多元线性回归中的逐步回归及其相关理论介绍
参考书籍:1、《应用多元统计分析》高惠璇1、表达式用来研究因变量Y和m个自变量的相关关系(一共有n个样本,)矩阵表示为:记为或2、回归方程和回归系数的显著性检验2.1 回归方程的显著性检验(又称相关性检验),即不全为0统计量:(在原假设成立时,)计算统计量的值,从而得到p值,或者查表与所对应的F统计量阈值进行比较,从而得到拒绝或不能拒绝原假设的结论。2.2 回归系数的显著性检验3、回归变量的选择3
·
参考书籍:1、《应用多元统计分析》高惠璇
1、表达式
用来研究因变量Y和m个自变量的相关关系(一共有n个样本,
)
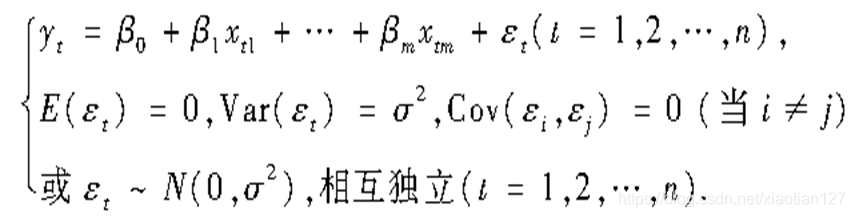
矩阵表示为:
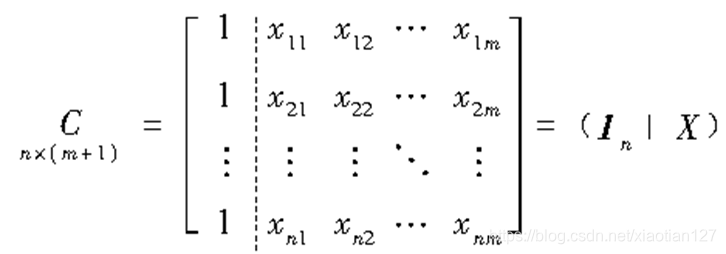
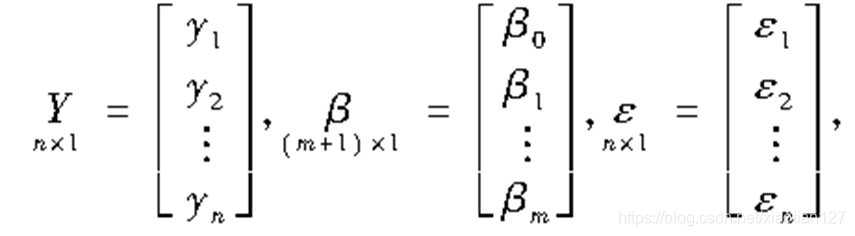
记为或
2、回归方程和回归系数的显著性检验
2.1 回归方程的显著性检验(又称相关性检验)
,即
不全为0
统计量:(在原假设成立时,
)
计算统计量的值,从而得到p值,或者查表与所对应的F统计量阈值进行比较,从而得到拒绝或不能拒绝原假设的结论。
2.2 回归系数的显著性检验

3、回归变量的选择
在实际问题中,影响因变量Y的因素(自变量)可能很多,所以要挑选出影响显著的自变量来建立回归关系式,因此涉及到自变量的选择问题。
3.1 分类
可以八种,可以分为三类:
- “最优”子集的变量筛选法: stepwise、forward、backward;
- 计算量很大的全子集法:计算所有可能回归子集(
)后按照变量选择的标准选择最优回归方程,有
选择法、
选择法、修正
- 计算量适中的选择法;
3.2 变量选择的标准
常用的有以下几种准则,分类为:
- 均方误差
,其中k为进入模型的变量个数,是回归模型中
的无偏估计;
 其中
其中。值越小越好
- 修正
,当模型含有截距项
时
,否则
。选合适的回归子集,使得
达到最大;
- AIC,SBC或BIC准则:
,其中
,

4、逐步回归分析
基本思想:逐个引入自变量,每次引入对Y影响显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除,从而得到的最终方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。
逐步回归的基本步骤如下表的三张图所示:
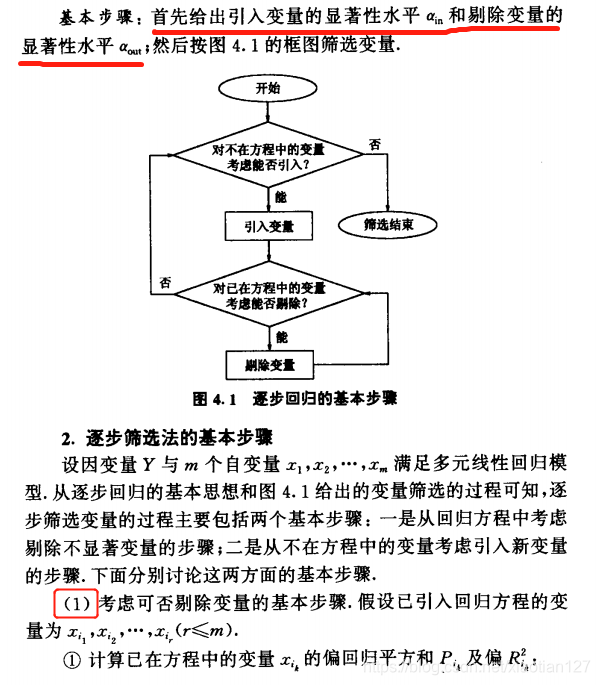 |
|
|



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)