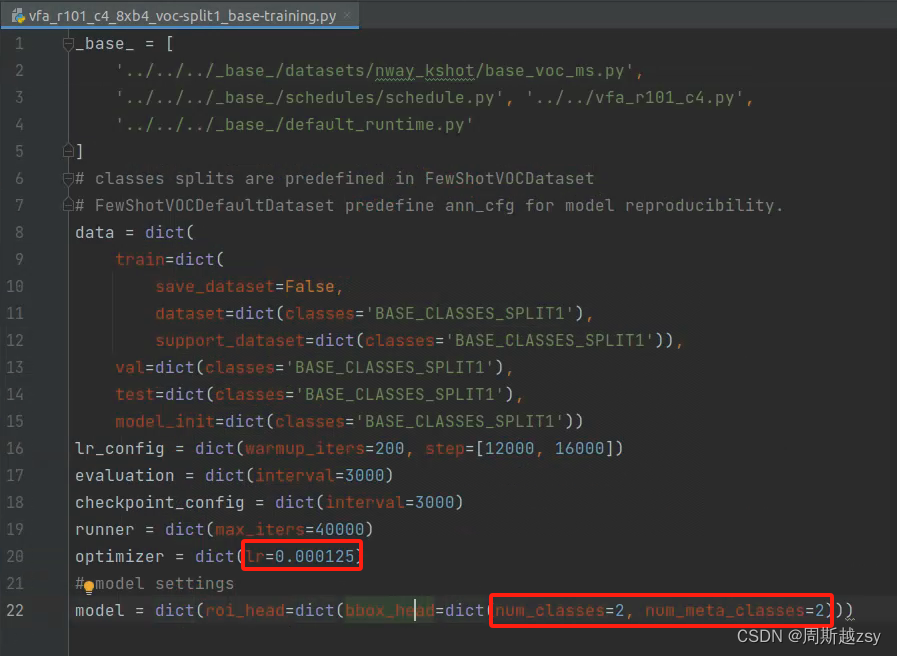
 修改configs/vfa/voc/vfa_split1/vfa_r101_c4_8xb4_voc-split1_base-training.py中num_classes和num_meta_classes为所有基类类别数量,lr自行修改
修改configs/vfa/voc/vfa_split1/vfa_r101_c4_8xb4_voc-split1_base-training.py中num_classes和num_meta_classes为所有基类类别数量,lr自行修改
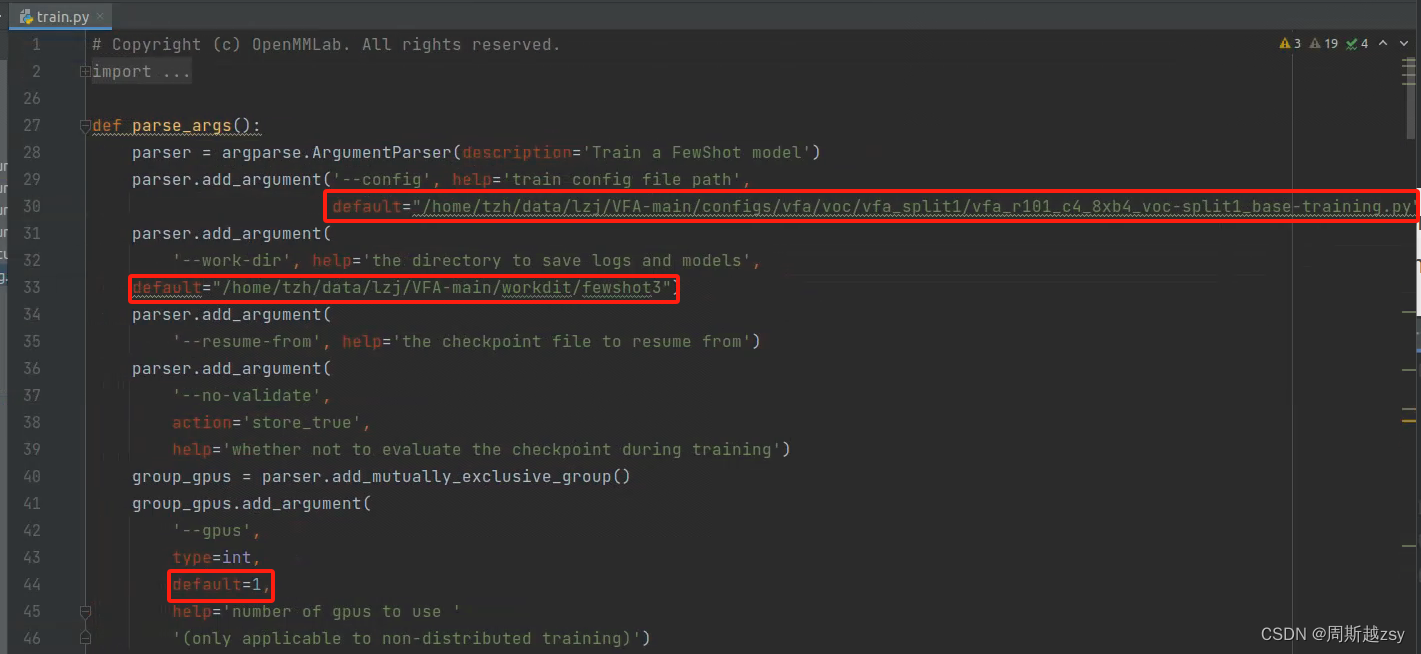
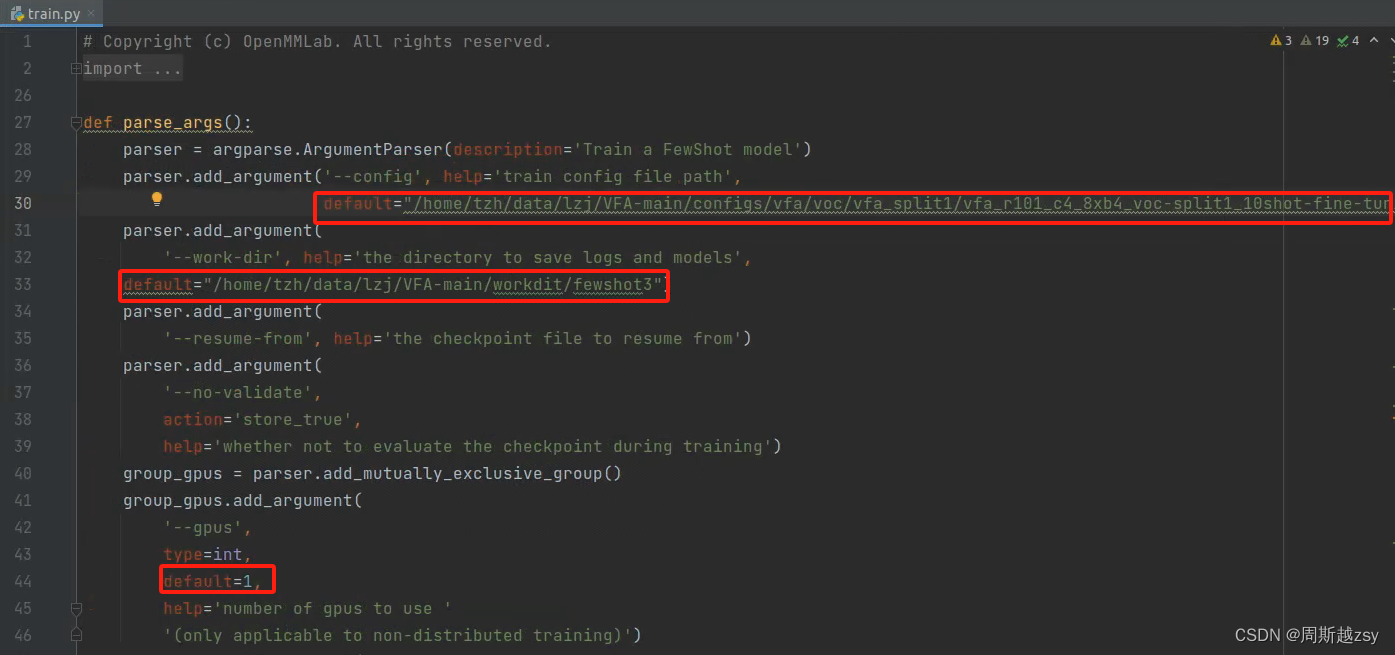
开始训练:修改train.py中config为上一步base-training代码路径,work-dir为自定义训练日志储存路径,gpus为使用显卡训练数量,修改后运行
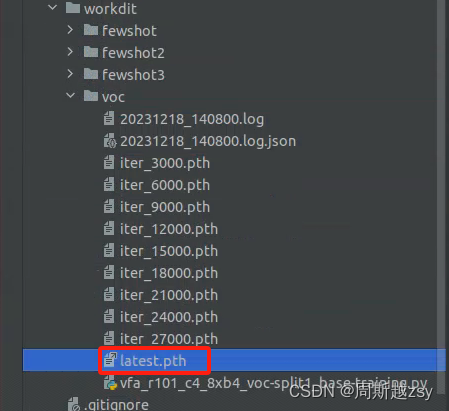
运行后在work-dir参数指定路径中生成latest.pth权重文件
(2)小样本训练(以10shot为例)
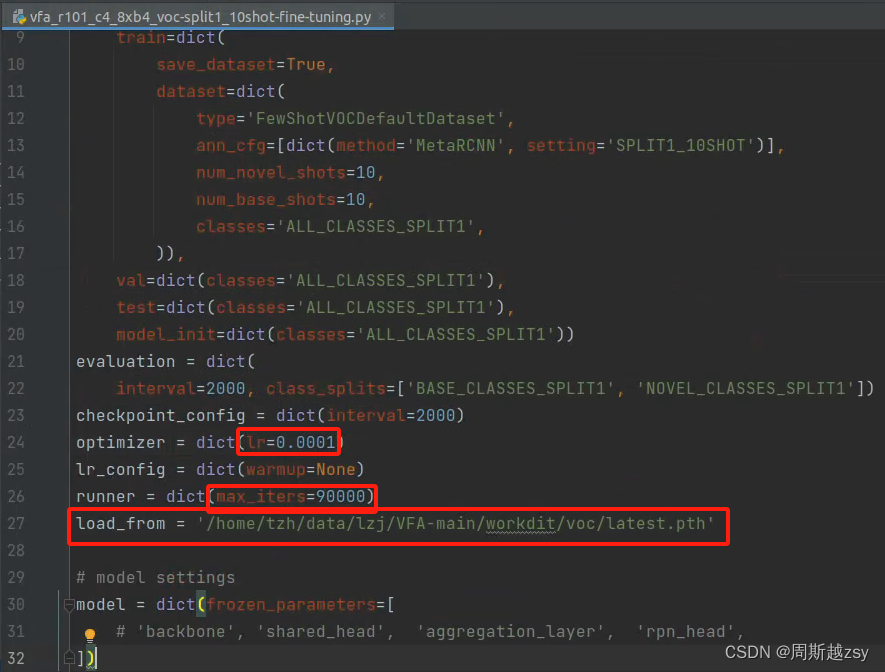
修改configs/vfa/voc/vfa_split1/vfa_r101_c4_8xb4_voc-split1_10shot-fine-tuning.py中lr学习率,max_iter迭代次数,load_from为上一步所生成latest.pth文件路径
开始训练:修改train.py中config为上一步10shot代码路径,work-dir为自定义训练日志储存路径,gpus为使用显卡训练数量,修改后运行
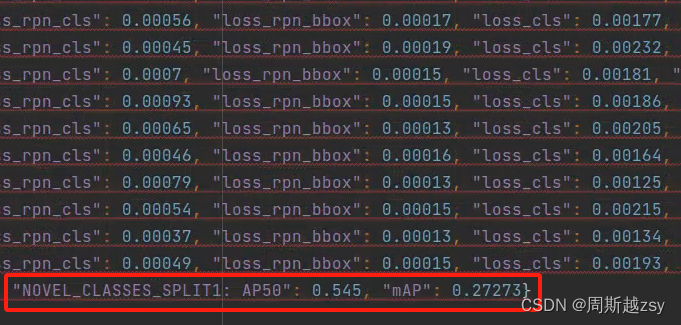
得到新类测试结果
至此,结束

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)