多尺度卷积
比如说,输出y4可以是x4经过一次卷积,也可以是x3经过2次卷积,还可以是x2经过三次卷积。如下图,黄色部分表示高频特征图,蓝色部分表示低频特征图。作者还提到,不仅在普通的卷积中可以改造成八度卷积的方法,对于分组和可分离卷积同样也是适用的。而且八度卷积是一个可插拔的整体操作,基本上只需要在特定位置上改成相应的八度卷积即可,卷积参数基本上保持不变,只是增加了一个低频占比的参数,以及在输入输出的特征图
1.多尺度卷积(比如特征金字塔)的优势:
- 多尺度信息:可以在不同层级的网络中提取特征来获取多尺度信息。在目标检测任务中,目标可能以不同的尺寸出现在图像中,因此需要在不同尺度上进行检测和定位。通过合并不同层次的特征图,可以检测和识别不同尺寸的目标。
- 上下文信息:通过在不同的层级中提取特征,可以捕获更广泛的上下文信息。较深层次的特征通常对于全局语义信息具有较好的把握,而较浅层次的特征可以提供更多局部细节信息。通过多尺度卷积,算法可以在不同层级上同时利用全局和局部信息,从而更好地理解图像内容。
- 减少信息丢失: 在深度卷积神经网络中,随着网络层数的增加,特征图的尺寸逐渐减小。这可能导致信息丢失,特别是对于较小目标或细节。通过融合多个尺度的特征,可以减少信息丢失的影响,提高网络的能力。
2. SSD
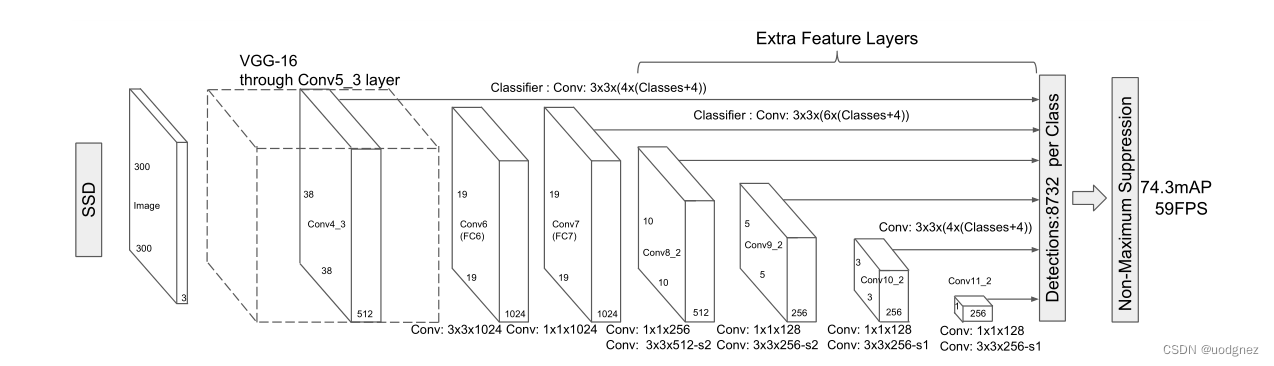
SSD的网络结构主要分为三个部分:VGG16 Base Layer, Extra Feature Layer, Detection layer
VGG16 Base Layer:
SSD网络以VGG16作为基础的特征提取层,并选取其中的Conv4_3作为第一个特征层用于目标检测。
Extra Feature Layer:
在Base Layer的基础上,作者将VGG16中的FC6,FC7改成了卷积层Conv6,Conv7,并且同时添加了Conv8,Conv9,Conv10,Conv11这几个特征层用于目标检测。
输入:reshape后 大小为 (300×300×3)(300 \times 300\times3)(300×300×3)的图像
Conv1_2:两次3×33 \times33×3卷积,得到(300×300×64)(300 \times 300\times64)(300×300×64);再经过2×22\times22×2最大池化,得到(150×150×64)(150 \times 150\times64)(150×150×64)
Conv2_2:两次3×33 \times33×3卷积,得到(150×150×128)(150 \times 150\times128)(150×150×128);再经过2×22\times22×2最大池化,得到(75×75×128)(75 \times 75\times128)(75×75×128)
Conv3_3:三次3×33 \times33×3卷积,得到(75×75×256)(75 \times 75\times256)(75×75×256);再经过2×22\times22×2最大池化,得到(38×38×256)(38 \times 38\times256)(38×38×256)
Conv4_3:三次3×33 \times33×3卷积,得到(38×38×512)(38 \times 38\times512)(38×38×512);再经过2×22\times22×2最大池化,得到(19×19×64)(19 \times 19\times64)(19×19×64)
Conv5_3:三次3×33 \times33×3卷积,得到(19×19×512)(19 \times 19\times512)(19×19×512);再经过3×33\times33×3最大池化,得到(19×19×512)(19 \times 19\times512)(19×19×512)
Conv6、Conv7:分别进行了一次3×33\times33×3卷积和1×11\times11×1卷积,得到(19×19×1024)(19 \times 19\times1024)(19×19×1024)
Conv8:经过一次1×11\times11×1卷积,和3×33\times33×3卷积,得到10×10×51210 \times 10 \times51210×10×512
Conv9:经过一次1×11\times11×1卷积,和3×33\times33×3卷积,得到5×5×2565 \times 5\times2565×5×256
Conv10:经过一次1×11\times11×1卷积,和3×33\times33×3卷积,得到3×3×2563 \times 3 \times2563×3×256
Conv11:经过一次1×11\times11×1卷积,和3×33\times33×3卷积,得到1×1×2561 \times 1 \times2561×1×256
3.Res2Net
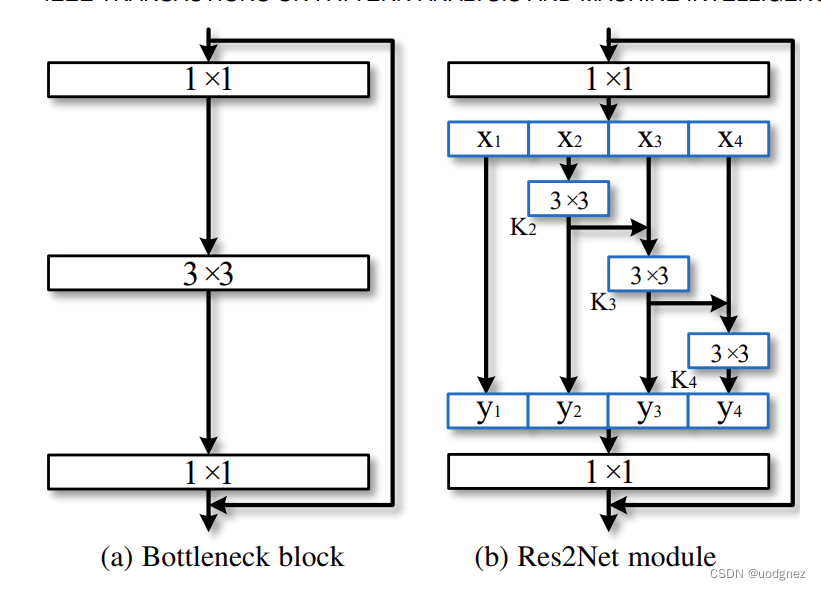
文章方法从卷积神经网络中的最基本的常用单元入手。对于主流卷积神经网络中广泛存在的残差瓶颈结构进行多尺度增强。如上图右图所示,对于输入特征,我们首先通过1×11\times11×1卷积进行通道数的调控。然后将这些特征分为4份。例如,x2可以经过一次卷积直接输出,其卷积结果可以进一步和x3相加再经过一次卷积后输出。这种做法的优势显而易见。比如说,输出y4可以是x4经过一次卷积,也可以是x3经过2次卷积,还可以是x2经过三次卷积。这种操作使得尺度种类组合爆炸,进而提供非常丰富的多尺度特征。虽然右侧的图看着更复杂,但是采用这种方式提升多尺度能力,仅需要增加十多行代码。而且,右侧的模块计算量和参数量小于左侧。左侧图中计算量最大的是3×33\times33×3卷积。假如我们有512个通道,这里的计算量是512×3×3×512512\times3\times3\times512512×3×3×512。像右图所示的分为四份之后,每一个3×33\times33×3的卷积仅需要左侧1/16的计算量。因此,如果简单的分割为4块而不大幅增加通道数,右侧的计算量只有左侧的不到1/4。
4.OctaveConv

作者认为:不仅自然世界中的图像存在高低频,卷积层的输出特征图以及输入通道也都存在高、低频分量。低频分量支撑的是整体,比如企鹅的白色大肚皮。显然,低频分量是存在冗余的,在编码过程中可以节省。如下图,黄色部分表示高频特征图,蓝色部分表示低频特征图。这种特征图按照频率分成两部分的做法称为"Octave feature representation"。其中低频特征图和高频特征图的比例为α:1−α,α∈[0,1]\alpha:1-\alpha, \alpha \in[0,1]α:1−α,α∈[0,1],表示低频特征图所占比例。
针对冗余问题,作者降低低频特征图的分辨率,即降低低频特征图的空间维度。这种方式不仅能够节省算力、储存,还有助于每个层获得更大的感受野,以捕获更多的上下文信息。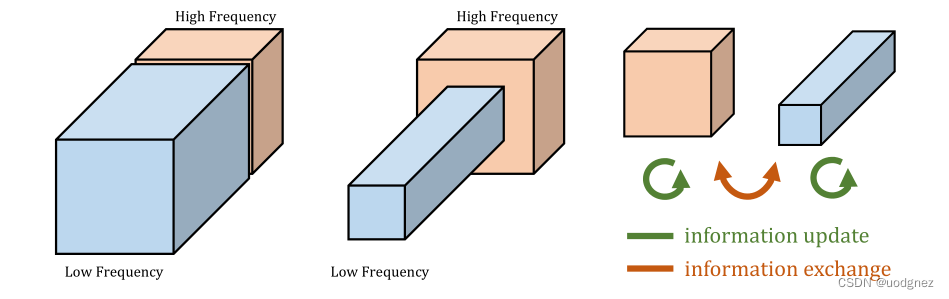
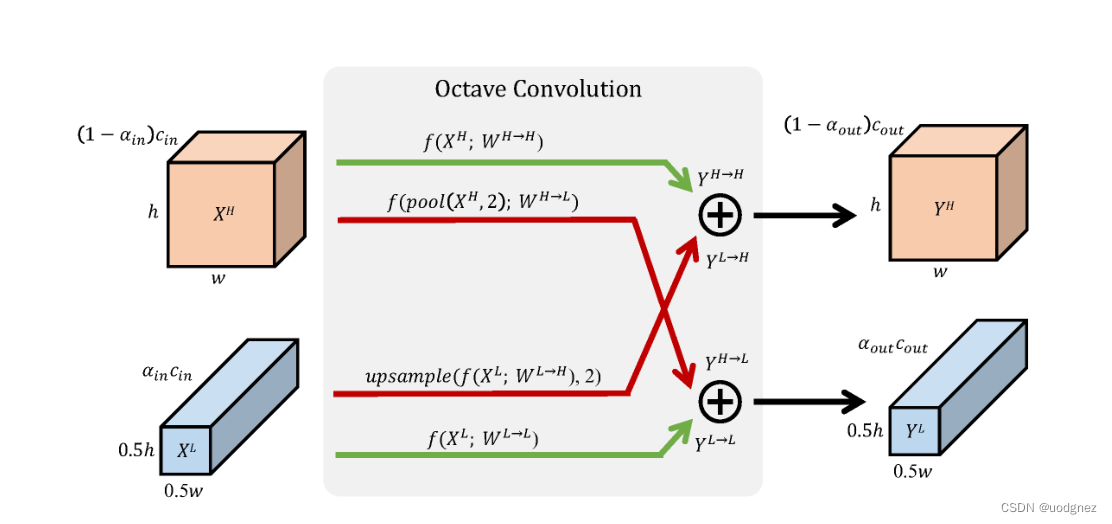
上半部分:输入XHX^HXH经过卷积之后得到输出YH→HY^{H \rightarrow H}YH→H,输入XLX^LXL经过卷积后,再进行上采样将分辨率扩大(与高频分辨率相同)得到输出YL→HY^{L \rightarrow H}YL→H,YH→HY^{H \rightarrow H}YH→H 与YL→HY^{L \rightarrow H}YL→H再经过点加操作得到高频输出特征图YHY^HYH。
下半部分:输入XLX^LXL经过卷积之后得到输出YL→LY^{L \rightarrow L}YL→L,输入XHX^HXH经过卷积后,再进行下采样(池化)得到输出YH→LY^{H \rightarrow L}YH→L,YH→LY^{H \rightarrow L}YH→L 与YL→LY^{L \rightarrow L}YL→L再经过点加操作得到低频输出特征图YLY^LYL。
作者还提到,不仅在普通的卷积中可以改造成八度卷积的方法,对于分组和可分离卷积同样也是适用的。而且八度卷积是一个可插拔的整体操作,基本上只需要在特定位置上改成相应的八度卷积即可,卷积参数基本上保持不变,只是增加了一个低频占比的参数,以及在输入输出的特征图上分成了高频和低频部分。
5.ScaleNet
6. MixConv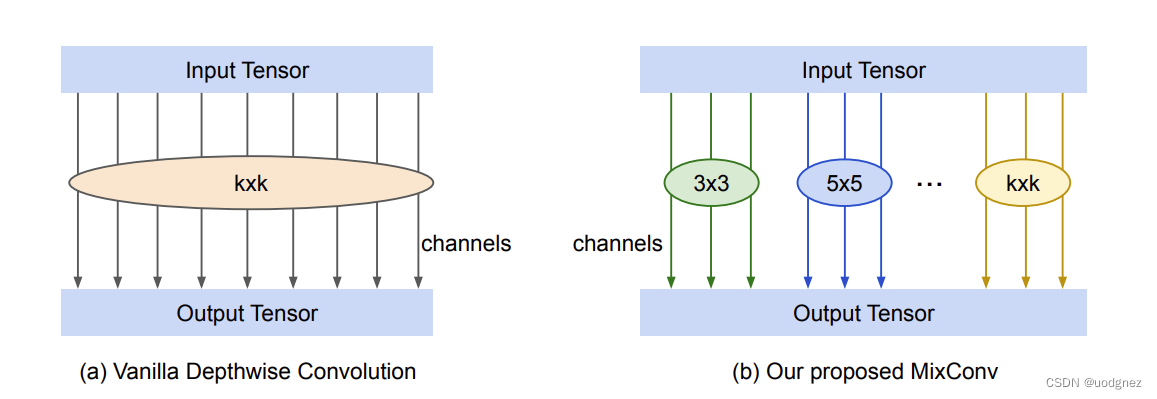
旨在设计单个深度卷积的直接替换,目的是轻松利用不同的卷积核大小而不改变网络结构。
6.Pyramidal Convolution

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)