mmfewshot训练自定义VOC格式数据集
修改tools/detection/misc/initialize_bbox_head.py文件中voc_tar_size为所有类别数量,src1为上一步latest.pth文件路径,save-dir为转换后权重储存路径,method为权重初始化方法,这里选择random-init。修改configs/detection/fsce/voc/split1/fsce_r101_fpn_voc_spli
参考博客:mmFewShot框架的配置、使用和训练-CSDN博客
一、配置环境
1、代码下载链接:open-mmlab/mmfewshot: OpenMMLab FewShot Learning Toolbox and Benchmark (github.com)
2、创建环境
conda create -n mmfewshot python=3.7 #创建名为mmfewshot的环境
conda activate mmfewshot #激活环境3、pytorch安装
这里我安装的是torch1.11.0 + cuda11.3
pytorch官网链接:PyTorch
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch4、mmfewshot框架环境配置
注意:这里最好依次安装,因为包之间有版本依赖,官方一步到位安装方式,很大概率后续跑代码会出错。
依次安装mmcv-full、mmcls、mmdet、mmfewshot,注意mmcv-full、mmcls、mmdet之间相互有依赖,安装不准确,后续跑代码会出现问题。以下安装版本亲测可用
pip install mmcv-full==1.6.0 mmcls==0.23.2 mmdet==2.25.0 mmfewshot==0.1.0注意:安装好mmfewshot之后,修改anaconda/envs/{所配置的环境名称} 的mmfewshot/detection/voc.py的类别为自己的类别,不改后续有可能出现所有类别AP为0的情况
5、其他包安装
cd到mmfewshot-main代码文件夹下,安装requirements.txt中相关包
cd mmfewshot-main
pip install -r requirements/build.txt二、数据集准备
(1)本人数据集配置:总共3个类别,其中taoguan和naizhangxianjia为基类,birdnest为新类
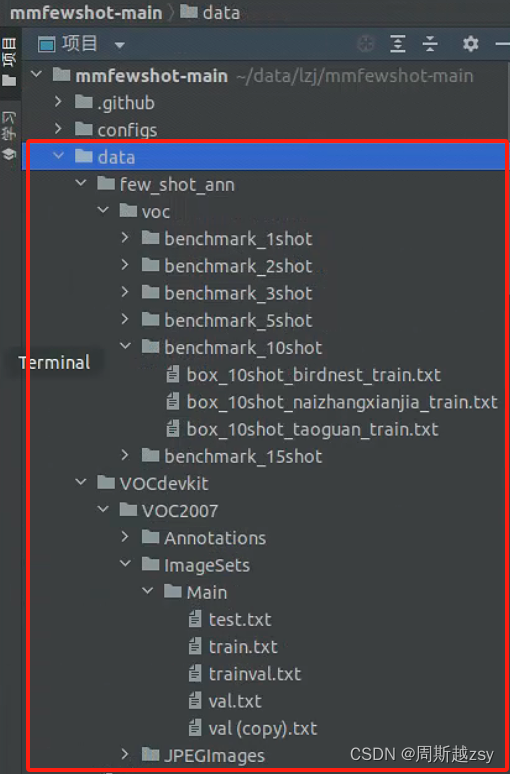
(2)数据集结构说明:
data/few_shot_ann/voc/benchmark_{实例数量}shot 下储存第二阶段迁移训练图像 txt文件,文件名称命名为 box_{实例数量}shot_{类别名称}_train.txt ;
data/VOCdevkit/VOC2007/Annotations下储存所有图像xml格式标签文件(所有=基类+新类);data/VOCdevkit/VOC2007/ImageSets/Main储存所有图像训练、验证、测试txt文件;
data/VOCdevkit/VOC2007/JPEGImages下储存所有图像
三、数据集训练与测试(以FSCE模型为例)
(1)基础训练
配置好环境,准备好数据集后开始修改代码
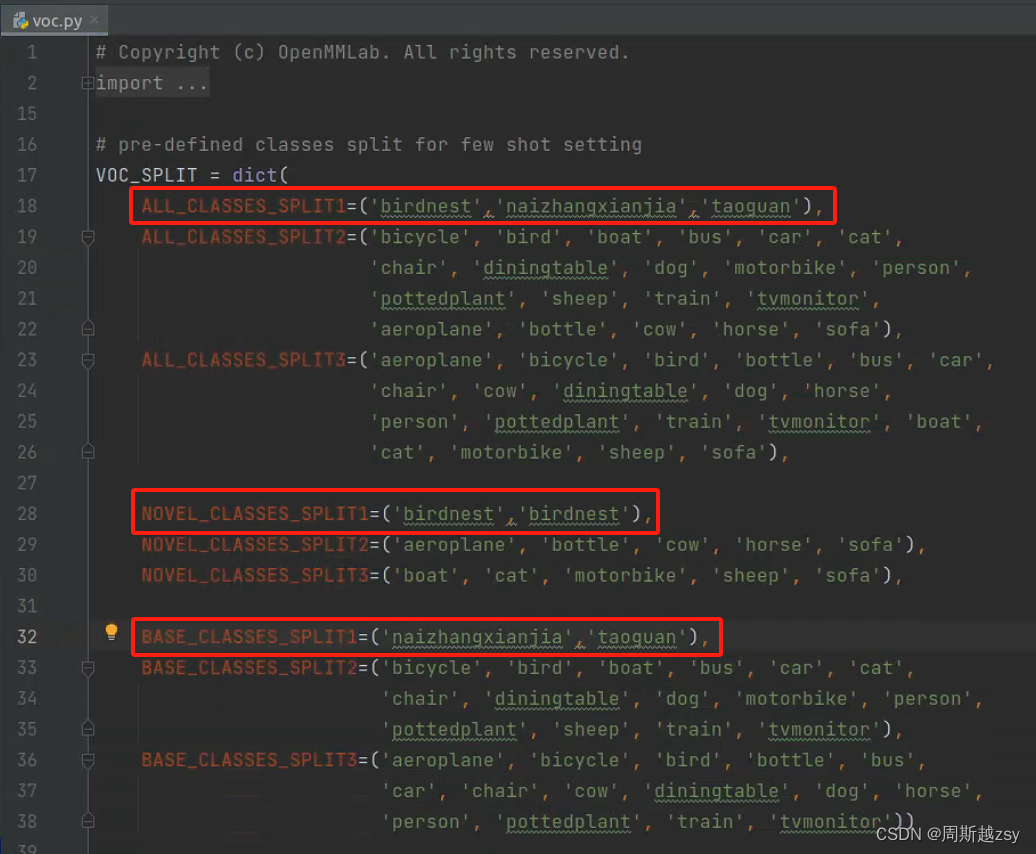
修改mmfewshot/detection/datasets/voc.py中类别为自己的类别
注意:如果新类只有一个类别的话 ,需要写两次,不然后面会出现 keyword:xxx not in classes 的报错(也有不写两次的其他解决方法,但是从debug的结果来看,这个比较方便)
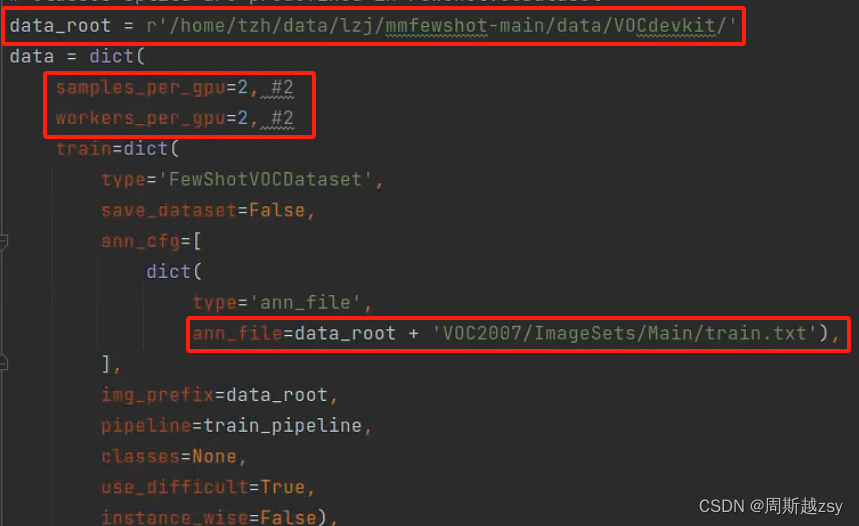
修改configs/detection/_base_/datasets/fine_tune_based/base_voc.py
data_root为自定义数据集根目录,samples_per_gpu为batchsize参数,修改ann_file路径
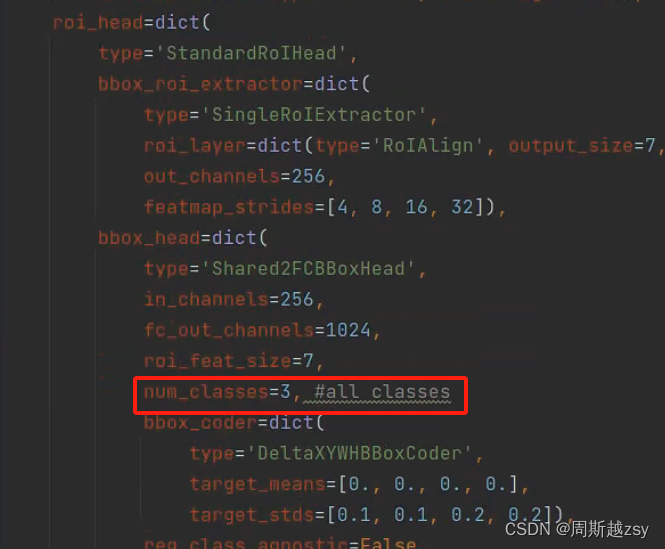
修改configs/detection/_base_/models/faster_rcnn_r50_caffe_fpn.py中num_classes为所有类别数
修改configs/detection/fsce/fsce_r101_fpn.py中num_classes和scale为所有类别数量
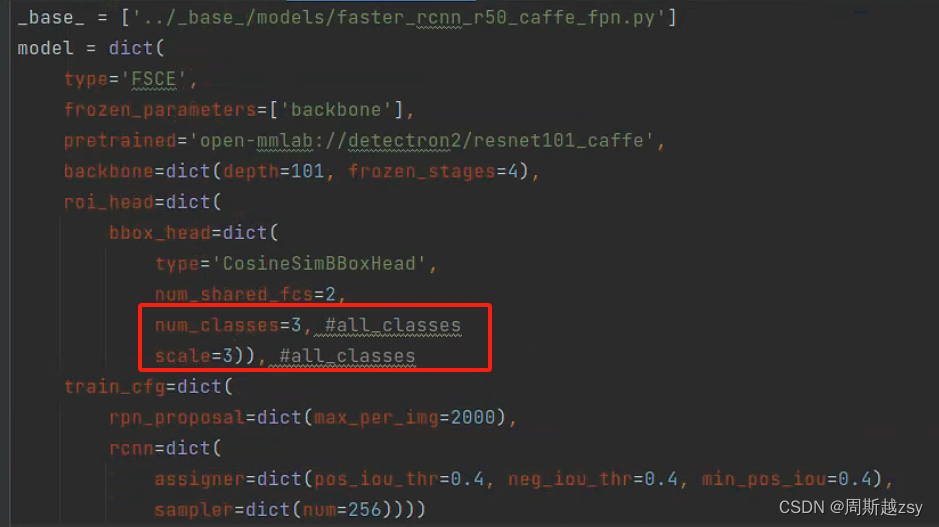
修改configs/detection/fsce/voc/split1/fsce_r101_fpn_voc_split1_base_training.py中max_iter迭代次数、num_classes为基类数量
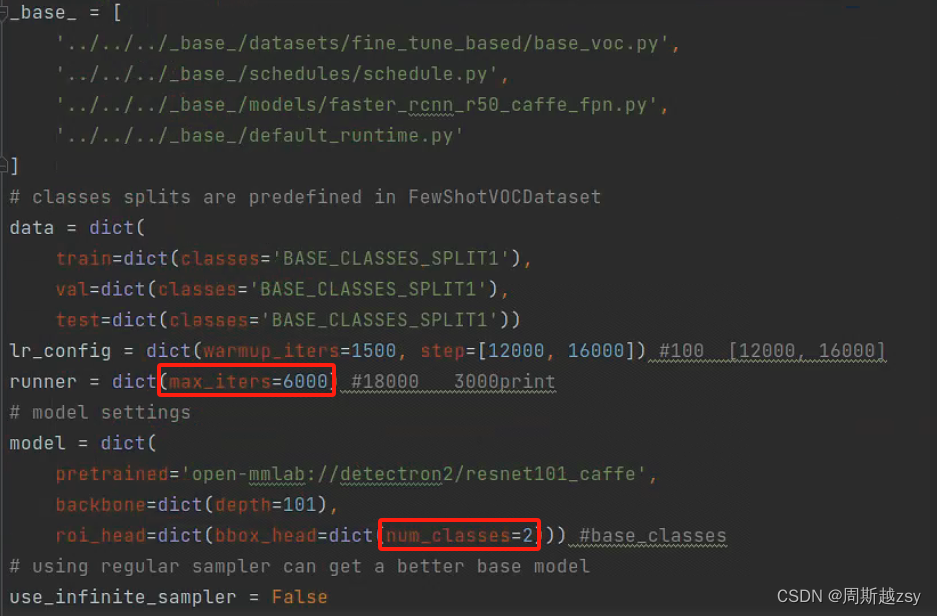
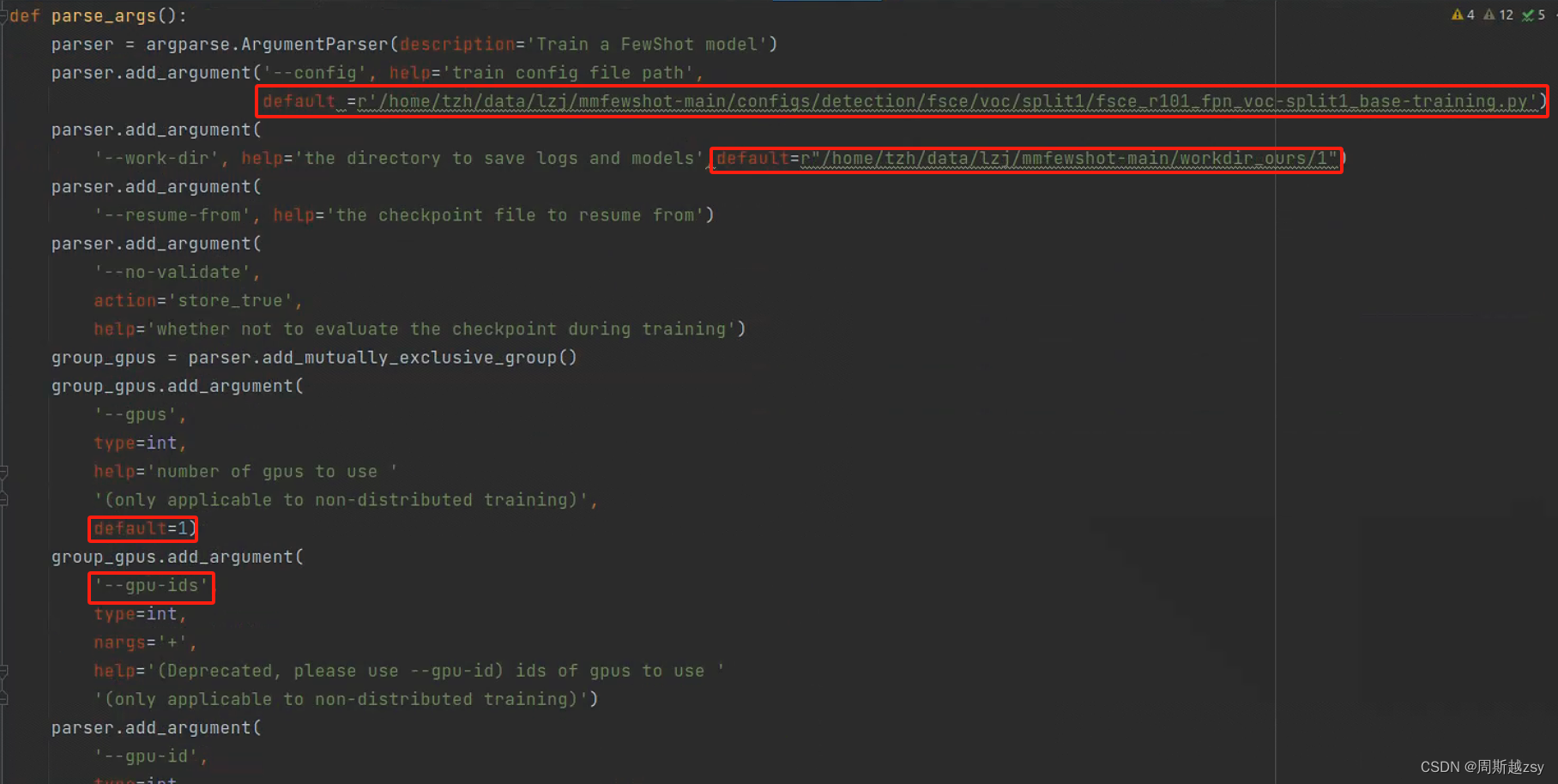
开始训练:修改tools/detection/train.py
修改config为上一步的py文件路径,work-dir为训练日志储存路径,gpus为采用多少gpu进行训练,修改后运行
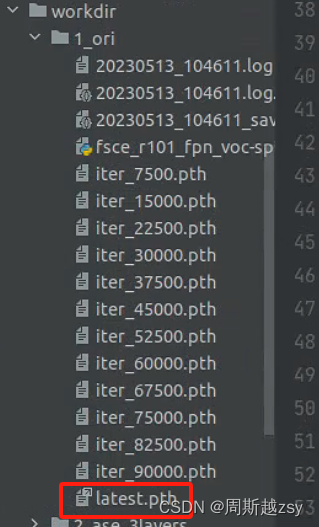
基础训练完毕后在上一步work-dir参数指定路径中产生latest.pth文件
(2)检测头初始化
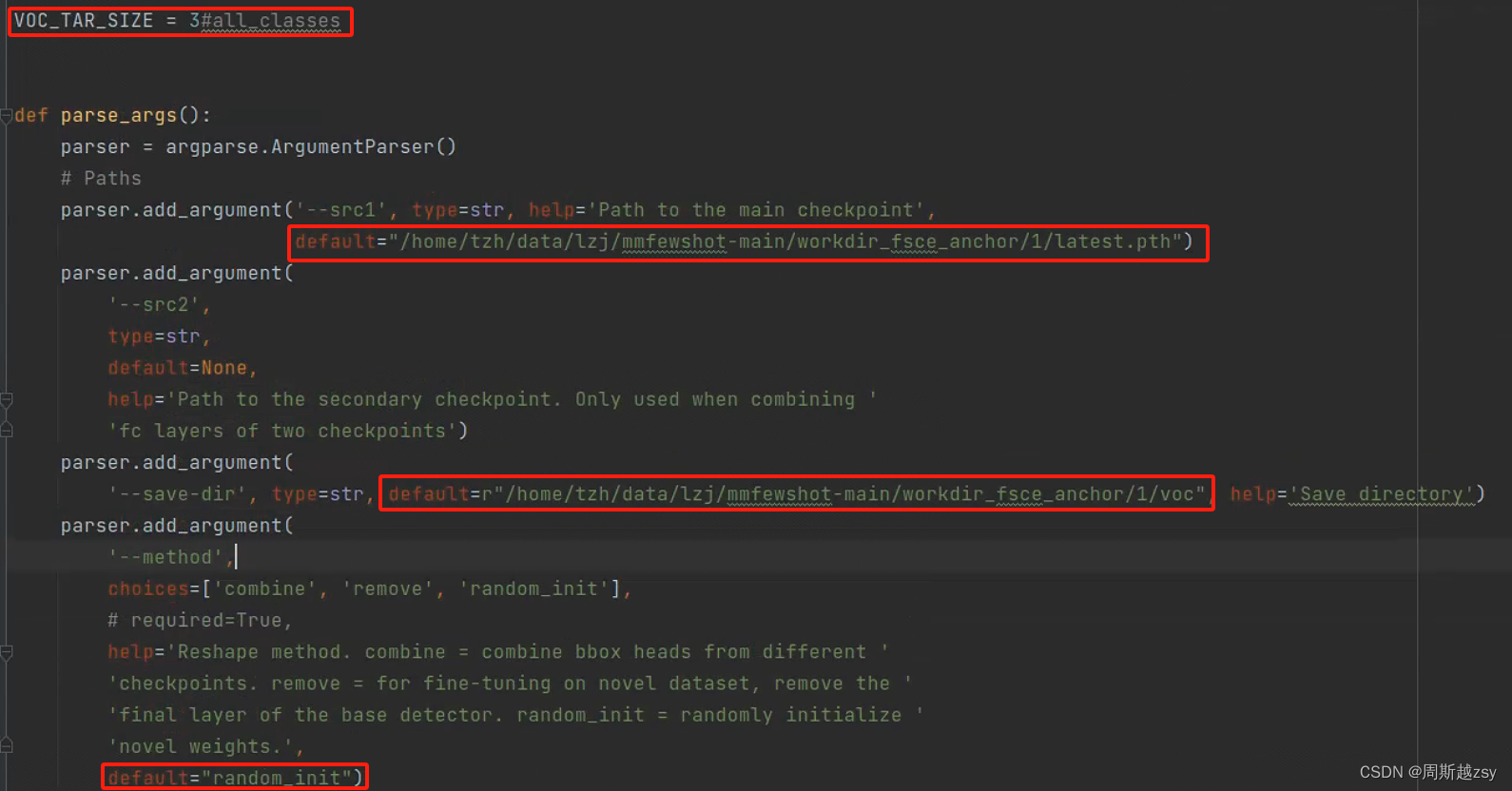
修改tools/detection/misc/initialize_bbox_head.py文件中voc_tar_size为所有类别数量,src1为上一步latest.pth文件路径,save-dir为转换后权重储存路径,method为权重初始化方法,这里选择random-init
修改后运行,得到base_model_random_init_bbox_head.pth文件
(3)迁移训练
这里以10shot为例
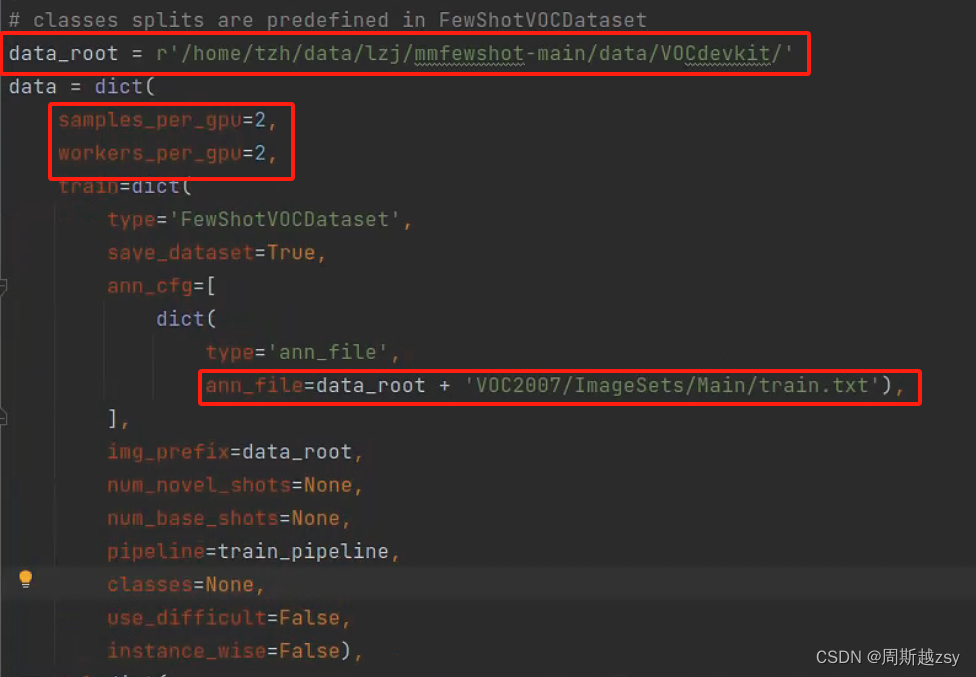
修改configs/detection/_base_/datasets/fine_tune_based/few_shot_voc.py
data_root为自定义数据集根目录,samples_per_gpu为batchsize参数,修改ann_file路径
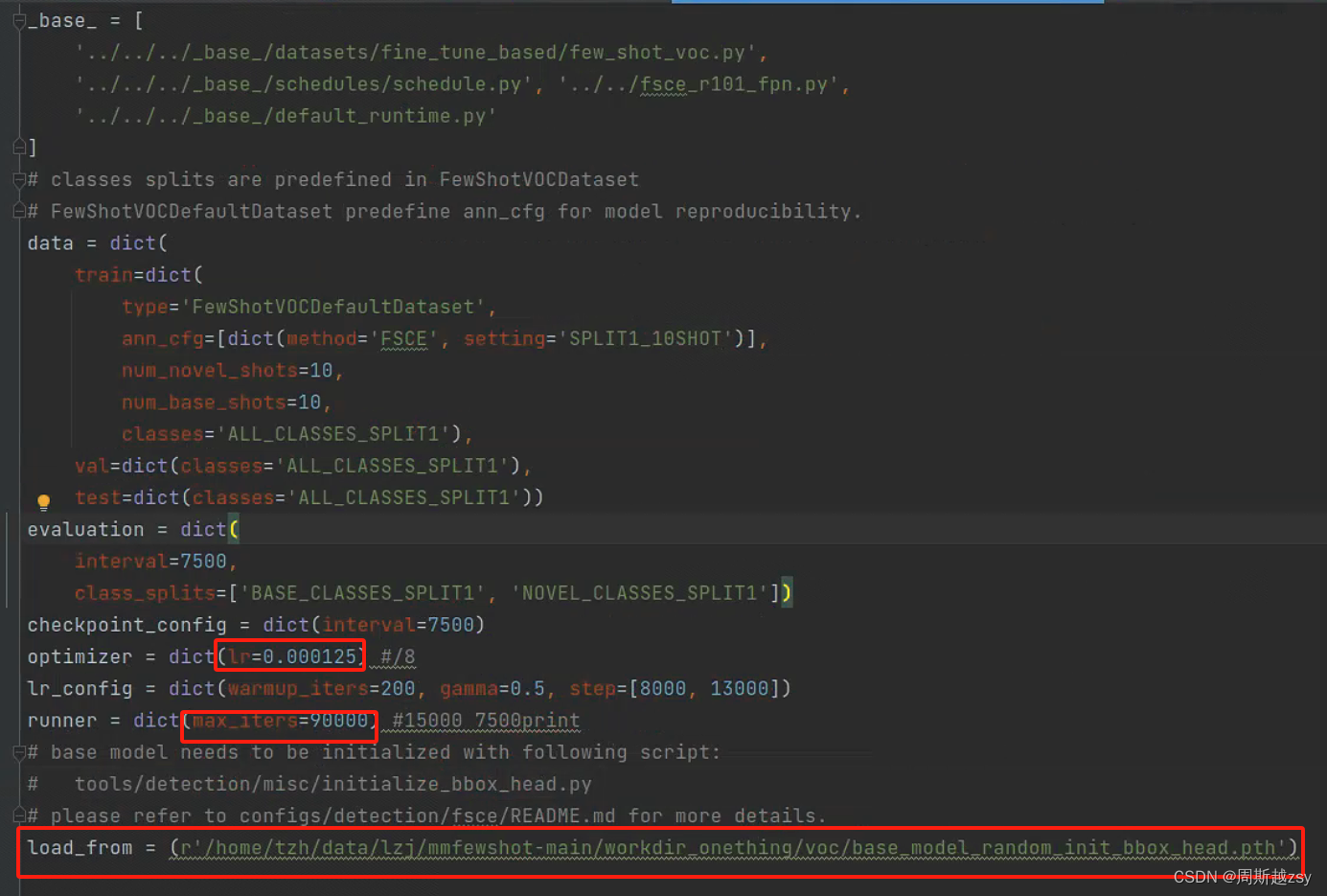
修改configs/detection/fsce/voc/split1/fsce_r101_fpn_voc_split1_10shot_-fine-tuning.py
修改lr学习率、max-iter迭代次数、load_from为转换后得到的base_model_random_init_bbox_head.pth权重文件路径
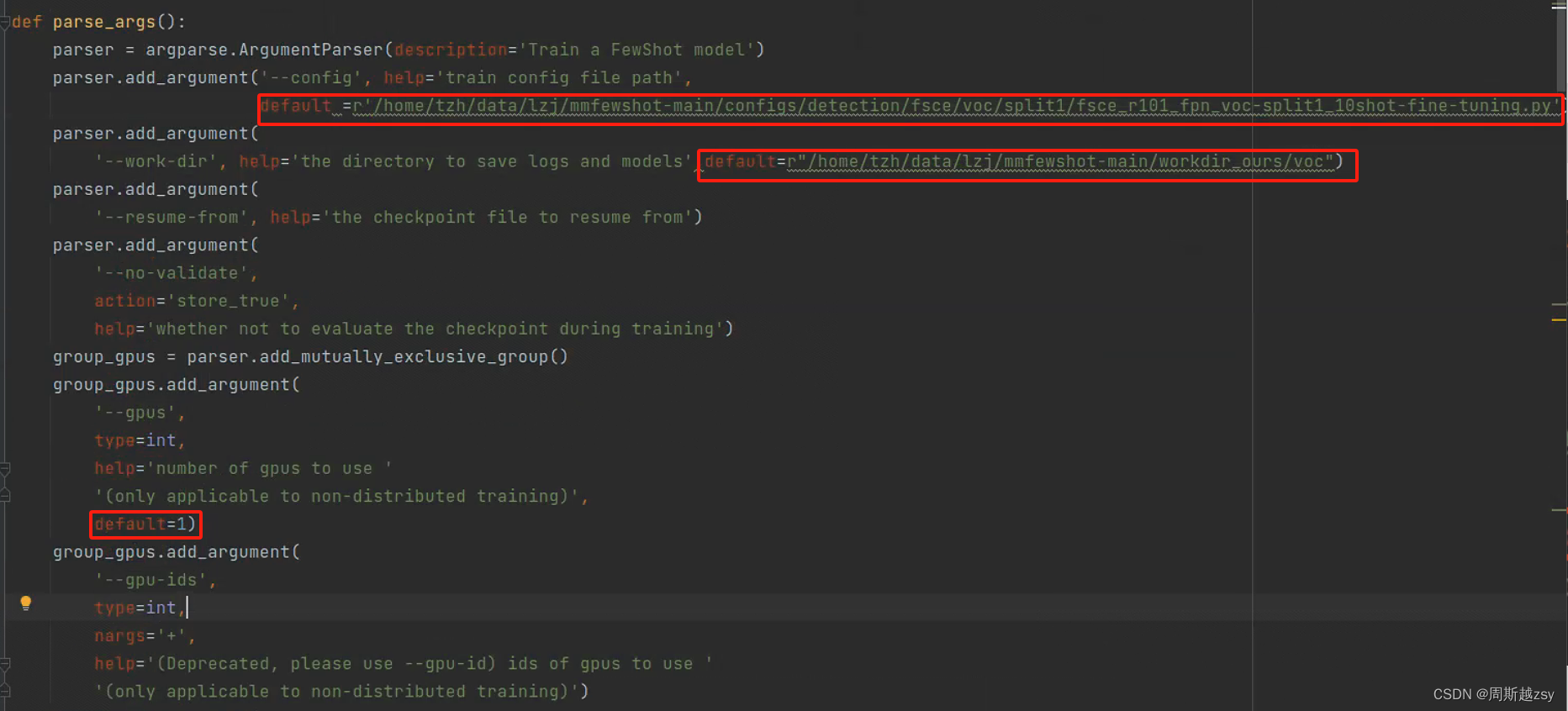
开始训练:修改tools/detection/train.py
修改config为上一步的py文件路径,work-dir为训练日志储存路径,gpus为采用多少gpu进行训练,修改后运行
得到结果
 (4)结果可视化
(4)结果可视化
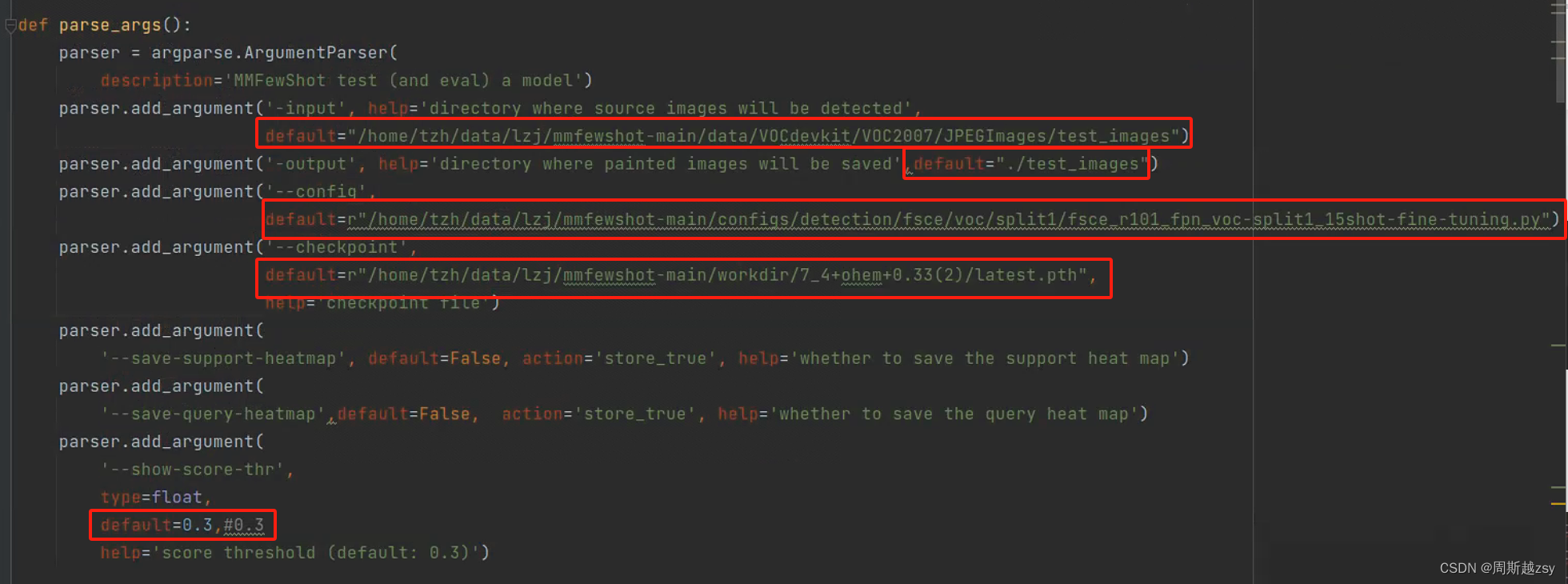
修改inference.py文件
通过网盘分享的文件:inference.py
链接: https://pan.baidu.com/s/1IequyBZaBdpnGQ2IQAJ59g 提取码: 1234
input为储存可视化图像文件夹路径,output为输出的可视化图像储存文件夹,config为迁移训练中tools/detection/train.py所用config,checkpoint为第二阶段训练完成所生成的latest.pth文件,show-score-thr为锚框显示阈值(锚框大于该值则在图像中显示)
以上为所有内容。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)