统计学习(二):线性回归
本文主要介绍了简单线性回归、多元线性回归的系数估计、模型选择以及对其的一些拓展等内容
文章目录
线性回归
概念
线性回归(linear regression) 是一种简单的指导学习方法,它假设 Y Y Y 和 X 1 , X 2 , ⋯ , X p X_1,X_2,\cdots,X_p X1,X2,⋯,Xp 的关系是线性的。
真正的回归函数永远都不是线性的。
虽然线性回归看起来过于简单,但它在概念上和实际上都非常有用。
简单线性回归
Y = β 0 + β 1 X + ε Y=\beta_0+\beta_1X+\varepsilon Y=β0+β1X+ε其中 β 0 , β 1 \beta_0,\beta_1 β0,β1 是两个未知的量,被称为模型的系数(coefficients)或参数(parameters),分别代表截距(intercept)和斜率(slope)。 ε \varepsilon ε 为误差项。
从训练数据中估计出模型的系数,我们可以得到
y ^ = β ^ 0 + β ^ 1 x \hat{y}=\hat{\beta}_0+\hat{\beta}_1x y^=β^0+β^1x其中 y ^ \hat{y} y^ 表示在 X = x X=x X=x 的基础上对 Y Y Y 的预测。
估计系数(最小二乘)
令 y ^ i = β ^ 0 + β ^ 1 x i \hat{y}_i=\hat{\beta}_0+\hat{\beta}_1x_i y^i=β^0+β^1xi 为根据 X X X 的第i个值预测的 Y Y Y, e i = y i − y ^ i e_i=y_i-\hat{y}_i ei=yi−y^i 表示第i个残差(residual)。
我们定义残差平方和(residual sum of squares ,RSS):
R S S = e 1 2 + e 2 2 + ⋯ + e n 2 R S S = ( y 1 − β ^ 0 − β ^ 1 x 1 ) 2 + ( y 2 − β ^ 0 − β ^ 1 x 2 ) 2 + ⋯ + ( y n − β ^ 0 − β ^ 1 x n ) 2 RSS=e_1^2+e_2^2+\cdots+e_n^2\\RSS=(y_1-\hat{\beta}_0-\hat{\beta}_1x_1)^2+(y_2-\hat{\beta}_0-\hat{\beta}_1x_2)^2+\cdots+(y_n-\hat{\beta}_0-\hat{\beta}_1x_n)^2 RSS=e12+e22+⋯+en2RSS=(y1−β^0−β^1x1)2+(y2−β^0−β^1x2)2+⋯+(yn−β^0−β^1xn)2
最小二乘法选择 β 0 , β 1 \beta_0,\beta_1 β0,β1 来使RSS最小。可以计算出使RSS最小的参数估计值为:
β ^ 1 = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 n ( x i − x ˉ ) 2 β ^ 0 = y ˉ − β ^ 1 x ˉ 其 中 , y ˉ = 1 n ∑ i = 1 n y i , x ˉ = 1 n ∑ i = 1 n x i , 为 样 本 均 值 。 \hat{\beta}_1=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^n(x_i-\bar{x})^2}\\\hat{\beta}_0=\bar{y}-\hat{\beta}_1\bar{x}\\其中,\bar{y}=\frac{1}{n}\sum_{i=1}^ny_i,\bar{x}=\frac{1}{n}\sum_{i=1}^nx_i,为样本均值。 β^1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)β^0=yˉ−β^1xˉ其中,yˉ=n1i=1∑nyi,xˉ=n1i=1∑nxi,为样本均值。
评估系数估计值的准确性
估计值的标准误差(standard error) 反映了它在重复采样下的变化。
S E ( β ^ 1 ) = σ 2 ∑ i = 1 n ( x i − x ^ ) 2 , S E ( β ^ 0 ) = σ 2 [ 1 n + x ^ 2 ∑ i = 1 n ( x i − x ^ ) 2 ] 其 中 , σ 2 = V a r ( ε ) SE(\hat{\beta}_1)=\frac{\sigma^2}{\sum_{i=1}^n(x_i-\hat{x})^2}\ \ ,\ \ SE(\hat{\beta}_0)=\sigma^2[\frac{1}{n}+\frac{\hat{x}^2}{\sum_{i=1}^n(x_i-\hat{x})^2}]\\其中,\sigma^2=Var(\varepsilon) SE(β^1)=∑i=1n(xi−x^)2σ2 , SE(β^0)=σ2[n1+∑i=1n(xi−x^)2x^2]其中,σ2=Var(ε)
一般情况下, σ 2 \sigma^2 σ2 是未知的,但可以从数据中估计出来,对 σ 2 \sigma^2 σ2 的估计被称为残差标准误(residual standard error),由下式定义。
R S E 2 = R S S / ( n − 2 ) RSE^2=RSS/(n-2) RSE2=RSS/(n−2)标准误差可用于计算置信区间(confidence intervals)。95%的置信区间被定义为一个一个取值范围:该范围有95%的概率会包含未知参数的真实值。对于线性回归模型, β 1 \beta_1 β1 的95%置信区间为:
β ^ 1 ± 2 ∗ S E ( β ^ 1 ) \hat{\beta}_1\pm 2*SE(\hat{\beta}_1) β^1±2∗SE(β^1)也就是,下述区间
[ β ^ 1 − 2 ∗ S E ( β ^ 1 ) , β ^ 1 + 2 ∗ S E ( β ^ 1 ) ] [\hat{\beta}_1-2*SE(\hat{\beta}_1),\hat{\beta}_1+2*SE(\hat{\beta}_1)] [β^1−2∗SE(β^1),β^1+2∗SE(β^1)]有大约95%的可能会包含 β 1 \beta_1 β1 的真实值。
标准误差也可用来对系数进行假设检验(Hypothesis testing)。最常用的假设检验包括对零假设(null hypothesis)和备择假设(alternative hypothesis) 进行检验。
零假设: H 0 H_0 H0:X和Y之间没有关系
备择假设: H 1 H_1 H1:X和Y之间有一定的关系
数学上就相当于检验
H 0 : β 1 = 0 H a : β 1 ≠ 0 H_0:\beta_1=0\\H_a:\beta_1\neq0 H0:β1=0Ha:β1=0为了检验零假设,我们计算t统计量
t = β ^ 1 − 0 S E ( β ^ 1 ) t=\frac{\hat{\beta}_1-0}{SE(\hat{\beta}_1)} t=SE(β^1)β^1−0上式服从自由度为n-2的t分布。
假设 β 1 = 0 \beta_1=0 β1=0,计算任意观测值大于等于 ∣ t ∣ |t| ∣t∣ 的概率十分简单,称这个概率为p值(p-value)。如果看到一个很小的p值,就能拒绝原假设,推断出预测变量和响应变量间存在关联。
评价模型的准确性
判断线性回归的拟合质量通常使用两个相关的量:**残差标准误(residual standard error,RSE)**和 R 2 R^2 R2 统计量。
我们计算残差标准误:
R S E = 1 n − 2 R S S = 1 n − 2 ∑ i = 1 n ( y i − y i ^ ) 2 其 中 , R S S = ∑ i = 1 n ( y i − y i ^ ) 2 RSE=\sqrt{\frac{1}{n-2}RSS}=\sqrt{\frac{1}{n-2}\sum_{i=1}^n(y_i-\hat{y_i})^2}\\其中,RSS=\sum_{i=1}^n(y_i-\hat{y_i})^2 RSE=n−21RSS=n−21i=1∑n(yi−yi^)2其中,RSS=i=1∑n(yi−yi^)2
RSE越小,说明模型得到的预测值非常接近真实值,拟合程度较好。
R 2 R^2 R2 统计量:
R 2 = T S S − R S S T S S = 1 − R S S T S S R^2=\frac{TSS-RSS}{TSS}=1-\frac{RSS}{TSS} R2=TSSTSS−RSS=1−TSSRSS
其中, T S S = ∑ i = 1 n ( y i − y ˉ ) 2 TSS=\sum_{i=1}^n(y_i-\bar{y})^2 TSS=∑i=1n(yi−yˉ)2 是总平方和(residual sum of squares)。
相关性 r = C o r ( X , Y ) r=Cor(X,Y) r=Cor(X,Y) :
r = C o r ( X , Y ) = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 n ( x i − x ˉ ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 r=Cor(X,Y)=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum_{i=1}^n(x_i-\bar{x})^2}\sqrt{\sum_{i=1}^n(y_i-\bar{y})^2}} r=Cor(X,Y)=∑i=1n(xi−xˉ)2∑i=1n(yi−yˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
r可以代替 R 2 R^2 R2 评估线性模型的拟合度。在简单线性回归模型中, R 2 = r 2 R^2=r^2 R2=r2。
多元线性回归
Y = β 0 + β 1 X 1 + β 2 X 2 + ⋯ + β p X p + ε Y=\beta_0+\beta_1X_1+\beta_2X_2+\cdots+\beta_pX_p+\varepsilon Y=β0+β1X1+β2X2+⋯+βpXp+ε其中, X j X_j Xj 代表第 j j j 个预测变量, β j \beta_j βj 代表第 j j j 个预测变量和响应变量之间的关联。 β j \beta_j βj 可解释为在所有其他预测变量保持不变(holding all other predictors fifixed) 的情况下, X j X_j Xj 增加一个单位对 Y Y Y 产生的平均(average) 效果。
预测变量之间的相关性会导致以下问题:所有系数的方差往往会增加,有时也会急剧增加;解释会变得危险——当 X j X_j Xj 改变时,其他一切都会改变。
对于观测数据,应避免因果关系(Claims of causality)。
估计回归系数
对于给定的回归系数 β ^ 0 , β ^ 1 , ⋯ , β ^ p \hat{\beta}_0,\hat{\beta}_1,\cdots,\hat{\beta}_p β^0,β^1,⋯,β^p,可以用如下公式进行预测:
y ^ = β ^ 0 + β ^ 1 x 1 + β ^ 2 x 2 + ⋯ + β ^ p x p \hat{y}=\hat{\beta}_0+\hat{\beta}_1x_1+\hat{\beta}_2x_2+\cdots+\hat{\beta}_px_p y^=β^0+β^1x1+β^2x2+⋯+β^pxp多元线性回归中的参数也用最小二乘法估计,使残差平方和RSS最小:
R S S = ∑ i = 1 n ( y i − y ^ i ) 2 = ∑ i = 1 n ( y i − β ^ 0 − β ^ 1 x i 1 − β ^ 2 x i 2 − ⋯ − − β ^ p x i p ) 2 RSS=\sum_{i=1}^n(y_i-\hat{y}_i)^2=\sum_{i=1}^n(y_i-\hat{\beta}_0-\hat{\beta}_1x_{i1}-\hat{\beta}_2x_{i2}-\cdots--\hat{\beta}_px_{ip})^2 RSS=i=1∑n(yi−y^i)2=i=1∑n(yi−β^0−β^1xi1−β^2xi2−⋯−−β^pxip)2
一些重要问题
1、预测变量 X 1 , X 2 , ⋯ , X p X_1,X_2,\cdots,X_p X1,X2,⋯,Xp 中是否至少有一个可以用来预测响应变量?
在有 p p p 个预测变量的多元回归模型中,我们要检验所有的回归系数是否均为零,即 β 1 = β 2 = ⋯ = β p = 0 \beta_1=\beta_2=\cdots=\beta_p=0 β1=β2=⋯=βp=0 是否成立:
H 0 : β 1 = β 2 = ⋯ = β p = 0 H a : 至 少 有 一 个 β j ≠ 0 H_0:\beta_1=\beta_2=\cdots=\beta_p=0\\H_a:至少有一个\beta_j\neq0 H0:β1=β2=⋯=βp=0Ha:至少有一个βj=0可以用F统计量:
F = ( T S S − R S S ) / p R S S / ( n − p − 1 ) , 服 从 F p , n − p − 1 F=\frac{(TSS-RSS)/p}{RSS/(n-p-1)},服从F_{p,n-p-1} F=RSS/(n−p−1)(TSS−RSS)/p,服从Fp,n−p−1F大于临界值时,拒绝原假设。
2、选定重要变量
最直接的方法称为所有子集(all subsets)或最佳子集(best subsets) 回归:我们计算适合所有可能子集的最小二乘值,然后根据一些平衡训练误差和模型大小的标准在它们之间进行选择。然而,我们通常不能检查所有可能的模型。
向前选择(Forward selection)
从零模型(null model)——只含有截距但不含预测变量的模型开始,拟合p个简单线性回归,并在零模型中添加能使RSS最小的变量。然后再加入一个新变量,得到新的双变量模型,加入的变量是使新模型的RSS最小的变量。继续持续此过程,直到满足某些停止规则为止,比如当所有剩余变量的p值都高于某个阈值时。
向后选择(Backward selection)
先从包含所有变量的模型开始,删除p值最大的变量——统计学上最不显著的变量。拟合完包含(p-1)个变量的新模型后,再删除p值最大的变量。此过程持续到满足某种停止规则为止,例如,当所有剩余变量的p值均低于某个阈值时,停止删除变量。
模型选择
Mallow’s统计量 Cp、赤池信息量准则(Akaike information criterion,AIC)、贝叶斯信息准则(Bayesian information criterion,BIC)、调整R方(adjusted R 2 R^2 R2)和交叉检验(Cross-validation,CV)。
3、模型拟合
R 2 、 R S E R^2、RSE R2、RSE
R S E = 1 n − p − 1 R S S RSE=\sqrt{\frac{1}{n-p-1}RSS} RSE=n−p−11RSS
回归模型中的其他注意事项
定性预测变量(Qualitative Predictors)
一些预测变量不是定量的而是定性的。这些也被称为分类预测因子或因子变量。
二值预测变量
调查男女信用卡债务差异,忽略其他变量,创造一个新的变量
x i = { 1 女 性 0 男 性 x_i=\begin{cases}1\ \ \ 女性\\0\ \ \ 男性\end{cases} xi={1 女性0 男性并在回归方程中使用这个变量:
y i = β 0 + β 1 x i + ε i = { β 0 + β 1 + ε i 女 性 β 0 + ε i 男 性 y_i=\beta_0+\beta_1x_i+\varepsilon_i=\begin{cases}\beta_0+\beta_1+\varepsilon_i\ \ \ 女性\\\beta_0+\varepsilon_i\ \ \ 男性\end{cases} yi=β0+β1xi+εi={β0+β1+εi 女性β0+εi 男性 β 1 \beta_1 β1 是男性和女性之间信用卡债务的平均差异。
定性变量有两个以上的水平
可以创造更多的虚拟变量。例如,对种族创建两个变量:
x i 1 = { 1 亚 洲 人 0 非 亚 洲 人 x i 2 = { 1 白 种 人 0 非 白 种 人 x_{i1}=\begin{cases}1\ \ \ 亚洲人\\0\ \ \ 非亚洲人\end{cases}\\x_{i2}=\begin{cases}1\ \ \ 白种人\\0\ \ \ 非白种人\end{cases} xi1={1 亚洲人0 非亚洲人xi2={1 白种人0 非白种人将这两个变量用于回归方程中:
y i = β 0 + β 1 x i 1 + β 2 x i 2 + ε i = { β 0 + β 1 + ε i 亚 洲 人 β 0 + β 2 + ε i 白 种 人 β 0 + ε i 非 裔 美 国 人 y_i=\beta_0+\beta_1x_{i1}+\beta_2x_{i2}+\varepsilon_i=\begin{cases}\beta_0+\beta_1+\varepsilon_i\ \ \ 亚洲人\\\beta_0+\beta_2+\varepsilon_i\ \ \ 白种人\\\beta_0+\varepsilon_i\ \ \ \ \ \ \ \ \ \ \ \ 非裔美国人\end{cases} yi=β0+β1xi1+β2xi2+εi=⎩⎪⎨⎪⎧β0+β1+εi 亚洲人β0+β2+εi 白种人β0+εi 非裔美国人dummy variable的数量总是比水平数少1。没有相对应的dummy variable的水平——上例是非裔美国人——被称为基准水平(baseline)。
线性模型的扩展
交互作用(interactions)
也叫做协同(synergy) 效应。
考虑在模型中加入交互项:
Y = β 0 + β 1 X 1 + β 2 X 2 + β 3 X 1 X 2 + ε Y=\beta_0+\beta_1X_1+\beta_2X_2+\beta_3X_1X_2+\varepsilon Y=β0+β1X1+β2X2+β3X1X2+ε上式可以写成
Y = β 0 + ( β 1 + β 3 X 2 ) X 1 + β 2 X 2 + ε = β 0 + β ~ 1 X 1 + β 2 X 2 + ε Y=\beta_0+(\beta_1+\beta_3X_2)X_1+\beta_2X_2+\varepsilon=\beta_0+\tilde{\beta}_1X_1+\beta_2X_2+\varepsilon Y=β0+(β1+β3X2)X1+β2X2+ε=β0+β~1X1+β2X2+ε其中 β ~ 1 = β 1 + β 2 X 2 \tilde{\beta}_1=\beta_1+\beta_2X_2 β~1=β1+β2X2。调整 X 2 X_2 X2 的值将改变 X 1 X_1 X1 对 Y Y Y 的影响。检验: H 0 : β 3 = 0 , H A : β 3 ≠ 0 H_0:\beta_3=0,H_A:\beta_3\neq0 H0:β3=0,HA:β3=0
少数情况下,交互项的p值很小,但相关的主效应的p值却不然。
实验分层原则(hierarchical principle):如果模型中含有交互项,那么即使主效应的系数的p值不显著,也应包括在模型中。
定性变量和定量变量之间的相互作用
不含交互项的模型:
b a l a n c e i ≈ β 0 + β 1 ∗ i n c o m e i + { β 2 学 生 0 非 学 生 = β 1 ∗ i n c o m e i + { β 0 + β 2 学 生 β 0 非 学 生 balance_i\approx\beta_0+\beta_1*income_i+\begin{cases}\beta_2\ \ \ 学生\\0\ \ \ 非学生\end{cases}=\beta_1*income_i+\begin{cases}\beta_0+\beta_2\ \ \ 学生\\\beta_0\ \ \ \ \ \ \ \ \ \ \ \ 非学生\end{cases} balancei≈β0+β1∗incomei+{β2 学生0 非学生=β1∗incomei+{β0+β2 学生β0 非学生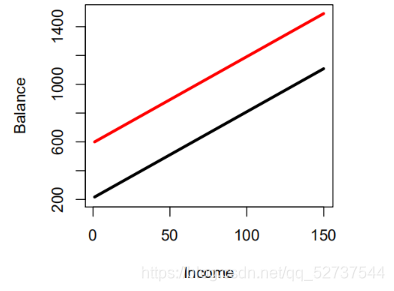 含交互项的模型:
含交互项的模型:
b a l a n c e i ≈ β 0 + β 1 ∗ i n c o m e i + { β 2 + β 3 ∗ i n c o m e i 学 生 0 非 学 生 = { ( β 0 + β 2 ) + ( β 1 + β 3 ) ∗ i n c o m e i 学 生 β 0 + β 1 ∗ i n c o m e i 非 学 生 balance_i\approx\beta_0+\beta_1*income_i+\begin{cases}\beta_2+\beta_3*income_i\ \ \ 学生\\0\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 非学生\end{cases}=\begin{cases}(\beta_0+\beta_2)+(\beta_1+\beta_3)*income_i\ \ \ 学生\\\beta_0+\beta_1*income_i\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 非学生\end{cases} balancei≈β0+β1∗incomei+{β2+β3∗incomei 学生0 非学生={(β0+β2)+(β1+β3)∗incomei 学生β0+β1∗incomei 非学生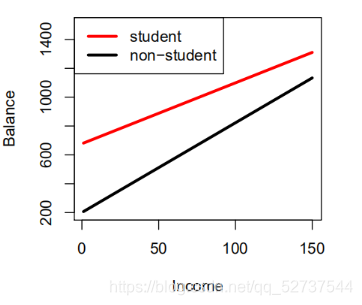
非线性关系
多项式回归(polynomial regression)
例如二次方(quadratic):
m p g = β 0 + β 1 ∗ h o r s e p o w e r + β 2 ∗ h o r s e p o w e r 2 + ε mpg=\beta_0+\beta_1*horsepower+\beta_2*horsepower^2+\varepsilon mpg=β0+β1∗horsepower+β2∗horsepower2+ε
潜在的问题
(1)非线性的响应——预测关系(nonlinaerity of response-predictor relationship):可用残差图(residual plot) 识别非线性。
(2)误差项自相关(correlation of error term):常出现在时间序列数据中,会低估标准误与p值。
(3)误差项方差非恒定(non-constant variance of error term):存在异方差性。
(4)离群点(outlier): y i y_i yi 远离模型预测值的点。
(5)高杠杆点(high-leverage point):观测点 x i x_i xi 是异常的
杠杆统计量:
h i = 1 n + ( x i − x ˉ ) 2 ∑ i ′ = 1 n ( x i ′ − x ˉ ) 2 h_i=\frac{1}{n}+\frac{(x_i-\bar{x})^2}{\sum_{i'=1}^n(x_{i'}-\bar{x})^2} hi=n1+∑i′=1n(xi′−xˉ)2(xi−xˉ)2
如果给定观测的杠杆统计量大大超过(p+1)/n,那么可以怀疑对应点有较高的杠杆作用。
(6)共线性(collinearity):
方差膨胀因子(variance inflation factor,VIF):
V I F ( β ^ j ) = 1 1 − R X j ∣ X − j 2 VIF(\hat{\beta}_j)=\frac{1}{1-R_{X_j|X_{-j}}^2} VIF(β^j)=1−RXj∣X−j21
其中 R X j ∣ X − j 2 R_{X_j|X_{-j}}^2 RXj∣X−j2 是 X j X_j Xj 对所有预测变量回归的 R 2 R^2 R2。如果该值接近于1,那么存在共线性,VIF会很大。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)