python爬虫之xpath的使用
python爬虫之xpath的使用
当使用requests爬取得到html文档(静态网页)之后,需要从html文档字符串中提取和筛选出我们想要的数据,使用xpath来处理解析之后的html文档字符串,就可以快速的寻找和提取数据。
xpath的定位思路是利用html中的标签嵌套层级关系,利用路径的形式来匹配相应的元素节点,并返回匹配得到的节点对象(内容)。例如:html为根目录节点,html/body/div表示body中的一个div标签。
学习xpath主要学习其定位方法:包括绝对定位、相对定位、如何确定同一个层级下的指定的标签(利用属性)、从某个节点向前或向后定位节点、定位元素内容、定位属性…
xpath并没有返回定位得到的节点对象,而是将元素内容和标签属性都当做路径来进行定位,如:tree.xpath('//div[@class="song"]/img/@src')中的@src就表示这张图片的url,并没有提供get方法或者attrs等属性来获取属性。
另外也可以使用浏览器开发工具自动生成xpath路径或者使用xpath helper插件来调试xpath路径,就不需要我们花心思去构造xpath路径了。
目录
一,html文档中的元素层级关系图
概括的分类有下面三类。而子子节点(孙子节点)也可以看成是某个节点的子节点,为了记忆,不需要使用子子节点这种节点关系。

二,数据预处理
预处理是指将给定的文档字符串进行格式化,例如:将不全的标签进行补全,将层级关系没有对齐的对齐……
2.1 使用lxml的etree.Html&parse函数
from lxml import etree
etree.parse(filePath,) #本地的文件路径
etree.HtML('page_text') #page_ text互联网中响应的数据2.2 使用parsel.Selector()函数
from parsel import Selector
# html 可以是请求某个网页的源码,也可以是html,xml格式的字符串
selector = Selector(html)
得到selector对象之后就可以使用selector.xpath(路径字符串)来进行定位元素节点。下面将要介绍用pasel库使用xpath语法。
三,xpath语法
3.1 常用的基础语法
/:从html节点开始绝对定位&进入到下一个层级,eg:tree.xpath('/html/body/div') 。
//:从任意位置开始相对定位,eg:('//div[@class="song"]/p[3]')。
.:表示当前节点;..:表示当前节点的上一个节点。(类似于cmd的cd命令)。
@:用于匹配带有属性内容的元素节点,写在[]里面,例如:[@class="header"],他的作用就是修饰一个节点,以便于准确定位,如:tree.xpath('//div[@class="song"]/p[3]'),[@class="song"]用于修饰div标签,表示从这个div相对定位。
text():表示元素内容。
[index]:表示同一个层级中的第几个。如:tree.xpath('//div[@class="tang"]//li[5]/a/text()')[0]。
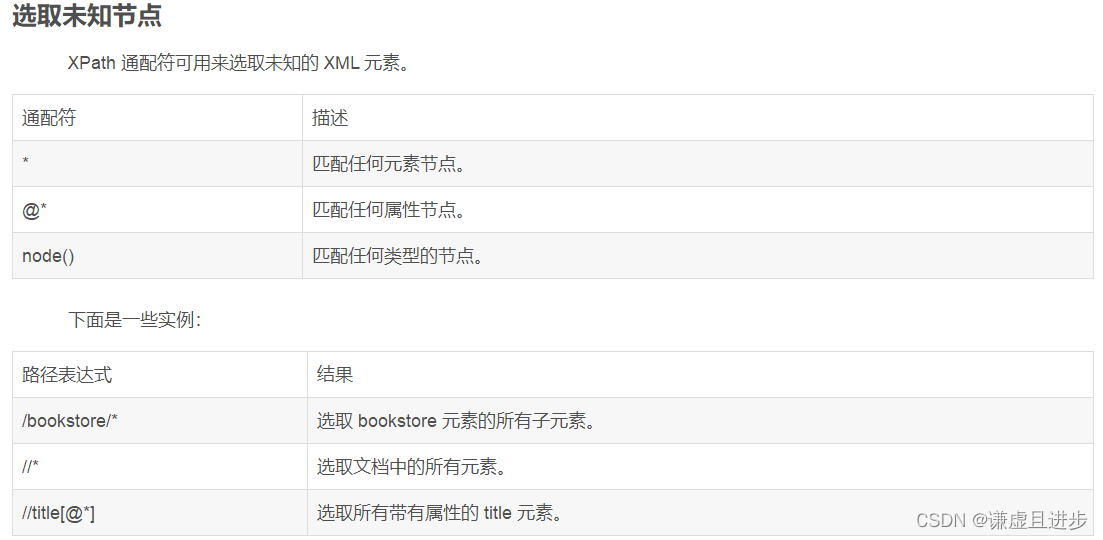
*:通配符,如"//div//*"选取div容器中的所有节点。
@*:@表示属性,@*表示任意属性,如[@*]。
node():某节点下的所有节点。

3.2 语法进阶
利用上面的基础语法基本上可以匹配到html文档任何地方的内容了,下面的语法不常用,截图来自各位大佬的博文。
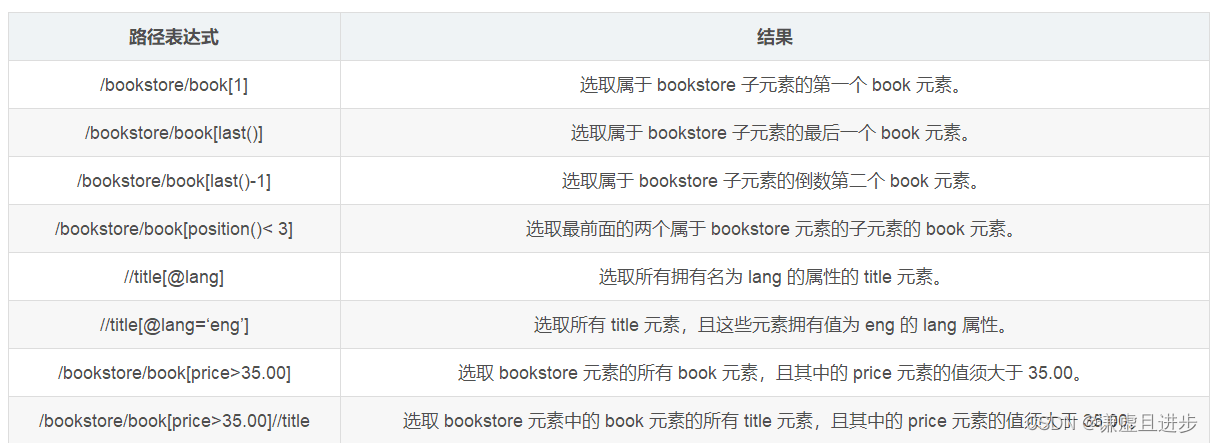
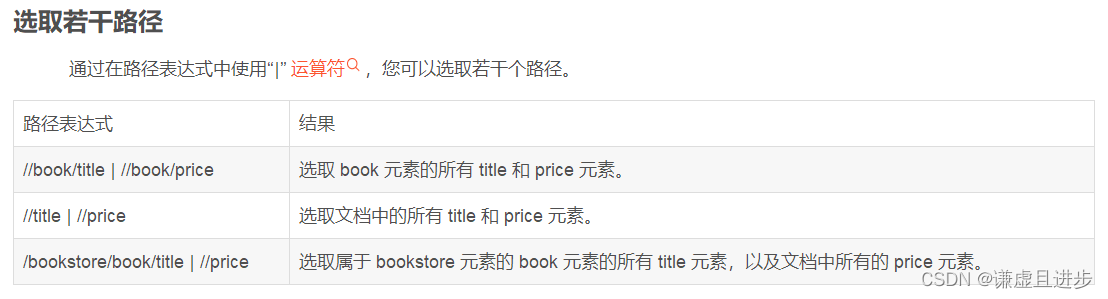
3.2.1 谓语
3.2.2 运算符
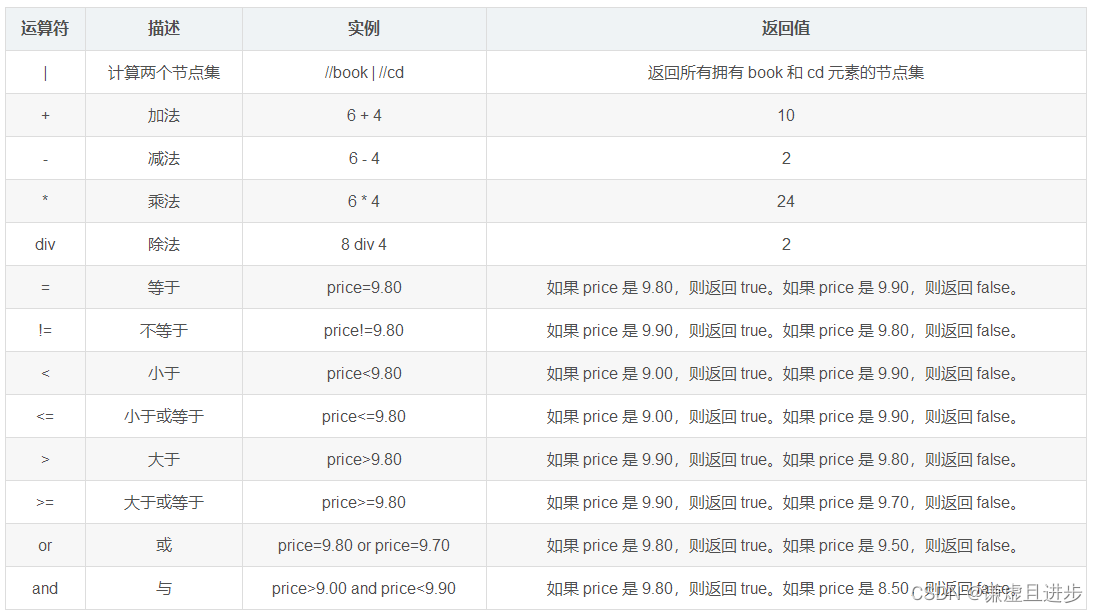
3.3.3 函数
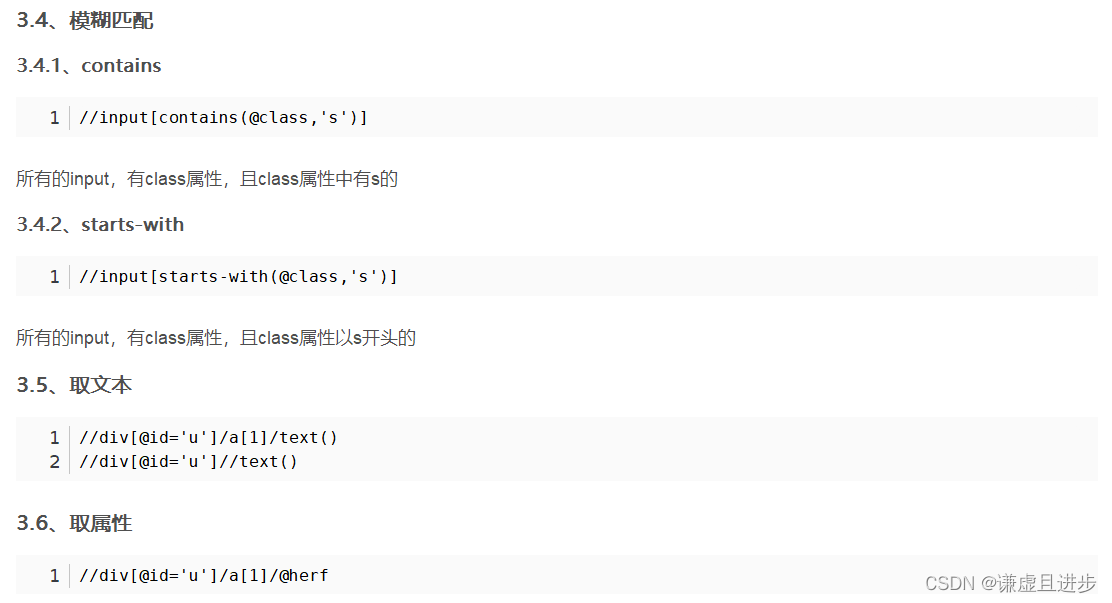
3.3.4 Xpath的轴及其实例
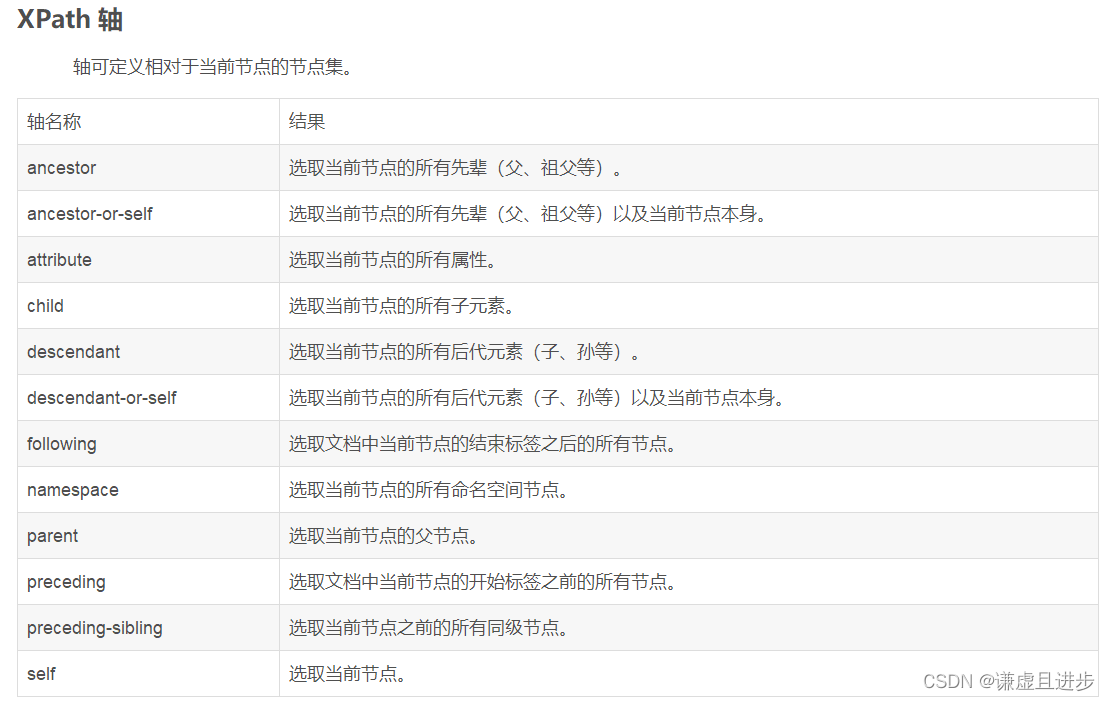
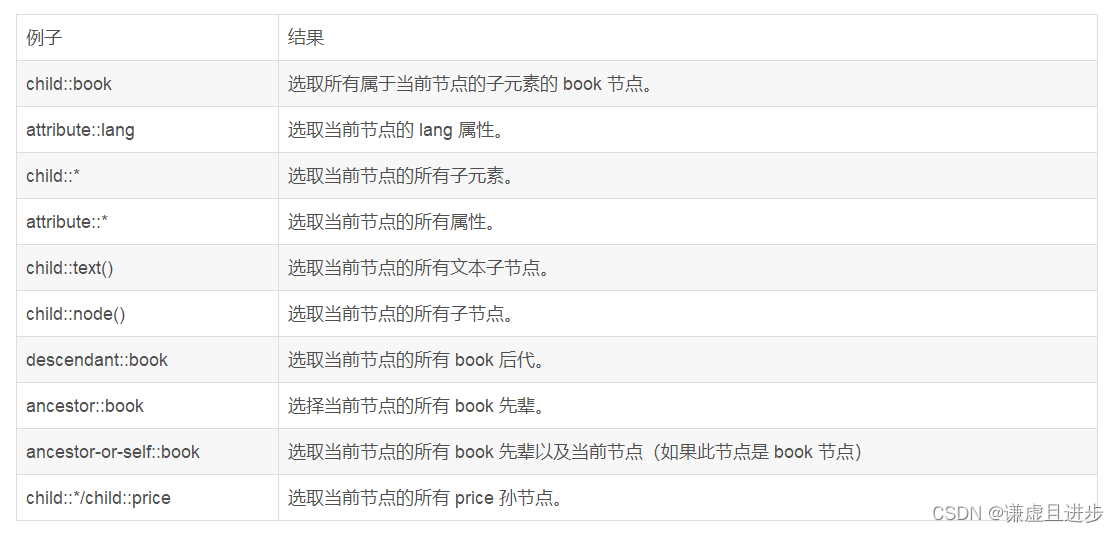
四,xpath实例实战
4.1 给定例子写路径
文档字符串:
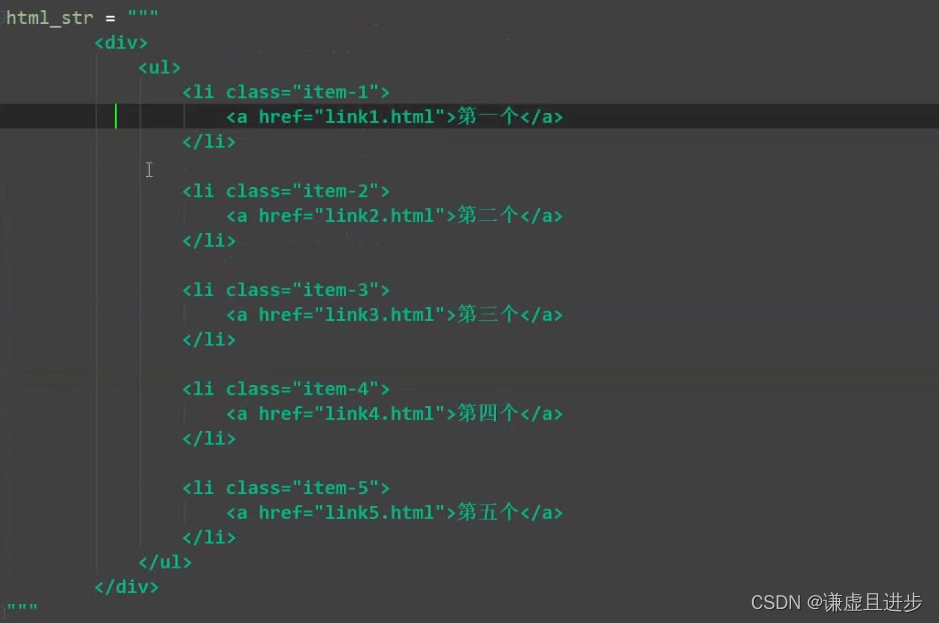
实战:extract()返回一个列表,列表内容为匹配得到的元素节点。

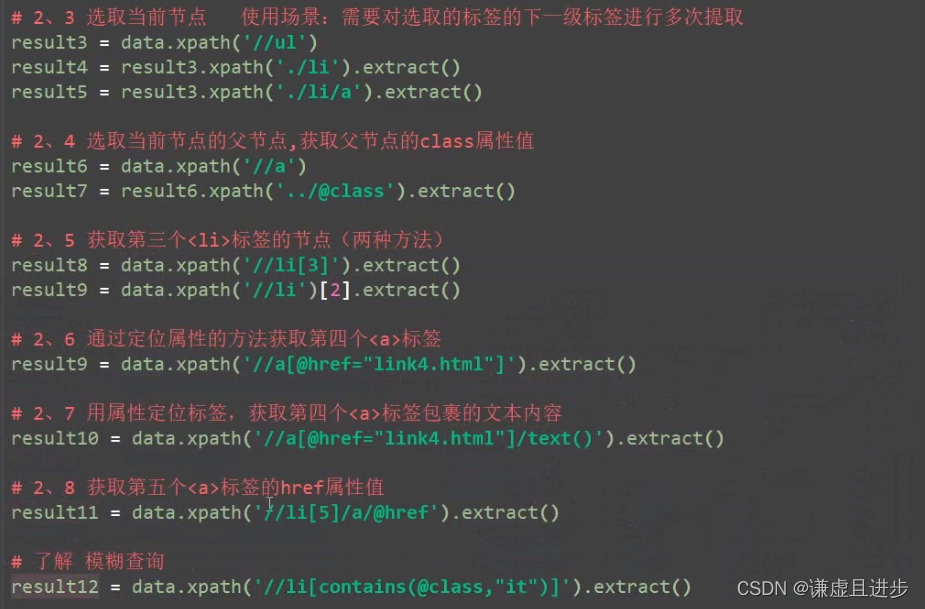
4.2 给定代码说出代码功能
#coding=utf-8
from lxml import etree
html = '''
<html>
<head>
<meta name="content-type" content="text/html; charset=utf-8" />
<title>友情链接查询 - 站长工具</title>
<!-- uRj0Ak8VLEPhjWhg3m9z4EjXJwc -->
<meta name="Keywords" content="友情链接查询" />
<meta name="Description" content="友情链接查询" />
</head>
<body>
<h1 class="heading">Top News</h1>
<p style="font-size: 200%">World News only on this page</p>
Ah, and here's some more text, by the way.
<p>... and this is a parsed fragment ...</p>
<a href="http://www.cydf.org.cn/" rel="nofollow" target="_blank">青少年发展基金会</a>
<a href="http://www.4399.com/flash/32979.htm" target="_blank">洛克王国</a>
<a href="http://www.4399.com/flash/35538.htm" target="_blank">奥拉星</a>
<a href="http://game.3533.com/game/" target="_blank">手机游戏</a>
<a href="http://game.3533.com/tupian/" target="_blank">手机壁纸</a>
<a href="http://www.4399.com/" target="_blank">4399小游戏</a>
<a href="http://www.91wan.com/" target="_blank">91wan游戏</a>
</body>
</html>
'''
# 下面代码的功能是什么?
page = etree.HTML(html.lower().decode('utf-8'))
hrefs = page.xpath(u"//a")
for href in hrefs:
print href.attrib五,Xpath Helper插件的安装
打开每个浏览器的应用程序拓展商店,搜索Xpath Helper安装之后,重启浏览器即可。这个插件的主要作用就是验证我们构思的xpath路径是否正确及是否能够匹配到内容。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)