基于BP算法的手写数字识别
本文为学校机器智能实践课的实验报告,想直接看代码可以跳到最后源码展示一块;具体细节在算法设计中有详解。
本文为学校机器智能实践课的实验报告,想直接看代码可以跳到piedpiperG/neuralnetwork (github.com);具体细节在算法设计中有详解
目录
一.概要说明
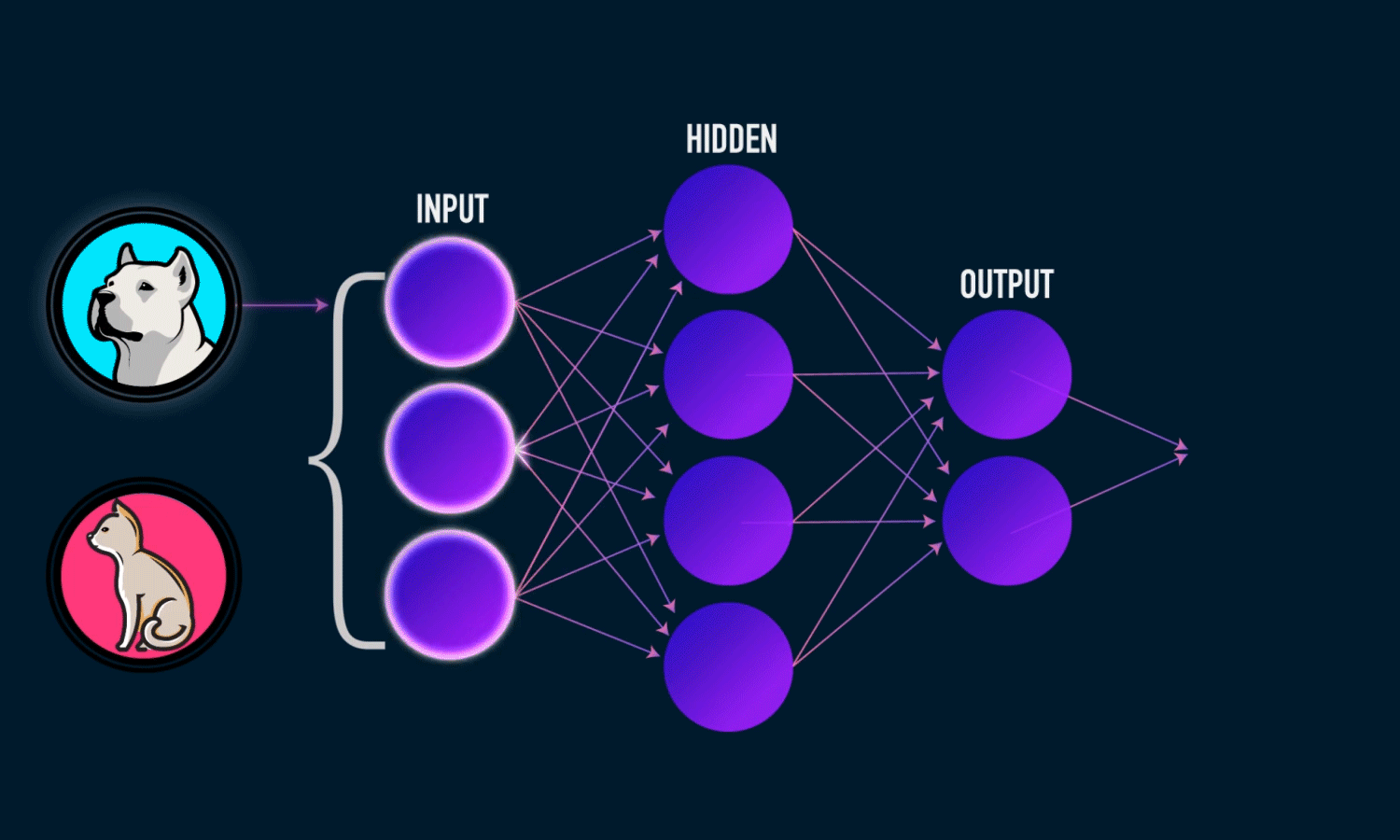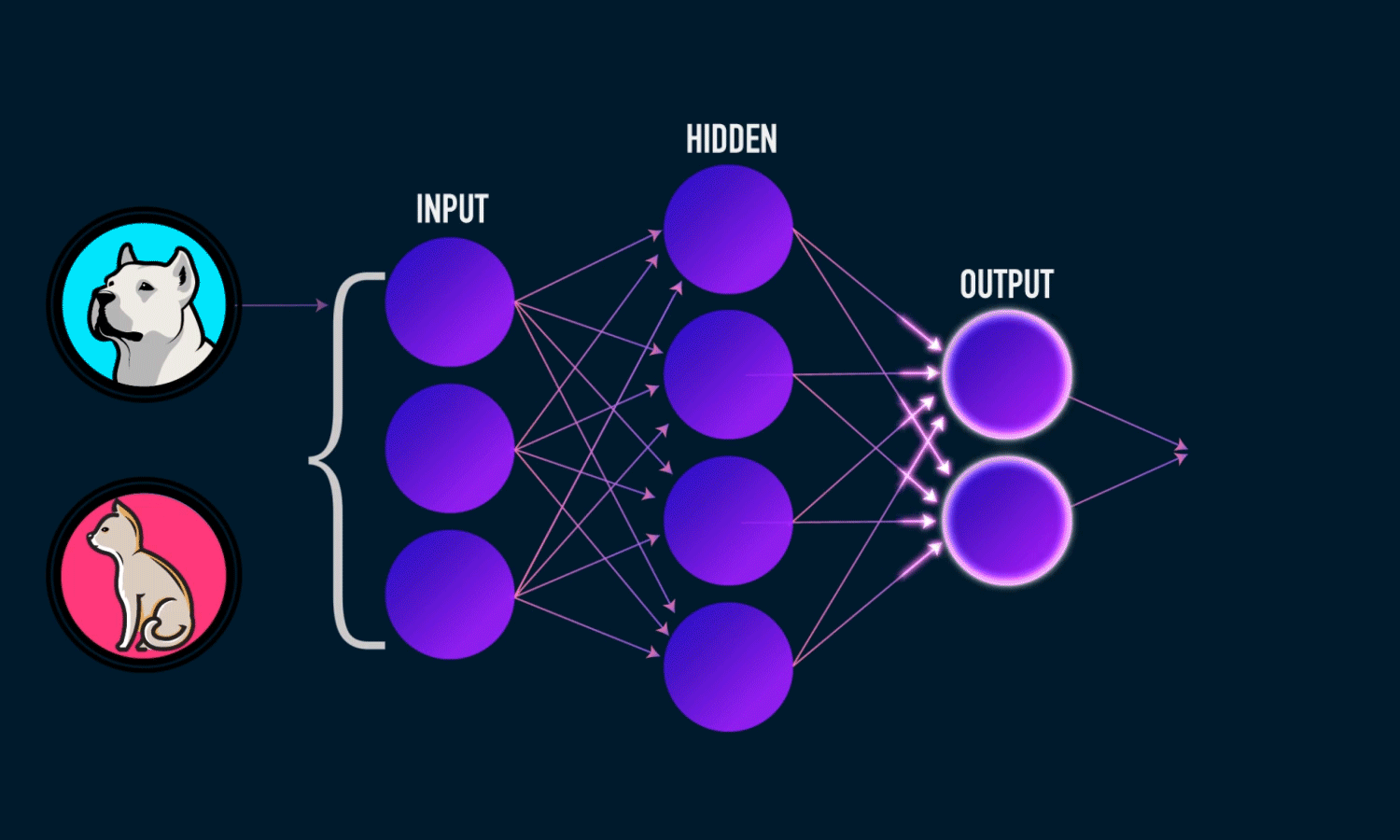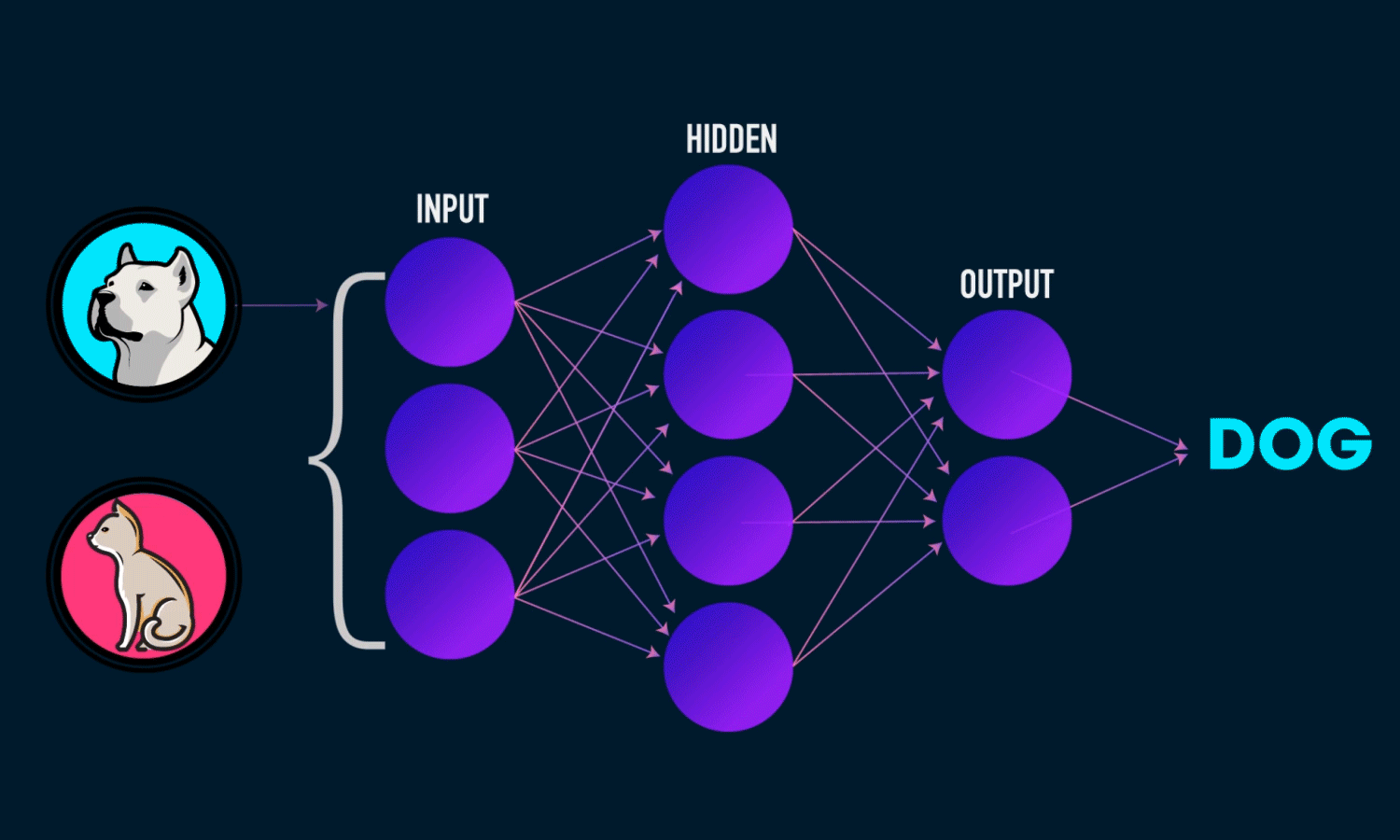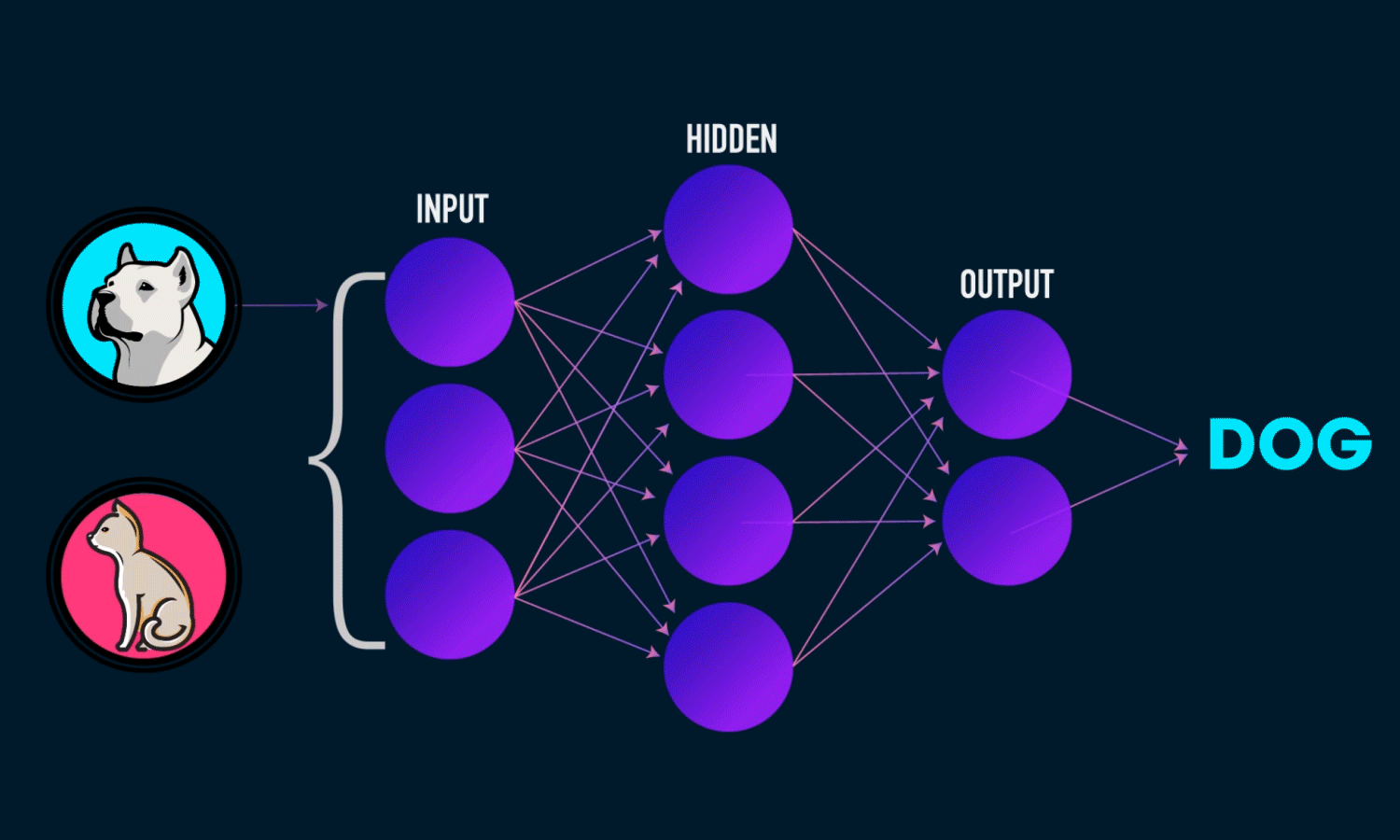
本程序使用BP神经网络,基于MINST数据集完成对手写数字的识别。
主体思路为构建输入,隐藏,输出三层神经网络;用MINST数据集中的数据对网络进行训练,训练成果通过输入层与隐藏层,隐藏层与输出层之间的权重保存下来。再用MINST数据集中的数据对神经网络的性能进行评估。
在一般神经网络训练,测试的基础上;创新点为我们的手写数字识别系统不仅可以检测手写数字的扫描图像,还可以在集成GUI的帮助下在屏幕上书写数字以进行识别。
原理为构建一个三层前馈神经网络函数,使用训练得到的两个权重进行判别,使用 Sigmoid 函数作为激活函数,在给定权重矩阵和输入特征的情况下,进行前向传播并输出预测的分类结果。
二.算法设计
1.MINST数据集的导入
 https://www.kaggle.com/avnishnish/mnist-original/download
https://www.kaggle.com/avnishnish/mnist-original/download从mist -original中提取数据。然后从提取的数据中分离出特征和标签。之后,数据将分为6万个训练集和1万个测试集
# 加载数据文件
data = loadmat('mnist-original.mat')
# 提取数据的特征矩阵,并进行转置
X = data['data']
X = X.transpose()
# 然后将特征除以255,重新缩放到[0,1]的范围内,以避免在计算过程中溢出
X = X / 255
# 从数据中提取labels
y = data['label']
y = y.flatten()
# 将数据分割为60,000个训练集
X_train = X[:60000, :]
y_train = y[:60000]
# 和10,000个测试集
X_test = X[60000:, :]
y_test = y[60000:]
2.神经网络的设置和求解
权重Theta
权重通常记为θ或w,这里我们将它们记为θ。输入层和隐藏层之间的权重表示为Theta1:100x785矩阵。隐藏层和输出层之间的权值表示为Theta2:10x101矩阵。
如果网络在j层有a个单位,在j+1层有b个单位,则θⱼ的维数为b ×(a+1)。
这里在[-0.15,+0.15]范围内随机初始化theta以打破对称性并获得更好的结果。
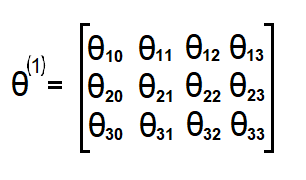
使用minimize方法求解神经网络
使用来自Scipy库的minimizm函数来求解神经网络的两个最优权值
minimize是scipy.optimize中的函数,可以实现非线性规划问题;给定一个优化目标,其可以自动求出优化目标取极值时所对应的参数
minimize(func,xo,args,**pos)
func:优化目标xo:优化参数初始值args:优化目标中其他参数的值
这里将两个权重Theta1,Theta2打包为initial_nn_params作为优化目标
同时BP神经网络函数计算损失值和梯度,返回给minimize函数
minimize函数根据目标函数的损失值 J 来评估当前参数值的好坏,以及确定下一步应该朝哪个方向移动。- 目标函数返回的梯度 grad 提供了关于参数向量的导数信息,用于指导优化算法在参数空间中的搜索方向和步长。
- 优化算法会迭代地调整参数值,并根据目标函数的返回值来寻找使损失值最小化的最优参数解。
通过反复计算损失值和梯度,minimize 函数会在优化过程中不断更新参数值,直到达到最优解或满足特定的停止条件。
input_layer_size = 784 # 图片大小为 (28 X 28) px 所以设置784个特征
hidden_layer_size = 100
num_labels = 10 # 拥有十个标准为 [0, 9] 十个数字
# 随机初始化 Thetas
initial_Theta1 = initialise(hidden_layer_size, input_layer_size) # 输入层和隐藏层之间的权重
initial_Theta2 = initialise(num_labels, hidden_layer_size) # 隐藏层和输出层之间的权重
# 设置神经网络的参数
initial_nn_params = np.concatenate((initial_Theta1.flatten(), initial_Theta2.flatten()))
lambda_reg = 0.1 # 避免过拟合
myargs = (input_layer_size, hidden_layer_size, num_labels, X_train, y_train, lambda_reg)
# 设置最小化函数的迭代次数
maxiter = 100
# 调用最小化函数来计算权重
results = minimize(neural_network, x0=initial_nn_params, args=myargs,
options={'disp': True, 'maxiter': maxiter}, method="L-BFGS-B", jac=True)
nn_params = results["x"] # 获得训练之后的权重3.BP神经网络构造
构造神经网络函数,该函数执行前向传播和反向传播,计算神经网络的损失值和梯度,并返回给minimize函数,以此来调整优化。
前向传播:输入数据通过网络向前向馈送。每个隐藏层接受输入数据,根据激活函数对其进行处理,并将其传递给后续层。激活函数为sigmoid函数。
反向传播:基于前一次迭代中获得的错误率对神经网络的权重进行微调。它还计算交叉熵损失,以检查预测值与原始值之间的误差。最后,对优化目标进行梯度计算。
下面结合具体代码对程序如何构建神经网络进行说明
偏置节点
使用“偏差”节点通常是创建成功学习模型的关键。简而言之,偏差值允许将激活函数向左或向右移动,这有助于更好地适应数据(更好的预测函数作为输出)。
m = X.shape[0]
one_matrix = np.ones((m, 1))
X = np.append(one_matrix, X, axis=1) # 向输入层添加偏置单元,使之成为偏差节点
a1 = X向前传播
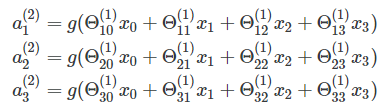
本层节点与权重相乘之后,使用激活函数激活,再传递给下一层
由于我们这里的权重是使用minimize函数进行优化得到的,这里并不做特殊处理
激活函数使用的是sigmoid函数
# 向前传播
m = X.shape[0]
one_matrix = np.ones((m, 1))
X = np.append(one_matrix, X, axis=1) # 向输入层添加偏置单元,使之成为偏差节点
a1 = X
z2 = np.dot(X, Theta1.transpose())
a2 = 1 / (1 + np.exp(-z2)) # 采用Sigmoid函数对隐藏层进行激活
one_matrix = np.ones((m, 1))
a2 = np.append(one_matrix, a2, axis=1) # 向隐藏层添加偏置单元,使之成为偏差节点
z3 = np.dot(a2, Theta2.transpose())
a3 = 1 / (1 + np.exp(-z3)) # 采用Sigmoid函数对输出层进行激活损失值
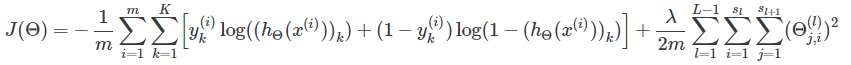
# 计算损失值
J = (1 / m) * (np.sum(np.sum(-y_vect * np.log(a3) - (1 - y_vect) * np.log(1 - a3)))) + (lamb / (2 * m)) * (
sum(sum(pow(Theta1[:, 1:], 2))) + sum(sum(pow(Theta2[:, 1:], 2))))向后传播
我们已经通过向前传播,计算出了神经网络在给定参数下的预测值 a3。
这里,根据实际标签 y 和预测值 a3,计算出输出层的误差 Delta3,表示输出层的误差信号。
接下来,通过矩阵乘法和逐元素乘法,计算出隐藏层的误差 Delta2,表示隐藏层的误差信号。
最后,去除 Delta2 中对应于偏置单元的误差项,并用 Delta2 和 Delta3 来更新隐藏层和输出层的梯度。
# 向后传播
Delta3 = a3 - y_vect
Delta2 = np.dot(Delta3, Theta2) * a2 * (1 - a2)
Delta2 = Delta2[:, 1:]计算梯度
使用误差信号 Delta2 和 Delta3 来计算隐藏层 Theta1 和输出层 Theta2 的梯度。
Theta1_grad = (1 / m) * (Delta2^T * a1) + (lambda / m) * Theta1,其中 a1 是输入层的激活值,^T 表示转置操作。
Theta2_grad = (1 / m) * (Delta3^T * a2) + (lambda / m) * Theta2,其中 a2 是隐藏层的激活值。
# 计算梯度
Theta1[:, 0] = 0
Theta1_grad = (1 / m) * np.dot(Delta2.transpose(), a1) + (lamb / m) * Theta1
Theta2[:, 0] = 0
Theta2_grad = (1 / m) * np.dot(Delta3.transpose(), a2) + (lamb / m) * Theta2
grad = np.concatenate((Theta1_grad.flatten(), Theta2_grad.flatten()))4.设计前馈神经网络反馈训练效果
设计一个简单的前馈神经网络,使用刚才训练得到的参数Theta1,Theta2来对输入的数字信息进行分类。这个函数可以有效的对手写数字进行识别。
def predict(Theta1, Theta2, X):
m = X.shape[0]
one_matrix = np.ones((m, 1))
X = np.append(one_matrix, X, axis=1) # 给第一层加入偏置参数
z2 = np.dot(X, Theta1.transpose())
a2 = 1 / (1 + np.exp(-z2)) # 使用Sigmoid函数激活第二层
one_matrix = np.ones((m, 1))
a2 = np.append(one_matrix, a2, axis=1) # 给第二层加入偏置参数
z3 = np.dot(a2, Theta2.transpose())
a3 = 1 / (1 + np.exp(-z3)) # 激活第三层
p = (np.argmax(a3, axis=1)) # 输出预测的分类
return p5.对模型精准度的分析
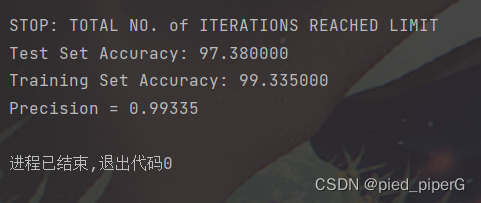
首先是使用测试集和数据集,对模型精准度进行一个比例的测试。
而后用得到的数据,使用评估标准,对模型进行评估
# 训练集的准确度
pred = predict(Theta1, Theta2, X_train)
print('Training Set Accuracy: {:f}'.format((np.mean(pred == y_train) * 100)))
# 模型的准确率(Precision)
true_positive = 0
for i in range(len(pred)):
if pred[i] == y_train[i]:
true_positive += 1
false_positive = len(y_train) - true_positive
print('Precision =', true_positive / (true_positive + false_positive))6.GUI的实现
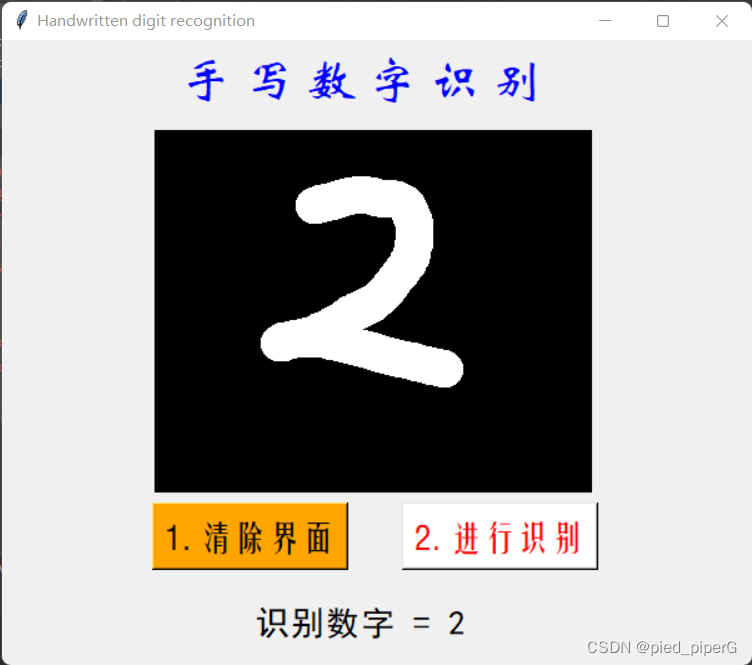
使用tkinter库实现简单的GUI,构建画布,然后将画布上的像素灰度处理,并转换为和MINST数据集中一样的格式数据,传递给前馈神经网络预测函数Predict来得到结果,并展示在屏幕上。
from tkinter import *
import numpy as np
from PIL import ImageGrab
from Prediction import predict
window = Tk()
window.title("Handwritten digit recognition")
l1 = Label()
def MyProject():
global l1
widget = cv
# 设置画布的坐标(加入参数index=55就对齐了,不知道为什么)
index = 55
x = window.winfo_rootx() + widget.winfo_x() + index
y = window.winfo_rooty() + widget.winfo_y() + index
x1 = x + widget.winfo_width() + index
y1 = y + widget.winfo_height() + index
# print(x, y, x1, y1)
# 从画布上提取图像并修改像素大小为 (28 X 28)
img = ImageGrab.grab().crop((x, y, x1, y1)).resize((28, 28))
img.save('photo_ori.jpg')
# 灰度处理(感觉没必要,本身就是黑白)
img = img.convert('L')
img.save('photo.jpg')
# 提取图像的像素矩阵,并转换为(1, 784)的矩阵
x = np.asarray(img)
vec = np.zeros((1, 784))
k = 0
for i in range(28):
for j in range(28):
vec[0][k] = x[i][j]
k += 1
# print(vec)
# 加载之前存储的两层神将网络权重
Theta1 = np.loadtxt('Theta1.txt')
Theta2 = np.loadtxt('Theta2.txt')
# 调用识别功能
pred = predict(Theta1, Theta2, vec / 255)
# 展示结果
l1 = Label(window, text="识别数字 = " + str(pred[0]), font=('黑体', 20))
l1.place(x=200, y=450)
lastx, lasty = None, None
# 清除界面功能实现
def clear_widget():
global cv, l1
cv.delete("all")
l1.destroy()
# 开始识别
def event_activation(event):
global lastx, lasty
cv.bind('<B1-Motion>', draw_lines)
lastx, lasty = event.x, event.y
# 展示界面
def draw_lines(event):
global lastx, lasty
x, y = event.x, event.y
cv.create_line((lastx, lasty, x, y), width=30, fill='white', capstyle=ROUND, smooth=TRUE, splinesteps=12)
lastx, lasty = x, y
# 标题展示
L1 = Label(window, text="手 写 数 字 识 别", font=('华文新魏', 30), fg="blue")
L1.place(x=140, y=10)
# 清楚界面按钮
b1 = Button(window, text="1. 清除界面", font=('方正姚体', 20), bg="orange", fg="black", command=clear_widget)
b1.place(x=120, y=370)
# 识别数字按钮
b2 = Button(window, text="2. 进行识别", font=('方正姚体', 20), bg="white", fg="red", command=MyProject)
b2.place(x=320, y=370)
# 设置手写界面参数
cv = Canvas(window, width=350, height=290, bg='black')
cv.place(x=120, y=70)
cv.bind('<Button-1>', event_activation)
window.geometry("600x500")
window.mainloop()
三.创新方法
使用GUI构建画布,即时传入在屏幕上输入的数字信息,并即时反馈识别结果。
使使用者更直观的感受到训练效果,并测试训练准确性。
四.遇到的问题与解决方式
在使用GUI对手写数字进行测试判断时,发现准确率非常低。
测试后发现问题出在对画布上元素信息的提取处理上,提取的范围没有对齐,所以导致得到的像素与实际不符,最终无法正常识别出来。
解决方式:在手动逼近尝试后,加入一个参数调整对齐。
五.结果分析与思考
看似复杂的神经网络拆分成每一个模块之后也就变得清晰起来。
迭代计算神经网络层之间的权重时,迭代次数越多,最终得到的效果越好,但速度也会越来越慢。
在迭代次数不够多时,使用GUI进行手写数字识别测试时,会发现模型会对于特定几个数字有着相当高的识别准确率,但对于特定的几个数字又有着相当低的识别准确率。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)