并行计算期末复习
并行计算的知识
目录
- 作业练习题
-
- 1. de Bruijn网络,节点数 N = 2 k N=2^k N=2k
- 2. "树网"是一种将树结构加在处理器网格上所形成的网络。
- 3. 树上一到多播送
- 4. 单点散播(一到多个人通信)
- 5. 全交换(多到多个人通信)(SF方式)
- 6. 分两步方法进行一到多播送
- 7. 程序的顺序执行时间 T 1 = N 2 T_1=N^2 T1=N2, 在p个节点上的并行执行时间 T p = N 2 p + N T_p=\frac{N^2}{p}+N Tp=pN2+N
- 8. 求n个数之和的ARPAM模型上的算法
- 9. 求数组a[n]最大值的PRAM模型上的算法
- 10. 求串匹配次数的PRAM模型上的算法
- 11. 画排序8个数的基于Batcher比较器的双调排序网络
- 12. PSRS排序算法
- 13. 分析PSRS排序算法的平均时间复杂度和加速比
- 14. Cannon算法的执行过程
- 15. DNS算法的执行过程
- 16. 画出DFT蝶式网络
- 理论
作业练习题
1. de Bruijn网络,节点数 N = 2 k N=2^k N=2k
- 节点用K位二进制表示
- 设节点M= a k − 1 a k − 2 … a 1 a 0 a_{k-1}a_{k-2}\dots a_1a_0 ak−1ak−2…a1a0.
- 节点M可达另外两个节点X和Y
- X= a k − 2 a k − 3 … a 1 a 0 0 a_{k-2}a_{k-3}\dots a_1 a_0 0 ak−2ak−3…a1a00
- Y= a k − 2 a k − 3 … a 1 a 0 1 a_{k-2}a_{k-3}\dots a_1 a_0 1 ak−2ak−3…a1a01
- 比如k=3的时候,网络如图:
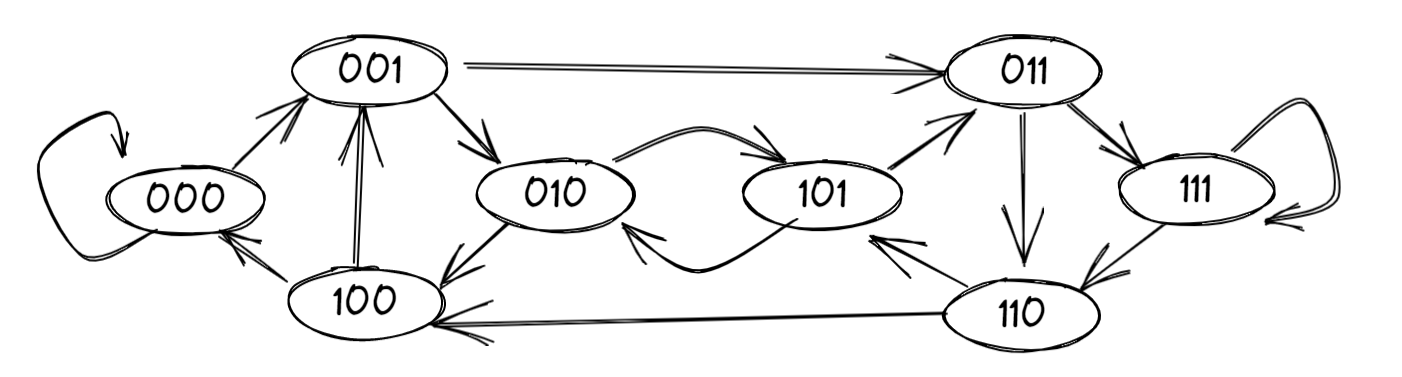
- 好了,现在你已经知道网络结构了。请问,这个网络的直径和对剖宽度是多少?
- 直径是3
- 关于对剖宽度的计算,需要引入一个概念:
如果一个节点的二进制表示中有m个1,则称该节点为一个m-节点。
①最高位是0,可达一个m-节点和一个(m+1)-节点
②最高位是1,可达一个m-节点和一个(m-1)-节点
抓住了网络的特性。利用这个规律可以很好地隔离。
- 假如k是奇数,那么A集合={ { 0 − } , { 1 − } , … , { k − 1 2 − } \{0-\},\{1-\},\dots ,\{\frac{k-1}{2}-\} {0−},{1−},…,{2k−1−}}, B集合={ { k + 1 2 − } , … , { k − } \{\frac{k+1}{2}-\},\dots,\{k-\} {2k+1−},…,{k−}}. A集合和B集合之间的边只存在于 { k − 1 2 − } 与 { k + 1 2 − } \{\frac{k-1}{2}-\}与\{\frac{k+1}{2}-\} {2k−1−}与{2k+1−}之间。对剖宽度为 2 C k − 1 k − 1 2 2C_{k-1}^{\frac{k-1}{2}} 2Ck−12k−1
- 假如k是偶数,那么A集合={ { 0 − } , { 1 − } , … , { ( k 2 − 1 ) − } , 最低位为 1 的 { k 2 − } \{0-\},\{1-\},\dots ,\{(\frac{k}{2}-1)-\},最低位为1的\{\frac{k}{2}-\} {0−},{1−},…,{(2k−1)−},最低位为1的{2k−}}, B集合={ 最低位为 0 的 { k 2 − } , … , { k − } 最低位为0的\{\frac{k}{2}-\},\dots,\{k-\} 最低位为0的{2k−},…,{k−}}. 对剖宽度为 4 C k − 2 k 2 − 1 4C_{k-2}^{\frac{k}{2}-1} 4Ck−22k−1
2. "树网"是一种将树结构加在处理器网格上所形成的网络。
-
将网格中的每一行变成一个完全二叉树
-
再将每一列变成一个完全二叉树。
-
中间节点都是开关元件。
-
计算对剖宽度,直径、开关元件的数量。
-
每行的二叉树的根上删除一条边,可以将网络对分各半,所以对剖宽度是 p \sqrt{p} p

-
直径: 2 log p 2\log\sqrt{p} 2logp
-
每个二叉树需要 p − 1 \sqrt{p}-1 p−1个开关,总共有 2 p 2\sqrt{p} 2p个二叉树
3. 树上一到多播送
- 二叉树的叶子节点是处理器,中间节点是开关。处理器个数为p
- 信包穿越 l − 1 l-1 l−1个开关节点需要耗时 t s + m t w + t h l t_s+mt_w+t_hl ts+mtw+thl
- 证:在树上,进行m个字的一到多播送的通信时间为 ( t s + m t w + t h ( log p + 1 ) ) log p (t_s+mt_w+t_h(\log p+1))\log p (ts+mtw+th(logp+1))logp

(1)源节点发送信包给另一个子树相应位置的节点,树高为i,通信时间为 t s + m t w + 2 i t h t_s+mt_w+2it_h ts+mtw+2ith
(2)将左子树和右子树分开,树高减一,左右子树继续分别执行(1),直至树高为0 - result: Σ i = 1 i = h ( t s + m t w + 2 i t h ) \Sigma_{i=1}^{i=h}(t_s+mt_w+2it_h) Σi=1i=h(ts+mtw+2ith)
4. 单点散播(一到多个人通信)
证明:使用SF和CT方式在超立方上进行单点散播的通信时间为 t = t s log p + m t w ( p − 1 ) t=t_s\log p+mt_w(p-1) t=tslogp+mtw(p−1)
t = Σ i = 1 log p ( t s + p 2 i m t w ) t=\Sigma_{i=1}^{\log p}(t_s+\frac{p}{2^i}mt_w) t=Σi=1logp(ts+2ipmtw)
5. 全交换(多到多个人通信)(SF方式)
-
在环上进行全交换的通信时间为 t = ( t s + p 2 m t w ) ( p − 1 ) t=(t_s+\frac{p}{2}mt_w)(p-1) t=(ts+2pmtw)(p−1)
-
在超立方上进行全交换的通信时间为 t = p 2 m t w log p t=\frac{p}{2}mt_w\log p t=2pmtwlogp, 忽略 t s t_s ts

-
在环绕网孔上进行全交换的通信时间为 t = p m t w ( p − 1 ) t=pmt_w(\sqrt{p}-1) t=pmtw(p−1),忽略 t s t_s ts

6. 分两步方法进行一到多播送
- 环形网络,且处理器数目p为偶数,采用SF方式。将消息分为p份,有点类似P2P,先把资源分布在各个站点。每个站点再互相索取。
- 一到多通信
- 信包大小: m p \frac{m}{p} pm
- 时间: p 2 t s + ( p + 2 ) m 8 t w \frac{p}{2}t_s+\frac{(p+2)m}{8}t_w 2pts+8(p+2)mtw
- 多对多播送
- 时间: ( t s + m p t w ) ( p − 1 ) (t_s+\frac{m}{p}t_w)(p-1) (ts+pmtw)(p−1)

- 直接使用多对多播送方式,时间是 p 2 t s + p 2 m t w \frac p2t_s+\frac p2 mt_w 2pts+2pmtw
7. 程序的顺序执行时间 T 1 = N 2 T_1=N^2 T1=N2, 在p个节点上的并行执行时间 T p = N 2 p + N T_p=\frac{N^2}{p}+N Tp=pN2+N
- 固定负载为N时,计算加速比
- 加速比: T 1 T p = N 2 N 2 p + N = p N p + N \frac{T_1}{T_p} = \frac{N^2}{\frac{N^2}{p}+N}=\frac{pN}{p+N} TpT1=pN2+NN2=p+NpN,当 p → ∞ p\rightarrow \infty p→∞, 加速比=N
- 固定时间为T时,计算加速比
- T = N 2 p + N , N = p 2 + 4 p T − p 2 T=\frac{N^2}{p}+N, N=\frac{\sqrt{p^2+4pT}-p}{2} T=pN2+N,N=2p2+4pT−p
- 加速比= N 2 N 2 p + N = p N p + N = ( p 2 + 4 p T − p ) 2 4 T \frac{N^2}{\frac{N^2}{p}+N}=\frac{pN}{p+N}=\frac{(\sqrt{p^2+4pT}-p)^2}{4T} pN2+NN2=p+NpN=4T(p2+4pT−p)2
8. 求n个数之和的ARPAM模型上的算法
- 局部求和
- x叉树
for all Pi where 0<=i<p
ls = 0;
for(k=i;k<n;k+=p)
ls += a[k];
s[i] = ls;
barrier;
for(k=0;k<log(x,p);k++)
for all Pi where 0<=i<p and i % x^(k+1) == 0
ls = 0;
for(j=i; j < i + x^(k+1) and j < p; j += x^k)
ls += s[j];
s[i] = ls;
barrier;
9. 求数组a[n]最大值的PRAM模型上的算法
for (k=0;k<logn;k++)
parfor(i=0;i<n-2^k;i+=2^(k+1))
a[i] = max(a[i],a[i+2^k);
10. 求串匹配次数的PRAM模型上的算法
parfor(i=0;i<=n-m;i++)
x[i] = 1;
for(k=0; k<m;k++)
if(p[k]!=a[i+k]) x[i] = 0;
for(k=0;k<log(n-m+1);k++)
parfor(i=n-m;i>=2^k;i-=2^(k+1)
x[i] = x[i] + x[i-2^k)
11. 画排序8个数的基于Batcher比较器的双调排序网络

12. PSRS排序算法
- Parallel Sorting by Regular Sampling 正则采样并行排序
- 执行PSRS算法的并行机必须是多指令流多数据流的。
- 算法描述
- 让各个处理器并行的调用串行排序算法进行局部排序;
- 从每个有序段中选p个样本元素,共 p 2 p^2 p2个样本元素(采样);、
- 对样本元数排序;
- 从样本元素中选p-1作为划分元素,并播送给其余的处理器;
- 各个处理器根据划分元素对局部序列进行划分(分为p段);
- 各个处理器将每一段按段号交换到相应序列号的处理器;
- 在各个处理器中使用串行算法再次进行局部排序。
13. 分析PSRS排序算法的平均时间复杂度和加速比
n = p 3 , p = n 1 3 n = p^3, p=n^{\frac{1}{3}} n=p3,p=n31
局部排序: O ( n 2 3 log n 2 3 ) O(n^{\frac{2}{3}}\log n^{\frac23}) O(n32logn32)
正则采样: O ( n 1 3 ) O(n^\frac13) O(n31)
样本排序: O ( n 2 3 log n 2 3 ) O(n^\frac23\log n^\frac23) O(n32logn32)
选择主元: O ( n 1 3 ) O(n^\frac13) O(n31)
主元划分: O ( n 1 3 log n 2 3 ) O(n^\frac13 \log n^\frac23) O(n31logn32)
归并排序: O ( n 2 3 log n 1 3 ) O(n^\frac23 \log n^\frac13) O(n32logn31)
- 总时间复杂度是 O ( n 2 3 log n 1 3 ) O(n^\frac23 \log n^\frac13) O(n32logn31), 加速比为 O ( n 1 3 ) O(n^\frac13) O(n31)
14. Cannon算法的执行过程

15. DNS算法的执行过程

16. 画出DFT蝶式网络

理论
1. 大型并行机系统的种类
- 单指令流多数据流
SIMD - 并行向量处理机
PVP - 对称多处理机
SMP - 大规模并行处理机
MPP - 分布共享存储多处理机
DSM - 工作站机群
COW
2. 并行计算机访存模型
UMA: 均匀存储访问NUMA:非均匀存储访问COMA:全高速缓存存储访问CC-NUMA: 高速缓存一致性非均匀存储访问NORMA: 非远程存储访问
3. 并行计算模型
PRAM模型
- 优点
- 使用简单,隐含了通信和同步等细节
- 易于设计算法,易于迁移
- 可拓展
- 缺点:
- 所有指令按锁步方式操作,性能低
- 共享单一存储器的假定不适合MIMD机
- 假定每个处理器均可在单位时间内访问任何存储单元,没有考虑存取竞争和有限带宽。
APRAM模型
- 优点:
- 保留了PRAM编程的便捷性
- 使用了同步路障
- 缺点:
- 不适合MPI并行计算机
BSP模型
- 优点:
- 强调了计算和通信的分离
- 在一个超级步内,可将消息作为一个整体传递
- 易于分析算法复杂性
- 缺点:
- 需要特殊的硬件支持全局路障同步
LogP模型
- 优点:
- 明确了通信网络的性能特征
- 隐藏了并行机的网络拓扑、路由、协议
- 可以应用到共享存储、消息传递的编程模型中
- 缺点:
- 难以进行算法描述、设计和分析
BSP模型和LogP模型不同之处
LogP基于成对消息传递,BSP进行整体通信
LogP增加了一个参数o,表示传递消息的额外开销
LogP鼓励计算与通信重叠,BSP强调计算与通信分离
BSP+Overhead-Barrier = LogP
两者可以高效地进行相互模拟
4. OpenMP并行编程模型
- 基于线程的并行编程模型
- 一个外部的编程模型:程序员完全控制并行化
- 通过Fork-Join并行执行模型
- 通过使用编译制导语句来实现并行
5. MPI标准
- MPI是一个消息传递接口的标准,用于开发基于消息传递的并行程序
- 目的:为用户提供实际可用的、可移植的、高效的、灵活的消息传递接口库
- 一个用标准的C或Fortran加上MPI实现的消息传递并行程序,可以不做修改地运行在单台PC机、单台工作站、机群系统和MPP系统上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)