详解+推导 神经网络中的前向传播和反向传播公式(神经网络中的梯度下降)
文章目录线性回归快速回忆逻辑回归中的正向传播与反向传播逻辑回归中的正向传播与反向传播-代码实战神经网络的正向传播与反向传播线性回归快速回忆在线性回归(y=ax+by=ax+by=ax+b)中,使用梯度下降时的公式为:a=a−ηdJdaa = a-\eta \frac{dJ}{da}a=a−ηdadJ通过求出代价函数 JJJ 对参数 aaa 的导数,来更新 aaa ,不断重复该过程,直到某次a值的
线性回归快速回忆
在线性回归( y = a x + b y=ax+b y=ax+b)中,使用梯度下降时的公式为:
a = a − η d J d a a = a-\eta \frac{dJ}{da} a=a−ηdadJ
通过求出代价函数 J J J 对参数 a a a 的导数,来更新 a a a ,不断重复该过程,直到某次a值的变化趋于0,即认为已经找到了最佳的 a a a
逻辑回归中的正向传播与反向传播
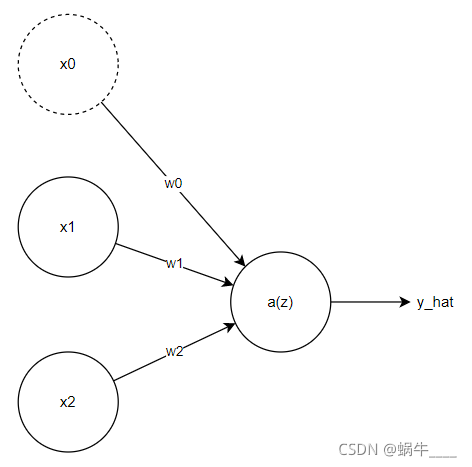
这里将逻辑回归看成一个:有两个输入,没有隐藏层的简单神经网络。
其中:
z = w 0 + w 1 x 1 + w 2 x 2 y ^ = a = σ ( z ) L ( a , y ) = − ( y log ( a ) + ( 1 − y ) log ( 1 − a ) ) \begin{aligned} & z = w_0 + w_1 x_1 + w_2 x_2 \\\\ & \hat{y}=a=\sigma(z) \\\\ & \mathcal{L}(a, y)=-(y \log (a)+(1-y) \log (1-a)) \end{aligned} z=w0+w1x1+w2x2y^=a=σ(z)L(a,y)=−(ylog(a)+(1−y)log(1−a))
使用sigmoid σ \sigma σ 作为激活函数, L \mathcal{L} L 为损失函数
正向传播就是输出 x 1 , x 2 x_1,x_2 x1,x2 ,通过上述公式计算出 y ^ \hat{y} y^
反向传播就是通过得到的 y ^ \hat{y} y^,利用上述公式,推导出 d L d w 1 \frac{d\mathcal{L}}{dw_1} dw1dL 和 d L d w 2 \frac{d\mathcal{L}}{dw_2} dw2dL(假设只取一样本)
正向传播很简单,只需要代入算即可。
反向传播只需要使用微积分中的链式法则即可,即:
d L d w 1 = d L d a d a d z d z d w 1 \frac{d\mathcal{L}}{dw_1} = \frac{d\mathcal{L}}{da} \frac{da}{dz} \frac{dz}{dw_1} dw1dL=dadLdzdadw1dz
其中:
d L d a = − y a + 1 − y 1 − a d a d z = a ( 1 − a ) d z d w 1 = x 1 \begin{aligned} & \frac{d\mathcal{L}}{da} = -\frac{y}{a} + \frac{1-y}{1-a}\\\\ & \frac{da}{dz} = a(1-a) \\\\ & \frac{dz}{dw_1} = x_1 \end{aligned} dadL=−ay+1−a1−ydzda=a(1−a)dw1dz=x1
将上式代入原式,得:
d L d w 1 = ( a − y ) x 1 = ( y ^ − y ) x 1 \frac{d\mathcal{L}}{dw_1} = (a - y)x_1 = (\hat{y} - y)x_1 dw1dL=(a−y)x1=(y^−y)x1
到这里,我们计算出了 d L d w 1 \frac{d\mathcal{L}}{dw_1} dw1dL ,这样就可以利用梯度下降求解最佳的 w 1 w_1 w1,即:
w 1 = w 1 − η d L d w 1 w_1 = w_1 - \eta \frac{d\mathcal{L}}{dw_1} w1=w1−ηdw1dL
w 0 和 w 2 w_0 和w_2 w0和w2 同理
逻辑回归中的正向传播与反向传播-代码实战
有了上面的理论基础,就可以轻松进行实现:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import math
import random
iris = datasets.load_iris() # 去iris数据集
X = iris.data
y = iris.target
X = X[y<2, :2] # 只要0、1的,且只取两个特征
y = y[y<2]
plt.scatter(X[y==0, 0],X[y==0, 1])
plt.scatter(X[y==1, 0],X[y==1, 1])
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QmzzQh81-1635311578992)(output_2_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/b1f46a840573489ccdf490461ebbed5a.png)
def z(x1, x2, w0, w1, w2):
return w0 + w1*x1 + w2*x2
def y_hat(z):
return 1 / (1 + math.exp(-z))
def dw1(y_hat, y, x1):
return (y_hat-y) * x1
def dw2(y_hat, y, x2):
return (y_hat-y) * x2
def dw0(y_hat, y):
return y_hat - y
# 初始化权重
w0, w1, w2 = random.random(), random.random(), random.random()
eta = 0.01 # 学习率
for _ in range(1000): # 进行1000次学习
for i, x in enumerate(X):
x1 = x[0]
x2 = x[1]
y_predict = y_hat(z(x1, x2, w0, w1, w2))
w1 = w1 - eta * dw1(y_predict, y[i], x1)
w2 = w2 - eta * dw2(y_predict, y[i], x2)
w0 = w0 - eta * dw0(y_predict, y[i])
x1_plot = np.arange(4, 7, 0.1) # 将直线绘制出来
x2_plot = (w0 + w1*x1_plot)/(-w2)
plt.scatter(X[y==0, 0],X[y==0, 1])
plt.scatter(X[y==1, 0],X[y==1, 1])
plt.plot(x1_plot, x2_plot)
plt.xlabel("x1")
plt.ylabel("x2")
plt.show()
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wmMH5SJL-1635311578995)(output_11_0.png)]](https://i-blog.csdnimg.cn/blog_migrate/6f7562e02d512483403777362ea11c39.png)
神经网络的正向传播与反向传播
有了上面的基础,我们就可以推导神经网络的正向传播和反向传播的公式了。
这里使用西瓜书的相关符号。
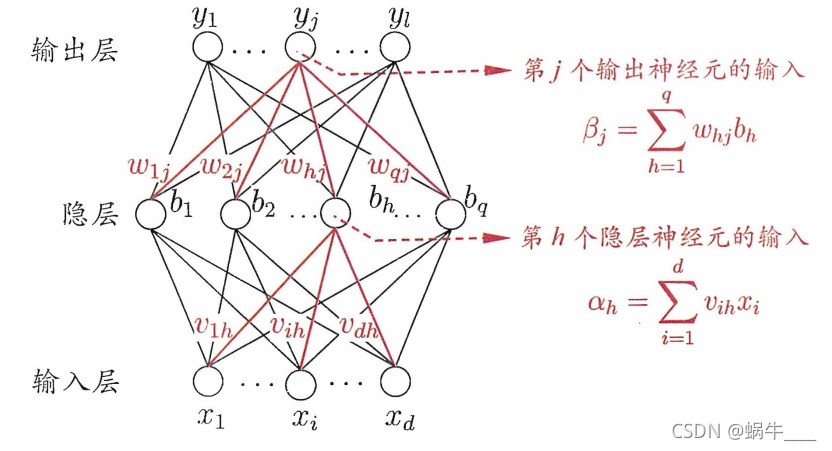
这里,我们有一个神经网络, d d d 个输入, l l l 个输出,单个隐层,隐层有 q q q 个神经元。 v i h v_{ih} vih表示 x i x_i xi与 b h b_h bh之间的权重, w h j w_{hj} whj 表示 b h b_h bh 与 y j y_j yj 之间的权重。
激活函数使用 sigmoid,记作 f f f
对于训练集 ( x k , y k ) (x_k, y_k) (xk,yk), 利用正向传播,我们可以得到第j个输出 y ^ j k \hat{y}^k_j y^jk 得值,公式为:
y ^ j k = f ( β j − θ j ) ( 1 ) \hat{y}^k_j = f(\beta_j - \theta_j) ~~~~~~~~~~~~~~~(1) y^jk=f(βj−θj) (1)
(1) 公式的解释:
β j \beta_j βj 为所有隐层“ b 1 , ⋯ , b q b_1, \cdots , b_q b1,⋯,bq” 与 输出层 y j y_j yj 的乘积,即:
β j = w 1 j b 1 + w 2 j b 2 + ⋯ + w q j b q = ∑ h = 1 q w h j b h \beta_j = w_{1_j} b_1 + w_{2_j} b_2 + \cdots + w_{q_j} b_q = \sum_{h=1}^{q} w_{h j} b_{h} βj=w1jb1+w2jb2+⋯+wqjbq=h=1∑qwhjbh
相当于上一章的 z = w 0 + w 1 x 1 + w 2 x 2 z = w_0 + w_1 x_1 + w_2 x_2 z=w0+w1x1+w2x2
此时可以发现 β j \beta_j βj 少了一个偏移量 w 0 w_0 w0,在西瓜书中,使用 θ j \theta_j θj 表示了这个偏移量。所以才会有 β j − θ j \beta_j - \theta_j βj−θj。
将其代入 sigmoid 函数,就可以得到 y ^ j k \hat{y}^k_j y^jk 的值:
y ^ j k = f ( β j − θ j ) \hat{y}^k_j = f(\beta_j - \theta_j) y^jk=f(βj−θj)
y ^ j k \hat{y}^k_j y^jk 的公式中为什么不包含输入 x x x ? 其实输入变量 x 包含在 隐层中,即隐层的 b j b_j bj 是通过所有 x x x 和 w w w 算出来的
拿到了 y ^ j k \hat{y}^k_j y^jk ,就可以定义代价函数了,这里使用均方误差来得出代价函数:
E k = 1 2 ∑ j = 1 l ( y ^ j k − y j k ) 2 E_{k}=\frac{1}{2} \sum_{j=1}^{l}\left(\hat{y}_{j}^{k}-y_{j}^{k}\right)^{2} Ek=21j=1∑l(y^jk−yjk)2
有了代价函数 E k E_k Ek,那只要求出来 ∂ E k ∂ w h j \frac{\partial E_{k}}{\partial w_{h j}} ∂whj∂Ek,那就可以利用梯度下降更新 w h j w_{hj} whj了,即
w h j = w h j − η ∂ E k ∂ w h j w_{hj} = w_{hj} - \eta \frac{\partial E_{k}}{\partial w_{h j}} whj=whj−η∂whj∂Ek
与上节一样,利用链式法则求 ∂ E k ∂ w h j \frac{\partial E_{k}}{\partial w_{h j}} ∂whj∂Ek, 即:
∂ E k ∂ w h j = ∂ E k ∂ y ^ j k ⋅ ∂ y ^ j k ∂ β j ⋅ ∂ β j ∂ w h j \frac{\partial E_{k}}{\partial w_{h j}}=\frac{\partial E_{k}}{\partial \hat{y}_{j}^{k}} \cdot \frac{\partial \hat{y}_{j}^{k}}{\partial \beta_{j}} \cdot \frac{\partial \beta_{j}}{\partial w_{h j}} ∂whj∂Ek=∂y^jk∂Ek⋅∂βj∂y^jk⋅∂whj∂βj
到这如果可以看懂,基本就算成功了。通过简单计算可以得出:
∂ β j ∂ w h j = b h ∂ y ^ j k ∂ β j = y ^ j k ( 1 − y ^ j k ) ∂ E k ∂ y ^ j k = y ^ j k − y j k \begin{aligned} & \frac{\partial \beta_{j}}{\partial w_{h j}}=b_{h} \\\\ & \frac{\partial \hat{y}_{j}^{k}}{\partial \beta_{j}} = \hat{y}^k_j (1-\hat{y}^k_j) \\\\ & \frac{\partial E_{k}}{\partial \hat{y}_{j}^{k}} = \hat{y}_{j}^{k}-y_{j}^{k} \end{aligned} ∂whj∂βj=bh∂βj∂y^jk=y^jk(1−y^jk)∂y^jk∂Ek=y^jk−yjk
将其代入原始就可以得到 w h j w_{hj} whj 的梯度下降公式,即:
w h j = w h j − η ∂ E k ∂ w h j = w h j − η ( y ^ j k − y j k ) y ^ j k ( 1 − y ^ j k ) b h w_{hj} = w_{hj} - \eta \frac{\partial E_{k}}{\partial w_{h j}} = w_{hj} - \eta (\hat{y}_{j}^{k}-y_{j}^{k})\hat{y}^k_j (1-\hat{y}^k_j)b_{h} whj=whj−η∂whj∂Ek=whj−η(y^jk−yjk)y^jk(1−y^jk)bh
同理,也可以得出 v h j v_{hj} vhj 和 θ j \theta_j θj 的梯度下降公式。
参考资料
考研必备数学公式大全: https://blog.csdn.net/zhaohongfei_358/article/details/106039576
机器学习纸上谈兵之线性回归: https://blog.csdn.net/zhaohongfei_358/article/details/117967229
Sigmoid函数求导过程: https://blog.csdn.net/zhaohongfei_358/article/details/119274445
周志华西瓜书
吴恩达深度学习

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)