Vivado HLS实现卷积和池化操作
Vivado HLS实现卷积和池化操作
卷积与池化是卷积神经网络(CNN)中两个最重要的操作,本文主要讲述如何在Vivdao HLS中利用C++实现卷积和池化。
一、什么是卷积操作
对于卷积神经网络,卷积的主要目的是提取输入图像的特征。卷积操作(Convolution)其实并不复杂,它就是卷积核(Filter)在图片(Image)上从左到右、从上到下进行滑动得到特征图(Convolved Feature)的过程。假设现在有一个单通道的原始图片和一个卷积核(图1),卷积过程如图2所示。
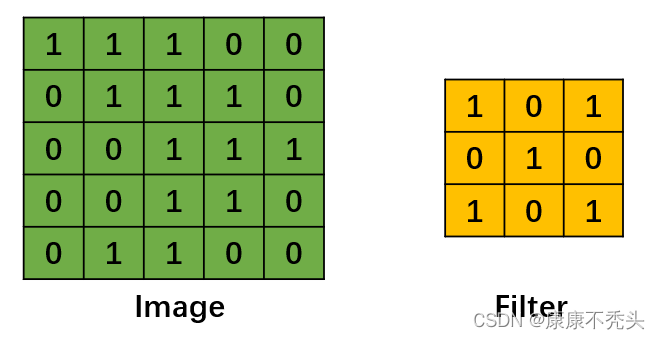

图1 图2
卷积核的通道个数核被卷积图片的通道数相同。当输入的是一个单通道的灰度图时,卷积核的通道个数是一个。当输入的是一个RGB三通道的彩色图片时,卷积核的通道个数是三个。不同的卷积核对应着不同的效果,比如说边缘检测、平滑滤波、锐化模糊等。

图3
一张原始图片可能会得到多个特征图,这取决于卷积核的个数。如图4所示,这里有四个卷积核,得到的特征图也是四个。
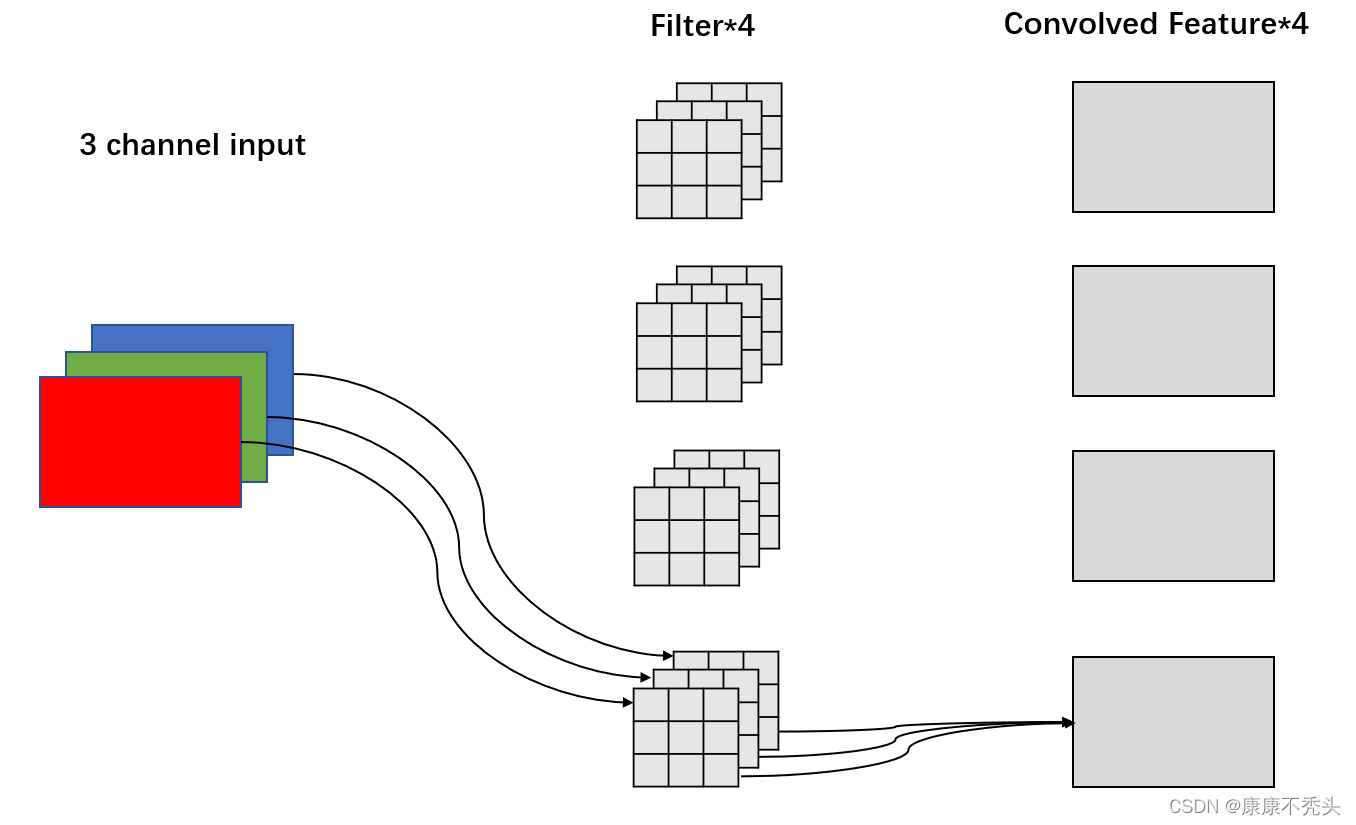
图4
卷积窗口从输入图像的最左上方开始,按从左往右、从上往下的顺序,依次在输入图像上滑动,每次滑动步长被称为stride,程序中Sx和Sy分别代表x轴(从左往右)和y轴方向(从上往下)的步长。
卷积操作存在着两个缺点:1.在卷积运算之后,输出的图像会缩小,不利于后续的卷积操作;2.图像边缘信息参与卷积的次数少,发挥的作用小。为了解决上述的问题,可以在卷积操作之前去填充图像,填充像素的多少,往往有两个选择,分别是Valid卷积和Same卷积。
Valid卷积(no padding):
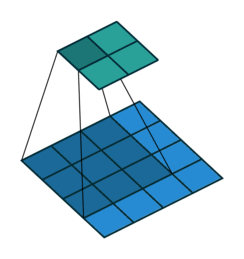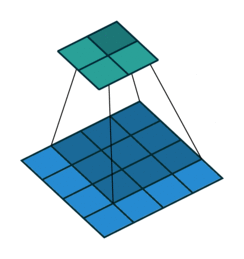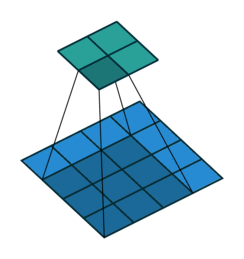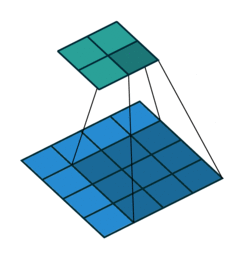
顾名思义就是卷积核只在有效(Valid)区域卷积,填充像素padding=0。output_size=
(input_size-kernel_size)/stride+1;当stride=1,output_size=input_size-kernel_size+1。
Same卷积:
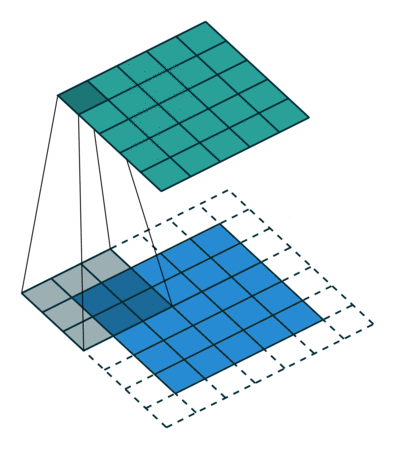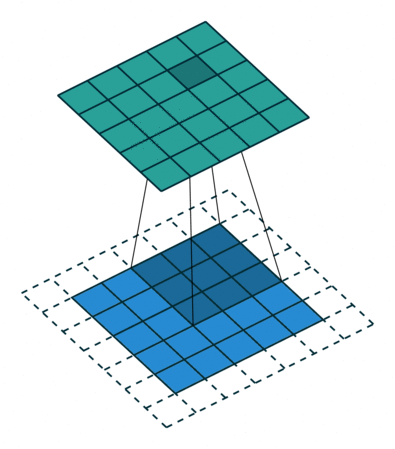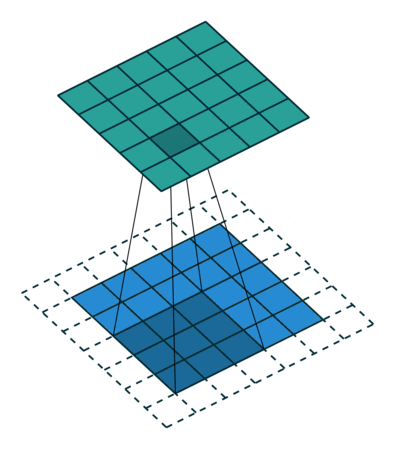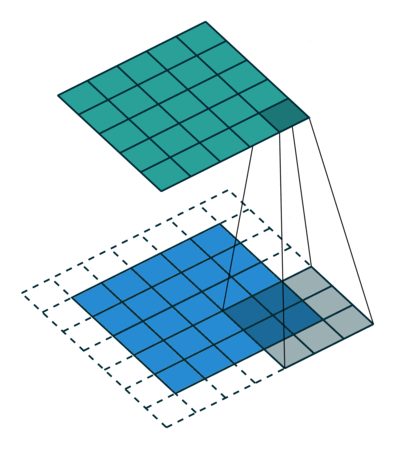
输出图像的尺寸等于输入图像的尺寸,填充padding=input_size*(stride-1)+kernel_size-stride。当stride=1,padding=kernel_size-1。
二、什么是池化操作
池化Pooling是卷积神经网络中常见的一种操作,其本质是降维,在卷积层之后,通过池化来降低卷积层输出的特征维度,减少网络参数和计算成本的同时,降低过拟合。
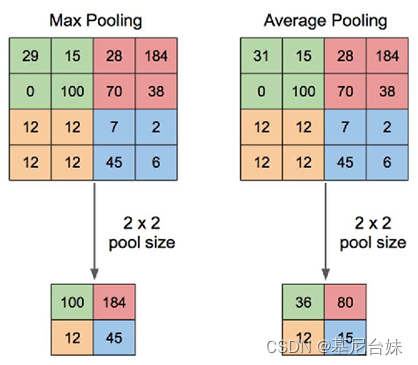
池化分为三种,分别为最大池化、最小池化和平均池化。
最大池化(Max Pooling)是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。即,取子区域中值最大的点;最小池化(Min Pooling)就是取子区域中的最小值。同理,平均池化(Average Pooling)为取子区域值的平均值。
三、HLS实现卷积操作
这里重要的是HLS接口的配置,卷积运算函数需要的参数如CHin、Hin、Win使用的s_axilite接口,说明这些参数都是可以使用axi总线进行配置的,而卷积运算所用的数据由于在存储空间中既要被读出,之后也要被写入,所以配置的m_axi接口;将整个函数配置为s_axilite接口,这样CPU可以通过axi总线控制函数的运行。
//mode: 0:VALID, 1:SAME
//pad填充 可以选择vaild or same(不填充和保持原来图像的相同大小)mode == 0 or 1
//生成的图像大小与图像原本边长n,卷积核边长f和步长s决定,O = (n-f)/s+1
//在s=1,的情况下,pad选择same时,需要两边各填充(f-1)/2
//当s=1,且pad=same的时候,此时Wout = Win
//当pad=valid的时候,此时Wout = (Win - Kx)/Sx+1
//Win、Hin:输入图像的长宽
//Kx、Ky:输入卷积核的长宽
//Sx,Sy:x轴和y轴方向的步长
//CHin、CHout:输入输出图像层数
void Conv(ap_uint<16> CHin,ap_uint<16> Hin,ap_uint<16> Win,ap_uint<16> CHout,
ap_uint<8> Kx,ap_uint<8> Ky,ap_uint<8> Sx,ap_uint<8> Sy,ap_uint<1> mode,ap_uint<1> relu_en,
float feature_in[],float W[],float bias[],float feature_out[]
){
#pragma HLS INTERFACE m_axi depth=4294967295 port=feature_out offset=slave
#pragma HLS INTERFACE m_axi depth=4294967295 port=bias offset=slave
#pragma HLS INTERFACE m_axi depth=4294967295 port=W offset=slave
#pragma HLS INTERFACE m_axi depth=4294967295 port=feature_in offset=slave
#pragma HLS INTERFACE s_axilite port=return
#pragma HLS INTERFACE s_axilite port=mode
#pragma HLS INTERFACE s_axilite port=relu_en
#pragma HLS INTERFACE s_axilite port=Sy
#pragma HLS INTERFACE s_axilite port=Sx
#pragma HLS INTERFACE s_axilite port=Ky
#pragma HLS INTERFACE s_axilite port=Kx
#pragma HLS INTERFACE s_axilite port=CHout
#pragma HLS INTERFACE s_axilite port=Win
#pragma HLS INTERFACE s_axilite port=Hin
#pragma HLS INTERFACE s_axilite port=CHin
ap_uint<8> pad_x,pad_y;
if(mode==0){
pad_x=0;
pad_y=0;
}else{
pad_x = (Kx-1)/2;
pad_y = (Ky-1)/2;
}
ap_uint<16> Hout,Wout;
Wout=(Win+2*pad_x-Kx)/Sx+1;
Hout=(Hin+2*pad_y-Ky)/Sy+1;
//输入Feature_in [H][W][C] 高 宽 通道数
//卷积核kernel [Ky,Kx,CHin,CHout]
for(int cout=0;cout<CHout;cout++)
for(int i=0;i<Hout;i++)
for(int j=0;j<Wout;j++){
Dtype_acc sum=0;
//ii、jj:卷积的乘操作相对于卷积核的位置
for(int ii=0;ii<Ky;ii++)
for(int jj=0;jj<Kx;jj++)
{
//发生卷积乘操作位于输入图像的位置
ap_uint<16> h=i*Sy-pad_y+ii;
ap_uint<16> w=j*Sy-pad_x+jj;
//判断这个位置是填充区域还是输入图像区域
if(h>=0 && w>=0 && h<Hin && w<Win){
for(int cin=0;cin<CHin;cin++){
//tp = feature_in[h][w][cin]*w[ii][jj][cin][cout];
//在存放的时候,不同层的相同位置顺序相连
Dtype_mul tp = feature_in[h*Win*CHin+w*CHin+cin]*W[ii*CHin*Kx*CHout+jj*CHin*CHout+cin*CHout+cout];
sum+=tp;
}
}
}
sum+=bias[cout];
if(relu_en && sum<0)
sum=0;
feature_out[i*Wout*CHout+j*CHout+cout]=sum;
}
}
由于卷积层后面一般都跟着激活函数,这里默认使用relu激活函数,小于0的数默认置零。
四、HLS实现池化操作
池化操作的输入是需要池化的图片,输出是池化后的图片。这里mode为池化操作的类型,0为平均池化,1为最小池化,2为最大池化;池化操作被划分子区域的长和宽分别用Kx和Ky表示;Win、Hin和CHin分别表示输入图片的长、宽和通道数。
#define max(a,b) ((a>b)? a:b)
#define min(a,b) ((a>b)? b:a)
//mode: 0:MEAN, 1:MIN, 2:MAX
void Pool(ap_uint<16> CHin,ap_uint<16> Hin,ap_uint<16> Win,
ap_uint<8> Kx,ap_uint<8> Ky,ap_uint<2> mode,
float feature_in[],float feature_out[]){
#pragma HLS INTERFACE s_axilite port=return
#pragma HLS INTERFACE m_axi depth=4294967295 port=feature_out offset=slave
#pragma HLS INTERFACE m_axi depth=4294967295 port=feature_in offset=slave
#pragma HLS INTERFACE s_axilite port=mode
#pragma HLS INTERFACE s_axilite port=Ky
#pragma HLS INTERFACE s_axilite port=Kx
#pragma HLS INTERFACE s_axilite port=Win
#pragma HLS INTERFACE s_axilite port=Hin
#pragma HLS INTERFACE s_axilite port=CHin
ap_uint<16> Hout,Wout;
Wout = Win/Kx;
Hout = Hin/Ky;
for(int c=0;c<CHin;c++)
for(int i=0;i<Hout;i++)
for(int j=0;j<Wout;j++){
Dtype_f sum;
if(mode==0)
sum=0;
else if(mode==1)
sum=9999999999999999;
else
sum=-9999999999999999;
for(int ii=0;ii<Ky;ii++)
for(int jj=0;jj<Kx;jj++){
ap_int<16> h=i*Ky+ii;
ap_int<16> w=j*Kx+jj;
switch(mode){
case 0: {sum+=feature_in[h*Win*CHin+w*CHin+c];break;}
case 1: {sum=min(sum,feature_in[h*Win*CHin+w*CHin+c]);break;}
case 2: {sum=max(sum,feature_in[h*Win*CHin+w*CHin+c]);break;}
default:break;
}
}
if(mode==0)
sum=sum/(Kx*Ky);
feature_out[i*Wout*CHin+j*CHin+c]=sum;
}
}
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)