基于 librosa 的 LFCC 和 CQCC 特征提取
本文实现了基于 librosa 的 LFCC 和 CQCC 特征提取,主要参考 librosa 中 MFCC 特征提取的过程,同时使用 torchaudio 来验证 LFCC 的正确性,使用 matlab 来验证 CQCC 的正确性。
本文实现了基于 librosa 的 LFCC 和 CQCC 特征提取,主要参考 librosa 中 MFCC 特征提取的过程,同时使用 torchaudio 来验证 LFCC 的正确性,使用 matlab 来验证 CQCC 的正确性。
LFCC
原理
LFCC 和 MFCC 的区别就是 fliter bank 的不同,MFCC 用的是 mel freq 的滤波器组,而 LFCC 用的是频率为线性分布的滤波器组,因此只要改变 MFCC 中滤波器组的获得方式保持其他代码不变即可。
实现
基于 librosa 库实现的 LFCC 如下:
import warnings
import numpy as np
import librosa
import scipy
def linear(sr, n_fft, n_filters=128, fmin=0.0, fmax=None, dtype=np.float32):
if fmax is None:
fmax = float(sr) / 2
# Initialize the weights
n_filters = int(n_filters)
weights = np.zeros((n_filters, int(1 + n_fft // 2)), dtype=dtype)
# Center freqs of each FFT bin
fftfreqs = librosa.fft_frequencies(sr=sr, n_fft=n_fft)
# 'Center freqs' of liner bands - uniformly spaced between limits
# * Need to validate
linear_f = np.linspace(fmin, fmax, n_filters + 2)
fdiff = np.diff(linear_f)
ramps = np.subtract.outer(linear_f, fftfreqs)
for i in range(n_filters):
# lower and upper slopes for all bins
lower = -ramps[i] / fdiff[i]
upper = ramps[i + 2] / fdiff[i + 1]
# .. then intersect them with each other and zero
weights[i] = np.maximum(0, np.minimum(lower, upper))
# Only check weights if f_mel[0] is positive
if not np.all((linear_f[:-2] == 0) | (weights.max(axis=1) > 0)):
# This means we have an empty channel somewhere
warnings.warn(
"Empty filters detected in linear frequency basis. "
"Some channels will produce empty responses. "
"Try increasing your sampling rate (and fmax) or "
"reducing n_filters.",
stacklevel=2,
)
return weights
def linear_spec(
y=None,
sr=22050,
S=None,
n_fft=2048,
hop_length=512,
win_length=None,
window='hann',
center=True,
pad_mode='constant',
power=2.0,
**kwargs
):
if S is not None:
# Infer n_fft from spectrogram shape, but only if it mismatches
if n_fft // 2 + 1 != S.shape[-2]:
n_fft = 2 * (S.shape[-2] - 1)
else:
S = (
np.abs(
librosa.stft(
y,
n_fft=n_fft,
hop_length=hop_length,
win_length=win_length,
center=center,
window=window,
pad_mode=pad_mode,
)
)
** power
)
# Build a linear filter
linear_basis = linear(sr=sr, n_fft=n_fft, **kwargs)
return np.einsum("...ft,mf->...mt", S, linear_basis, optimize=True)
def expand_to(x, *, ndim, axes):
try:
axes = tuple(axes)
except TypeError:
axes = tuple([axes])
if len(axes) != x.ndim:
raise Exception(
"Shape mismatch between axes={} and input x.shape={}".format(
axes, x.shape)
)
if ndim < x.ndim:
raise Exception(
"Cannot expand x.shape={} to fewer dimensions ndim={}".format(
x.shape, ndim)
)
shape = [1] * ndim
for i, axi in enumerate(axes):
shape[axi] = x.shape[i]
return x.reshape(shape)
def lfcc(y=None,
sr=22050,
S=None,
n_lfcc=20,
dct_type=2,
norm='ortho',
lifter=0,
**kwargs):
if S is None:
S = librosa.power_to_db(linear_spec(y=y, sr=sr, **kwargs))
M = scipy.fftpack.dct(S, axis=-2, type=dct_type,
norm=norm)[..., :n_lfcc, :]
if lifter > 0:
# shape lifter for broadcasting
LI = np.sin(np.pi * np.arange(1, 1 + n_lfcc, dtype=M.dtype) / lifter)
LI = expand_to(LI, ndim=S.ndim, axes=-2)
M *= 1 + (lifter / 2) * LI
return M
elif lifter == 0:
return M
else:
raise Exception(
"LFCC lifter={} must be a non-negative number".format(lifter)
)
用 torchaudio 现有的函数进行验证:
import torchaudio
import librosa
from torchaudio.transforms import LFCC
path = ''
# torchaudio
waveform, sample_rate = torchaudio.load(full_path)
print(waveform.shape)
lfcc_transform = LFCC(
sample_rate=sample_rate,
n_lfcc=13,
n_filter=128,
speckwargs={"n_fft": 512, "hop_length": 160, },
)
torch_lfcc = lfcc_transform(waveform)
print(torch_lfcc[0, :, 0])
# librosa
wave, sr = librosa.load(full_path, sr=16000)
print(wave.shape)
librosa_lfcc = lfcc(
y=wave, sr=sr, n_lfcc=13, n_fft=512, hop_length=240, n_filters=128, pad_mode='reflect')
print(librosa_lfcc[:, 0])
运行结果为: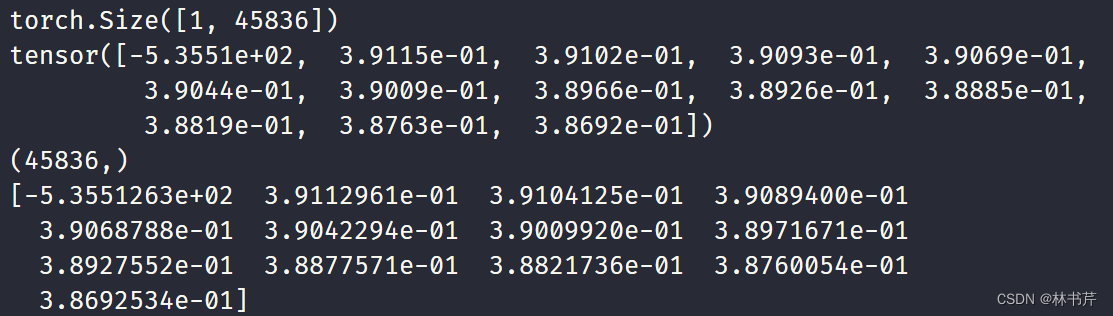
两者得到的结果基本一致。
CQCC
原理
STFT 和 CQT 可以看成是时间信号频域分析的两个同级的方法。
在 STFT 中,从长的序列中提取固定长度的片段与窗函数相乘后进行 FFT,然后重复应用滑动窗口得到最终的谱图。
STFT 实际上是一个滤波器组,定义 Q 因子为滤波器的中心频率和滤波器带宽之比:Q=fkδfQ=\frac{f_k}{\delta f}Q=δffk在STFT 中,每个滤波器的带宽是恒定的,当频率从低频到高频时,Q 因子增加。
但是人类的感知系统的 Q 因子在 500Hz-20KHz 之间近似常数,因此,至少从感知角度来看,STFT对于语音信号的时频分析可能并不理想。
于是提出 CQT 变换,第一种算法由Youngberg和Boll于1978年提出的(Youngberg-Boll),而另一种算法则是由 Kashima 和MontReynaud-Kashima在1986年提出(Mont Reynaud)。在这些方法中,倍频程(octaves)是几何分布的,如下图: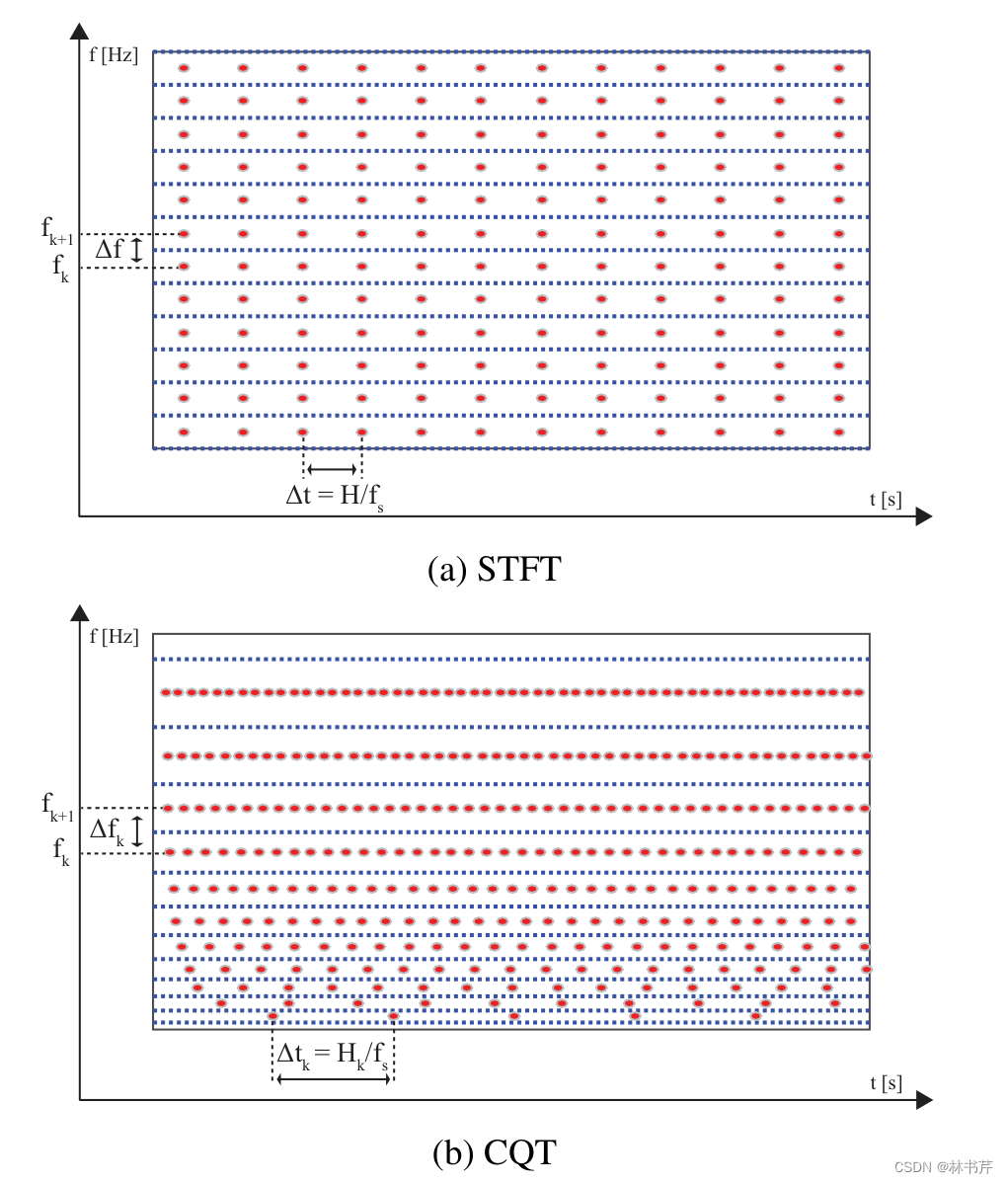
CQT 计算
离散时域信号 x(n)x(n)x(n) 的 CQT 计算如下:
XCQ(k,n)=∑j=n−⌊Nk/2⌋n+⌊Nk/2⌋x(j)ak∗(j−n+Nk/2)X^{C Q}(k, n)=\sum_{j=n-\left\lfloor N_k / 2\right\rfloor}^{n+\left\lfloor N_k / 2\right\rfloor} x(j) a_k^*\left(j-n+N_k / 2\right)XCQ(k,n)=j=n−⌊Nk/2⌋∑n+⌊Nk/2⌋x(j)ak∗(j−n+Nk/2)
其中,k=1,2,⋯ ,Kk = 1,2,\cdots, Kk=1,2,⋯,K 为频率索引,ak∗(n)a_k^*(n)ak∗(n) 为 ak(n)a_k(n)ak(n) 的复共轭,NkN_kNk 为可变的窗口大小,⌊⋅⌋\left\lfloor \cdot \right\rfloor⌊⋅⌋ 代表向下取整,基函数 ak(n)a_k(n)ak(n) 定义如下:
ak(n)=1C(nNk)exp[i(2πnfkfs+Φk)]a_k(n)=\frac{1}{C}\left(\frac{n}{N_k}\right) \exp \left[i\left(2 \pi n \frac{f_k}{f_s}+\Phi_k\right)\right]ak(n)=C1(Nkn)exp[i(2πnfsfk+Φk)]
其中,fkf_kfk 是第 kkk 个频带的中心频率,fsf_sfs 为采样率,w(t)w(t)w(t) 为窗函数,Φk\Phi_kΦk 为相位偏置,缩放因子 CCC 由下式给出:
C=∑l=−⌊Nk/2⌋⌊Nk/2⌋w(l+Nk/2Nk)C=\sum_{l=-\left\lfloor N_k / 2\right\rfloor}^{\left\lfloor N_k / 2\right\rfloor} w\left(\frac{l+N_k / 2}{N_k}\right)C=l=−⌊Nk/2⌋∑⌊Nk/2⌋w(Nkl+Nk/2)
为了满足恒Q变换,中心频率必须满足:
fk=f12k−1Bf_k=f_1 2^{\frac{k-1}{B}}fk=f12Bk−1
其中,f1f_1f1 是最低频率带的中心频率,BBB 确定每个倍频程的频带数。
例如,假设 B=1B=1B=1,则 fk=f12k−1f_k = f_1 2^{k-1}fk=f12k−1 ,取 fs=8000Hz,f1=500Hzf_s=8000Hz, f_1 = 500Hzfs=8000Hz,f1=500Hz,则 f2=1000Hz,f3=2000Hz,f4=4000Hz,f5=8000Hzf_2=1000Hz, f_3=2000Hz, f_4=4000Hz, f_5=8000Hzf2=1000Hz,f3=2000Hz,f4=4000Hz,f5=8000Hz,不能再大了。而在DFT中,这几个频率呈线性变化。
则 Q 因子计算如下:
Q=fkfk+1−fk=(21/B−1)−1Q=\frac{f_k}{f_{k+1}-f_k}=\left(2^{1 / B}-1\right)^{-1}Q=fk+1−fkfk=(21/B−1)−1
同时窗函数长度 NkN_kNk 满足:
Nk=fsfkQN_k=\frac{f_s}{f_k} QNk=fkfsQ
CQCC 提取
首先 MFCC 计算如下:
MFCC(q)=∑m=1Mlog[MF(m)]cos[q(m−12)πM]\operatorname{MFCC}(q)=\sum_{m=1}^M \log [M F(m)] \cos \left[\frac{q\left(m-\frac{1}{2}\right) \pi}{M}\right]MFCC(q)=m=1∑Mlog[MF(m)]cos[Mq(m−21)π]
其中,Mel 谱计算如下:
MF(m)=∑k=1K∣XDFT(k)∣2Hm(k)M F(m)=\sum_{k=1}^K\left|X^{D F T}(k)\right|^2 H_m(k)MF(m)=k=1∑K
XDFT(k)
2Hm(k)
其中,kkk 是DFT之后的频率索引系数,Hm(k)H_m(k)Hm(k) 是第 mmm 个Mel 尺度下的三角加权函数带通滤波器。这里,MMM 代表滤波器的个数(MF(m)M F(m)MF(m) 为 MMM 点的序列),qqq 代表离散余弦变换的点数。
倒谱分析不能直接被用于 CQT,因为 XCQ(k)X^{C Q}(k)XCQ(k) 和 DCT 的余弦函数的尺度不同(一个是几何一个是线性)。可以通过将几何空间转换为线性空间来解决这个问题。
由于在 XCQ(k)X^{C Q}(k)XCQ(k) 中,kkk 个频带几何分布,信号重构的过程可以看成是前 kkk 个频带(低频部分)进行下采样,后 K−kK-kK−k 个频带(高频部分)进行上采样得到的,将第 kkk 个频带的中心频率 fkf_kfk 和 第一个频带的中心频率 f1=fminf_1=f_{min}f1=fmin 的频率差记为:
Δfk↔1=fk−f1=f1(2k−1B−1)\Delta f^{k \leftrightarrow 1}=f_k-f_1=f_1\left(2^{\frac{k-1}{B}}-1\right)Δfk↔1=fk−f1=f1(2Bk−1−1)
其中,k=1,2,⋯ ,Kk = 1,2,\cdots, Kk=1,2,⋯,K 为频率索引,距离 Δfk↔1\Delta f^{k \leftrightarrow 1}Δfk↔1 为 kkk 的递增函数。我们以周期 TlT_lTl 进行重采样,这等效于确定一个关于 klk_lkl 的函数使得:
Tl=Δfkl↔1T_l=\Delta f^{k_l \leftrightarrow 1}Tl=Δfkl↔1
以下关注第一个倍频程,通过将第一个倍频程以周期 TlT_lTl 进行 ddd 等分,解得 klk_lkl 为:
f1d=f1(2kl−1B−1)→kl=Blog2(1+1d)\frac{f_1}{d}=f_1\left(2^{\frac{k_l-1}{B}}-1\right) \rightarrow k_l=B \log _2\left(1+\frac{1}{d}\right)df1=f1(2Bkl−1−1)→kl=Blog2(1+d1)
新的频率计算为:
Fl=1Tl=[f1(2kl−1B−1)]−1F_l=\frac{1}{T_l}=\left[f_1\left(2^{\frac{k_l-1}{B}}-1\right)\right]^{-1}Fl=Tl1=[f1(2Bkl−1−1)]−1
因此,在第一个倍频程中有 ddd 个均匀采样,第二个倍频程中有 2d2d2d 个,第 j−1j-1j−1 个倍频程中有 2jd2^jd2jd 个。
信号重构方法采用了多相抗混叠滤波器和样条插值方法,以均匀的采样率 FlF_lFl 对信号进行重新采样。
最后,CQCC 系数计算如下:
CQCC(p)=∑l=1Llog∣XCQ(l)∣2cos[p(l−12)πL]C Q C C(p)=\sum_{l=1}^L \log \left|X^{C Q}(l)\right|^2 \cos \left[\frac{p\left(l-\frac{1}{2}\right) \pi}{L}\right]CQCC(p)=l=1∑Llog
XCQ(l)
2cos[Lp(l−21)π]
其中,p=0,1,⋯ ,L−1p=0,1,\cdots,L-1p=0,1,⋯,L−1 是重采样之后得频带索引。
我理解是,比如说设置 d=5d=5d=5 ,频率 500−1000Hz500-1000Hz500−1000Hz 之间采样就可以分成五个 500,600,700,800,900500,600,700,800,900500,600,700,800,900,而频率 1000−2000Hz1000-2000Hz1000−2000Hz 之间采样分成 2d=102d=102d=10 个频带,即 1000,1100,1200,⋯ ,19001000,1100,1200,\cdots,19001000,1100,1200,⋯,1900,同理频率范围在 2000−4000Hz2000-4000Hz2000−4000Hz 之间的频率可以分成 22∗5=202^2*5=2022∗5=20 个频带,以此类推。这样虽然两两中心频率之间是几何间隔,但是采样的数量也是呈几何增长,所以最终重采样得到的频率还是线性的,从而可以进行 DCT 变换。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)