CFNet:用于密集预测的级联融合网络
多尺度特征对于密集预测、目标检测、实例分割和语义分割任务来说是至关要的。现在最先进的是通过分类主干提取多尺度特征,然后通过轻量级模块(例如FPN中的融合模块)融合这些特征。但是与重型分类主干相比,为特征融合分配的参数有限,不能够充分的融合多尺度特征。对此提出级联融合网络(CFNet),用于密集预测。除了用于提取初始高分辨率特征的干和几个块外,还引入了几个级联阶段来生成CFNet中的多尺度特征。每个
摘要
多尺度特征对于密集预测、目标检测、实例分割和语义分割任务来说是至关要的。现在最先进的是通过分类主干提取多尺度特征,然后通过轻量级模块(例如FPN中的融合模块)融合这些特征。但是与重型分类主干相比,为特征融合分配的参数有限,不能够充分的融合多尺度特征。对此提出级联融合网络(CFNet),用于密集预测。除了用于提取初始高分辨率特征的干和几个块外,还引入了几个级联阶段来生成CFNet中的多尺度特征。每个阶段包括一个用于特征提取的子主干和一个用于特征集成的极其轻量级的过渡块。这样的设计使得整个主干的参数比例大,特征融合更深入、更有效。在目标检测、实例分割和语义分割方面的大量实验验证了CFNet的有效性。代码。
导读
在过去的几年中,卷积神经网络(cnn)和Transformer及其各种变型网络在许多计算机视觉任务中取得了可喜的成果,包括图像分类、目标检测、语义分割等。CNN和transformer网络在架构设计上通常采用顺序的方式,即逐渐减小特征映射的空间大小,并基于最粗尺度的特征进行预测。然而,对于许多密集的预测任务,如对象检测和实例分割,需要多尺度特征来处理不同尺度的对象。获取多尺度特征并对其进行有效整合是这些任务成功的关键。

特征金字塔网络(Feature pyramid network, FPN)及其变体是广泛应用于多尺度特征提取和融合的模型。如上图 (a)所示,这些模型通常包含大量的分类主干用于提取多尺度特征的骨和用于融合这些特征的轻量级融合模块。为了融合多尺度特征,首先通过执行元素加法对相邻层的特征进行集成,然后使用单个3×3卷积对求和特征进行变换。我们将这两个步骤称为特征集成和特征转换,构成特征融合。由于与重分类主干相比,为特征融合分配的参限,我们认为使用这种范式可能不足以融合多尺度特征,只有分配更大比例的参数用于特征融合才可以获得更好的性能。
针对上述存在的问题,本文提出了一种新的用于密集预测的级联融合网络(CFNet)架构,并针对该网络进行了一系列的研究和验证。总结本文的工作可以分为一下:
提出来用于密集预测的级联融合网络(CFNet)架构;
验证CFNet,在COCO 数据集上验证对象检测和实例分割;在ADE20k数据集上验证语义分割。
方法
总体架构
下图显示了CFNet的体系结构。基于一个stem和多个block提取的高分辨率特征,引入M级联的CFNet阶段来生成多尺度特征。所有阶段都有相同的结构,但它们的大小可以不同。具体来说,每个阶段包括一个用于提取多尺度特征的子主干和一个用于集成这些特征的非常轻量级的过渡块。这样,我们将特征整合操作插入到主干中,使得整合后的特征可以在过渡块之后的各个阶段进行转换。换句话说,过渡块之后的所有参数都可以用于特征融合。此外,我们在图像分类任务上进行的实验表明,CFNet结构简单,仍然可以从大规模的预训练中获益。
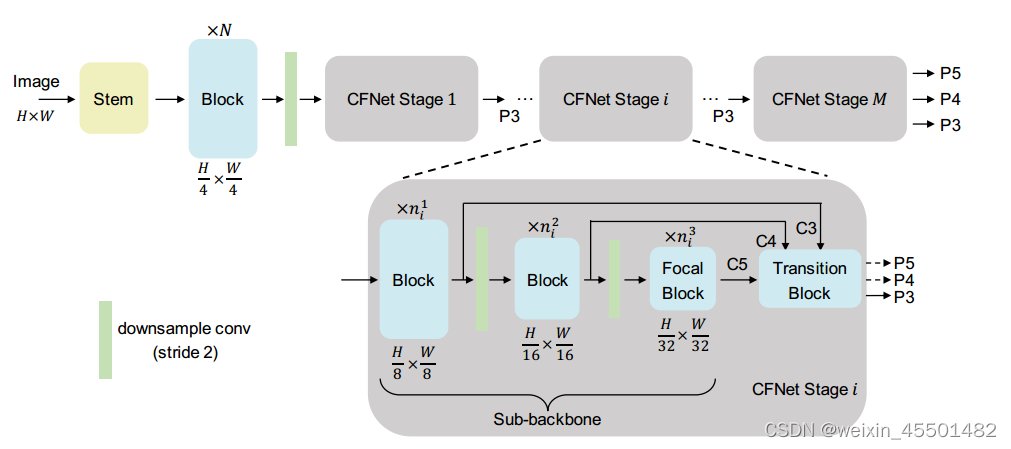
首先将空间大小为H × W的输入图像输入到一个stem(由两个3×3卷积组成,每个卷积的步长为2,每个卷积后面都有一个LayerNorm层和一个GELU单元)和N个连续的block中,提取空间大小为h4 × w4的高分辨率特征。然后,将这些特征送到M级联阶段,提取多尺度特征。值得注意的是,每个阶段的输出都有P3、P4、P5,步幅分别为8、16、32,但只有P3被送入后期。最后,将最后一阶段输出的融合特征P3、P4和P5用于密集预测任务。在整个过程中只有stem和“下采样卷积”减小了特征的空间大小,其他操作并未改变特征空间的大小。
转换块(Transition block)
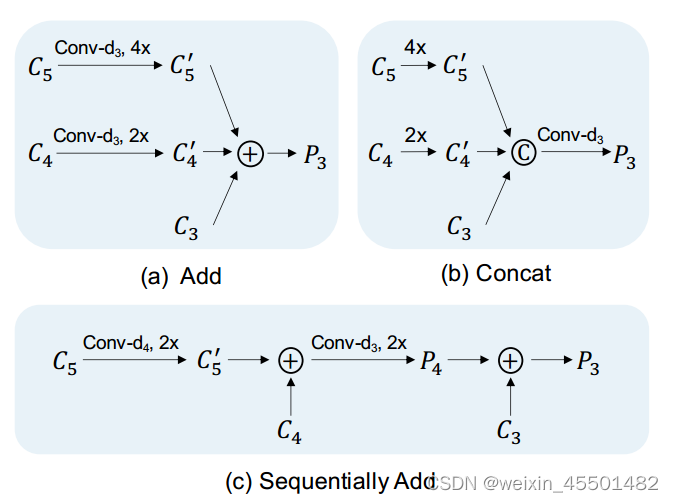
引入转换块,整合各阶段不同尺度的特征。为了避免引入过多的额外计算成本,我们提出三种简单的设计,如上图所示。给定C3, C4, C5作为输入,转换块输出具有P3, P4, P5。如果特定设计中没有P4/P5,则C4/C5为输出P4/P5(身份映射)。con -dx表示输出通道号为dx的1×1 conv,其中dx为特征Cx的通道号。带+和C的圆圈分别表示元素的加法和连接操作。2x表示以比例因子2对特征进行上采样,4x类似。
其中“Add”融合首先减少了特征C4和C5的通道数,使C3的通道数与1×1卷积对齐。在进行元素加法之前,使用双线性插值操作来对齐特征的空间大小。“Concat”融合直接对特征C4和C5进行上采样,以对齐空间C3的大小,然后将这些特征连接起来,然后进行1×1卷积以减少通道数。“Sequentially Add”融合上采样样并顺序组合不同尺度的特征。该设计类似于FPN中的融合模块,不同之处在于没有额外的卷积来变换求和特征。以上三种设计在实验中均表现良好
聚焦块(Focal block)
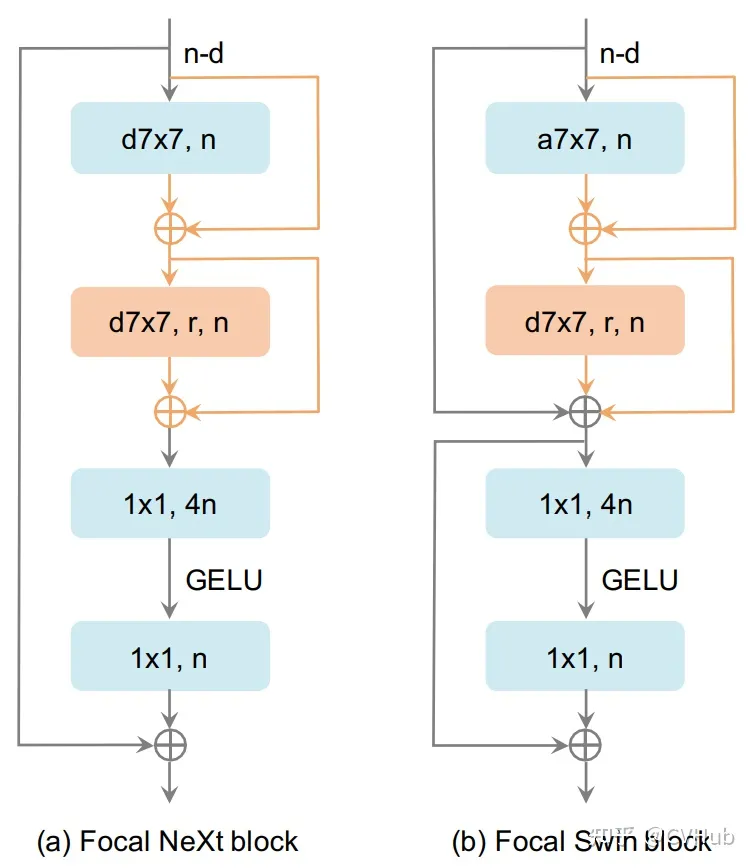
如上图所示,本文提出了两种聚焦块的设计,它们分别是基于ConvNeXt块和Swin Transformer块构建的。橙色部分是添加到两个块中的操作。N为输出特征的通道数。D7×7表示7×7深度卷积,a7×7表示窗口关注,窗口大小为7×7。R为附加卷积的扩张速率。1×1表示1×1卷积。GELU[35]是激活单位。每个d7×7或a7×7后面都有一个LayerNorm[34]层和一个GELU单元,为清晰起见省略。
在ConvNeXt块和Swin Transformer块中引入了扩展深度卷积和两个跳过连接。因此,焦点块可以同时合并细粒度的本地交互和粗粒度的全局交互(焦点块名称的来源)。利用全局注意力[38,39]或大卷积核[5,40]来扩大感受野,近年来得到了广泛的研究。尽管取得了令人满意的结果,但由于输入图像大小较大,在将这些操作应用于密集预测任务时,通常会引入大量的计算成本和内存开销
结构变体(Architecture variants)
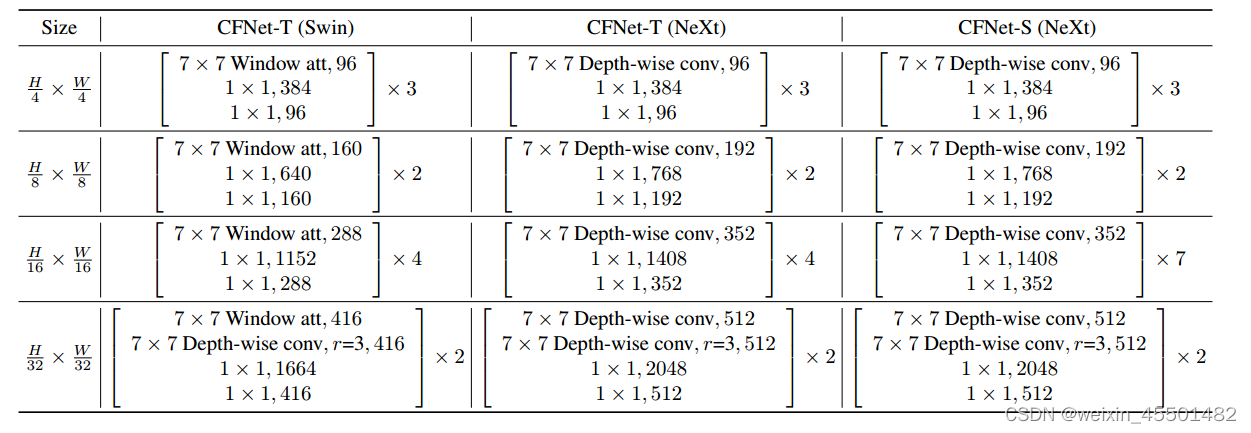
三种CFNet变体配置信息
我们设计了三个CFNet变体,即CFNet-T(Swin)、CFNet-T(NeXt)和CFNet-S(NeXt)。T和S分别是tiny和small两个词的缩写,表示模型大小。第一个使用Swin Transformer块和focal Swin块,另外两个使用ConvNeXt块和focal NeXt块。
上表列出了每个CFNet变体的详细配置。CFNet-T和CFNet-S的阶段数分别设置为3和4。尽管不同配置的stage可能会取得更好的性能,但为了简单起见,我们为所有阶段设置了相同的配置。所有focal块中的扩张率r默认设置为3。
我们构建了三个CFNet变体,即CFNet- t (Swin)、CFNet- t (NeXt)和CFNet- s (NeXt)。T和S分别是tiny和small这两个单词的缩写,表示模型的尺寸。第一个使用Swin Transformer块和焦点Swin块。另外两个使用ConvNeXt块和focal NeXt块。每个CFNet变体的详细配置如下表所示。Swin和NeXt分别表示使用Swin Transformer块和ConvNeXt块来构建CFNet。第一行显示了前N个块的配置。其他三行显示了每个阶段中三个块组的配置,并且所有阶段共享相同的配置。
实验
详细的验设计和实验结果见原文https://arxiv.org/abs/2302.06052
代码
代码地址:GitHub - zhanggang001/CFNet: CFNet: Cascade Fusion Network for Dense Prediction

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)