Mybatis(一)Mybatis的基本使用
接口绑定、动态SQL
文章目录
本系列文章:
Mybatis(一)Mybatis的基本使用
Mybatis(二)Mybatis的高级使用
Mybatis(三)集成Mybatis
一、初始MyBatis
1.1 ORM
要了解ORM,先了解下面概念:
- 持久化
把数据(如内存中的对象)保存到可永久保存的存储设备中。持久化的主要应用是将内存中的数据存储在关系型的数据库中,当然也可以存储在磁盘文件中、XML数据文件中等等。 - 持久层
即专注于实现数据持久化应用领域的某个特定系统的一个逻辑层面,将数据使用者和数据实体相关联。
ORM,即Object-Relational Mapping(对象关系映射),它的作用是在关系型数据库和业务实体对象之间作一个映射。这样在具体的操作业务对象的时候,就不需要再去和复杂的SQL语句打交道,只需简单的操作对象的属性和方法。
总结:
- 它是一种
将内存中的对象保存到关系型数据库中的技术;- 主要
负责实体对象的持久化,封装数据库访问细节;- 提供了实现持久化层的另一种模式,采用映射元数据(XML)来描述对象-关系的映射细节,使得ORM中间件能在任何一个Java应用的业务逻辑层和数据库之间充当桥梁。

Java典型的ORM框架:
1)hibernate:全自动的框架,强大、复杂、笨重、学习成本较高;
2)Mybatis:半自动的框架, 必须要自己写sql;
3)JPA:JPA全称Java Persistence API、JPA通过JDK 5.0注解或XML描述对象-表的映射关系,是Java自带的框架。
1.2 MyBatis
MyBatis是一款优秀的支持自定义SQL查询、存储过程和高级映射的持久层框架,消除了几乎所有的JDBC代码和参数的手动设置以及结果集的检索。MyBatis可以使用XML或注解进行配置和映射,MyBatis通过将参数映射到配置的SQL形成最终执行的SQL语句,最后将执行SQL的结果映射成Java对象返回。
与其他的ORM(对象关系映射)框架不同,MyBatis并没有将Java对象与数据库表关联起来,而是将Java方法与SQL语句关联。MyBatis允许用户充分利用数据库的各种功能,例如存储过程、视图、各种复杂的查询以及某数据库的专有特性。
MyBatis支持声明式数据缓存。当一条SQL语句被标记为“可缓存”后,首次执行它时从数据库获取的所有数据会被存储在高速缓存中,后面再执行这条语句时就会从高速缓存中读取结果,而不是再次命中数据库。
1.2.1 MyBatis特点
- 1、定制化SQL
同为持久层框架的Hibernate,对操作数据库的支持方式较多,完全面向对象的、原生SQL的和HQL的方式。MyBatis只支持原生的SQL语句,这个“定制化”是相对Hibernate完全面向对象的操作方式的。 - 2、支持存储过程
储存过程是实现某个特定功能的一组sql语句集,是经过编译后存储在数据库中。当出现大量的事务回滚或经常出现某条语句时,使用存储过程的效率往往比批量操作要高得多。 - 3、高级映射
可以简单理解为支持关联查询。 - 4、避免了几乎所有的JDBC代码和手动设置参数以及获取结果集
使用Mybatis时,数据库的连接配置信息,是在mybatis-config.xml文件中配置的。同时,获取查询结果的代码,也是尽量做到了简洁。 - 5、Mybatis中ORM的映射方式也是比较简单的
使用resultType或resultMap标签指定SQL语句返回对象的类型。
1.2.2 Mybatis的适用场景
MyBatis专注于SQL本身,是一个足够灵活的DAO层解决方案。
MyBatis框架的适用场景:对性能的要求很高,或者需求变化较多的项目,如互联网项目。
1.2.3 为什么说Mybatis是半自动ORM映射工具
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
MyBatis作为半自动ORM映射工具与全自动ORM工具相比,有几个主要的区别点:
- 1、SQL的灵活性
MyBatis作为半自动ORM映射工具,开发人员可以灵活地编写SQL语句,充分发挥数据库的特性和优势。而全自动ORM工具通常会在一定程度上限制开发人员对SQL的灵活控制。 - 2、映射关系的可定制性
MyBatis允许开发人员通过配置文件(或注解)自定义对象和数据库表之间的映射关系,可以满足各种复杂的映射需求。而全自动ORM工具通常根据约定和规则自动生成映射关系,对于某些特殊需求无法满足。 - 3、SQL的可复用性
MyBatis支持SQL的可复用性,可以将常用的SQL语句定义为独立的SQL片段,并在需要的地方进行引用。而全自动ORM工具通常将SQL语句直接与对象的属性绑定在一起,缺乏可复用性。 - 4、性能调优的灵活性
MyBatis作为半自动ORM映射工具,允许开发人员对SQL语句进行灵活的调优,通过手动编写SQL语句和使用高级特性进行性能优化。而全自动ORM工具通常将性能优化的控制权交给框架,开发人员无法灵活地对SQL进行调优。
MyBatis作为一种半自动ORM映射工具,相对于全自动ORM工具具有更高的灵活性和可定制性。通过灵活的SQL控制、自定义的映射关系、可复用的SQL以及灵活的性能调优,MyBatis可以满足各种复杂的映射需求和性能优化需求。虽然MyBatis相对于全自动ORM工具需要开发人员编写更多的SQL语句,但正是由于这种半自动的特性,使得MyBatis在某些复杂场景下更加灵活和可控。
因此,我们可以说MyBatis是一种半自动ORM映射工具,与全自动的ORM工具相比,它更适用于那些对SQL灵活性和性能调优需求较高的场景。
1.2.4 Mybatis的优缺点
Mybatis有以下优点:
- 1、基于SQL语句编程,相当灵活
SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;提供XML标签,支持编写动态SQL语句,并可重用。 - 2、代码量少
与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接。 - 3、很好的与各种数据库兼容
- 4、数据库字段和对象之间可以有映射关系
提供映射标签,支持对象与数据库的ORM字段关系映射。 - 5、能够与Spring很好的集成
Mybatis有以下缺点:
- 1、SQL语句的编写工作量较大
尤其当字段多、关联表多时,SQL语句较复杂。 - 2、数据库移植性差
SQL语句依赖于数据库,不能随意更换数据库(可以通过在mybatis-config.xml配置databaseIdProvider来弥补),示例:
<databaseIdProvider type="DB_VENDOR">
<property name="MySQL" value="mysql"/>
<property name="SQL Server" value="sqlserver"/>
<property name="Oracle" value="oracle"/>
</databaseIdProvider>
然后在xml文件中,就可以针对不同的数据库,写不同的sql语句。示例:
<select id="selectById" resultType="user" databaseId="mysql">
select * from user where id = #{id}
</select>
关于数据源,可以在配置文件中配置一个默认数据源,示例:
<environments default="development">
<environment id="development">
...
</environment>
</environments>
- 3、字段映射标签和对象关系映射标签仅仅是对映射关系的描述,具体实现仍然依赖于sql
即resultType或resultMap标签的使用。 - 4、DAO层过于简单,对象组装的工作量较大
即Mapper层Java代码过少,XxxMapper.xml文件中维护数据库字段和实体类字段的工作量较大。 - 5、不支持级联更新、级联删除*
1.2.5 Mybatis使用时可能会产生什么问题
- 1、使用不当,会导致N+1的sql性能问题*
“N+1”问题具体指的是:
- 执行了一个单独的SQL语句来获取结果的一个列表(就是“1”)。
- 对列表返回的每条记录,执行一个select查询语句来为每条记录加载详细信息(就是“N”)。
其实就是相关联的两步查询,可能会出现"N+1"的情况。修改方法如下:
1、在sql语句中使用join语句连接多张表并进行查询(常用)。
2、使用懒加载技术,延迟“N查询”部分中各操作被执行的时间节点;
3、合并N查询为一个查询,通过使用Sql的关键字in。
- 2、使用不当,会分页BUG*
写法1:
//错误写法
startPage();
List<User> list;
if(user != null){
list = userService.selectUserList(user);
} else {
list = new ArrayList<User>();
}
Post post = postService.selectPostById(1L);
return getDataTable(list);
//正确写法
List<User> list;
if(user != null){
startPage();
list = userService.selectUserList(user);
} else {
list = new ArrayList<User>();
}
Post post = postService.selectPostById(1L);
return getDataTable(list);
以上代码错误的原因是:由于user存在null的情况,就会导致pageHelper生产了一个分页参数,但是没有被消费,这个参数就会一直保留在这个线程上。 当这个线程再次被使用时,就可能导致不该分页的方法去消费这个分页参数,这就产生了莫名其妙的分页。
写法2:
//错误写法
startPage();
Post post = postService.selectPostById(1L);
List<User> list = userService.selectUserList(user);
return getDataTable(list);
//正确写法
Post post = postService.selectPostById(1L);
startPage();
List<User> list = userService.selectUserList(user);
return getDataTable(list);
以上代码错误的原因是:只对开启分页后的第一个查询sql语句查到的数据进行分页。
- 3、使用不当,会产生脏数据*
产生脏数据的原因是Mybatis的二级缓存机制。
MyBatis二级缓存是和命名空间绑定的 ,所以通常情况下不同的Mapper映射文件都拥有自己的二级缓存,不同Mapper之间的二级缓存互不影响 。在关联多表查询时肯定会将该查询放到某个命名空间下的映射文件中,这样一个多表的查询就会缓存在该命名空间的二级缓存中。
因此,对于同一个表的数据,在一个Mapper文件了进行了增删改查,该Mapper文件对应的二级缓存发生了变化。该表所在的别的Mapper文件的二级缓存可能没发生变化,这种情况下就会产生脏数据。
脏数据解决方法:不使用Mybatis的二级缓存,使用Redis的缓存。
1.3 Mybatis和JDBC、Hibernate、JPA的区别
1.3.1 JDBC和Mybatis
JDBC(Java Data Base Connection,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。
传统的JDBC开发,通常是如下的流程:
加载驱动;
建立连接;
定义sql语句;
准备静态处理块对象;
执行sql语句;
处理结果集;
关闭连接.
传统的JDBC开发的最原始的开发方式,有以下问题:
1、频繁创建数据库连接对象、释放,容易造成系统资源浪费,影响系统性能。可以使用连接池解决这个问题,但是使用JDBC需要自己实现连接池。- 2、sql语句定义、参数设置、结果集处理存在硬编码。
实际项目中sql语句变化的可能性较大,一旦发生变化,需要修改java代码,系统需要重新编译,重新发布,不好维护。 3、使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能多也可能少,修改sql还要修改代码,系统不易维护。4、结果集处理存在重复代码,处理麻烦。如果可以映射成Java对象会比较方便。 这点也容易理解,在使用JDBC时,需要用 ResultSet之类的方式来遍历数据库中查询出来的一条条字段,这是不方便的,示例:
/*ResultSet:查询结果集*/
ResultSet rs = s.executeQuery(sql);
while (rs.next()) {
/*可以使用字段名获取该列内容*/
int id = rs.getInt("id");
/*也可以使用字段的顺序,需要注意的是:顺序是从1开始的*/
String name = rs.getString(2);
float hp = rs.getFloat("hp");
int damage = rs.getInt(4);
System.out.printf("%d\t%s\t%f\t%d%n", id, name, hp, damage);
}
- JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的
- 数据库连接创建、释放频繁造成系统资源浪费从而影响系统性能。
MyBatis:在mybatis-config.xml中配置数据连接池,使用连接池管理数据库连接。 - Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变Java代码。
MyBatis:将Sql语句配置在XXXXmapper.xml文件中,与Java代码分离。 - 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
MyBatis: Mybatis自动将Java对象映射至sql语句。 - 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
MyBatis:Mybatis可以自动将sql执行结果映射至Java对象(一般是DTO对象)。
1.3.2 Hibernate和MyBatis
相同点:都是对JDBC的封装,都是持久层的框架,都用于dao层的开发。
-
不同点1:映射关系
MyBatis是一个半自动映射的框架,配置Java对象与sql语句执行结果的对应关系,多表关联关系配置简单。
Hibernate是一个全表映射的框架,配置Java对象与数据库表的对应关系,多表关联关系配置复杂。 -
不同点2:SQL优化和移植性
Hibernate对SQL语句封装,提供了日志、缓存、级联(级联比MyBatis强大)等特性, 此外还提供HQL(Hibernate Query Language)操作数据库,数据库无关性支持好,但会多消耗性能。如果项目需要支持多种数据库,代码开发量少,但SQL语句优化困难。
MyBatis需要手动编写SQL,支持动态SQL、处理列表、动态生成表名、支持存储过程。 开发工作量相对大些。直接使用SQL语句操作数据库,不支持数据库无关性,但sql语句优 化容易。 -
不同点3:开发难易程度和学习成本
Hibernate是重量级框架,学习使用门槛高,适合于需求相对稳定,中小型的项目,比如: 办公自动化系统。
MyBatis是轻量级框架,学习使用门槛低,适合于需求变化频繁,大型的项目,比如:互 联网电子商务系统。 -
Hibernate优势
1)Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
2)Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
3)Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
4)Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。 -
Mybatis优势
1)MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
2)MyBatis容易掌握,而Hibernate门槛较高。
3)sql语句和Java代码耦合性低。 -
总结
MyBatis是一个小巧、方便、高效、简单、直接、半自动化的持久层框架,
Hibernate是一个强大、方便、高效、复杂、间接、全自动化的持久层框架。
1.3.3 Mybatis和JPA
spring data jpa默认使用hibernate作为ORM实现,是spring 提供的一套jpa接口,使用spring data jpa主要完成一些简单的增删改查功能。
对于复杂的查询功能会使用mybatis编写sql语言来实现,因为使用spring data jpa来做一些复杂的查询没有mybatis方便,spring data jpa是面向对象,而mybatis直接面向sql语句。
- 1、ORM映射不同
Mybatis是半自动的ORM框架,提供数据库与结果集的映射;
JPA(Hibernate)是全自动的ORM框架,提供对象与数据库的映射; - 2、可移植性不同
JPA(Hibernate)通过它强大的映射结构和hql语言,大大降低了对象与数据库(oracle、mysql等)的耦合性。
Mybatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。 - 3、日志系统的完整性不同
JPA(Hibernate)日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而Mybatis则除了基本记录功能外,功能薄弱很多。 - 4、SQL优化上的区别
由于Mybatis的sql都是写在xml里,因此优化sql比Hibernate方便很多。而Hibernate的sql很多都是自动生成的,无法直接维护sql;虽有hql,但功能还是不及sql强大,见到报表等变态需求时,hql也歇菜,也就是说hql是有局限的;hibernate虽然也支持原生sql,但开发模式上却与orm不同,需要转换思维,因此使用上不是非常方便。总之写sql的灵活度上Hibernate不及Mybatis。
1.4 Mybatis和MybatisPlus的比较
MybatisPlus是一个Mybatis的增强工具,在MyBatis的基础上只做增强不做改变,简化开发、提高效率。
Mybatis依赖示例:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.3.0</version>
</dependency>
MybatisPlus依赖示例:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3</version>
</dependency>
1.4.1 MybatisPlus的特性
MybatisPlus官网上给出了MybatisPlus的12个特性。
- 1、无侵入:由于MybatisPlus是在Mybatis基础上做了功能扩展,只做增强不做改变,引入它不会对现有工程产生影响。
- 2、损耗小:启动即会自动注入基本CURD,性能基本无损耗,直接面向对象操作。
- 3、强大的CRUD操作:内置通用Mapper、通用Service,仅仅通过少量配置即可实现单表大部分CRUD操作,更有强大的条件构造器,满足各类使用需求。
- 4、支持Lambda形式调用:通过Lambda表达式,方便的编写各类查询条件,无需再担心字段写错。
- 5、支持主键自动生成:支持多达4种主键策略(内含分布式唯一ID生成器:Sequence),可自由配置,完美解决主键问题。
- 6、支持ActiveRecord模式:支持ActiveRecord形式调用,实体类只需继承Model类即可进行强大的CRUD操作。
- 7、支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )。
- 8、内置代码生成器:采用代码或者Maven插件可快速生成 Mapper 、Model 、Service 、 Controller层代码,支持模板引擎,更有超多自定义配置等您来使用。
- 9、内置分页插件:基于MyBatis物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询。
- 10、分页插件支持多种数据库:支持MySQL、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer等多种数据库。
- 11、内置性能分析插件:可输出SQL语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询。
- 12、内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作。
1.4.2 Mybatis和MybatisPlus使用的差别(驼峰映射/MybatisPlus有关于表名和字段映射的注解/简单的增删改查MybatisPlus不用写sql)
以下列举几点两者在使用上的差别。
- 1、驼峰映射
在Mybatis中,驼峰映射默认是关闭的;在MybatisPlus中是默认打开的。如设置不使用驼峰规则:
mybatis-plus.configuration.map-underscore-to-camel-case=false
- 2、实体类和表对应关系的一些注解
在MybatisPlus中,有一些注解,可以用来表示实体类和数据库表的对应关系。常见的有:@TableName、@TableId、@TableField。
@TableName("table_name"):在数据库表对应的实体类中,指定该实体类在数据库中对应的表名。示例:
@TableName("test_user")
@Data
public class User implements Serializable {
}
@TableId(ype=IdType.AUTO):若type=IdType.AUTO则表示id自增长,一般用来注解在主键对应的字段上。示例:
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
@TableField(value="email"):指定某个实体类字段在数据库中的字段名。如果实体类字段名和字段名符合下划线和驼峰的转换关系的话,该注解可以不使用。但通常为了代码的易读性,使用该注解,示例:
@TableField("tag_code")
private String tagCode;
@TableField(exist=false):通常我们在写查询sql时,会将查询结果封装成一个实体类,实体类属性为数据库表对应的字段。如果某个查询字段不是数据库中的字段,就需要在该字段上使用该注解,表示该字段不对应数据中的任何字段。
- 3、是否可以不写SQL
这应该是Mybatis和MybatisPlus最核心的区别之一了。Mybatis是必须要写sql的,无论是用注解还是xml文件的方式。而MybatisPlus则不用写sql就可以实现基本的CRUD功能。
Mybatis需要写sql,常用方式有2种:注解和xml的形式。
Mybatis1:注解的方式
用注解的方式写sql,也就是将sql写在Java代码中。示例:
@Select("select \* from Type where id = #{id, jdbcType=LONG} and code= #{code, jdbcType=VARCHAR}")
Type selectTypeById(@Param("id") Long id, @Param("code") String code);
这种写法,不仅耦合性高,而且可读性差,不易维护,所以这种方式不推荐使用。
Mybatis2:xml的方式
将sql写在XxxMapper.java对应的XxxMapper.xml文件中,这是使用Mybatis时常用的做法。示例:
<select id="queryUserByCustNo" parameterType="java.lang.String" resultType="com.test.entity.User">
select
cust_no as custNo,
age,
name
from
test_user
where
cust_no = #{custNo}
</select>
这样的作法无可厚非,但不方便的是,即便是再简单的sql,也需要写对应的xml文件,增加一些工作量。
对于基本的CRUD,MybatisPlus则不用写对应xml文件,就可以实现。具体的步骤如下:
1、指定了具体数据库表的实体类
示例:
@TableName("test_user")
@Data
public class User implements Serializable {
}
2、继承了BaseMapper的类
编写一个XxxMapper文件,继承BaseMapper,这样不写具体的XxxMapper.xml文件,就可以使用简单的CRUD功能。示例:
// 继承BaseMapper,User是数据库表对应的实体类
public interface UserMapper extends BaseMapper<User> {
}
3、使用继承了BaseMapper的类
在查询时,经常会用到QueryWrapper,查询结果有2种:1条记录或多条记录,分别对应selectOne方法和selectList方法。示例:
// 查询1条记录
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("cust_no", user.getCustNo());
List<User> userList = userMapper.selectOne(wrapper);
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("status", "1");
List<User> userList = userMapper.selectList(wrapper);
在实现基本的查询时,除了使用QueryWrapper,也可以使用EntityWrapper,两者在简单的查询上没啥差别。示例:
EntityWrapper<User> queryWrapper = new EntityWrapper<User>();
queryWrapper.eq("age", 23);
List<User> loanInfoEntities = userMapper.selectList(queryWrapper);
使用MybatisPlus实现简单的增删改
其实不仅查询功能,实现了BaseMapper的类,还可以在不写sql的情况下,实现修改、新增、删除功能。示例:
// 新增
User user = new User();
user.setName("zhangsan");
user.setAge(23);
userMapper.insert(user);
// 根据id进行删除
User user = new User();
user.setId("123456789");
sresult = userMapper.deleteById(user);
//根据name更新,其他属性不变
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("name","zhangsan");
User user = new User();
user.setAge(18);
userMapper.update(user, updateWrapper);
1.4.3 使用MybatisPlus时的注意事项(实体类属性要用包装类)
以上是MybatisPlus查询的最基本使用。在查询时,需要注意的是,在实体类中,一定要使用包装类,而不能使用基本类型。以下是错误的示例:
@TableName("test_user")
@Data
public class User implements Serializable {
@TableField("status")
private String status;
@TableField("age")
private int age;
//....
}
以下为查询代码:
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("status", "1");
List<User> userList = userMapper.selectList(wrapper);
上面的查询sql可能会差不出来数据,因为age字段是基本数字类型int,默认值为0,所以上面的代码在转换为sql时,转换为的sql是:
select * from test_user where status = '1' and age = 0
所以在写实体类时,尽量使用对象类型,不使用基本类型,会避免掉一些不必要的问题。
1.4.4 Mybatis-plus常用注解(@TableName/@TableId/@TableField)
- @TableName/@TableId/@TableField
@TableName用来将指定的数据库表和JavaBean进行映射。
@TableId用于将某个成员变量指定为数据表主键。
@TableField用于标识非主键的字段。将数据库列与JavaBean中的属性进行映射。示例:
@TableName(value = "user")
public class UserBean {
@TableId(value = "user_id", type = IdType.AUTO)
private String userId;
@TableField("name")
private String name;
@TableField("sex")
private String sex;
@TableField("age")
private Integer age;
}
- @Param
@Param注解的作用是给参数命名,参数命名后就能根据名字得到参数值,正确的将参数传入sql语句中。示例:
public int getUsersDetail(@Param("userId") int userId);
- @MapperScan/@Mapper
指定要变成实现类的接口所在的包,包下面的所有接口在编译之后都会生成相应的实现类。
在接口类上添加了@Mapper,在编译之后会生成相应的接口实现类。
示例:
@SpringBootApplication
@MapperScan({"com.kfit.demo","com.kfit.user"})
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
@Mapper
public interface Inter {
int queryUserByid(int id);
}
二、Mybatis的使用
2.1 Mybatis使用示例
- 1、数据库准备
创建一个名为mybatis的数据库,然后再创建一个名为country的表并插入一些简单的数据。
-- 创建数据库
CREATE DATABASE mybatis DEFAULT CHARACTER SET utf8 COLLATE utf8 general ci;
-- 创建表
use mybatis;
CREATE TABLE country (
id int NOT NULL AUTO INCREMENT,
countryname varchar(255) NULL,
countrycode varchar(255) NULL,
PRIMARY KEY (id)
);
-- 插入数据
insert country(countryname,countrycode) values('中国','CN'),('美国','US'),('俄罗斯','RU'),('英国','GB'),('法国','FR');
- 2、配置Mybatis
导入mybatis和mysql相关依赖:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
使用XML形式进行配置,首先在src/main/resources下面创建mybatis-config.xml配置文件,配置内容示例:
<?xml version="1.0"encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="logImpl"value="LOG4J"/>
</settings>
<typeAliases>
<package name="tk.mybatis.simple.model"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name=""value=""/>
</transactionManager>
<dataSource type="UNPOOLED">
<property name="driver"value="com.mysql.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://localhost:3306/mybatis"/>
<property name="username"value="root"/>
<property name="password"value=""/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="tk/mybatis/simple/mapper/CountryMapper.xml"/>
</mappers>
</configuration>
这个配置的作用简述:
<settings>中的logImpl属性配置指定使用L0G4J输出日志。
<typeAliases>元素下面配置了一个包的别名,通常确定一个类的时候需要使用类的全限定名称,例如tk.mybatis.simple.model,Country。在MyBatis中需要频繁用到类的全限定名称,为了方便使用,我们配置了tk.mybatis.simple.model包,这样配置后,在使用类的时候不需要写包名的部分,只使用Country即可。
<environments>环境配置中主要配置了数据库连接,数据库的ur1为jdbc:mysql://1 ocalhost:3306/mybatis,使用的是本机MySQL中的mybatis数据库,后面的username和password分别是数据库的用户名和密码。
<mappers>中配置了一个包含完整类路径的CountryMapper.xml,这是一个MyBatis的SQL语句和映射配置文件。
- 3、创建实体类和Mapper.xml文件
在实际应用中,一个表一般会对应一个实体,用于INSERT、UPDATE、DELETE和简单的SELECT操作,所以称这个简单的对象为实体类。
在MyBatis中,根据MyBatis官方的习惯,一般用Mapper作为XML和接口类名的后缀。
在src/main/java下创建一个基础的包tk.mybatis.simple,在这个包下面再创建model包。再根据数据库表country,在model包下创建实体类Country。示例:
package tk.mybatis.simple.model;
public class Country{
private Long id;
private String countryname;
private String countrycode;
//...
}
在src/main/resources下面创建tk/mybatis//simple/mapper目录,再在该目录下面创建CountryMapper.xml文件,示例:
<?xml version="1.0"encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="tk.mybatis.simple.mapper.CountryMapper">
<select id="selectAll"resultType="Country">
select id,countryname,countrycode from country
</select>
</mapper>
<mapper>:XML的根元素,属性namespace定义了当前XML的命名空间。
<select>元素:我们所定义的一个SELECT查询。
id:定义了当前SELECT查询的唯一一个id。
resultType:定义了当前查询的返回值类型,此处就是指实体类Country,前面配置中提到的别名主要用于这里,如果没有设置别名,此处就需要写成resultType=“tk.mybatis.simple.model.Country”。
- 4、配置日志输出
此处配置日志,是为了方便查看SQL执行的过程和其他信息。日志选用Log4j,相关的依赖示例:
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.12</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
在src/main/resources中添加log4 j.properties配置文件,内容示例:
#全局配置
l0g4j.rootLogger=ERROR,stdout
#MyBatis日志配置
log4j.logger.tk.mybatis.simple.mapper=TRACE
#控制台输出配置
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern:=%5p[%t]-%m%n
- 5、测试
常用的测试框架为junit,配置示例:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
首先在src/test/java中创建tk.mybatis.simple.mapper包,然后创建CountryMapperTest测试类。示例:
public class CountryMapperTest {
private static SqlSessionFactory sqlSessionFactory;
@Beforeclass
public static void init(){
try{
Reader reader = Resources.getResourceAsReader ("mybatis-config.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
reader.close();
catch (IOException ignore){
ignore.printstackTrace();
}
}
@Test
public void testSelectAll(){
SqlSession sqlSession = sqlSessionFactory.openSession ()
try{
List<Country> countryList = sqlSession.selectList ("selectAll");
printCountryList (countryList);
}finally{
//不要忘记关闭sqlSession
sqlSession.close();
}
}
private void printCountryList(List<Country>countryList){
for(Country country countryList){
System.out.printf("%-4d%4s%4s\n",
country.getId(),country.getCountryname(),country.getCountrycode());
}
}
}
2.2 mybatis-config.xml详解
mybatis-config.xml是Mybatis使用的核心配置文件。在该文件中,各个标签是有顺序的,因为mybatis加载配置文件的源码中是按照这个顺序进行解析的:
<configuration>
<!-- 配置顺序
properties
settings
typeAliases
typeHandlers
objectFactory
plugins
environments
environment
transactionManager
dataSource
mappers
-->
</configuration>
1、<properties>
一般将数据源的信息单独放在一个properties文件中,然后用这个标签引入,在下面environment标签中,就可以用${}占位符快速获取数据源的信息。示例:
<properties>
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://mysql://localhost:3306/mybatis"/>
<property name="username" value="root"/>
<property name="password" value="learn"/>
</properties>
置完这些属性信息之后,就可以在XML文件的上下文中使用:
<dataSource type="POLLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
2、<settings>
用来开启或关闭mybatis的一些特性。示例:
<!-- 配置全局属性 -->
<settings>
<!-- 使用jdbc的getGeneratedKeys获取数据库自增主键值 -->
<setting name="useGeneratedKeys" value="true" />
<!-- 使用列别名替换列名 默认:true -->
<setting name="useColumnLabel" value="true" />
<!-- 开启驼峰命名转换:Table{create_time} -> Entity{createTime} -->
<setting name="mapUnderscoreToCamelCase" value="true" />
<!-- 开启延迟加载 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!-- 开启二级缓存 -->
<settings name="cacheEnabled" value="true"/>
</settings>
3、<typeAliases>
在XXXMapper.xml中需要使用parameterType和resultType属性来配置SQL语句的输入参数类型和输出参数类型,类必须要写上全限定名,比如一个SQL的返回值映射为Student类,则resultType属性要写com.test.po.Student,可以用别名来简化书写,示例:
<typeAliases>
<typeAlias type="com.test.po.Student" alias="student"/>
</typeAliases>
之后就可以在resultType上直接写student,mybatis会根据别名配置自动找到对应的类。当然,如果想要一次性给某个包下的所有类设置别名,可以用如下的方式:
<typeAliases>
<package name="com.test.po"/>
</typeAliases>
如此,指定包下的所有类,都会以简单类名的小写形式,作为它的别名。
别名使用时是不区分大小写的。
另外,对于基本的Java类型 -> 8大基本类型以及包装类,以及String类型,mybatis提供了默认的别名,别名为其简单类名的小写,比如原本需要写java.lang.String,其实可以简写为string。
Mybatis默认的别名在TypeAliasRegistry中进行注册的,这个类就是Mybatis注册别名使用的,别名和具体的类型关联是放在这个类的一个map属性(typeAliases)中。
Mybatis默认为很多类型提供的别名:
| 别名 | 对应的实际类型 |
|---|---|
| _byte | byte |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| object | Object |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
| iterator | Iterator |
别名的原理:Mybatis允许我们给某种类型注册一个别名,别名和类型之间会建立映射关系,这个映射关系存储在一个map对象中,key为别名的名称,value为具体的类型。当我们通过一个名称访问某种类型的时候,Mybatis根据类型的名称,先在别名和类型映射的map中按照key进行查找,如果找到了直接返回对应的类型。如果没找到,会将这个名称当做完整的类名去解析成Class对象,如果这2步解析都无法识别这种类型,就会报错。
4、<typeHandlers>
用于处理Java类型和Jdbc类型之间的转换,mybatis有许多内置的TypeHandler,比如StringTypeHandler,会处理Java类型String和Jdbc类型CHAR和VARCHAR。
如果要对特殊的字段进行解析,可以自定义类型转换器。简单的使用步骤:
1)在Java代码中继承BaseTypeHandler,实现自定义转换器逻辑。
2)在mybatis-config.xml文件中,注册自定义转化器:
<typeHandlers>
<typeHandler handler="com.zdp.type.CommentTypeHandler"/>
</typeHandlers>
3) 在需要使用的字段上指定自定义转化器:
<!-- 插入时使用 -->
<insert id="insertBlog" parameterType="com.zdp.entity.BlogComment">
insert into blog (bid, name, author_id, comment)
values (
#{bid,jdbcType=INTEGER},
#{name,jdbcType=VARCHAR},
#{authorId,jdbcType=INTEGER},
#{comment,jdbcType=VARCHAR, typeHandler=com.zdp.type.CommentTypeHandler}
)
</insert>
<!-- 查询时使用 -->
<resultMap id="BaseResultMap" type="com.zdp.entity.BlogComment">
<id column="bid" property="bid" jdbcType="INTEGER"/>
<result column="name" property="name" jdbcType="VARCHAR"/>
<result column="author_id" property="authorId" jdbcType="INTEGER"/>
<result column="comment" property="comment" jdbcType="VARCHAR" typeHandler="com.zdp.type.CommentTypeHandler"/>
</resultMap>
<select id="selectBlogById" resultMap="BaseResultMap" statementType="PREPARED" useCache="false">
select * from blog where bid = #{bid}
</select>
5、<objectFactory>
mybatis会根据resultType或resultMap的属性来将查询得到的结果封装成对应的Java类,它有一个默认的DefaultObjectFactory,用于创建对象实例。
该标签使用较少,如果通过继承DefaultObjectFactory类的方法来实现了自定义的ObjectFactory,那么就得使用Mybatis提供的标签来注册自定义的ObjectFactory。示例:
<objectFactory type="">
<property name="" value=""/>
</objectFactory>
6、<plugins>
可以用来配置mybatis的插件,比如在开发中经常需要对查询结果进行分页,就需要用到pageHelper分页插件,这些插件就是通过这个标签进行配置的。示例:
<!-- PageHelper 分页插件 -->
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="helperDialect" value="mysql"/>
</plugin>
</plugins>
7、<environments>
配置数据源。示例:
<environments default="development">
<environment id="development">
<!-- 使用jdbc事务管理 -->
<transactionManager type="JDBC" />
<!-- 数据库连接池 -->
<dataSource type="POOLED">
<property name="driver" value="${driver}" />
<property name="url" value="${url}" />
<property name="username" value="${username}" />
<property name="password" value="${password}" />
</dataSource>
</environment>
</environments>
8、<mappers>
用来配置XxxMapper.xml映射文件。示例:
<!-- Using classpath relative resources -->
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<mapper resource="org/mybatis/builder/BlogMapper.xml"/>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
2.3 【XML方式实现接口绑定】
- 准备工作
此处设定了一个简单的权限控制需求,采用RBAC(Role-Based Access Control,基于角色的访问控制)方式,这也是实际开发中常见的情况。
权限管理的需求的常见方式:一个用户拥有若干角色,一个角色拥有若干权限,权限就是对某个资源(模块)的某种操作(增、删、改、查),这样就构成了“用户-角色-权限”的授权模型。在这种模型中,用户与角色之间、角色与权限之间,一般是多对多的关系。示例: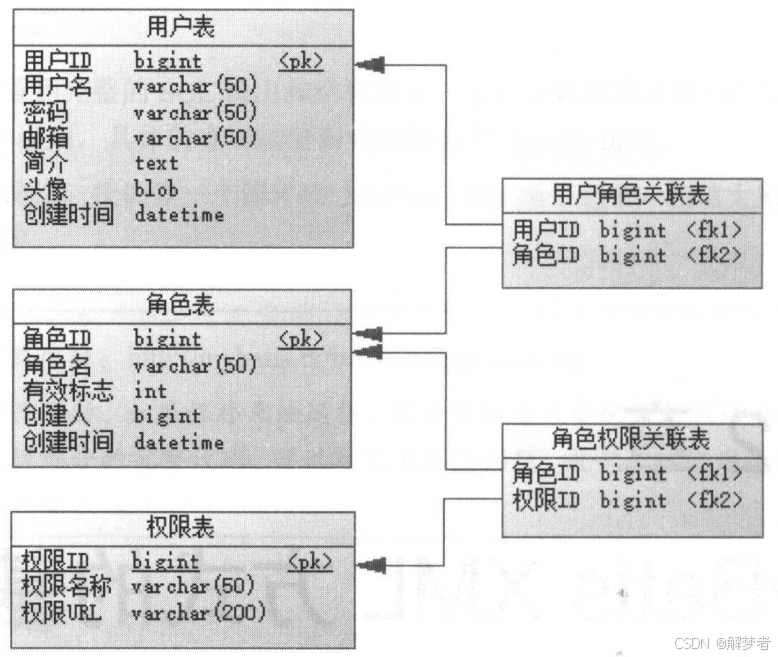
2.3.1 创建数据库表和实体类
- 创建表
要创建五个表:用户表、角色表、权限表、用户角色关系表和角色权限关系表,并插入一些简单的数据。示例:
-- 权限表
DROP TABLE IF EXISTS `sys_privilege`;
CREATE TABLE `sys_privilege` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '权限ID',
`privilege_name` varchar(50) DEFAULT NULL COMMENT '权限名称',
`privilege_url` varchar(200) DEFAULT NULL COMMENT '权限URL',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 COMMENT='权限表';
INSERT INTO `sys_privilege` VALUES ('1', '用户管理', '/users');
INSERT INTO `sys_privilege` VALUES ('2', '角色管理', '/roles');
INSERT INTO `sys_privilege` VALUES ('3', '系统日志', '/logs');
INSERT INTO `sys_privilege` VALUES ('4', '人员维护', '/persons');
INSERT INTO `sys_privilege` VALUES ('5', '单位维护', '/companies');
-- 角色表
DROP TABLE IF EXISTS `sys_role`;
CREATE TABLE `sys_role` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '角色ID',
`role_name` varchar(50) DEFAULT NULL COMMENT '角色名',
`enabled` int(11) DEFAULT NULL COMMENT '有效标志',
`create_by` bigint(20) DEFAULT NULL COMMENT '创建人',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='角色表';
INSERT INTO `sys_role` VALUES ('1', '管理员', '1', '1', '2016-04-01 17:02:14');
INSERT INTO `sys_role` VALUES ('2', '普通用户', '1', '1', '2016-04-01 17:02:34');
-- 角色权限关联表
DROP TABLE IF EXISTS `sys_role_privilege`;
CREATE TABLE `sys_role_privilege` (
`role_id` bigint(20) DEFAULT NULL COMMENT '角色ID',
`privilege_id` bigint(20) DEFAULT NULL COMMENT '权限ID'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='角色权限关联表';
INSERT INTO `sys_role_privilege` VALUES ('1', '1');
INSERT INTO `sys_role_privilege` VALUES ('1', '3');
INSERT INTO `sys_role_privilege` VALUES ('1', '2');
INSERT INTO `sys_role_privilege` VALUES ('2', '4');
INSERT INTO `sys_role_privilege` VALUES ('2', '5');
-- 用户表
DROP TABLE IF EXISTS `sys_user`;
CREATE TABLE `sys_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '用户ID',
`user_name` varchar(50) DEFAULT NULL COMMENT '用户名',
`user_password` varchar(50) DEFAULT NULL COMMENT '密码',
`user_email` varchar(50) DEFAULT 'test@mybatis.tk' COMMENT '邮箱',
`user_info` text COMMENT '简介',
`head_img` blob COMMENT '头像',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1035 DEFAULT CHARSET=utf8 COMMENT='用户表';
INSERT INTO `sys_user` VALUES ('1', 'admin', '123456', 'admin@mybatis.tk', '管理员用户', null, now());
INSERT INTO `sys_user` VALUES ('1001', 'test', '123456', 'test@mybatis.tk', '测试用户', null, now());
-- 用户角色关联表
DROP TABLE IF EXISTS `sys_user_role`;
CREATE TABLE `sys_user_role` (
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`role_id` bigint(20) DEFAULT NULL COMMENT '角色ID'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户角色关联表';
INSERT INTO `sys_user_role` VALUES ('1', '1');
INSERT INTO `sys_user_role` VALUES ('1', '2');
INSERT INTO `sys_user_role` VALUES ('1001', '2');
- 创建实体类
MyBatis默认是遵循“下画线转驼峰”命名方式的,所以在创建实体类时一般都按照这种方式进行创建。因此,上面5个表对应的5个实体类为:SysUser、SysRole、SysPrivilege、SysUserRole和SysRolePrivilege。
由于Java中的基本类型会有默认值,例如当某个类中声明了private int age;类似的字段。创建这个类时,age会有默认值0。当使用age属性时,它总会有值。因此在某些情况下,便无法实现使age为null。并且在动态SQL的部分,如果使用age!=null进行判断,结果总会为true,因而会导致很多隐藏的问题。
所以,在实体类中不要使用基本类型(byte、int、short、long、float、double、char、boolean),正确的做法是应该使用它们的包装类。示例:
public class SysUserRole {
private Long userId;
private Long roleId;
//getter和setter
}
2.3.2 XML方式
MyBatis使用Java的动态代理可以直接通过接口来调用相应的方法,不需要提供接口的实现类,更不需要在实现类中使用SqlSession以通过命名空间间接调用。另外,当有多个参数的时候,通过参数注解@Param设置参数的名字省去了手动构造Map参数的过程。
接下来看一看如何使用MyBatis的XML方式。
在src/main/resources的tk.mybatis.simple.mapper目录下创建5个表各自对应的XML文件,分别为UserMapper.xml、RoleMapper.xml、PrivilegeMapper.xml、UserRoleMapper.xml和RolePrivilegeMapper.xml。然后,在src/main/java下面创建包tk.mybatis.simple.mapper。接着,在该包下创建XML文件对应的接口类,分别为UserMapper.java、RoleMapper.java、PrivilegeMapper.java、UserRoleMapper.java、RolePrivilegeMapper.java。
接口和xml文件的所在位置如图: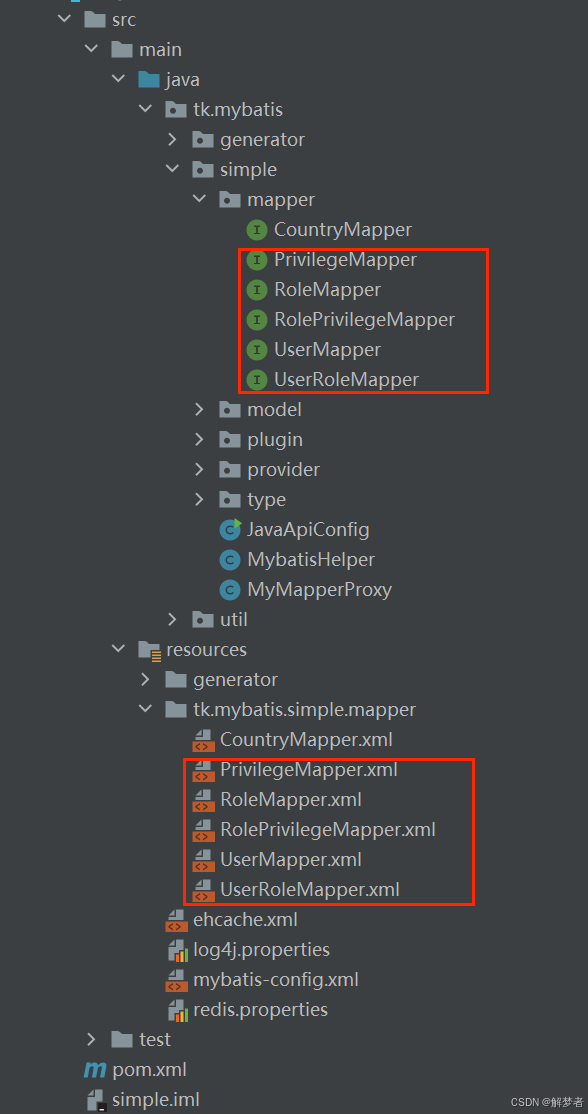
用户表对应的Mapper接口UserMapper.java示例(目前是空内容,后续添加):
public interface UserMapper {
}
UserMapper.xml示例(目前是空内容,后续添加):
<mapper namespace="tk.mybatis.simple.mapper.UserMapper">
</mapper>
当Mapper接口和XML文件关联的时候,命名空间namespace的值就需要配置成接口的全限定名称,例如UserMapper接口对应的tk,mybatis.simple,mapper.UserMapper,MyBatis内部就是通过这个值将接口和XML关联起来的。
准备好这几个XML映射文件后,还需要在mybatis-config…xml配置文件中的mappers元素中配置所有的mapper。示例:
<mappers>
<mapper resource="tk/mybatis/simple/mapper/CountryMapper.xml"/>
<mapper resource="tk/mybatis/simple/mapper/UserMapper.xml"/>
</mappers>
这种配置Mapper文件的方式不灵活,有种更简单的方式:
<mappers>
<package name="tk.mybatis.simple.mapper"/>
</mappers>
这种配置方式会先查找tk.mybatis.simple.mapper包下所有的接口,循环对接口进行如下操作:
1、判断接口对应的命名空间是否已经存在。如果存在就抛出异常,不存在就继续进行接下来的操作。
2、加载接口对应的ML映射文件,将接口全限定名转换为路径。例如,将接口tk.mybatis.simple.mapper.UserMapper转换为tk/mybatis/simple/mapper/UserMapper.xml,以xml为后缀搜索XML资源,如果找到就解析XML。
3、处理接口中的注解方法。
2.3.3 SELECT(resultType/resultMap/驼峰命名)
比如要根据id查询User。UserMapper.java中要添加一个查询方法的声明:
SysUser selectById(Long id);
UserMapper.xml中就要添加该方法的实现SQL,示例:
<resultMap id="userMap" type="tk.mybatis.simple.model.SysUser">
<id property="id" column="id"/>
<result property="userName" column="user_name"/>
<result property="userPassword" column="user_password"/>
<result property="userEmail" column="user_email"/>
<result property="userInfo" column="user_info"/>
<result property="headImg" column="head_img" jdbcType="BLOB"/>
<result property="createTime" column="create_time" jdbcType="TIMESTAMP"/>
</resultMap>
<select id="selectById" resultMap="userMap">
select * from sys_user where id = #{id}
</select>
XML中的select标签的id属性值和定义的接口方法名是一样的。MyBatis就是通过这种方式将接口方法和XML中定义的SQL语句关联到一起的,如果接口方法没有和XML中的d属性值相对应,启动程序便会报错。
- resultMap
resultMap标签用于配置Java对象的属性和查询结果列的对应关系,通过resultMap中配置的column和property可以将查询列的值映射到type对象的属性上,因此当我们使用select*查询所有列的时候,MyBatis也可以将结果正确地映射到SysUser对象上。
id和result标签包含的属性:
column:从数据库中得到的列名,或者是列的别名。
property:映射到列结果的属性。可以映射简单的如“username”这样的属性,也可以映射一些复杂对象中的属性,例如“address.street.number”,这会通过“.”方式的属性嵌套赋值。
javaType:一个Java类的完全限定名,或一个类型别名(通过typeAlias配置或者默认的类型)。如果映射到一个JavaBean,MyBatis通常可以自动判断属性的类型。如果映射到HashMap,则需要明确地指定javaType属性。
jdbcType:列对应的数据库类型。JDBC类型仅仅需要对插入、更新、删除操作可能为空的列进行处理。这是JDBC jdbcType的需要,而不是MyBatis的需要。
typeHandler:使用这个属性可以覆盖默认的类型处理器。这个属性值是类的完全限定名或类型别名。
接口中定义的返回值类型必须和XM中配置的resultType类型一致,否则就会因为类型不一致而抛出异常。
- resultType(起别名)
如要获取所有User,先在UserMapper.java接口中定义一个方法:
List<SysUser> selectAll();
UserMapper.xml中就可以使用resultType来写SQL,示例:
<select id="selectAll" resultType="tk.mybatis.simple.model.SysUser">
select id,
user_name userName,
user_password userPassword,
user_email userEmail,
user_info userInfo,
head_img headImg,
create_time createTime
from sys_user
</select>
如果使用resultType来设置返回结果的类型,需要在SQL中为所有列名和属性名不一致的列设置别名,通过设置别名使最终的查询结果列和resultType指定对象的属性名保持一致,进而实现自动映射。
- resultType和resultMap的选择
MyBatis中在查询进行select映射的时候,返回类型可以用resultType,也可以用resultMap。resultType是直接表示返回类型的,而resultMap则是对外部ResultMap的引用,resultType跟resultMap不能同时存在。
resultType的适用场景
表示返回的结果的类型,此类型只能返回单一的对象(比如Integer、String等)。
当返回的结果是一个集合的时候,只需要使用resultType指定集合中的元素类型即可。示例:
List<Student> students selectById();
<mapper namespace="com.domain.Student">
<select id="selectById" resultType="student">
select * from student
</select>
</mapper>
resultMap的适用场景
当进行关联查询的时候,在返回结果的对象中还包含另一个对象的引用时,此时需要返回自定义结果集合,则需要使用resultMap,示例:
public class User{
private Long id;
private String username;
private String email;
private List<Address> address;
}
<resultMap id="userResultMap" type="com.example.model.User">
<id column="id" property="id" />
<result column="user_name" property="username" />
<result column="email" property="email" />
<association property="address" javaType="com.example.model.Address">
<result column="street" property="street" />
<result column="city" property="city" />
</association>
</resultMap>
- 驼峰命名映射
在数据库中,由于大多数数据库设置不区分大小写,因此下画线方式的命名很常见,如user_name、user_email。在Java中,一般都使用驼峰式命名,如userName、userEmail。因为数据库和Java中的这两种命名方式很常见,因此MyBatis还提供了一个全局属性mapUnderscoreToCamelCase,通过配置这个属性为true可以自动将以下画线方式命名的数据库列映射到Java对象的驼峰式命名属性中。这个属性默认为false,如果想要使用该功能,需要在mybatis-config.xml中增加如下配置:
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
驼峰命名规则也可以使用属性map-underscore-to-camel-case来控制将该属性设置为true即使用驼峰命名规则:
mybatis.configuration.map-underscore-to-camel-case=true
此时就可以将selectAll方法对应的SQL修改为:
<select id="selectAll" resultType="tk.mybatis.simple.model.SysUser">
select id,
user_name,
user_password,
user_email,
user_info,
head_img,
create_time
from sys_user
</select>
在实际开发中还是建议加上和实体类属性一致的别名,为了提高代码可读性。
- 查询的数据在多个表中存在时,怎么定义查询数据的实体类?
比如查询的结果不仅要包含sys_role中的信息,还要包含当前用户的部分信息(不考虑嵌套的情况),例如增加查询列u.user_name as userName。这时resultType该如何设置呢?
第一种方法就是在SysRole对象中直接添加userName属性,这样仍然使用SysRole作为返回值,或者也可以创建一个如下所示的对象:
public class SysRoleExtend extends SysRole {
private String userName;
//getter和setter
}
将resultType设置为扩展属性后的SysRoleExtend对象,通过这种方式来接收多余的值。这种方式比较适合在需要少量额外字段时使用,但是如果需要其他表中大量列的值时,这种方式就不适用了,因为我们不能将一个类的属性照搬到另一个类中。
这种情况,可以直接在SysRole中增加SysUser对象,字段名为user,增加这个字段后,示例:
public class SysRole
//其他原有字段...
private SysUser user;
}
然后修改XML中的selectRolesByUserId方法:
<select id="selectRolesByUserId" resultType="tk.mybatis.simple.model.SysRole">
select
r.id,
r.role_name roleName,
r.enabled,
r.create_by createBy,
r.create_time createTime,
u.user_name as "user.userName",
u.user_email as "user.userEmail"
from sys_user u
inner join sys_user_role ur on u.id = ur.user_id
inner join sys_role r on ur.role_id = r.id
where u.id = #{userId}
</select>
以下2行比较特殊:
u.user_name as "user.userName",
u.user_email as "user.userEmail"
这里在设置别名的时候,使用的是“user.属性名”,user是SysRole中刚刚增加的属性,userName和userEmail是SysUser对象中的属性,通过这种方式可以直接将值赋给user字段中的属性。
2.3.4 INSERT(获取主键)
- 简单使用
比如在UserMapper.java中增加一个新增用户的方法:
int insert(SysUser sysUser);
UserMapper.xml中新增对应的SQL:
<insert id="insert">
insert into sys_user(
user_name, user_password, user_email,
user_info, head_img, create_time)
values(
#{userName}, #{userPassword}, #{userEmail},
#{userInfo}, #{headImg, jdbcType=BLOB}, #{createTime, jdbcType=TIMESTAMP})
</insert>
为了保证数据类型的正确,需要手动指定日期类型,date、time、datetime对应的JDBC类型分别为DATE、TIME、TIMESTAMP。
- 使用JDBC的方式返回主键
此时的SQL为:
<insert id="insert2"useGeneratedKeys="true"keyProperty="id">
insert into sys user(
user_name,user password,user email,
user info,head img,create time)
values(
#{userName},#{userPassword},#(userEmail},
#{userInfo},#(headImg,jdbcType=BLOB},
#{createTime,jdbcType=TIMESTAMP})
</insert>
相比上一个SQL,多了2个属性:useGeneratedKeys="true"keyProperty=“id”。useGeneratedKeys设置为true后,MyBatis会使用JDBC的getGeneratedKeys方法来取出由数据库内部生成的主键。获得主键值后将其赋值给keyProperty配置的id属性。
- 使用selectKey的方式返回主键
上面这种回写主键的方法只适用于支持主键自增的数据库(比如MySQL、Sql Server)。有些数据库(如Oracle)不提供主键自增的功能,而是使用序列得到一个值,然后将这个值赋给id,再将数据插入数据库。对于这种情况,可以采用另外一种方式:使用<selectKey>标签来获取主键的值,这种方式不仅适用于不提供主键自增功能的数据库,也适用于提供主键自增功能的数据库。
SQL示例:
<insert id="insert3">
insert into sys_user(
user_name, user_password, user_email,
user_info, head_img, create_time)
values(
#{userName}, #{userPassword}, #{userEmail},
#{userInfo}, #{headImg, jdbcType=BLOB}, #{createTime, jdbcType=TIMESTAMP})
<selectKey keyColumn="id" resultType="long" keyProperty="id" order="AFTER">
SELECT LAST_INSERT_ID()
</selectKey>
</insert>
selectKey标签的keyColumn、keyProperty和上面useGeneratedKeys的用法含义相同,这里的resultType用于设置返回值类型。order属性的设置和使用的数据库有关。在MySQL数据库中,order属性设置的值是AFTER,因为当前记录的主键值在insert语句执行成功后才能获取到。而在Oracle数据库中,order的值要设置为BEFORE,这是因为Oracle中需要先从序列获取值,然后将值作为主键插入到数据库中。
2.3.5 UPDATE
比如要根据主键更新用户信息:
int updateById(SysUser sysUser);
对应的SQL为:
<update id="updateById">
update sys_user
set user_name = #{userName},
user_password = #{userPassword},
user_email = #{userEmail},
user_info = #{userInfo},
head_img = #{headImg, jdbcType=BLOB},
create_time = #{createTime, jdbcType=TIMESTAMP}
where id = #{id}
</update>
2.3.6 DELETE
比如根据主键删除用户信息:
int deleteById(Long id);
对应的SQL为:
<delete id="deleteById">
delete from sys_user where id = #{id}
</delete>
2.3.7 多个接口参数的用法(JavaBean/Map/@Param)
在实际应用中经常会遇到使用多个参数的情况。可以将多个参数合并到一个JavaBean中,并使用这个JavaBean作为接口方法的参数。这种方法用起来很方便。
- JavaBean传参
#{}里面的名称对应的是User类里面的成员属性。这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。示例:
//User类中有userName和deptId2个属性
public User selectUser(User user);
<select id="selectUser" parameterType="com.test.pojo.User" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
对于参数比较少的情况,还有两种方式可以采用:使用Map类型作为参数或使用@Param注解。
- Map的方式
使用Map类型作为参数的方法,就是在Map中通过key来映射XML中SQL使用的参数值名字,value用来存放参数值,需要多个参数时,通过Map的key-value方式传递参数值。
#{}里面的名称对应的是Map里面的key名称。这种方法适合传递多个参数,且参数易变能灵活传递的情况。示例:
public User selectUser(Map<String, Object> params);
<select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
- @Param注解的方式
比如根据用户 id 和 角色的 enabled 状态获取用户的角色:
List<SysRole> selectRolesByUserIdAndRoleEnabled(@Param("userId")Long userId, @Param("enabled")Integer enabled);
对应的SQL:
<select id="selectRolesByUserIdAndRoleEnabled" resultType="tk.mybatis.simple.model.SysRole">
select
r.id,
r.role_name roleName,
r.enabled,
r.create_by createBy,
r.create_time createTime
from sys_user u
inner join sys_user_role ur on u.id = ur.user_id
inner join sys_role r on ur.role_id = r.id
where u.id = #{userId} and r.enabled = #{enabled}
</select>
给参数配置@Param注解后,MyBatis就会自动将参数封装成Map类型,@Param注解值会作为Map中的key,因此在SQL部分就可以通过配置的注解值来使用参数。
2.3.8 Mapper接口动态代理
为什么Mapper接口没有实现类却能被正常调用呢?这是因为MyBaits在Mapper接口上使用了动态代理的一种非常规的用法。
比如有个Mapper接口:
public interface UserMapper {
List<SysUser>selectAll();
}
然后使用Java动态代理方式创建一个代理类:
public class MyMapperProxy<T>implements InvocationHandler
private class<T>mapperInterface;
private SqlSession sqlSession;
public MyMapperProxy(Class<T>mapperInterface,SqlSession sqlSession){
this.mapperInterface = mapperInterface;
this.sqlSession = sqlSession;
}
@Override
public object invoke(object proxy,Methodmethod,Object[]args) throws Throwable {
//针对不同的sql类型,需要调用sqlSession不同的方法
//接口方法中的参数也有很多情况,这里只考虑没有有参数的情况
List<T>list sqlSession.selectList(
mapperInterface.getCanonicalName()+"."method.getName());
//返回值也有很多情况,这里不做处理直接返回
return list;
}
}
测试代码:
//获取sqlSession
SqlSession sqlSession getsqlSession();
//获取,UserMapper接口
MyMapperProxy userMapperProxy new MyMapperProxy(UserMapper.class,sqlSession);
UserMapper userMapper = (UserMapper)Proxy.newProxyInstance(
Thread.currentThread().getContextclassLoader (),
new class [(UserMapper.class},
userMapperproxy);
//调用se1ectA11方法
List<SysUser>user userMapper.selectAll();
从代理类中可以看到,当调用一个接口的方法时,会先通过接口的全限定名称和当前调用的方法名的组合得到一个方法id,这个id的值就是映射XML中namespace和具体方法id的组合。所以可以在代理方法中使用sqlSession以命名空间的方式调用方法。通过这种方式可以将接口和XML文件中的方法关联起来。这种代理方式和常规代理的不同之处在于,这里没有对某个具体类进行代理,而是通过代理转化成了对其他代码的调用。
2.4 【动态SQL】
MyBatis的强大特性之一便是它的动态SQL。MyBatis的动态SQL在XML中支持的几种标签:if、choose (when,oterwise)、trim(where、set)、foreach、bind。
2.4.1 if用法(单条件判断)
if标签通常用于WHERE语句中,通过判断参数值来决定是否使用某个查询条件,它也经常用于UPDATE语句中判断是否更新某一个字段,还可以在NSERT语句中用来判断是否插入某个字段的值。
- 1、在where中使用
示例:
where 1 = 1
<if test="userName != null and userName != '' ">
and user name like concat('%',#{userName},'%')
</if>
<if test="userEmail != null and userEmail != ''">
and user email =#(userEmail}
</if>
if标签有一个必填的属性test,test的属性值是一个符合OGNL要求的判断表达式,表达式的结果可以是true或false,除此之外所有的非0值都为true,只有0为false。为了方便理解,在表达式中,建议只用true或false作为结果。
判断条件property !=null 或 property == null:适用于任何类型的字段,用于判断属性值是否为空。
判断条件property != ''或property == ‘’:仅适用于String类型的字段,用于判断是否为空字符串。
and和or:当有多个判断条件时,使用and或or进行连接,嵌套的判断可以使用小括号分组,and相当于Java中的与(&&),or相当于Java中的或(||)。
SQL中有个特殊内容:where 1 = 1。由于两个条件都是动态的,所以如果没有1=1这个默认条件,当两个1£判断都不满足时,最后生成的SQL就会以where结束,这样不符合SQL规范,因此会报错。加上1=1这个条件就可以避免SQL语法错误导致的异常。
- 2、在update中使用
示例:
<update id="updateByIdSelective">
update sys_user
set
<if test="userName != null and userName != ''">
user_name = #{userName},
</if>
<if test="userPassword != null and userPassword !=''">
user_password = #{userPassword},
</if>
id = #{id}
where id = #{id}
</update>
id = #{id}是为了处理当所有参数值都为空的情况,此时sql会变成:
update sys_user set id = #(id} where id = #(id}
- 2、在insert中使用
示例:
<insert id="insert2"useGeneratedKeys="true"keyProperty="id">
insert into sys user(
user_name,user_password,
<if test="userEmail != null and userEmail != ''">
user email,
</if>
user_info,head_img,create_time)
values(
#{userName},#{userPassword},
<if test="userEmail != null and userEmail !=''">
#(userEmail},
</if>
#(userInfo},#(headImg,jdbcType=BLOB),
#(createTime,jdbcType=TIMESTAMP})
</insert>
在INSERT中使用时要注意,若在列的部分增加if条件,则values的部分也要增加相同的if条件,必须保证上下可以互相对应,完全匹配。
2.4.2 choose用法(多条件判断)
要实现if…else if…else…的逻辑,要想实现这样的逻辑,就需要用到choose when otherwise标签。choose元素中包含when和otherwise两个标签,一个choose中至少有一个when,有0个或者1个otherwise。
示例:
// 根据用户 id 或用户名查询
SysUser selectByIdOrUserName(SysUser sysUser);
<select id="selectByIdOrUserName" resultType="tk.mybatis.simple.model.SysUser">
select id,
user_name userName,
user_password userPassword,
user_email userEmail,
user_info userInfo,
head_img headImg,
create_time createTime
from sys_user
where 1 = 1
<choose>
<when test="id != null">
and id = #{id}
</when>
<when test="userName != null and userName != ''">
and user_name = #{userName}
</when>
<otherwise>
and 1 = 2
</otherwise>
</choose>
</select>
and 1=2是为了避免id和userName都为空时,把所有用户都查出来的情况。
2.4.3 where(动态处理where语句中的and/or)、set(动态处理set语句中的,)、trim用法
这3个标签解决了类似的问题,并且where和set都属于trim的一种具体用法。
- where
where标签的作用:如果该标签包含的元素中有返回值,就插入一个where;如果where后面的字符串是以AND和OR开头的,就将它们剔除。
示例:
<where>
<if test="userName != '' and userName != null">
and user_name like concat('%', #{userName}, '%')
</if>
<if test="userEmail != '' and userEmail != null">
and user_email = #{userEmail}
</if>
</where>
当if条件都不满足的时候,where元素中没有内容,所以在SQL中不会出现where。如果if条件满足,where元素的内容就是以and开头的条件,where会自动去掉开头的and,这也能保证where条件正确。这种写法,比之前的出现在where条件中的1=1要优雅一些。
- set
set标签的作用:如果该标签包含的元素中有返回值,就插入一个set;如果set后面的字符串是以逗号结尾的,就将这个逗号剔除。
示例:
<update id="updateByIdSelective">
update sys_user
<set>
<if test="userName != null and userName != ''">
user_name =#{userName},
</if>
<if test="userPassword != null and userPassword != ''">
user password =#(userPassword},
</if>
id = #(id)
</set>
where id =#(id}
</update>
在set标签的用法中,SQL后面的逗号没有问题了,但是如果set元素中没有内容,照样会出现SQL错误,所以为了避免错误产生,类似id=#{id}这样必然存在的赋值仍然有保留的必要。因此,set标签的使用不是必须的,大多数时候直接用set而非<set>标签即可。
- trim
where和set标签的功能都可以用trim标签来实现。
where标签对应trim的实现:
<trim prefix="WHERE"prefixOverrides="AND |OR ">
</trim>
set标签对应的trim实现:
<trim prefix="SET"suffixOverrides=",">
</trim>
trim标签有如下属性:
prefix:当trim元素内包含内容时,会给内容增加prefix指定的前缀。
prefixOverrides:当trim元素内包含内容时,会把内容中匹配的前缀字符串去掉。
suffix:当trim元素内包含内容时,会给内容增加suffix指定的后缀。
suffixOverrides:当trim元素内包含内容时,会把内容中匹配的后缀字符串去掉。
比如用<where>标签实现的一个查询:
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
用<trim>标签也能实现:
<trim prefix="WHERE" prefixOverrides="AND">
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</trim>
2.4.4 sql(sql片段)、include用法(sql复用)
<sql>可将重复的SQL片段提取出来,然后在需要的地方,使用<include>标签进行引用。示例:
<select id="findUser" parameterType="user" resultType="user">
SELECT * FROM user
<include refid="whereClause"/>
</select>
<sql id="whereClause">
<where>
<if test user != null>
AND username like '%${user.name}%'
</if>
</where>
</sql>
2.4.5 foreach用法(批量操作)
foreach可以对数组、Map或实现了Iterable接口(如List、Set)的对象进行遍历。
- 用在where子句中(批量判断)
示例:
//根据用户 id 集合查询
List<SysUser> selectByIdList(List<Long> idList);
<select id="selectByIdList"resultType="tk.mybatis.simple.model.SysUser">
select id,
user_name userName,
user_password userpassword,
user_email userEmail,
user_info userInfo
from sys_user
where id in
<foreach collection="list"open="("close=")"separator=","
item="id"index="i">
#{id}
</foreach>
</select>
foreach包含以下属性:
collection:必填,值为要迭代循环的属性名(当集合为List时,该属性值为list;当集合为数组时,该属性值为array)。
item:变量名,值为从迭代对象中取出的每一个值。
index:索引的属性名,在集合数组情况下值为当前索引值,当迭代循环的对象是Map类型时,这个值为Map的key(键值)。
open:整个循环内容开头的字符串。
close:整个循环内容结尾的字符串。
separator:每次循环的分隔符。
- 用在insert子句中(批量插入)
示例:
//批量插入用户信息
int insertList(List<SysUser> userList);
<insert id="insertList">
insert into sys user(
user_name,user_password,user_email,user_info)
values
<foreach collection="list"item="user"separator=",">
#{user.userName},#user.userPassword),#(user.userEmail},#{user.userInfo})
</foreach>
</insert>
通过item指定了循环变量名后,在引用值的时候使用的是“属性.属性”的方式,如user.userName。
- 用在update子句中(批量更新)
这一节主要介绍当参数类型是Map时,foreach如何实现动态UPDATE。当参数是Map类型的时候,foreach标签的index属性值对应的不是索引值,而是Map中的key,利用这个key可以实现动态UPDATE。
示例:
int updateByMap (Map<String,Object> map);
<update id="updateByMap">
update sys_user
set
<foreach collection="_parameter"item="val"index="key"separator=",">
${key} = #{va1}
</foreach>
where id = #(id}
</update>
MyBatis在内部的上下文中使用了默认值_parameter作为该参数的key,所以在XML中也使用了_parameter。
2.4.6 多数据库支持(配置多种数据库链接)
MyBatis可以根据不同的数据库厂商执行不同的语句,这种多厂商的支持是基于映射语句中的databaseId属性的。MyBatis会加载不带databaseId属性和带有匹配当前数据库databaseId属性的所有语句。如果同时找到带有databaseId和不带databaseId的相同语句,则后者会被舍弃。为支持多厂商特性,只要像下面这样在mybatis-config.xml文件中加入databaseIdProvider配置即可。
<databaseIdprovider type="DB VENDOR">
<property name="SQL Server"value="sqlserver"/>
<property name="DB2"value="db2"/>
<property name="Oracle"value="oracle"/>
<property name="MySQL"value="mysql"/>
<property name="PostgreSQL"value="postgresql"/>
<property name="Derby"value="derby"/>
<property name="HSQL"value="hsqldb"/>
<property name="H2"value="h2"/>
</databaseIdProvider>
数据库产品名一般由所选择的当前数据库的JDBC驱动所决定。
除了增加上面的配置外,映射文件也是要变化的,关键在于以下几个映射文件的标签中含有的databaseId属性:select、insert、delete、update、selectKey、sql。
- 示例1
<select id="selectByUser"databaseId="mysql"
resultType="tk.mybatis.simple.model.SysUser">
select * from sys_userand where user_name like concat ('#userName),'$')
</select>
<select id="selectByUser"databaseId="oracle"
resultType="tk.mybatis.simple.model.SysUser">
select * from sys_userand where user_name like'%'||#{userName}||'%'
</select>
当基于不同数据库运行时,yBatis会根据配置找到合适的SQL去执行。
- 示例2
数据库的更换可能只会引起某个SQL语句的部分不同,所以也没有必要使用上面的写法,而可以使用if标签配合默认的上下文中的databaseId参数这种写法去实现。这样可以避免大量重复的SQL出现。
<select id="selectByUser"resultType="tk.mybatis.simple.model.SysUser">
select id,
user_name userName,
user_password userPassword,
user_email userEmail,
user_info userInfo
from sys_user
<where>
<if test="userName != null and userName != ''">
<if test="databaseId =='mysql'">
and user_name like concat('%',#{userName},'%')
</if>
<if test="databaseId ='oracle'">
and user_name like'%'|| #{userName}||'%'
</if>
</if>
<if test="userEmail != '' and userEmail != null">
and user_email = #(userEmail}
</if>
</where>
</select>
2.5 相关问题
2.5.1 使用MyBatis的mapper接口调用时的4个要求(id相同/参数类型相同/返回值类型相同/namesace与Mapper文件类路径相同)
1、Mapper接口方法名和mapper.xml中定义的每个sql的id相同。
2、Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同。
3、Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同。
4、Mapper.xml文件中的namespace即是mapper接口的类路径。
2.5.2 Mybatis中不同的xml映射文件,id是否可以重复(namespace不同就可以)
不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复。namespace不是必须的,只是最佳实践而已。在实际开发中一般都使用namespace。
原因:namespace+id是作为Map<String, MappedStatement>的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
xml文件中,namespace和id的示例:
<mapper namespace="com.test.dao.EmpDao">
<delete id="delete">
delete from emp where empno = #{empno}
</delete>
</mapper>
2.5.3 Mybatis映射文件中,如果A标签通过include引用了B标签的内容,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面(不必)
虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。
原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
2.5.4 模糊查询like语句该怎么写
'%${question}%' :可能引起SQL注入,不推荐。
CONCAT('%',#{question},'%'): 使用CONCAT()函数,推荐。
2.5.5 #{}和${}(前者是占位符,后者是直接替换)
- 两者的区别
1、#{}是占位符,预编译处理;${}是拼接符,字符串替换,没有预编译处理。
2、#{}方式能够很大程度防止sql注入,原因在于预编译机制;Mybatis在处理${}时,就是把${}替换成变量的值。因此${}方式可能会产生Sql注入问题。
3、一般能用#{}的就别用${}。 - 两者的使用场景
1、${}方式用于传入数据库对象。
当需要传入动态的表名、列名的时候就需要使用${}。因为使用#{}拼接表名的话,会有多余的字符串。示例:
select * from #{param}
//传入值为user时,就会拼接处下面的sql
select * from 'user'
2、${}方式用于排序字段。
按某个字段排序,升降序也需要使用${}来指定。示例:
//接口
List<Userinfo> sortAll(@Param("sort") String userinfo);
//测试
@Test
void sortAll() {
String sort = "desc";
List<Userinfo> userinfos = userMapper.sortAll(sort);
System.out.println(userinfos);
}
如果使用#{},如:
<select id="sortAll" resultType="com.example.demo.entity.Userinfo">
select * from userinfo order by id #{sort}
</select>
那么拼接出来的sql是 select * from userinfo order by id 'desc';,显然有问题,所以要用${}。
3、用于模糊查询
因为有注入风险,所以一般不会使用${},而是用concat函数代替。
普通的入参(如String类型参数)不能用${}。因为${}不会做类型解析,存在SQL注入的风险。示例:
SELECT * FROM user WHERE name = '${name}' AND password = '${password}'
假如password属性为'OR '1' = '1,最终的SQL会变成:
SELECT * FROM user WHERE name = 'test' AND password = ''OR '1' = '1'
因为OR '1' = '1'恒成立,这个where条件就不起作用了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)