聚类分析、matlab\我国各地区普通高等教育发展状况分析、Q型、R型聚类
聚类分析、matlab\我国各地区普通高等教育发展状况分析、Q型、R型聚类、谱系聚类、肘部法则
- 聚类分析又称为群分析,是对多个样本(或指标)进行定量分类的一种多元统计分析方法。对样本进行分类称为Q型聚类分析,对指标进行分类称为R型聚类分析。
- 本文讲解层次聚类(谱系聚类)
Q型聚类分析
样本的相似性度量
- 闵氏(Minkowski)距离
dq(x,y)=[∑k=1p∣xk−yk∣q]1qd_q(x,y)=[\sum_{k=1}^p|x_k-y_k|^q]^{\frac{1}{q}}dq(x,y)=[k=1∑p∣xk−yk∣q]q1
- q=1q=1q=1,绝对值距离
d1(x,y)=∑k=1p∣xk−yk∣d_1(x,y)=\sum_{k=1}^p|x_k-y_k|d1(x,y)=k=1∑p∣xk−yk∣
- q=2q=2q=2,欧几里得距离
d2(x,y)=[∑k=1p∣xk−yk∣2]12d_2(x,y)=[\sum_{k=1}^p|x_k-y_k|^2]^{\frac{1}{2}}d2(x,y)=[k=1∑p∣xk−yk∣2]21
- q=∞q=\inftyq=∞,切比雪夫距离
d∞(x,y)=max1≤k≤p∣xk−yk∣d_{\infty}(x,y)=\max_{1\le k\le p}|x_k-y_k|d∞(x,y)=1≤k≤pmax∣xk−yk∣
- 马氏(Mahalanobis)距离
d(x,y)=(x−y)TΣ−1(x−y)d(x,y)=\sqrt{(x-y)^T\Sigma^{-1}(x-y)}d(x,y)=(x−y)TΣ−1(x−y)
xxx,yyy来自ppp维总体ZZZ的样本观测值;Σ\SigmaΣ为ZZZ的协方差矩阵,实际中Σ\SigmaΣ往往是位置的,常常需要用样本协方差矩阵来估计。
- 此外还有样本相关系数、夹角余弦和其它关联性度量作为相似性度量
类与类间的相似性度量
- 最短距离法
D(G1,G2)=minxi∈G1yj∈G2{d(xi,yj)}D(G_1,G_2)=\min_{\substack{x_i\in G_1 \\ y_j\in G_2}}\{d(x_i,y_j)\}D(G1,G2)=xi∈G1yj∈G2min{d(xi,yj)}
- 最长距离法
D(G1,G2)=maxxi∈G1yj∈G2{d(xi,yj)}D(G_1,G_2)=\max_{\substack{x_i\in G_1 \\ y_j\in G_2}}\{d(x_i,y_j)\}D(G1,G2)=xi∈G1yj∈G2max{d(xi,yj)}
- 重心法
D(G1,G2)=d(xˉ,yˉ)D(G_1,G_2)=d(\bar x,\bar y)D(G1,G2)=d(xˉ,yˉ)
xˉ\bar xxˉ,yˉ\bar yyˉ分别为G1G_1G1,G2G_2G2的重心。
- 类平均法
D(G1,G2)=1n1n2∑i∈G1∑yj∈G2d(xi,yj)D(G_1,G_2)=\frac{1}{n_1n_2}\sum_{_i\in G_1}\sum_{y_j\in G_2}d(x_i,y_j)D(G1,G2)=n1n21i∈G1∑yj∈G2∑d(xi,yj)
- 离差平方和法(Ward法)
D1=∑xi∈G1(xi−xˉ)T(xi−xˉ)D_1=\sum_{x_i\in G_1}(x_i-\bar{x})^T(x_i-\bar x)D1=xi∈G1∑(xi−xˉ)T(xi−xˉ)
D2=∑yj∈G2(yj−yˉ)T(yj−yˉ)D_2=\sum_{y_j\in G_2}(y_j-\bar y)^T(y_j-\bar y)D2=yj∈G2∑(yj−yˉ)T(yj−yˉ)
D12=∑zk∈G1∪G2(zk−zˉ)T(zk−zˉ)D_{12}=\sum_{z_k\in{G_1\cup G_2}}(z_k-\bar z)^T(z_k-\bar z)D12=zk∈G1∪G2∑(zk−zˉ)T(zk−zˉ)
xˉ\bar xxˉ,yˉ\bar yyˉ,zˉ\bar zzˉ分别为G1G_1G1,G2G_2G2和G1∪G2G_1\cup G_2G1∪G2的重心。
D(G1,G2)=D12−D1−D2D(G_1,G_2)=D_{12}-D_1-D_2D(G1,G2)=D12−D1−D2
系统(层次)聚类流程
- 将每个对象看成一类,计算两两之间的距离(距离矩阵)
- 将距离最小的两个类合并成新类
- 重新计算新类与所有类之间的距离
- 重复2 3步,知道所有类最后合并成一类
R型聚类分析
- 按照变量的相似关系把它们聚合成若干类,进而找出影响系统的主要因素
变量相似性度量
- 相关系数:用变量xjx_jxj(x1j,x2j,...,xnjx_{1j},x_{2j},...,x_{nj}x1j,x2j,...,xnj)与xkx_kxk的样本相关系数rjkr_{jk}rjk作为它们的相似性度量
rjk=∑i=1n(xij−xjˉ)(xik−xkˉ)[∑i=1n(xij−xjˉ)2∑i=1n(xik−xkˉ)2]12r_{jk}=\frac{\sum_{i=1}^n(x_{ij}-\bar{x_j})(x_{ik}-\bar{x_k})}{[\sum_{i=1}^n(x_{ij}-\bar{x_j})^2\sum_{i=1}^n(x_{ik}-\bar{x_k})^2]^{\frac{1}{2}}}rjk=[∑i=1n(xij−xjˉ)2∑i=1n(xik−xkˉ)2]21∑i=1n(xij−xjˉ)(xik−xkˉ)
- 夹角余弦:
rjk=∑i=1nxijxik(∑i=1nxij2∑i=1nxik2)12r_{jk}=\frac{\sum_{i=1}^nx_{ij}x_{ik}}{(\sum_{i=1}^nx_{ij}^2\sum_{i=1}^nx_{ik}^2)^{\frac{1}{2}}}rjk=(∑i=1nxij2∑i=1nxik2)21∑i=1nxijxik
两类变量的距离
- 最长距离法
R(G1,G2)=maxxj∈G1xk∈G2{djk}R(G_1,G_2)=\max_{\substack{x_j\in G_1 \\ x_k\in G_2}}\{d_{jk}\}R(G1,G2)=xj∈G1xk∈G2max{djk}
djk=1−∣rjk∣d_{jk}=1-|r_{jk}|djk=1−∣rjk∣或djk2=1−∣rjk∣2d_{jk}^2=1-|r_{jk}|^2djk2=1−∣rjk∣2
变量聚类
- 变量聚类和层次聚类思路和过程是一样的
聚类分析案例——我国各地区普通高等教育发展状况分析
x1x_1x1为每百万人口高等院校数; x2x_2x2为 每十万人口高等院校毕业生数; x3x_3x3为每十万人口高等院校招生数; x4x_4x4为每十万人口高 等院校在校生数;x5x_5x5为每十万人口高等院校教职工数;x6x_6x6为每十万人口高等院校专职 教师数;x7x_7x7 为高级职称占专职教师的比例;x8x_8x8 为平均每所高等院校的在校生数; x9x_9x9为 国家财政预算内普通高教经费占国内生产总值的比重;x10x_{10}x10 为生均教育经费 。
部分数据如下表所示: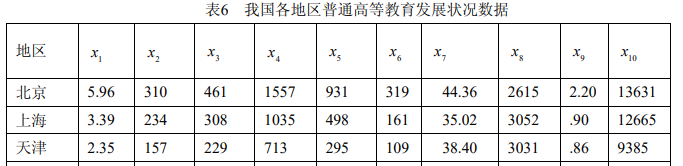
先对变量进行聚类选出指标,再对样本进行聚类。
clc;clear
a=load('gj.txt');
b=zscore(a); %数据标准化
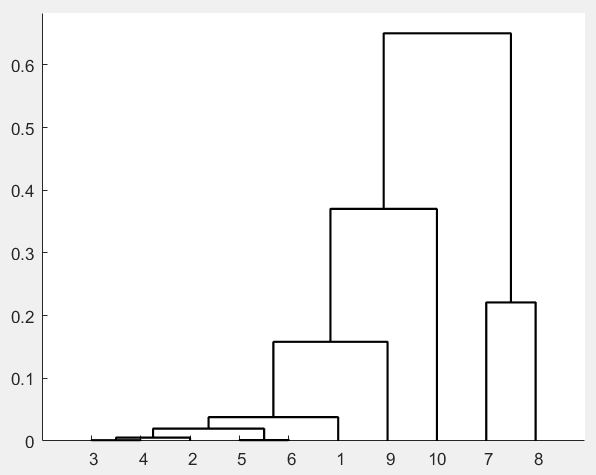
%% R型聚类
r=corrcoef(b);%计算相关系数
d=tril(1-abs(r));%根据相关系数计算距离,并取矩阵的下三角部分
d=nonzeros(d)'; %取出非零数据形成一个向量
%或者直接使用这种方法求距离向量
%d=pdist(b','correlation'); %b需要转置是因为在R型聚类中,b的每一列是一个样本,而pdist需要的是每一行是一个样本
z=linkage(d,'average');%按类平均法聚类
figure()
h=dendrogram(z);
set(h,'Color','k','LineWidth',1.3)
T=cluster(z,'maxclust',6);
%可以将求距离pdist,聚类过程linkage,聚类结果cluster 合并为一个函数
%hidx=clusterdata(data,'maxclust',numClust,'distance',dist_h,'linkage',link);
%T=clusterdata(b','maxclust',6,'distance','correlation','linkage','average');
for i=1:6
tm=find(T==i); %求第i类的对象
tm=reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类的有%s\n',i,int2str(tm)); %显示分类结果
end
%根据聚类结果选择2(在第2类中,2是最后被聚类的) 1 9 7 8 10六个指标
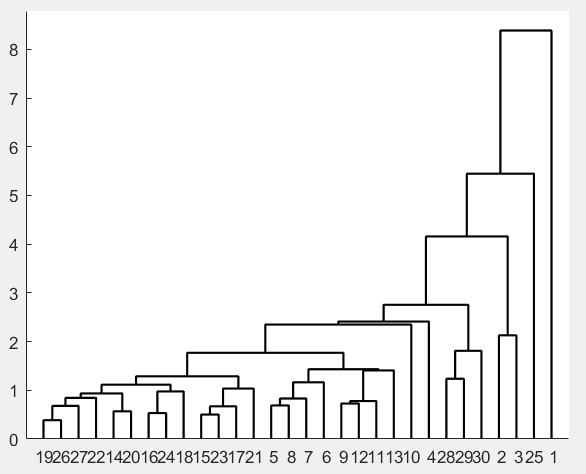
%% Q型聚类
%根据这6个指标对30个地区进行聚类
b_=b(:,[1:2,7:10]);
y=pdist(b_);%求对象间的欧式距离(默认),y的结果是行向量,squareform(y)可转成距离矩阵
z=linkage(y,'average');
figure()
h=dendrogram(z);
set(h,'Color','k','LineWidth',1.3)
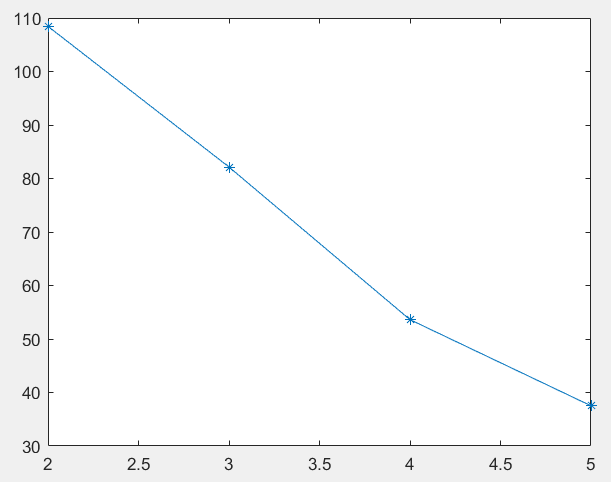
%% 用sse画肘部图
sse=[];
for k=2:5
T=cluster(z,'maxclust',k);
s=zeros(1,k);
for i=1:k
tm = find(T==i);%第i类有哪些地区
mean_=mean(b_(tm,:),1);
for j=1:length(tm)
s(i)=s(i)+sum((b_(tm(j),:)-mean_).^2);
end
end
sse=[sse,sum(s)];
%fprintf('分为%d类时的sse=%f\n',k,sum(s));
end
figure()
plot(2:5,sse,'*-')
% 设分为K个类别
K=4;
for i=1:K
tm=find(T==i); %求第i类的对象
tm=reshape(tm,1,length(tm)); %变成行向量
fprintf('第%d类的有%s\n',i,int2str(tm)); %显示分类结果
end

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)