self-attention的介绍和代码手写
self-Attention的介绍和代码实践
self-Attention
self-Attention架构
self-attention的运作方式就是,输入一排vector,输出一排vector.
输出的vector是考虑了输入的所有向量的信息.

- self-attention可以叠加很多次.

可以把全连接层(FC)和Self-attention交替使用.
- Self-attention处理整个Sequence的信息
- FC的Network,专注于处理某一位置的咨询
Self-Attention的过程
-
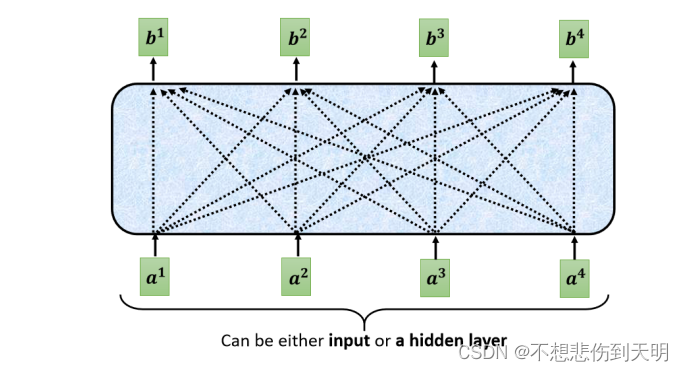
它的一个架构是这样的,输出的一排 b b b 是 a a a经过计算输出的.
-
b 1 b^{1} b1是考虑了 a 1 , a 2 , a 3 , a 4 a^{1},a^{2},a^{3},a^{4} a1,a2,a3,a4后产生的.
-
b 2 , b 3 , b 4 b^{2},b^{3},b^{4} b2,b3,b4也是考虑了 a 1 , a 2 , a 3 , a 4 a^{1},a^{2},a^{3},a^{4} a1,a2,a3,a4后产生的,它们的计算原理是一样的.
计算两个输入vector相关性

-
比较常见的两种计算方法 : dot product 以及 Additive
-
其中,第一种方法, 首先让这两个向量先乘一个W(这两个w是不同的,一个是weight_q ,一个是weight_k),分别得到 q , k q,k q,k,然后再做内积,得到一个score α i , j \alpha _{i,j} αi,j 表示计算 a i 和 a j a_{i}和a_{j} ai和aj的相关性.

-
然后 a 1 a^{1} a1 分别和 a 2 , a 3 , a 4 a^{2},a^{3},a^{4} a2,a3,a4计算相似度. a 1 a^{1} a1的 q 1 q^{1} q1分别和 a 2 , a 3 , a 4 a^{2},a^{3},a^{4} a2,a3,a4的 k 2 , k 3 , k 4 k^{2},k^{3},k^{4} k2,k3,k4做内积得到attention scorce a 1 , 2 a_{1,2} a1,2, a 1 , 3 a_{1,3} a1,3, a 1 , 4 a_{1,4} a1,4, 在实际操作中也会计算 a 1 a^{1} a1和自己的相似度.
-
接下来将 a 1 , 1 , a 1 , 2 a_{1,1},a_{1,2} a1,1,a1,2, a 1 , 3 a_{1,3} a1,3, a 1 , 4 a_{1,4} a1,4, 经过一个soft-max层得到 a 1 , 1 ′ a^{'}_{1,1} a1,1′ a 1 , 2 ′ a^{'}_{1,2} a1,2′ …

-
然后把 a 1 a^{1} a1到 a 4 a^{4} a4的每一个向量乘上 W v W^{v} Wv得到新的向量,分别得到 v 1 , v 2 , v 3 , v 4 v^{1},v^{2},v^{3},v^{4} v1,v2,v3,v4
-
接下来将 v 1 v^{1} v1到 v 4 v^{4} v4,每一个向量都去乘上Attention score的分数,然后在加起来得到 b 1 b^{1} b1
b 1 = ∑ i α 1 , i ′ v i b^{1} = \sum_{i}\alpha_{1,i}^{'}v^{i} b1=i∑α1,i′vi -
同理, a 2 , a 3 , a 4 a^{2},a^{3},a^{4} a2,a3,a4也做一样的操作得到 b 2 , b 3 , b 4 b^{2},b^{3},b^{4} b2,b3,b4 .
矩阵的角度
每一个input的vector都会产生一组 q i , k i , v i q^{i} ,k^{i},v^{i} qi,ki,vi

因此,我们将每一个 a i a^{i} ai左乘上一个 w q w^{q} wq矩阵, 做矩阵乘法就可以得到Q矩阵,Q矩阵的每一个列就是每一个input a i a^{i} ai的 q i q^{i} qi.

同理每一组 k i , v i k^{i} ,v^{i} ki,vi 也是一样可以用矩阵计算.
我们知道,每一个attention a i , j a_{i,j} ai,j代表第i个input的 q i q^{i} qi和第j个input的 k j k^{j} kj内积得到.
那么,这四个步骤操作,可以用矩阵和向量相乘得到.
进而,我们可以计算所有的attention ,并经过一个softmax得到 A ′ A^{'} A′
而 b 1 b^{1} b1是通过使用 v i v^{i} vi左乘 A ′ A^{'} A′的得到,

回顾

图(15)
- I 是 self-attention的 input ,Self-attention的input是一排的vector,这排vector拼起来当做矩阵的列.
- input分别乘上三个矩阵 w q , w k , w v w^{q} ,w^{k} , w^{v} wq,wk,wv 就得到了 Q,K,V .
- 接下来,Q乘上K的转置,得到矩阵A,在经过softmax处理得到 A ′ A^{'} A′,然后左乘V就得到Output.
- 因此,self-attention里面唯一要学习的参数是W矩阵,这是需要network train的部分.
代码实例
例子分为以下步骤:
- 准备输入
- 初始化权重
- 导出key, query and value的表示
- 计算注意力得分(attention scores)
- 计算softmax
- 将attention scores乘以value
- 对加权后的value求和以得到输出
假设输入:
Input 1: [1, 0, 1, 0]
Input 2: [0, 2, 0, 2]
Input 3: [1, 1, 1, 1]
初始化参数
由于我们的input 是3个4维的vector,由图(15)需要左乘W,W的维度设置为(4,3),
w k , w q , w v w^{k} ,w^{q},w^{v} wk,wq,wv分别是 w_key ,w_query,w_value.
x = [
[1,0,1,0], # 输入1
[0,2,0,2], #输入2
[1,1,1,1], #输入3
]
x = torch.tensor(x,dtype=torch.float32)
# 初始化权重
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
# 转化成tensor数据类型
w_key = torch.tensor(w_key,dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
查看QKV

querys = torch.tensor(np.dot(x,w_query),dtype=torch.float32)

keys = torch.tensor(np.dot(x,w_key) ,dtype=torch.float32)
计算attention
# get attention scorce
attention_scores = torch.tensor(np.dot(querys,keys.T))
softmax处理
# 计算soft-max
attention_scores_softmax = torch.tensor( softmax(attention_scores,dim=-1) )
将attention scores乘以value
weight_values = values[:,None] * attention_scores_softmax.T[:,:,None]
对加权后的value求和以得到输出
outputs = weight_values.sum(dim=0)
测试代码
import torch
import numpy as np
from torch.nn.functional import softmax
def preData():
#
x = [
[1,0,1,0], # 输入1
[0,2,0,2], #输入2
[1,1,1,1], #输入3
]
x = torch.tensor(x,dtype=torch.float32)
# 初始化权重
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
# 转化成tensor数据类型
w_key = torch.tensor(w_key,dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
# get K, Q,V
keys = torch.tensor(np.dot(x,w_key) ,dtype=torch.float32)
querys = torch.tensor(np.dot(x,w_query),dtype=torch.float32)
values = torch.tensor(np.dot(x,w_value),dtype=torch.float32)
# get attention scorce
attention_scores = torch.tensor(np.dot(querys,keys.T))
print(attention_scores)
# 计算soft-max
attention_scores_softmax = torch.tensor( softmax(attention_scores,dim=-1) )
print(values.shape)
weight_values = values[:,None] * attention_scores_softmax.T[:,:,None]
outputs = weight_values.sum(dim=0)
return outputs
if __name__ == "__main__" :
b = preData()
print(b)
参考

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)