stream流的介绍和使用
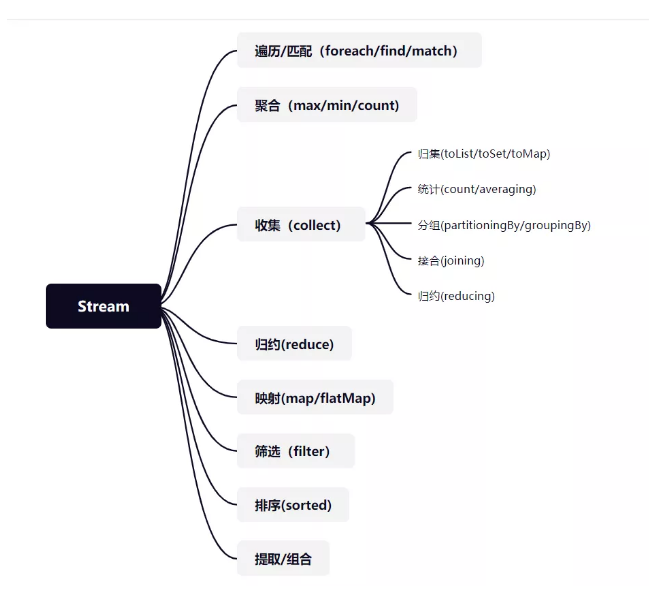
#Stream 流的操作流程Stream流的操作常见的 Stream 中间操作:按照条件过滤得到 ==> filter()有返回的循环改变(可返回一部分,甚至变换类型) ==> map()无返回的循环改变 (全部返回相同类型)==> peek()限制最大个数() ==> limit()跳过几个,从最开始跳() ==> skip()排序() ==> sorted(
文章目录
- 一、Stream流的介绍
- 二、Stream流的使用
-
- Stream 流的操作流程
- 2.1 filter 过滤
- 2.2 peek 和 map 的区别:
- 2.3 sorted 排序
- 2.4 distinct 去重
- 2.5 skip 和 limit:可以实现分页
- 2.6 findFirst 和 findAny:
- 2.7 coleect收集
- 2.8 归集(toList/toSet/toMap)
- 2.9 统计(count/averaging)
- 2.10 分组(partitioningBy/groupingBy)
- 2.11 接合(joining)
- 2.12 归约(reducing)
- 2.13 归约(reduce)
- 2.14 映射(map/flatMap)
- 2.15 提取/组合
- 2.16 其他(聚合求和,平均值,最大小值,返回一组数据中某个字段的最大最小值)
- 三、例子
一、Stream流的介绍
函数式接口
使用注解@FunctionalInterface标识,并且只包含一个抽象方法的接口是函数式接口。
函数式接口主要分为:
- Supplier供给型函数 (无参有返)
- Consumer消费型函数 (有参无返)
- Runnable无参无返回型函数
- Function有参有返回型函数 - 作转换型函数
1.1 Supplier供给型函数
Supplier的表现形式为 不接受参数、只返回数据
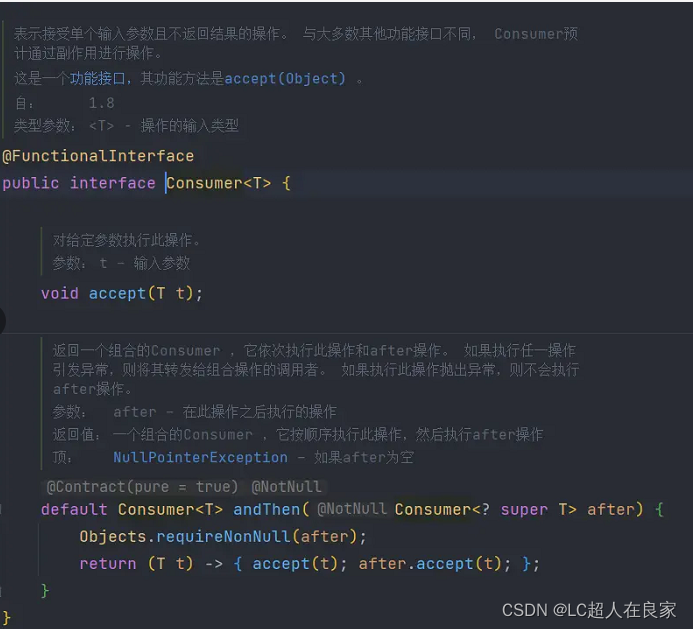
1.2 Consumer消费型函数
Consumer消费型函数和Supplier刚好相反。Consumer接收一个参数,没有返回值
1.3 Runnable无参无返回型函数
Runnable的表现形式为即没有参数也没有返回值

1.4 Function函数
Function函数的表现形式为接收一个参数,并返回一个值。
Supplier、Consumer和Runnable可以看作Function的一种特殊表现形式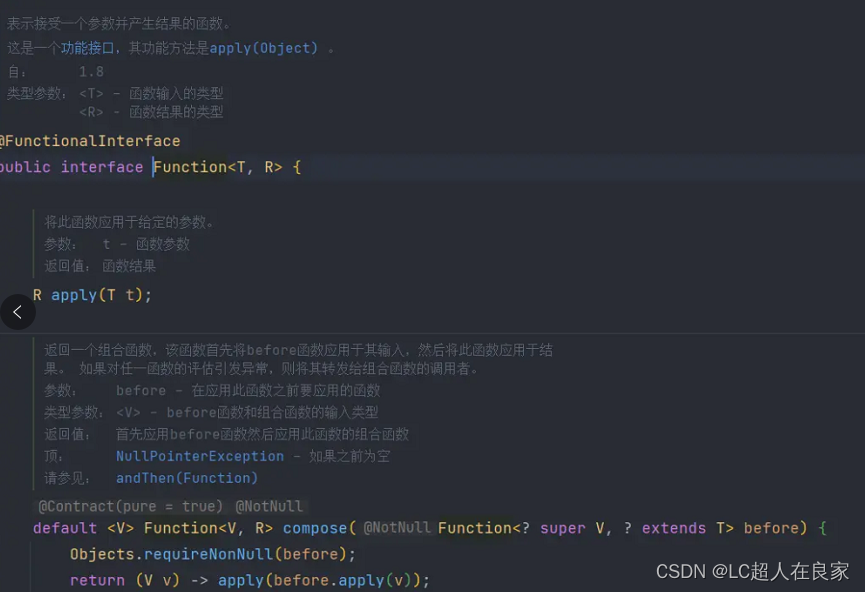
二、Stream流的使用
Stream 流的操作流程
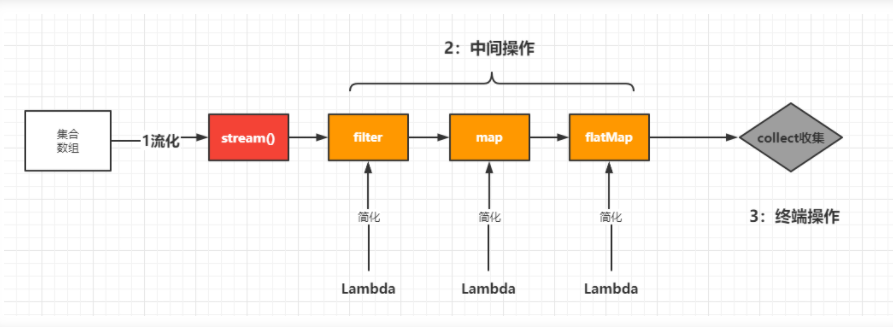
常见的 Stream 中间操作:
按照条件过滤得到 ==> filter()
有返回的循环改变(可返回一部分,甚至变换类型) ==> map()
无返回的循环改变 (全部返回相同类型)==> peek()
限制最大个数() ==> limit()
跳过几个,从最开始跳() ==> skip()
排序() ==> sorted()
不同() ==> distinct()
2.1 filter 过滤
// 只要姓张的人
stream.filter(name -> name.startsWith("张"));
// 对布尔值过=过滤
collect = acDevices.stream().filter(deviceVo -> !deviceVo.isOnline()).collect(Collectors.toList()); // 要为false的元素
collect = acDevices.stream().filter(deviceVo -> deviceVo.isOnline()).collect(Collectors.toList());// 要为true的元素
2.2 peek 和 map 的区别:
peek 无返回值,map 有返回值。
peek 集合流化后的对象的返回值是什么就返回什么。而 map 可以对集合流化后的对象的返回值进行改变,比如可以把集合中的对象改成 map 再返回,或者只需要集合中某一列的值返回。
List<User> userList1 = new ArrayList<>();
userList1.add(new User(1, "小文", "12#6", 16, 1, 20000d));
userList1.add(new User(2, "老季", "12#56", 22, 1, 100000d));
userList1.add(new User(3, "怪咖", "1#56", 13, 1, 89557d));
userList1.add(new User(4, "小六", "#6", 26, 1, 78000d));
userList1.add(new User(5, "小刘", "1#6", 46, 0, 58000d));
List<User> collect1 = userList1.stream()
.filter(user -> user.getAge() > 16)
.peek(user -> user.setAge(user.getAge() + 1))
.collect(Collectors.toList());
for (User user : collect1) {
System.out.println(user);
}
System.out.println("--------------------------------------------------------------------------------");
List<User> collect2 = userList1.stream()
.filter(user -> user.getAge() > 16)
.map(user -> {
user.setAge(user.getAge() + 1);
return user;
})
.collect(Collectors.toList());
for (User user : collect2) {
System.out.println(user);
}
返回:
User{id=2, username='老季', password='123#6', age=23, sex=1, money=100000.0}
User{id=4, username='小六', password='#6', age=27, sex=1, money=78000.0}
User{id=5, username='小刘', password='1#56', age=47, sex=0, money=58000.0}
2.3 sorted 排序
默认升序,需要.reversed()来降序
List<User> sortUserList = userList1.stream()
.sorted((o1, o2) -> o2.getAge() - o1.getAge()) // 从大到小
.collect(Collectors.toList());
for (User user : sortUserList) {
System.out.println(user);
}
//按照升序排序 -- 可以不接受
collect = equipmentVideolist.stream().
sorted(Comparator.comparing(EquipmentVideo::getCreatetime)).
collect(Collectors.toList());
// resultList.sort(Comparator.comparing(ProcessVo::getCreateTime).reversed());
//按照降序排序 -- 可以不接受
collect = equipmentVideolist.stream().
sorted(Comparator.comparing(EquipmentVideo::getCreatetime).
reversed()).collect(Collectors.toList());
// 对boolean类型的排序 -- 可以不接受
List<DeviceVo> collect = acDevices.stream().sorted(Comparator.comparing(DeviceVo::isOnline)).collect(Collectors.toList()); // false放前
List<DeviceVo> collect = acDevices.stream().sorted(Comparator.comparing(DeviceVo::isOnline).reversed()).collect(Collectors.toList()); // true放前
// 对个字段排序【两个sorted(先按第一个排在按第二个排)和一个sorted(纪要满足第一个条件也要满足第二个条件)得到的结果是不一样的,需要注意】
List<DeviceVo> collect = acDevices.stream().sorted(Comparator.comparing((DeviceVo::getOrganizationUnitId))).sorted(Comparator.comparing(DeviceVo::isOnline).reversed()).collect(Collectors.toList());
value.stream()
.sorted(Comparator.comparing(TreeNodeAndIndex::getRow)
.thenComparing(TreeNodeAndIndex::getNodeVal);
// 对jsonarray排序
bindArrayResult.sort(Comparator.comparing(obj -> ((JSONObject) obj).getString("cdn").length()).reversed());
2.4 distinct 去重
判断两个对象是同一个对象:eqauls 是 true 且 hashCode 值都要相同。
所以,要想使用distinct就需要
重写 eqauls 和 hashCode 方法:
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return Objects.equals(id, user.id) && Objects.equals(username, user.username) && Objects.equals(password, user.password) && Objects.equals(age, user.age) && Objects.equals(sex, user.sex) && Objects.equals(money, user.money);
}
@Override
public int hashCode() {
return Objects.hash(id, username, password, age, sex, money);
}
List<User> userList = userList1.stream()
.distinct()
.collect(Collectors.toList());
for (User user : userList) {
System.out.println(user);
}
本质上还是使用treeset对实体类集合进行去重判断
peoples = peoples.stream().collect(
Collectors.collectingAndThen(
Collectors.toCollection(
() -> new TreeSet<>(
Comparator.comparing(People::getName)
)
),ArrayList::new
)
)
2.5 skip 和 limit:可以实现分页
List<User> collect1 = userList1.stream()
.sorted((o1, o2) -> o2.getAge() - o1.getAge())
.collect(Collectors.toList());
for (User user : collect1) {
System.out.println(user);
}
System.out.println("--------------------------------------------------------------------------------");
List<User> collect2 = userList1.stream()
.sorted((o1, o2) -> o2.getAge() - o1.getAge())
.skip(1) // (pageno-1) * pageSize,跳过第一个
.limit(2) // pageSize , 限制个数为2
.collect(Collectors.toList());
for (User user : collect2) {
System.out.println(user);
}
2.6 findFirst 和 findAny:
两者在 stream 串行的情况下,两者都返回第一个元素。
如果是 parallelStream 并行情况下 findAny 会随机返回
Optional<User> first1 = userList1.stream()
.findFirst();
System.out.println(first1.get());
Optional<User> any1 = userList1.stream()
.findAny();
System.out.println(any1.get());
Optional<User> first2 = userList1.parallelStream()
.findFirst();
System.out.println(first2.get());
Optional<User> any2 = userList1.parallelStream()
.findAny();
System.out.println(any2.get());
User{id=1, username='小文', password='1##6', age=16, sex=1, money=20000.0}
User{id=1, username='小文', password='1#56', age=16, sex=1, money=20000.0}
User{id=1, username='小文', password='1#6', age=16, sex=1, money=20000.0}
User{id=3, username='怪咖', password='1#6', age=13, sex=1, money=89557.0}
2.7 coleect收集
2.8 归集(toList/toSet/toMap)
流本身不存储数据,在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用
List<Integer> list = Arrays.asList(3, 6, 4, 5, 7, 8, 9, 10, 20);
List<Goods> goodsList = new ArrayList<>();
goodsList.add(new Goods("商品1", 2000, 20, "类型1", "地区1"));
goodsList.add(new Goods("商品2", 3000, 25, "类型1", "地区1"));
goodsList.add(new Goods("商品3", 3500, 30, "类型2", "地区1"));
goodsList.add(new Goods("商品4", 4000, 21, "类型2", "地区2"));
goodsList.add(new Goods("商品5", 5000, 35, "类型3", "地区2"));
List<Integer> listNew = list.stream().filter(x -> x % 3 == 0).collect(Collectors.toList());
Set<Integer> set = list.stream().filter(x -> x % 3 == 0).collect(Collectors.toSet());
Map<String, Goods> map = goodsList.stream().filter(p -> p.getMoney() > 2000)
.collect(Collectors.toMap(Goods::getName, p -> p));
2.9 统计(count/averaging)
List<Goods> goodsList = new ArrayList<>();
goodsList.add(new Goods("商品1", 2000, 20, "类型1", "地区1"));
goodsList.add(new Goods("商品2", 3000, 25, "类型1", "地区1"));
goodsList.add(new Goods("商品3", 3500, 30, "类型2", "地区1"));
goodsList.add(new Goods("商品4", 4000, 21, "类型2", "地区2"));
goodsList.add(new Goods("商品5", 5000, 35, "类型3", "地区2"));
// 求总数
Long count = goodsList.stream().collect(Collectors.counting());
// 求平均
Double average = goodsList.stream().collect(Collectors.averagingDouble(Goods::getMoney));
// 求最高
Optional<Integer> max = goodsList.stream().map(Goods::getMoney).collect(Collectors.maxBy(Integer::compare));
// 求和
Integer sum = goodsList.stream().collect(Collectors.summingInt(Goods::getMoney));
// 一次性统计所有信息
DoubleSummaryStatistics collect = goodsList.stream().collect(Collectors.summarizingDouble(Goods::getMoney));
System.out.println("总数:" + count);
System.out.println("平均单价:" + average);
System.out.println("最高单价:" + max.get());
System.out.println("单价总和:" + sum);
// 单价所有统计:DoubleSummaryStatistics{count=5, sum=17500.000000, min=2000.000000, // average=3500.000000, max=5000.000000}
System.out.println("单价所有统计:" + collect);
2.10 分组(partitioningBy/groupingBy)
分区:partitioningBy,按条件分成两个Map,比如按商品单价是否大于2000分成两组。
分组:groupingBy,将集合分成多个Map,比如按商品类别分组,分词可以单级分组,也可以多级分组。
List<Goods> goodsList = new ArrayList<>();
goodsList.add(new Goods("商品1", 2000, 20, "类型1", "地区1"));
goodsList.add(new Goods("商品2", 3000, 25, "类型1", "地区1"));
goodsList.add(new Goods("商品3", 3500, 30, "类型2", "地区1"));
goodsList.add(new Goods("商品4", 4000, 21, "类型2", "地区2"));
goodsList.add(new Goods("商品5", 5000, 35, "类型3", "地区2"));
// 单价是否高于2000分组
Map<Boolean, List<Goods>> part = goodsList.stream().collect(Collectors.partitioningBy(goods -> goods.getMoney() > 2000));
// 按类别分组
Map<String, List<Goods>> group1 = goodsList.stream().collect(Collectors.groupingBy(Goods::getType));
// 先按类别分组,再按所属区域分组
Map<String, Map<String, List<Goods>>> group2 = goodsList.stream().collect(Collectors.groupingBy(Goods::getType, Collectors.groupingBy(Goods::getArea)));
System.out.println("单价是否高于2000分组:" + part);
System.out.println("按类别分组:" + group1);
System.out.println("按类别、所属区域:" + group2);
单价是否高于2000分组:{false=[com.btzh.utils.Goods@5622fdf], true=[com.btzh.utils.Goods@4883b407, com.btzh.utils.Goods@7d9d1a19, com.btzh.utils.Goods@39c0f4a, com.btzh.utils.Goods@1794d431]}
按类别分组:{类型1=[com.btzh.utils.Goods@5622fdf, com.btzh.utils.Goods@4883b407], 类型3=[com.btzh.utils.Goods@1794d431], 类型2=[com.btzh.utils.Goods@7d9d1a19, com.btzh.utils.Goods@39c0f4a]}
按类别、所属区域:{类型1={地区1=[com.btzh.utils.Goods@5622fdf, com.btzh.utils.Goods@4883b407]}, 类型3={地区2=[com.btzh.utils.Goods@1794d431]}, 类型2={地区1=[com.btzh.utils.Goods@7d9d1a19], 地区2=[com.btzh.utils.Goods@39c0f4a]} }
//groupingBy分组,求每组的个数
Map<Integer, Long> map = list.stream().collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
分组后,收集个数
Map<String, Long> map = employees.stream()
.collect(Collectors.groupingBy(Employee::getCity, Collectors.counting()));
2.11 接合(joining)
joining可以把stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
List<Goods> goodsList = new ArrayList<>();
goodsList.add(new Goods("商品1", 2000, 20, "类型1", "地区1"));
goodsList.add(new Goods("商品2", 3000, 25, "类型1", "地区1"));
goodsList.add(new Goods("商品3", 3500, 30, "类型2", "地区1"));
goodsList.add(new Goods("商品4", 4000, 21, "类型2", "地区2"));
goodsList.add(new Goods("商品5", 5000, 35, "类型3", "地区2"));
String names = goodsList.stream().map(Goods::getName).collect(Collectors.joining(","));
System.out.println("名称拼接:" + names);
名称拼接:商品1,商品2,商品3,商品4,商品5
2.12 归约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。(归约即缩减,把集合缩减为一个值)
// **获取所有商品单价减去500之和**
List<Goods> goodsList = new ArrayList<>();
goodsList.add(new Goods("商品1", 2000, 20, "类型1", "地区1"));
goodsList.add(new Goods("商品2", 3000, 25, "类型1", "地区1"));
goodsList.add(new Goods("商品3", 3500, 30, "类型2", "地区1"));
goodsList.add(new Goods("商品4", 4000, 21, "类型2", "地区2"));
goodsList.add(new Goods("商品5", 5000, 35, "类型3", "地区2"));
// 单价-500的和
Integer sum = goodsList.stream().collect(Collectors.reducing(0, Goods::getMoney, (o1, o2) -> (o1 + o2 - 500)));
System.out.println("单价-500的和:" + sum);
2.13 归约(reduce)
归约,也称缩减,是把一个流缩减为一个值,能实现对集合求和、求乘积和求最值等操作。
例子一:
List<Goods> goodsList = new ArrayList<>();
goodsList.add(new Goods("商品1", 2000, 20, "类型1", "地区1"));
goodsList.add(new Goods("商品2", 3000, 25, "类型1", "地区1"));
goodsList.add(new Goods("商品3", 3500, 30, "类型2", "地区1"));
goodsList.add(new Goods("商品4", 4000, 21, "类型2", "地区2"));
goodsList.add(new Goods("商品5", 5000, 35, "类型3", "地区2"));
// 单价之和
Integer sumMoney = goodsList.stream().reduce(0, (sum, goods) -> sum += goods.getMoney(), Integer::sum);
// 最高单价:
Integer maxMoney = goodsList.stream().reduce(0, (max, goods) ->
max > goods.getMoney() ? max : goods.getMoney(), Integer::max);
System.out.println("单价之和:" + sumMoney);
System.out.println("最高单价:" + maxMoney);
例子二:
// allSituationInfoDtos 是一个集合,里面有集合属性
Optional<List<Integer>> reduce = allSituationInfoDtos.stream()
.map(SituationInfoDto::getDid)
.reduce((before, after) -> {
before.addAll(after);
return before;
});
List<Integer> integers = allSituationInfoDtos.stream()
.map(SituationInfoDto::getDid)
.reduce((before, after) -> {
before.addAll(after);
return before;
})
.orElse(Collections.emptyList());
reduce方法有三个override重载方法的方法,分别接受1个参数,2个参数,和3个参数,下面来依次介绍
- 2个参数
方法定义为:T reduce(T identity, BinaryOperator accumulator);
参数一:identity 初始值
参数二:accumulator 告诉reduce方法怎么去累计stream中的数据
/*
// 初始化值
int sum = 0;
List list={1,2,3,4,5};
for (n : list) {
// 指定计算方式
sum = sum + n;
}*/
// 类似与上面的功能
public static void main(String[] args) {
/*Integer sum1 = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer integer, Integer integer2) {
return integer + integer2;
}
});*/
// lambda表达式
int sum1 = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(0, (n1, n2) -> n1 + n2);
System.out.println("累加和为:" + sum1); //累加和为:45
}
reduce的作用是把stream中的元素给组合起来,我们可以传入一个初始值,它会按照我们的计算方式依次拿流中的元素和初始化值进行计算,计算结果再和后面的元素计算
注意:
Stream.parallel()或者parallelStream()的方法开启并行模式(可以简单理解为在多线程中执行)。
Stream.sequential()开启串行模式,默认开启的是串行模式。
identity是reduce的初始化值,但是在并行模式下,这个值不能随意指定:
public static void main(String[] args) {
Integer sum1 = Stream.of(1, 2, 3).reduce(100, (integer, integer2) -> integer + integer2);
System.out.println("累加和为:" + sum1); //累加和为:106
// 在并行计算的时候,每个线程的初始累加值都是100,最后3个线程加出来的结果就是306
Integer sum2 = Stream.of(1, 2, 3).parallel().reduce(100, (integer, integer2) -> integer + integer2);
System.out.println("累加和为:" + sum2); //累加和为:306
}
官方文档说明:identity必须是accumulator函数的一个identity,也就是说必须满足:对于所有的 t, 都必须满足 accumulator.apply(identity, t) == t
所以,
sum方法的identity只能是0。 满足sum(0+1)== 1
计算求积(乘法)时,初始值必须设置为1。
- 一个参数
方法定义为:Optional reduce(BinaryOperator accumulator);
参数:accumulator告诉reduce方法怎么去累计stream中的数据
原理:将流中的第一个元素作为初始化值,这里返回值类型为Optional,这是因为Stream的元素有可能是0个,这样就没法调用reduce()的聚合函数了,因此返回Optional对象,需要进一步判断结果是否存在。
注意:此时会导致第一条数据不对,会累加上后面的所有数据
public static void main(String[] args) {
Optional<Integer> opt = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer acc, Integer n) {
return acc + n;
}
});
//Optional<Integer> opt = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9).reduce((acc, n) -> acc + n);
if (opt.isPresent()) {
System.out.println("累加和为:" + opt.get());
}
}
简化写法:
// allSituationInfoDtos 是一个集合,里面有集合属性
Optional<List<Integer>> reduce = allSituationInfoDtos.stream()
.map(SituationInfoDto::getDid)
.reduce((before, after) -> {
before.addAll(after);
return before;
});
List<Integer> integers = allSituationInfoDtos.stream()
.map(SituationInfoDto::getDid)
.reduce((before, after) -> {
before.addAll(after);
return before;
})
.orElse(Collections.emptyList());
// **注意:此时会导致第一条数据不对,会累加上后面的所有数据** 解决方法如下,用两个参数的
List<Integer> deviceIdIntegerList = stateIdSituationInfoDtos.stream()
.map(SituationInfoDto::getDid)
.reduce(new ArrayList<>(), (before, after) -> {
before.addAll(after);
return before;
});
注意:此时会导致第一条数据不对,会累加上后面的所有数据
- 三个参数
方法定义为: U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator combiner);
参数一: identity:给定一个初始值
参数二: accumulator:基于初始值,对元素进行收集归纳
参数三: combiner:对每个accumulator返回的结果进行合并,此参数只有在并行模式中生效
BinaryOperator是供多线程使用的,需要考虑线程安全的问题
说明:
1)和前面的方法不同的是,多了一个combiner,这个combiner用来合并多线程计算的结果;
2)BinaryOperator combiner 操作的对象是第二个参数BiFunction<U,? super T,U> accumulator的返回值;
2.14 映射(map/flatMap)
map:接收一个函数作为参数,该函数会被应用到每个元素上,映射为一个新的元素。
flatMap:接收一个函数作为参数,将流中的每个值换成另一个流,最后把所有的流连接为一个流。
将所有商品的单价加1000
// 不改变原来集合的方式
List<Goods> goodsListNew1 = goodsList.stream().map(goods -> {
Goods goodsNew = new Goods(goods.getName(), goods.getMoney(), goods.getReadCount(), goods.getType(), goods.getArea());
goodsNew.setMoney(goods.getMoney() + 1000);
return goodsNew;
}).collect(Collectors.toList());
System.out.println("第一次变动前:" + goodsList.get(0).getName() + ":" + goodsList.get(0).getMoney());
System.out.println("第一次变动后:" + goodsListNew1.get(0).getName() + ":" + goodsListNew1.get(0).getMoney());
// 改变原来集合的方式
List<Goods> goodsListNew2 = goodsList.stream().map(goods -> {
goods.setMoney(goods.getMoney() + 1000);
return goods;
}).collect(Collectors.toList());
System.out.println("第二次变动前:" + goodsList.get(0).getName() + ":" + goodsListNew1.get(0).getMoney());
System.out.println("第二次变动后:" + goodsListNew2.get(0).getName() + ":" + goodsList.get(0).getMoney());
将两个字符数组合并成一个新的字符数组
List<String> list = Arrays.asList("a,b,c,d", "2,4,6,8");
List<String> listNew = list.stream().flatMap(s -> {
// 将每个元素转换成一个stream
String[] split = s.split(",");
return Arrays.stream(split);
}).collect(Collectors.toList());
System.out.println("pre:" + list);
System.out.println("now:" + listNew);
2.15 提取/组合
合并两个流,去重;获取流中的前2个数据;跳过流中第1个数据
String[] arr1 = { "123", "234", "111", "222" };
String[] arr2 = { "123", "234", "124", "235" };
Stream<String> stream1 = Stream.of(arr1);
Stream<String> stream2 = Stream.of(arr2);
// concat:合并两个流并去重
List<String> distinct = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());
// limit:从流中获得前n个数据
List<Integer> limit = Stream.iterate(0, x -> x + 1).limit(2).collect(Collectors.toList());
// skip:跳过前n个数据
List<Integer> skip = Stream.iterate(0, x -> x + 1).skip(1).limit(2).collect(Collectors.toList());
System.out.println("distinct:" + distinct);
System.out.println("limit:" + limit);
System.out.println("skip:" + skip);
distinct:[123, 234, 111, 222, 124, 235]
limit:[0, 1]
skip:[1, 2]
2.16 其他(聚合求和,平均值,最大小值,返回一组数据中某个字段的最大最小值)
// 聚合
int sum = userList1.stream()
.mapToInt(user -> user.getAge()).sum();
System.out.println(sum);
monthMoney = currentMonthOrders.getJSONArray("data").toJavaList(OrderInfo.class)
.stream().filter(orderInfo -> orderInfo.getDeviceName().equals(deviceName)).mapToDouble(OrderInfo::getTotalFee).sum();
// 平均值
double avg = userList1.stream()
.mapToInt(user -> user.getAge()).average().getAsDouble();
System.out.println(avg);
// 最大值
int max = userList1.stream()
.mapToInt(user -> user.getAge()).max().getAsInt();
System.out.println(max);
// 最小值
int min = userList1.stream()
.mapToInt(user -> user.getAge()).min().getAsInt();
System.out.println(min);
// 最大年龄
User userVo = userList1.stream()
.max((user1, user2) -> user1.getAge() - user2.getAge()).get();
System.out.println(userVo);
// 只返回年龄
Integer age = userList1.stream()
.map(user -> user.getAge())
.max((age1, age2) -> age1 - age2).get();
System.out.println(age);
List<Goods> goodsList = new ArrayList<>();
goodsList.add(new Goods("商品1", 2000, 20, "类型1", "地区1"));
goodsList.add(new Goods("商品2", 3000, 25, "类型1", "地区1"));
goodsList.add(new Goods("商品3", 3500, 30, "类型2", "地区1"));
goodsList.add(new Goods("商品4", 4000, 21, "类型2", "地区2"));
goodsList.add(new Goods("商品5", 5000, 35, "类型3", "地区2"));
Optional<Goods> min = goodsList.stream().min(Comparator.comparingInt(Goods::getMoney));
List<Integer> numList = Arrays.asList(1,2,5,10);
//方法一:
int max = numList.stream().mapToInt(x -> x).summaryStatistics().getMax();
int min = numList.stream().mapToInt(x -> x).summaryStatistics().getMin();
double average = numList.stream().mapToInt(x -> x).summaryStatistics().getAverage();
long sum = numList.stream().mapToInt(x -> x).summaryStatistics().getSum();
System.out.println("maxYear:"+max);
System.out.println("minYear:"+min);
System.out.println("average:"+average);
System.out.println("sum:"+sum);
//方法二:
Integer maxNum = numList.stream().max(Integer::compareTo).get();
Integer minNum = numList.stream().min(Integer::compareTo).get();
System.out.println("maxNum:"+maxNum);
System.out.println("minNum:"+minNum);
三、例子
3.1 处理抛出异常的if
1.定义函数
定义一个抛出异常的形式的函数式接口, 这个接口只有参数没有返回值是个消费型接口

2.编写判断方法
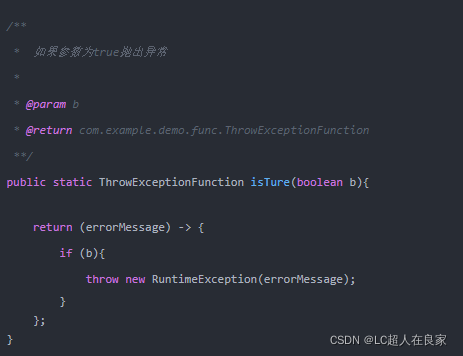
创建工具类VUtils并创建一个isTure方法,方法的返回值为刚才定义的函数式接口-ThrowExceptionFunction。ThrowExceptionFunction的接口实现逻辑为当参数b为true时抛出异常
3.使用方式
调用工具类参数参数后,调用函数式接口的throwMessage方法传入异常信息。当出入的参数为false时正常执行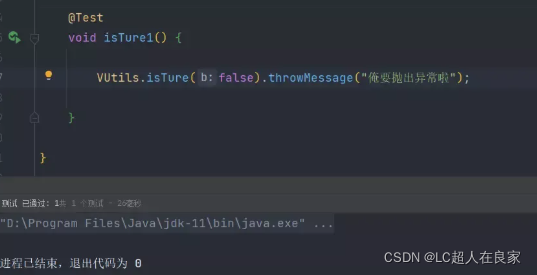
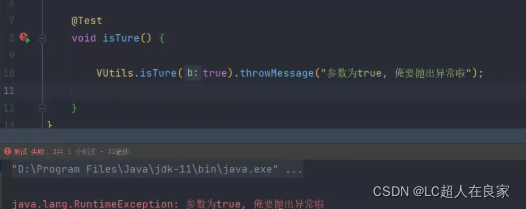
当出入的参数为true时抛出异常
3.2处理if分支操作
1.定义函数式接口
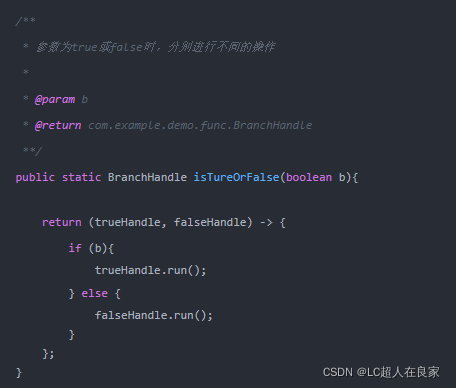
创建一个名为BranchHandle的函数式接口,接口的参数为两个Runnable接口。这两个两个Runnable接口分别代表了为true或false时要进行的操作

2.编写判断方法
创建一个名为isTureOrFalse的方法,方法的返回值为刚才定义的函数式接口-BranchHandle。
3.使用方式
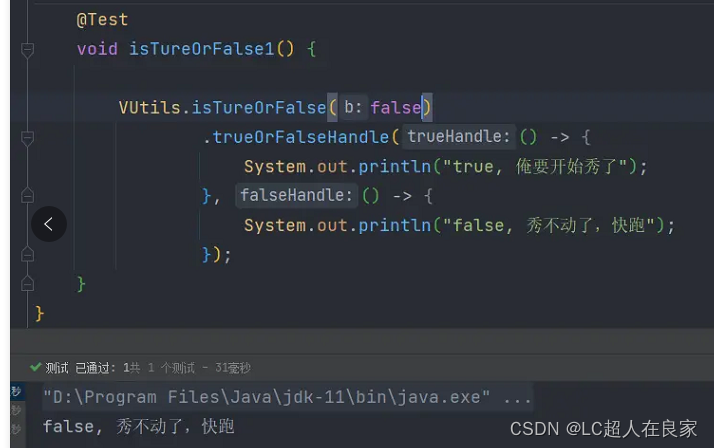
参数为true时,执行trueHandle
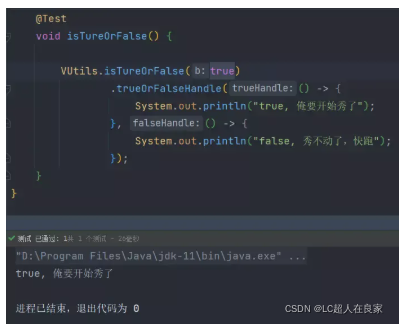
参数为false时,执行falseHandle
如果存在值执行消费操作,否则执行基于空的操作
1.定义函数
创建一个名为PresentOrElseHandler的函数式接口,接口的参数一个为Consumer接口。一个为Runnable,分别代表值不为空时执行消费操作和值为空时执行的其他操作

2.编写判断方法
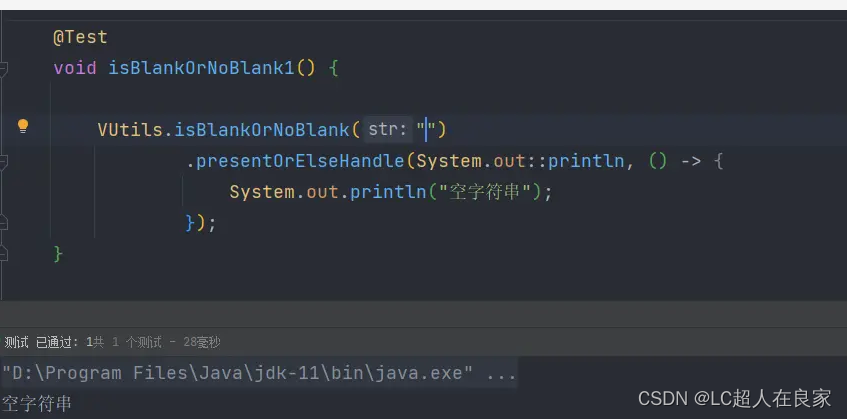
创建一个名为isBlankOrNoBlank的方法,方法的返回值为刚才定义的函数式接口-PresentOrElseHandler。
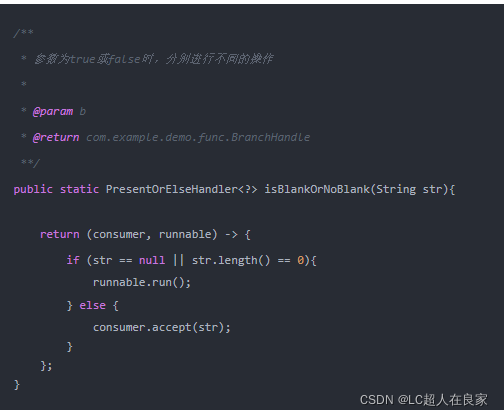
3.使用方式
调用工具类参数参数后,调用函数式接口的presentOrElseHandle方法传入一个Consumer和Runnable
参数不为空时,打印参数
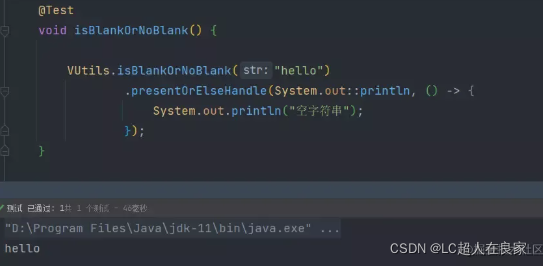
参数不为空时
3.3 分组后在计算和
// 按照productId进行分组
Map<String, List<GoodsVo>> productIdGroup = goodsVos.stream().collect(Collectors.groupingBy(GoodsVo::getProductId));
productIdGroup.entrySet().forEach(entry -> {
GoodsVo goodsCountInfo = new GoodsVo();
List<GoodsVo> GoodsByProductId = entry.getValue();
int count = GoodsByProductId.stream().mapToInt(GoodsVo::getInventory).sum();
String productName = GoodsByProductId.get(0).getProductName();
goodsCountInfo.setProductName(productName).setInventory(count);
goodsCountList.add(goodsCountInfo);
});
3.4 Stream流操作小数时会又精度问题
解决:
BigDecimal reduce = roleList.stream().map(Entity::getNum).filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
3.5 对一个集合里面的某个字段去重
vos = vos.stream().collect( Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(
Comparator.comparing(User::getName))), ArrayList::new
)
)
3.6 用Stream流对多个字段进行分组,得用字符串的拼接
.COLLECT(Collectors.groupingBy(v -> v.getName() + v.getAge()))
3.7 合并两个map
- Stream.concat();
但是key相同会导致-java.lang.IllegalStateException: Duplicate key 1
HashMap<String, String> map1 = new HashMap<>();
HashMap<String, String> map2 = new HashMap<>();
map1.put("a", "1");
map2.put("a", "2");
map1.put("b", "1");
map2.put("b", "2");
Stream<Map.Entry<String, String>> combined = Stream.concat(map1.entrySet().stream(), map2.entrySet().stream());
Map<String, String> result = combined.collect(
Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
相同的键,值合并
Map<String, People> map5 = Stream.concat(map1.entrySet().stream(), map2.entrySet().stream())
.collect(Collectors.toMap(
Map.Entry::getKey,
Map.Entry::getValue,
(value1, value2) -> new People(value2.getId(), value1.getName()))); // 遇到相同的键的时候,值的设置,可以自己设置需要的值,比如相加
printMap("map5", map5);
3.8 字符串转换成集合
List<Integer> collect = Arrays.stream(groups.split(",")).map(Integer::parseInt).collect(Collectors.toList());
3.9 差集,交集,并集
public static void main(String[] args) {
List<String> list1 = new ArrayList();
list1.add("1111");
list1.add("2222");
list1.add("3333");
List<String> list2 = new ArrayList();
list2.add("3333");
list2.add("4444");
list2.add("5555");
// 交集
List<String> intersection = list1.stream().filter(item -> list2.contains(item)).collect(Collectors.toList());
// 差集 (list1 - list2)
List<String> reduce1 = list1.stream().filter(item -> !list2.contains(item)).collect(Collectors.toList());
// 差集 (list2 - list1)
List<String> reduce2 = list2.stream().filter(item -> !list1.contains(item)).collect(Collectors.toList());
// 并集
List<String> listAll = list1.parallelStream().collect(Collectors.toList());
List<String> listAll2 = list2.parallelStream().collect(Collectors.toList());
listAll.addAll(listAll2);
// 去重并集
List<String> listAllDistinct = listAll.stream().distinct().collect(Collectors.toList());
}
3.10 分组后在收集,求和等
// 分组求和
Map<Integer, IntSummaryStatistics> collect = students.stream().collect(Collectors.groupingBy(Student::getId, Collectors.summarizingInt(Student::getS
core)));
// 分组收集
Map<String, List> map = list.stream().collect(Collectors.groupingBy(CourseTeacherDTO::getCourseId, Collectors.mapping(CourseTeacherDTO::getName, Collectors.toList())));
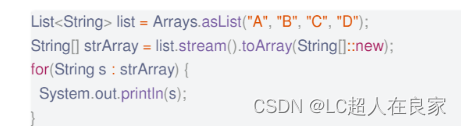
3.11 集合转数组
3.12 对map的key排序
对map的key进行升序排序,时间升序排序
timeMap = timeMap.entrySet().stream().sorted(Map.Entry.comparingByKey(String::compareTo)).
collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue,newValue)->oldValue, LinkedHashMap::new));
3.13 找最大值
Student student = stu.stream.max(Comparator.comparing(Student::getRecord)).get();

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)