编译原理——词法分析器的设计(笔记)
词法分析器的设计
对于词法分析器的要求
词法分析的任务
- 从左至右逐个字符地对源程序进行扫描,产生一个个单词符号
词法分析器 (Lexical Analyzer) 又称扫描器 (Scanner)
- 执行词法分析的程序
功能
输入源程序、输出单词符号
单词符号的种类
- 基本字:如 begin , repeat
- 标识符——表示各种名字:如变量名、数组名和过程名
- 常数:各种类型的常数
- 运算符: + , - , * , /
- 界符:逗号、分号、括号和空白
输出的单词符号的表示形式
- 单词种别
- 单词自身的值
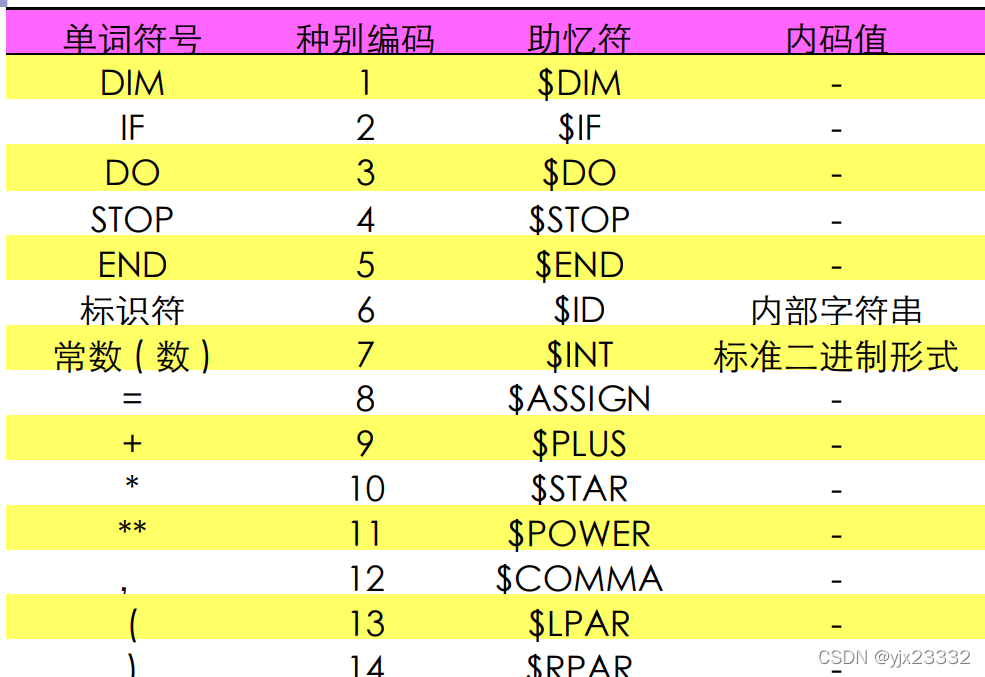
单词种别通常用整数编码表示
若一个种别只有一个单词符号,则种别编码就代表该单词符号。假定基本字、运算符和界符都是一符一种。
若一个种别有多个单词符号,则对于每个单词符号,给出种别编码和自身的值。
- 标识符单列一种;标识符自身的值表示成按机器字节划分的内部码
- 常数按类型分种;常数的值则表示成标准的二进制形式
我们常用常量对应种别编码方便阅读。
如下图,'id’则是‘标识符’的种别编码。‘while’的是‘while’,‘(’是‘(’。

词法分析器作为一个独立子程序
词法分析是作为一个独立的阶段,是否应当将其处理为一遍呢?
作为独立阶段的优点:
- 结构简洁、清晰和条理化,有利于集中考虑词法分析一些枝节问题
不作为一遍:
- 将其处理为一个子程序
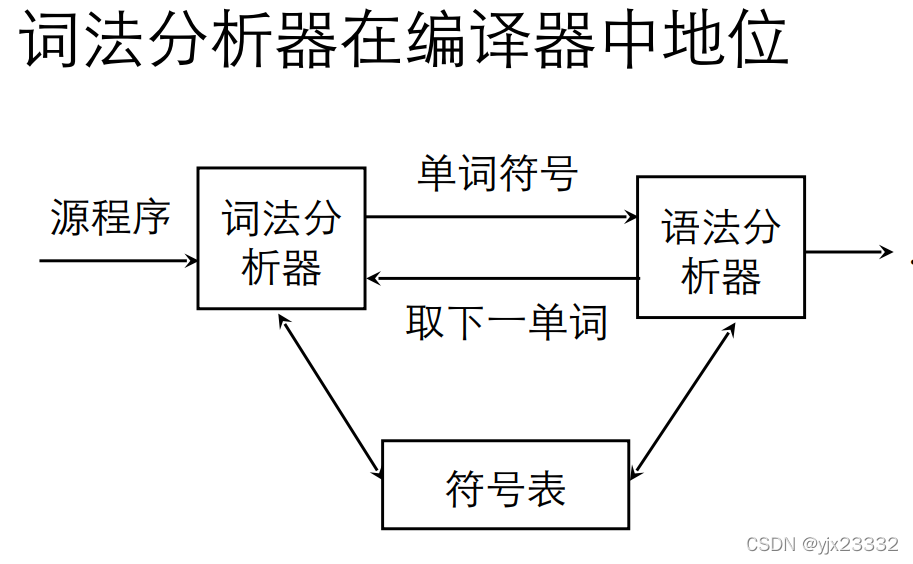
词法分析器在编译器中地位
语法分析器驱动词法分析器。
当语法分析器需要下一个单词时,调用词法分析器。词法分析器扫描下一个单词,分析下一个种类编码和自身的值,交给语法分析器。
语法分析器拿到后,如果可以进行语法分析,则进行语法分析,不行则取下一个单词。
词法分析器的设计
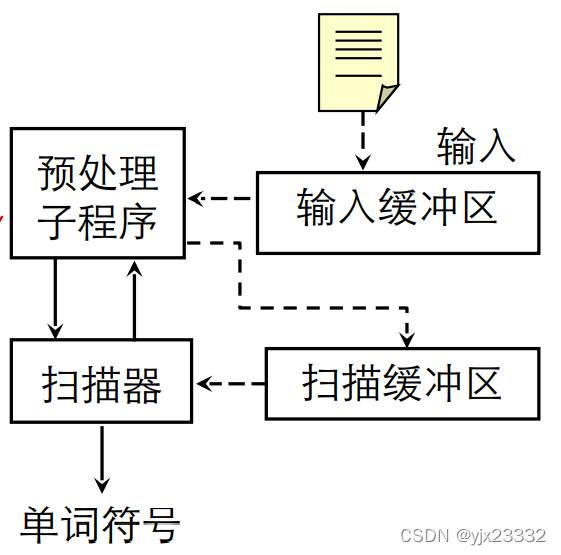
词法分析器的结构
在预处理子程序中
- 剔除无用的空白、跳输入格、回车和换行等编辑性字符
- 区分标号区、连接续行和给出句末符等
随后程序控制会返回到扫描器中,扫描器会扫描缓冲区,将预处理处理的比较规范的字符串取出。
依据此法规则,识别但此符号(基本子,标识符,常量等),将单词符号的二元组返回给外界。
输入、预处理
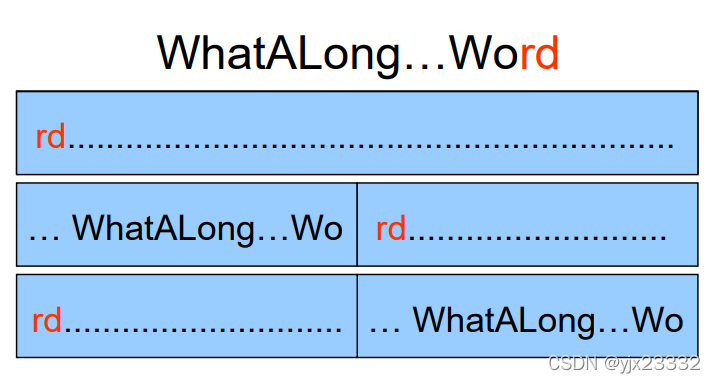
两根指针,起点指示器表示起点,搜索指示器表示当前终点。以此来指示一个单词。
当单词过长或内容过多时,单词可能会被截断。如果只用一个缓冲区,我们需要设置阈值,超过就不能再填入单词了,但设置上比较麻烦。
为了解决这个问题,将缓冲区一分为二。两个半区互补使用。限制每一个单词不可超过半区长度。
当我们使用前半部分缓冲区时,后半部分用于存储溢出。当我们使用后半部分缓冲区时,前半部分用于存储溢出。当溢出时,就不再填入了。
单词符号的识别 : 超前搜索
基本字的识别:当有允许程序员在编写中不空格等,我们需要超前搜索才能确定哪些是基本字。
DO99K=1,10 DO 99 K = 1,10
标识符识别:比如字母开头的字母数字串,后跟界符或算符,我们也需要用超前搜索。
常数识别:识别出算术常数并将其转变为二进制内码表示。有些也要超前搜索。
- 5.EQ.M(5==M)
- 5.E08(5.0*10^8)
算符和界符的识别:当有把多个字符符合而成的算符和界符拼合成一 个单一单词符号,我们也需要超前搜索。
:= , ** , .EQ. , ++ , -- , >=
但是,由于做超前搜索比较困难,一般会用一些限制,以避免超前搜索。
所有基本字都是保留字 ; 用户不能用它们作自己的标识符
基本字作为特殊的标识符来处理,使用保留字表
如果基本字、标识符和常数 ( 或标号 ) 之间没有确定的运算符或界符作间隔,则必须使用一个空白符作间隔
状态转换图
状态转换图是一张有限方向图
结点代表状态,用圆圈表示(词法分析器分析一个单词时,所处的不同状态)
状态之间用箭弧连结,箭弧上的标记(字符)代表射出结状态下可能出现的输入字符或字符类
一张转换图只包含有限个状态,其中有一个为初态,至少要有一个终态
状态转换图可用于识别(或接受)一定的字符串
65. 有效数字 - 力扣(LeetCode) (leetcode-cn.com)
若存在一条从初态到某一终态的道路,且这条路 上所有弧上的标记符连接成的字等于,则称
为 该状态转换图所识别 ( 接受 )
助忆符
直接用编码表示不便于记忆,因此用助忆符来表示编码。
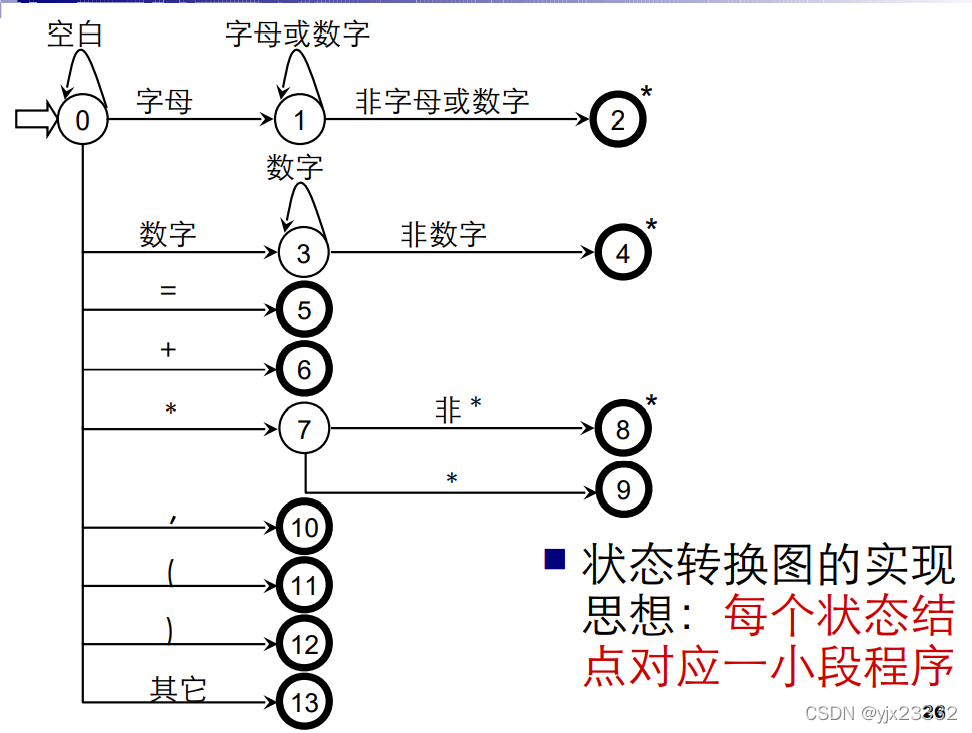
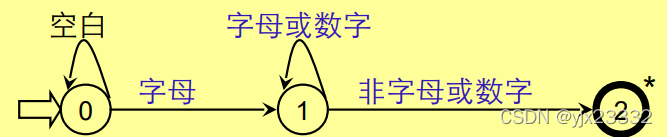
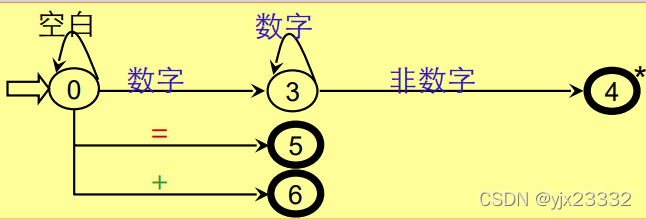
实现:
- 对不含回路的分叉结点,可用一个CASE(SWITCH语句)语句或一组IF-THEN-ELSE语句实现。
- 对含回路的状态结点,可对应一段由WHILE结构和IF语句构成的程序。
- 终态结点表示识别出某种单词符号,因此,对应语句为RETURN(C,VAL)其中,C为单词种别,VAL为单词自身值。
伪代码实现一
定义
- ch 字符变量、存放最新读入的源程序字符
- strToken 字符数组,存放构成单词符号的字符串
- GetChar 子程序过程,把下一个字符读入到ch中
- GetBC 子程序过程,跳过空白符,直至ch中读入一非空白符
- Concat 子程序,把 ch中的字符连接到strToken
- IsLetter和IsDisgital布尔函数,判断ch中字符是否为字母和数字
- Reserve 整型函数,对于strToken中的字符串查找保留字表,若它实保留字则给出它的编码,否则回送0
- Retract 子程序,把搜索指针回调一个字符位置
- InsertId 整型函数,将strToken中的标识符插入符号表,返回符号表指针
- InsertConst整型函数过程,将strToken中的常数插入常数表,返回常数表指针
伪代码
int code,value;
string strToken = "";
Getchar();
GetBC();
if(IsLetter()){
while (IsLetter() || IsDigit()){
Concat();
GetChar();
}
Retract();
code = Reserve();
if (code = 0){//标识符
value := InsertId(strToken);
return ($ID, value);
}
else//保留字
return (code, -);
}
else if (IsDigit()){
while (IsDigit()){
Concat( );
GetChar( );
}
Retract();
value = InsertConst(strToken);
return($INT, value);
}
else if (ch =‘=’)
return ($ASSIGN, -);
else if (ch =‘+’)
return ($PLUS, -);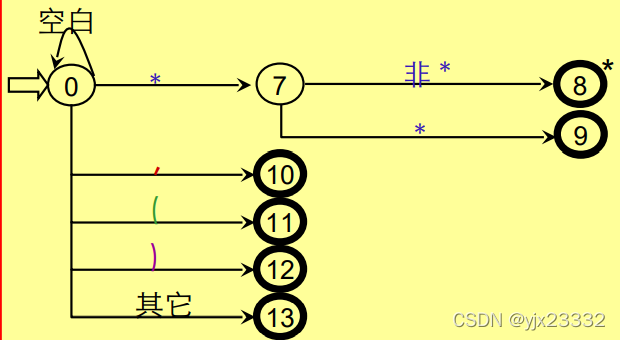
else if (ch =‘*’){
GetChar();
if (ch =‘*’)
return ($POWER, -);
Retract();
return ($STAR, -);
}
else if (ch =‘,’)
return ($COMMA, -);
else if (ch =‘(’)
return ($LPAR, -);
else if (ch =‘)’)
return ($RPAR, -);
else
ProcError( ); /* 错误处理 */
伪代码实现二
一般化,可以用二位数组表示状态图。
int curState = 0;//初态
GetChar();
while(stateTrans[curState][ch]){
// 存在后继状态,读入、拼接
Concat();
// 转换入下一状态,读入下一字符
curState = stateTrans[curState][ch];
if(cur_state == 8)
return strToken;
GetChar( );
}
如果想要实际实现一下代码,可以看一下力扣的65题:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)