C语言中数据的写入、存储及读取
C语言众多数据类型归根结底,存储的格式只有整型及浮点型,一切其他数据类型都是在此基础上进行拓展。如字符型本质是一个 1 字节的整型,字符串是由若干个字符型元素构成的数组,至于指针类型是 4 字节(32 位)或 8 字节(64 位)的整型。
1、数据类型
1.1、数据类型的本质
C语言众多数据类型归根结底,存储的格式只有整型及浮点型,一切其他数据类型都是在此基础上进行拓展。如字符型本质是一个 1 字节的整型,字符串是由若干个字符型元素构成的数组,至于指针类型是 4 字节(32 位)或 8 字节(64 位)的整型。
1.2、观察方式
#include <stdio.h>
int main()
{
//写入视角
int i = -999999;
unsigned int ui = 4294967295;
float f = -999999.f;
char c = 'A';
char str[] = "Hello!";
int* pi = &i;
//读取视角
printf("%d => %d\n", i, i);
printf("%u => %d\n", ui, ui);
printf("%f => %d\n", f, (int*)&f);
printf("%c => %d\n", c, c);
printf("%s[0] => %d\n", str, str[0]);
printf("%p => %d\n", pi, pi);
return 0;
}
/*
输出:
-999999 => -999999
4294967295 => -1
-999999.000000 => 13629928
A => 65
Hello![0] => 72
00CFFA00 => 13629952
*/上述代码输出结果很好地阐述了写入与读取根据观察方式不同而改变。不论写入什么内容,均以 int 类型读取并输出。虽然能得到结果,但与输入内容完全不同。
现实中也有类似的例子。A 想要一袋马铃薯,于是A 交代 B 买一袋土豆,结果 B 买回来一袋花生,因为在 B 的视角,土豆就是花生。
该例子中,A、B 相当于数据类型,马铃薯相当于数据的写入视角,土豆则是内存中实际储存的数据,花生即为观察方式。

回到上述代码,输入与输出虽然看似毫不相关,但幼儿园老师教育我们,凡事皆须去其外表,探其本质。要了解这段代码本质,则必须探究内存中的土豆到底长什么样。
2、进制
探究内存中的土豆,便不得不先提到进制。应该没人不懂进制是什么,因而在此不多作阐述。C语言中常用进制即二进制、八进制、十进制、十六进制。
2.1、进制的意义(转为十进制)
先提及十进制。由于十进制睁眼闭眼都在用,很容易忽略每一个数位的意义。
如 5286.7801 的数学意义则是:
同样如十六进制 0xB7AC2FDD 的数学意义:
因此,对于 D 进制的第N位数字 C ,其数学意义为(N 取:个位为 1,十位为 2,十分位为 0,百分位为 -1,以此类推):
2.2、十进制转其他进制
对于任意十进制数,要将其转化为其他进制,则必须先将十进制数分成整数部分及小数部分。下列举例均用 1327.6204 转为二进制。
2.2.1、整数部分(取余法)
将十进制整数部分除以进制,获得商及余数,再将商除以进制,得到新的商及余数,如此反复直到商为 0 。将余数倒列,即是新进制的整数部分。
1327.6204 取整数部分为 1327,对其除以进制 2 取余数:
① 1327 ÷ 2 = 663 ······ 1
② 663 ÷ 2 = 331 ······ 1
③ 331 ÷ 2 = 165 ······ 1
④ 165 ÷ 2 = 82 ······ 1
⑤ 82 ÷ 2 = 41 ······ 0
⑥ 41 ÷ 2 = 20 ······ 1
⑦ 20 ÷ 2 = 10 ······ 0
⑧ 10 ÷ 2 = 5 ······ 0
⑨ 5 ÷ 2 = 2 ······ 1
⑩ 2 ÷ 2 = 1 ······ 0
⑪ 1 ÷ 2 = 0 ······ 1
将余数倒列,得到整数部分二进制 10100101111 。用计算器验证答案:
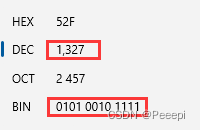
得到答案正确无误。
虽然方法如此,但本着打破砂锅问到底的精神,我们继续探究,为什么是这种方法。我们不得不回到上面总结的 这个中公式来。
经过上述计算,现已知 1327 的二进制是 10100101111 。我们不妨用 10100101111 来进行说明。该二进制的数学意义是:
① 对其进行除以 2 操作得到商:
同时得到余数 ;
② 在对商进行除以 2 操作得到新得商:
同时得到余数 ;
③ …………
⑩ 商:
余:
⑪ 商: 0
余:
阐述得如此复杂,实际上不外乎是取出个位作为余数后,进行一次右移操作:
10100101111
① 01010010111 ······ 1
② 00101001011 ······ 1
③ 00010100101 ······ 1
④ 00001010010 ······ 1
⑤ 00000101001 ······ 0
⑥ 00000010100 ······ 1
⑦ 00000001010 ······ 0
⑧ 00000000101 ······ 0
⑨ 00000000010 ······ 1
⑩ 00000000001 ······ 0
⑪ 00000000000 ······ 1
而因为最后取出的余数实际上是二进制的最高位,所以需要倒列。
根据以上原理,我们可以指定任意进制,如六进制、十五进制等。既然如此,写个最大支持62进制的代码(顺带水下字数):
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <Windows.h>
int main()
{
int num, trans, rem;
int flag = 0;
char digit[100];
scanf("%d%d", &num, &trans);//输入:十进制数 转换进制
system("CLS");
printf("10-%d\n%d-", num, trans);
while (num)
{
if (num % trans <= 9)
{
digit[flag] = num % trans + 48;
}
else if (num % trans <= 35 && num % trans >= 10)
{
digit[flag] = num % trans + 55;
}
else if (num % trans <= 61 && num % trans >= 36)
{
digit[flag] = num % trans + 61;
}
flag++;
num /= trans;
}
for (int i = flag - 1; i >= 0; i--)
{
printf("%c", digit[i]);
}
printf("\n");
return 0;
}2.2.2、小数部分(取整法)
将十进制整数部分乘以进制,获得积,取积的整数部分,将小数部分重新乘以进制,得到新的积,再将新的积取其整数部分,再将小数部分乘以进制,反复直到小数部分为 0 或者满足要求的精度为止。将取出的整数部分按顺序排列,即是新进制的小数部分。
1327.6204 取小数部分为 0.6204,对其乘以进制 2 取整数:
① 0.6204 x 2 = 1 + 0.2408
② 0.2408 x 2 = 0 + 0.4816
③ 0.4816 x 2 = 0 + 0.9632
④ 0.9632 x 2 = 1 + 0.9264
⑤ 0.9264 x 2 = 1 + 0.8528
⑥ 0.8528 x 2 = 1 + 0.7056
⑦ 0.7056 x 2 = 1 + 0.4112
⑧ 0.4112 x 2 = 0 + 0.8224
⑨ 0.8224 x 2 = 1 + 0.6448
⑩ 0.6448 x 2 = 1 + 0.2896
⑪ 0.2896 x 2 = 0 + 0.5792
⑫ ……
将每一步的积整数部分正列,得到小数部分二进制 10011110110 。但是根据上述过程可得知,根本取不尽,因此十进制小数转其他进制均会有精度损失。例如这个数字作为小数部分,仅仅等于 0.6201171875,与预期的 0.6204 仍有约 0.0003 的差距。只有当二进制小数位数足够多,结果才能无限趋近于十进制的小数。
同样,追根究底地,为什么小数部分是乘以 2 。
先看十进制,十分位满 10 才等于个位的 1 ,因此,十分位每增加 1 ,代表增加了 0.1 。百分位满 10 才等于十分位的 1, 因此,百分位每增加 1 , 代表增加了 0.01 ,以此类推。
以上看似好像废话,但如果是二进制呢?十分位满 2 即可等于个位的 1 ,因此十分位每增加 1 ,代表增加了 0.5,百分位满 10 才等于十分位的 1, 因此,百分位每增加 1 , 代表增加了 0.25 。其他进制也类似,参考 这个公式即可。
3、数据的储存方式
老生常谈的废话:数据在计算机中以二进制存储。而在开头已经提到,存储的格式只有整型及浮点型。同样的数值,通过整型及浮点型的方式储存,其结果完全不同。先对这两句代码进行调试,查看内存中 i 和 f 的储存样貌:
int i = 1;
float f = 1.f;内存中 i 的数值如下图:
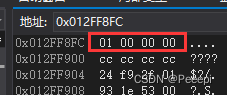
所以 i 实际在内存中储存样貌是 0000 0000 0000 0000 0000 0000 0000 0001 。
内存中 f 的数值如下图:
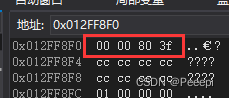
换算二进制可得,f 在内存中储存样貌是 0011 1111 1000 0000 0000 0000 0000 0000 。
数值同为 1 ,储存结果截然不同是因为储存的标准不同。
3.1、整型数据的储存
整型的储存是直接将数值转换为二进制进行存储。但有符号(signed)和无符号(unsigned)的储存方式略有不同。
3.1.1、unsigned类型
先说无符号整型,该类型最为简单粗暴。由于该类型不存在负数,只需根据 char 、 short 、 int 、 long 、 long long 等这些不同类型占用的内存空间大小直接对数据进行二进制存放。
| 数据位1 | 数据位2 | 数据位3 | 数据位4 | …… | 数据位n |
据此还可以得出 unsigned 各个类型的取值范围:
| 类型 | 取值范围 | 所占字节 |
| unsigned short | 0 至 |
2 |
| unsigned int | 0 至 |
4 |
| unsigned long | 0 至 |
4 |
| unsigned long long | 0 至 |
8 |
3.1.2、signed类型
signed 类型储存正数与 unsigned 类型无异。但该类型在内存中最高位占用 1 bit 作为符号位,该位置正数为 0 ,负数为 1 。
| 符号位 1bit | 数据位1 | 数据位2 | 数据位3 | …… | 数据位n-1 |
也就是说,比如 int 类型,其二进制取值范围:
0000 0000 0000 0000 0000 0000 0000 0000 至 0111 111 1111 1111 1111 1111 1111 1111
负数二进制取值范围:
1000 0000 0000 0000 0000 0000 0000 0000 至 1111 111 1111 1111 1111 1111 1111 1111
比如 int 类型的 1 和 -1,转换为二进制分别为:
0000 0000 0000 0000 0000 0000 0000 0001(1)
1000 0000 0000 0000 0000 0000 0000 0001(-1)
上述的二进制写法称作原码。其中 1 的二进制便是内存中储存的样子。但 -1的储存,并非如上所述 。除了将符号位写为 1 表示负数外,还涉及到反码及补码。
先说结论,内存中储存的数据均为补码,而正整数的反码及补码是其本身。负数则需要经过转换。
3.1.2.1、反码
顾名思义,反码是对原码除符号位之外的每一位分别取反,即对每一位进行 ~ 操作。如 char 类型下的 -110 原码是 1001 0010 ,其反码则为1110 1101 。排除符号位之后,而且根据二进制的特性,反码的反码即为原码(进行 2 次 ~ 操作),即 ~(~001 0010) = 001 0010。而且反码加原码即每一位都为1 ,即 001 0010 + 110 1101 = 111 1111 。
3.1.2.2、补码
在反码的基础上加 1 即为补码。如 char 类型下的 -110 原码是 1001 0010 ,其反码则为 1110 1101 ,补码为 1110 1110 。1110 1101 的补码便是 1110 1101 + 1 = 1110 1110 。同样,补码的补码为原码。
3.1.2.3、整型负数的储存
根据运算规则,一个数加上其相反数,结果为 0 ,而负数的符号位 1 可以看作是正数符号位 0 的 ~ 运算。也就是说,负数的补码可以看作是其相反数(正数)的 ~ 运算后再加一。
计算机在读取写入及计算时,根本不区分符号位数据位,只是将对这些二进制补码直接进行操作。仅仅在展示数值时对这些二进制进行翻译。如以下代码:
short s = 32767;
s += 3;
printf("%%d = %d\n", s);
printf("%%u = %u\n", s);
//输出
//%d = -32766
//%u = 65534
//
// s = 0111 1111 1111 1111 (补码)
// s + 3 = 0111 1111 1111 1111 + 0000 0000 0000 0011
// = 1000 0000 0000 0010 (补码)
// = 1111 1111 1111 1110 (原码)
// = -32766 (翻译为有符号十进制)
// = 65534 (翻译为无符号十进制)顺带一提,计算机只会加法,减法、乘法、除法、取模等都是通过加法实现的。如 char 类型下的 3 - 3 在计算机看来是 3 + (-3) ,补码上呈现的是 0000 0011 + 1111 1101 = 1 0000 0000 。而char 类型只截取 1 个字节,因此最高位的 1 被舍去,称作溢出,剩余 0000 0000 。如此实现 3 - 3 = 0 的操作。
另外最高位为 1 ,其他位为 0 的情况需要单独说明,以 char 类型来举例。 1000 0000 因为符号位是 1 ,作为负数,得到反码是 1111 1111 ,原码为反码 + 1 ,得到原码 1000 0000 。十进制是 - 0 。在数学上, -0 = 0 。至此除了重复定义 0 之外,似乎没什么问题。但一旦涉及计算,问题便出现了:
1000 0000 - 0000 0001 = 0111 1111(-0 - 1 = 127)
0000 0000 - 0000 0001 = 1111 1111(0 - 1 = -1)
1000 0000 - 0000 0010 = 0111 1110(-0 - 2 = 126)
0000 0000 - 0000 0010 = 1111 1110(0 - 2 = -2)
1000 0000 - 0000 0011 = 0111 1101(-0 - 3 = 125)
0000 0000 - 0000 0011 = 1111 1101(0 - 2 = -3)
……
至此便会颠覆整套设定好的规则。
而如果将 1000 0000 规定为 -128,以上问题便不再存在。而且符合逻辑:
1000 0001 - 0000 0001 = 1000 0000(-127 - 1 = -128)
因此规定,1000 0000 作为 -128 。
3.1.2.4、补充
根据以上规则,也能得出 signed 各个类型的取值范围。
| 类型 | 取值范围 | 所占字节 |
| signed short | 2 | |
| signed int | 4 | |
| signed long | 4 | |
| signed long long | 8 |
3.2、浮点型数据的储存
连只学了两天 C 语言的都知道,浮点数用于储存小数。
早期的小数储存方式类似于 SQL 中的 Decimal 类型,分别在内存中储存完整有效数字、数字长度、小数位数,而这三部分的数据存储是将整个数据空间划分为三块,分别以类似整型的方式储存。但由于用到小数位数不同等原因造成了编码极其繁琐。因此逐渐摒弃。如今小数储存大部分采用 IEEE754 标准。
先提一嘴,IEEE754 标准储存的数据类型均称为浮点型,浮点型不一定是小数,而是以二进制科学计数法储存的实数。
3.2.1、二进制的科学计数法
要了解二进制科学计数法则必须先了解十进制科学计数法。
将一个十进制数表示为 a 与 10 的 n 次幂相乘,且满足 ,则称为科学计数法。在 C 语言中的浮点型常量有两种表示方法,其中一种即为科学计数法。如下所示:
double a = -123.45; //常规表示
double b = -1.2345e2; //科学计数法表示
a == b ? printf("a = b\n") : printf("a != b\n");
//输出 a = b 可见 -1.2345e2 与 -123.45是等价的,其在数学上写作 。此外, 1234.5 可以写作
, 0.12345 写作
。如同以上,小数点的位置是根据指数数值进行左右浮动而确定的,因此该类型才称之为浮点型。
至于二进制的科学计数法,根据前文所提及的十进制转二进制规则,将 -123.45 表示为二进制形式,约为:
-1111011.01110011001 (存在精度损失)。
再根据十进制的科学计数法规则推导出二进制表示法: 将一个二进制数表示为 a 与 10 的 n 次幂相乘,且满足 ( 10 为二进制的 2 )。因此该数字可以表示为 :
。
如同 C 语言中浮点型常量将十进制将 写作 e ,其也可以写作:
-1.11101101110011001e110 。
3.2.2、浮点型的内存空间划分
IEEE754 标准核心即是二进制的科学计数法。接下来用 -1.11101101110011001e110 作为实例来说明该标准的实现方式。
先观察 -1.11101101110011001e110 这个数决定其值的三个部分:负号、 e 之后的二进制整数、e 之前的二进制小数。因此该标准规定了三个区域分别储存以上数值:符号位、指数位、尾数位。标准中常用的浮点类型有两个,分别是 float 类型和 double 类型。其中, float 类型占 4 字节(即 32 bit),double 占 8 字节(即 64 bit)。因此,标准对于这两种类型在内存中的空间规定如下表:
| 类型 | 符号位 | 指数位 | 尾数位 |
| float | 1 bit | 8 bit | 23 bit |
| double | 1 bit | 11 bit | 52 bit |
符号位如同整型,0 为正数, 1 为负数。
尾数位需稍经处理。由于二进制数只存在 0 或者 1 ,但 ,所以个位只能是 1 。所以标准省略了个位的 1 ,只记录小数部分的 11101101110011001 ,所以这部分称作尾数位。读取的时候也会由于浮点类型,自动在整数部分加上 1 。
指数位较为复杂。由于指数位没有指数符号位,但指数存在正负数之分,所以规定一个中位数(最大值除以 2 )作为 0 ,小于中位数则为负数,大于中位数则为正数。写入时将实际值加上中位数后进行储存。
如 float 指数位占 8 bit ,可以表示 0 至 255中任意数,将其中位数(0111 1111)作为 0,将 0000 0000 作为 -127,1111 1110 作为 127,而 double 的中位数为 1023。
此外,指数位全为 1 的情况另行规定:
| 符号位 | 指数位 | 尾数位 | 输出 | 含义 |
| 0 | 全1 | 全0 | inf | 正无穷 |
| 1 | 全1 | 全0 | -inf | 负无穷 |
| 0 或 1 | 全1 | 全0除外任意 | NaN | 非数 |
如果 -1.11101101110011001e110 作为 float 类型,经过以下三步转换为 IEEE754 标准:
a、符号位:负数,为 1 ;
b、指数位:加上中位数 127,为 1000 0101
c、尾数位:不满 23 bit 的末尾补 0 ,为 111 0110 1110 0110 0100 0000 。
得到结果 1100 0010 1111 0110 1110 0110 0100 0000 。
4、再谈观察方式(数据读取)
先看以下代码:
#include <stdio.h>
int main()
{
unsigned int a;
a = 2457235520u;
//a的二进制 1001 0010 0111 0110 0111 0000 0100 0000
int* pi = (int*)&a;
short* ps = (short*)&a;
float* pf = (float*)&a;
char* pc = (char*)&a;
printf("%d\n", *pi);
printf("%d %d\n", *ps, *(ps + 1));
printf("%.100f\n", *pf);
printf("%c %c %c %c\n", *pc, *(pc + 1), *(pc + 2), *(pc + 3));
printf("%d %d %d %d\n", *pc, *(pc + 1), *(pc + 2), *(pc + 3));
printf("\naddress:\n");
printf("%p %p %p %p\n", pc, (pc + 1), (pc + 2), (pc + 3));
}
/*
输出:
-1837731776
28736 -28042
-0.0000000000000000000000000007776227188095234067619763227922146617840729043713565715734148398041725159
@ p v ?
64 112 118 -110
address:
009AFA3C 009AFA3D 009AFA3E 009AFA3F
(上述地址每次运行都不一样,但一定是连续的)
*/这段代码阐述了对于内存中同一个地址中 unsigned int 类型的数据 1001 0010 0111 0110 0111 0000 0100 0000 根据不同类型的观察方式得到不一样的结果。深究为什么会得到这样的结果便不得不了解这个数据在内存中是如何储存的。
首先 unsigned int 类型占用内存空间为 4 字节,因此此次运行 unsigned int a 语句便在内存中申请地址为 009AFA3C ~ 009AFA3F 这 4 个字节的空间。之后的 a = 2457235520u 便将该十进制无符号整型常数转换为二进制 1001 0010 0111 0110 0111 0000 0100 0000 储存进这块空间中。
但由于空间是 4 字节,因此将此二进制拆成 4 段每段 8 bit 的数据,并从最后 8 bit 往前依次存入申请到的地址中。如下表:
| 内存地址 |
储存数据 Binary |
储存数据 Signed Decimal |
| …… | …… | |
| 009AFA41 | - | - |
| 009AFA40 | - | - |
| 009AFA3F | 1001 0010 | -110 |
| 009AFA3E | 0111 0110 | 118 |
| 009AFA3D | 0111 0000 | 112 |
| 009AFA3C | 0100 0000 | 64 |
| 009AFA3B | - | - |
| 009AFA3A | - | - |
| …… | …… |
此时 a 的地址实际上是储存此二进制数据最后 8 bit 的内存空间地址。之后,我们分别以 int 、 short 、 float 、 char 类型的观察方式读取这段空间中的数据。
首先是 int 类型观察 1001 0010 0111 0110 0111 0000 0100 0000 。 符号位是 1 ,因此它是个负数,所以是 - 0110 1101 1000 1001 1000 1111 1100 0000 ,因此是 -1837731776 。
short 类型由于只占 2 字节,所以分别用 short 观察前 2 字节和后 2 字节。分别是 0111 0000 0100 0000 和 1001 0010 0111 0110 。其中 1001 0010 0111 0110 即为 -0110 1101 1000 1010 。 所以是 28736 和 -28042。
用 float 观察则该数据等于 ,因此输出上述结果。
char 类型观察此数据每个字节,观察结果即为上表中数据的十进制。以字符表示即为 @ 、 p 、 v 、 ? 。
这便是马铃薯、土豆和花生的关系。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)