pytorch GradScaler() 出现 UserWarning: Detected call of lr_scheduler.step() before optimizer.step().
UserWarning: Detected call of lr_scheduler.step() before optimizer.step(). In PyTorch 1.1.0 and later, you should call them in the opposite order: optimizer.step() before lr_scheduler.step(). Failure
问题:
在pytorch中使用GradScaler + lr_scheduler后出现UserWarning:
Detected call of lr_scheduler.step() before optimizer.step(). In PyTorch 1.1.0 and later, you should call them in the opposite order: optimizer.step() before lr_scheduler.step(). Failure to do this will result in PyTorch skipping the first value of the learning rate schedule.
检测到lr_scheduler.step()的调用在optimizer.step()之前。在PyTorch 1.1.0及更高版本中,应按相反顺序调用它们:optimizer.step()在lr_scheduler.step()之前。否则将导致PyTorch跳过学习率计划的第一个值。
即在新版的pytorch中,参数更新optimizer.step()应该放在学习率调整 lr_scheduler.step()之前。
然而如下示例代码所示,在使用了GradScaler之后,即便scaler.step(optimizer)放在scheduler.step()之前,仍然会收到此警告。
steps = len(train_dl) * epochs
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=lr, steps_per_epoch=len(train_dl), epochs=epochs)
avg_train_losses = []
avg_val_losses = []
avg_val_scores = []
lr = []
best_avg_val_score = -1000
scaler = torch.cuda.amp.GradScaler() # 混合精度
for epoch in tqdm(range(epochs), total=epochs):
model.train()
total_train_loss = 0.0
for i, (x, y, image_tensor) in enumerate(train_dl):
x, y, image_tensor = move_to_dev(x, y, image_tensor)
model.zero_grad()
with torch.cuda.amp.autocast():
output = model(x, image_tensor)
loss = criterion(y, output)
total_train_loss += loss.item()
# 反向传播和优化
scaler.scale(loss).backward()
###
scaler.step(optimizer)
scaler.update()
scheduler.step()
###
lr.append(get_lr(optimizer))可能的原因:
1、如果第一次迭代时出现了梯度为 NaN 的情况(例如,由于过高的比例因子(scale factor)导致梯度溢出),则参数更新 optimizer.step()将被跳过,直接跳到学习率调整scheduler.step(),因此即便optimizer.step()已经在scheduler.step()之前,也可能会收到此警告。
2、torch.optim.lr_scheduler.OneCycleLR()的学习率如下图所示,刚开始学习率非常小,较小的学习率应该会降低梯度溢出的概率,这也可能导致梯度为 NaN 的情况,同样会导致参数更新 optimizer.step()将被跳过,直接跳到学习率调整scheduler.step()。
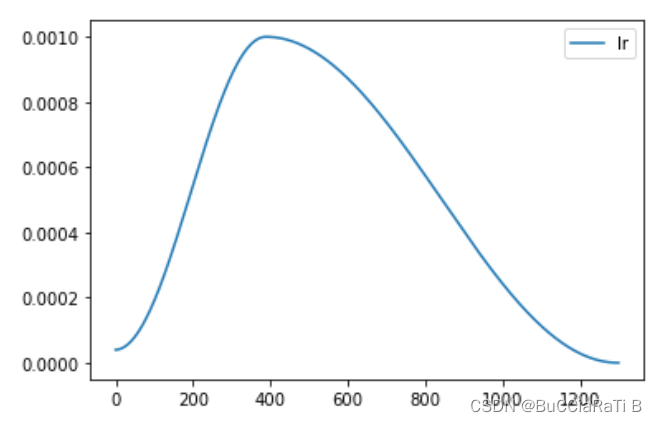
总之,如果出现了梯度为NaN的情况,则optimizer.step()将被跳过,直接跳到lr_scheduler.step(),pytorch就会认为你在没有更新参数的情况下调整了学习率,即便你已经把optimizer.step()放在lr_scheduler.step()前,也可能会收到此警告。
解决方法一:
如果该警告只是偶尔出现一次,应该可以不用管;
解决方法二:
将代码做如下修改
steps = len(train_dl) * epochs
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=lr, steps_per_epoch=len(train_dl), epochs=epochs)
avg_train_losses = []
avg_val_losses = []
avg_val_scores = []
lr = []
best_avg_val_score = -1000
scaler = torch.cuda.amp.GradScaler() # 混合精度
for epoch in tqdm(range(epochs), total=epochs):
model.train()
total_train_loss = 0.0
for i, (x, y, image_tensor) in enumerate(train_dl):
x, y, image_tensor = move_to_dev(x, y, image_tensor)
model.zero_grad()
with torch.cuda.amp.autocast():
output = model(x, image_tensor)
loss = criterion(y, output)
total_train_loss += loss.item()
# 反向传播和优化
scaler.scale(loss).backward()
scaler.step(optimizer)
###
scale = scaler.get_scale()
scaler.update()
skip_lr_sched = (scale > scaler.get_scale())
if not skip_lr_sched:
scheduler.step()
###
lr.append(get_lr(optimizer))建议使用:skip_lr_sched = (scale > scaler.get_scale())
而非skip_lr_sched = (scale != scaler.get_scale())
因为根据 docs 7, 当 optimizer.step() 被跳过时, scaler.update()会减小 scale_factor; 当 optimizer.step() 未被跳过时,scaler.update()会增加scale_factor。
Simply checking scale != scaler.get_scale() will return False even when the scale_factor is increased (and optimizer.step has NOT been skipped), which we don’t want.
参考:
1、
https://discuss.pytorch.org/t/optimizer-step-before-lr-scheduler-step-error-using-gradscaler/92930/5
2、

3、
下溢出:下溢出一般是log(0) 或者exp(x)操作出现的问题。可能的情况可能是学习率设定过大,需要降低学习率,可以降低到学习率直至不出现nan为止,例如将学习率1e-4设定为1e-5即可。
除了降低学习率的方法,也可在在优化器上面加上一个eps来防止分母上出现0的现象,例如在batchnorm中就设定eps的数值为1e-5,在优化器同样推荐加入参数eps,torch.optim.adam中默认的eps 是1e-8。但是这个值属实有点小了,可以调大这个默认的eps 值,例如设定为1e-3。
4、
如果要解决问题,首先就要明确原因:为什么全精度训练时不会nan,但是半精度就开始nan?这其实分了三种情况:
- 计算loss 时,出现了除以0的情况
- loss过大,被半精度判断为inf
- 网络参数中有nan,那么运算结果也会输出nan
1&2我想放到后面讨论,因为其实大部分报nan都是第三种情况。这里来先看看3。什么情况下会出现情况3?这个讨论给出了不错的解释:
Nan Loss with torch.cuda.amp and CrossEntropyLoss
给大家翻译翻译:在使用ce loss 或者 bceloss的时候,会有log的操作,在半精度情况下,一些非常小的数值会被直接舍入到0,log(0)等于啥?——等于nan啊!
于是逻辑就理通了:回传的梯度因为log而变为nan->网络参数nan-> 每轮输出都变成nan。(;´Д`)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)