ReID讲解
通过最小化网络的度量损失,可以寻找一个最优的映射函数,使得相同行人的两张图片的距离尽可能小,不同行人的两张图片的距离尽可能大。通过最小化正例之间的距离同时最大化负例之间的距离,模型可以学习到一个好的特征表示,使得相似的行人之间的距离更近,而不相似的行人之间的距离更远。其中,d(a,p)表示锚点(anchor)和正样本(positive)之间的距离,d(a,n)表示锚点和负样本(negative)之
使用ReID的原因:
- 由于人脸的角度以及分辨率等问题,获取不到有效的人脸图像。
- 检测目标在镜头与镜头之间会有一段时间的消失,导致了空间与时间上的缺失。
ReID是什么?
ReID技术作为一种人脸识别的补充技术,主要用来解决跨摄像头、跨场景中的行人检索。ReID是与人脸识别类似的,本质就是利用算法在图像库中找到目标,通过行人目标的衣着、配饰、体态等进行特征提取匹配,属于图像检索问题。
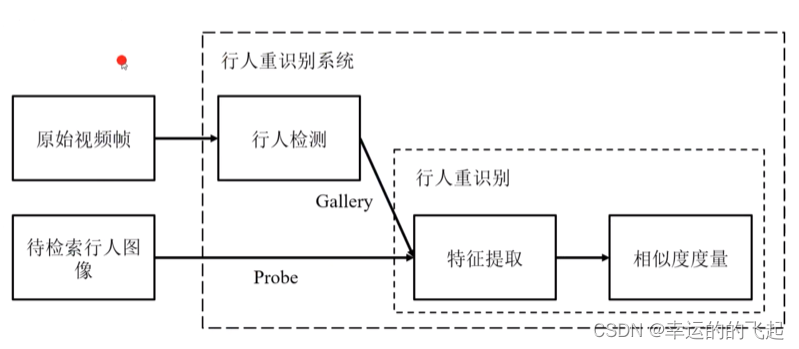
ReID思路流程:
- 获取监控视频中的多段视频
- 将视频中每一帧中的行人目标利用检测算法(YOLO、Faster-RCNN等)检测出来
- 利用检测算法将行人目标扣出来后,得到了一个由行人组成的图像底库(Gallery)
- 将想要检索的目标图像(Probe)与底库中的图像通过算法进行比较搜索,得到检索目标的轨迹
ReID的数据集:
数据集分为训练集、验证集、Query、Gallery。在训练集上进行ReID模型的训练,得到模型后对Query和Gallery中的图片提取特征计算相似度,对于灭个Query在Gallery中找出钱前N个与其相似的图片。并且训练、测试中人物身份是不重复的,每个行人都有唯一的ID。
常用的数据集:
| 数据集 | ID数 | 图片数 |
摄像头 (室内,室外) |
检测器 |
| CUHK03 | 1360 | 13164 | (10,0) | 手动+DPM |
| Market1501 | 1501 | 32643 | (0,6) | 手动+DPM |
| DukeMTMC-ReID | 1812 | 36441 | (0,8) | 手动 |
| MSMT7 | 4101 | 126411 | (3,12) | Faster RENN |
常用数据集下载地址:
 http://robustsystems.coe.neu.edu/sites/robustsystems.coe.neu.edu/files/systems/projectpages/reiddataset.html
http://robustsystems.coe.neu.edu/sites/robustsystems.coe.neu.edu/files/systems/projectpages/reiddataset.htmlReID的挑战:
- 低分辨率
- 遮挡
- 视角、姿势变化
- 光照变化
- 视觉模糊性
这些问题导致类内差异增大、类间差异减少。
ReID需要用到的基本算法:
目前的ReID都是基于深度学习实现的,训练CNN网络,进行特征的提取。
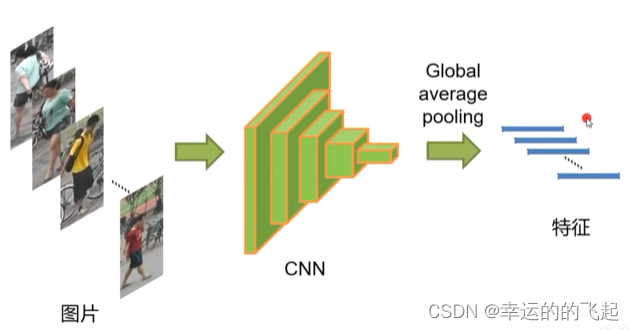
一般都会采用表征学习或者度量学习来实现在图像库中找到检索的目标。
表征学习:
把行人重识别任务当作分类问题或者验证问题来看待,相对应的就有分类损失(ID损失)函数和验证损失函数。
表征学习损失函数---分类损失(Identification):
也叫ID损失,利用行人的ID作为训练标签来训练模型,每次只需要输入一张图片。它帮助模型学习将输入数据正确分类到预定义的类别中。简单来说,把一个行人在所有场景下出现的图片作为一个类别,有多少行人就有多少个类别。例如,在market1501数据集中,有751个类别,那么最后一层输出神经元就有751个,损失函数即定义为分类错误率。
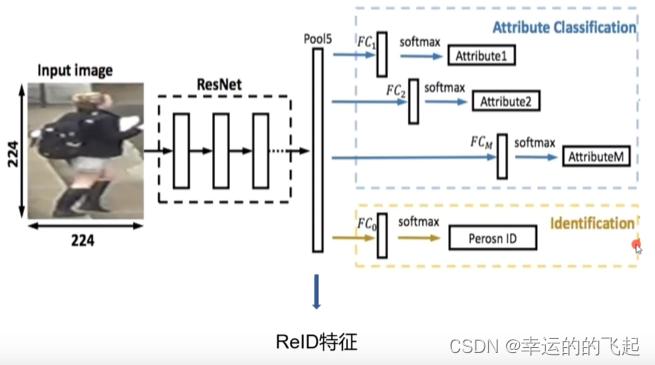
只有ID损失的网络称为ID Embedding网络(IDE网络)。IDE网络是ReID领域最基础的一个网络模型,类似于程序语言设计中的Hello world。特征层后接一个全连接层改变输出维度(与类别数匹配),经过Softmax激活函数计算交叉熵损失。测试阶段使用倒数第二层的特征向量进行检索,分类FC层丢弃。
常见的分类损失函数包括交叉熵损失(Cross-Entropy Loss)和softmax损失(Softmax Loss)。
表征学习损失函数---属性损失(Attribute Loss):
指通过对行人图片提取的特性进行训练,使得模型可以更好地对行人属性进行建模。用于学习数据的属性或特征。与分类损失不同,属性损失关注的是数据的属性信息,而不仅仅是将数据分类到预定义的类别中。
在进行Re-ID识别时,可以通过一些辅助特征来判断是否为同一人,比如衣服的颜色、头发的颜色等。这种网络的结构设计就是如果属性预测的准,那么最好得到的ID也就准。
常见的属性损失包括均方差损失(Mean Squared Error Loss)和对比损失(Contrastive Loss)。
属性损失的特点在于:
- 可以同时连接几个属性分类损失,增强ReID特征的性能。
- 每一个属性损失都是一个分类的交叉熵。
- 这种结构的网络可以理解为一个multi-task网络(多任务网络),因为有很多FC层。
- 测试的时候也是丢弃FC层,只用Pool层。
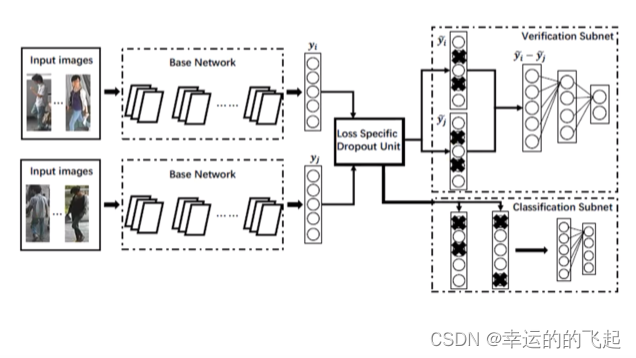
表征学习损失函数---验证损失(Verification loss):
输入一对(两张)行人图片,让网络来学习这两张图片是否属于同一个行人,等效于二分类问题。
验证损失在训练阶段可以和ID损失一起使用。网络的输入是一组图片,经过孪生网络后得到特征向量,最后网络输出0和1,判断两张图片是否是同一个人。在测试阶段,验证损失需要输入一对图片,效率相对较低。
验证损失通常用于模型训练过程中,用来评估模型在验证集上的性能。
验证损失的计算方式通常与模型任务类型有关。对于分类任务,常见的验证损失包括交叉熵损失(Cross-Entropy Loss)和准确率(Accuracy)。对于回归任务,常见的验证损失可以是均方差损失(Mean Squared Error Loss)或平均绝对误差(Mean Absolute Error)。
总的来说,表征学习在ReID中的应用主要是为了提取出能够反映行人个体差异的特征,以便实现高效的行人识别。
度量学习:
通过网络学习两张图片的相似度,同一行人的不同图片间的相似度大于不同行人的不同图片。
其基本思想是通过学习一个映射函数,将行人图片从原始域映射到特征域,并定义一个距离度量函数来计算两个特征向量之间的距离。通过最小化网络的度量损失,可以寻找一个最优的映射函数,使得相同行人的两张图片的距离尽可能小,不同行人的两张图片的距离尽可能大。这个映射函数就是我们训练得到的深度卷积网络。常用的度量函数包括欧氏距离和余弦距离。
在ReID中,度量学习可以通过以下步骤进行:
- 将行人图片输入到一个深度卷积网络中,提取出每个行人的特征向量。
- 通过计算特征向量之间的距离,评估不同行人之间的相似性。
- 使用一个距离度量函数(如欧氏距离或余弦距离)来进一步量化特征向量之间的相似性。
- 通过最小化网络的度量损失(如三元组损失、对比损失),不断调整网络参数,以优化映射函数和特征提取的性能。
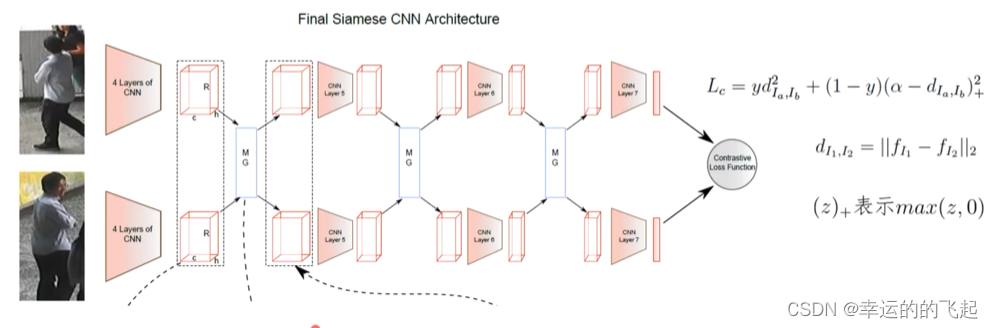
度量损失函数---对比损失(Contrastive loss):
通过比较两个样本之间的相似性来学习一个度量空间。对比损失函数通过将相似样本和不相似样本组合在一起,构成“正例”和“负例”,并最小化正例之间的距离同时最大化负例之间的距离来实现这一目标。
d(Ia,Ib)表示两张输入图片Ia和Ib之间的距离,y是一个标签,指示这两张图片是否属于同一个人。margin是一个预设的阈值,用于控制正样本对和负样本对之间的距离。
当输入为正样本对时,dIa,Ib会逐渐减小,相同ID的行人图片会持续在特征空间形成聚类。当网络输入负样本对时,dIa,Ib会逐渐变大,直到超过设定的a。通过最小化损失函数,最后可以使正样本对之间距离逐渐变小,负样本对之间距离逐渐变大,从而满足行人重识别任务的需要。
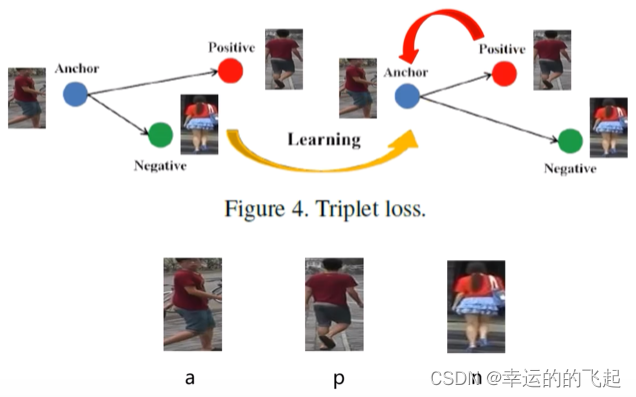
度量损失函数---三元组损失(Triplet loss):
基本思想是将样本组织成三元组,其中两个样本是正例(相似),另一个样本是负例(不相似)。通过最小化正例之间的距离同时最大化负例之间的距离,模型可以学习到一个好的特征表示,使得相似的行人之间的距离更近,而不相似的行人之间的距离更远。
三元组损失函数的定义如下:
L = d(a,p)^2 - d(a,n)^2 + margin
其中,d(a,p)表示锚点(anchor)和正样本(positive)之间的距离,d(a,n)表示锚点和负样本(negative)之间的距离,margin是一个预设的阈值,用于控制正样本对和负样本对之间的距离。
在训练过程中,网络会学习到一个映射函数,将行人图片从原始域映射到特征域。通过最小化三元组损失函数,网络可以找到一个最优的映射函数,使得相同行人的三个图片的距离尽可能小,不同行人的三个图片的距离尽可能大。这个映射函数就是我们训练得到的深度卷积网络。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)