几种python存储数据(海量数据)的方式及读取时间对比
使用背景:需要保存通过包括但不限于torch及numpy创建的数据(在这里主要测试的是通过网络训练,提取到的图片的特征向量)数据格式及大小:在这里使用torch创建数据,没用使用GPU(已经是该配置下能运行的最大数据量了,否则会爆内存)运行环境:具体参数参考R9000P 2021 3070版本;数据存储在新加的固态上型号是三星1tb 980测试内容:测试python主要的几种存储数据方式包括:h5
先说在本机环境下的测试结果,仅供参考,其中单次调用时测试了10次,多次调用时测试了5次:
单次读取时,h5py文件整体平均读取速度最快,pkl文件整体平均读取最慢
多次读取(循环读取同一文件10次,并取平均时间)时,pt文件平均读取速度最快,pkl文件平均读取速度最慢
需要注意的是,每个文件类型读取出的数据类型不同,如果需要特定的数据类型,那么当数据读取后还需要增加数据类型转换时间,比如存储[1000000, 1024]维的数据时,若提取需要的是torch类型数据,那么存储为h5py文件后读取时需要进行数据转换,所以可以在存储数据时直接使用pt文件存储,此时读取时就不需要类型转换。(我踩的坑,从h5py读取的时又使用了数据类型转换,从而导致读取很慢(读一个文件要几分钟))
| 文件类型 | h5py | npy | pt | pkl |
|---|---|---|---|---|
| 读取出的数据类型 | numpy.ndarray | numpy.ndarray | torch.Tensor | 写入时的数据类型 |
以单次运行时间为准(单位:秒,测试10次):
| 文件类型 | 单次运行时间(最长) | 单次运行时间(最短) | 单次运行时间(平均) |
|---|---|---|---|
| h5py | 2.9399638175964355 | 2.3647351264953613 | 2.56110846996307 |
| npy | 2.813739061355591 | 2.6315581798553467 | 2.72723414897918 |
| pt | 3.1011040210723877 | 2.7481846809387207 | 2.90884675979614 |
| pkl | 4.722779989242554 | 4.355636358261108 | 4.56104216575622 |
以多次运行(循环读取同一文件10次,并取平均时间)时间为准(单位:秒,测试5次):
| 文件类型 | 多次运行时间(最长) | 多次运行时间(最短) | 多次运行时间(平均) |
|---|---|---|---|
| h5py | 2.88373696804046 | 2.54924149513244 | 2.74235633373260 |
| npy | 2.82599551677703 | 2.58592479228973 | 2.70383455276489 |
| pt | 2.63072323799133 | 2.41257598400115 | 2.53340683937072 |
| pkl | 4.05210723876953 | 3.87074110507965 | 3.96310455799102 |
1 前言
使用背景:需要保存通过包括但不限于torch及numpy创建的数据(在这里主要测试的是通过神经网络训练,提取到的图片的特征向量)
数据格式及大小:在这里使用torch创建数据,没有使用GPU(已经是该配置下能运行的最大数据量了,否则会爆内存),几个文件类型存储的data是同一个data
data = torch.Tensor(1000000, 1024)运行环境:具体参数参考R9000P 2021 3070版本;数据存储在新加的固态上型号是三星1tb 980
测试内容:测试python主要的几种存储数据方式包括:h5py、npy、pkl、pt的读取速度。同时,测试分为单次运行与多次运行(单次运行循环读取10次),其分别在不同的py文件下(需在不同py文件下测试,同时每个文件类型的测试也需要在不同py文件下测试,且同一文件类型不能连续测试,否则会存在缓存影响测试结果)。
2 测试
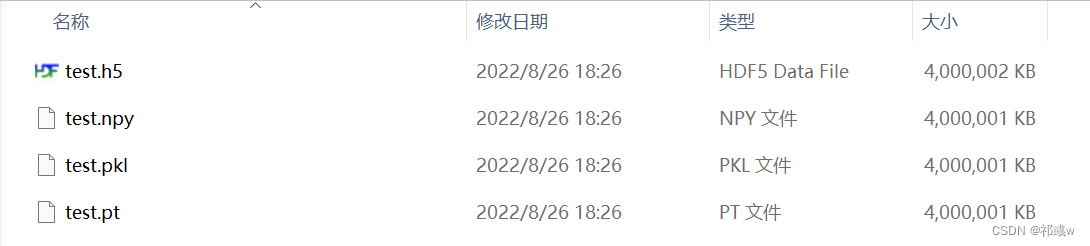
存储文件大小, 几种文件存储大小基本相同
各文件类型单次运行(各文件类型读取时,在不同的py文件中)时,运行速度如下(单位:秒):
| 测试次数\文件类型 | h5py | npy | pt | pkl |
|---|---|---|---|---|
| 1 | 2.9399638175964355 | 2.7908334732055664 | 2.9762351512908936 | 4.643392324447632 |
| 2 | 2.5050277709960938 | 2.813739061355591 | 2.7838234901428223 | 4.722779989242554 |
| 3 | 2.648083448410034 | 2.742082357406616 | 2.8236582279205322 | 4.454906702041626 |
| 4 | 2.4942474365234375 | 2.749253511428833 | 2.7481846809387207 | 4.355636358261108 |
| 5 | 2.5487558841705322 | 2.696244239807129 | 2.9988608360290527 | 4.5721657276153564 |
| 6 | 2.4321188926696777 | 2.7138049602508545 | 3.1011040210723877 | 4.612890243530273 |
| 7 | 2.49503231048584 | 2.6315581798553467 | 2.92618727684021 | 4.6190714836120605 |
| 8 | 2.3647351264953613 | 2.770236015319824 | 2.824173927307129 | 4.568334579467773 |
| 9 | 2.5203959941864014 | 2.666151762008667 | 3.005869150161743 | 4.478247404098511 |
| 10 | 2.662724018096924 | 2.6984379291534424 | 2.9003708362579346 | 4.582996845245361 |
| 平均 | 2.56110846996307 | 2.72723414897918 | 2.90884675979614 | 4.56104216575622 |
各文件类型多次运行(单次运行时循环读取10次,并取平均)时,其平均运行速度如下(单位:秒):
| 测试次数\文件类型 | h5py | npy | pt | pkl |
|---|---|---|---|---|
| 1 | 2.88373696804046 | 2.82599551677703 | 2.41257598400115 | 3.87074110507965 |
| 2 | 2.54924149513244 | 2.63526268005371 | 2.56912226676940 | 4.05210723876953 |
| 3 | 2.57715878486633 | 2.58592479228973 | 2.53995752334594 | 3.91412274837493 |
| 4 | 2.80590989589691 | 2.79449951648712 | 2.51465518474578 | 3.96075069904327 |
| 5 | 2.89573452472686 | 2.67749025821685 | 2.63072323799133 | 4.01780099868774 |
| 平均 | 2.74235633373260 | 2.70383455276489 | 2.53340683937072 | 3.96310455799102 |
2.1 h5py文件存取
# 存储
f = h5py.File('./datasets/test.h5', 'w')
f.create_dataset('features', data=data)
f.close()
"""
单次运行
"""
start = time.time()
f = h5py.File('./datasets/test.h5', 'r')
vecs = f['features'][()]
f.close()
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
f = h5py.File('./datasets/test.h5', 'r')
vecs = f['features'][()]
f.close()
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))2.2 npy文件存取
# 存储
np.save('./datasets/test.npy', data)
"""
单次运行
"""
start = time.time()
vecs_npy = np.load('./datasets/test.npy')
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
vecs_npy = np.load('./datasets/test.npy')
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))2.3 pt文件存取
# 存储
torch.save(data, './datasets/test.pt')
"""
单次运行
"""
start = time.time()
vecs_pt = torch.load('./datasets/test.pt')
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
vecs_pt = torch.load('./datasets/test.pt')
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))2.4 pkl文件存取
# 存储
f = open('./datasets/test.pkl', 'wb')
pickle.dump(data, f)
f.close()
"""
单次运行
"""
start = time.time()
f = open('./datasets/test.pkl', 'rb+')
vecs_pkl = pickle.load(f)
f.close()
end = time.time() - start
print(end)
"""
多次运行
"""
start = time.time()
start_end = start
ltime = []
for i in range(10):
f = open('./datasets/test.pkl', 'rb+')
vecs_pkl = pickle.load(f)
f.close()
ltime.append(time.time()-start)
start = time.time()
end = time.time() - start_end
print(ltime)
print(np.mean(ltime))
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)