VSCode使用03--基于正则表达式的搜素与替换
基于正则表达式的搜素与替换
在VSCode中使用正则表达式时,先要把查找输入框右边的".*"符号的通配符开关打开
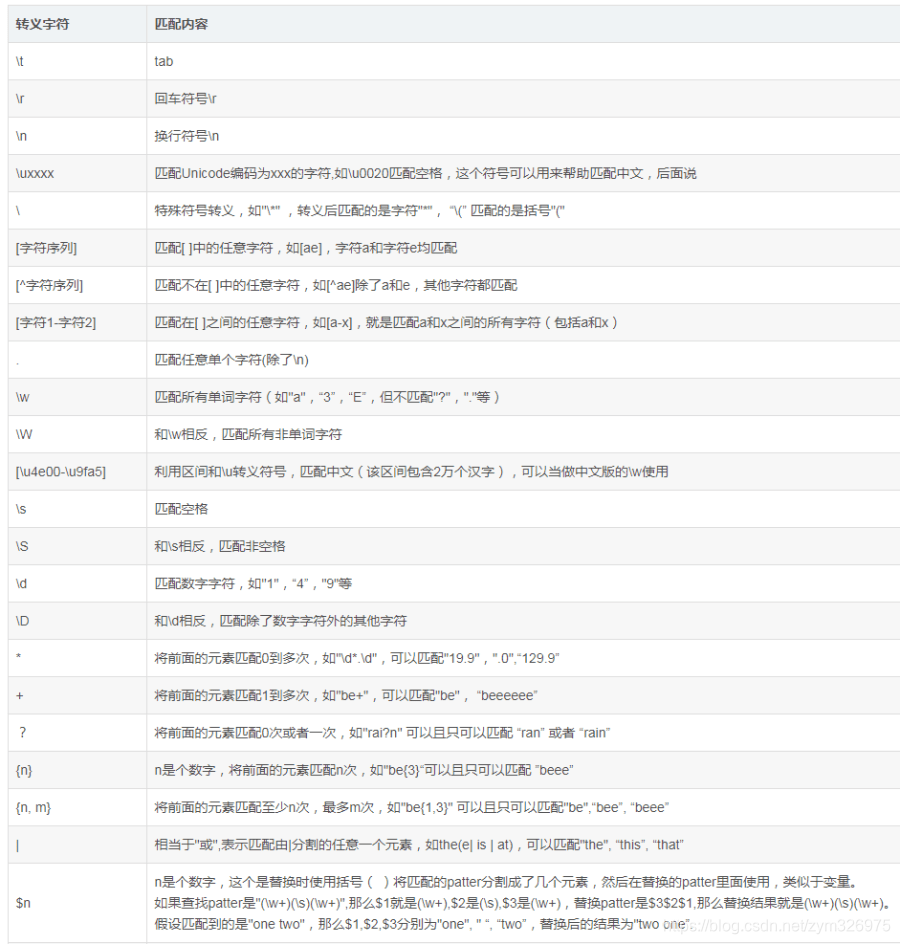
替换示例
(num.\w+())
print($1)
将所有的方法调用都套上print()
|
用途 |
表达式 |
示例 |
|
与任何单个字符匹配(换行符除外)。 |
. |
a.o 匹配“around”中的“aro”及“about”中的“abo”,但不匹配“across”中的“acro”。 |
|
零次或多次匹配前面的表达式(匹配尽可能多的字符) |
* |
a*r 匹配“rack”中的“r”,“ark”中的“ar”和“aardvark”中的“aar” |
|
零次或多次匹配任何字符(通配符 *) |
.* |
c.*e 匹配“racket”中的“cke”,“comment”中的“comme”和“code”中的“code” |
|
一次或多次匹配前面的表达式(匹配尽可能多的字符) |
+ |
e.+e 匹配“feeder”中的“eede”,而不是“ee”。 |
|
一次或多次匹配任意字符(通配符 ?) |
.+ |
e.+e 匹配“feeder”中的“eede”,而不是“ee”。 |
|
零次或多次匹配前面的表达式(匹配尽可能多的字符) |
*? |
e.*?e 匹配“feeder”中的“ee”,而不是“eede”。 |
|
一次或多次匹配前面的表达式(匹配尽可能多的字符) |
+? |
e.+?e 匹配“enterprise”中的“ente”和“erprise”,但不匹配整个单词“enterprise”。 |
|
将匹配字符串定位到行或字符串的开头 |
^ |
^car 仅在出现于行开头时才匹配单词“car”。 |
|
将匹配字符串定位到行尾 |
\r?$ |
End\r?$ 仅在出现于行尾时才匹配“end”。 |
|
匹配集中的任何单个字符 |
[abc] |
b[abc] 匹配“ba”、“bb”和“bc”。 |
|
匹配的字符范围中的任意字符 |
[a-f] |
be[n-t] 匹配“between”中的“bet”,“beneath”中的“ben”,“beside”中的“bes”,但不匹配“below”。 |
|
捕获包含在括号中的表达式并对其进行隐式编号 |
() |
([a-z])X\1 匹配“aXa”和“bXb”,但不匹配“aXb”。 ". “\1”是指第一个表达式组“[a-z]”。 |
|
使匹配无效 |
(?!abc) |
real (?!ity) 匹配“realty”和“really”中的“real”,但不匹配“reality”。 它还可找到“realityreal”中的第二个“real”(而非第一个“real”)。 |
|
匹配不在给定字符集中的任意字符 |
[^abc] |
be[^n-t] 匹配“before”中的“bef”,“behind”中的“beh”和“below”中的“bel”,但不匹配“beneath”。 |
|
匹配符号前或符号后的表达式。 |
| |
(sponge|mud) bath 匹配“sponge bath”和“mud bath”。 |
|
对反斜杠后面的字符进行转义 |
|\^ 匹配字符 ^。 |
|
|
指定前面的字符或组的出现次数 |
{x},其中 x 是出现次数 |
x(ab){2}x 匹配“xababx”,x(ab){2,3}x 匹配“xababx”和“xabababx”,但不匹配“xababababx”。 |
|
匹配 Unicode 字符类中的文本,其中“X”是 Unicode 数字。 有关 Unicode 字符类的详细信息,请参阅 |
\p{X} |
\p{Lu} 匹配“Thomas Doe”中的“T”和“D”。 |
|
与字边界匹配 |
\b(在字符类 \b 的外部指定字边界,而在字符类内部指定退格符)。 |
\bin 匹配“inside”中的“in”,不匹配“pinto”。 |
|
与换行符(即回车符后跟新行)相匹配。 |
\r?\n |
仅当“End”是一行的最后一个字符串,且“Begin”是下一行的第一个字符串时,End\r?\nBegin 才匹配“End”和“Begin”。 |
|
匹配任意字母数字字符 |
\w |
a\wd 匹配“add”和“a1d”,不匹配“a d”。 |
|
匹配任意空格字符。 |
(?([^\r\n])\s) |
Public\sInterface 匹配词组“Public Interface”。 |
|
匹配任意数字字符 |
\d |
\d 匹配“3456”中的“3”,“23”中的“2”和“1”中的“1”。 |
|
匹配 Unicode 字符 |
\uXXXX,其中 XXXX 指定 Unicode 字符值。 |
\u0065 匹配字符“e”。 |
|
匹配标识符 |
\b(\w+|[\w-[0-9\]]\w*)\b |
匹配“Type1”,但不匹配“&type1”或“#define”。 |
|
与引号中的字符串匹配 |
((\".+?\")|('.+?')) |
匹配单引号或双引号内的任意字符串。 |
|
匹配十六进制数 |
\b0[xX]([0-9a-fA-F])\b |
匹配“0xc67f”但不匹配“0xc67fc67f”。 |
|
匹配整数和小数 |
\b[0-9]*\.*[0-9]+\b |
匹配“1.333”。 |
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 \\t )匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾。 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
| re* | 匹配0个或多个的表达式。 |
| re+ | 匹配1个或多个的表达式。 |
| re? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| re{ n} | 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。 |
| re{ n,} | 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。 |
| re{ n, m} | 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
| a| b | 匹配a或b |
| (re) | 匹配括号内的表达式,也表示一个组 |
| (?imx) | 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
| (?-imx) | 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
| (?: re) | 类似 (...), 但是不表示一个组 |
| (?imx: re) | 在括号中使用i, m, 或 x 可选标志 |
| (?-imx: re) | 在括号中不使用i, m, 或 x 可选标志 |
| (?#...) | 注释. |
| (?= re) | 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
| (?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。 |
| (?> re) | 匹配的独立模式,省去回溯。 |
| \w | 匹配数字字母下划线。匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非数字字母下划线。匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]。 |
| \S | 匹配任意非空字符,等价于 [^ \f\n\r\t\v]。 |
| \d | 匹配任意数字,等价于 [0-9]。 |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。 |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \n, \t, 等。 | 匹配一个换行符。匹配一个制表符, 等 |
| \1...\9 | 匹配第n个分组的内容。 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。 |
正则表达式实例
字符匹配
| 实例 | 描述 |
|---|---|
| python | 匹配 "python". |
字符类
| 实例 | 描述 |
|---|---|
| [Pp]ython | 匹配 "Python" 或 "python" |
| rub[ye] | 匹配 "ruby" 或 "rube" |
| [aeiou] | 匹配中括号内的任意一个字母 |
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)