Pytorch 之torch.nn初探
Pytorch里面,构建线性模型使用的是 torch.nn 里面的:Linear方法!Linear的默认参数是:Linear(输入样本大小,输出样本大小)如果要用线性模型进行一个序列变量的构建,需要采用的是torch.nn里面的Sequential方法。Sequential默认参数:(线性模型1,线性模型2,…,线性模型n),从而可以构建n个序列构成的变量。Linear是module的子类,是参数
任务描述
第一关任务:
本关要求利用nn.Linear()声明一个线性模型 l,并构建一个变量 net 由三个l序列构成。
编程要求:
import torch
import torch.nn as nn
from torch.autograd import Variable
# 声明一个in_features=2, out_features=3的线性模型l并输出
l = nn.Linear(2, 2)
print(l)
# 变量net由三个l序列构成并输出net
net = nn.Sequential(l, l)
print(net)
print()
print('Congratulation!',end="")
总结:
Pytorch里面,构建线性模型使用的是 torch.nn 里面的:Linear方法!
Linear的默认参数是:Linear(输入样本大小,输出样本大小)
如果要用线性模型进行一个序列变量的构建,需要采用的是torch.nn里面的Sequential方法。
Sequential默认参数:(线性模型1,线性模型2,…,线性模型n),从而可以构建n个序列构成的变量。
第二关任务:
本关要求同学们创建一个线性层变量linear并输出linear的 type 属性。
编程要求:
创建in_features=3, out_features=2线性层变量 linear并输出;
输出linear的 type 属性。
import torch
import torch.nn as nn
from torch.autograd import Variable
#/********** Begin *********/
# 创建in_features=3, out_features=2线性层变量 linear
linear = nn.Linear(3, 2)
#输出linear
print ("linear: ", linear)
#输出linear的 type 属性
print("type of linear : ", linear.type)
print()
print("Congratulation!", end="")
#/********** End *********/
总结:
Linear是module的子类,是参数化module的一种,与其名称一样,表示着一种线性变换。
torch.nn.Linear
基本形式:
torch.nn.Linear (in_features, out_features, bias=True)
用途:对输入数据应用一个线性转换,格式如下所示:
y=Ax+b
参数说明:
-
in_features – 输入样本的大小
-
out_features – 输出样本的大小
-
bias – 偏移量
-
False:该层将不会学习额外的偏移量
-
默认值为True
维度大小:
- Input: (N,∗,in_features) *表示任意大小的附加维度
- bias – 可学习偏移量(out_features)
学习到的变量:
- weight– 可学习权重(out_features x in_features)
- bias – 可学习偏移量(out_features)
第三关任务:
在实际应用中,非线性模型往往比线性模型更加适用,而 torch.nn 中也提供了许多非线性模型供大家使用。让我们一起来看一看吧!
请同学们掌握 torch.nn 提供的几个重要的非线性模型,如下所示。由此对数据进行相应的非线性映射,便于之后的处理和应用。
- ReLU
- Threshold
- Sigmoid
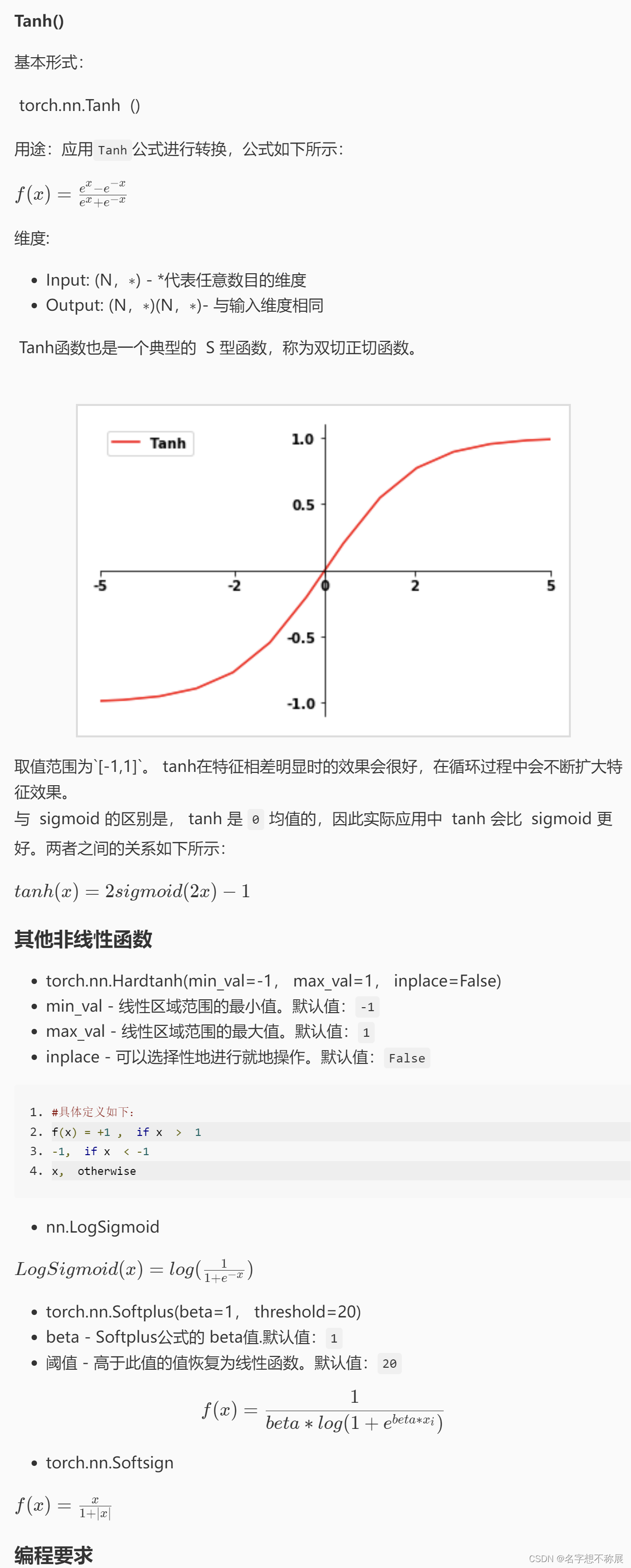
- Tanh
本关提供了一个 Variable 类型的变量input,利用tanh模型对数据进行非线性映射。
编程要求:
本关涉及的代码文件为nonlinear.py,本次的编程任务是补全右侧代码片段中Begin至End中间的代码,具体要求如下:
创建 Tanh 模型 m;
输出经m变化后的input值。
具体请参见后续测试样例。
相关知识:

代码:
import torch
import torch.nn as nn
from torch.autograd import Variable
input = Variable(torch.Tensor([2.3,-1.4,0.54]))
#/********** Begin *********/
#创建 Tanh 模型 m
m = nn.Tanh()
#输出经 m 变化后的 input 值
print(m(input))
print()
print("Congratulation!", end="")
#/********** End *********/
第四关任务:
本关提供了一个Variable 类型的变量input,按照要求创建一 Conv1d变量conv,对input应用卷积操作并赋值给变量 output,并输出output 的大小。
编程要求:
本关涉及的代码文件为convolution.py,本次编程任务是补全右侧代码片段中Begin至End中间的代码,具体要求如下:
创建一个in_channels=16, out_channels=33, kernel_size=3, stride=2的Conv1d变量conv;
对input应用卷积操作并赋值给变量 output;
输出 output 的大小。
具体请参见后续测试样例。
相关知识:

第五关任务:
本关提供了一个Variable 类型的变量x,要求按照条件创建一个Conv2d变量conv,一个MaxPool2d变量pool,对x应用卷积和最大池化操作并赋值给变量outpout_pool,并输出outpout_pool 的大小。
编程要求:
编程要求
本关涉及的代码文件为pool.py,本次编程任务是补全右侧代码片段中Begin至End中间的代码,具体要求如下:
创建一个in_channels=3, out_channels=32, kernel_size=(3, 3), stride=1, padding=1, bias=True的Conv2d变量conv;
创建一个kernel_size=(2, 2), stride=2的MaxPool2d变量pool;
对x应用卷积和最大池化操作并赋值给变量outpout_pool;
输出 outpout_pool 的大小。
相关知识:
本关将介绍神经网络的另外一个特殊的定义——池化层。在神经网络中,池化层往往跟在卷积层后面。通过平均池化或者最大池化的方法将之前卷基层得到的特征图做一个聚合统计,从而达到压缩数据量的目的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)