模型评估指标详解(分类、回归)
建模常用的分类、回归模型评估指标。
模型评估指标详解(分类、回归)
分类模型评估指标
对于构建好的分类模型,需要对模型的效果进行评估,本节介绍分类模型常用的评估指标。
以二分类问题为例,考虑真实分类和模型预测的组合,会出现以下4种结果:
上述矩阵称之为混淆矩阵,是一个N X N的方阵,其中 表示类别数。对于二分类而言,就是 的矩阵,其中:
TP 对应 true positive,真正例,真实分类为正,模型预测也为正;
TN 对应 true negative,真反例,真实分类为反,模型预测也为反;
FP 对应 false positive,假正例,真实分类为反,模型预测为正;
FN 对应 false negative,假反例,真实分类为正,模型预测为反。
基于以上4种结果,得出了以下几个分类评估指标:
准确率(Accuracy)
准确率:对于给定的测试数据集,分类器正确分类的样本数与总样本数之比,其计算公式为: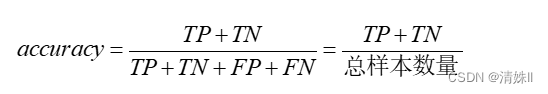
准确率本质是预测正确的概率,应该越大越好,准确率越高,说明模型预测正确的样本比例越高,模型性能越好。
查准率(Precision)
查准率,又称为精确率,指的是模型预测为正的样本中实际情况也为正的概率,公式如下: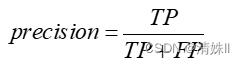
查准率反映预测为正类的样本中有多少是预测对的,衡量模型预测的精确性,查准率越高,分类器对正样本的识别能力越强,说明模型的效果越好。
召回率(Recall)
召回率,又叫做查全率,指的是实际为正的样本中模型预测为正的概率,公式如下: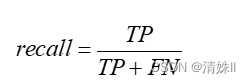
召回率反映真实为正类的样本中有多少是预测为正的,衡量模型查找正类样本的性能,召回率越高,分类器对正样本的查找能力越强,说明模型的性能越好。
F1分数(F1-Score)
可以看出,召回率和查准度是一对相对的概念,它们在关注正类样本的识别过程中,各有侧重点。召回率的目标是尽可能地将正类样本识别出来,而查准率则追求在每次对正类样本的判断都能获得正确的结果。
然而,在大多数情况下,我们的期望是获得一个在两者之间实现“均衡”的模型评估指标,既不希望模型过于冒进,也不希望模型过于保守。特别是对于偏斜的样本,不仅要求模型能够准确地识别出正类样本,同时也希望能尽可能地减小对负类样本准确率的牺牲。因此,在这种情况下,可以考虑使用召回率和查准率的调和平均数作为模型评估指标,这就是F1-Score,其常用的一种计算公式为: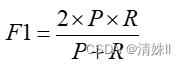
其中,P 为查准率,R 为召回率。
F1-Score是综合考虑使用召回率和查准率的指标,F1-Score越高,模型分类效果越好。
P-R曲线、ROC曲线
P-R曲线:
对于不同的应用场景,精确率和召回率两个指标各有侧重。精确率和召回率是此消彼长的关系,二者之间的关系可以通过P-R曲线来描述:
可以看到,精确率和召回率是此消彼长的关系。精确率越大,召回率越小;精确率越小,召回率越大。在P-R曲线中,存在一个平衡点的概念,即Break-Even Point, 简称BEP,在该点处,查准率=召回率。
ROC曲线:
ROC的全称为Receiver Operating Characteristic,被翻译为受试者工作特征曲线,为了理解ROC曲线,首先要搞清楚以下两个概念:
1.True Positive Rate, 简称TPR,称之为真阳性率,描述的是实际为正的样本中,模型预测为正的概率,就是召回率了,这个指标也叫做灵敏度;
2.False Positive Rate, 简称FPR, 称之为假阳性率,描述的是实际为负的样本中,模型预测为正的概率。假阳性率又等价于1 - 特异性。
对于真阳性率和假阳性率而言,这两个指标都是基于实际样本中正和负两部分的数目单独分开定义的,所以无论实际样本正负分布的比例有多么不均衡,都不会影响这两个指标的计算。ROC曲线就是以这两个指标为轴进行绘制的,其中横轴为假阳性率,纵轴为真阳性率。
和P-R曲线类似,ROC曲线可以展示同一个模型,不同阈值条件下的效果,相比单一阈值条件下计算的准确率,精确率,召回率,其衡量模型泛化能力的效果更强。
ROC曲线下的面积,即Area Under Curve, 简称AUC。对于一个模型而言,其AUC越大,效果越好。AUC取值范围为0到1, 0.5表示随机选择,所以0.5-1之间的模型是有实际意义的分类模型,其中0.5-0.7, 效果较低,0.7-0.85,效果一般,0.85-0.95,效果很好,0.95-1,效果非常好。
回归模型评估指标
平均绝对误差(MAE)
平均绝对误差是衡量预测模型准确性的一种标准,它是所有实际观察值和预测值之间的绝对误差的平均值。MAE的计算公式为: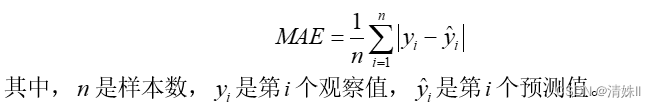
MAE的值越小,预测模型的准确性越高。具体来说,MAE=0表示预测模型的预测结果和实际观察值完全一致,没有误差。MAE的值越接近0,预测模型的准确性越高。并且,MAE只关注误差的绝对值大小,并未考虑误差的方向。这意味着,无论预测值是大于还是小于实际观察值,只要绝对误差一样,对MAE的贡献就是一样的。因此,MAE不能提供误差方向的信息,它只能提供预测模型准确性的大概情况。
均方误差平方和(MSE)
均方误差平方和:计算每一个样本的预测值与真实值之差的平方,然后求和再取平均值,计算公式为:
该指标计算的是拟合数据和原始数据对应样本点误差的平方和的均值,其值越小说明拟合效果越好。
可决系数( R^2)
可决系数(记为R^2 ),亦称测定系数、判定系数、可决指数,在统计学中用于度量因变量的变异中可由自变量解释部分所占的比例,以此来判断统计模型的解释力。可决系数 计算公式为: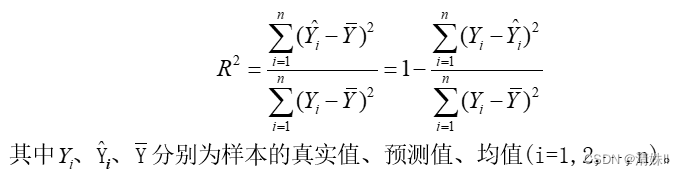
可决系数值在0~1之间,越接近于1,说明模型的预测效果越好,越接近于0,说明模型的预测效果越差。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)