编译原理——实验1 词法分析程序设计
编译原理词法分析器实验。#include <iostream>#include <cstring>using namespace std;char prog[800];//存储程序char token[10];//存储单词字符串char ch;//当前字符int syn;//单词种别码int sum;//整型常数int p;/...
实验1 词法分析程序设计
【实验要求】
1、待分析的简单语言的词法
1) 关键字
begin if then while do end
2) 运算符和界符
:= + - * / < <= > >= <> = ; ( ) #
3) 其他单词是标识符(ID)和整形常数(NUM),通过以下正规式定义:
ID=letter(letter|digit)*
NUM=digitdigit*
4) 空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
2、各种单词符号对应的种别编码
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<> |
21 |
|
do |
5 |
<= |
22 |
|
end |
6 |
> |
23 |
|
letter(letter|digit)* |
10 |
>= |
24 |
|
digitdigit* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
3、词法分析程序的功能
输入:所给文法的源程序字符串
输出:二元组(syn,token或sum)构成的序列。
syn为单词种别码;
token为存放的单词自身字符串;
sum为整形常数。
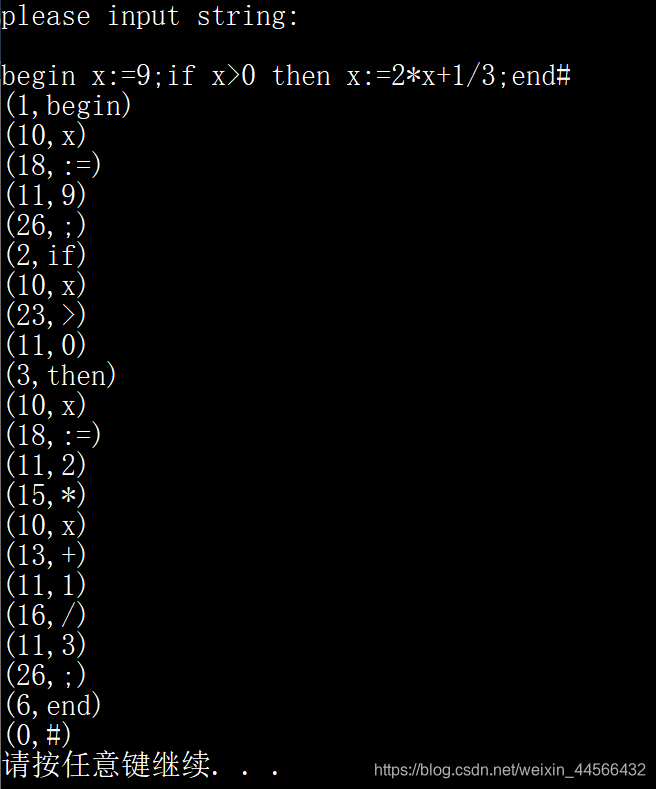
例如:对源程序begin x:=9;if x>0 then x:=2*x+1/3;end# 经词法分析后输出如下序列:
(1,begin)(10,’x’) (18,:=) (11,9) (26,;) (2,if)……
#include <iostream>
#include <cstring>
using namespace std;
char prog[800]; //存储程序
char token[10]; //存储单词字符串
char ch; //当前字符
int syn; //单词种别码
int sum; //整型常数
int p; //prog指针
int m; //token指针
int n;
//关键字
const char * rwtab[6] = {"begin", "if", "then", "while", "do", "end"};
bool isLetter(char ch); //判断是否为字母
bool isDigit(char ch); //判断是否为数字
void scanner(); //扫描分析器
bool isLetter(char ch){
if ((ch <= 'z' && ch >='a') || (ch <'Z' && ch >= 'A')){
return true;
}
else{
return false;
}
}
bool isDigit(char ch){
if(ch >= '0' && ch <= '9'){
return true;
}
else{
return false;
}
}
void scanner(){
//清空token
for (n = 0 ; n < 8; n++){
token[n] = NULL;
}
m = 0;
//获取下一个有效字符
ch = prog[p];
while(ch == ' '){
p++;
ch = prog[p];
}
if(isDigit(ch)){
//字符为数字
sum = 0;
while (isDigit(ch)){
sum = sum * 10 + ch - '0'; //str转换为数值类型
p++;
ch = prog[p];
syn = 11;
}
}
//字符为字符串
else if(isLetter(ch)){
while(isDigit(ch) || isLetter(ch)){
token[m] = ch;
m++;
p++;
ch = prog[p];
}
token[m] = '\0';
m++;
syn = 10;
for(n = 0; n < 6; n++){
if(strcmp(token, rwtab[n]) == 0){
syn = n + 1;
break;
}
}
}
else{
switch (ch){
case '<':
syn = 20;
m = 0;
token[m] = ch;
m++;
p++;
ch = prog[p];
if (ch == '>') {
syn = 21;
token[m] = ch;
m++;
p++;
ch = prog[p];
}
else if (ch == '=') {
syn = 22;
token[m++] = ch;
m++;
p++;
ch = prog[p];
}
break;
case '>':
syn = 23;
m = 0;
token[m++] = ch;
p++;
ch = prog[p];
if (ch == '=') {
syn = 24;
token[m] = ch;
m++;
p++;
ch = prog[p];
}
break;
case ':':
syn = 17;
m = 0;
token[m] = ch;
m++;
p++;
ch = prog[p];
if (ch == '=') {
syn = 18;
token[m] = ch;
m++;
p++;
ch = prog[p];
}
break;
case '+':
syn = 13;
token[0] = ch;
p++;
ch = prog[p];
break;
case '-':
syn = 14;
token[0] = ch;
p++;
ch = prog[p];
break;
case '*':
syn = 15;
token[0] = ch;
p++;
ch = prog[p];
break;
case '/':
syn = 16;
token[0] = ch;
p++;
ch = prog[p];
break;
case '=':
syn = 25;
token[0] = ch;
p++;
ch = prog[p];
break;
case ';':
syn = 26;
token[0] = ch;
p++;
ch = prog[p];
break;
case '(':
syn = 27;
token[0] = ch;
p++;
ch = prog[p];
break;
case ')':
syn = 28;
token[0] = ch;
p++;
ch = prog[p];
break;
case '#':
syn = 0;
token[0] = ch;
break;
default:
syn = -1;
break;
}
}
}
int main(int argc, char** argv) {
cout << "please input string: \n" << endl;
p = 0;
char str;
//获取程序
do{
str = getchar();
prog[p] = str;
p++;
}while(str != '#');
p = 0;
ch = prog[p];
//开始分析
do{
scanner();
switch(syn){
case 11:
cout << "(" << syn << "," << sum << ")" << endl;
break;
case -1:
cout << "error" << endl;
break;
default:
cout << "("<< syn << "," << token << ")" <<endl;
}
}while(syn != 0);
system("pause");
return 0;
}
气人的编译器!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)