【MongoDB 实战】 07 MongoDB 是如何进行文档模型设计的呢?
传统的数据库设计是如何进行的呢?MongoDB 文档模型设计有哪些特点,与关系模型区别?文档模型设计步骤有哪些 ?文档模型设计优点?传统模型设计首先进行需求分析,得出概念模型,其次通过E-R 实体关系图,描述各实体之间的关系,最后进行物理模型设计,三范式等设计原则设计表结构,这是一个逐层细化的过程。E-R实体关系图三要素我们还记得么,实体,属性,关系,结构如下所示:JSON ...
- 传统的数据库设计是如何进行的呢?
- MongoDB 文档模型设计有哪些特点,与关系模型区别?
- 文档模型设计步骤有哪些 ?
- 文档模型设计优点?
传统模型设计
首先进行需求分析,得出概念模型,其次通过E-R 实体关系图,描述各实体之间的关系,最后进行物理模型设计,三范式等设计原则设计表结构,这是一个逐层细化的过程。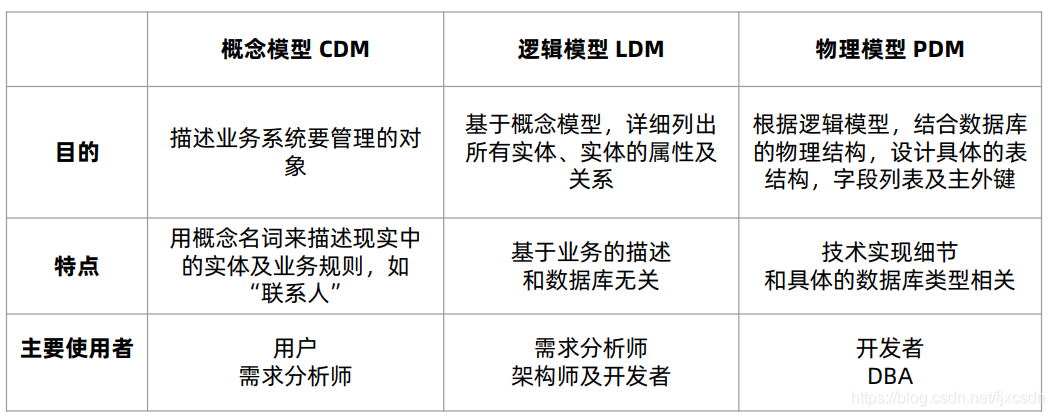
E-R实体关系图三要素我们还记得么,实体,属性,关系,结构如下所示: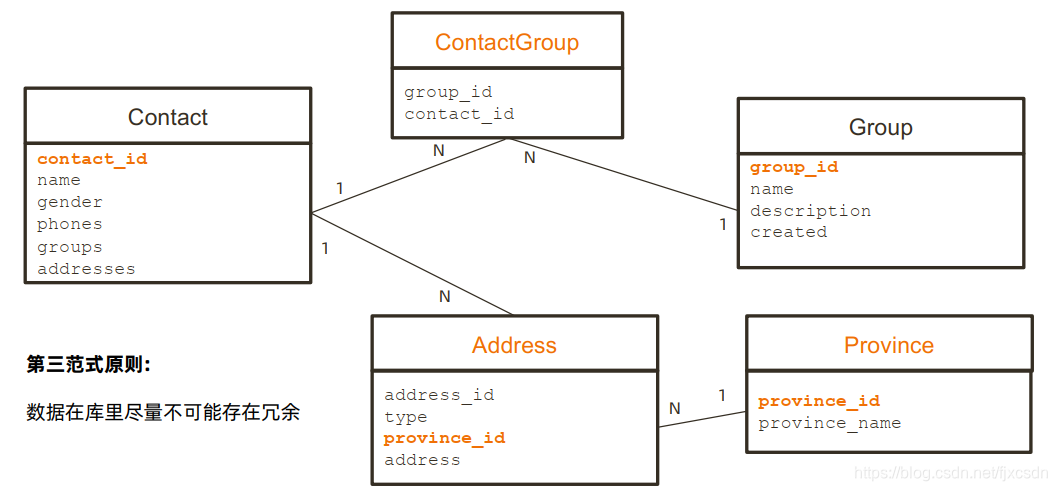
JSON 文档模型设计特点
关系型数据库设计时,实体和实体之间一对多的关系时,此时需要将数据拆分为多张表,然后通过主外键进行联系,如果是实体和实体之间是多对多关系,此时则需要额外建立第三张表。MongoDB 则有所不同,它是基于json 格式存储数据,可以通过内嵌数组和引用字段的方式,只需要维护一个集合即可,且不需要遵从第三范式,允许存在冗余字段。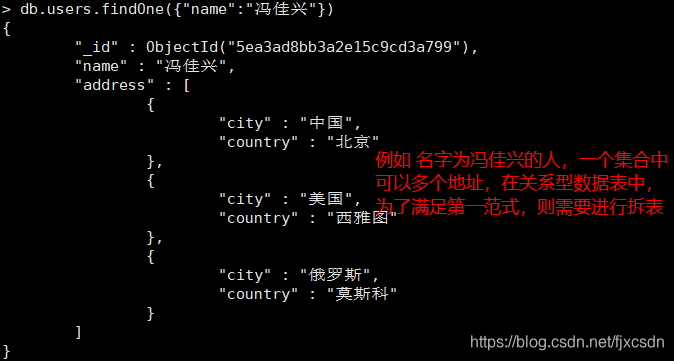
此时你是否会想,MongoDB文档模型设计过程中也不需要描述实体和实体之间关系,所以所有的数据就都可以放到一个文档里面了,也就是时候整个过程中根本没有进行概念和逻辑建模。那mongoDB岂不是成了无模式设计了?
严格来说,MongoDB 也需要进行概念和逻辑建模,其实逻辑建模就是物理建模的过程,其实整个过程省略了物理建模的过程。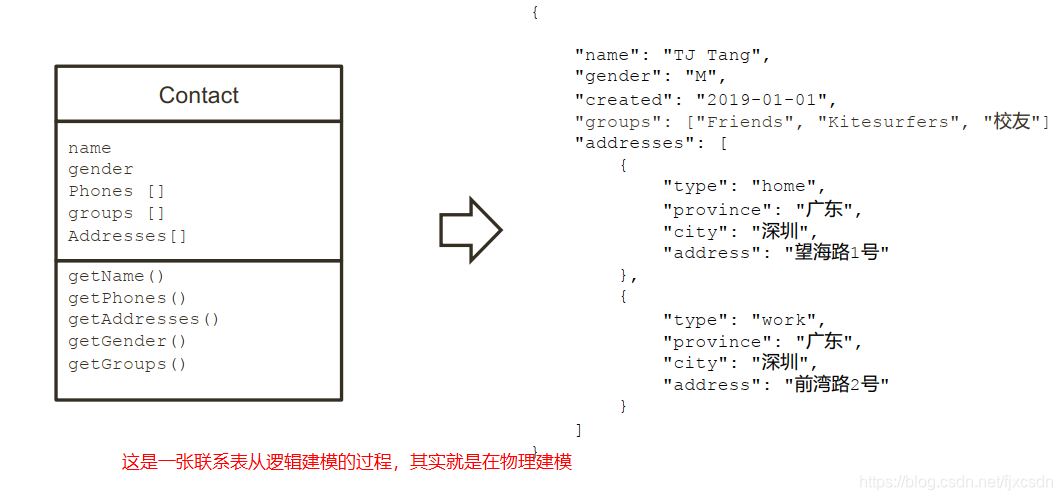
关系模型 VS 文档模型
| header1 | 关系型数据库 | JSON文档模型 |
|---|---|---|
| 设计层次 | 概念、逻辑、物理 模型 | 概念、逻辑 |
| 实体 | 表 | 集合 |
| 属性 | 列 | r字段 |
| 关系 | 主外键 | 内嵌数组,引用字段 |
文档模型设计
如何进行文档模型设计呢?文档模型设计三部曲,分别是基础建模,工况细化,套用设计模式。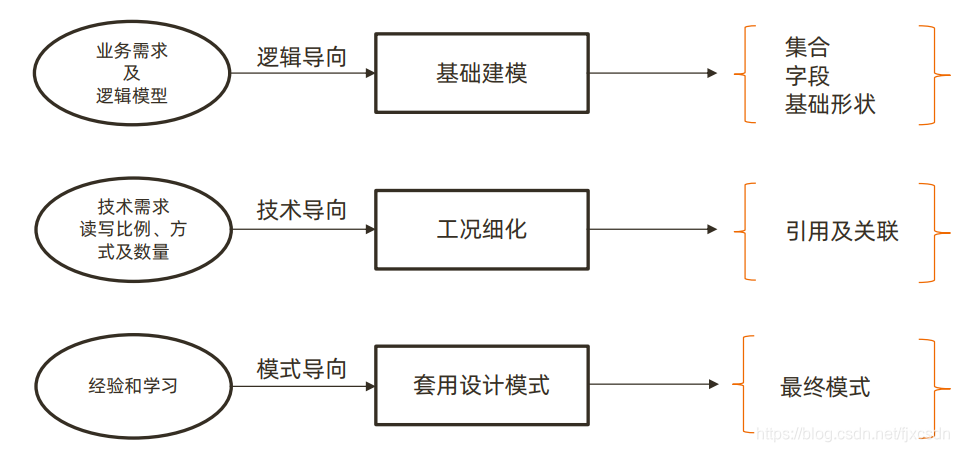
第一步,基础建模

实体就是对象,在mongoDB我们可以称实体为集合,数据就是文档,大家一定要适应各种叫法
基础建模我们首先找实体,也就是根据业务需求推导出对象,其次明确实体和实体之间的关系,设计E-R实体图。mongoDB 虽然可以内嵌,但是不是所有的数据都放到一个文档中,这样是不可行的,会导致数据库变得臃肿。基础建模后非常利于查询操作,但是有一个前提,整个集合大小不得超过16M。
实体和实体之间关系
一对一:采用内嵌为主,将一个集合作为子文档内嵌到集合当中,且不存在冗余。一对多:采用内嵌数组的方式,将数据放入的集合当中,且不会存在冗余。多对多:采用内嵌数组的方式,但存在数据冗余,下面有一张客户营销联系表,就提到了这一点。
总结:当集合和集合之间关系为多对多时,存在大量数据冗余,此时可以考虑拆集合。
第二步,工况细化:根据各种条件将一个集合拆分为多个集合。
通过引用(主外键的方式进行多个集合之间连接)和关联进行多表联查。
第一步我们通过基础建模,形成了基本的集合,但是此时集合过于臃肿,可能会出现以下情况
读写失衡:一张表如果写操作频繁,读操作比较少,如果文档过大,性能则会降低。常用的查询参数:有些字段访问频繁,有些字段基本不访问,此时则需要拆集合。频繁改动的字段:如下图,如果字段频繁改动,则设计到百万数据同时改动,这样是不合理的。
为了解决上述问题,我们需要单独将分组字段独立出来形成一个新的Group 集合,通过主外键连接。查询时则通过 lookup进行联表查询,且lookup 进行联表查询,且lookup进行联表查询,且lookup 只支持 left outer join ,关联的目标(from)不能是分片表。
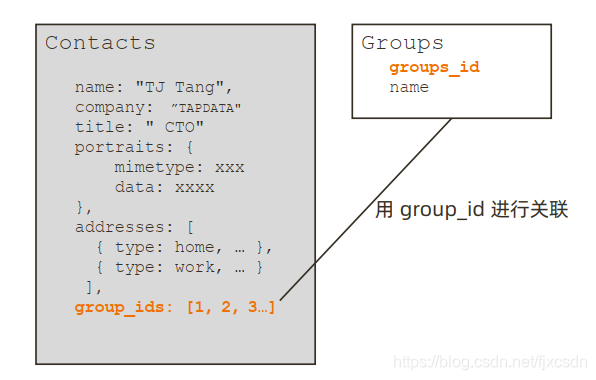

数据量大小:有的字段可能是一个超清的头像,且头像所占空间大小基本在 5M 以上,且查询的次数非常少,如果此时和普通的基础信息在一个集合当中,是非常耗时的,此时可以采用引用的方式,将头像单独放入一个集合当中,从而提高查询效率。
引用方式使用场景:
- 内嵌文档过大,且在MB级别或者超多16M
- 内嵌文档或数组改动频繁
- 内嵌数组元素一直持续增长

第三步,套用设计模式

套用设计模式,是根据不同的业务场景,选择相应的解决模式。
分桶嵌套模式
例如我们设计采集日志的系统,智慧交通,智慧社区,每分钟都会采集交通和社区情况,且采集的信息很固定,如果采集频率较高,就会形成多个集合,此时可以采用内嵌数组的方式,将一个时间段内的数据放到一个集合当中,从而提高公用字段,以及索引的使用,提升数据读写效率,降低资源需求。
列转行设计模式
不同电影在多个国家不同日期上映,就会形成如下表,如果此时只有4个国家,一个电影则需要4个日期索引,如果是1万个电影呢,如果是100个国家呢,索引数量是很大的。
版本字段模式
MongoDB 数据是支持动态扩展字段的,关系型数据库则不可以,当我们动态增加集合中的字段时,可能会造成同种集合,确有着不同的字段,此时需要一个增加一个版本字段。

近似计算

如果每点击一下,进行一次数据库数据的更新操作,消耗太多资源,可以通过计时器,每10次写入一次,可减少频繁写入数据库的次数。
预聚合
如果有些数据需要精确的排名,例如商品热销排名,电影排行榜,电影院某电影场次统计,人数统计,关系型数据库中我们可以通过聚合函数来进行计算,此时聚合所花费的时间较长。
在 MongoDB 中我们可增加这些预聚合的字段,例如在销售表中增加一个一周商品销售总量的字段,每次更新数据库的时候该字段自增,查询的时候则不需要进行任何的聚合查询,是访问效率增加。
关于MongoDB 数据库文档设计我们先分享到这里,本篇案例多来自 TJ 唐建法老师的 MongoDB 高手课,喜欢的同学可以在极客购买,为老师点赞,欢迎同学留言评论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)