二,jmeter基础
文章目录
-
- 一、jmeter简介及安装
- 二、jmeter设置语言
- 三、jmeter文件路径说明
- 四、编写jmeter脚本
- 五、乱码的处理:
- 六、写脚本方法扩展
- 七、 脚本功能增强
-
- 1、用户自定义变量,用户参数
- 2、函数概念及常用函数
-
- 1、概念:
- 2、重要函数
-
- ${__counter(,)} 计数器
- ${__dateTimeConvert(,,,)} 时间格式转换
- ${__time(,)} 获取**当前时间函数**
- ${__timeShift(,,,,)} 数据格式化
- ${__RandomDate(,,,,)} 随机日期,不包括结束日期
- ${__digest(,,,,)} **加密** 简单加密
- ${__intSum(,,)} 整数相加函数
- ${__Random(,,)} 获取一定范围的随机数
- ${__RandomString(,,)} 获取随机字符串
- ${__threadNum} 获取线程号函数
- ${__P(,)} **获取属性函数**
- ${__property(,,)} **获取属性函数**
- ${__setProperty(,,)} 设置**属性函数**
- ${__V(,)} 拼接函数
- 八、响应提取
- 九、关联
- 十、DDT数据驱动性能测试
- 十一、逻辑控制器
一、jmeter简介及安装
1、简介
- Apache 托管的开源java工具
- 接口测试、自动化测试、性能测试
- java要运行依赖什么?
- jre java 运行环境
- jdk java开发工具包,一般是包含jre
- 查看jdk版本
java -version正常返回jdk版本,但是不代表你的系统就配置JAVA_HOME环境变量- JAVA_HOME
2、安装
- 解压zip包,进入解压后文件夹\bin文件夹中,双击 jmeter.bat,启动图形界面GUI
- mac ./jmeter.sh
- 1、不需要配置JMETER_HOME环境变量
- 原因: 如果配置了,那么你的电脑就有且仅能运行一个jmeter
- 配置环境变量,可能会导致,直接闪退
- 直接闪退原因:
- 配置了环境变量
- 没有安装jdk
- 包少了文件
- 直接闪退原因:
- 2、一台电脑,理论上可以启动任意多个不同版本jmeter
二、jmeter设置语言
- jmeter.properties
- 以
.properties结尾的文件,都是jmeter的属性配置文件 - 最关键的 属性 配置文件
jmeter.properties - 修改属性配置文件中的信息,一定要重启才能生效
- gui中 options > choose language > chinese simplied
- 临时切换gui界面语言
- 一旦关闭gui,就会被还原
- 以
三、jmeter文件路径说明
-
bin启动 配置文件 -
libjar包 工具自身jar, 以及第三方jarext第三方插件管理
-
docs文档 用于jmeter进行二次开发调用的api 接口文档 -
printable_docs离线帮助文档 -
extras扩展 CICD 性能测试持续集成 -
gui界面
- 一切都在右键掌握之中
- 测试计划: 工作中测试计划: 什么时间什么人做什么事情
- 万物的根, 脚本的根文件
- 元件
- 线程组: 接口、自动化测试时,基本不会去改动
- 性能测试,这个是用于进行性能场景设计的
- 线程组:进行性能场景设计
- setup线程组
- teardown线程组
- 配置元件
- 优先级是最高的, 正式干活时,急先锋
- 用户定义变量
- 监听器
- 就是侦探 就是摄像头,性能结果进行监控,展示结果数据
- 不同的元件,是从不同的角度,展示结果数据
- 取样器: 根据不同的协议,使用不同的取样器
- 线程组: 接口、自动化测试时,基本不会去改动
- 作用域
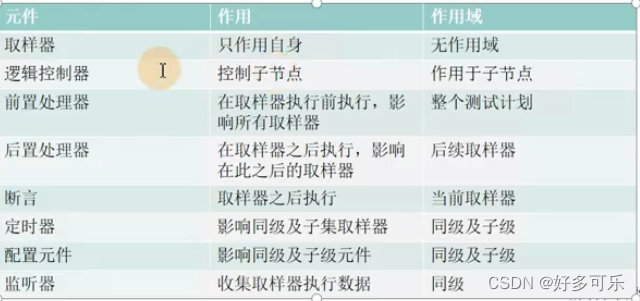
- 执行顺序:配置元件>前置处理器>取样器>监听器
- 配置元件执行顺序:因为都是相同优先级,故按照从上往下来执行(取样器也是一样)
四、编写jmeter脚本
-
逻辑控制:
-
前置: 用户参数
-
后置: 对取样器进行控制
-
定时器
-
写脚本
1)测试计划上右键, 添加 线程组
2)线程组上右键,添加 取样器> http请求 (http协议簇)
3)线程组上右键,添加 监听器 > 查看结果树- 脚本构成:
一个最简单的jmeter脚本,包括,线程组、取样器、监听器-
线程组: 性能测试中用于场景设计的,写脚本阶段不用改动
-
取样器: 根据不同的协议,编写不同的脚本。 填空
-
监听器: 调试脚本时使用,性能测试执行时,禁用
不管哪种监听器,都是对结果数据进行不同维度的展示,这些展示,是需要 消耗本地资源的
-
- jmeter的默认保存路径,jmeter的bin文件夹
- 脚本构成:
-
请注意:
-
当请求体为json, 一定要有请求头 Content-Type:application/json
-
协议: 当协议为http时,可以不写,如果是https,那就必须写
-
服务器名称或IP:不能带有/
-
路径: 不要带域名或ip,和端口。路径开头用/,不要带有空格, 带有空格请求URL%20 urlencoded编码
-
参数、消息体数量的选择
消息体:当我们的请求接口文档中说,请求体为json格式,那么我们就选择用json
参数: 我们的请求体,form-data
Content-Type: application/x-www-form-urlencoded 或者不指明请求体类型,get -
keepAlive勾选:如果勾上,表示保持长连接。因为现在用http协议版本为1.1 就是长连接,所以,默认勾选keepAlive,但是在性能测试中,我们会根据需要,去掉这个勾。
-
参数、消息体数量 选择
- 消息体:当我们的请求接口文档中说,请求体为json格式,那么我们就选择用消息体数据,来写json, 像soap接口,是http+xml的,我们就把xml写到消息体
- 参数: 存放请求体,是form-data格式的
比如 Content-Type: application/x-www-form-urlencoded,或者不指明请求体类型
-
请求重定向
-
自动重定向:不会显示中间重定向过程,无法从过程中,提取信息
-
跟随重定向:会自动显示重定向过程,能从过程中,提取想要信息,用于后面接口请求
-
-
-
一些补充:
-
用jmeter写脚本,可以去做接口测试、自动化测试、性能测试
- 但是,接口测试、自动化测试脚本,不能直接用于性能测试,需要进行性能转换,才能用于性能测试
- 性能测试脚本,可以直接用于接口测试、自动化测试。
- 性能测试,要尽可能的降低jmeter工具自身对资源消耗
- 接口测试、自动化测试脚本,一定会添加断言,断言的目的是判断,是否有bug,断言这个元件在执行时,资源消耗,来自jmeter工具的资源,这个时间和资源的消耗,都是本机的,不是服务器消耗的时间和资源。-----我个人观点里面,是不要加断言。
- Beanshell元件,写脚本时,只考虑功能能实现即可,不会过多去考虑,元件使用的时间、资源消耗。
- 性能测试中, Beanshell所有元件,能不用则不用,如果,一定要写java代码来处理的 JSR223取样器(支持java,python等语言)、 _ _ j e x l 3 ( , ) 、 {\_\_jexl3(,)}、 __jexl3(,)、{__groovy(,)}
- 元件的选择:
- JSR223
- DDT
- 运行模式: GUI 图形界面模式,===只用于编辑调试脚本
- 真正性能测试用 CLI模式 —无图形界面模式
- 性能测试,要尽可能的降低jmeter工具自身对资源消耗
五、乱码的处理:
1、 请求内容出现乱码处理方法
- 内容编码设置为
utf8 - 请求头设置:
,;charset=utf-8 - 请求体为参数类型:
勾选参数“编码” 编码:urlencoded编码 - 在参数值为 非字符(汉字、特殊符号) 我都需要勾选编码。给大家的建议: 参数值,不管什么类型,都建议勾选编码
2、响应内容出现乱码处理方法
- 修改jmeter.properties中
sampler.result.encoding,不是简单的设置为utf8、 gbk、gb2312、big5 - 同一个接口,用postmen请求,响应是正常,用jmeter请求响应中文乱码?
原因是: jmeter的编码是根据操作系统编码。
在国内,中文windows系统的字符集编码是gbk 936, mac系统中文编码utf8,所以通常只是windows乱码,mac不乱码
六、写脚本方法扩展
-
录制脚本
- badboy: 曾经很流行,现在已经不维护,已经被遗弃
-
代理录制: 用于脚本参数比较多,或者用手动编写脚本,一时半会写不出来。
- 代理服务器: 自己启动一个代理服务器
- 本地,要使用代理服务器的ip和端口,使用自己启动的代理服务器
- 1、添加线程组
- 2、测试计划 > 非测试元件 > http代理服务器
- ip就是你自己电脑的ip,port是可以修改,默认8888
- 目标控制器,一定要修改为 测试计划>线程组
- 添加过滤器
- 3、启动代理服务器(chrome推荐proxy omega插件)时,会出现一个证书的弹窗(7天内有效,7天后要重新安装)
- 如果要抓取https信息时,就必须使用证书
- 4、本地浏览器使用 代理服务器上网
- 5、录制后查看
ps:代理使用完记得关上哦,否则无法上网了
- 代理配置
七、 脚本功能增强
1、用户自定义变量,用户参数
-
关联: 前面接口的响应信息,有动态值,作为后续接口的参数参数
-
我想把手机号码参数化,怎么办呢:
- 实现方式:
- 1、用户定义变量:
- 在配置元件,测试计划里
- 作用域:全局变量,作用于整个测试计划,可以跨线程组
- 在启动运行时,获取一次值,在运行过程中,不会动态获取值,在运行过程中,值一直都不变。
- 2、用户参数:
- 在前置处理器里
- 属于局部变量
- 作用域: 作用于当前线程组或当前的取样器,但是无法跨线程组
- 在启动运行时,获取一次值,在运行过程中,还会动态获取值。
ps:这里有每次迭代更新一次的选项,勾选了这个后,比如我现在这个线程组2个请求都引用了这个用户参数,那每次跑这个线程组的时候,2个接口获取的参数值是一致的,然后第二次调用的时候,值会被重新替换,以此类推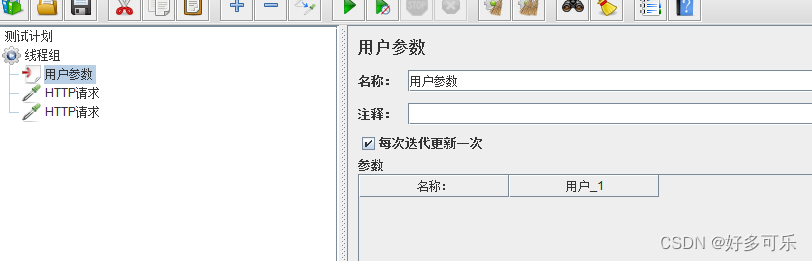
- 1、用户定义变量:
- 在性能测试时,可能会因为不同的需求,把接口写到不同的线程组中
- 多线程组脚本,有个难题,跨线程组传参,这个时候,我们可以采用函数的“用户属性”进行传参
2、函数概念及常用函数
- 实现方式:
-
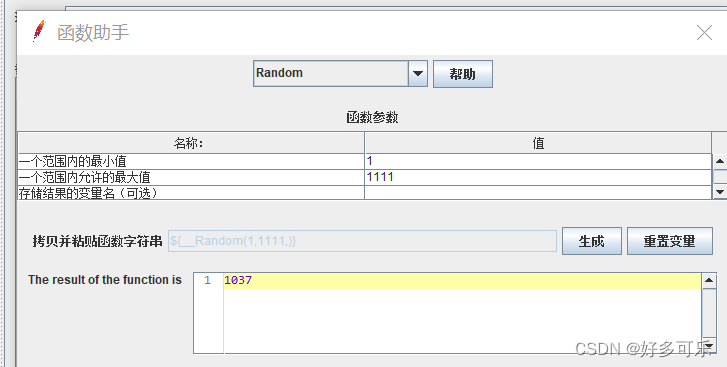
1、概念:
- 函数:方法
- 双下划线开头
- 函数名称,严格区分大小写
- 如何调用:工具-函数助手对话框-选择对应的函数-复制,后续在脚本直接调用即可。如果对函数功能不太了解,可以点击旁边的帮助按钮,会跳转到帮助文档
-
2、重要函数
-
${__counter(,)} 计数器
- 加1功能(注意,只能加1):
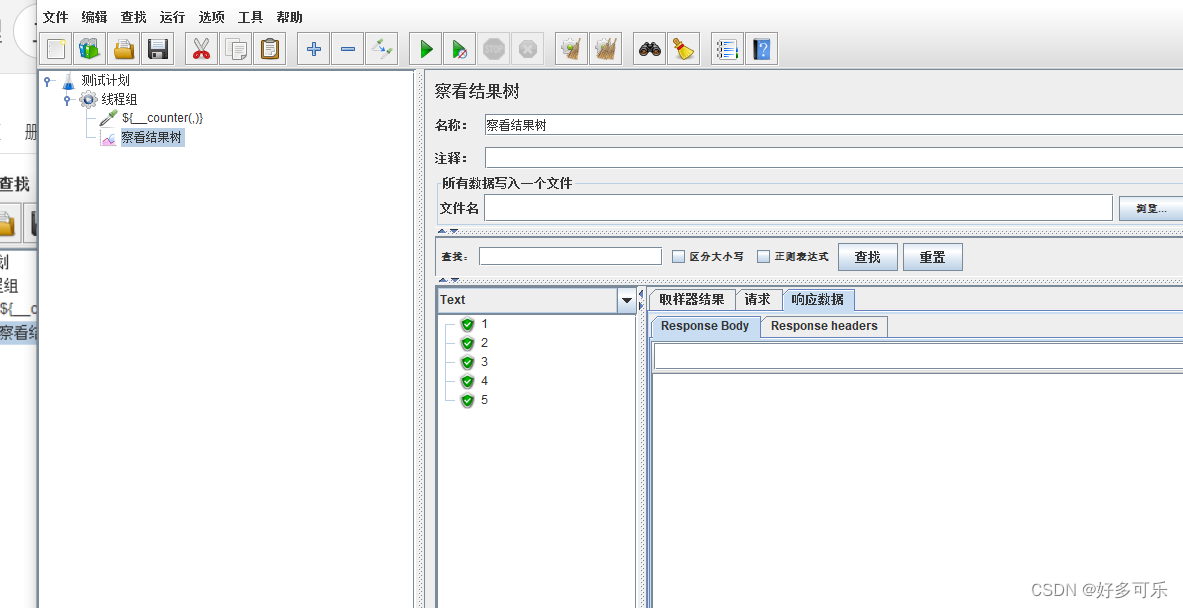
- 如果需要加1以上的,要用计数器(配置元件-计数器)
- 这里有2个注意点:
- 1)如果运行结果超过最大值时,又会从起始值开始循环。如果最大值设置成5,那就是0-2-4-0-2
- 2)每个用户独立计数器: 勾选这个后,多线程时,每个用户都是从起始值开始计数
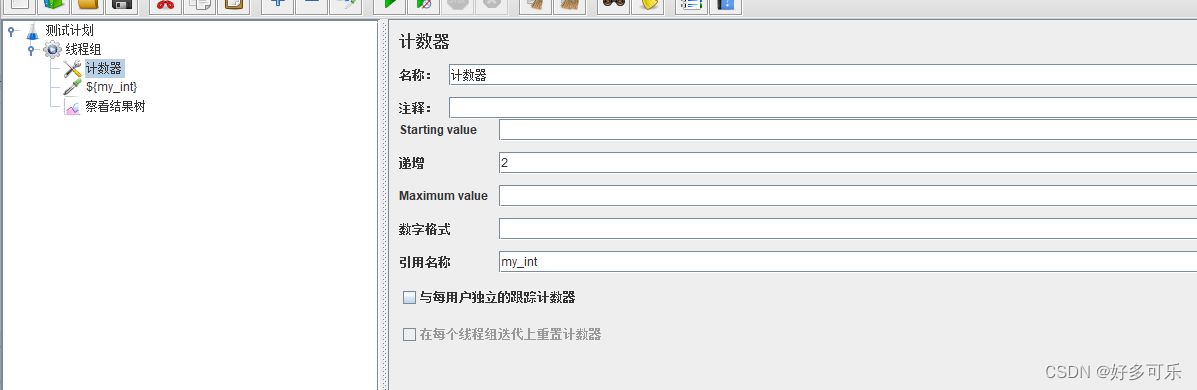
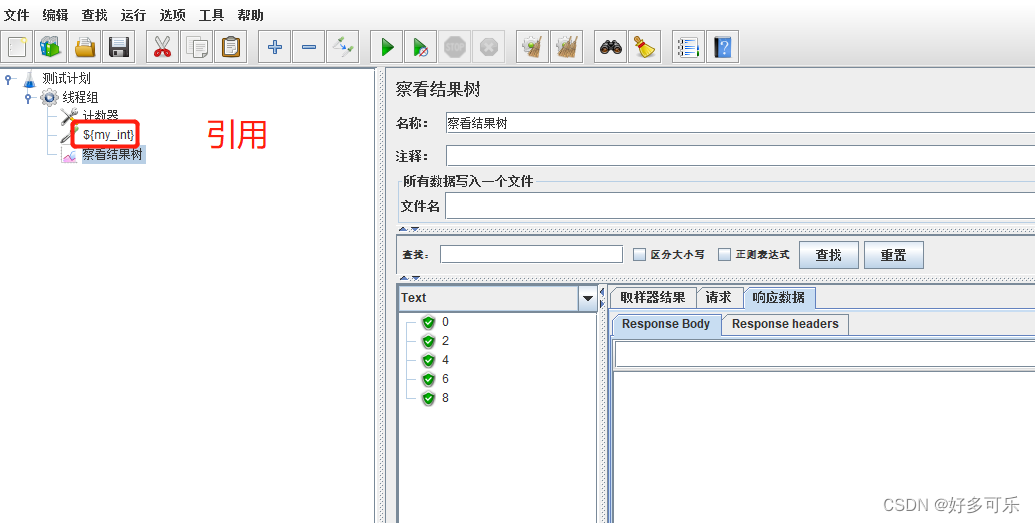
- 这里有2个注意点:
- 加1功能(注意,只能加1):
-
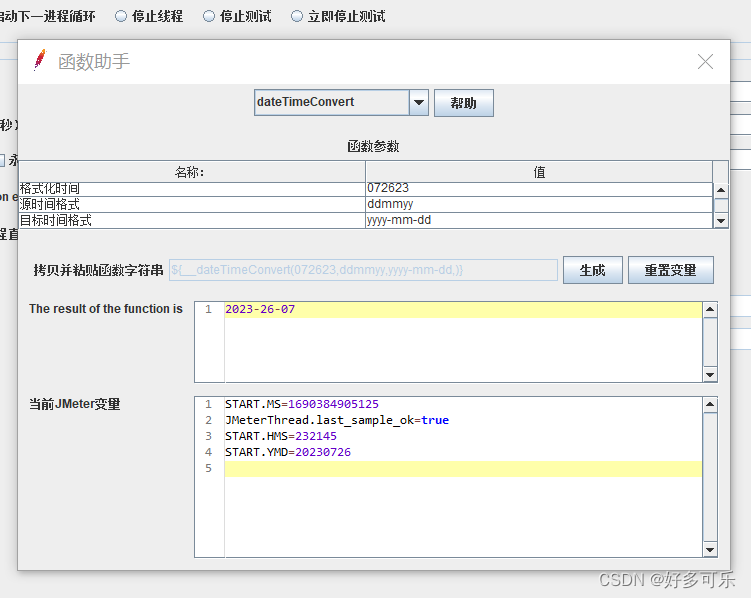
${__dateTimeConvert(,)} 时间格式转换
-
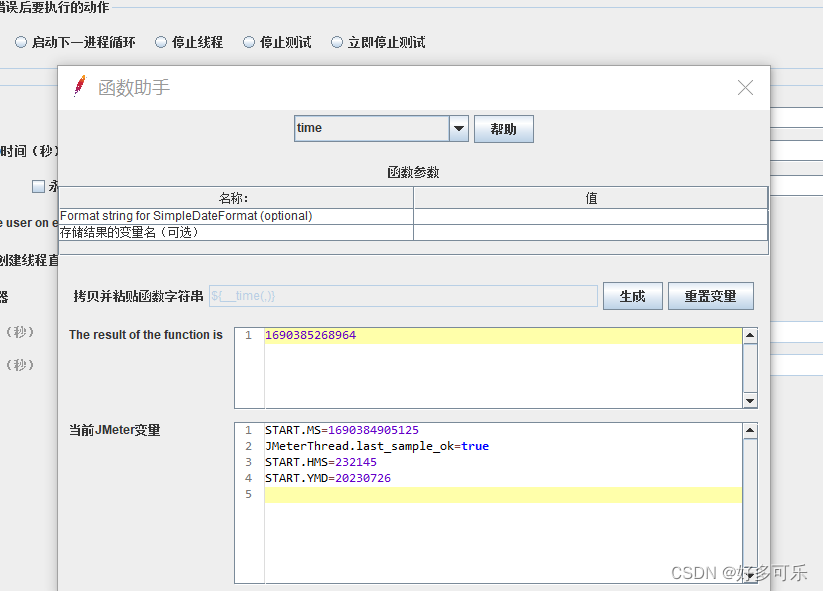
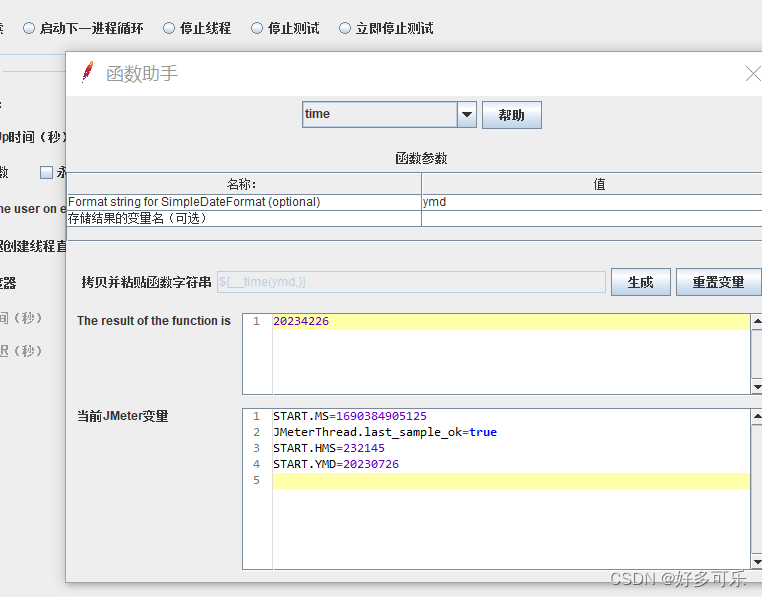
${__time(,)} 获取当前时间函数
-
-
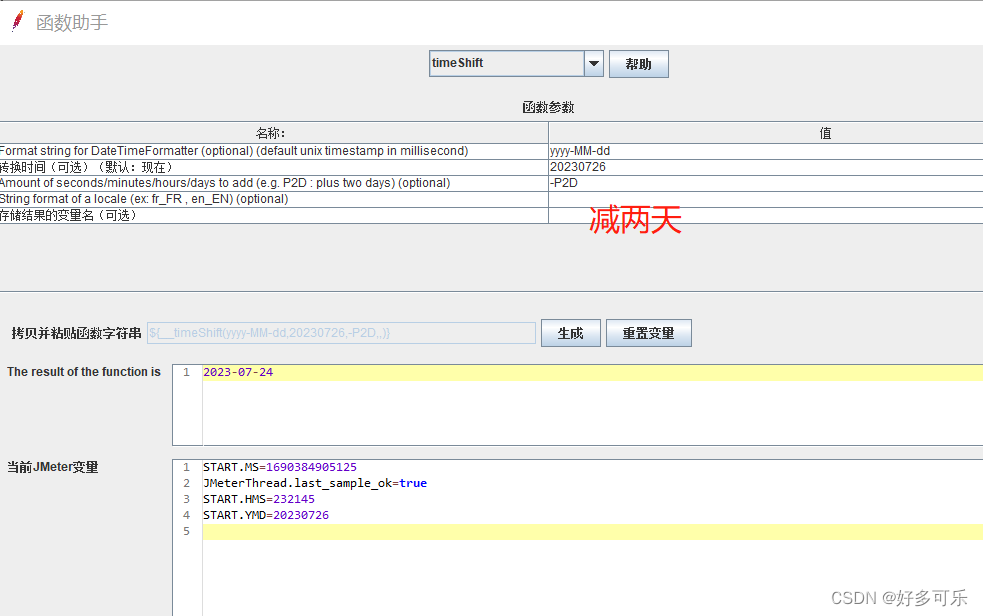
${__timeShift(,)} 数据格式化
- 支持加减天时分秒
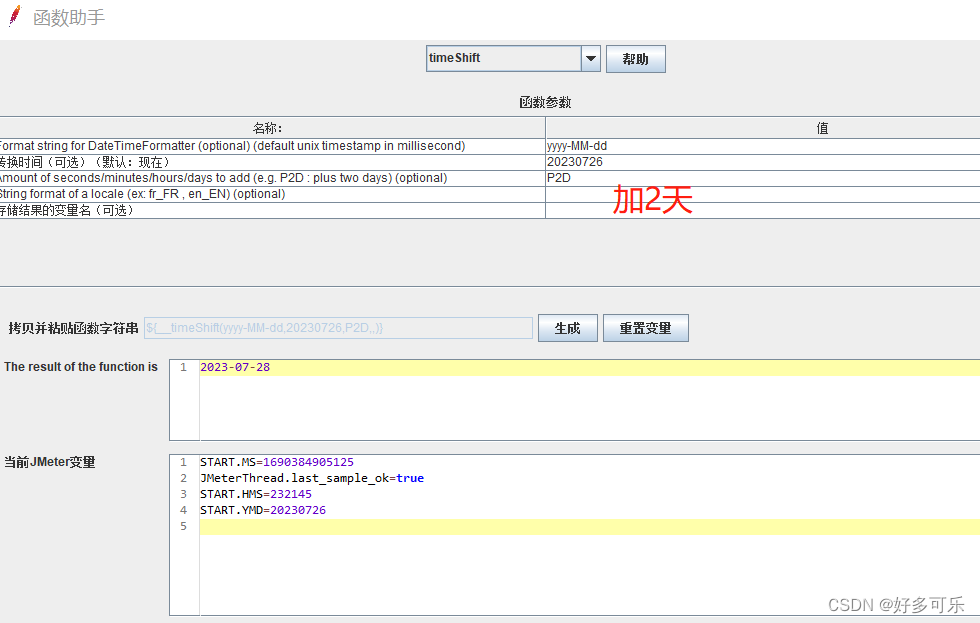
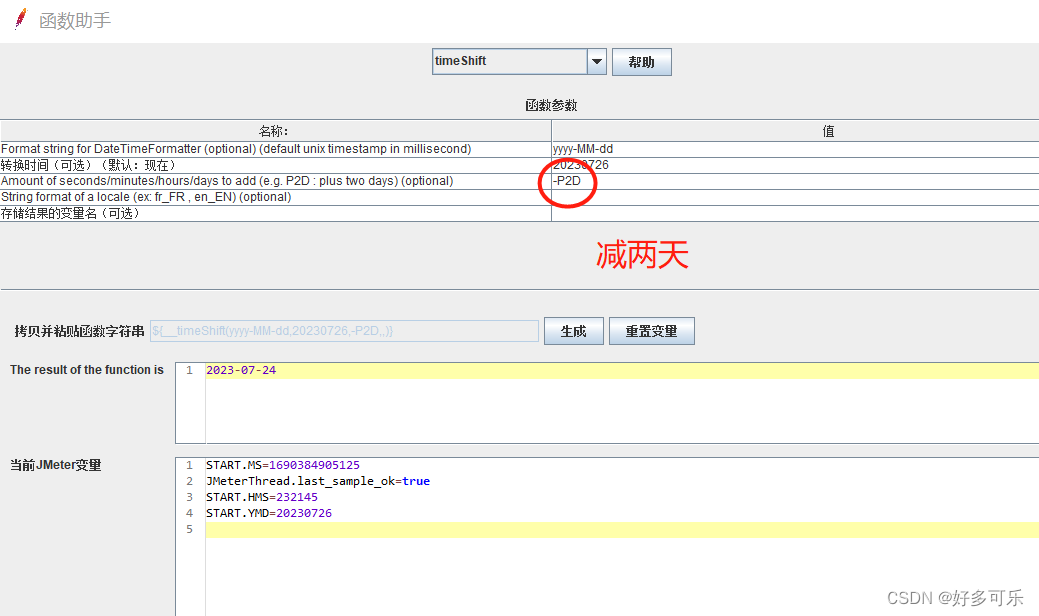
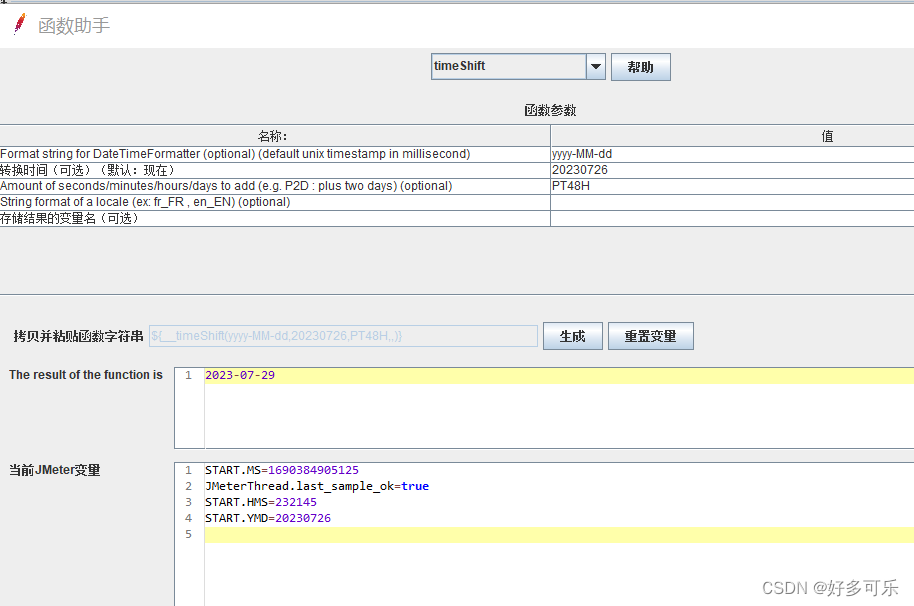
- 支持加减天时分秒
-
${__RandomDate(,)} 随机日期,不包括结束日期
- 7月29到9月21日中随机一天
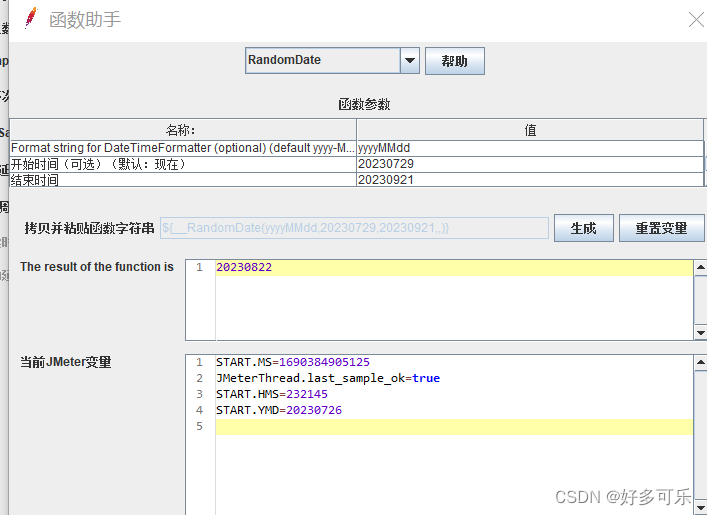
- 7月29到9月21日中随机一天
-
${__digest(,)} 加密 简单加密
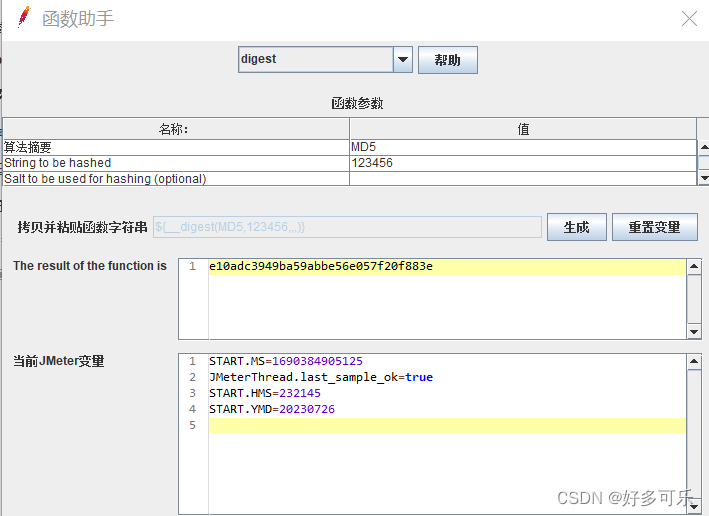
-
${__intSum(,)} 整数相加函数
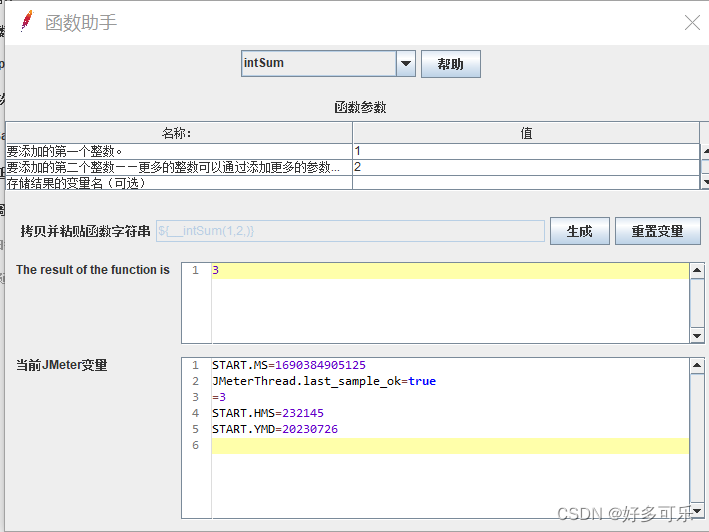
-
${__Random(,)} 获取一定范围的随机数
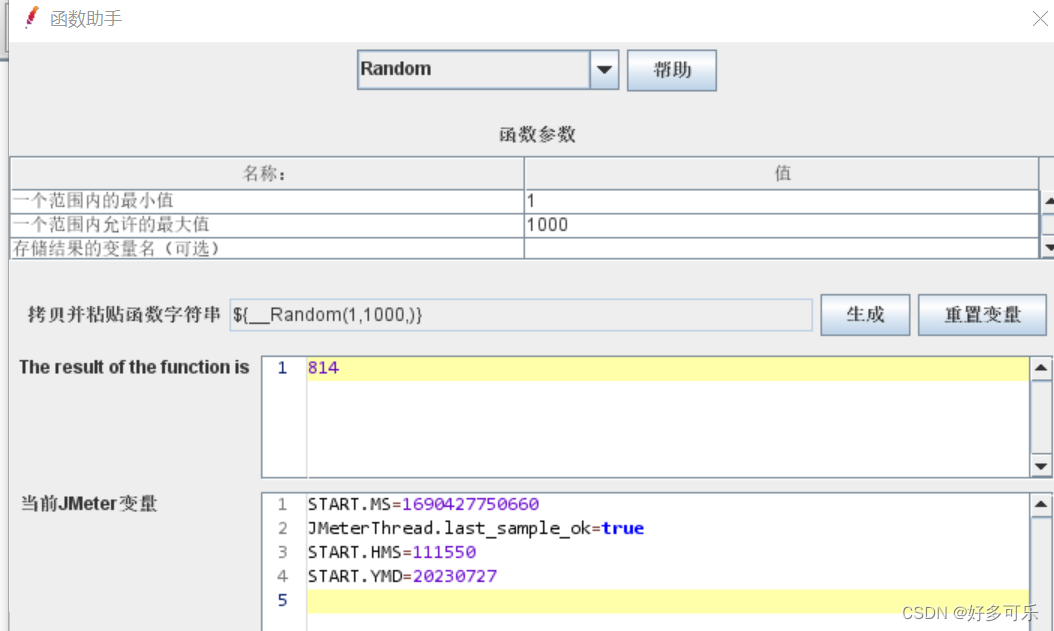
-
${__RandomString(,)} 获取随机字符串
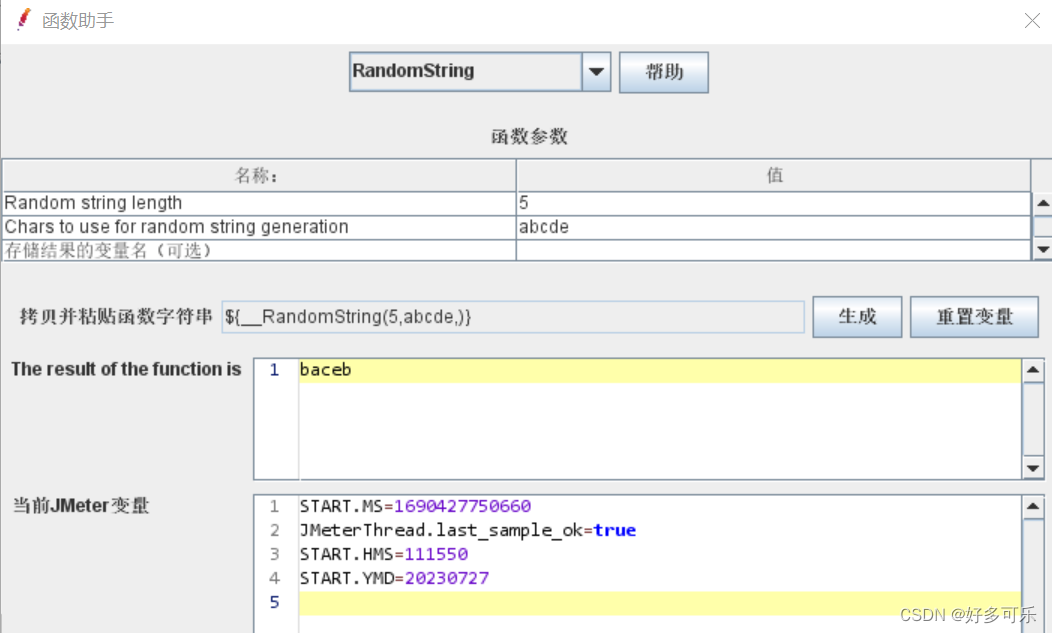
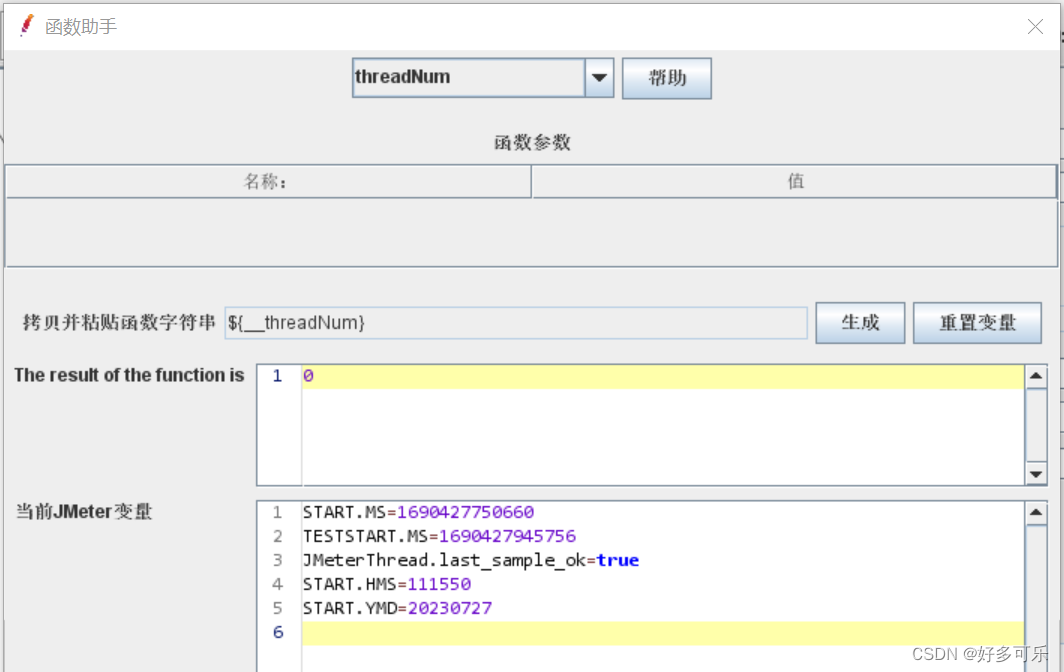
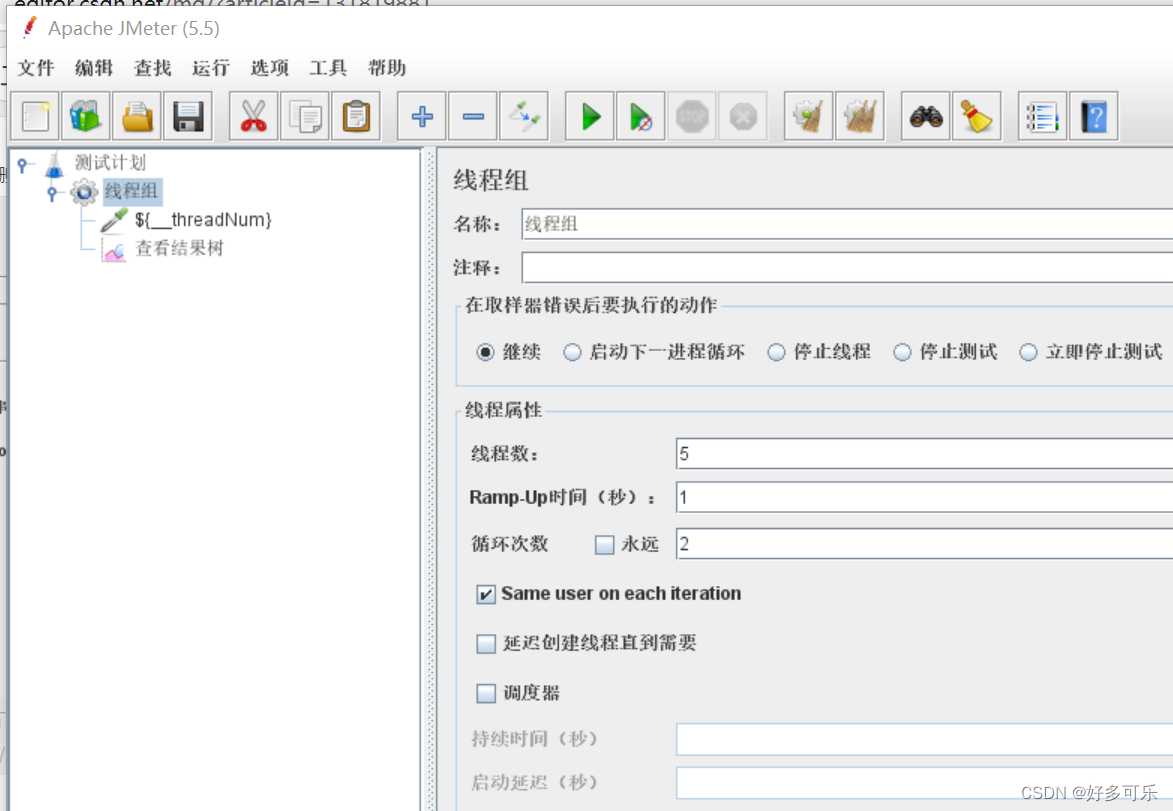
${__threadNum} 获取线程号函数
-
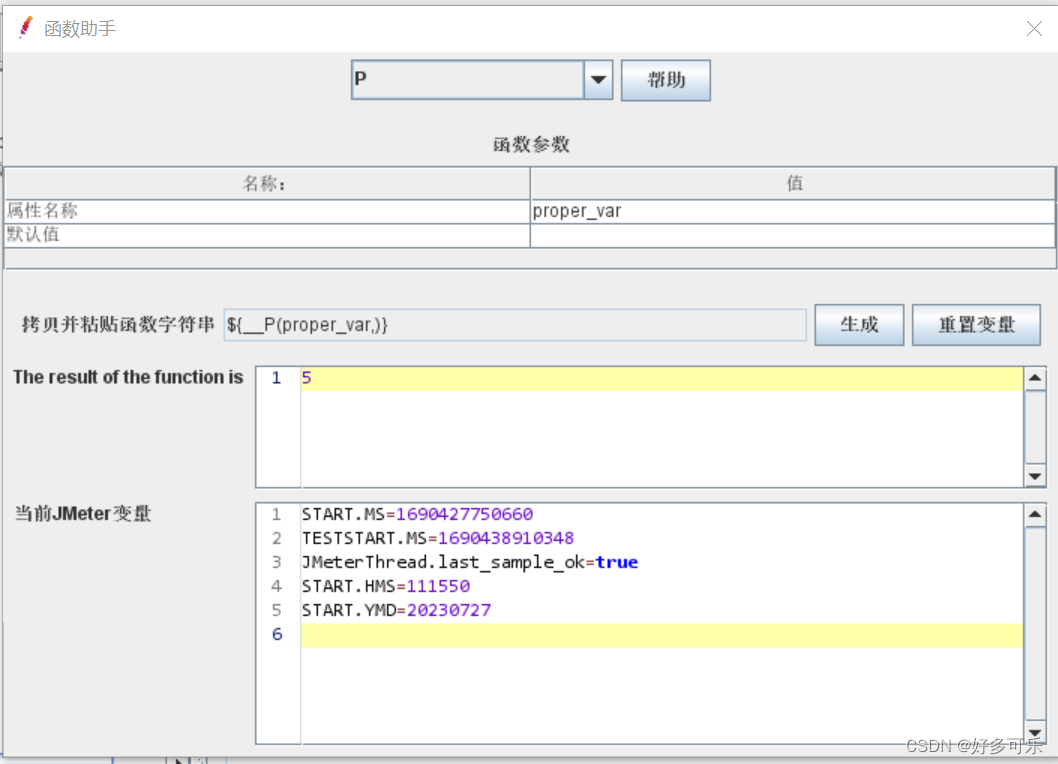
${__P(,)} 获取属性函数
-
${__property(,)} 获取属性函数
- 上面2个函数作用一样,P只是property的简写
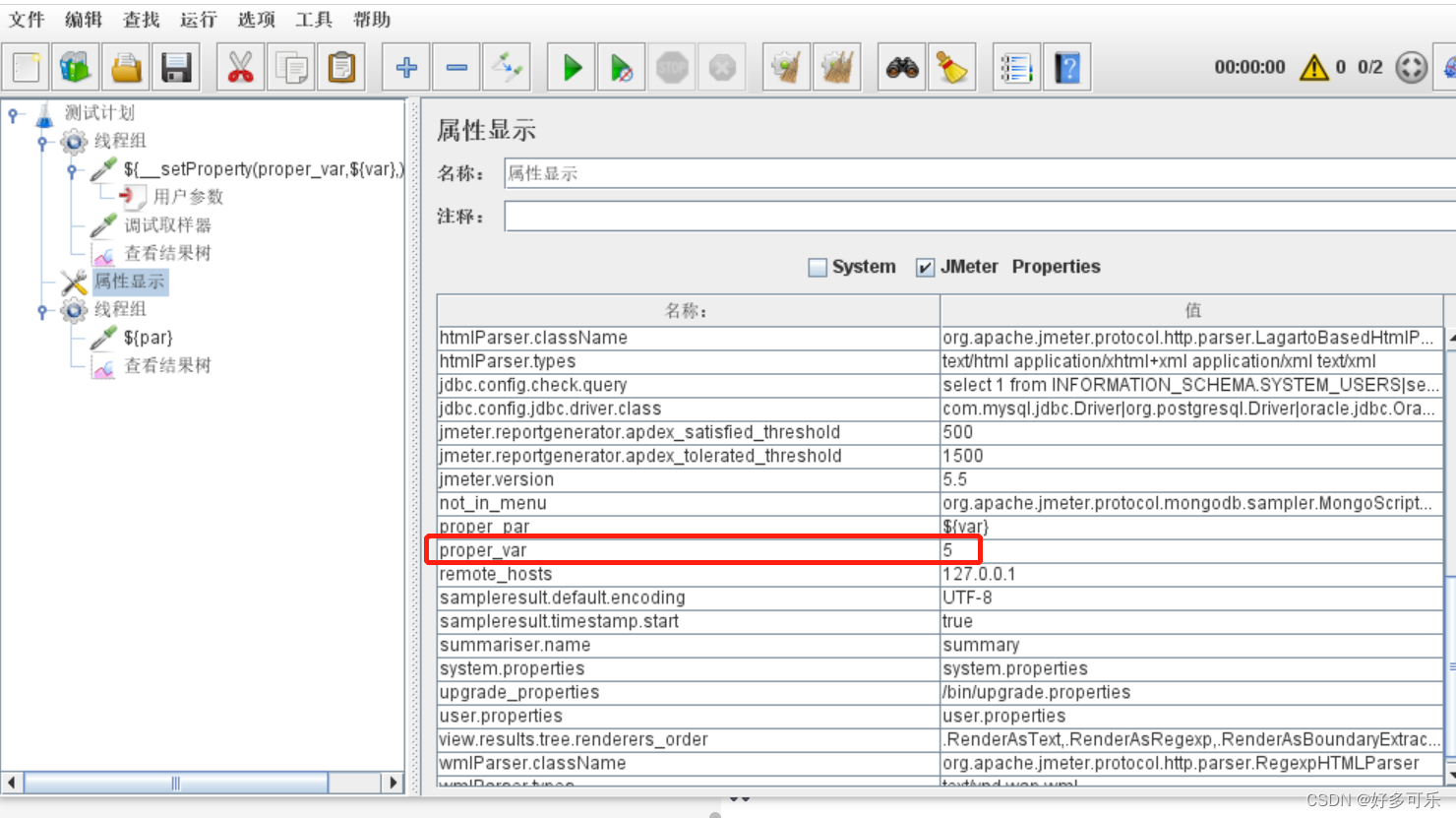
- 属性:
-
以properties结尾的属性,都是jmeter的属性文件
-
jmeter里有系统属性和jmeter属性2大类
- 1)系统属性:比如os,jdk这种,是不可改变的
- 2)jmeter的属性,是可以被改变的,也可以分为2种,静态和动态的
- 静态属性:在properties内的属性信息,都是静态属性
- 动态属性:运行过程中,动态定义的属性
-
查看属性路径:测试计划-非测试元件-属性展示
-
属性VS参数/变量:
- 属性是jmeter工具所有,jmeter的线程组都需要使用属性,也都可以使用
- 参数/变量有访问的局限性
-
系统属性
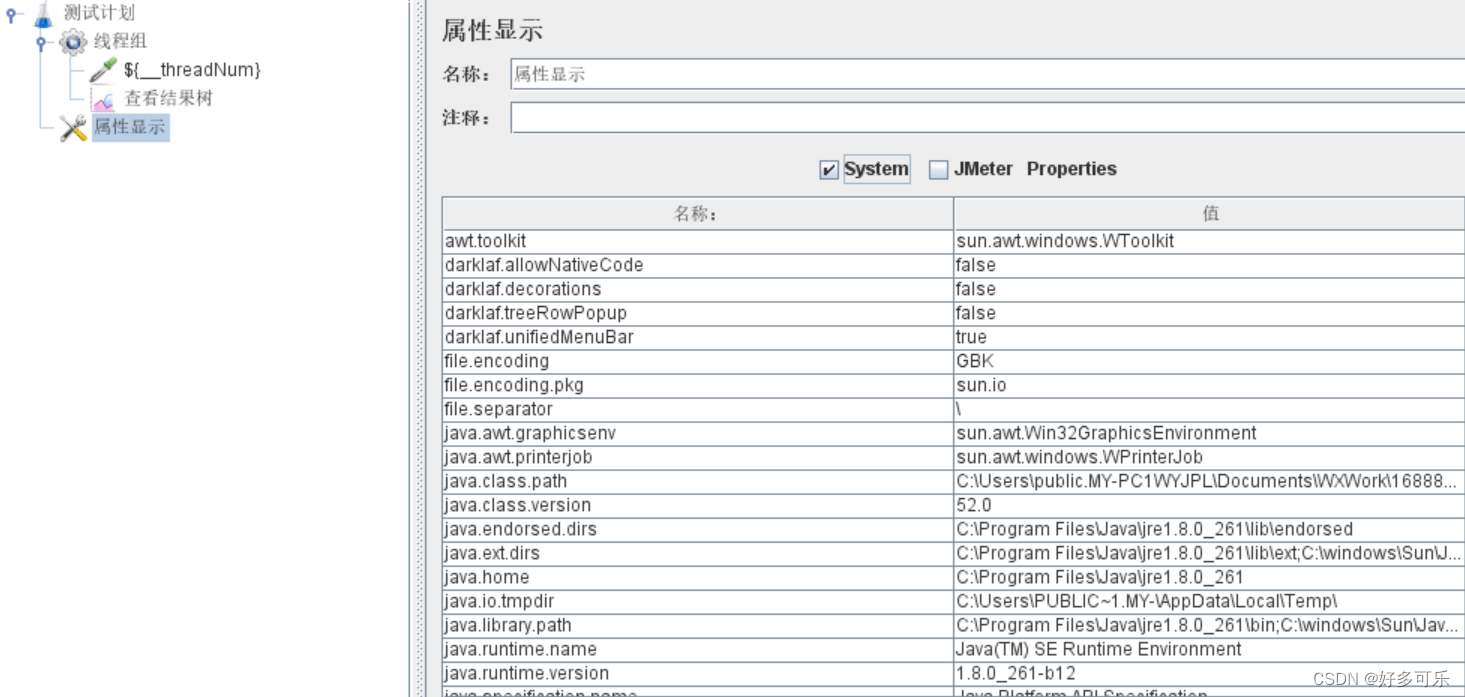
-
动态属性
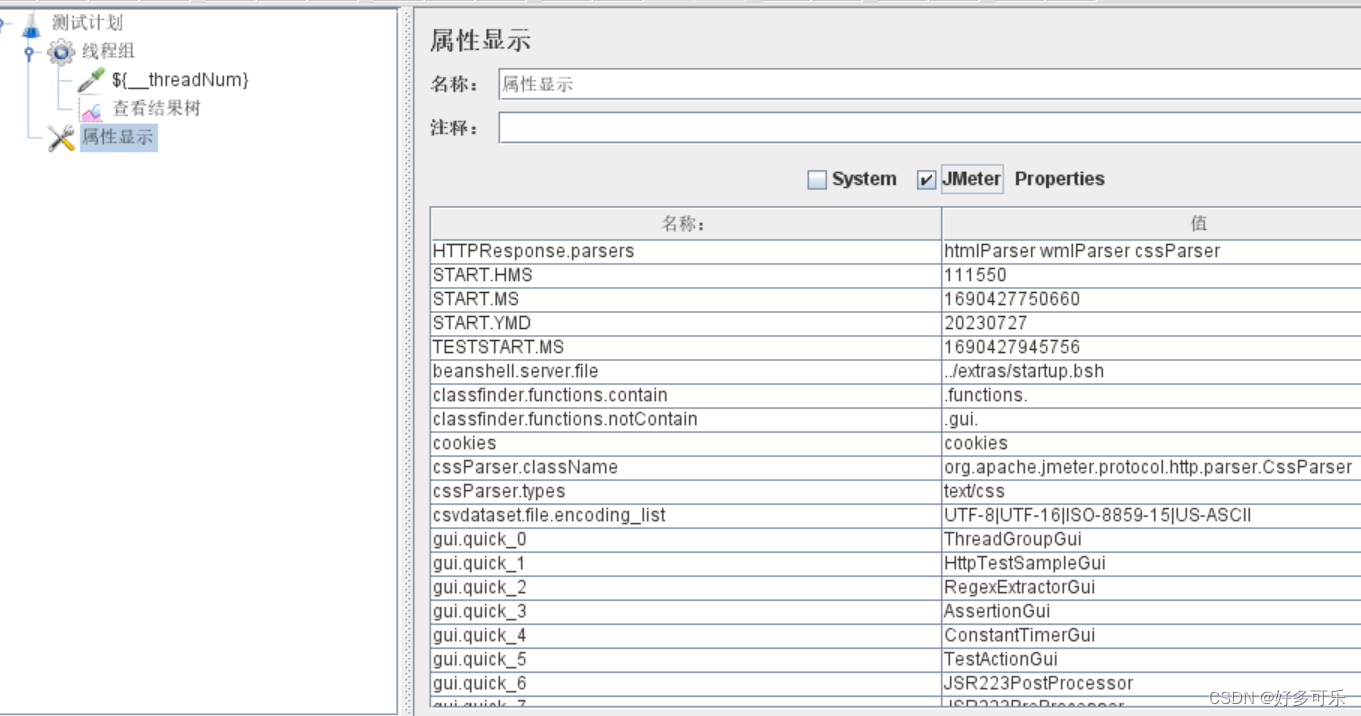
-
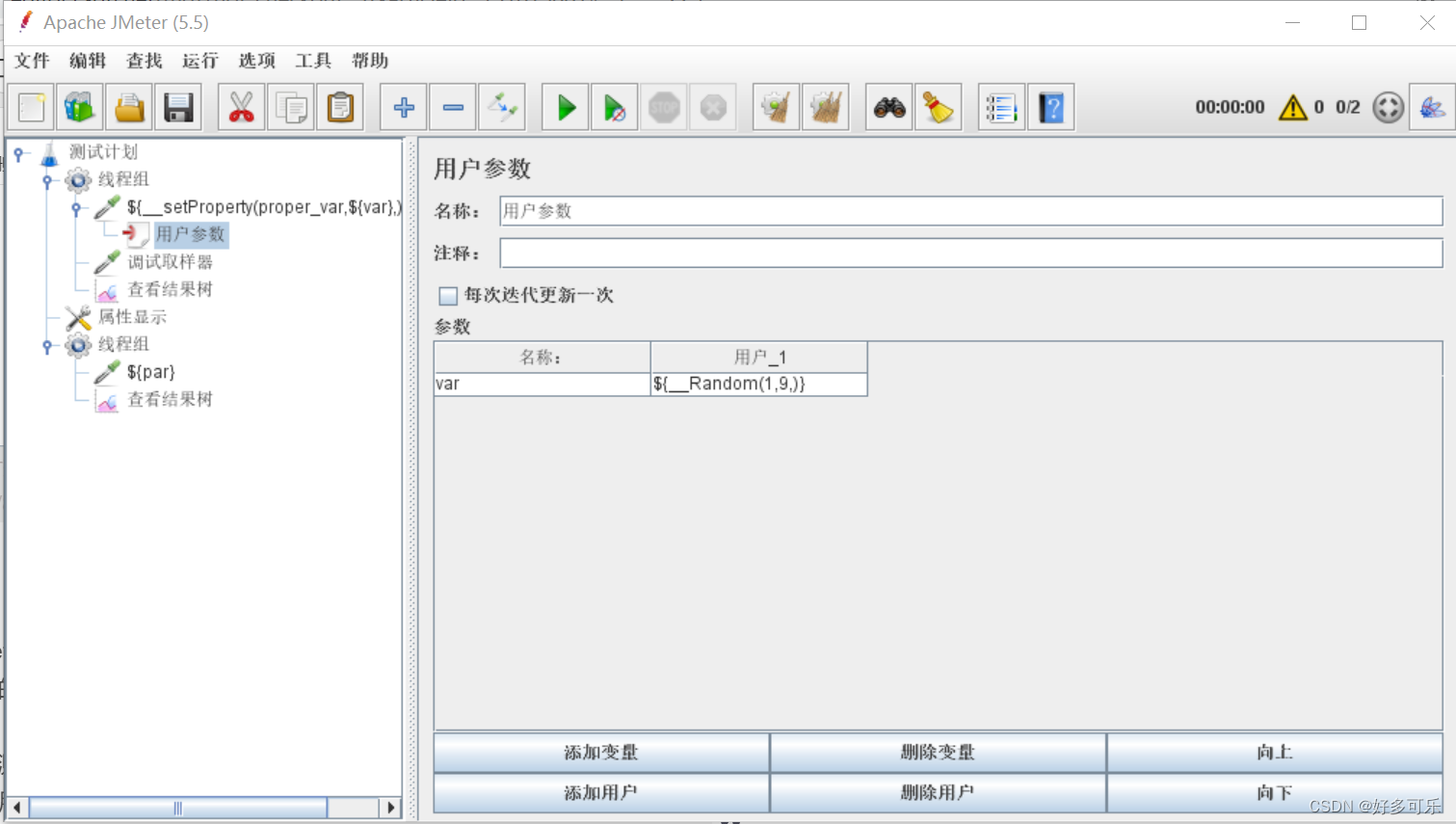
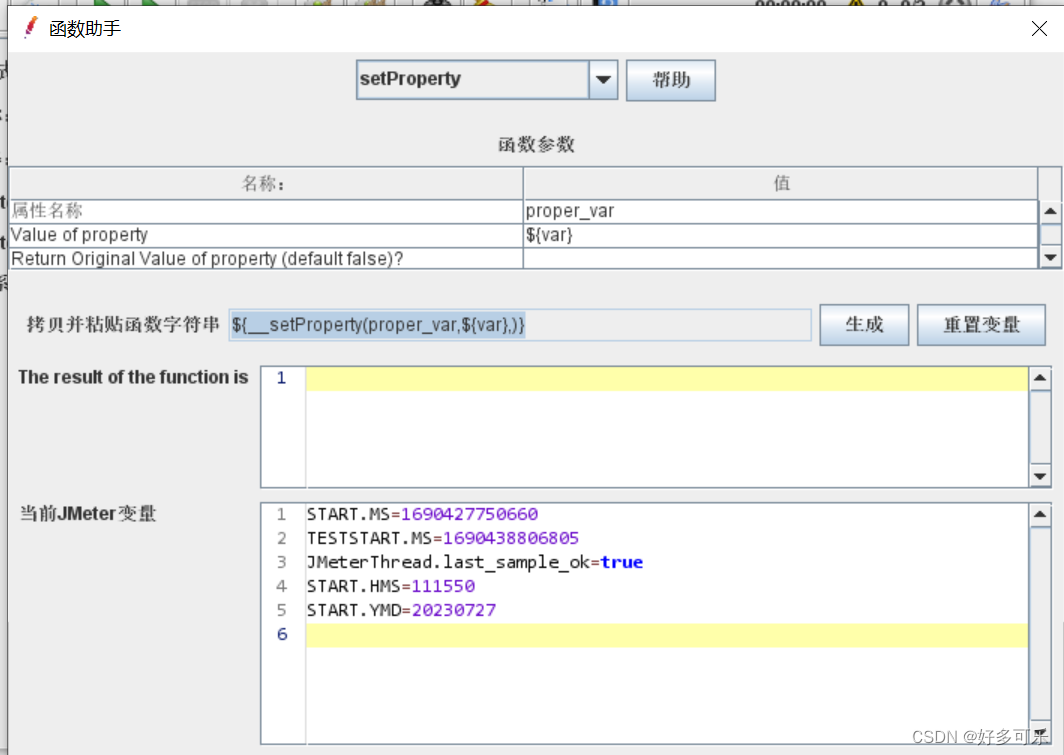
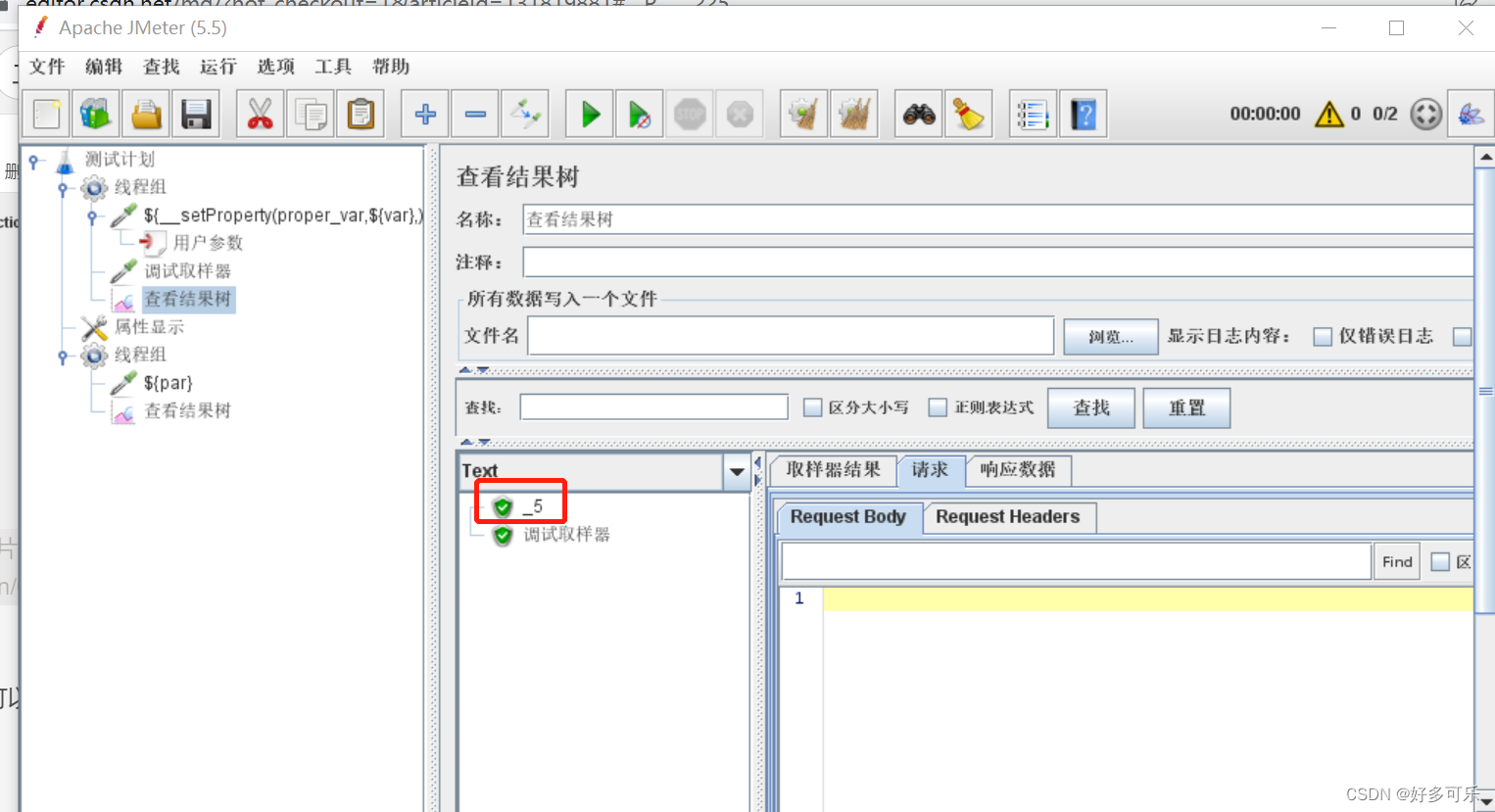
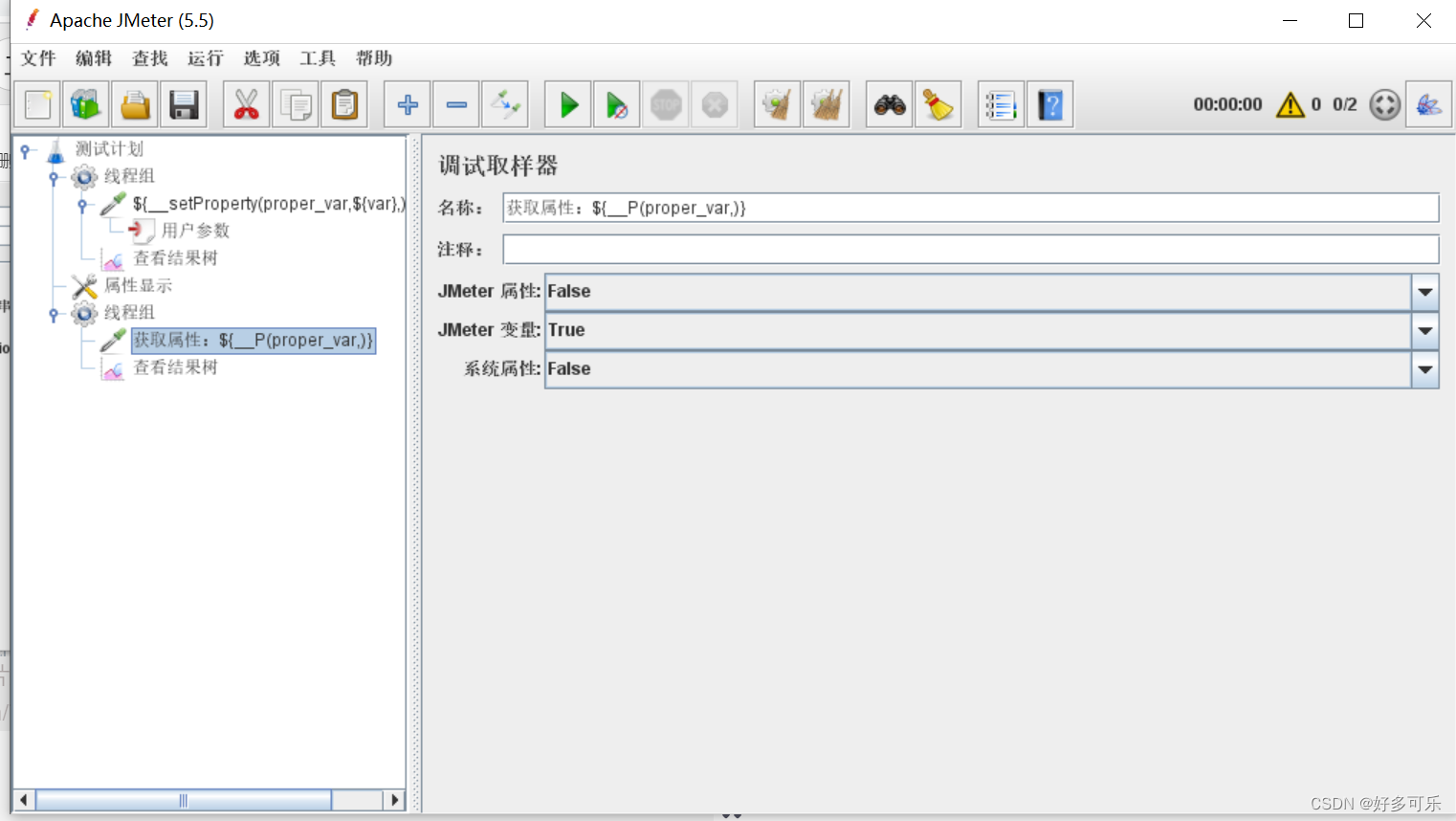
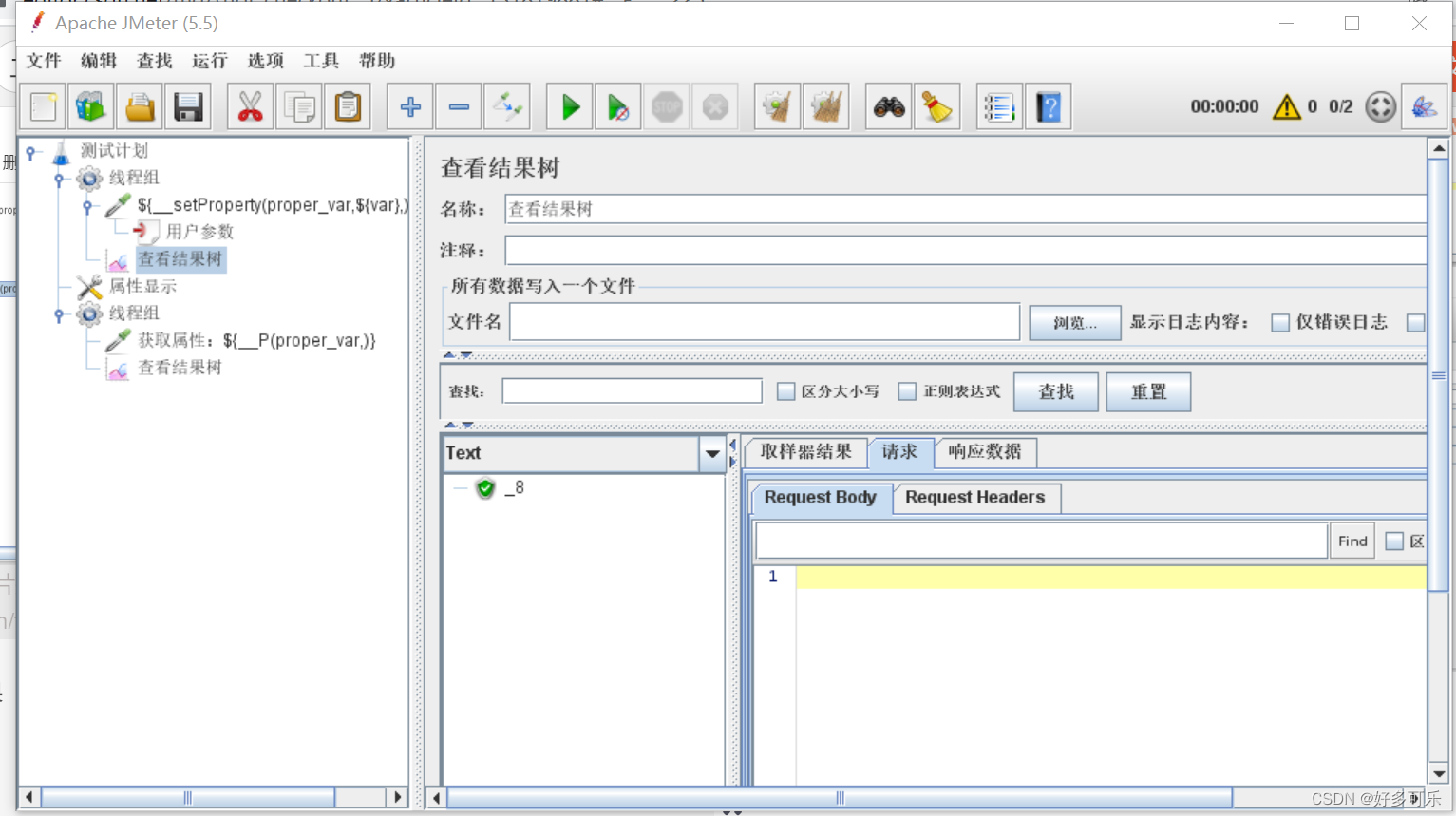
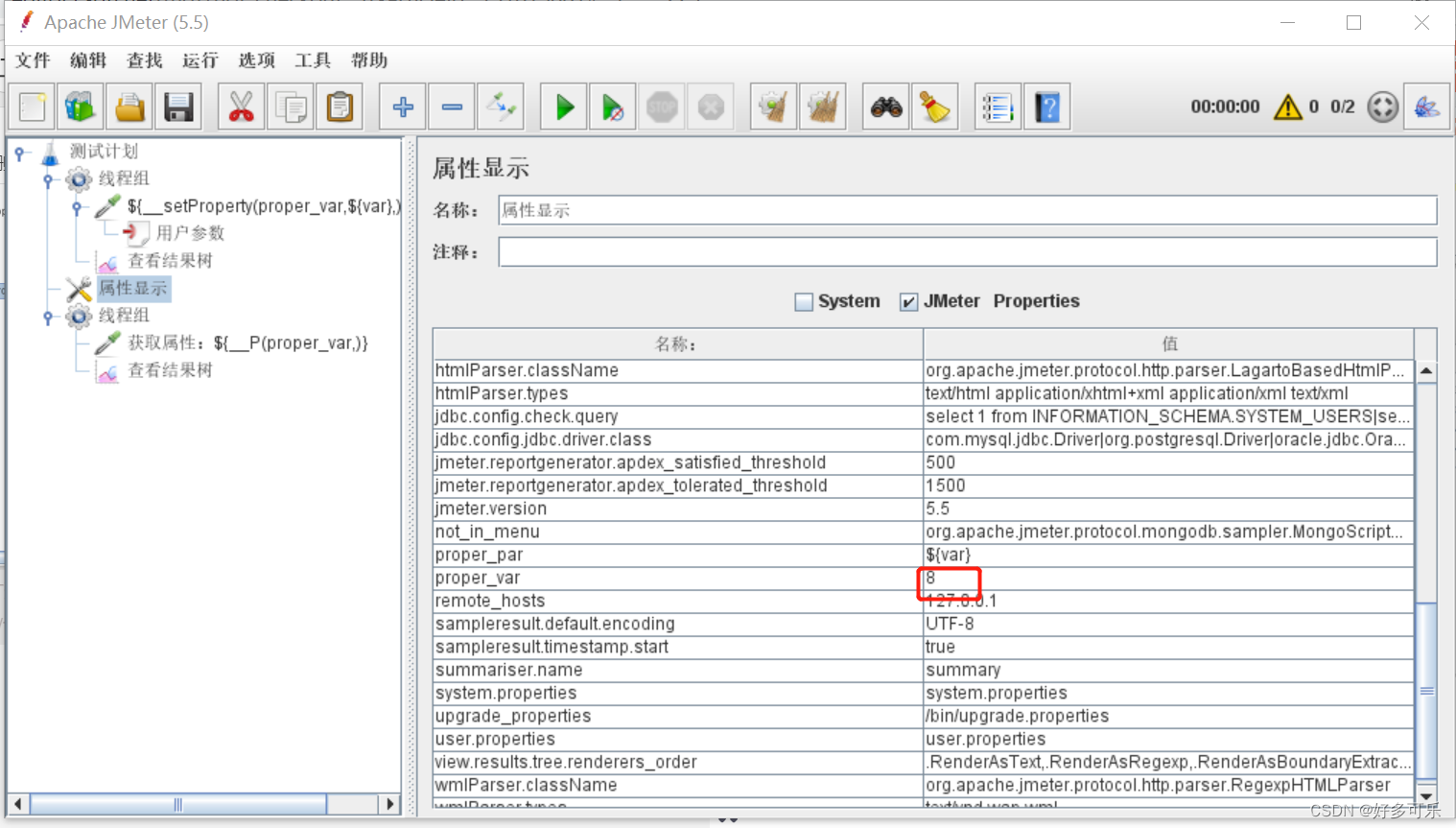
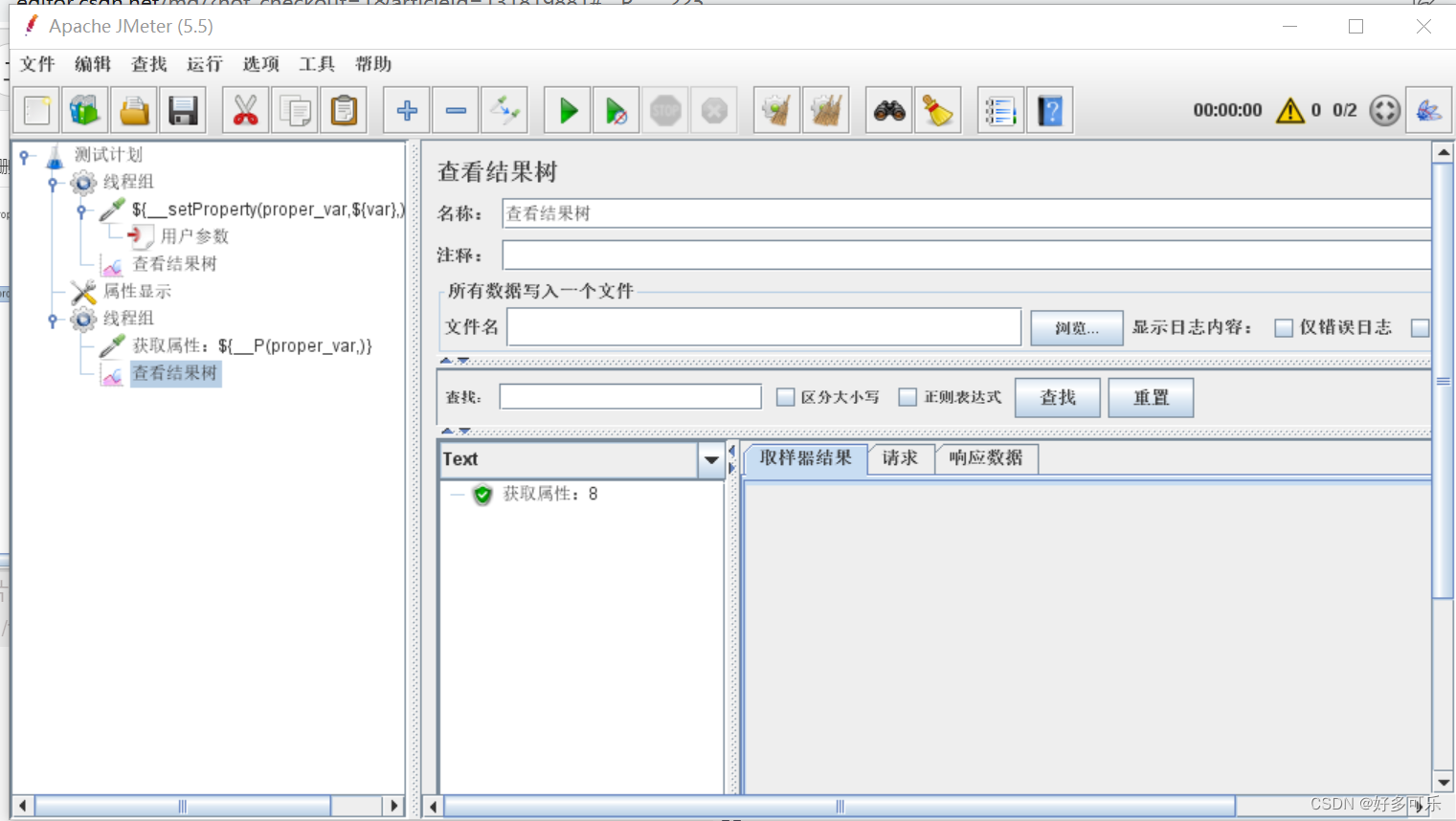
- 注意点:
- 1、属性显示那边更新可能有时候不及时,不是100%可以及时更新的
- 2、为什么会出现数据不对的情况,我们还是要用呢,为什么不用全局变量?
- 因为用户属性是不能跨线程组的,用这个我们可以实现跨线程组的动态调用。
- 值可能有时候需要动态调用,全局变量是全局都是一个,不支持更改。用户参数是可以变,但是不跨线程组,所以用属性函数调用是最好的解决方案
- 性能测试是多个人做某件事,偶尔出错对总体性能结果影响不大
- 3、 动态属性是一直存在的还是阅后即焚?
- 动态属性是运行过程中产生的,关闭jmeter就自动释放了,是临时存储的
- 4、 jmeter的执行顺序?
- 启动后jmeter的线程组默认并行执行的,不是按照先后顺序执行,这样做不是我们获取属性有时候会取不到吗?jmeter是支持设置的,测试计划这边勾选这个选项即可。但是在性能测试中,我们是不会勾选这个选项的,这样不符合实际应用场景,不可能说等做完某些操作,再继续下一个操作,一般都是并行的
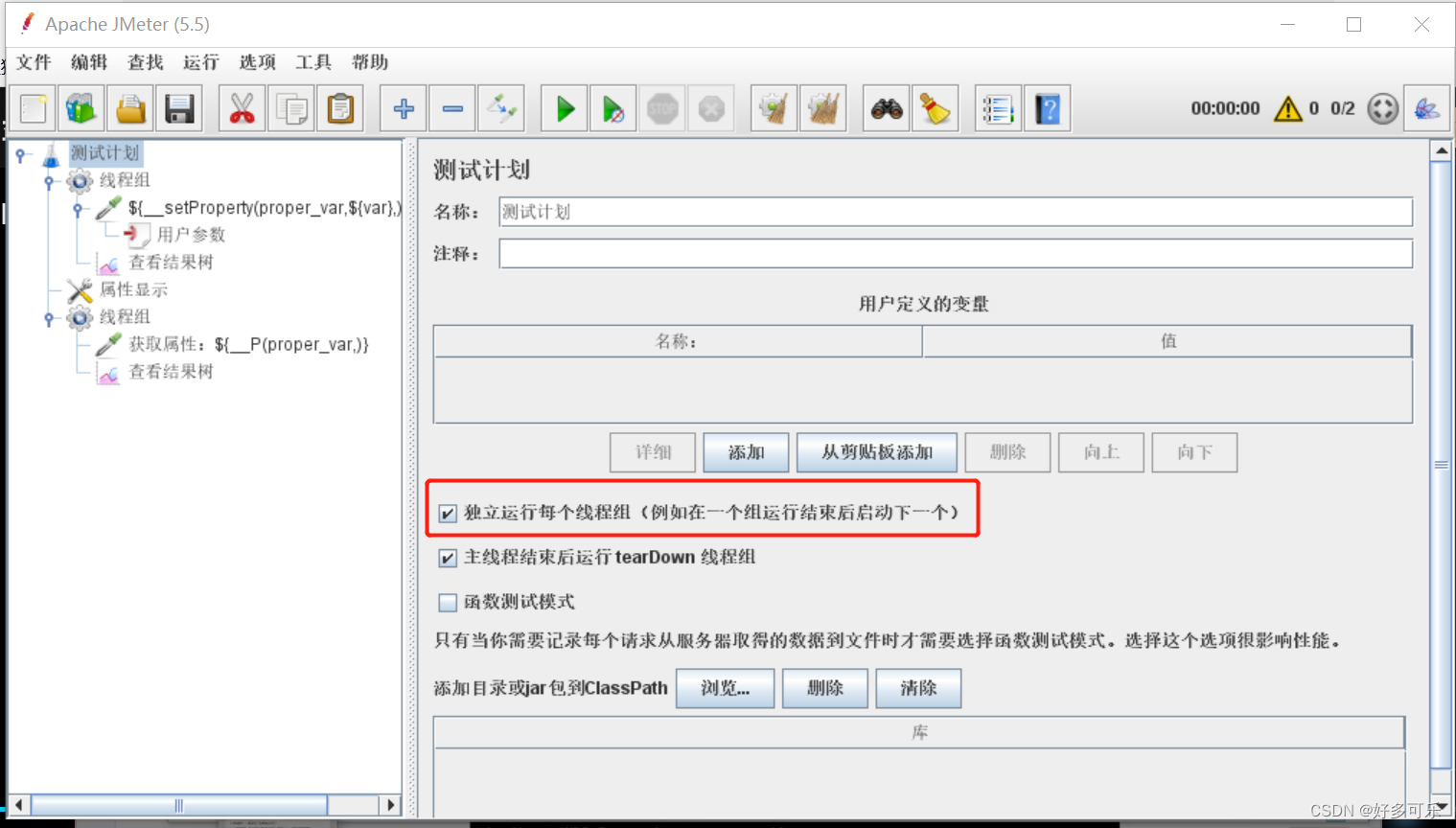
- 启动后jmeter的线程组默认并行执行的,不是按照先后顺序执行,这样做不是我们获取属性有时候会取不到吗?jmeter是支持设置的,测试计划这边勾选这个选项即可。但是在性能测试中,我们是不会勾选这个选项的,这样不符合实际应用场景,不可能说等做完某些操作,再继续下一个操作,一般都是并行的
-
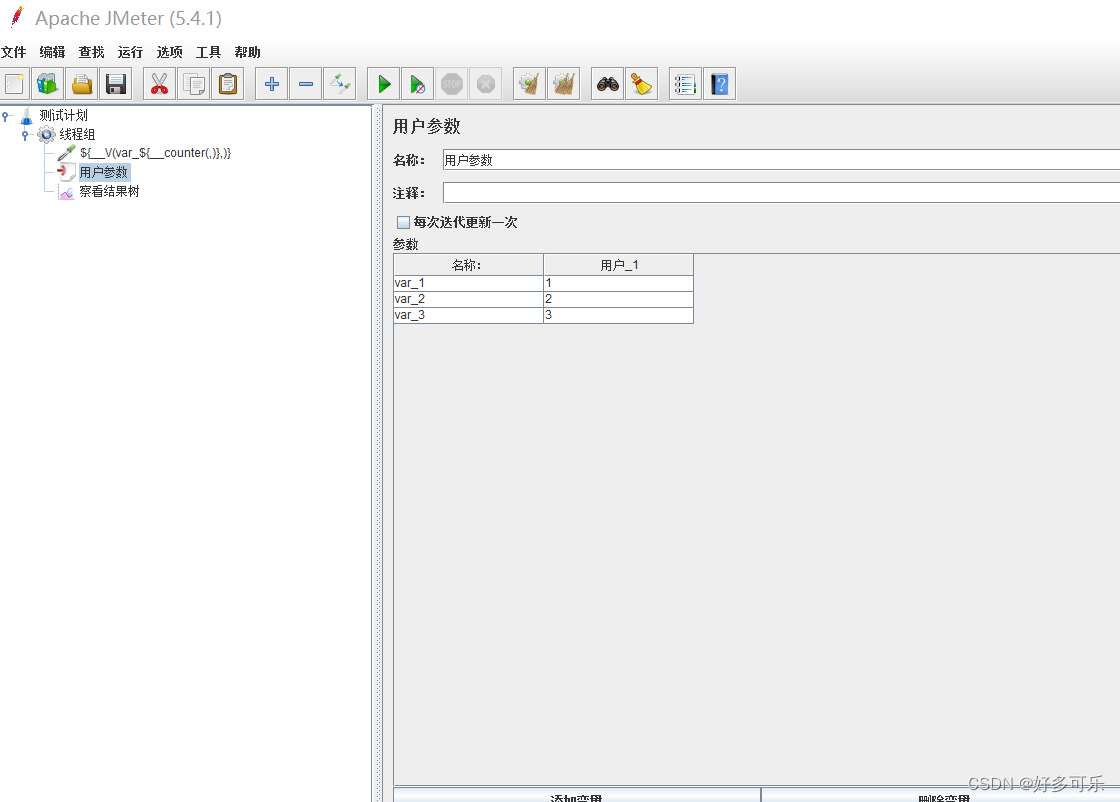
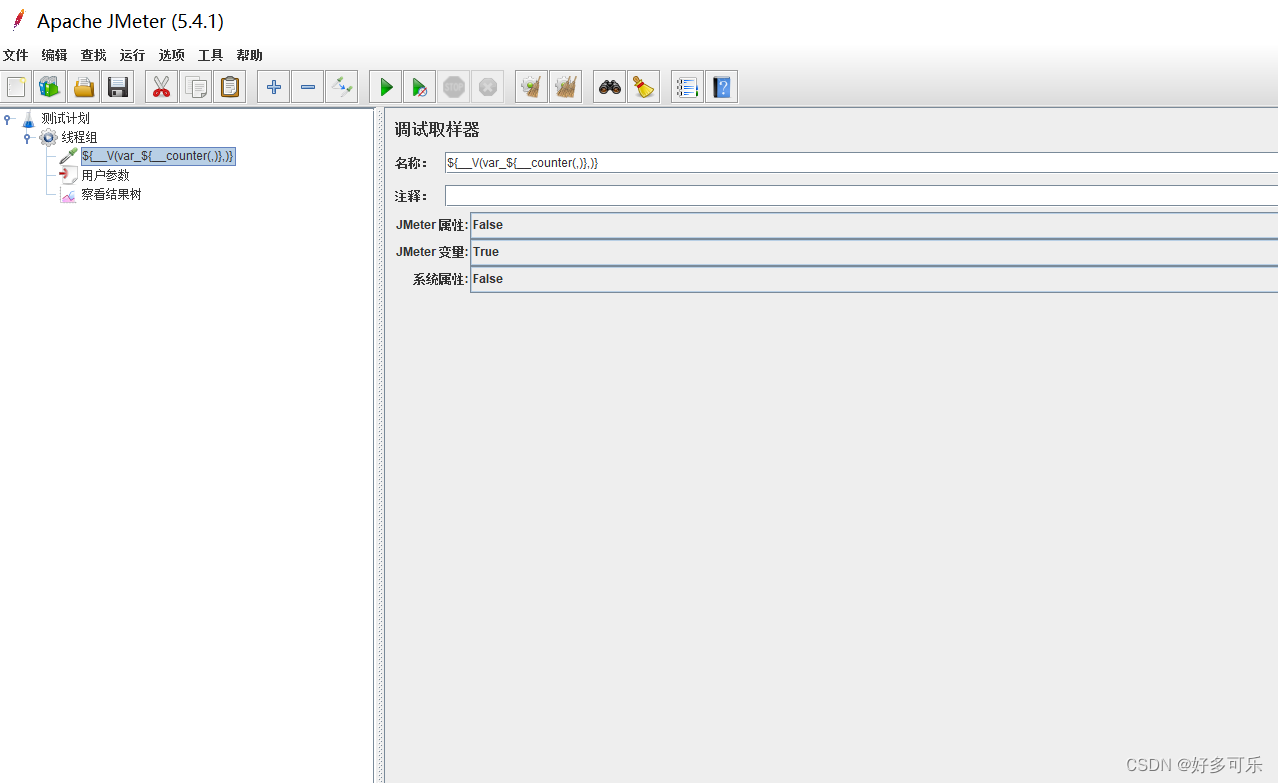
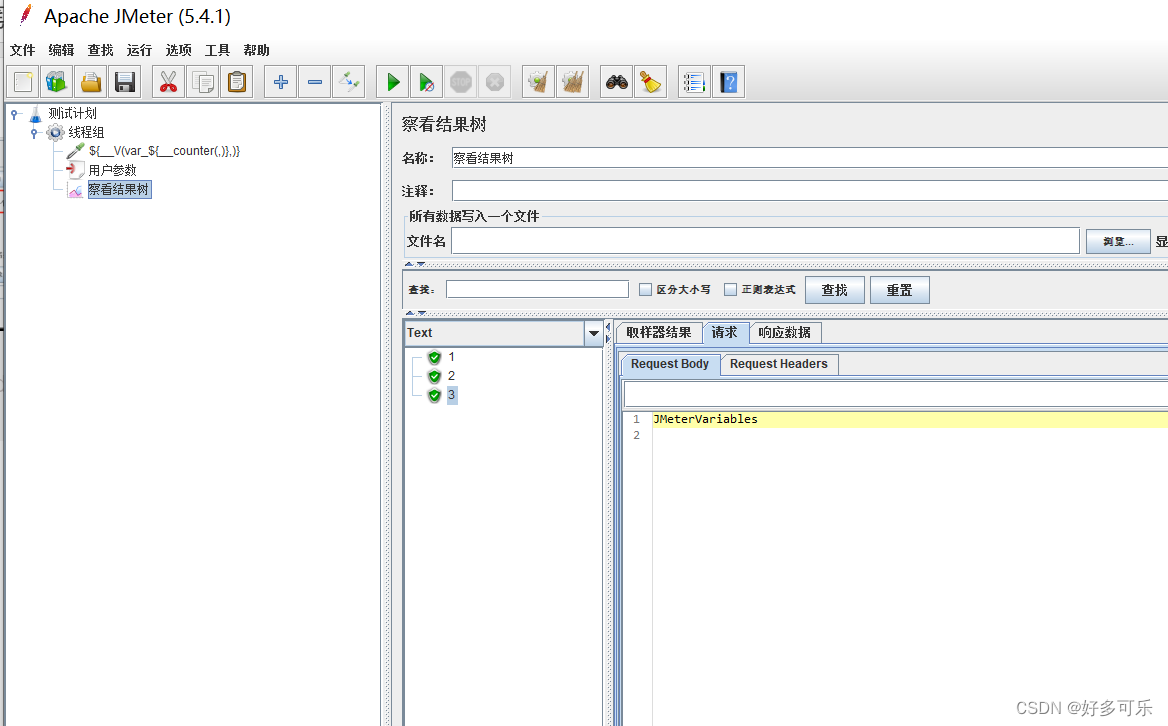
${__V(,)} 拼接函数
我们想要拼接函数的时候,比如我们要得到var_1,var_2,var_3,我们想着用拼接函数${__var_${__counter(,)}}来实现,但是实际上是不行滴。。最终结果只会是${__var_${__counter(,)}},原封不动返回给你,这个时候我们就需要用到V函数啦。正确打开方式如下: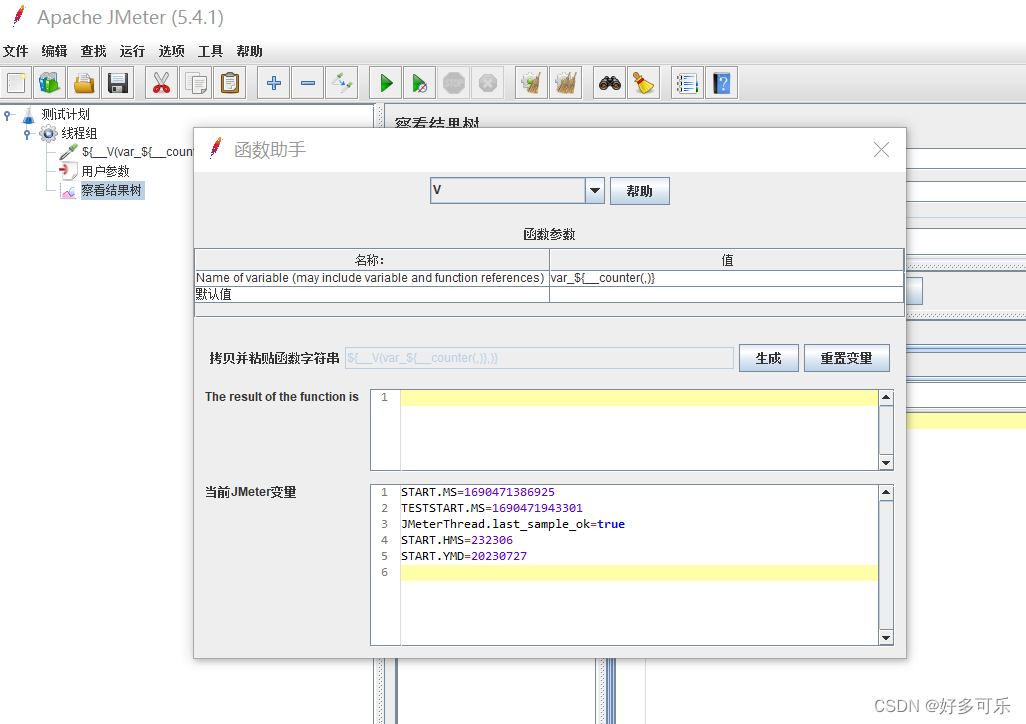
-
应用场景:
- 常用于jdbc从数据库读取数据。比如
select * from table where name like '123%‘;结果可能有多个name,我们用table_name这个变量来接收值,table_name_1,table_name_2…
- 常用于jdbc从数据库读取数据。比如
-
${变量名称}:得到的是变量的值
-
${__V(前缀_可变后缀)} :得到是这个
前缀_可变后缀变量的值 -
${__P(属性名称)}:得到的是属性名称的值
八、响应提取
-
1、json提取器
-
当确定响应信息为json格式时,推荐使用json提取器提取响应信息
-
语法:
- 1、绝对路径: .路径.二级路径
- 举例:
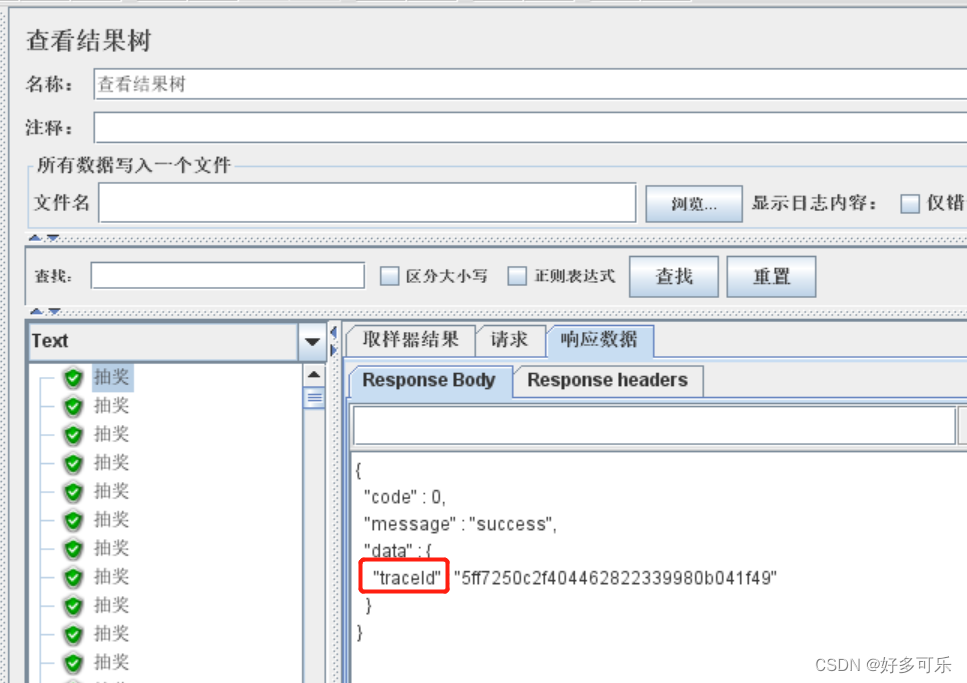
- 举例:
- 1、绝对路径: .路径.二级路径
-
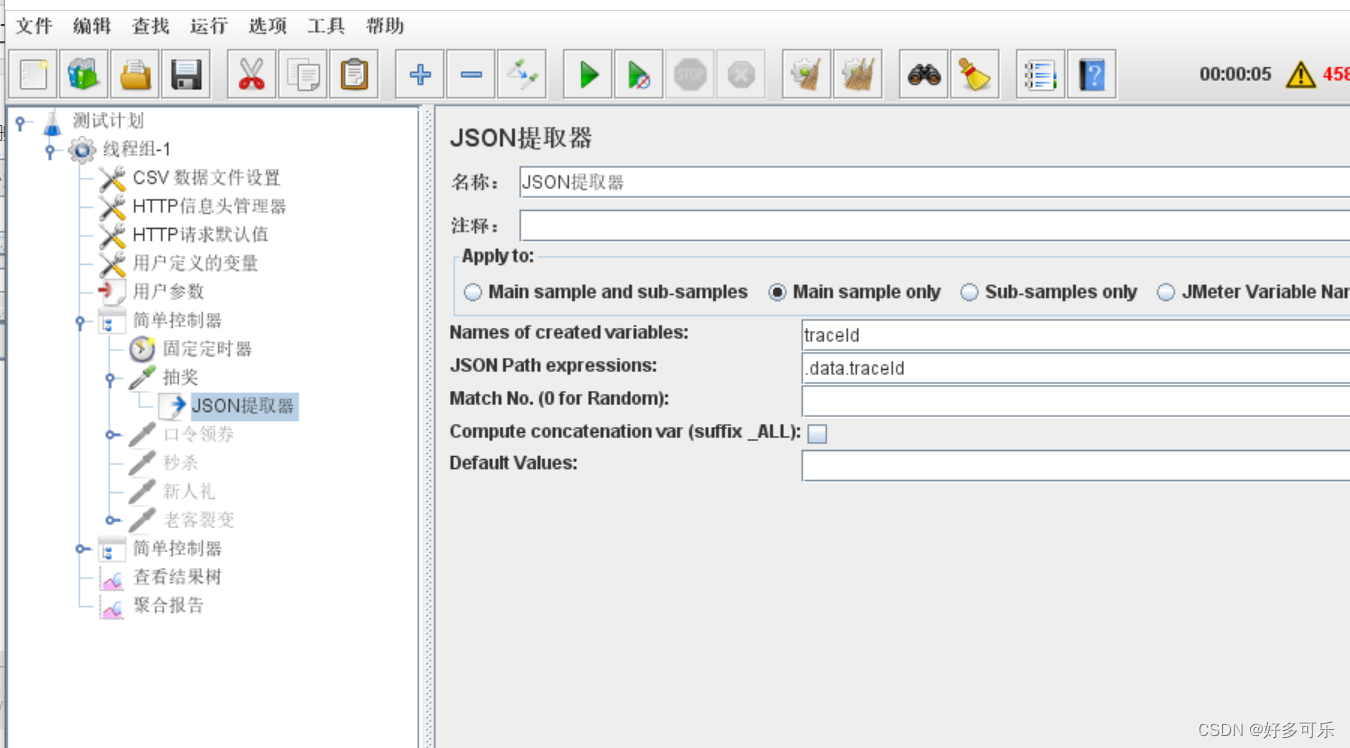
2、相对路径:$…末梢节点名称(推荐)
- 举例
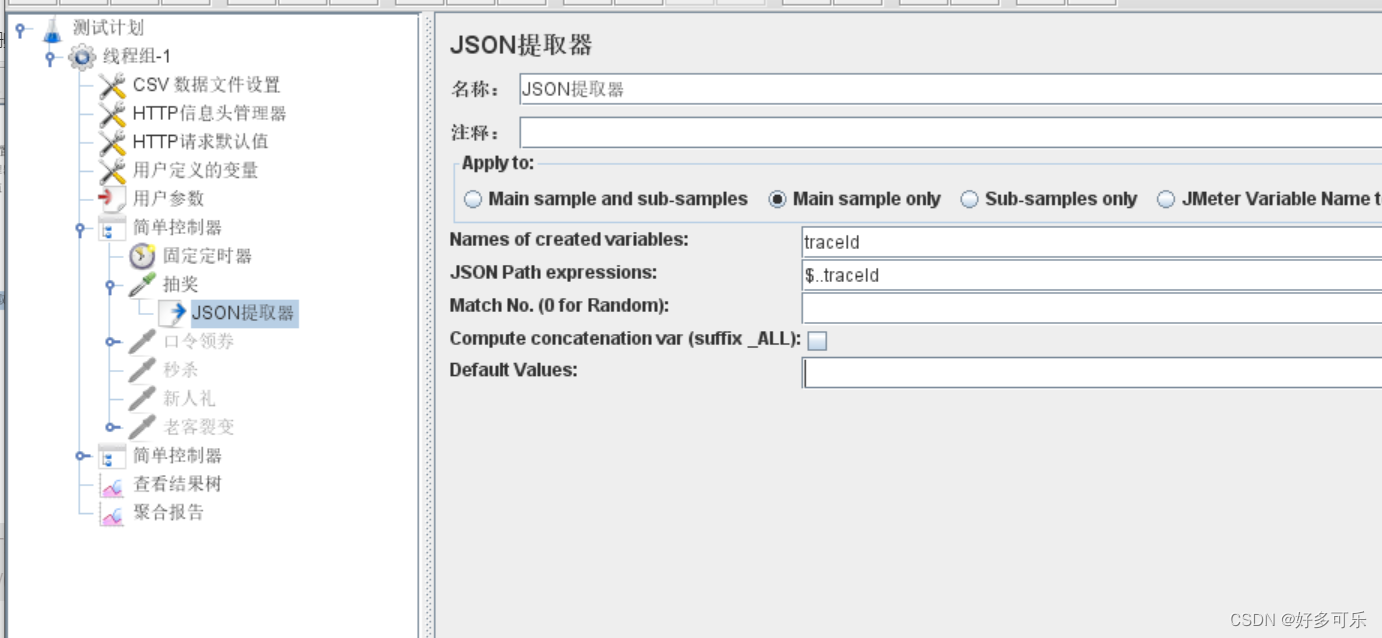
- 举例
-
添加json提取器:右键-后置处理器-json提取器
-
json中的key-value键值对是无序的
- 所以虽然我们下面是按顺序取到了,但是这也是随机的
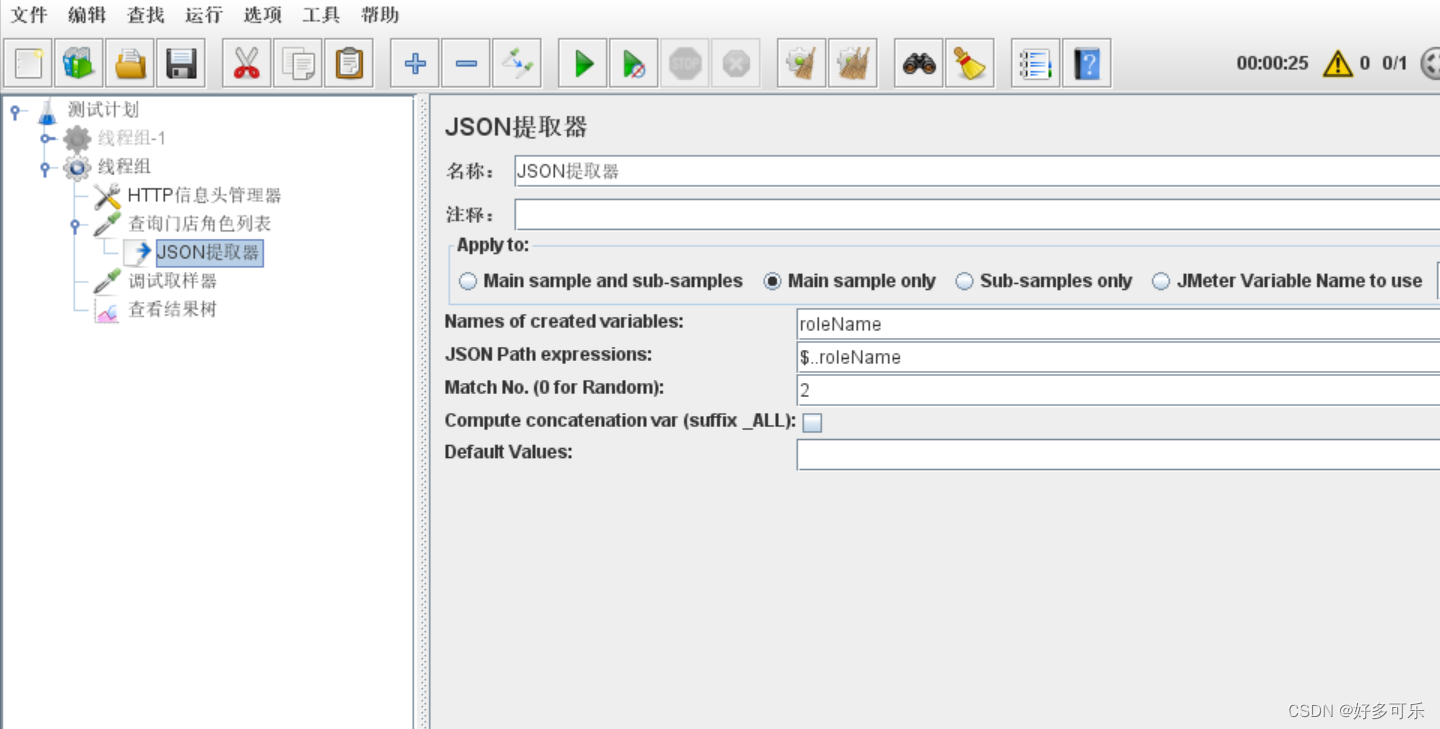
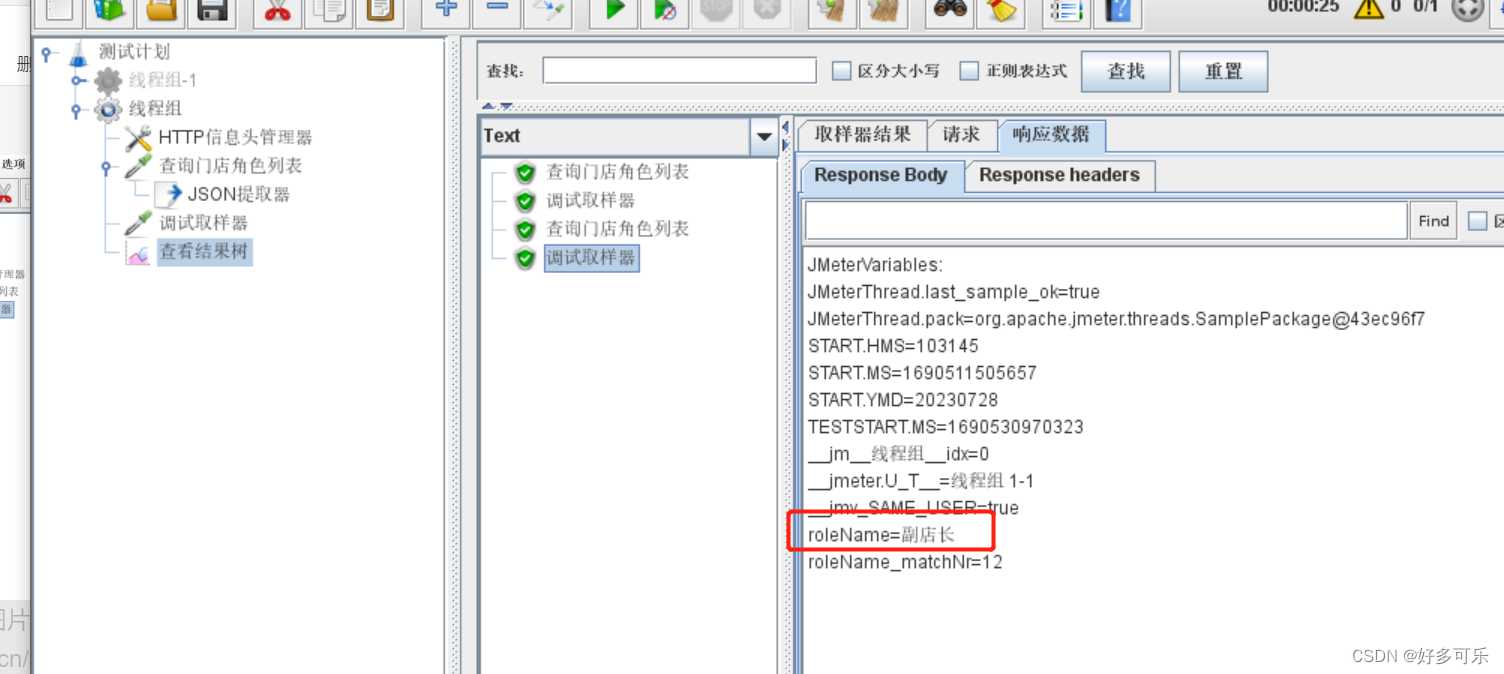
- 如果这里输入-1,返回的是所有的
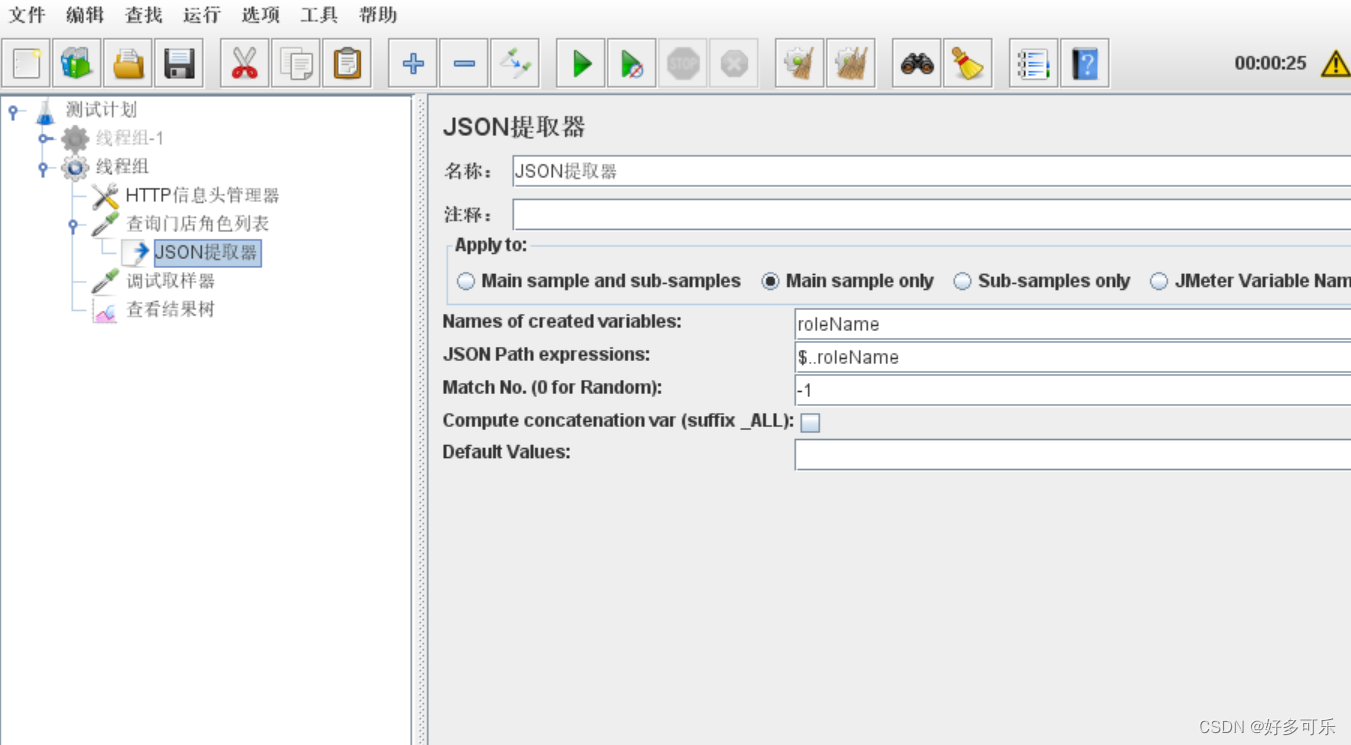
- 所以虽然我们下面是按顺序取到了,但是这也是随机的
-
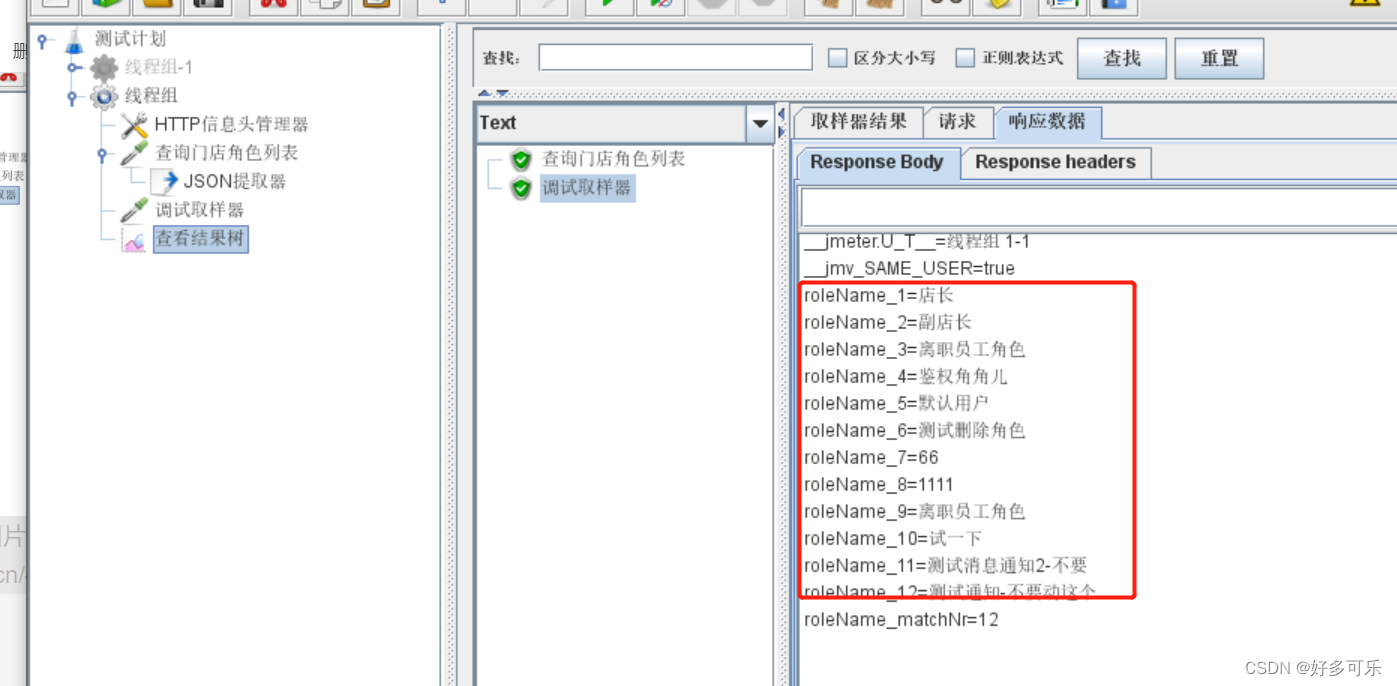
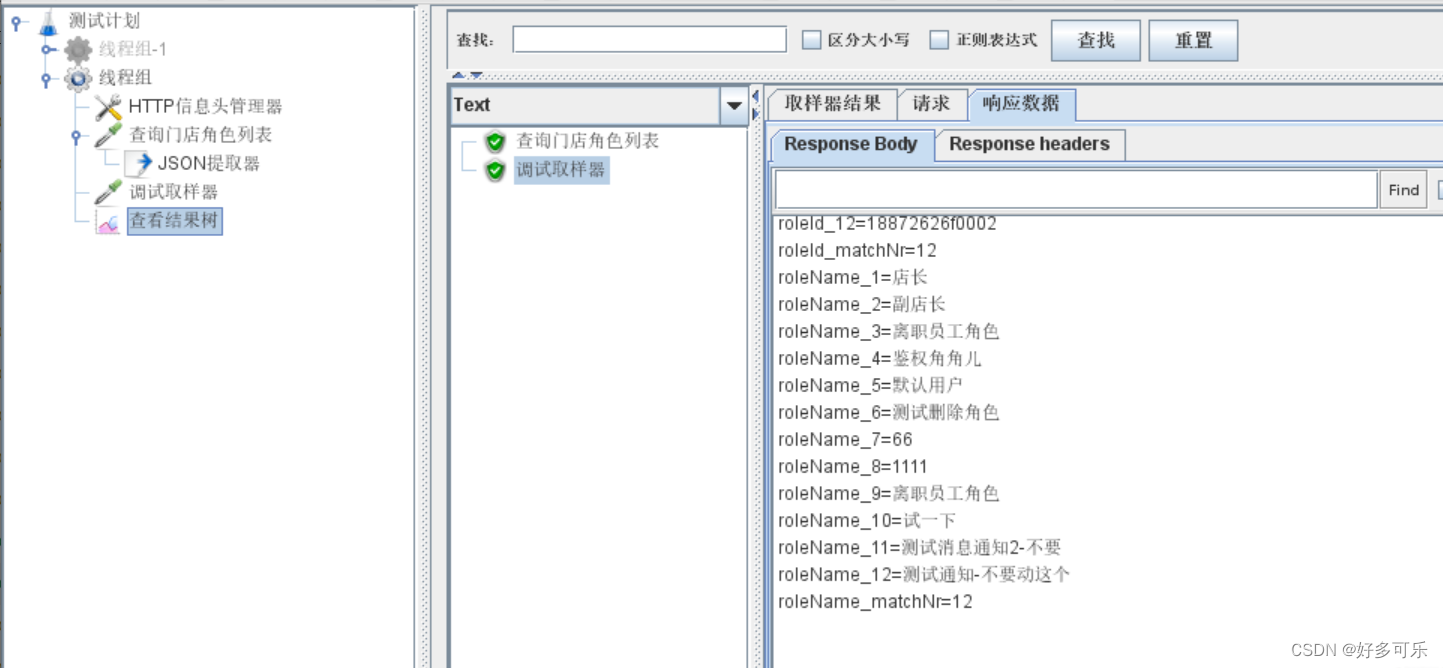
提取多个参数
- 2种方式进行提取:
- 1)使用多个json提取器(不推荐,消耗性能)
- 2) 在一个json提取器提取多个(推荐!!)记得要用分号隔开
ps:这里记得一定要写默认值,否则会报错!!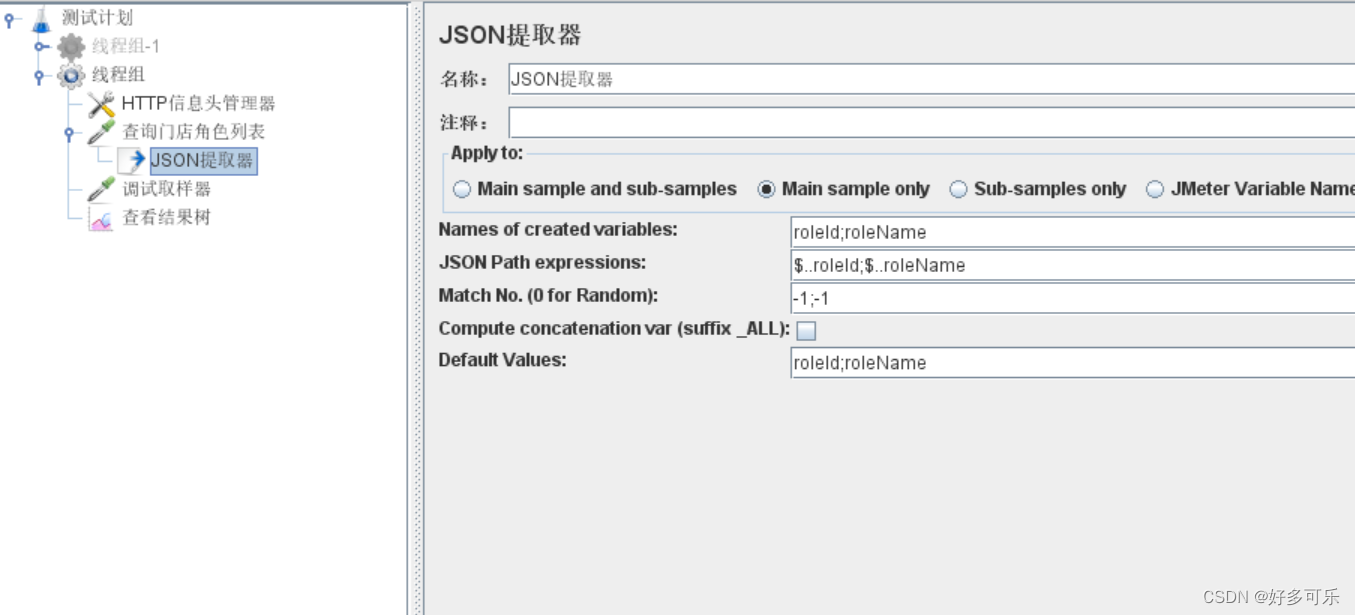
- 2种方式进行提取:
-
-
2、正则提取器
- 如果想要提取请求中的内容,响应的头部内容,或者响应体格式非json格式,推荐使用这个
- 正则提取式:左边界(正则式)右边界 万能正则式:
.*? - 可以匹配除换行符以外的所有字符
- 常用正则表达式:
| 表达式 | 含义 |
|---|---|
| . | 匹配除换行符外的所有字符 |
| * | 匹配0次或多次–贪婪匹配 |
| + | 匹配1次或多次–懒惰 |
| ? | 匹配1次或1次 |
| {m} | 匹配刚好是m个的指定字符串 |
| {m,n} | 匹配在m个以上n个以下的指定字符串 |
| {m,} | 匹配m个以上的指定字符串 |
| [] | 匹配符合[]内的字符 |
| [^] | 匹配不符合[]内的字符 |
| [0-9] | 匹配所以数字字符 |
| [a-z] | 匹配所以小写字母字符 |
| [^0-9] | 匹配所以非数字字符 |
| [^a-z] | 匹配所以非小写字母字符 |
| ^ | 匹配字符开头的字符 |
| $ | 匹配字符结尾的字符 |
| \d | 匹配一个数字的字符,和[0-9]写法一样 |
| \d+ | 匹配多个数字字符串,和[0-9]+语法一样 |
| \D | 非数字,其他同\d |
| \D+ | 非数字,其他同\d+ |
| \w | 英文字母或数字的字符串,和[a-zA-Z0-9_]语法一样 |
| \w+ | 和[a-zA-Z0-9_]+语法一样 |
| \W | 非英文字母或数字的字符串,和[^a-zA-Z0-9_]语法一样 |
| \W+ | 和[a-zA-Z0-9_]+语法一样 |
| \s | 空格,和[^\n\t\r\f]语法一样 |
| \s+ | 和[^\n\t\r\f]+语法一样 |
| \S | 非空格,和和[^\n\t\r\f]语法一样 |
| \S+ | 和[^\n\t\r\f]+语法一样 |
| \b | 匹配以英文字母,数字为边界的字符串 |
| \B+ | 匹配不以英文字母,数值为便捷的字符串 |
- demo:
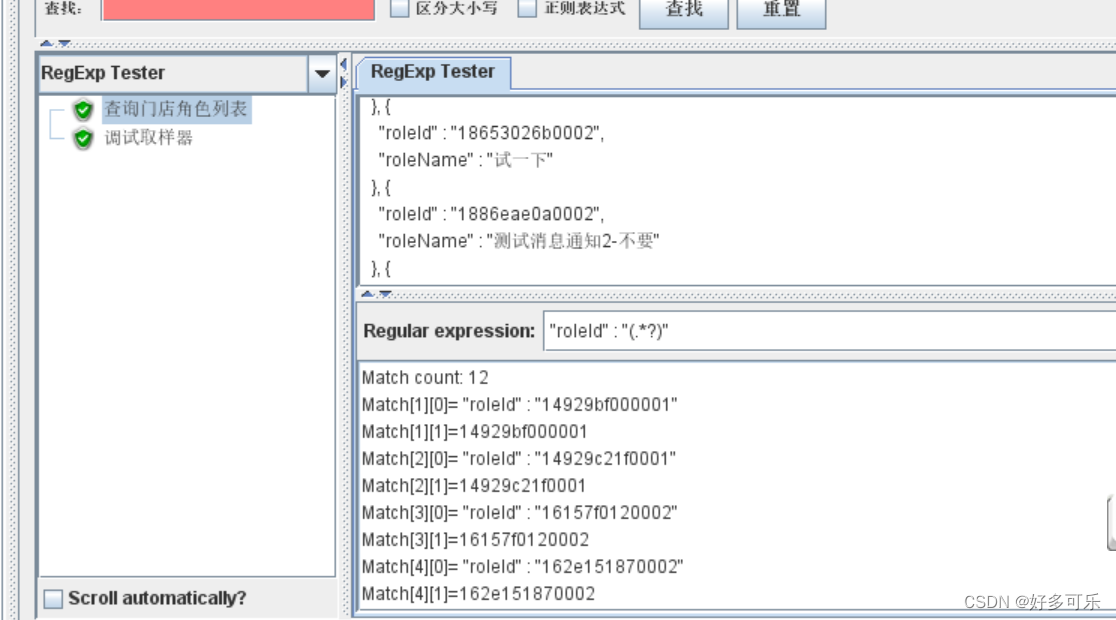
- 使用正则表达式
模板:两个$是固定写法,中间加上数字,从1开始,代表取第一个括号,以此类推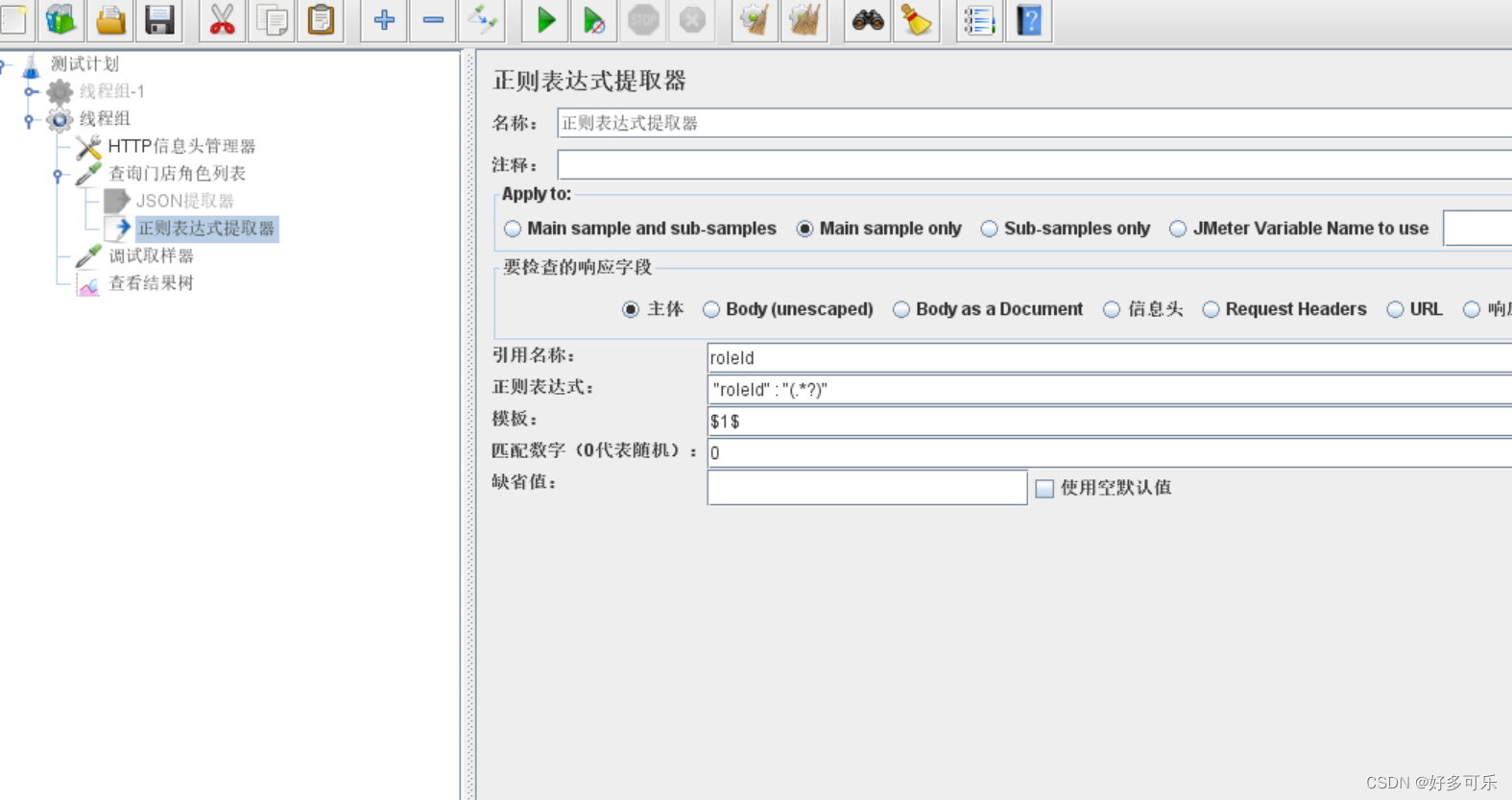
- 当然也可以引用多个
- 提取
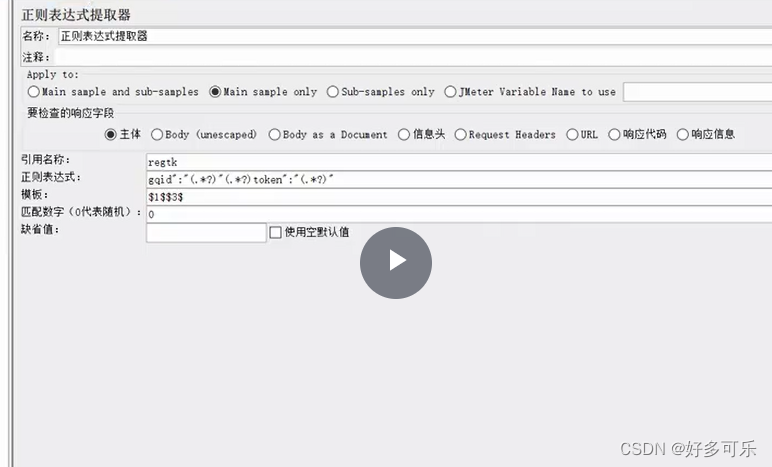
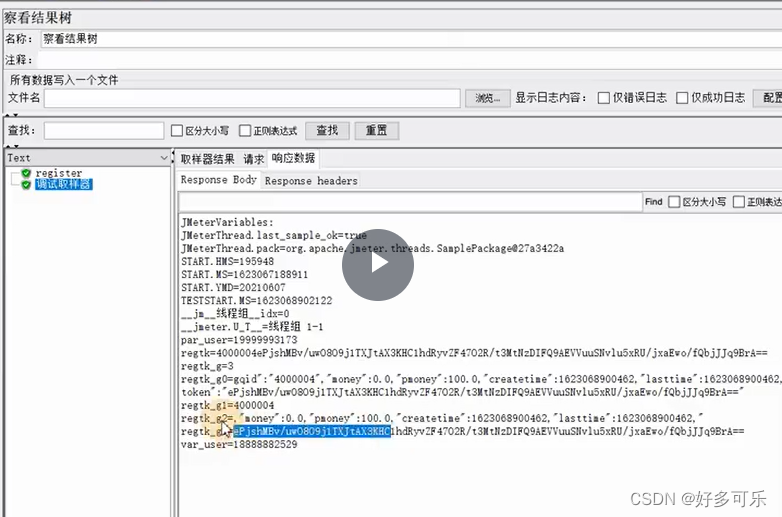
- 引用
- 提取
九、关联
- 前面接口的动态数据信息,提取出来,作为后面接口的传入参数
- 当接口,使用cookie来管理信息时,请使用cookie管理器,而且,第一次使用时,不要去修改任何cookie管理器信息。
- 只要使用到登录接口,以及登录之后才能使用的接口,就添加cookie管理器。不管你的项目是否使用cookie。
- 使用默认的cookie管理器,先不要去配置如何信息。
十、DDT数据驱动性能测试
-
性能测试,因为要使用多用户并发,请求的时间也要几分钟到几十分钟,所以总请求量,可能会很大。
- 准备测试数据
- 测试数据文件
- 准备测试数据
-
最典型的应用: 使用一批测试账号登录
- 把一批测试账号,放在一个纯文本文件中管理。
- 文本文件:txt,csv,json,xml,yml等
- 把一批测试账号,放在一个纯文本文件中管理。
-
csv数据文件设置
- 用csv来准备数据,能用csv数据文件设置时,坚决不用 ${__CSVRead(,)}函数(只能将就着用,功能不如csv数据文件设置齐全)
- 支持的文件: 文本文件, 不局限于 txt,csv
- 配置元件
- 注意事项:
- 1、文件名称:可以是txt、csv等文本文件,但推荐使用txt,能不用csv,就不用csv,原因如下:
- 1)获取速度txt相对要快
- 2)编码:txt文件,默认编码,utf8; csv文件,默认编码,不是utf8
- 因为csv文件,默认不是utf8格式,使用,在文件中包含中文时,使用其中的数据,会出现中文乱码
- 如果工作中,看到jmeter读取csv文件内容出现乱码:
- 原因:csv的编码不是utf8,而csv数据文件设置中,如果选择了utf8,会导致编码不一致
- 解决方案:把csv文件,用记事本打开,选择编码为utf8保存
- 默认使用的是绝对路径,当路径出错时,会导致整个线程组,都不执行,那要怎么处理呢?
- 解决方案:
- 使用相对路径:
-
相对点: 默认是jmeter的bin文件夹,也可以是jmeter脚本的保存路径。(建议把jmx文件与数据文件放在同一个路径下。如果csv文件路径出错,会导致当前整个线程组无法运行)
-
2种写法:
-
./ 开头 跟上相对路径,这种写法可以支持跨平台,放在不同操作系统都可以正常运行(推荐)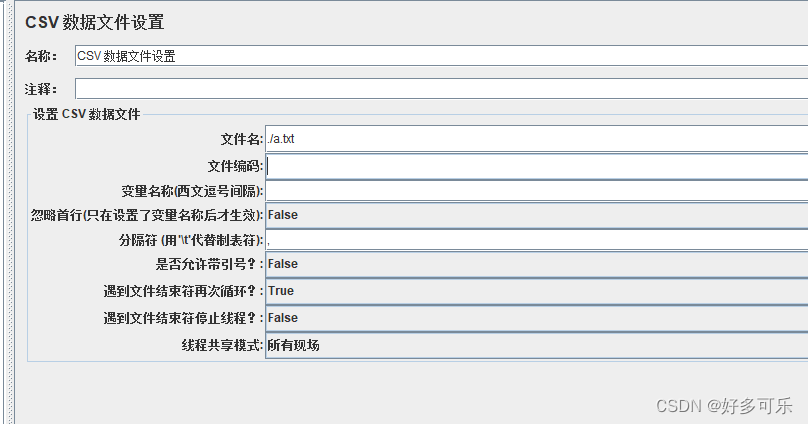
-
- 直接写文件名称(如果你的jmx文件存的是在jmeter默认的bin路径下)
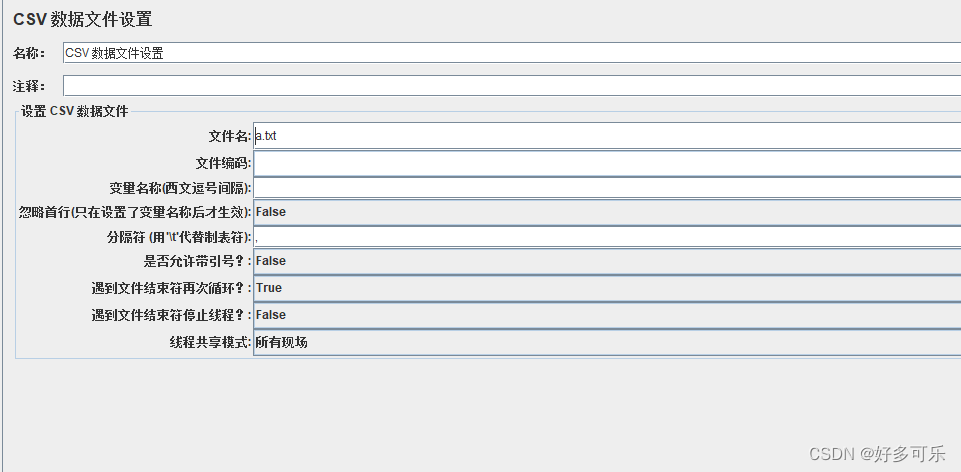
- 直接写文件名称(如果你的jmx文件存的是在jmeter默认的bin路径下)
-
- 使用相对路径:
- 解决方案:
- 2、变量名称: 可以写多个,多个之间用逗号隔开
- 3、是否允许带引号: 一对英文双引号
- 4、 遇到文件结束符再次循环
- 用来管理取值的情况
- true: 运行次数超过总数量行数时,会从头开始取值
- False:运行次数超过总数量行数时,还会继续运行,但是取不到值
- 5、 遇到文件结束符停止线程
- 用来管理运行状态的
- 如果为true,且在线程共享模式设置所有线程时,无论你设置多少个线程,假设是循环10次,但是你文件里只有6条数据,那无论如何就只跑6次(就像你请客吃饭,请了10个人,但是桌上只有6付碗筷,那只有6个人可以吃饭)
- 如果为false,且在线程共享模式设置所有线程时,假设是10个线程,循环10次,数据有10条,那么就会跑100次,但是有数据的只有前6条
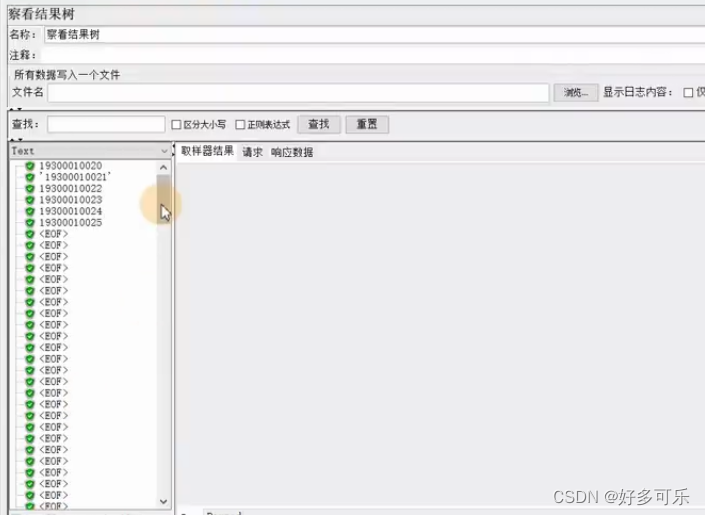
- 6、 线程共享模式
- 所有线程:所有线程按顺序取文件行
- 当前线程组:所有线程组中的线程按顺序取行
- 当前线程
- 使用csv数据设置,默认配置情况下
- 当使用多并发时,
- 第一个用户,第一次取值,取第一行,
- 第二个用户,第一次取值,取第二行
- …
- 1、文件名称:可以是txt、csv等文本文件,但推荐使用txt,能不用csv,就不用csv,原因如下:
十一、逻辑控制器
-
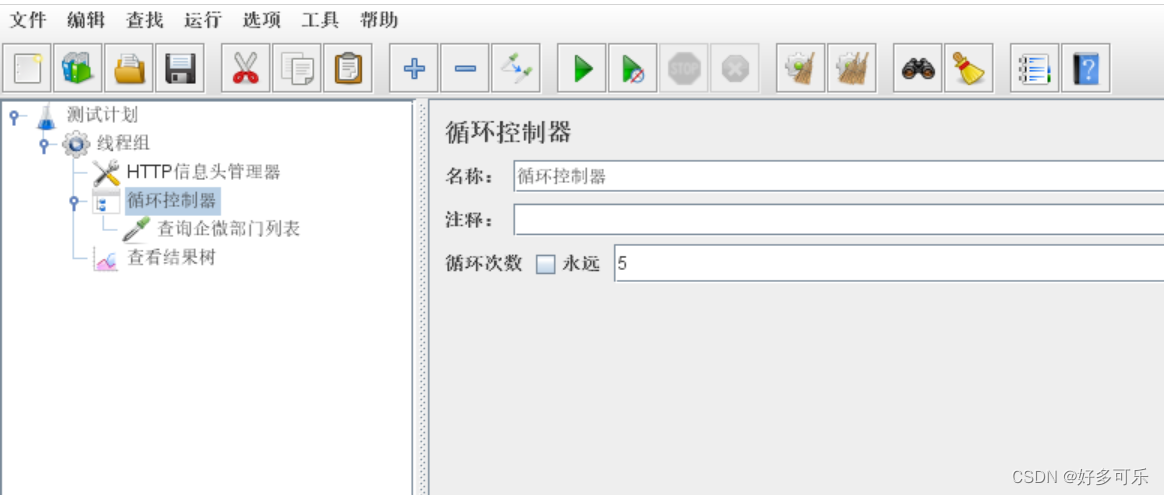
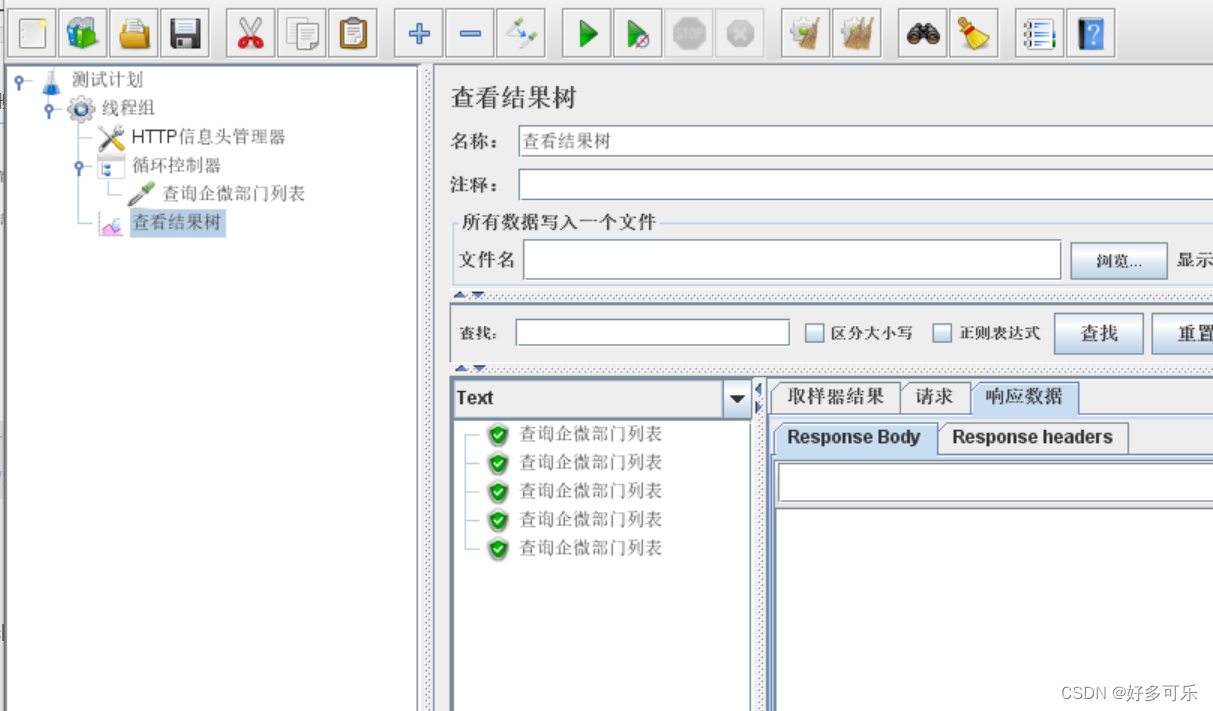
1、循环控制器
- 常用于重复运行多次的场景
- 添加控制器:逻辑控制器-循环控制器
- demo:
-
2、foreach控制器
- 常用于带下划线的变量引用
- 我个人理解有点像java的for循环?
- demo
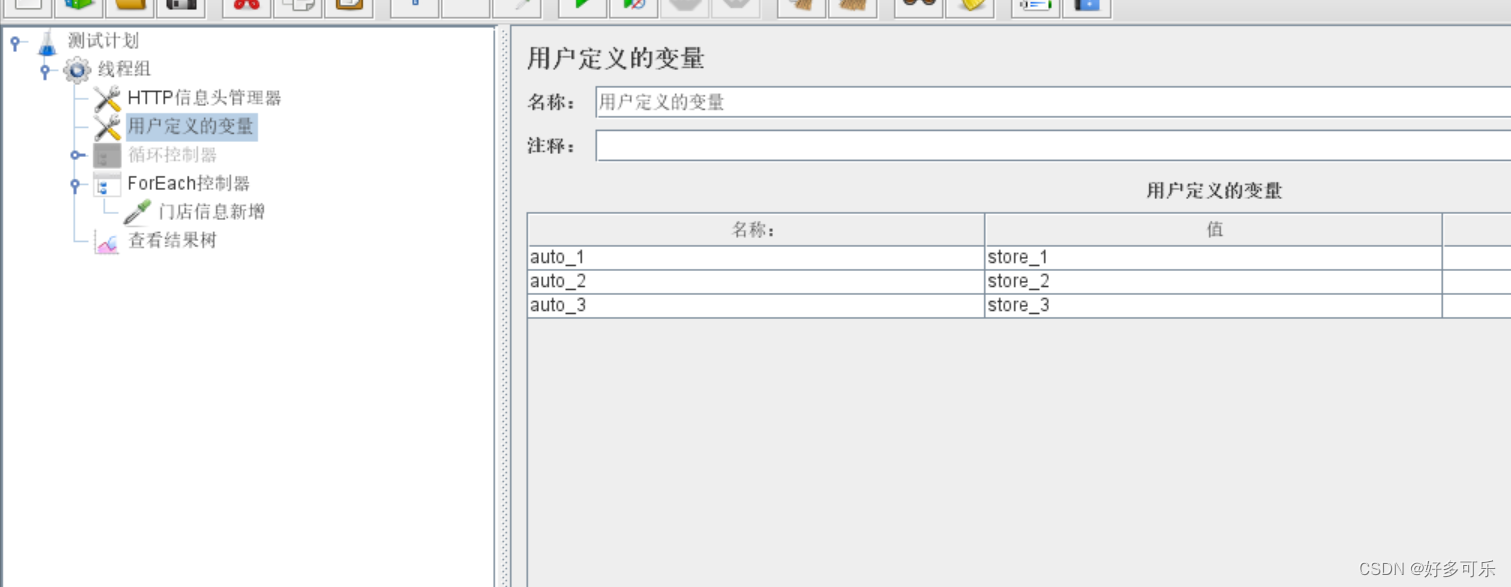
- 1,添加一个foreach控制器,控制循环3次,然后勾选数字之前加上下划线,这样设置后变量名称就变成auto_1,auto_2,auto_3
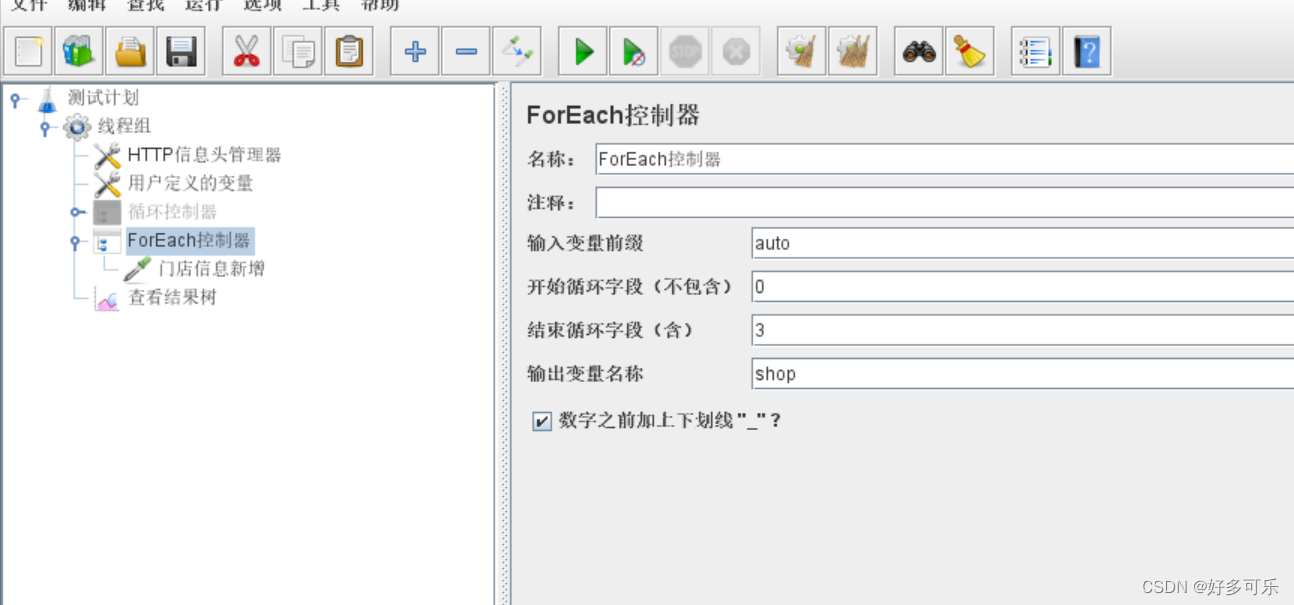
- 2、添加用户定义变量,设置auto_1=store_1…
- 3、demo里引用,之前那边引用名称设置成shop,所以这里用
${shop}进行引用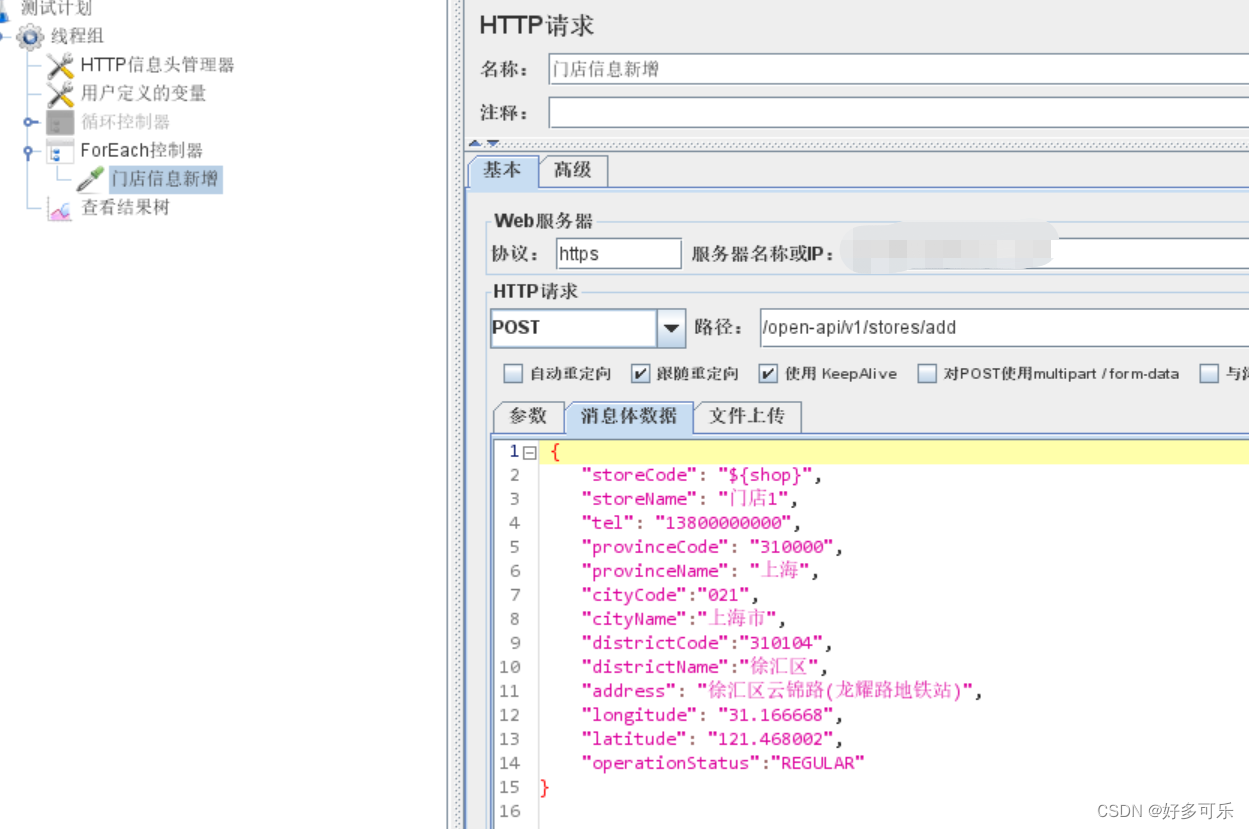
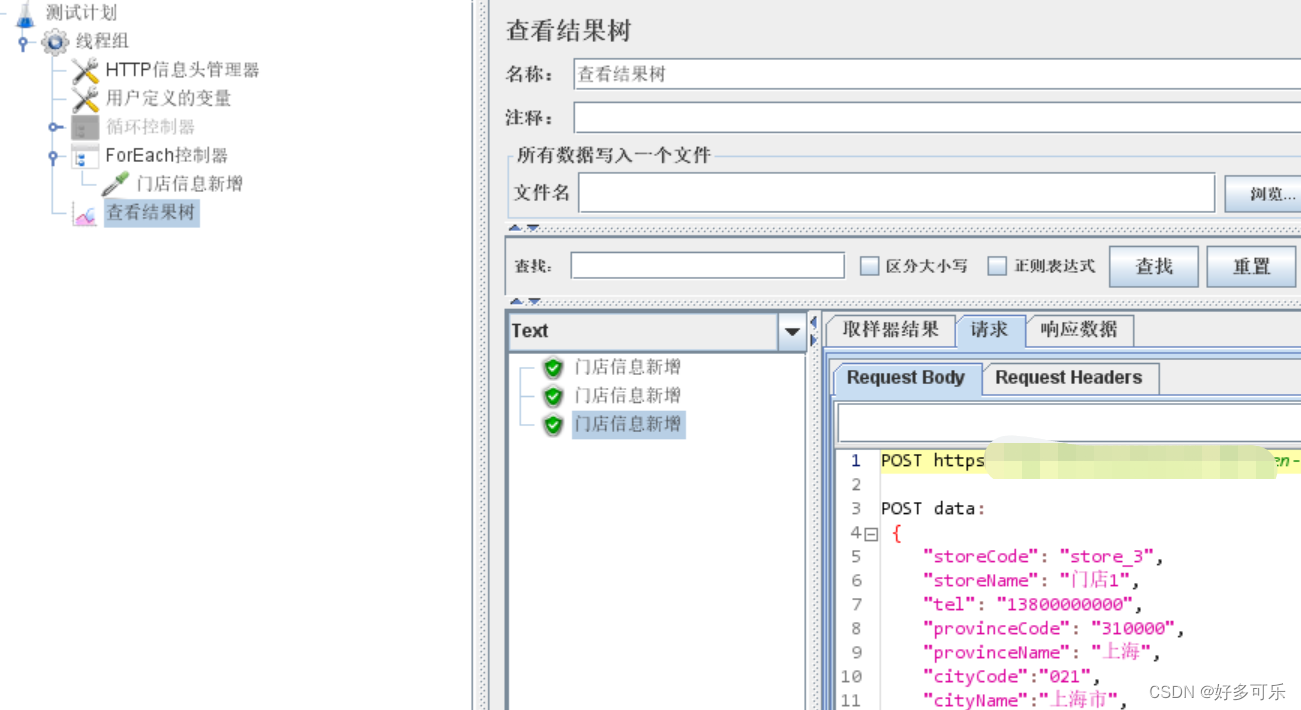
- 4、查看结果,发现循环了3次
- 1,添加一个foreach控制器,控制循环3次,然后勾选数字之前加上下划线,这样设置后变量名称就变成auto_1,auto_2,auto_3
- 那循环控制器可以实现foreach控制器类似功能吗?当然可以,我们可以用计数器+函数来实现类似功能,如下:
- 1、 添加计数器
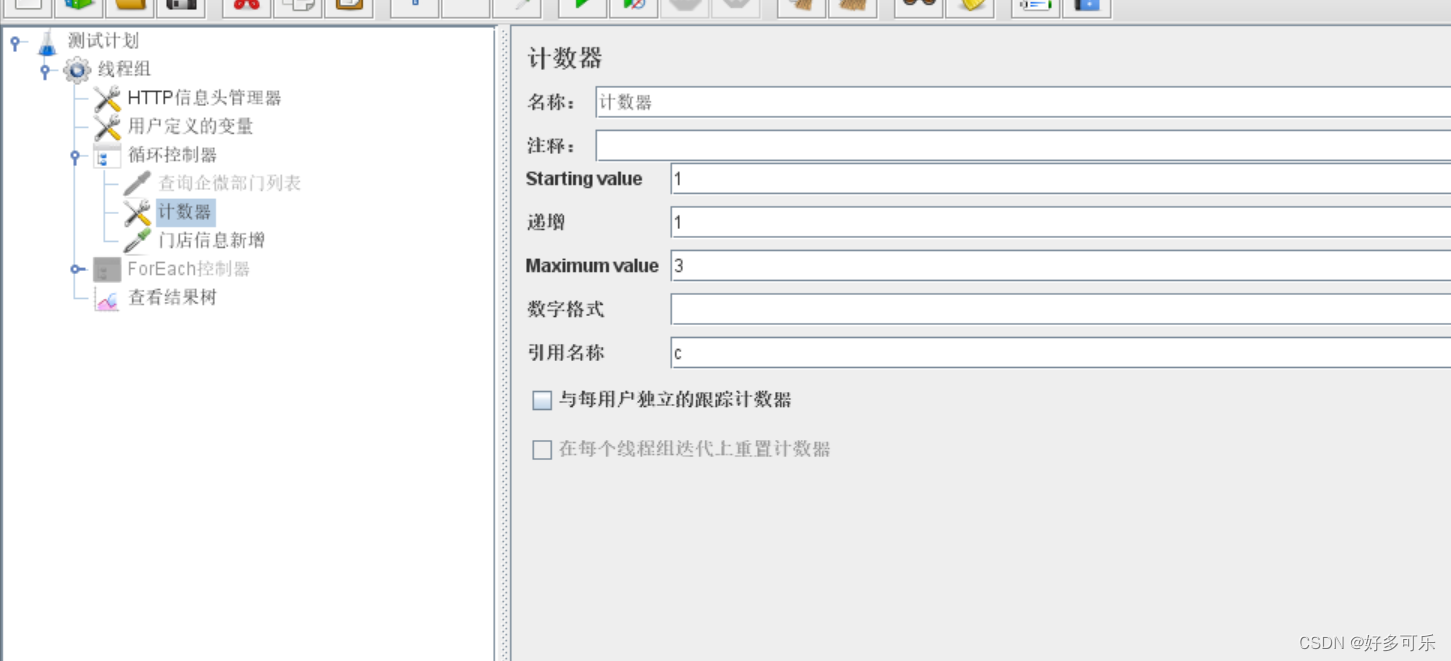
- 2、函数助手,选择V函数,配置如下:
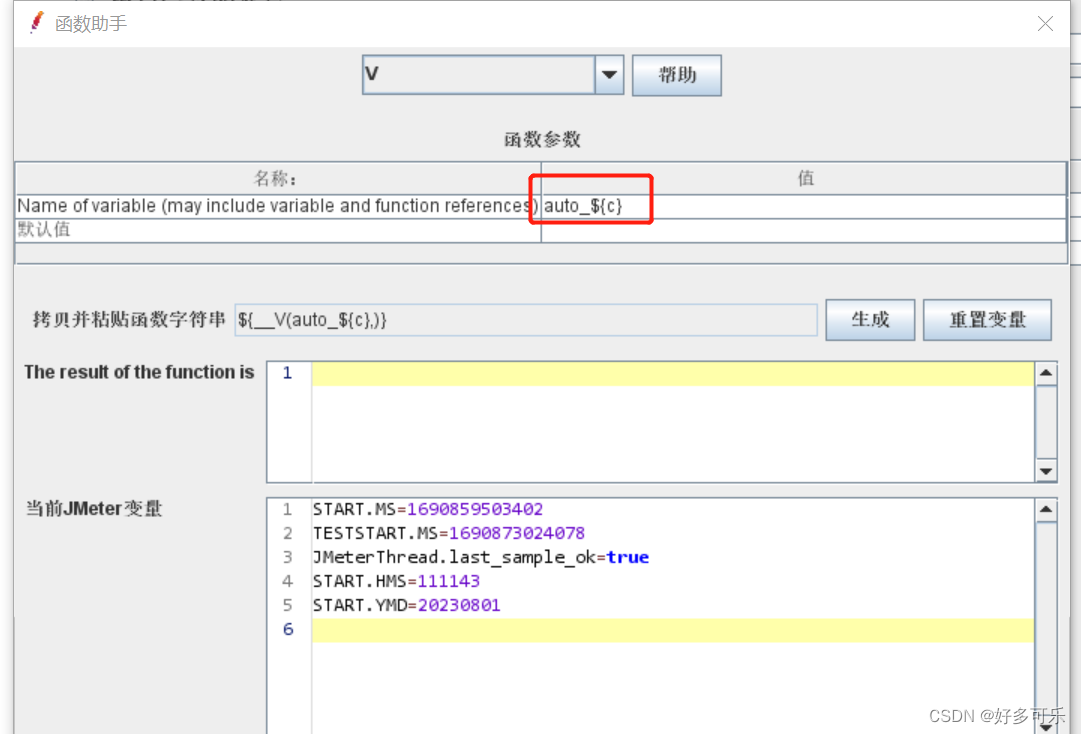
- 3、引用变量
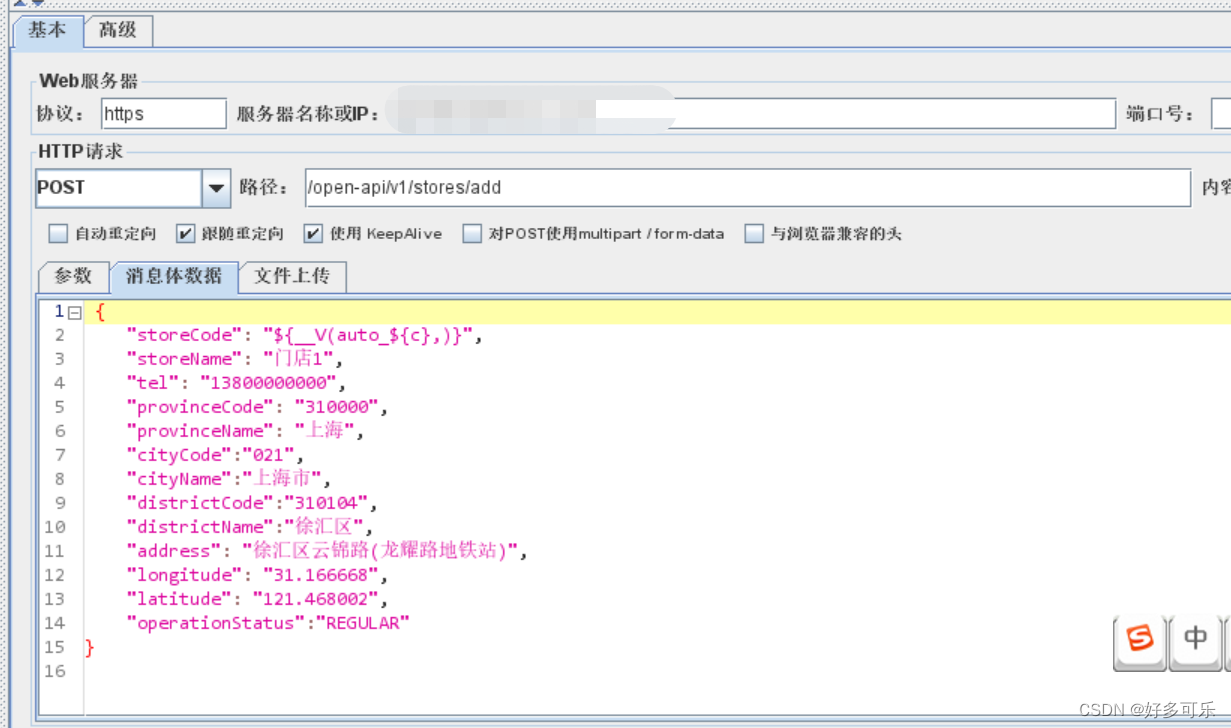
- 4、用户自定义变量同之前
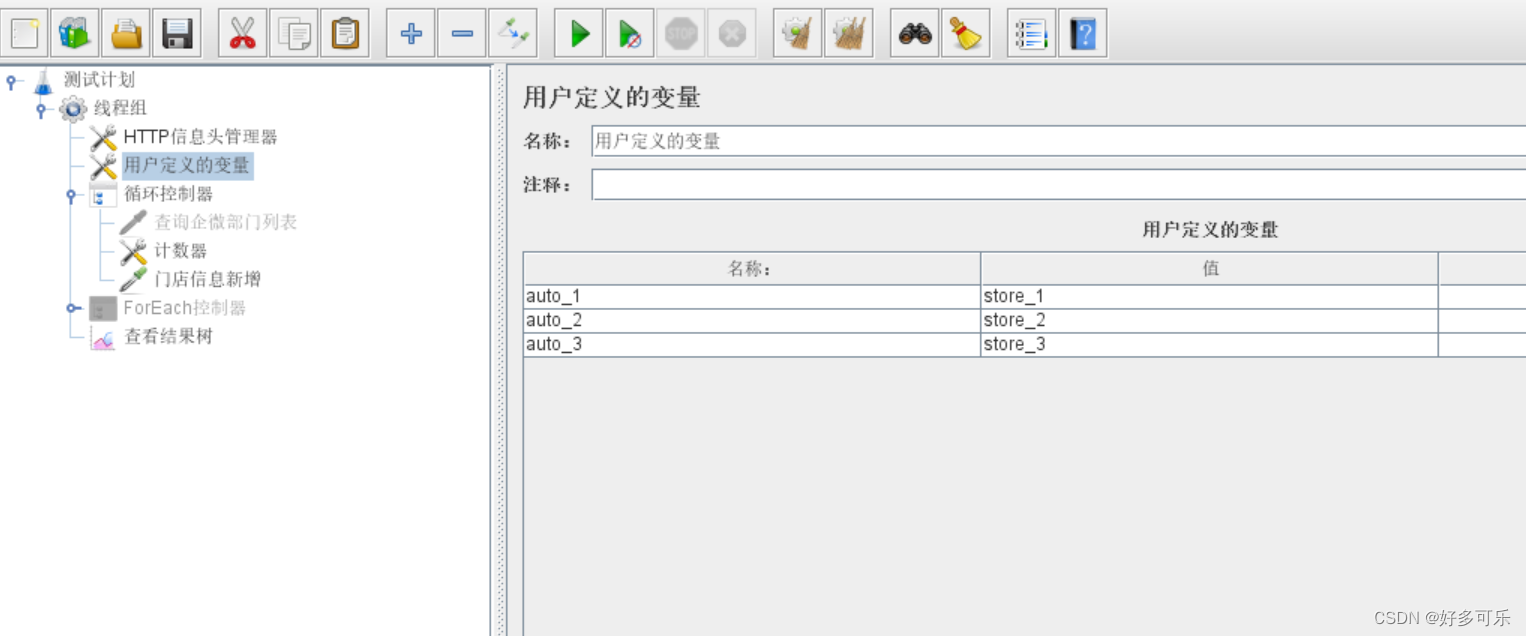
- 5、然后跑起来吧。通过auto_xxx,找到自定义变量对应的值,然后传入
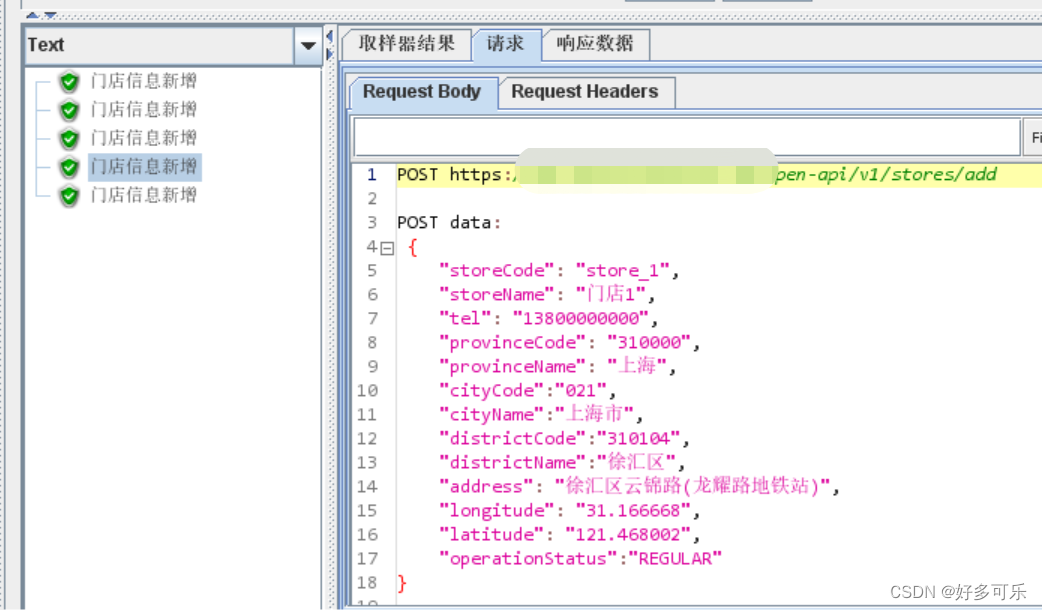
- 1、 添加计数器
-
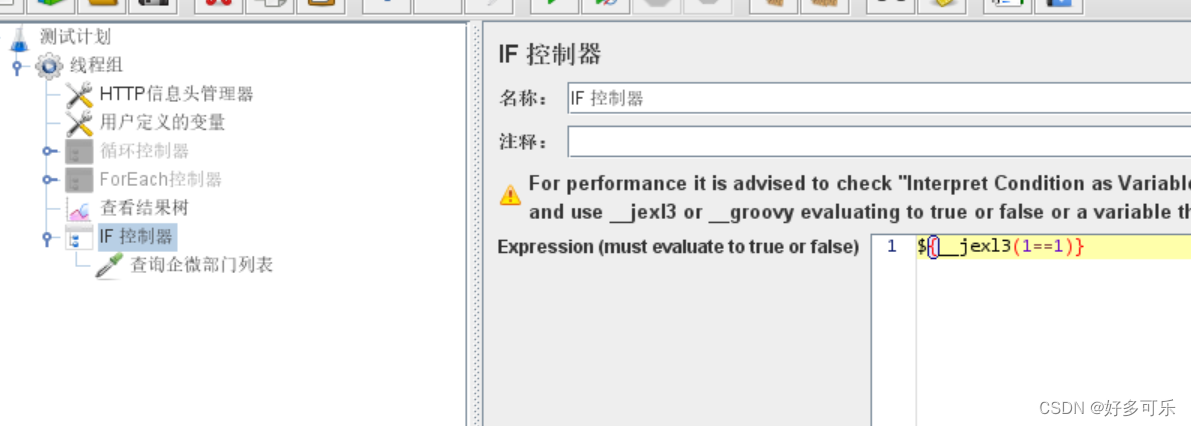
3、if控制器
- 默认情况下,条件框中需要使用 __jexl3或是 __groovy函数
- 如果不勾选interpret condition as variable expression,把条件框中的表达式当做js来计算,计算结果为true,则继续执行脚本,否则不执行
- 如果脚本一定要使用beanshell,这边推荐用jexl3函数,性能更好,然后也能实现相关功能
- demo
- 判断当1==1时,结果为true,所以执行了
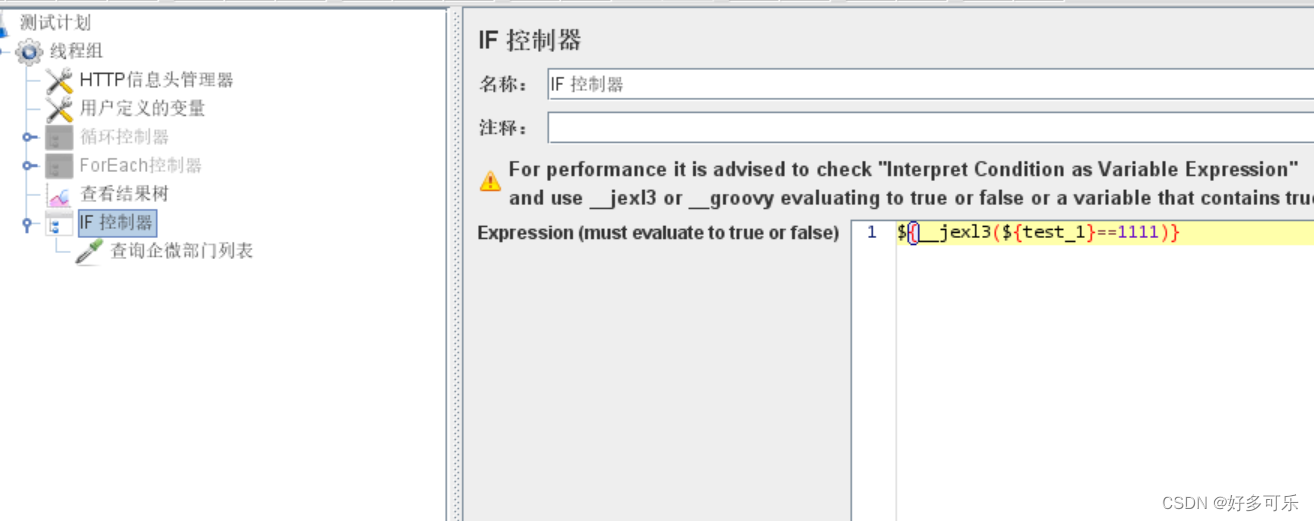
- 也支持变量的引用
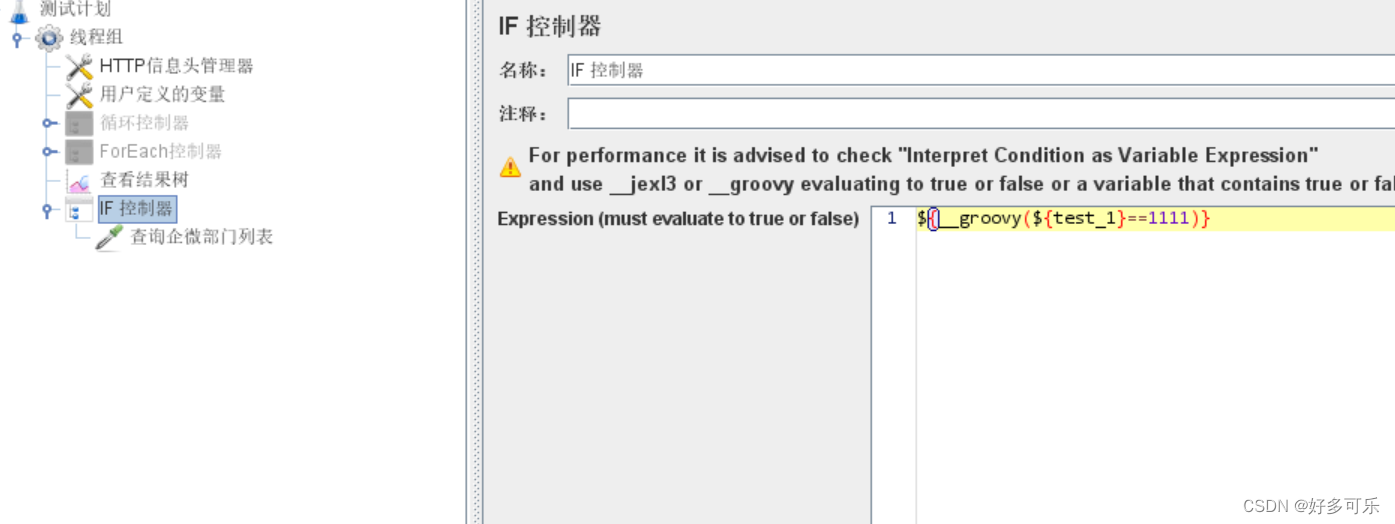
- 也可以使用groovy脚本
- 去掉这个的时候,默认使用js
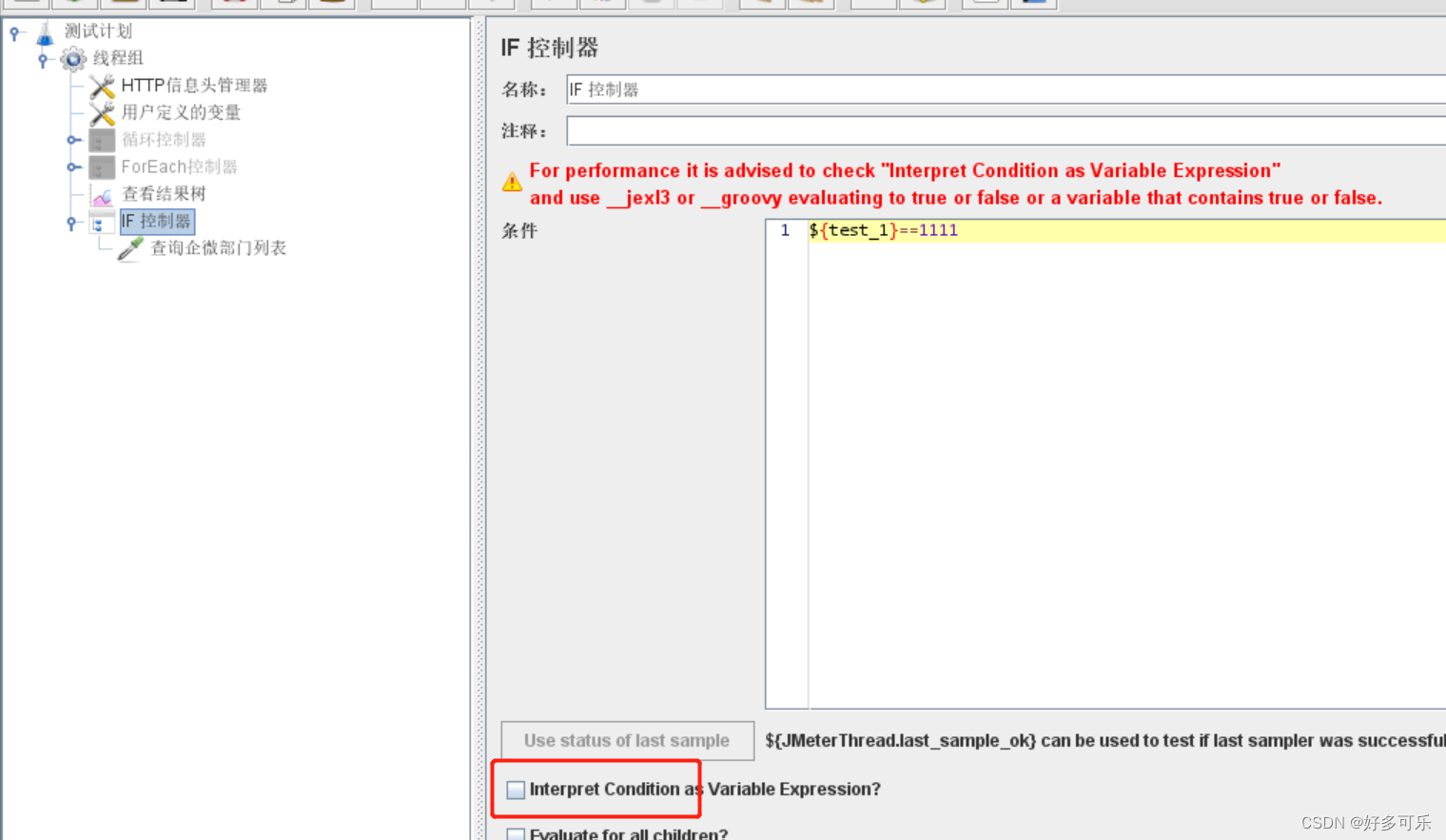
- 判断当1==1时,结果为true,所以执行了
-
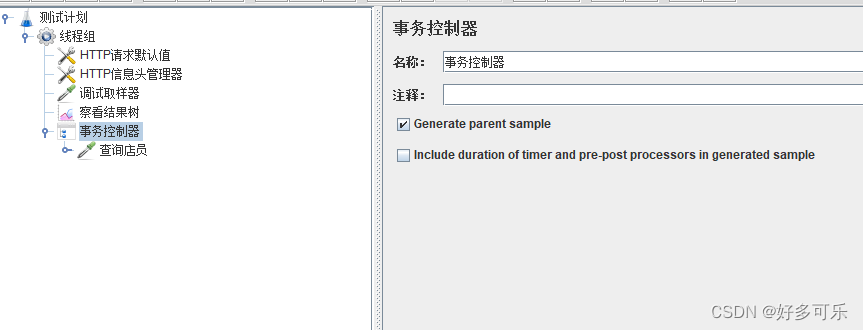
4、事务控制器
- 在jmeter中,默认一个取样器,就是一个事务
-
事务控制器,控制其子集取样器(n),合并为一个事务
- 事务: TPS 服务器每秒处理的事务数
- 在事务控制器下,挂载多个取样器,想要把多个取样器合并为1个事务,必须勾选“Generate parent sample”
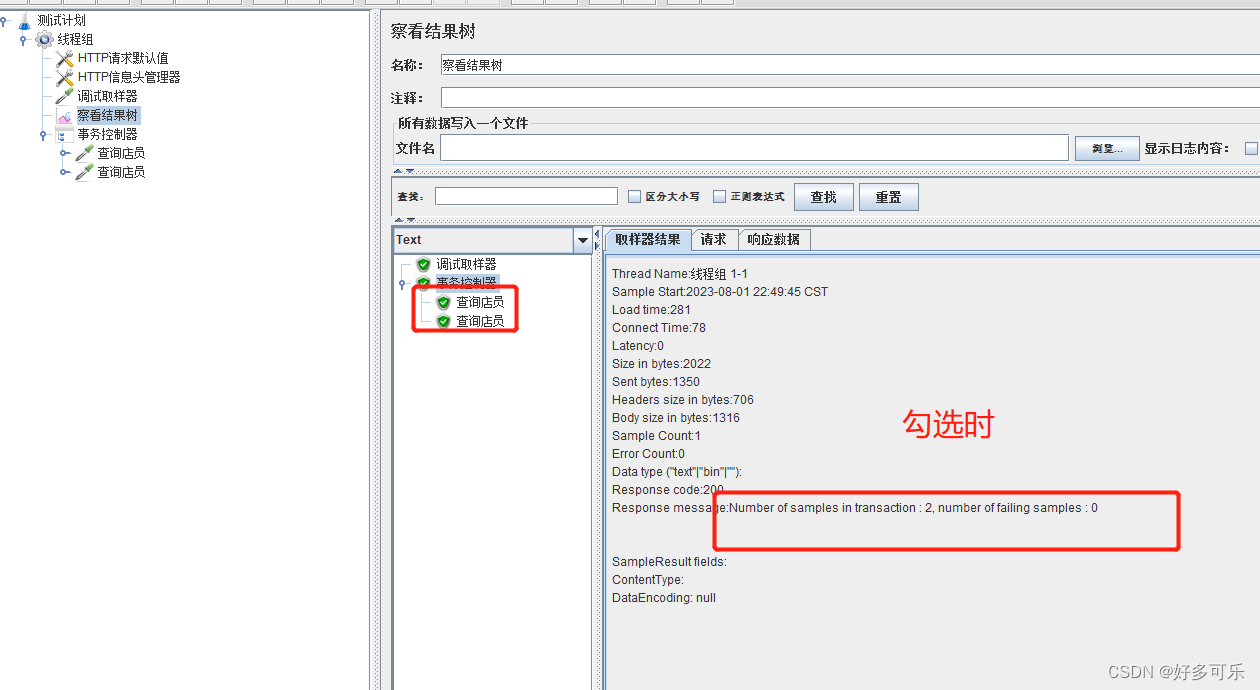
在聚合报告只展示1个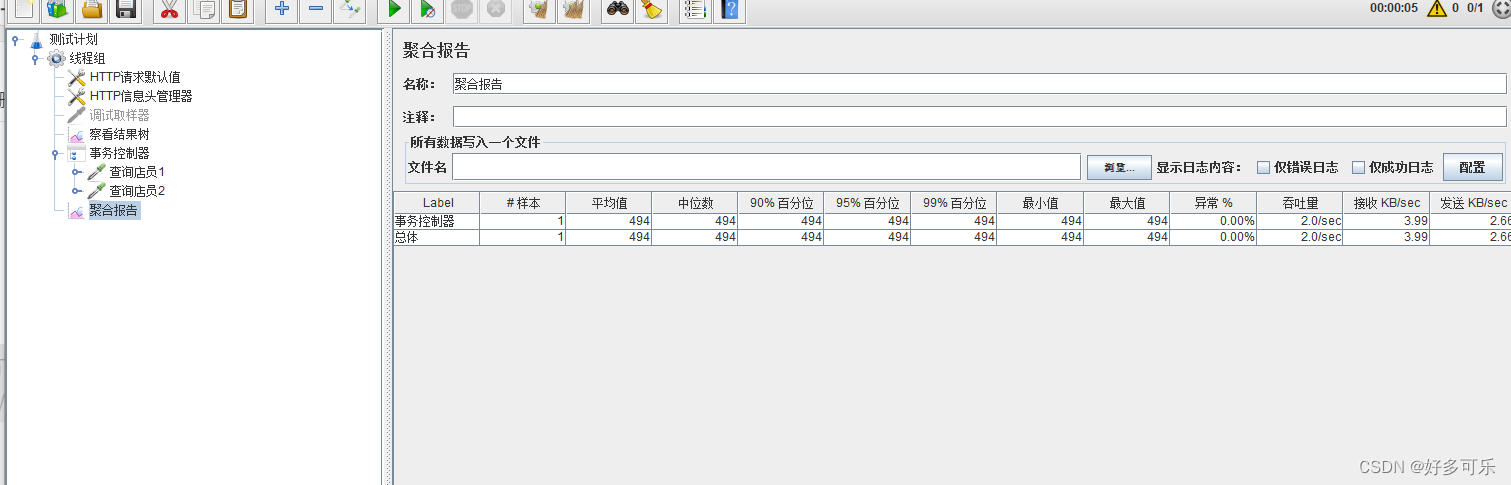
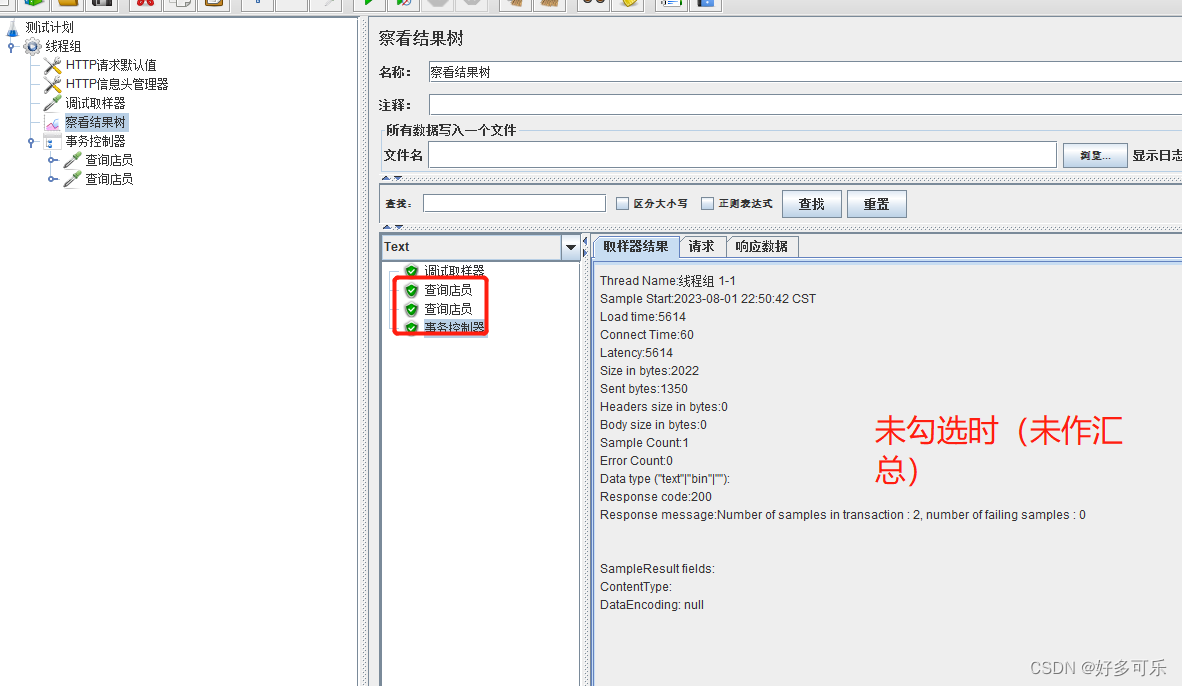
在聚合报告展示多个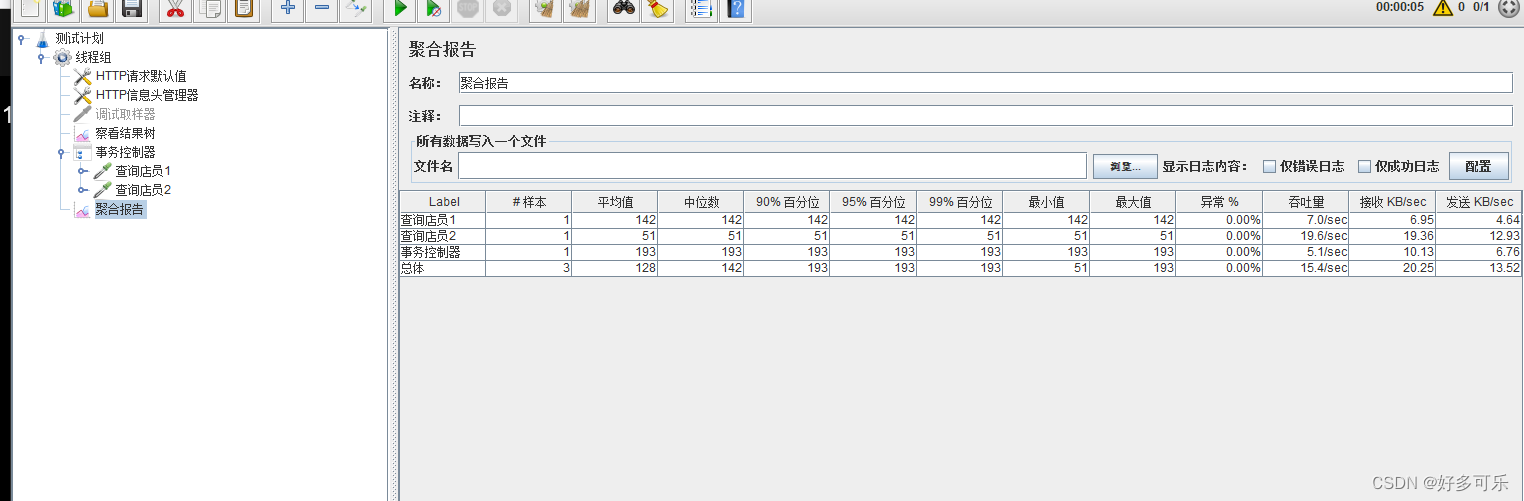
-
性能测试中,是否要勾选“Generate parent sample”?
- 性能测试,要先做单接口的性能测试,然后再做多接口的性能测试。
- 在做多接口合并的时候,需要勾选。
- 在性能测试中, 需要先用单个取样器,做出某个接口的性能测试指标,然后再出多个接口的性能指标, 然后再使用事务控制器,勾选Generate parent sample,做出业务的性能指标, 把所有 业务都出来,再合并,做出整个系统的性能指标
- 如果领导要你做某个业务的性能指标,哪你需要先梳理出这个业务所有的接口,然后对这个业务所有的接口进行性能测试,得到性能指标,然后,再使用事务控制器,合并取样器,最终才得到 业务的性能指标。
- 真正做性能测试时,所有的监听器,都要禁用
-
聚合报告\汇总报告
- 在性能测试中,看聚合报告,有前提条件:
- 1、没有网络瓶颈
- 因为,在很多时候,我们在看聚合报告时,会把 吞吐量的值 等价为 TPS的值(因为如果遇到网络问题,即使通信顺畅也传不过来)
- 怎么判断有没有网络瓶颈?
- 聚合报告最后两列(接收/发送数据/s),就是吞吐率(每秒传输多少kb)。 吞吐率与我们的带宽是有关系,所以看这个可以看出是否存在网络带宽问题。我们只需要对比带宽的值和实际的值,如果实际的值比带宽的小,则表示不存在网络瓶颈。
+目前带宽里, 20Mb (民用带宽最低标准) 100Mb(目前主流)- 首先我们算出:1Mb = 1 x 1024kb -> 1024kb/8 = 128KB/s(kb转KB),128KB/s是理论上的最大值
- 然后我们对照聚合报告的值:远远低于这个数,所以判断不存在网络瓶颈

- 当然带宽也分为上行和下行,企业的上行比较宽,下行会窄一些。民用级的则相反(可以简单理解成发出去是上行,收到的是下行)
- 企业服务器,一般电商类的产品,也就几m带宽
- 聚合报告最后两列(接收/发送数据/s),就是吞吐率(每秒传输多少kb)。 吞吐率与我们的带宽是有关系,所以看这个可以看出是否存在网络带宽问题。我们只需要对比带宽的值和实际的值,如果实际的值比带宽的小,则表示不存在网络瓶颈。
- 2、并发用户数不变
- 负载测试时,并发用户数会随着时间变化,而变化,就不能看聚合报告。
- 每一行:都是一种事务
- 每一列:
- 样本: 在过程的过程中,所有的并发用户数,在一段时间中的总请求量
- 单独看样本,是无法知道并发用户数、 执行时长
- 平均值…最大值: 表示响应时间,单位是毫秒ms,其中90%最接近真实情况
- 90%: 所有的样本中,有90%的样本时间是小于等于这个时间的
- 吞吐量 :qps(每秒处理事物数)
- 样本: 在过程的过程中,所有的并发用户数,在一段时间中的总请求量
- 1、没有网络瓶颈
- 在性能测试中,看聚合报告,有前提条件:
-
5、临界控制器
- 严格控制请求顺序(加和不加其实没啥区别,所以可以不用)
- 锁名称: 默认是一个固定锁名称
- 相当于把性能测试中的并行执行,强制转换为串行
- 如何让锁变成动态锁,生成多把锁?
- 锁名称变成一个动态名称:global_lock_${__threadNum}
-
6、Once Only Controller 仅一次控制器
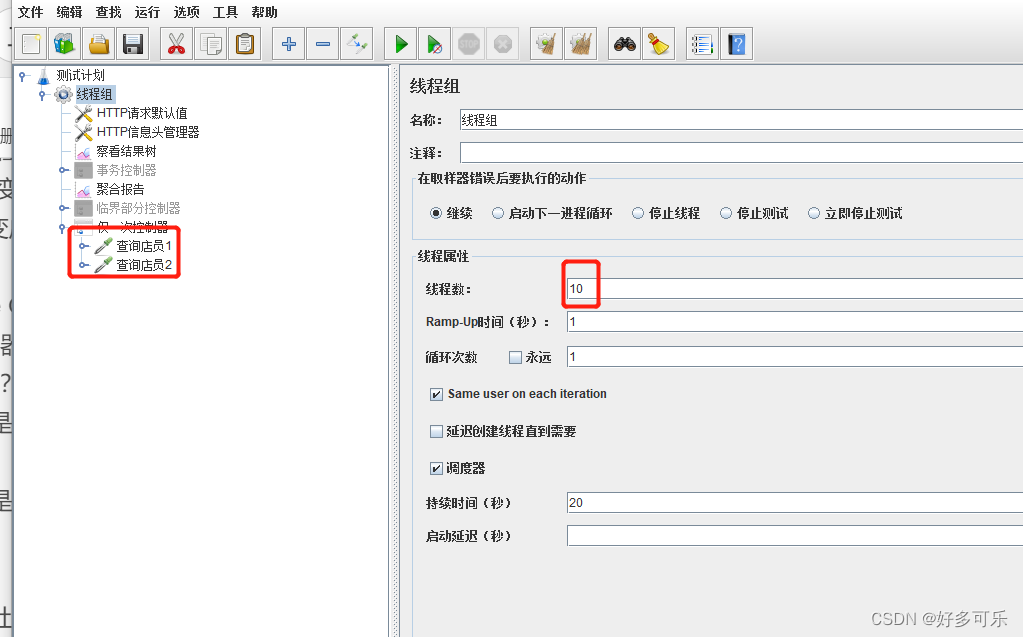
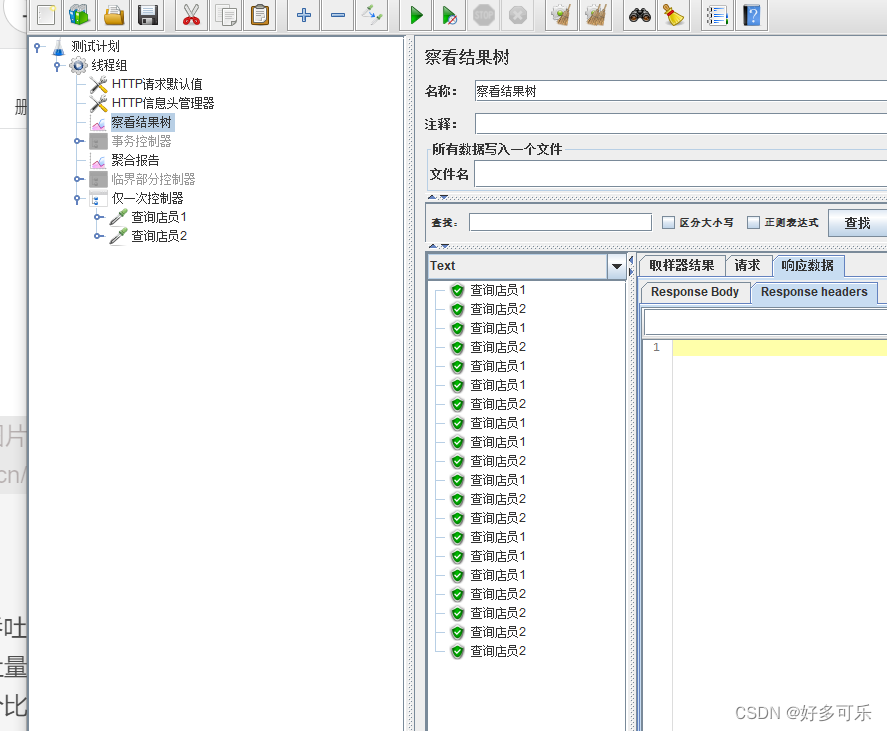
- 仅一次控制器: 意思是,一个线程用户只执行一次
- 怎么理解呢?
- 并发用户是10,不管你设置循环多少次,其下挂载的取样器,每个都只会执行10次
- 并发用户是10,不管你运行多长时间,其下挂载的取样器,每个都只会执行10次
- demo
-
7、 吞吐量控制器
- 总的吞吐量
- 控制百分比, 使用多个吞吐量控制器,使他们的之和100
- 不推荐大家用吞吐量控制器
- 总请求量 = 并发用户数 * 时间 * 频率(会强制拉低请求的频率,这样会测不出服务器真实的性能)
-
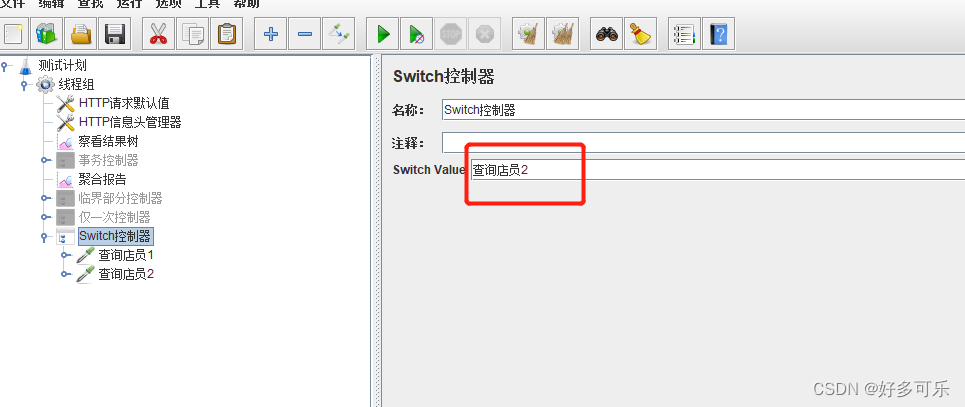
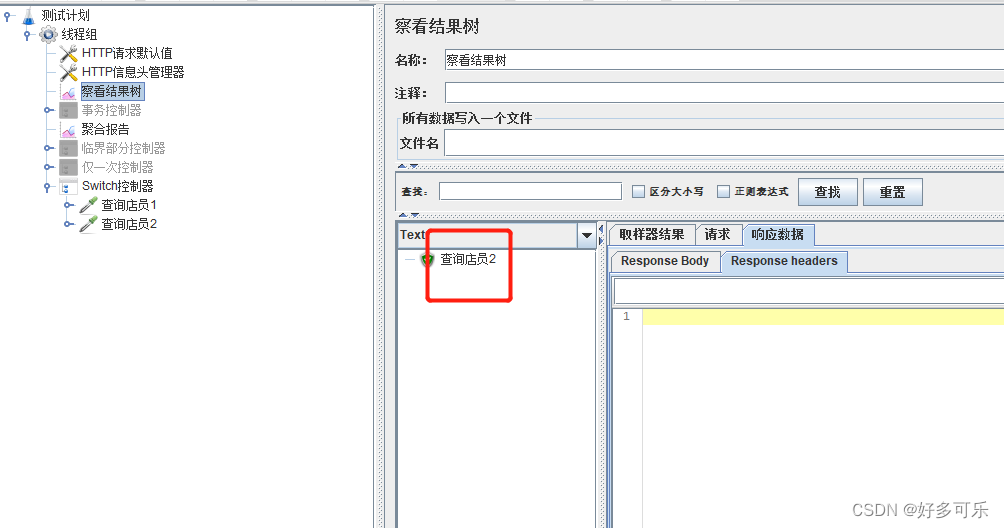
8、 switch控制器
- 随机跳转到选择的请求
- demo
-
9、随机控制器
- 随机挑选其下挂载的取样器中1个执行
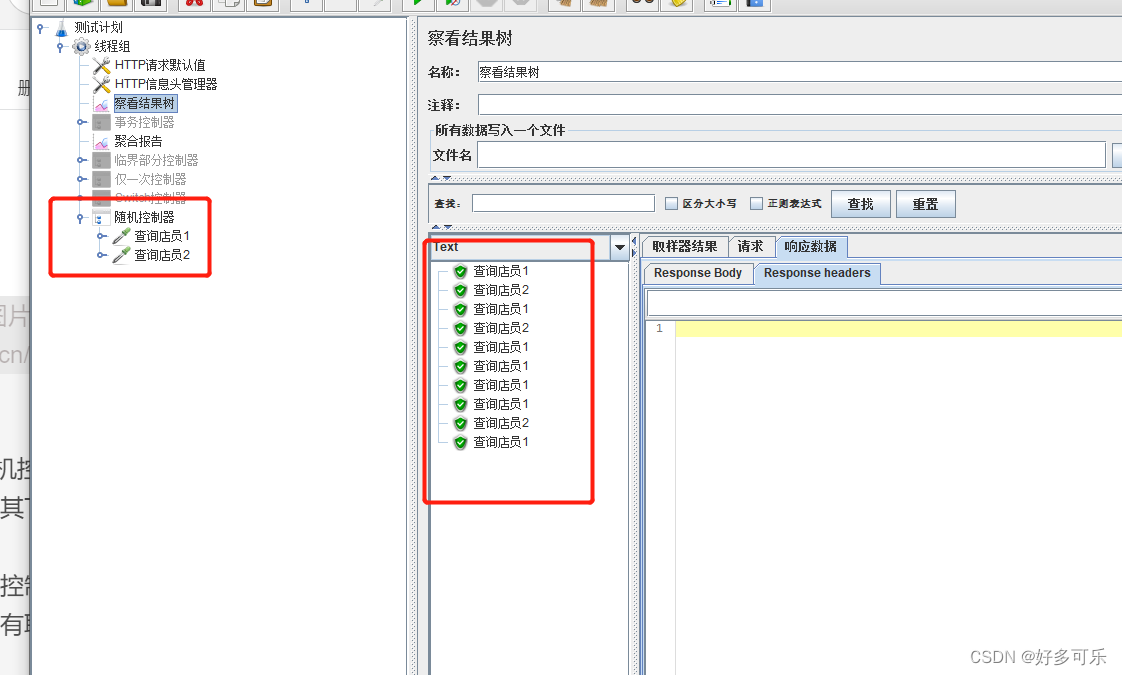
- 随机挑选其下挂载的取样器中1个执行
-
10、随机顺序控制器:
- 其下的所有取样器都会被打乱顺序执行
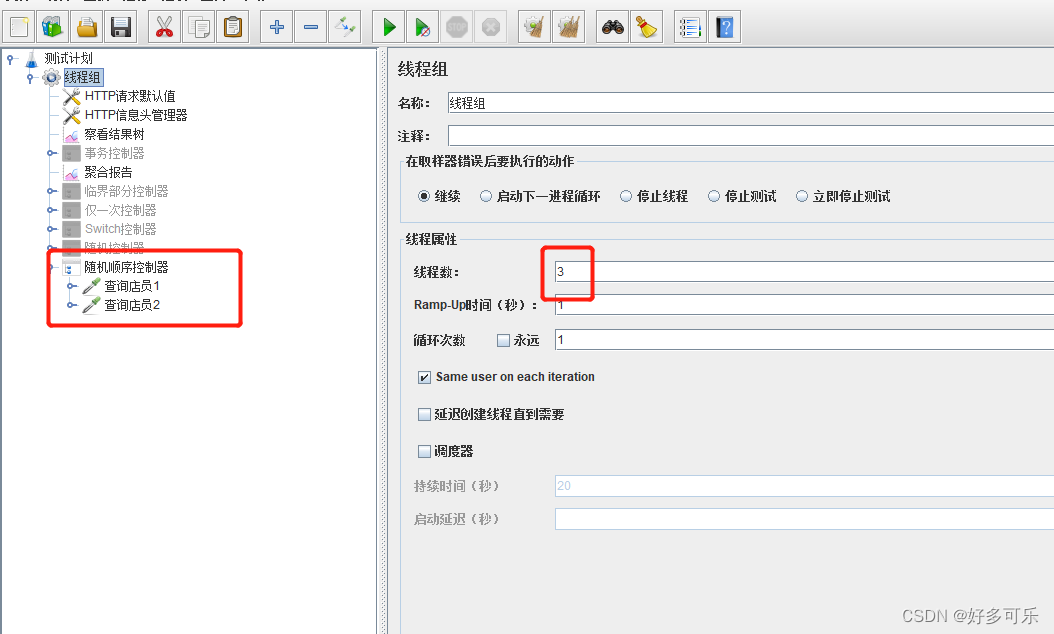
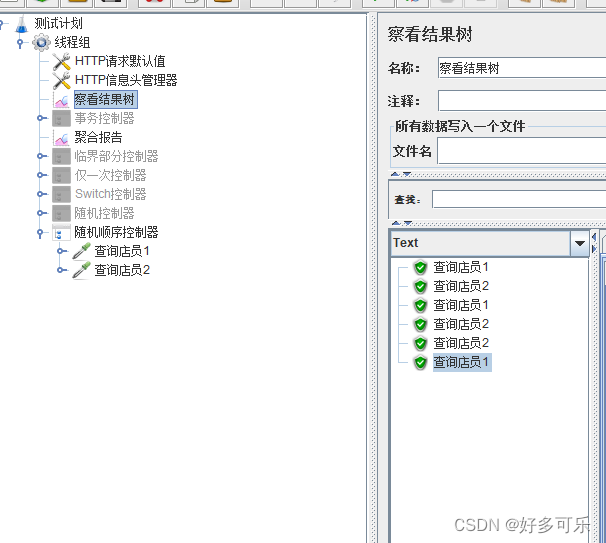
- 其下的所有取样器都会被打乱顺序执行
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)