bpftrace(一):bpftrace介绍
bpftrace
目录
摘要
BPF提供了一种软件定义内核的方法,可以使用eBPF实现Linux的动态追踪以及Linux高速的网络数据包处理。
Bpftrace提供了一种快速利用eBPF实现动态追踪的方法,可以作为简单的命令行工具或者入门级编程工具来使用。本文以bpftrace为例,介绍如何利用eBPF实现内核的动态追踪。
什么是动态追踪
对计算机系统进行动态追踪,清晰的知道应用程序或者操作系统内核当前正在执行哪些操作,一直以来,都是开发者、系统运维者或者安全运维者十分关注和感兴趣的话题。
动态追踪(DynamicTracing)是一种高级的内核调试技术,通过探针机制,采集内核态或者用户态程序的运行信息,而不需要修改内核和应用程序的代码。这种机制性能损耗小,不会对系统运行构成任何危险。因此,能够以非常低的成本,在短时间内获得丰富的运行信息,进而可以快速的分析、排查、发现系统运行中的问题。
动态追踪到底能追踪什么?我们知道,Linux是一个事件驱动的系统设计,因此,对于任何事件的发生,理论上都可以对其进行追踪。比如:追踪目标可以是一次“系统调用”,一个“函数的调用”,甚至是这种调用内部发生的一些细节。除此之外,还可以是一个计时器或硬件事件,比如:“发生了页面错误”、“发生了上下文切换”或“发生了CPU缓存丢失”等等。
动态追踪工具
dtrace的缺陷
提到动态追踪,首先不得不说的就是DTrace[2]。DTrace作为动态追踪领域的鼻祖(the Father of Tracing),最初是由Sun开发的全系统动态跟踪框架,然后将其开源,支持Solaris、FreeBSD、Mac OS X等操作系统。遗憾的是,由于许可(License)问题而非技术问题,DTrace无法直接在Linux上运行,但其对Linux的动态追踪依然有着巨大的影响。
DTrace提供了一种很像C语言的脚本语言,叫做D语言,开发者可以使用D语言实现相应的追踪调试工具。它的运行时(runtime)常驻在内核中,用户可以通过dtrace命令,把D语言编写的追踪脚本,提交到内核中的运行时来执行。
DTrace可以跟踪用户态和内核态的几乎所有事件,并通过一系列的优化措施,保证最小的性能开销。
systemtam的缺陷
尽管DTrace无法直接在Linux上运行,但是很多工程师都尝试过把DTrace 移植到Linux中,这其中,最著名的就是RedHat主推的SystemTap。同DTrace一样,SystemTap也定义了一种类似的脚本语言,方便用户根据需要自由扩展。不过,不同于DTrace,SystemTap并没有常驻内核的运行时,它需要先把脚本编译为内核模块,然后再插入到内核中执行,如下图所示。
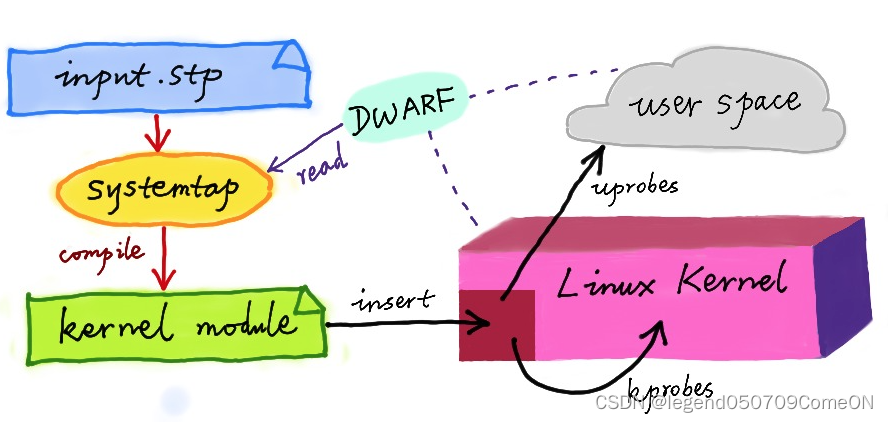
因此,要实现动态追踪,通常需要在Linux中使用相应的探测手段,甚至涉及到编写并编译成内核模块,这可能会在生产系统中导致灾难性的后果。经过多年的发展,尽管它们的执行已经变的更加安全了,但是编写和测试仍然很麻烦。
bcc/bpftrace的出现
eBPF似乎为上述问题找到了解决的福音,eBPF通过一种软件定义的方式,提供并支持了丰富的内核探针类型,提供了强大的动态追踪能力。开发者通过编写eBPF程序,实现相应的追踪脚本,eBPF利用自身的实现机制,保障了在内核执行动态追踪的效率以及安全性问题。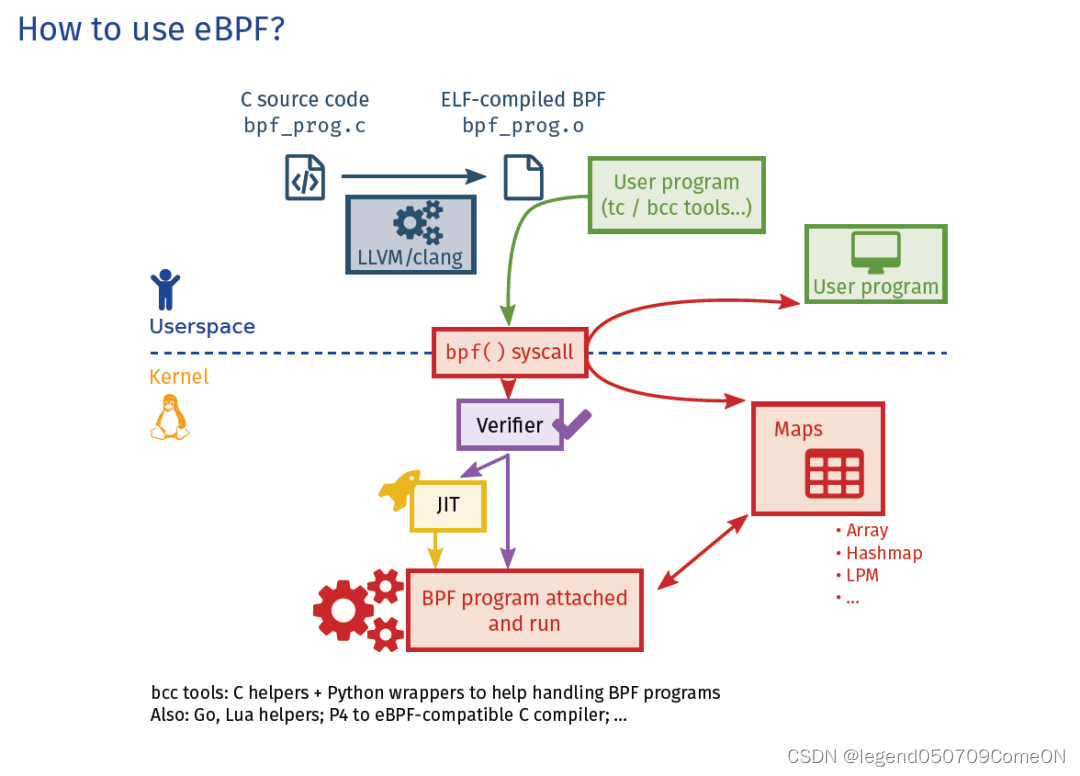
然而,编写eBPF程序对于开发者来说,门槛相对还是比较高,一方面需要开发者对内核有一个深入的了解,另一方面,需要使用LLVM/clang等编译程序去编译并手动的将其加载到内核中。那么像bpftrace、BCC这样的工具,就得到了开发者的青睐。
bcc和bpftrace对比
-
llvm
一个编译器,帮助高级语言(c、GO、Rust)的子集被编译成为eBPF字节码程序;将“”受限的C语言“”(符合eBPF验证规范的)编译为ELF对象文件,随后即可通过bpf等系统调用实现加载到内核中;受限的c语言的引入带来的好处是更加容易用高级语言编写,带来的坏处在于加载器程序的复杂性变高(需要解析ELF对象) -
bcc
一个BPF工具链集合(libbcc、libbpf的前身), 解决了上述整体四个组织架构之间的整合关系,尽量实现自动化和标准化,其本身组成分为两个部分:
- 编译器集合(BCC 本身):这是用于编写 BCC 工具的框架
- BCC-tools:这是一个不断增长的基于 eBPF 且经过测试的程序集,提供了使用的例子和手册(基于BCC开发的成熟工具)
重新定义了组织结构,eBPF 程序组件在BCC组织方式如下:
- 后端和数据结构:用 “受限制的C语言” 编写(本身也依赖于llvm/clang进行编译成eBPF程序)。可以在单独的文件中,或直接作为多行字符串存储在加载器/前端的脚本中,以方便使用(很多方便的宏定义)。
- 加载器和前端:可用非常简单的高级python/lua脚本编写。
例如python的BPF(text=‘BPF_program’))即可加载BPF字节码到内核。
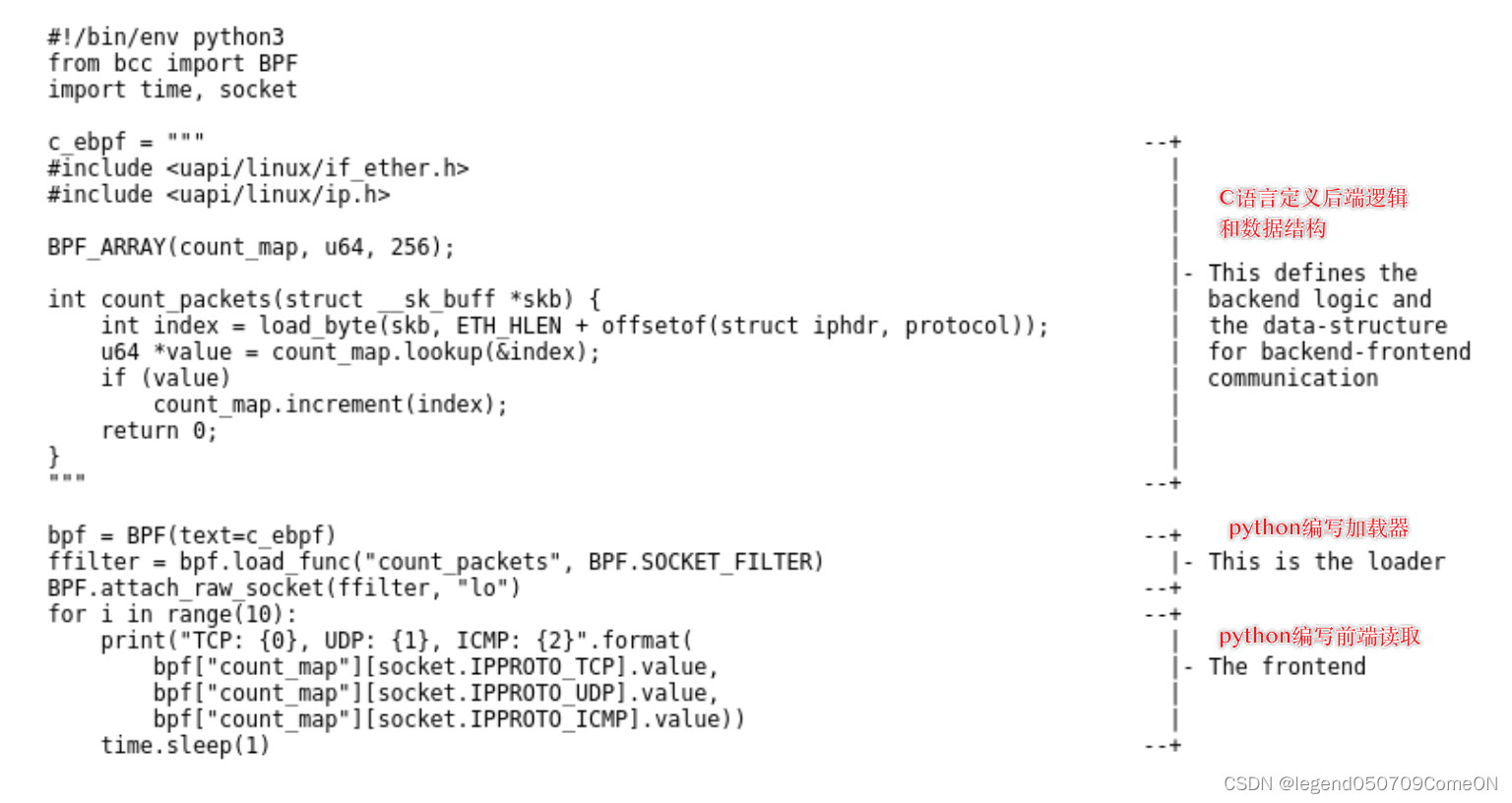
- bpftrace
在某些用例中,BCC 仍然过于底层,例如在事件响应中检查系统时,时间至关重要,需要快速做出决定,而编写 python/“限制性 C” 会花费太多时间,因此 BPFtrace 建立在 BCC 之上,通过特定领域语言(受 AWK 和C启发实现的一种自定义的高级语言)提供更高级别的抽象,根据声明帖,该语言类似于 DTrace 语言实现,也被称为 DTrace 2.0,并提供了良好的介绍和例子。
例如:这个单行 shell 程序统计了每个用户进程系统调用的次数(访问内置变量、map 函数 和count()文档获取更多信息):
bpftrace -e ‘tracepoint:raw_syscalls:sys_enter {@[pid, comm] = count();}’
局限性:上层的封装抽象会受限于特殊的功能需求,在某些场景下很难直接用一个bpftrace命令实现,所以还是需要BCC工具。
- BCC与bpftrace适用场景对比:
BCC: 开发复杂的脚本和作为后台进程使用
bpftrace:编写强大的单行程序、短小的脚本使用
bpftrace执行原理
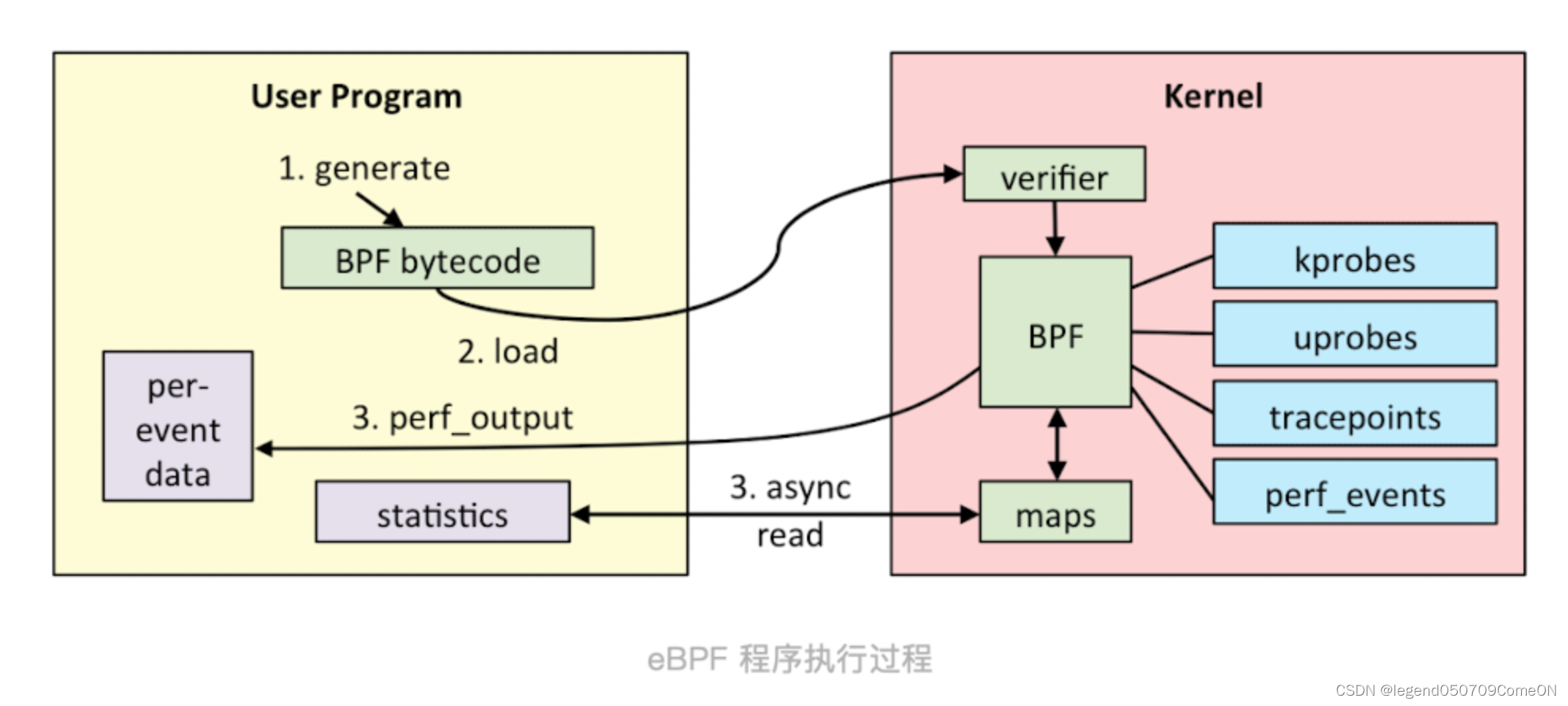
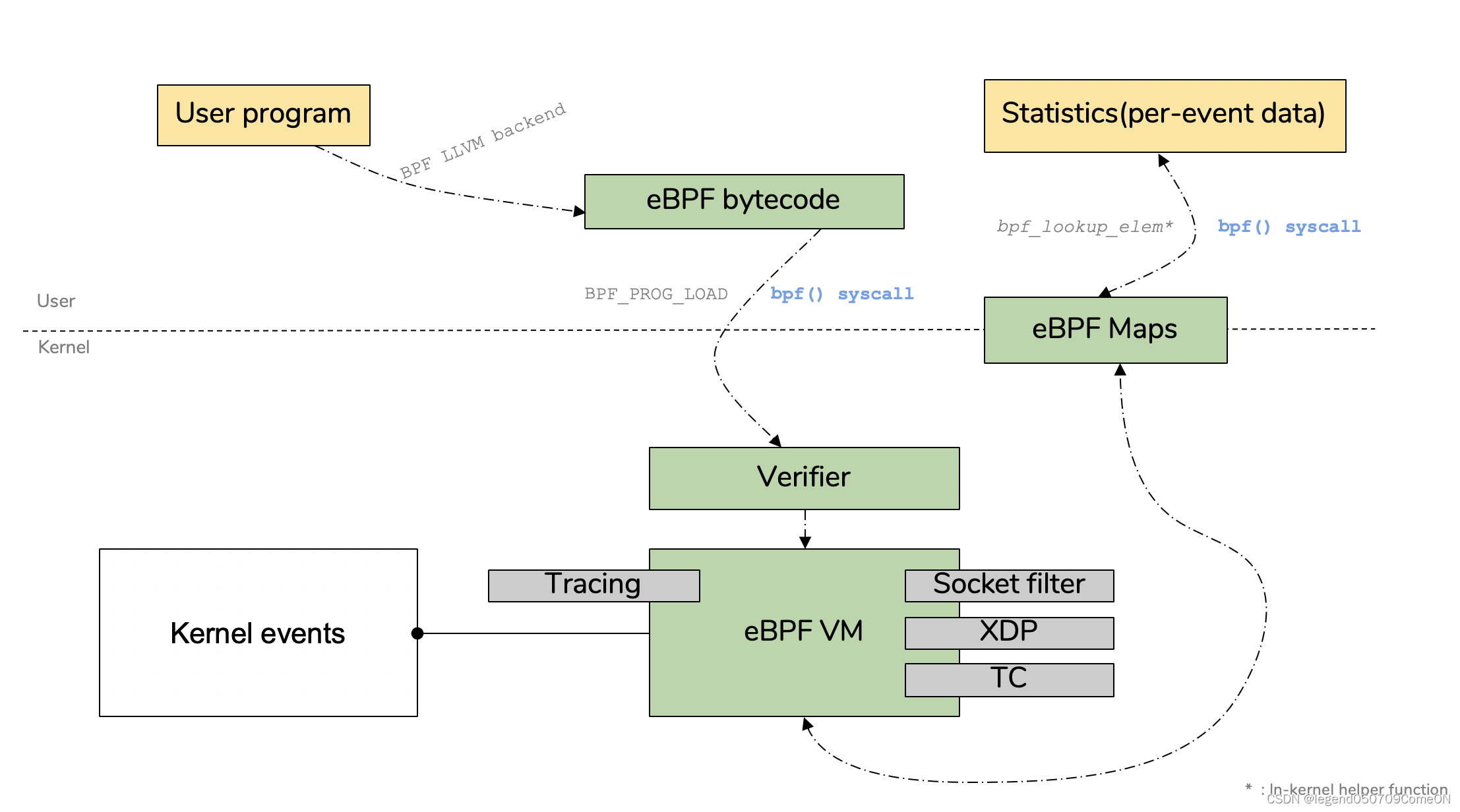
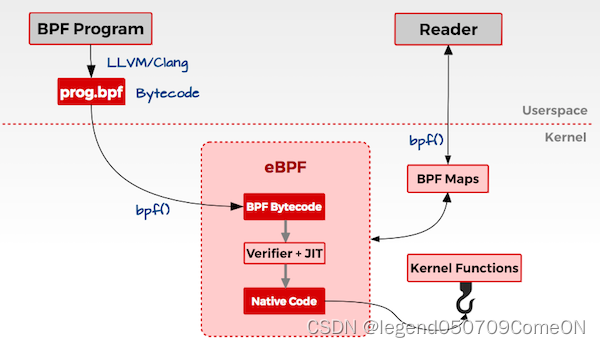
bpftrace支持的探针类型/采集点
无论是DTrace、SystemTap,还是bpftrace,其实现动态追踪都是通过探针的机制,依赖于在追踪点实现的探针,进而获取相应的追踪数据。
bpftrace 能够在不影响系统运行的情况下,采集细致到源码级别的信息,例如系统调用情况、内核函数调用情况、函数的入参和返回值等。
bpftrace 把采集动作被称为 probe,采集动作的类型是 probe types。
采集动作类型有很多种,总体上可以分为两大类:静态点采集 和 动态点采集。
- 静态点是在源码中植入的采集点,种类是固定的,在编码时就定义好了,每个采集点有哪些数据也都是定好的,一般不会因为内核版本的变化而变化。
- 动态点可以是内核的任意一个函数,内核版本不同,相应函数实现可能不同,能够采集的到数据不同。
内核动态探针-Kprobes
eBPF支持的内核探针(Kernel probes)功能,允许开发者在几乎所有的内核指令中以最小的开销设置动态的标记或中断。当内核运行到某个标记的时候,就会执行附加到这个探测点上的代码,然后恢复正常的流程。对内核行为的追踪探测,可以获取内核中发生任何事件的信息,比如系统中打开的文件、正在执行的二进制文件、系统中发生的TCP连接等。
内核动态探针可以分为两种:kprobes 和 kretprobes。二者的区别在于,根据探针执行周期的不同阶段,来确定插入eBPF程序的位置。Kprobes通常在内核函数执行前插入eBPF程序,而kretprobes则在内核函数执行完毕返回之后,插入相应的eBPF程序。
比如,tcp_connect() 是一个内核函数,当有TCP连接发生时,将调用该函数,那么如果对tcp_connect()使用kprobes探针,则对应的eBPF程序会在tcp_connect() 被调用时执行,而如果是使用kretprobes探针,则eBPF程序会在tcp_connect() 执行返回时执行。
-
“不稳定"的探针类型
尽管Kprobes允许在执行任何内核功能之前插入eBPF程序。但是,它是一种“不稳定"的探针类型,开发者在使用Kprobes时,需要知道想要追踪的函数签名(Function Signature)。而Kprobes当前没有稳定的应用程序二进制接口(ABI),这意味着它们可能在内核不同的版本之间发生变化。如果内核版本不同,内核函数名、参数、返回值等可能会变化。如果尝试将相同的探针附加到具有两个不同内核版本的系统上,则相同的代码可能会停止工作。 -
列出当前版本内核所支持Kprobes探针列表
# bpftrace -l 'kprobe:tcp*'
kprobe:tcpm_rp_cc
kprobe:tcpm_try_role
kprobe:tcpm_queue_vdm
kprobe:tcpm_log
kprobe:tcpm_pd_transmit_complete
kprobe:tcpm_set_current_limit
kprobe:tcpm_set_polarity
kprobe:tcpm_set_cc
kprobe:tcpm_set_charge
kprobe:tcpm_set_vbus
kprobe:tcpm_log_force
kprobe:tcpm_validate_caps
kprobe:tcpm_altmode_vdm
kprobe:tcpm_altmode_exit
kprobe:tcpm_altmode_enter
kprobe:tcpm_pd_receive
kprobe:tcpm_unregister_altmodes
kprobe:tcpm_debug_open
kprobe:tcpm_debug_show
......
内核静态探针-Tracepoints
Tracepoints是在内核代码中所做的一种静态标记[4],是开发者在内核源代码中散落的一些hook,开发者可以依托这些hook实现相应的追踪代码插入。
开发者在/sys/kernel/debug/tracing/events/目录下,可以查看当前版本的内核支持的所有Tracepoints,在每一个具体Tracepoint目录下,都会有一系列对其进行配置说明的文件,比如可以通过enable中的值,来设置该Tracepoint探针的开关等。
- Tracepoints与Kprobes相比
Tracepoints是内核开发人员已经在内核代码中提前埋好的,这也是为什么称它们为静态探针的原因。而kprobes更多的是跟踪内核函数的进入和返回,因此将其称为动态的探针。但是内核函数会随着内核的发展而出现或者消失,因此kprobes对内核版本有着相对较强的依赖性,前文也有提到,针对某个内核版本实现的追踪代码,对于其它版本的内核,很有可能就不工作了。
相比Kprobes探针,我们更加喜欢用Tracepoints探针,因为Tracepoints有着更稳定的应用程序编程接口,而且在内核中保持着前向兼容,总是保证旧版本中的跟踪点将存在于新版本中。
然而,Tracepoints的不足之处在于,这些探针需要开发人员将它们添加到内核中,因此,它们可能不会覆盖内核的所有子系统,只能使用当前版本内核所支持的探测点。
bpftrace -vl “tracepoint:xxx” 添加 -vl 可以列举出tracepoint类型的静态probe点函数的参数信息。但是对于kprobe类型的不可以。如下所示:
# bpftrace -vl tracepoint:tcp:tcp_retransmit_skb
tracepoint:tcp:tcp_retransmit_skb
const void * skbaddr;
const void * skaddr;
__u16 sport;
__u16 dport;
__u8 saddr[4];
__u8 daddr[4];
__u8 saddr_v6[16];
__u8 daddr_v6[16];
# bpftrace -vl kprobe:tcp_recv_skb
kprobe:tcp_recv_skb
其他探针
除了前面介绍的Kprobes/Kretprobes和Tracepoints内核探针外,eBPF还支持对用户态程序通过探针进行追踪。
例如用户态的Uprobes/Uretprobes探针,在用户态对函数进行hook,实现与Kprobes/Kretprobes类似的功能;
再比如USDTs(User Static Defined Tracepoints)探针,是用户态的Tracepoints,需要开发者在用户态程序中自己埋点Tracepoint,实现与内核Tracepoints类似的功能。
另外,bpftrace还支持内核软件事件(software)、处理器事件(hardware)等探针格式,具体可参考其github官方的介绍[5],本文就不逐一进行分析了。
bpftrace支持的采集点
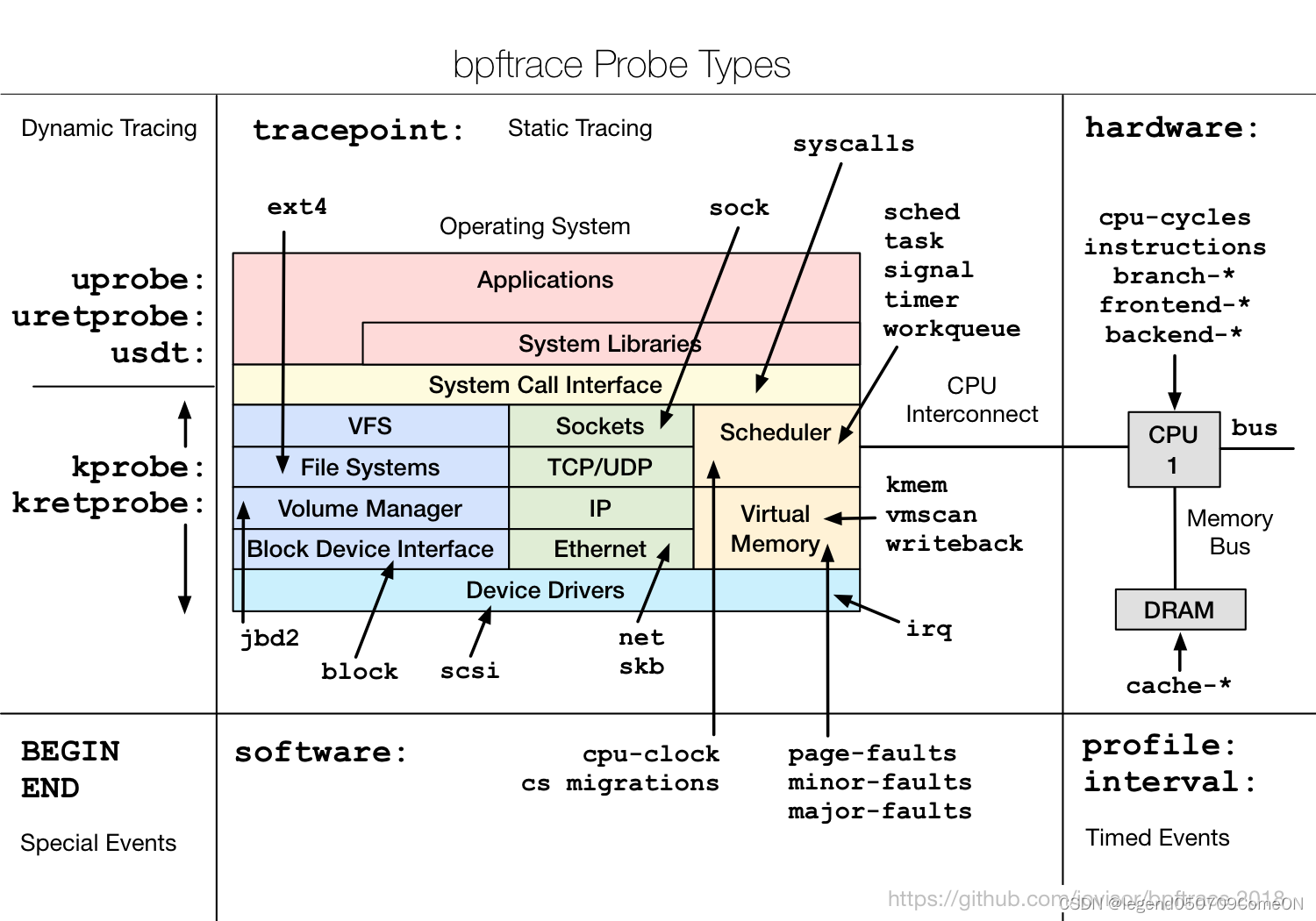
bpftrace 对采集点的划分更细致,如下所示:
Alias Type Description
t tracepoint Kernel static instrumentation points
U usdt User-level statically defined tracing
k kprobe Kernel dynamic function instrumentation
kr kretprobe Kernel dynamic function return instrumentation
u uprobe User-level dynamic function instrumentation
ur uretprobe User-level dynamic function return instrumentation
s software Kernel software-based events
h hardware Hardware counter-based instrumentation
w watchpoint Memory watchpoint events
p profile Timed sampling across all CPUs
i interval Timed reporting (from one CPU)
BEGIN Start of bpftrace
END End of bpftrace
bpftrace -l 命令会列出支持的采集点(probes):
bpftrace -l
software:alignment-faults:
software:bpf-output:
...
hardware:backend-stalls:
hardware:branch-instructions:
...
tracepoint:sunrpc:rpc_call_status
tracepoint:sunrpc:rpc_bind_status
...
kprobe:in_tx_show
kprobe:cmask_show
kprobe:inv_show
...
注意:bpftrace -l 没有列出的采集点,可能也是支持的,譬如 kretprobe:vfs_read 没有被列出,但是可用:
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
Attaching 1 probe...
^C
@bytes:
(..., 0) 2 |@ |
[0, 200) 91 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[200, 400) 10 |@@@@@ |
[400, 600) 5 |@@ |
[600, 800) 0 | |
[800, 1000) 20 |@@@@@@@@@@@ |
[1000, 1200) 0 | |
[1200, 1400) 0 | |
[1400, 1600) 0 | |
[1600, 1800) 0 | |
[1800, 2000) 0 | |
[2000, ...) 5 |@@ |
参考
https://mp.weixin.qq.com/s/eZySfbqwOzG5EW7YL6enSw

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)