NLP——7.LDA主题模型(数学公式推导)
这篇文章看一下公式式怎么推导出来的。正经的LDA,主要有以下几个方面:一个函数:gamma函数四个分布:二项分布,多项分布,beta分布,狄利克雷分布一个概念一个理念:共轭先验与贝叶斯框架pLSA,LDA一个采样:Gibbs采样我们来看一下它是怎么推导出来的。共轭先验与共轭分布假定似然函数p(x|θ)p(x|θ)已知,问题是选取什么样的先验分布p(θ)p(θ)和后验分布p(...
这篇文章看一下公式式怎么推导出来的。
正经的LDA,主要有以下几个方面:
- 一个函数:gamma函数
- 四个分布:二项分布,多项分布,beta分布,狄利克雷分布
- 一个概念一个理念:共轭先验与贝叶斯框架
- pLSA,LDA
- 一个采样:Gibbs采样
我们来看一下它是怎么推导出来的。
共轭先验与共轭分布
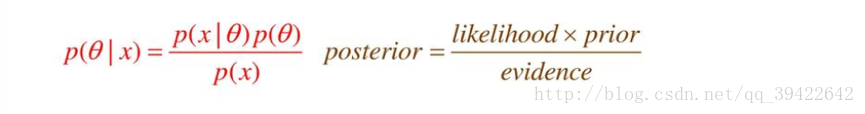
假定似然函数 p ( x ∣ θ ) p(x|θ) p(x∣θ)已知,问题是选取什么样的先验分布 p ( θ ) p(θ) p(θ)和后验分布 p ( θ ∣ x ) p(θ|x) p(θ∣x),使得他们具有相同的数学形式(参数可以不一样)。如果先验分布和后验分布具有相同的数学形式,则称他们为共轭分布,且先验分布为似然函数的共轭先验分布。
举个例子就是
先 验 分 布 : p 先 = ν a ( 1 − ν ) b 先验分布:p_先=ν^a(1−ν)^b 先验分布:p先=νa(1−ν)b
后 验 分 布 : p 后 = ν m ( 1 − ν ) n 后验分布:p_后=ν^m(1−ν)^n 后验分布:p后=νm(1−ν)n
这就是具有相同的数学形式,但参数不一样的情况。
gamma函数
对于整数而言:
Γ ( n ) = ( n − 1 ) ! Γ(n)=(n−1)! Γ(n)=(n−1)!
对于实数:
Γ ( x ) = ∫ 0 ∞ t x − 1 e − t d t Γ(x)=∫^∞_0t^{x−1e^{−t}}dt Γ(x)=∫0∞tx−1e−tdt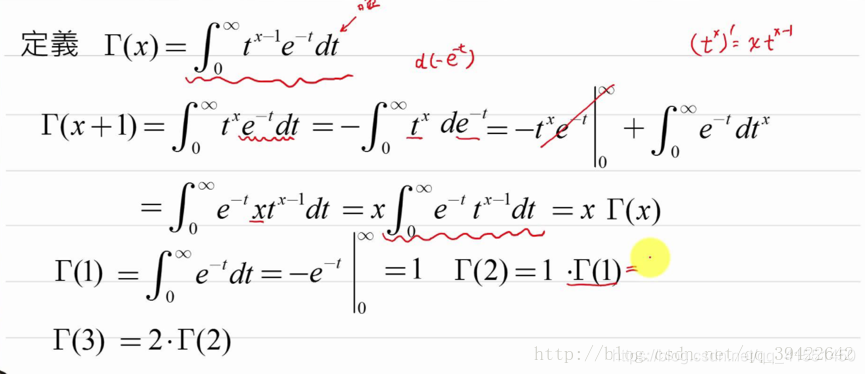
二项分布
二项分布是由n个独立的是、非重复实验中成功次数的离散概率分布其中每次成功的概率为p,相当于你去求婚,每次求婚都有两种结果,成功或失败,如果求婚一次,则称为伯努利分布,如果求婚n次的话(有点略倒霉呀!),则称为二项分布,记为:X ~ B(n,p),它的概率密度函数为:
p ( X = k ) = C n k p k ( 1 − p ) n − p = n ! k ! ( n − k ) ! p k ( 1 − p ) n − p p(X=k)=C^k_np^k(1−p)^{n−p}=\frac{n!}{k!(n−k)!}p^k(1−p)^{n−p} p(X=k)=Cnkpk(1−p)n−p=k!(n−k)!n!pk(1−p)n−p
分布如图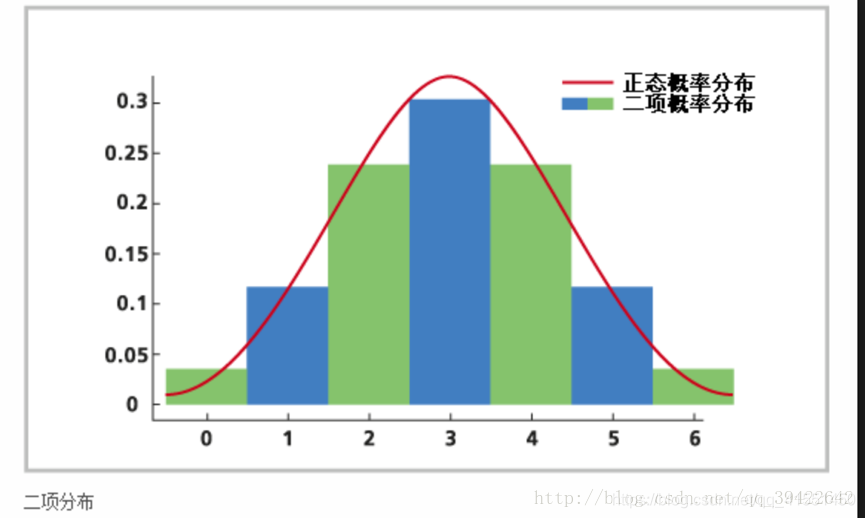
多项式分布(multinomial distribution)
多项式就是二项分布在高维情况下的推广,把求婚的例子改成抛骰子就OK了。
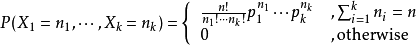
如果用骰子的例子,k=6, n i n_i ni表示出现第i点的次数 ( i ∈ 1 , 2 , 3 , 4 , 5 , 6 i ∈ 1 , 2 , 3 , 4 , 5 , 6 ) (i∈{1,2,3,4,5,6}i∈{1,2,3,4,5,6}) (i∈1,2,3,4,5,6i∈1,2,3,4,5,6); p i p_i pi表示出现第i点的概率。
beta分布
beta是指一组定义在(0,1)之间的连续概率分布,记为 X B e ( α , β ) X~Be(α,β) X Be(α,β)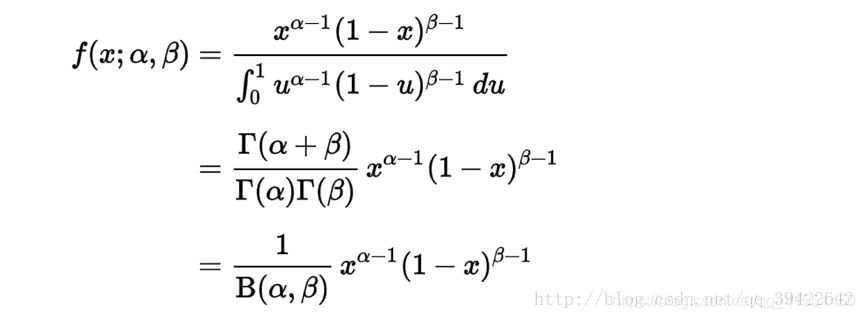
它的概率密度函数和累积分布函数为: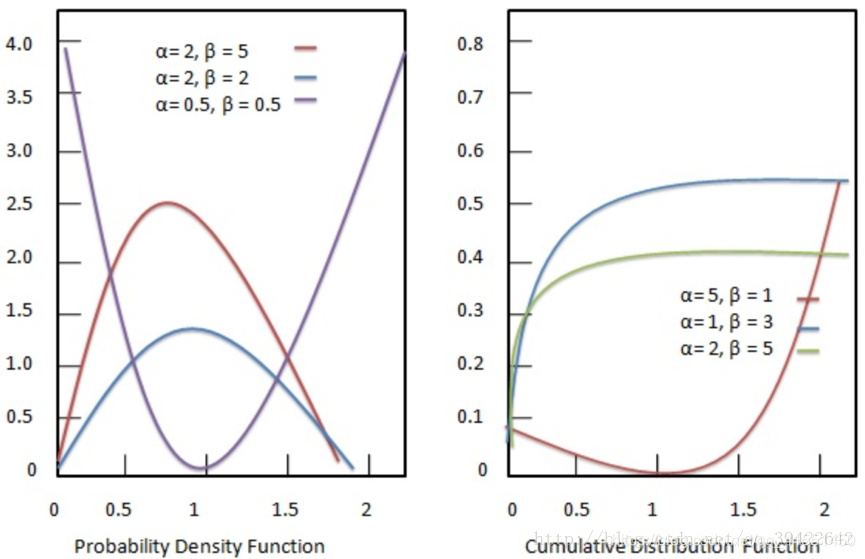
狄利克雷分布
事实上,它是Beta函数在高维空间上的推广,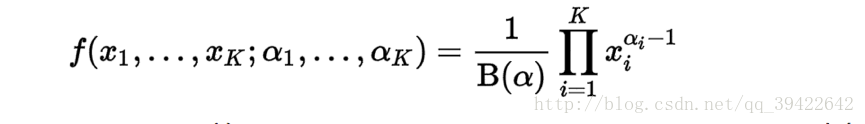
其中: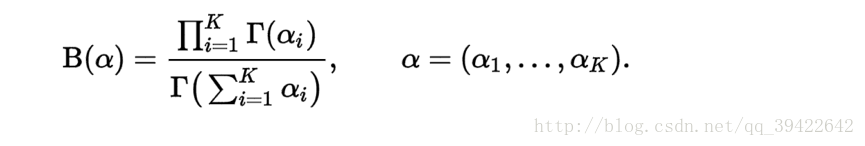
对于三维的情况下,将它的概率密度函数取对数,绘制它的分布图像如下: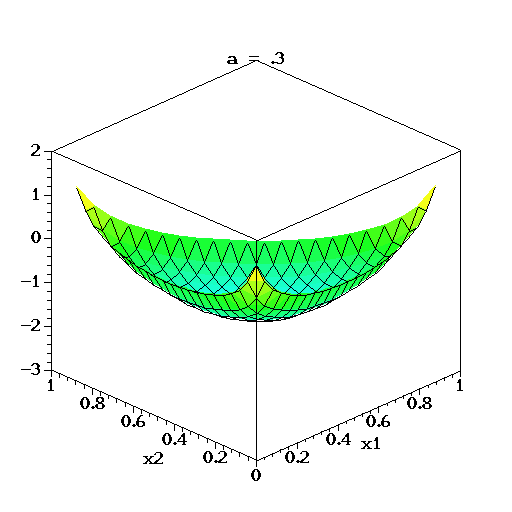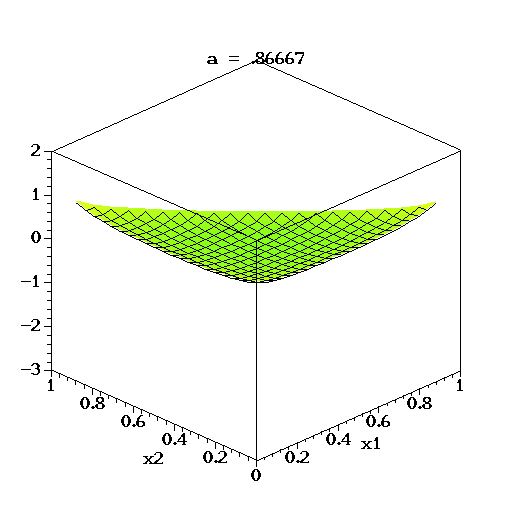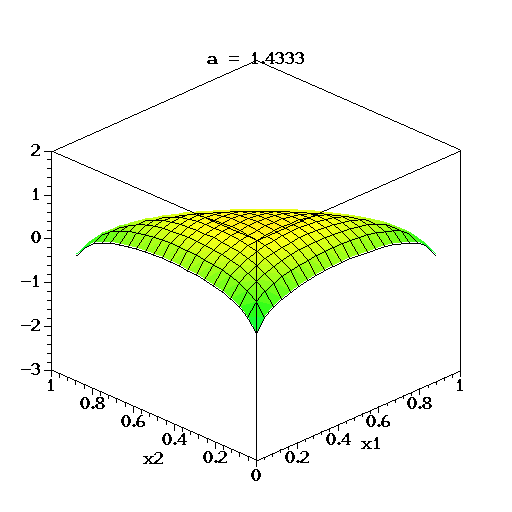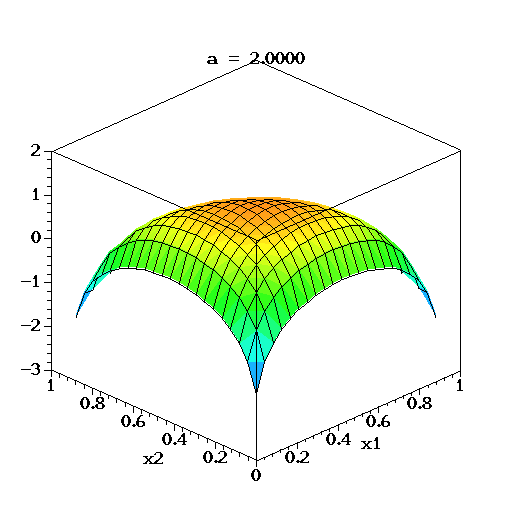
上图中,取K=3,也就是有两个独立参数x1,x2,分别对应图中的两个坐标轴,第三个参数始终满足 x 3 = 1 − x 1 − x 2 x3=1-x1-x2 x3=1−x1−x2且 α 1 = α 2 = α 3 = α α1=α2=α3=α α1=α2=α3=α,图中反映的是参数 α α α从 α = ( 0.3 , 0.3 , 0.3 ) α=(0.3, 0.3, 0.3) α=(0.3,0.3,0.3)变化到 ( 2.0 , 2.0 , 2.0 ) (2.0, 2.0, 2.0) (2.0,2.0,2.0)时的概率对数值的变化情况。
几个主题模型
1.生成模型unigram model
对于已经分好词的文档 d = ( w 1 , w 2 , w 3 , … , w N ) d=(w_1,w_2,w_3,…,w_N) d=(w1,w2,w3,…,wN),用 p ( w n ) p(w_n) p(wn)表示词 w n w_n wn的先验概率,则生成文档dd的概率为:
p ( d ) = ∏ n = 1 N p ( w n ) p(d)=∏_{n=1}^Np(w_n) p(d)=n=1∏Np(wn)
这个是最简单的方法,就是把文章中每个单词出现的概率是多少乘起来,就等于这篇文档的出现的概率。
2.Mixture of unigrams model
这个模型的生成过程是先给某个文档生成主题,再根据主题生成文档,该文档中的每个词都来源于同一主题。
举个例子,假如有k个主题:z1,z2,z3,…,zkz1,z2,z3,…,zk,那生成文档的概率为:
p ( d ) = p ( z 1 ) ∏ i = 1 N p ( w i ∣ z 1 ) + p ( z 2 ) ∏ i = 1 N p ( w i ∣ z 2 ) ⋯ + p ( z k ) ∏ i = 1 N p ( w i ∣ z k ) p(d)=p(z_1)∏_{i=1}^Np(w_i|z_1)+p(z_2)∏_{i=1}^Np(w_i|z_2)⋯+p(z_k)∏_{i=1}^Np(w_i|z_k) p(d)=p(z1)i=1∏Np(wi∣z1)+p(z2)i=1∏Np(wi∣z2)⋯+p(zk)i=1∏Np(wi∣zk)
它的含义就是这篇文档属于某一主题 t t t 的概率乘以这篇文档中的每一个单词出现在该主题 t t t 下的概率的连乘。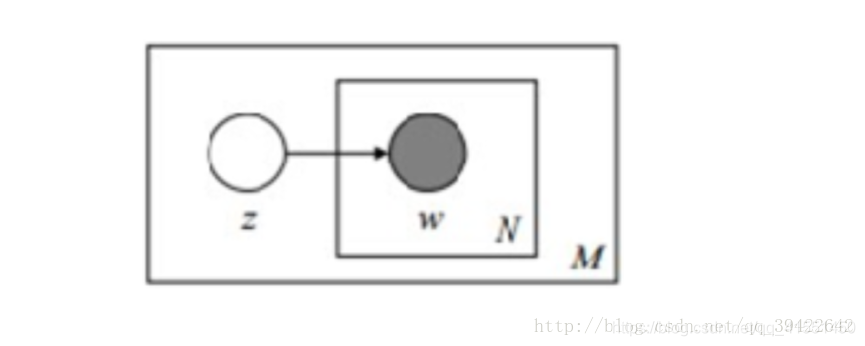
与上一个模型相比,这个模型的主要改进是使用了Topic作为中间量。
这两个模型被我们称之为生成模型,扮演的角色相当于前面的似然函数likelihood.
3.PLSA
假设有三个主题,分别为教育,经济,交通,PLSA就像扔骰子一样,第一次得到文档到主题的概率分布: P ( t ∣ d ) P(t|d) P(t∣d),第二次呢,就得到主题都单词的分布: p ( w ∣ t ) p(w|t) p(w∣t),假设得到的主题是经济,那就是 p ( 金 融 ∣ 经 济 ) p(金融|经济) p(金融∣经济),最后把这两个概率相乘,就得到了文档到单词的分布: p ( 单 词 ∣ 文 档 ) p(单词|文档) p(单词∣文档)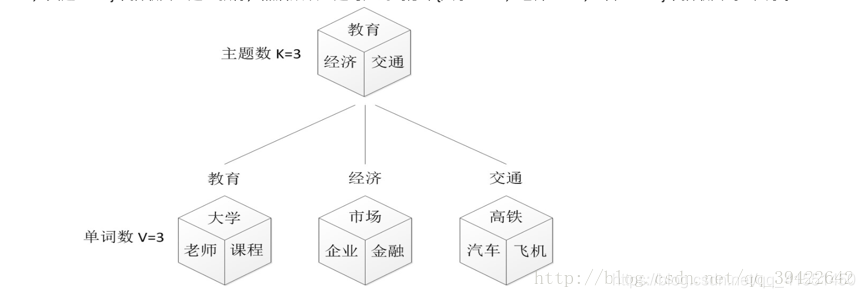
我们用公式表示出来就是: 根 据 文 档 → 单 词 的 信 息 : p ( w j ∣ d i ) 根据文档→单词的信息:p(w_j|d_i) 根据文档→单词的信息:p(wj∣di)训练出
文 档 → 主 题 : p ( z k ∣ d i ) 文档→主题:p(z_k|d_i) 文档→主题:p(zk∣di)
主 题 → 单 词 : p ( w j ∣ z k ) 主题→单词:p(w_j|z_k) 主题→单词:p(wj∣zk)
得到:
p ( w j ∣ d i ) = ∑ k = 1 K p ( w j ∣ z k ) p ( z k ∣ d i ) p(w_j|d_i)=∑_{k=1}^Kp(w_j|z_k)p(z_k|d_i) p(wj∣di)=k=1∑Kp(wj∣zk)p(zk∣di)
然后得到文档中每个词的生成概率:
p ( d i , w i ) = p ( d i ) p ( w j ∣ d i ) = p ( d i ) ∑ k = 1 K p ( w j ∣ z k ) p ( z k ∣ d i ) p(d_i,w_i)=p(d_i)p(w_j|d_i)=p(d_i)∑_{k=1}^Kp(w_j|z_k)p(z_k|d_i) p(di,wi)=p(di)p(wj∣di)=p(di)k=1∑Kp(wj∣zk)p(zk∣di)
其中, p ( d i ) p(di) p(di)可以事先计算出来,但是 p ( w j ∣ z k ) , p ( z k ∣ d i ) p(w_j|z_k),p(z_k|d_i) p(wj∣zk),p(zk∣di)是未知的,这就是我们要估计 的参数值,
θ = ( p ( w j ∣ z k ) p ( z k ∣ d i ) ) θ=(p(w_j|z_k)p(z_k|d_i)) θ=(p(wj∣zk)p(zk∣di))
最大化就是我们的优化目标。
4.LDA
LDA其实就是在PLSA上加了一层贝叶斯框架,为了更好的理解LDA,我们把LDA和PLSA比较一下:
对于PLSA:
- 按照概率 p ( d i ) p(d_i) p(di)选择一篇文档 d i d_i di
- 选定文档 d i d_i di之后,确定该文档的主题;
- 从主题分布中按照概率 p ( z k ∣ d i ) p(z_k|d_i) p(zk∣di)选择隐含的主题的类别 z k z_k zk;
- 选择主题后,确定该主题下词分布
- 从词分布中按照概率 p ( w j ∣ z k ) p(w_j|z_k) p(wj∣zk)选择一个词 w j w_j wj
对于LDA:
- 按照先验概率 p ( d i ) p(d_i) p(di)选择一篇文档 d i d_i di
- 从狄利克雷分布 α α α中取样生成文档 d i d_i di的主题分布 θ i θ_i θi,也就是主题分布 θ i θ_i θi由超参数为 α α α的狄利克雷分布构成
- 从主题的多项式分布 θ i θ_i θi取样生成文档 d i d_i di的第 j j j个词的主题 z i , j z_{i,j} zi,j
- 从狄利克雷分布ββ中取样生成主题 z i , j z_{i,j} zi,j对应的词语分布 z i , j z_{i,j} zi,j,也就是说词语分布由参数为 β β β的狄利克雷分布生成
- 从词语的多项式分布 ϕ z i , j ϕ_{z_{i,j}} ϕzi,j采样最终生成词语 w i , j w_{i,j} wi,j
用一分钟解释就是LDA把PLSA中按照固定概率取的参数都换成了某一固定的概率分布,它们的本质区别是估计未知参数所采用的思想不同,PLSA采用的是频率派的思维:参数 θ θ θ虽然未知,但它是一个确定的值;LDA采用的是贝叶斯思维:认为待估计参数为随机变量,且服从一定的概率分布。
详细公式解释:https://blog.csdn.net/v_july_v/article/details/41209515
参考
七月算法课课件

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)