梯度下降 Gradient Descent 详解、梯度消失和爆炸
1、什么是梯度在微积分中,对多元函数的参数求∂偏导,把求得的各个参数的偏导数以向量形式写出来即为梯度。例如对于函数f(x,y),分别对x,y求偏导,求得的梯度向量就是 (∂f/∂x, ∂f/∂y)^T,简称 grad f(x,y),或者▽f(x,y)。相对于的,在点(x_0,y_0)处的梯度就是(∂f/∂x_0, ∂f/∂y_0)^T, 或者记做 ▽f(x_0,y_0)。2、梯度的意义...
1、什么是梯度
在微积分中,对多元函数的参数求∂偏导,把求得的各个参数的偏导数以向量形式写出来即为梯度。
例如对于函数f(x,y),分别对x,y求偏导,求得的梯度向量就是 (∂f/∂x, ∂f/∂y)^T,简称 grad f(x,y),或者▽f(x,y)。相对于的,在点(x_0,y_0)处的梯度就是 (∂f/∂x_0, ∂f/∂y_0)^T, 或者记做 ▽f(x_0,y_0)。
2、梯度的意义
从几何的角度上讲,就是函数变化增加最快的方向。或者说,沿着梯度的方向更容易找到函数的最大值,反过来说沿着梯度相反的方向更容易找到函数的最小值,这就奠定了后面在求解损失函数的最小值时,可以使用梯度下架来求解参数。
3、梯度下降法详解
3.1、梯度下降的直观解释
假设我么在一片山脉上,随机初始化一个坐标,那么沿着梯度的方向就是我们向最陡峭的方向前进一步,这个步长的大小由学习率控制。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
由此来看,使用梯度下降很有可能出现2种情况:
- 跨步太小陷入局部最优无法自发
- 跨步太大错过全局最优
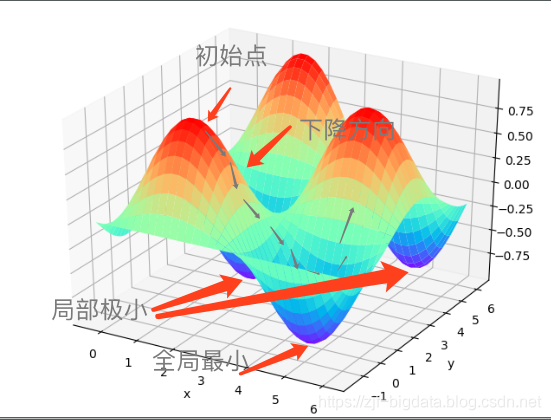
3.2 这中间涉及到几个相关概念:
- 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。
- 特征(feature):指的是样本中输入部分,比如2个单特征的样本(𝑥(0),𝑦(0)),(𝑥(1),𝑦(1)),则第一个样本特征为𝑥(0),第一个样本输出为𝑦(0)。
- 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数,记为ℎ𝜃(𝑥)。比如对于单个特征的m个样本(𝑥(𝑖),𝑦(𝑖))(𝑖=1,2,…𝑚),可以采用拟合函数如下: ℎ𝜃(𝑥)=𝜃0+𝜃1𝑥。
- 损失函数(loss function):为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输 出和假设函数的差取平方。比如对于m个样本(𝑥𝑖,𝑦𝑖)(𝑖=1,2,…𝑚),采用线性回归,损失函数为:𝐽(𝜃0,𝜃1)=∑𝑖=1𝑚(ℎ𝜃(𝑥𝑖)−𝑦𝑖)2 其中𝑥𝑖表示第i个样本特征,𝑦𝑖表示第i个样本对应的输出,ℎ𝜃(𝑥𝑖)为假设函数。
4、梯度下降求解
4.1、确定优化模型的假设函数和损失函数
这里,我们以线性回归为例:假设函数表示为:ℎ𝜃(𝑥1,𝑥2,…𝑥𝑛)=𝜃0+𝜃1𝑥1+…+𝜃𝑛𝑥𝑛, 其中𝜃𝑖 (i = 0,1,2… n)为模型参数,𝑥𝑖 (i = 0,1,2… n)为每个样本的n个特征值。
这个表示可以简化,我们增加一个特征𝑥0=1 ,这样ℎ𝜃(𝑥0,𝑥1,…𝑥𝑛)=∑_𝑖=0-𝑛(𝜃_i*𝑥_𝑖)。
那么它对应的损失函数为: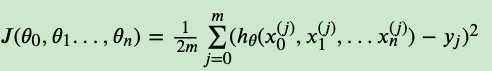
4.2、相关参数初始化
- 初始化参数矩阵 (𝜃0,𝜃1…,𝜃𝑛)
- 算法终止距离𝜀
- 步长𝛼
在没有任何先验知识的时候,一般将所有的𝜃初始化为0, 将步长初始化为1。在调优的时候再优化。
4.3、算法过程
- 确定当前位置的损失函数梯度,对于θ_j, 它当前的梯度表示为:
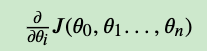
- 用户步长乘以损失函数的梯度,得到当前位置的下降距离,即:
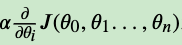
- 确定是否所有的𝜃𝑖,梯度下降的距离都小于𝜀,如果小于𝜀则算法终止,当前所有的𝜃𝑖(i=0,1,…n)即为最终结果。否则进入步骤4…
- 更新所有的𝜃,对于𝜃𝑖,其更新表达式如下。更新完毕后继续转入步骤1.
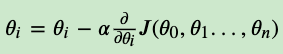
5、梯度下降法调优:
- 步长(学习率)的选择。在前面的算法描述中,我提到取步长为1,但是实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。前面说了。步长太大,会导致迭代过快,甚至有可能错过最优解。步长太小,迭代速度太慢,很长时间算法都不能结束。所以算法的步长需要多次运行后才能得到一个较为优的值。
- 参数初始化的选择。初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
- 特征数据归一化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化,也就是对于每个特征x,求出它的期望𝑥⎯⎯⎯和标准差std(x),然后转化为:
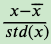
这样特征的新期望为0,新方差为1,迭代速度可以大大加快。
6、梯度下降法的所有变种:
- 批量梯度下降法 Batch Gradient Descent
- 随机梯度下降法 Stochastic Gradient Descent
- 小批量梯度下降法 mini-batch Gradient Descent。他结合了上述2种方案的优点
7、如何跳出局部极小值
- 使用SGD或者 MBGB
- 加入冲量 Momentum来冲出局部极小值。上一时刻的速度和当前时刻的梯度(加速度)共同作用的结果。
- 以多组不同的初始化参数值来初始化模型参数,按照标准方法训练完成后,取其中误差最小的解作为最终参数
- 目前绝大多数训练算法在碰到无论是鞍点或者局部最小值点的时候,它的学习率已经非常小了,所以会陷入非全局最优解。可在优化过程的末尾,放大学习率,让训练算法强行跳出当前的鞍点或者局部最小点
8、梯度消失/梯度爆炸
8.1、什么是梯度消失和梯度爆炸?它为什么会发生?
在典型的BP中,基于求导的链式法则,需要对激活函数进行求导。而有些激活函数求导之后的最大值 < 1 或者 > 1,那么在多层的网络结构中导数值的连续相乘会导致求出的梯度更新以指数的形式减小或者增加(趋向于0和∞)。这属于BP的先天缺陷,
8.1.1、从激活函数的角度而言,我们看看常用的激活函数图像和他们的导数图像:
tanh和它的导数图像如下:偏导后的值都是 <=1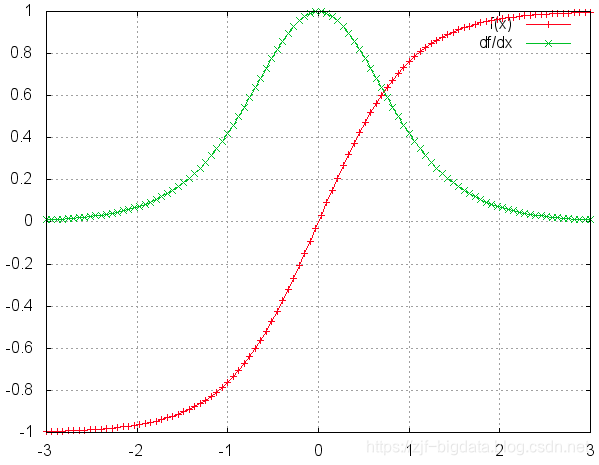
sigmod: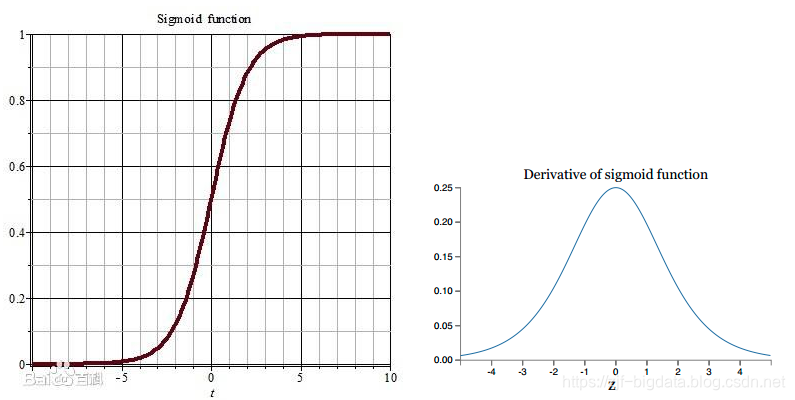
如果使用sigmoid作为损失函数,其梯度是不可能超过0.25的,这样经过链式求导之后,很容易发生梯度消失
8.1.2、从实际的模型角度来看,我们以一个4层全连接层网络为例:

假设每一层网络激活后的输出为f_i(x), 其中i为第i层, x代表第iii层的输入,也就是第i-1层的输出,f是激活函数,那么可以得出: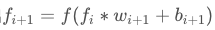
BP算法本身还是基于梯度下降策略,以目标的负梯度方向进行参数调整, 基于求导的链式法则: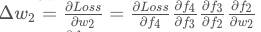
在公式中,∂f4/∂f3即时对激活函数求导,实际训练中网络层数远大于4层,如果此时的激活函数是 sigmod或者tanh,求导后的偏导值必 <=1, 所以本身 ▽w是无限趋近于0的,即“梯度消失”
8.2、解决方案是什么?
- 预训练加微调,先逐层每次只训练一层隐节点,再利用BP进行全局训练:Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。Hinton在训练深度信念网络(Deep Belief Networks中,使用了这个方法,在各层预训练完成后,再利用BP算法对整个网络进行训练。此思想相当于是先寻找局部最优,然后整合起来寻找全局最优,此方法有一定的好处,但是目前应用的不是很多了。
- 梯度的剪切和正则,本身主要解决梯度爆炸问题。
– 梯度剪切:为梯度设置一个剪切阈值,如果超过,那么将其强制限制再这个范围之内。
– 权重正则化:最为常见的是L1正则和L2正则。正则化是通过对网络权重做正则限制过拟合,表现形式为:Loss=(y−W^T*x)^2+α∣∣W∣∣^2
// 若搭建网络的时候已经设置了正则化参数,则调用以下代码可以直接计算出正则损失:
regularization_loss = tf.add_n(tf.losses.get_regularization_losses(scope='my_resnet_50'))
// 如果没有设置初始化参数,也可以使用以下代码计算L2正则损失:
regularization_loss = tf.add_n([tf.nn.l2_loss(var) for var in tf.trainable_variables() if 'weights' in var.name])
- 使用relue、leakrelu、elu等激活函数
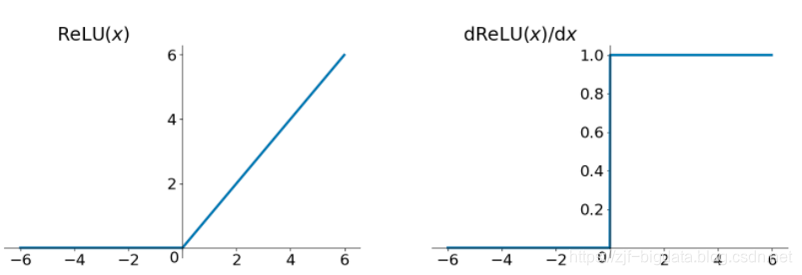
relu函数有一些问题:由于负数部分恒为0,会导致一些神经元无法激活(可通过设置小学习率部分解决)。这时候可以使用leakrelu函数来解决: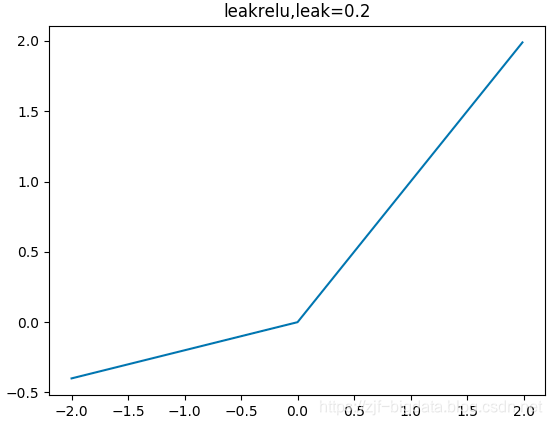
其数学表达为:leakrelu=max(k∗x,x) 其中k是leak系数,一般选择0.01或者0.02,或者通过学习而来
elu函数也能解决relu的0区间问题: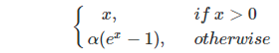
- 使用BN算法,通过对每一层的输出规范为均值和方差一致的方法,消除了x带来的放大缩小的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区 (参考:http://note.youdao.com/noteshare?id=199931798c93f6c3e683f57c6716c505)
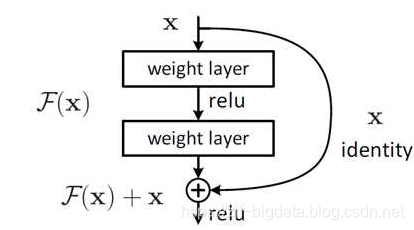
- 使用残差结构 , (残差详解:https://zhuanlan.zhihu.com/p/31852747)
- 使用LSTM (long-short term memory network)。lstm不那么容易发生梯度消失,因为其内部具有复杂的“门结构”,如下图,LSTM通过它内部的“门”可以接下来更新的时候“记住”前几次训练的”残留记忆“,因此,经常用于生成文本中。目前也有基于CNN的LSTM。下面简介LSTM如何记住前几次训练的残留记忆:
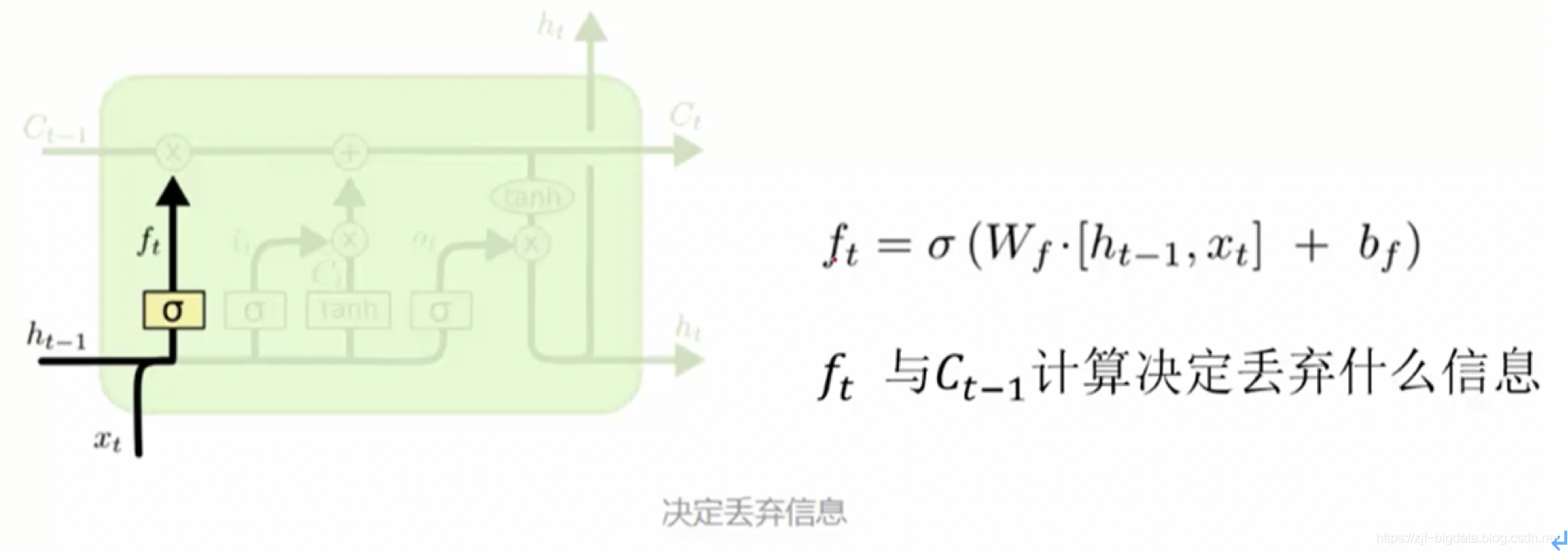
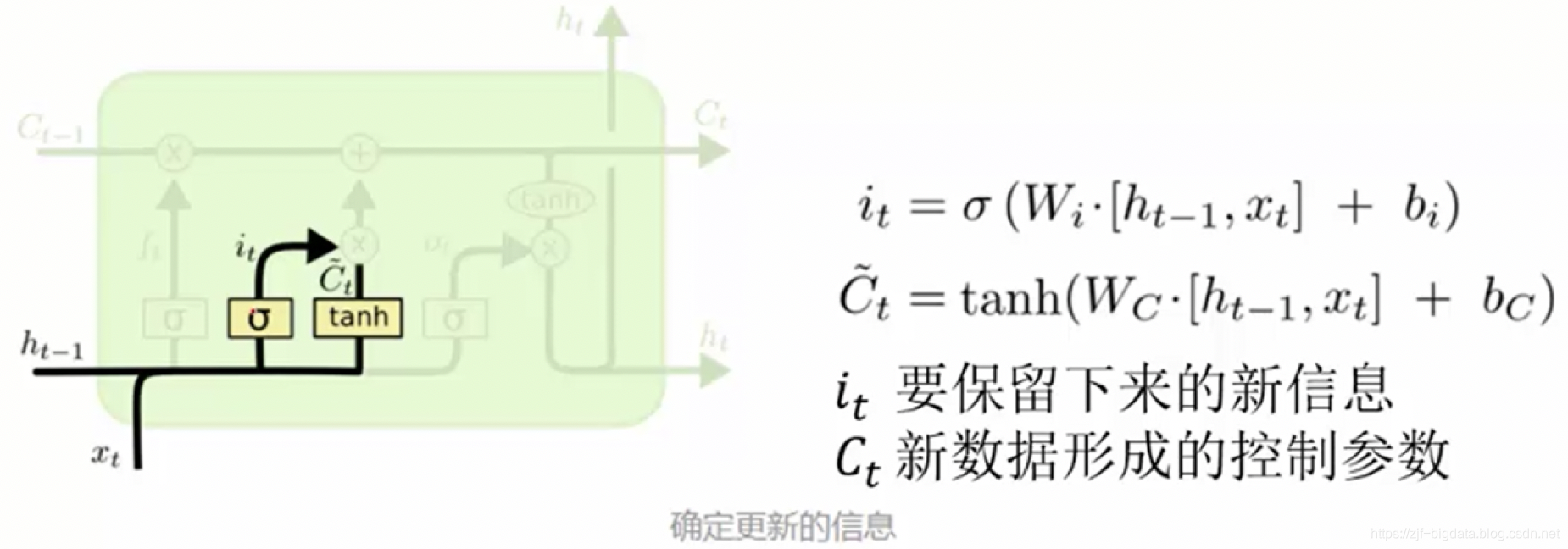
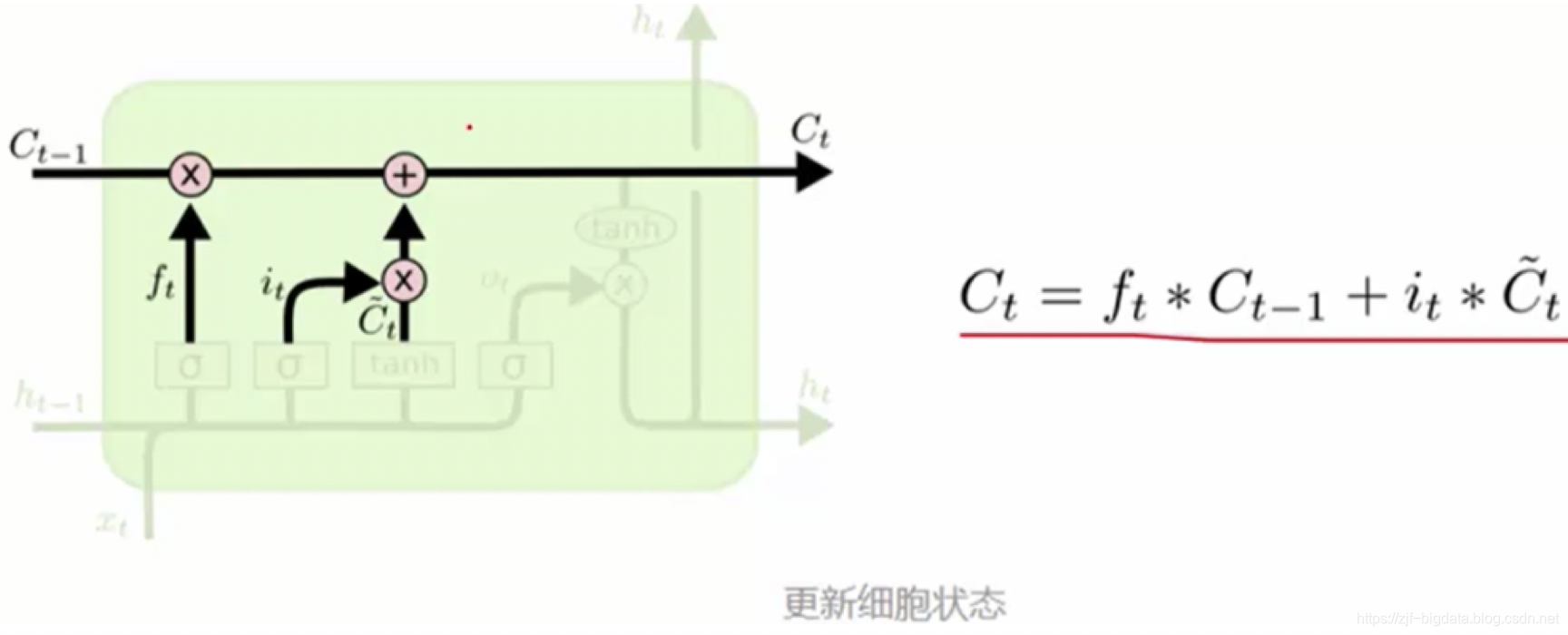

最后一个单元产生输出:Ot是什么都没忘的结果 与新控制参数组合产生输出
爸爸们赏点,交电费

附:
1、三维图片生成代码
# -*- coding:UTF-8 -*-
"""
@Description:
@Author: zjf
@Date: 2019/12/26 15:39
"""
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
from matplotlib import pyplot as plt
fig = plt.figure()
ax = Axes3D(fig)
x = np.arange(-0.1 * np.pi, 2 * np.pi, 0.2)
y = np.arange(-0.5 * np.pi, 2 * np.pi, 0.2)
X, Y = np.meshgrid(x, y) # 网格的创建,这个是关键
Z = np.sin(X) * np.cos(Y)
plt.xlabel('x')
plt.ylabel('y')
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='rainbow')
plt.show()
参考:
1、刘建平大佬总结 https://www.cnblogs.com/pinard/p/5970503.html
2、https://blog.csdn.net/qq_25737169/article/details/78847691
3、https://cloud.tencent.com/developer/article/1374163
4、ResNet残差:https://zhuanlan.zhihu.com/p/31852747

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)