PTPX功耗分析笔记——跑出功耗报告
(5)进行功耗分析。从芯片设计到芯片量产的过程中功耗分析是必不可少的环节,在流片前进行功耗分析可以大致估计芯片在各应用场景中的功耗,可以提前做好功耗的优化,达到我们的预期功耗目标。功耗分析分为综合后的功耗分析(简称pre功耗分析)和PR后的功耗分析(简称post功耗分析)。post的功耗分析用的网表是经过布局布线、插入时钟树等相关操作后的网表和sdf文件跑出波形文件(这里用的是fsdb波形文件)来
从芯片设计到芯片量产的过程中功耗分析是必不可少的环节,在流片前进行功耗分析可以大致估计芯片在各应用场景中的功耗,可以提前做好功耗的优化,达到我们的预期功耗目标。但毕竟不是实际芯片的测量功耗,与实际芯片实际功耗还是不同的。而回片后的功耗测量则是实际的芯片功耗,与预估功耗会有一定的差别。流片前的功耗分析十分重要,有助于我们提前做好芯片的优化,避免无效投入和资源消耗。而流片前的功耗分析能检查出在不同的工作模式下或者工作场景下是否存在不必要的功耗,比如时钟该关的模块是否关闭,不该工作的模块是否没有工作,可以做到芯片设计的合理性检查。
功耗分析分为综合后的功耗分析(简称pre功耗分析)和PR后的功耗分析(简称post功耗分析)。pre功耗分析是直接用综合后的网表和sdf文件跑出波形文件(这里用的是fsdb波形文件),进行功耗分析。post的功耗分析用的网表是经过布局布线、插入时钟树等相关操作后的网表和sdf文件跑出波形文件(这里用的是fsdb波形文件)来进行功耗分析,且在PR过程中可能会引入新的库文件,在post功耗分析时需要将新的库文件加入功耗分析的库里面。
不论是pre功耗分析还是post功耗分析,个人认为功耗分析的能力分为三种级别:(1)根据输入文件能跑出正确的功耗;(2)能对跑出的功耗进行正确合理与否的分析;(3)能根据功耗报告提出相应的功耗优化措施。这里的笔记是关于如何跑出功耗报告,关于分析和优化建议后面会用其它笔记记录。
这里记录的功耗分析是使用ptpx进行的,进行功耗分析主要分为以下几个步骤:(1)设置功耗分析模型,总共包括time_based和averaged两个功耗分析模型;(2)读取库文件和网表文件并将它们link起来;(3)设置input transition和annotate parasitics;(4)读取波形文件;(5)进行功耗分析。进行功耗分析的模板在功耗分析工具的教程里就有,如用ptpx进行功耗分析的步骤介绍就在PT的目录下能找到。虽然能找到,但比较简单,可能在实际使用中还有所修改增补,下面简单给出一个,仅为方便自己以后翻看笔记并进行修改完善,如有错误和欠缺的,请大家慷慨指出和补充。
1 跑出功耗数据
第一步:设置功耗分析模型,这里是固定格式,注:这里的averaged可以根据需求换成time_based
# set the power analysis mode
set power_enable_analysis TRUE
set power_analysis_mode averaged
注:averaged功耗和time_based功耗的区别有:
1 time_based是基于时间的,会有一个ptpx.fsdb(可能会保存在功耗分析的执行路径下),现实每一时刻的功耗情况的分析,可以通过verdi打开看功耗波形,且在报告里会有peak值;而averaged则只是个功耗报告。
2 time_based的功耗分析时间长于averaged的功耗分析时间。
3 两者的总功耗数据不一定完全一致,会有略微的区别,但不影响功耗分析。
第二步:读取网表和库文件,设置current_design,将它们link起来,注:关于库文件的设置可以单独放在一个文件里,在这个script中直接source 放库的文件,放库的文件可以参考综合时对综合库的文件进行放置。
# read and link the gate level netlist
set search_path "../src/hdl/gate ../src/lob/snps "
set link_library "* core_type.db"
#source ptpx_setup_lib.tcl
read_verilog design.vg
current_design design_top
link
注:link_library和link_path是相同的,可以用link_path替换link_library
第三步:读取时序约束文件
# read sdc and set transition time or annotate parasitics
read_sdc ../../design.sdc
#read_parasitics ../src/annotate/mac.spef.gz
read_sdf -analysis_type on_chip_variation design_top.sdf
注:sdc文件应该包含如下设置:
set_max_transition 0.8 [current_design]
set_max_fanout 50 [current_design]
set_max_capacitance 0.2 [current_design]
因为这些参数会影响功耗数据。(对时序的约束相对于这些参数没有那么重要,原因是:波形文件中已经包含用于分析功耗的时间信息,且sdf中也包含基于时序约束的时间信息。这一点是基于比较去掉sdc文件和加上sdc文件的功耗结果分析得出的,希望有经验的大拿帮忙分析,如有不对还请指正。)
第四步:检查、更新、报告时序
# check update or report the timing
check_timing
update_timing
report_timing > ./rpt/report_timing.rpt
第五步:读取波形文件
# read switching activity file
#read_vcd -strip_path tb/macinst ../sim/vcd.dump.gz
read_fsdb -strip_path "tb_top.design_top" /path/wavie.fsdb -time {start_time end_time}
report_switching_activity -list_not_annotated > ./rpt/report_switching_activity_annotated.rpt
第六步:检查、更新、报告功耗到指定的文件中
# check or update or report power
check_power > ./rpt/check_power.rpt
update_power
report_power -hierarchy > ./rpt/report_power.rpt
report_power -verbose > ./rpt/report_power_verbose.rpt
quit
两种功耗分析模型的报告不一样,下面展示一下手册里的报告,如有侵权,请及时告知并会即使删除。第一张为time_based的功耗报告,第二张为averaged的功耗报告。
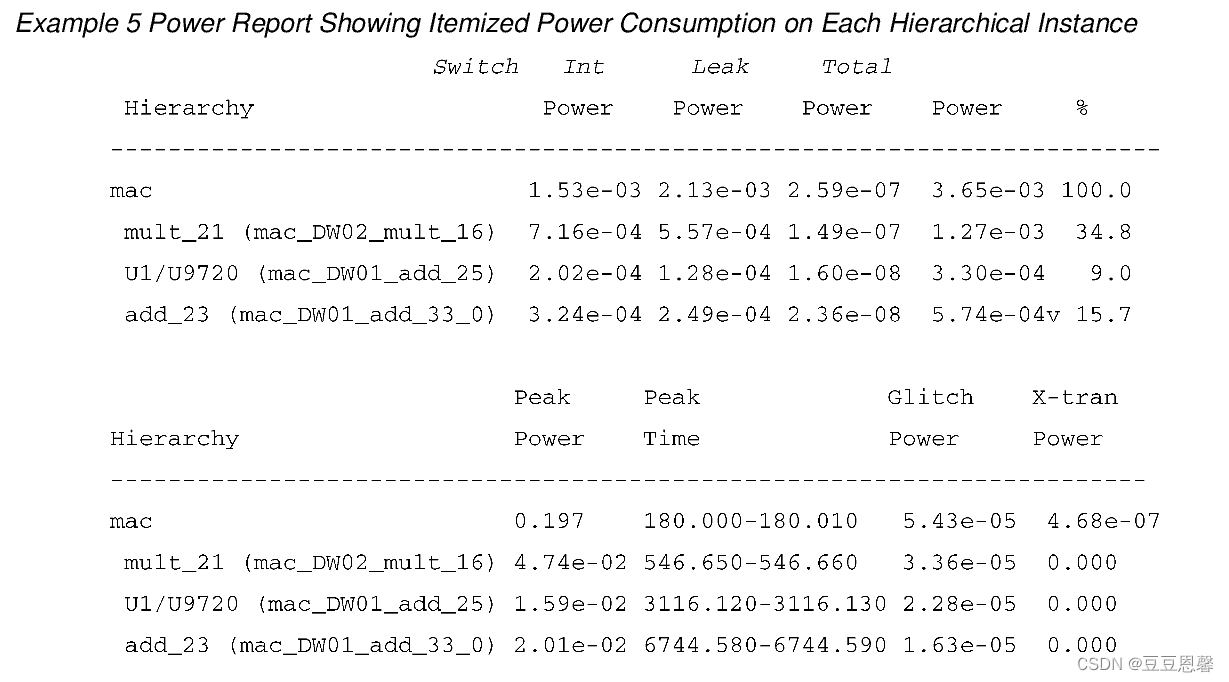

上面给出的是用ptpx分析功耗的大致步骤,在具体使用的过程中,可能还会涉及到对operating_condition的设置,某些drc的设置,环境变量的设置等。
set_operating_conditions -tt_typical_max_0p90v_25c -analysis_type on_chip_variation
set timing_save_pin_arrival_and_slack true
注:设置所有pins的slack in memory。当设置为true,the arrival times and slacks of all pins of the designe are kept in memory。如果设置为false,arrival times and slacks 只针对endpoints of the design.
set timing_save_pin_arrival_and_required true
set timing_enable_max_capacitance_set_case_analysis true
注:使能对constant pins进行max capacitance检查,default为false
set auto_wire_load_selection false
注:使能自动选择wire load models,default是true
set svr_keep_unconnected_nets true
注:设置保存未连接的net,default是true。
set timing_remove_clock_reconvergence_pessimism true
注:当设置为true时,工具在计算slack和minimum pulse width check时会移除clock reconvergence pessimism.
set timing_disable_recovery_removal_checks false
注:设置不进行recovery/rrmoval的timing check,default是false。
set timing_early_launth_at_borrowing_latches false
set si_enable_analysis true
注:设置PrimeTime SI (之行crosstalk analysis)使能,default是false。
功耗报告中还有一个总的概述的功耗内容,从PTPX的使用手册中可以找到,下面的截图和说明引用自PTPX的使用手册。
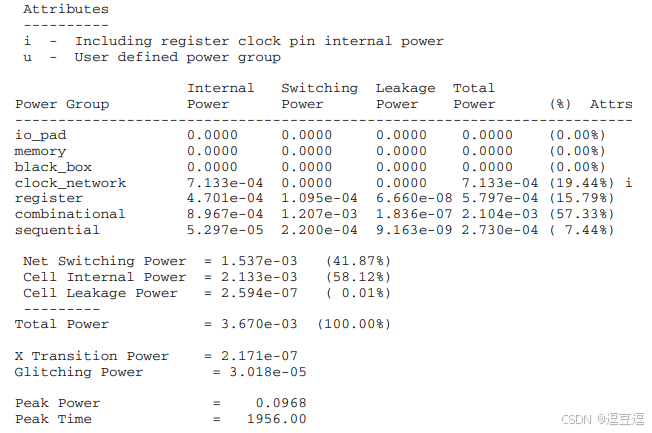
black_box:cells with no functionality, excluding io_pad 安定memory cells
clock_network: cells in the clock tree network,excluding io_pad cells,包括始终网络中的buffers、inverters,时钟门控逻辑
register:latches and flip-flops ,excluding clock-gating logic, driven by a clock
如果power_clock_network_include_register_clock_pin_power为true,则register的时钟引脚的功耗算在了时钟网络中,而register的其他部分的工号为register的功耗。
如果power_clock_network_include_register_clock_pin_power为false,则register的时钟引脚的功耗算入了register功耗里。
sequential:latches and flip-flops excluding clock-gating logic and not driven by a clock;the clock pin of the sequential cell is not connected to the clock network.
combinational:any remaining cells not identified as belonging to the other power groups.
2 check为正确的功耗数据
跑出功耗数据是基础,但不正确的功耗数据不具有任何意义,因此在跑出功耗数据后,在发布功耗数据前一定要检查跑出来的功耗数据是否正确,若不正确则可能大至影响上层的决策,小则损失个人在团队中的形象。检查功耗数据的正确与否可以从以下几个方面出发:
(1)波形是否正确,使用的sdf文件是否和网表版本一致,case是否正确;波形的截取时间范围是否正确。
(2)库文件是否正确完整:功耗分析的corner和库文件的corner是否一致;库文件是否有缺失。
(3)网表文件和sdf文件是否正确:网表文件和sdf文件版本要一致,也要和波形文件一致。
(3)log的检查:其中的error和warning是否可以忽略;网表和库文件是否link成功。
如果以上几个方面都是正确的,符合要求的则输出的功耗数据便具有分析的意义,可以进行下一步的功耗分析。
补充1:
在跑功耗的脚本里一定要加上这一句:save_session 保存到的具体路径
保存到的具体路径最好里面是空的,只存session的内容,该文件可以用于本次功耗分析退出后再次查看本次功耗的分析结果,直接在pt_shell中使用restore_session 保存到的具体路径即可。
如果没有保存session,需要再次生成该次功耗分析的其他报告时,需要重新跑功耗分析后才能输出,这样很浪费时间甚至不可复现。
补充2:
在跑time_based功耗后会产生一个ptpx.fsdb的文件,用于查看实时功耗波形变化,这个可以用verdi打开,具体的打开命令是:verdi -ssf ptpx.fsdb &
一个Verdi可以打开多个波形包括rtl级或者门级的仿真波形,可以查看对比功耗随工作的变化,也可以帮助分析功耗。
先写到这里,后面有更新或修改再补充修改。
3 推荐链接
关于upf在ptpx分析中的使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)