聚类算法之k均值聚类(K-Means)
它的基本思想是,随着聚类数的增加,聚类结果的惯性会逐渐减小,但减小的速度会逐渐变缓。因此,在使用 KMeans 算法进行聚类时,通常会尝试不同的聚类数,并选择惯性最小的聚类结果作为最终的聚类结果。其基本思想是基于数据的内部结构和特点,对其进行组织和分类,使得相同组内的数据点之间的相似性尽量大,而不同组之间的数据点的差异性尽量显著。最终,你会得到K个配送站的最佳位置,以及相应的服务区域。从图中可以观
注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
引言
聚类,作为一种核心的无监督学习技术,长久以来在数据挖掘、机器学习、统计分析和其他多个领域中占据了重要的地位。其基本思想是基于数据的内部结构和特点,对其进行组织和分类,使得相同组内的数据点之间的相似性尽量大,而不同组之间的数据点的差异性尽量显著。
聚类的应用十分广泛,从市场细分、社交网络分析,到生物信息学、图像识别等领域,都有其身影。例如,在商业领域,根据消费者的购买记录和行为模式进行聚类,可以帮助企业发现不同的市场细分,进而制定更有针对性的营销策略。
本文将介绍四种主流的聚类算法:K均值、层次聚类、DBSCAN和高斯混合模型。每种算法都有其特点,适用于不同的数据类型和场景。
K均值聚类 (K-Means)
K均值聚类是机器学习中最受欢迎和最广泛使用的聚类算法之一。它是无监督学习的代表,典型地用于市场细分、图像分割、社交网络分析等。由于其简洁性和效率,K均值已经成为初学者和研究者首选的工具,尤其是当面对大规模数据集时。
1. 算法解读:
K均值聚类的基本思想是:给定数据集中的数据点,算法试图找到K个中心(或称为质心),这些中心能够最好地代表数据。算法的工作方式是迭代的:初始化中心,将每个数据点分配给最近的中心,然后根据分配给它们的数据点来重新计算中心。这个过程一直重复,直到中心点不再显著变化或达到预设的迭代次数。
2. 步骤和细节:
初始化:随机选择数据集中的K个数据点作为初始中心。
分配:对于数据集中的每一个数据点,测量它到每一个中心的距离,并将其分配给最近的中心。
计算新的中心:对于每个聚类,计算其所有数据点的均值,该均值即为新的中心。
迭代:重复步骤2和3,直到中心不再显著变化或达到预定的迭代次数。
结果:最后的K个中心及其各自的聚类为算法的输出。
3. 举例:
让我们使用城市配送站的例子来详细解释K均值聚类算法。
假设你是一家快递公司的经理,公司负责为城市中的居民配送包裹。为了提高配送效率,你决定在城市中设立K个配送站。每个配送站会负责为附近区域的居民提供服务。你希望通过K均值聚类算法来确定这K个配送站的最佳位置。
初始化:
你在地图上随机选择K个点作为配送站的初始位置。这些点可能并不是实际的居民区,但是它们将作为算法的起始点。
分配:
接下来,你会计算城市中每个居民区到这K个初始配送站的距离,并将每个居民区分配给距离最近的配送站。这样,整个城市就被划分成了K个区域,每个区域都有一个配送站负责服务。
计算新的中心:
对于每个划分出来的区域,你会计算区域内所有居民区的地理中心,并将这个中心作为新的配送站位置。这个过程是为了确保配送站位于其服务区域的中心位置,从而最小化配送距离。
迭代:
你会重复“分配”和“计算新的中心”的步骤,直到配送站的位置不再显著变化,或者达到了预设的迭代次数。这个过程是为了不断优化配送站的位置,使得总的配送距离最小。
结果:
最终,你会得到K个配送站的最佳位置,以及相应的服务区域。这些配送站的位置是根据居民区的分布来确定的,以确保每个居民区都能够得到方便快捷的配送服务。
通过这个例子,我们可以看到K均值聚类算法是如何通过迭代优化来确定最佳的分类中心的。在这个应用场景中,算法帮助我们找到了提高配送效率的最佳配送站位置。
Python代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 设置随机种子,以便结果可复现
np.random.seed(0)
# 生成100个居民区的坐标点
X, _ = make_blobs(n_samples=100, centers=5, cluster_std=1.0)
# 设置K均值聚类算法的参数
n_clusters = 5 # 配送站的数量
n_iterations = 5 # 迭代次数
# 初始化图表
fig, ax = plt.subplots(n_iterations, figsize=(6, 10))
# 运行K均值聚类算法并逐步展示结果
for i in range(n_iterations):
# 创建K均值聚类模型
kmeans = KMeans(n_clusters=n_clusters, max_iter=i + 1, n_init=1, init='random', random_state=0)
# 训练模型
kmeans.fit(X)
# 获取居民区的分类标签
labels = kmeans.labels_
# 获取配送站的坐标
centers = kmeans.cluster_centers_
# 绘制居民区和配送站
ax[i].scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis', marker='o', alpha=0.6)
ax[i].scatter(centers[:, 0], centers[:, 1], c='red', s=200, marker='X')
ax[i].set_title(f'Iteration {i + 1}')
# 调整图表布局
plt.tight_layout()
plt.show() 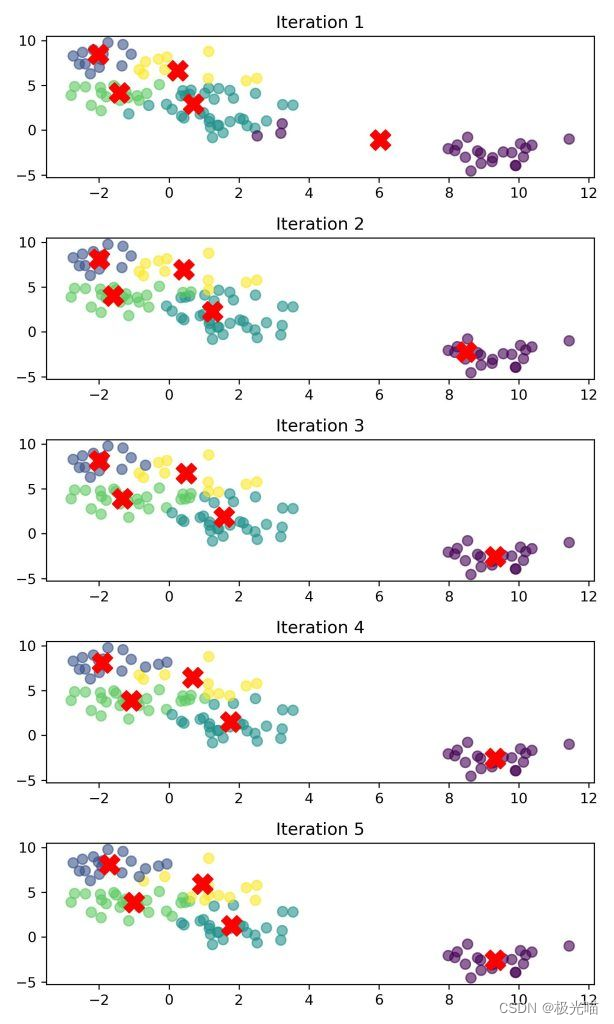
4. 算法评价:
优点:
简单:K均值的算法逻辑清晰,容易实现。
快速:对于大数据集,K均值相对较快,尤其是与其他聚类方法相比。
适用于大数据集:K均值常用于大规模数据集,因为它的计算复杂度相对较低。
缺点:
K值:需要预先指定K值,但在实际应用中,最佳的K值通常是未知的。
初始点敏感:不同的初始化中心可能导致不同的聚类结果。
局部最小值:算法可能会陷入局部最小值,尤其是在选择了不良初始中心时。
肘部法则:
肘部法则是一种常用的聚类分析方法,用于确定最佳聚类数。它的基本思想是,随着聚类数的增加,聚类结果的惯性会逐渐减小,但减小的速度会逐渐变缓。当聚类数增加到一定程度时,惯性的减小速度会急剧变缓,形成一个类似于手肘的拐点。这个拐点所对应的聚类数就是最佳聚类数。因此,肘部法则的目的就是通过绘制肘部曲线来找到这个拐点,以确定最佳聚类数。
聚类结果的惯性是指聚类结果与聚类中心的距离平方和。在 KMeans 算法中,惯性是一个重要的评估指标,用于衡量聚类结果的好坏。聚类结果的惯性越小,说明聚类结果与聚类中心的距离越近,聚类效果越好。因此,在使用 KMeans 算法进行聚类时,通常会尝试不同的聚类数,并选择惯性最小的聚类结果作为最终的聚类结果。
代码如下:
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 生成100个居民区的坐标点
X, _ = make_blobs(n_samples=100, centers=5, cluster_std=1.0)
# 定义K值的范围
k_values = range(1, 11)
# 初始化一个列表来存储每个K值对应的惯性值
inertia_values = []
# 对每个K值运行K均值聚类算法,并记录惯性值
for k in k_values:
kmeans = KMeans(n_clusters=k, random_state=0)
kmeans.fit(X)
inertia_values.append(kmeans.inertia_)
# 绘制肘部曲线
plt.figure(figsize=(8, 6))
plt.plot(k_values, inertia_values, marker='o')
plt.xlabel('Number of Clusters (K)')
plt.ylabel('Inertia')
plt.title('Elbow Method For Optimal k')
plt.grid(True)
plt.show() 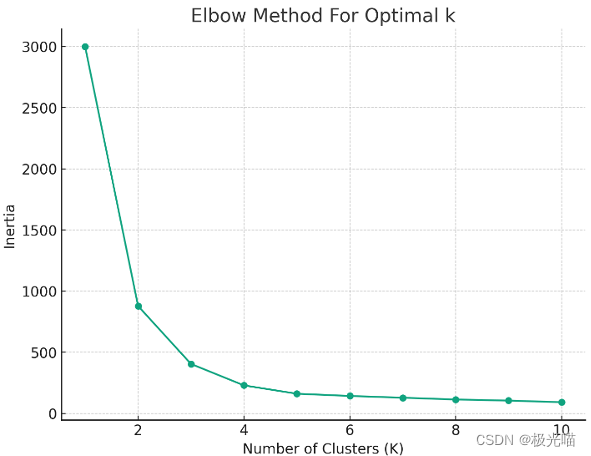
在上图中,横坐标是聚类数 K,纵坐标是对应的惯性值。我们可以看到,随着 K 值的增加,惯性值逐渐减小。我们要找的“肘部”是曲线上的一个拐点,即增加聚类数带来的惯性减小幅度开始变缓的点。
从图中可以观察到,当 K 值在5附近时,曲线的斜率开始变缓,因此,根据肘部法则,5可能是这个数据集的最佳聚类数。
需要注意的是,肘部法则并不总是会给出一个清晰的肘部点,有时可能会有一些主观判断。在实际应用中,可能还需要考虑业务需求、计算资源等因素来确定最终的 K 值。
5. 算法的变体:
Mini Batch K-Means:对于非常大的数据集,使用随机样本进行K均值迭代,大大加快速度。(参考文献:Sculley, D. (2010). Web-scale k-means clustering. In Proceedings of the 19th international conference on World wide web (pp. 1177-1178).)
K-Means++:这是K均值的一种变体,旨在为初始质心选择更好的起始点,以提高算法的收敛速度和准确性。
引用:
Arthur, D., & Vassilvitskii, S. (2007). k-means++: The advantages of careful seeding. In Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms (pp. 1027-1035). Society for Industrial and Applied Mathematics.
K均值聚类因其简单性和有效性而备受推崇。其最大的优势是处理大数据集的能力。但是,与所有方法一样,K均值也有其局限性,尤其是K值的选择和初始质心的敏感性。尽管如此,它仍然是很多实际应用中的首选。对于未来,随着更多的变体和优化方法的出现,K均值将继续保持其在机器学习领域的主导地位。为了更好地使用K均值,我们建议用户充分了解其数据,并考虑使用如K-Means++这样的方法来优化初始质心的选择。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 38
38 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)