Lucene构建索引的原理及源代码分析
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。在讲全文
文章目录
1. Lucene是什么
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
2. 全文检索是什么
在讲全文检索之前,我们先聊下数据的分类。那么什么是数据呢?提起数据,大家可能会说数据库里存的就是数据。这个没错,比如我们熟知的mysql、oracle,都是知名的数据库。除了数据库之外,用其他格式存储的,也是数据,比如用word处理的文件、一个网页等等。由于存储数据的格式有很多,我们可以数据进行如下的分类:
- 结构化数据
- 格式固定,长度固定,数据类型固定。比如常用的关系型数据库就属于这类
- 非结构化数据
- 格式不固定,长度不固定,数据类型不固定。word文档、pdf文档、邮件、网页等等
不同类型的数据,其查询方式也有不同:结构化数据,可以通过SQL查询,简单快速。但是对于非结构化数据,立马可以想到的检索方式就是遍历,比如要查询包含某个单词的文档,就可以顺序扫描所有要检索的文档,然后通过字符串匹配,找到所有包含该单词的文档。这种方式在小数据量的情况下还ok,但是如果数据量特别大的话,这种方式就显得力不从心了。
顺序扫描不合适,那还有其他方式吗?大家可能会想,既然结构化数据在检索方面可以做到快速高效,能不能把非结构化数据也转变成结构化数据呢?其实Lucene就是这么干的。lucene做的只有两件事:建立索引和搜索索引。
非结构化数据转变成结构化数据的过程如下:先根据空格将字符串拆分,得到一个单词列表,基于单词列表创建一个索引。所以底层就要维护单词索引、文档以及单词和文档的关系。那么在查询的过程中,就需要先查索引,然后根据单词和文档的对应关系找到需要的文档。这个过程就叫做全文检索。
有人会问,这个过程相比与顺序扫描,其实是把压力给到了写数据的环节。是这样的,索引操作只不过是为了增强用户搜索体验而需要跨越的一到障碍而已,所以这种方式适用于读多写少的场景,一次写入可以大量读取的场景,那么这样建立索引就是值得的。
3. 术语
- 原始文档:要基于哪些数据进行搜索,那么这些就是原始文档
- 文档对象(Document):每个原始文档对应一个Document对象,每一个文档都有唯一的id,也就是文档id
- 域(Field):每个Document包含多个Field,Field中保存了原始文档的数据,包含了域的名称和域的值
- Term:每个关键词都封装成一个Term对象。Term中包含两部分内容:关键词所在域、关键词本身
- 索引:基于关键词列表创建一个索引,保存在索引库中
4. 创建索引过程
Lucene将输入数据以一种倒排索引的数据结构进行存储。使用倒排数据结构的原因是:把文档中提取出的语汇单元作为查询关键字,而不是将文档作为中心实体。为什么称为倒排索引呢?因为正常看一个文档会提出“这个文档中包含哪些单词?”,但是检索的场景更多是“哪些文档包含单词X?”,这种像是反着来查结果,所以被称为倒排。
4.1 Lucene创建索引示例代码
public static void main(String[] args) throws Exception {
//1. 创建一个Director对象,指定索引库保存的位置
Directory directory = FSDirectory.open(new File("/Users/luceneIndex/index").toPath());
//2. 基于Director对象,创建一个IndexWriter对象
IndexWriter indexWriter = new IndexWriter(directory, new IndexWriterConfig());
//3. 读取磁盘上的文件,对应每个文件创建一个文档对象
File dir = new File("/Users/soft/luceneIndex/source");
File[] files = dir.listFiles();
//4. 向文档中添加域
for (File file : files) {
String name = file.getName();
String path = file.getPath();
String fileContent = FileUtils.readFileToString(file, "UTF-8");
//参数1:域的名称 参数2:域的内容 参数3:是否存储
Field fieldContent = new TextField("content", fileContent, Field.Store.YES);
//创建对象
Document document = new Document();
document.add(fieldContent);
//5. 把文档对象写入索引库
indexWriter.addDocument(document);
}
//6. 关闭IndexWriter对象
indexWriter.close();
}
一旦建立起Lucene文档和域,就可以调用IndexWriter对象的addDocument方法将数据传递给Lucene进行索引操作了。分析文本的过程,主要是将文本数据分割成语汇单元串,然后执行一些可选操作,比如利用LowerCaseFilter转换大小写,利用StopFilter去掉没有实际意义的词等等。
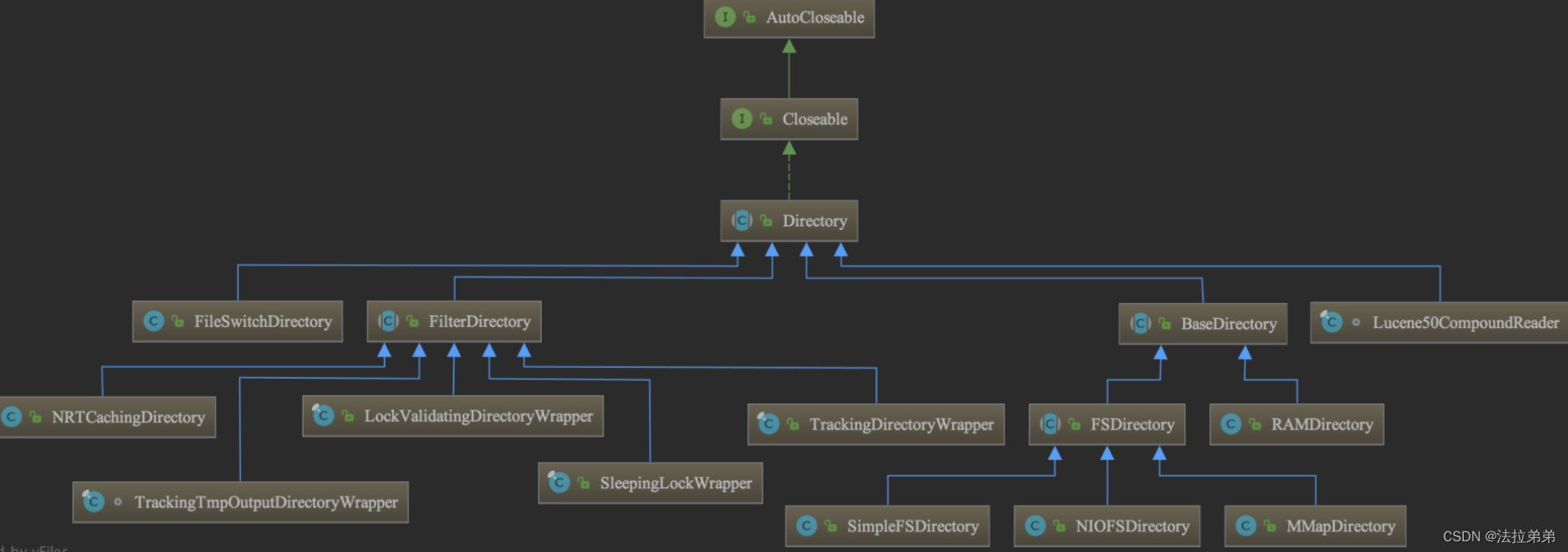
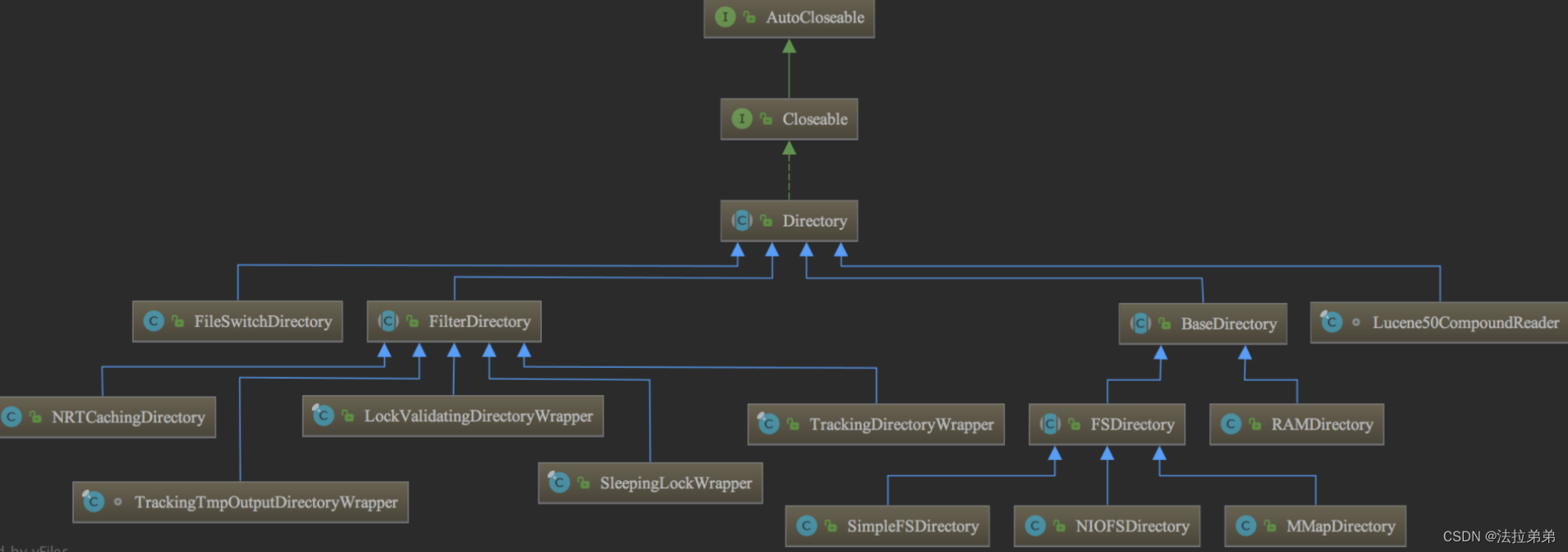
Directory类描述了Lucene索引的存放位置。它是一个抽象类,它的子类负责具体指定索引的存储路径。类继承结构如下图所示:
4.2 分词的过程
4.2.1 原理
从上面的示例代码可以看出来,通过indexWriter.addDocument把文档添加进去。
IndexWriter是索引过程的核心组件。这个类负责创建新索引或者打开已有索引,以及向索引中添加、删除或更新被索引文档的信息。IndexWriter需要开辟一定空间来存储索引,该功能由Directory完成。
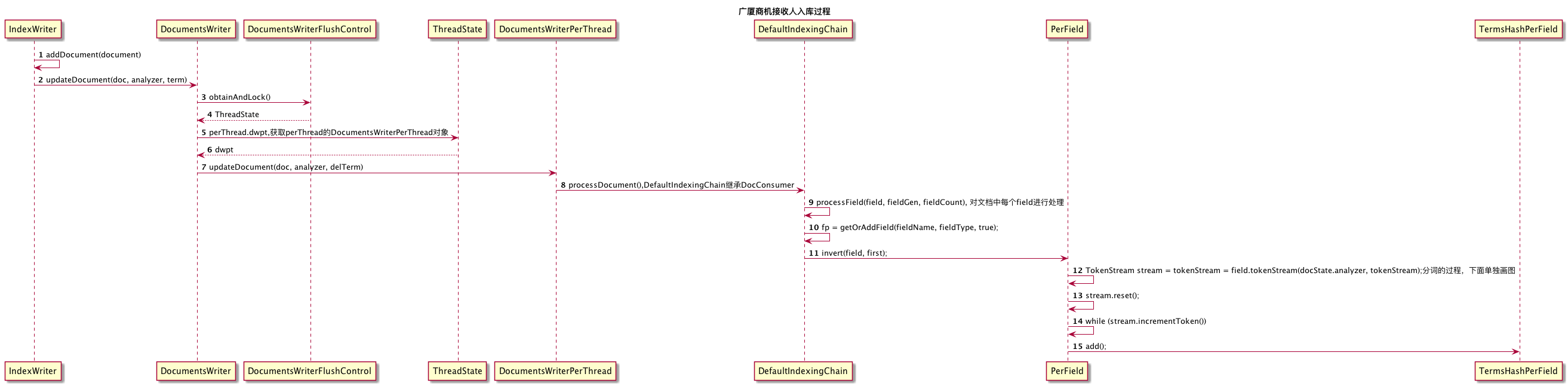
添加document的过程,就是循环把对应的field内容分词并排序的过程。我们可以看到DefaultIndexingChain,这里会通过Analyzer对field进行分词,Analyzer通过链的形式对数据进行处理,就像是工厂一样,包含了很多工序,每一道工序处理一方面的事情。这些工序在Lucene里面分为两大类:Tokenizer和TokenFilter。
Tokenizer永远是Analyzer的第一道工序,有且只有一个。它的作用是读取输入的原始文本,然后根据工序的内部定义,将其转化为一个个token输出。
TokenFilter只能接在Tokenizer之后,因为它的输入只能是token。然后它将输入的token进行加工,输出加工之后的token。一个Analyzer中,TokenFilter可以没有,也可以有多个。
处理的过程如下:
比如StandardAnalyzer的流水线就是下面这个样子:

文本文件在被索引之前,需要经过Analyzer处理,它负责被索引文本文件中提取语汇单元。如果被索引内容不是纯文本文件,那就需要先将其转换为文本文档。对于将Lucene集成到应用程序的开发人员来说,选择什么样的Analyzer是程序设计中非常关键的一步。
有人可能就会疑问:难道原始记录拆分的数据都是一个一个汉字进行拆分的吗??然后在词汇表中不就有很多的关键字了???其实,我们在存到原始记录表中的时候,可以指定我们使用哪种算法来将数据拆分,存到词汇表中。
下面是StandardAnalyzer的组装各个工序的方法,我们可以看到,StandardFilter嵌套了StandardTokenizer,LowerCaseFilter嵌套了StandardFilter,StopFilter嵌套了LowerCaseFilter。
protected TokenStreamComponents createComponents(final String fieldName) {
final StandardTokenizer src = new StandardTokenizer();
src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new StandardFilter(src);
tok = new LowerCaseFilter(tok);
tok = new StopFilter(tok, stopwords);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(final Reader reader) {
// So that if maxTokenLength was changed, the change takes
// effect next time tokenStream is called:
src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);
super.setReader(reader);
}
};
}
createComponents 是Analizer中唯一的抽象方法,扩展点。通过提供该方法的实现来实现自己的Analyzer。
而在真正执行stream.incrementToken()的时候,就会按照工序一道一道执行。uml图如下:
4.2.2 源代码
下面通过分析源码对分词的过程进行一个分析:
IndexWriter:
public long updateDocument(Term term, Iterable<? extends IndexableField> doc) throws IOException {
this.ensureOpen();
boolean success = false;
long var6;
try {
//
long seqNo = this.docWriter.updateDocument(doc, this.analyzer, term);
if (seqNo < 0L) {
seqNo = -seqNo;
this.processEvents(true, false);
}
success = true;
var6 = seqNo;
return var6;
}
DocumentsWriter:
long updateDocument(Iterable<? extends IndexableField> doc, Analyzer analyzer, Term delTerm) throws IOException, AbortingException {
boolean hasEvents = this.preUpdate();
//Lucene会为每个文档创建ThreadState对象,对象持有DocumentWriterPerThread来执行文件的增删改操作;
ThreadState perThread = this.flushControl.obtainAndLock();
DocumentsWriterPerThread flushingDWPT;
long seqNo;
try {
this.ensureOpen();
this.ensureInitialized(perThread);
assert perThread.isInitialized();
DocumentsWriterPerThread dwpt = perThread.dwpt;
int dwptNumDocs = dwpt.getNumDocsInRAM();
try {
//通过DocumentsWriterPerThread更新文档
seqNo = dwpt.updateDocument(doc, analyzer, delTerm);
} catch (AbortingException var20) {
this.flushControl.doOnAbort(perThread);
dwpt.abort();
throw var20;
} finally {
this.numDocsInRAM.addAndGet(dwpt.getNumDocsInRAM() - dwptNumDocs);
}
boolean isUpdate = delTerm != null;
flushingDWPT = this.flushControl.doAfterDocument(perThread, isUpdate);
assert seqNo > perThread.lastSeqNo : "seqNo=" + seqNo + " lastSeqNo=" + perThread.lastSeqNo;
perThread.lastSeqNo = seqNo;
} finally {
this.perThreadPool.release(perThread);
}
if (this.postUpdate(flushingDWPT, hasEvents)) {
seqNo = -seqNo;
}
return seqNo;
}
DocumentsWriterPerThread:
public long updateDocument(Iterable<? extends IndexableField> doc, Analyzer analyzer, Term delTerm) throws IOException, AbortingException {
this.testPoint("DocumentsWriterPerThread addDocument start");
assert this.deleteQueue != null;
this.reserveOneDoc();
//文档内容传给了docState
this.docState.doc = doc;
this.docState.analyzer = analyzer;
this.docState.docID = this.numDocsInRAM;
boolean success = false;
try {
try {
//这里是调用的DefaultIndexingChain对文档进行处理
this.consumer.processDocument();
} finally {
//
this.docState.clear();
}
success = true;
} finally {
if (!success) {
this.deleteDocID(this.docState.docID);
++this.numDocsInRAM;
}
}
return this.finishDocument(delTerm);
}
DefaultIndexingChain:
public void processDocument() throws IOException, AbortingException {
int fieldCount = 0;
long fieldGen = (long)(this.nextFieldGen++);
this.termsHash.startDocument();
this.startStoredFields(this.docState.docID);
boolean aborting = false;
boolean var12 = false;
try {
var12 = true;
Iterator var5 = this.docState.doc.iterator();
while(true) {
if (!var5.hasNext()) {
var12 = false;
break;
}
IndexableField field = (IndexableField)var5.next();
//对文档中每个field进行处理
fieldCount = this.processField(field, fieldGen, fieldCount);
}
} catch (AbortingException var14) {
aborting = true;
throw var14;
} finally {
if (var12) {
if (!aborting) {
for(int i = 0; i < fieldCount; ++i) {
this.fields[i].finish();
}
this.finishStoredFields();
}
}
}
if (!aborting) {
for(int i = 0; i < fieldCount; ++i) {
this.fields[i].finish();
}
this.finishStoredFields();
}
try {
this.termsHash.finishDocument();
} catch (Throwable var13) {
throw AbortingException.wrap(var13);
}
}
private int processField(IndexableField field, long fieldGen, int fieldCount) throws IOException, AbortingException {
String fieldName = field.name();
IndexableFieldType fieldType = field.fieldType();
DefaultIndexingChain.PerField fp = null;
if (fieldType.indexOptions() == null) {
throw new NullPointerException("IndexOptions must not be null (field: \"" + field.name() + "\")");
} else {
if (fieldType.indexOptions() != IndexOptions.NONE) {
fp = this.getOrAddField(fieldName, fieldType, true);
//创建倒排索引
boolean first = fp.fieldGen != fieldGen;
fp.invert(field, first);
if (first) {
this.fields[fieldCount++] = fp;
fp.fieldGen = fieldGen;
}
} else {
verifyUnIndexedFieldType(fieldName, fieldType);
}
if (fieldType.stored()) {
if (fp == null) {
fp = this.getOrAddField(fieldName, fieldType, false);
}
if (fieldType.stored()) {
String value = field.stringValue();
if (value != null && value.length() > IndexWriter.MAX_STORED_STRING_LENGTH) {
throw new IllegalArgumentException("stored field \"" + field.name() + "\" is too large (" + value.length() + " characters) to store");
}
try {
this.storedFieldsConsumer.writeField(fp.fieldInfo, field);
} catch (Throwable var10) {
throw AbortingException.wrap(var10);
}
}
}
DocValuesType dvType = fieldType.docValuesType();
if (dvType == null) {
throw new NullPointerException("docValuesType must not be null (field: \"" + fieldName + "\")");
} else {
if (dvType != DocValuesType.NONE) {
if (fp == null) {
fp = this.getOrAddField(fieldName, fieldType, false);
}
this.indexDocValue(fp, dvType, field);
}
if (fieldType.pointDimensionCount() != 0) {
if (fp == null) {
fp = this.getOrAddField(fieldName, fieldType, false);
}
this.indexPoint(fp, field);
}
return fieldCount;
}
}
}
PerField:
//此方法的主要逻辑就是,先基于分词器对Field的值进行分词处理,得到一个个的Term对象,在对Term建立一个倒排表,倒排表中存放的主要信息就是Term的长度、字节值、所在文档ID、词频、在文档中的偏移量等信息。
public void invert(IndexableField field, boolean first) throws IOException, AbortingException {
if (first) {
this.invertState.reset();
}
IndexableFieldType fieldType = field.fieldType();
IndexOptions indexOptions = fieldType.indexOptions();
this.fieldInfo.setIndexOptions(indexOptions);
if (fieldType.omitNorms()) {
this.fieldInfo.setOmitsNorms();
}
boolean analyzed = fieldType.tokenized() && DefaultIndexingChain.this.docState.analyzer != null;
boolean succeededInProcessingField = false;
try {
//基于分词器获取分词后的字节流,称之为token流,Analyzer就是在这里进行的组装
//所谓TokenStream,后面我们会讲到,是一个由[分词]后的Token结果组成的流,能够不断的得到下一个分成的Token。
TokenStream stream = this.tokenStream = field.tokenStream(DefaultIndexingChain.this.docState.analyzer, this.tokenStream);
Throwable var8 = null;
try {
stream.reset();
// 把stream给到inverState
this.invertState.setAttributeSource(stream);
this.termsHashPerField.start(field, first);
//对每一个分词,都执行一遍相同的逻辑
while(true) {
//获取下一个词汇单元,这里是真正执行Analyzer工序的过程
if (stream.incrementToken()) {
//invertState用于记录该域中词汇单元的数量以及位置信息
//invertState.posIncrAttribute 是指前后词汇单元位置的增量,一般为1,说明前后两个词汇单元中间没有空位。如果大于1,说明前后两个词汇单元中间存在空位,这可能是分析器将停词删除后留下的空位。如果如果等于0,有可能是存在同义词的情况了。这时候记录词汇覆盖数的invertState.numOverlap就会加1。invertState.length用于记录词汇数量。
int posIncr = this.invertState.posIncrAttribute.getPositionIncrement();
this.invertState.position += posIncr;
if (this.invertState.position < this.invertState.lastPosition) {
if (posIncr == 0) {
throw new IllegalArgumentException("first position increment must be > 0 (got 0) for field '" + field.name() + "'");
}
if (posIncr < 0) {
throw new IllegalArgumentException("position increment must be >= 0 (got " + posIncr + ") for field '" + field.name() + "'");
}
throw new IllegalArgumentException("position overflowed Integer.MAX_VALUE (got posIncr=" + posIncr + " lastPosition=" + this.invertState.lastPosition + " position=" + this.invertState.position + ") for field '" + field.name() + "'");
}
if (this.invertState.position > 2147483519) {
throw new IllegalArgumentException("position " + this.invertState.position + " is too large for field '" + field.name() + "': max allowed position is " + 2147483519);
}
this.invertState.lastPosition = this.invertState.position;
if (posIncr == 0) {
++this.invertState.numOverlap;
}
int startOffset = this.invertState.offset + this.invertState.offsetAttribute.startOffset();
int endOffset = this.invertState.offset + this.invertState.offsetAttribute.endOffset();
if (startOffset >= this.invertState.lastStartOffset && endOffset >= startOffset) {
this.invertState.lastStartOffset = startOffset;
try {
this.invertState.length = Math.addExact(this.invertState.length, this.invertState.termFreqAttribute.getTermFrequency());
} catch (ArithmeticException var36) {
throw new IllegalArgumentException("too many tokens for field \"" + field.name() + "\"");
}
try {
//具体的倒排索引建立工作,在这里执行
this.termsHashPerField.add();
continue;
} catch (MaxBytesLengthExceededException var37) {
byte[] prefix = new byte[30];
BytesRef bigTerm = this.invertState.termAttribute.getBytesRef();
System.arraycopy(bigTerm.bytes, bigTerm.offset, prefix, 0, 30);
String msg = "Document contains at least one immense term in field=\"" + this.fieldInfo.name + "\" (whose UTF8 encoding is longer than the max length " + 32766 + "), all of which were skipped. Please correct the analyzer to not produce such terms. The prefix of the first immense term is: '" + Arrays.toString(prefix) + "...', original message: " + var37.getMessage();
if (DefaultIndexingChain.this.docState.infoStream.isEnabled("IW")) {
DefaultIndexingChain.this.docState.infoStream.message("IW", "ERROR: " + msg);
}
throw new IllegalArgumentException(msg, var37);
} catch (Throwable var38) {
throw AbortingException.wrap(var38);
}
}
throw new IllegalArgumentException("startOffset must be non-negative, and endOffset must be >= startOffset, and offsets must not go backwards startOffset=" + startOffset + ",endOffset=" + endOffset + ",lastStartOffset=" + this.invertState.lastStartOffset + " for field '" + field.name() + "'");
}
stream.end();
this.invertState.position += this.invertState.posIncrAttribute.getPositionIncrement();
this.invertState.offset += this.invertState.offsetAttribute.endOffset();
succeededInProcessingField = true;
break;
}
} catch (Throwable var39) {
var8 = var39;
throw var39;
} finally {
if (stream != null) {
if (var8 != null) {
try {
stream.close();
} catch (Throwable var35) {
var8.addSuppressed(var35);
}
} else {
stream.close();
}
}
}
} finally {
if (!succeededInProcessingField && DefaultIndexingChain.this.docState.infoStream.isEnabled("DW")) {
DefaultIndexingChain.this.docState.infoStream.message("DW", "An exception was thrown while processing field " + this.fieldInfo.name);
}
}
if (analyzed) {
this.invertState.position += DefaultIndexingChain.this.docState.analyzer.getPositionIncrementGap(this.fieldInfo.name);
this.invertState.offset += DefaultIndexingChain.this.docState.analyzer.getOffsetGap(this.fieldInfo.name);
}
}
StandardTokenizer:
public final boolean incrementToken() throws IOException {
//清楚所有的attribute
clearAttributes();
skippedPositions = 0;
while(true) {
//获得匹配的表达式
int tokenType = scanner.getNextToken();
//是否打到文件末尾
if (tokenType == StandardTokenizerImpl.YYEOF) {
return false;
}
//当前匹配的单次长达不大于最大长度
if (scanner.yylength() <= maxTokenLength) {
//获得当前匹配的单词的位置,并保存再PositionIncrementAttribute类型变量postIncrAtt中
posIncrAtt.setPositionIncrement(skippedPositions+1);
//获得当前单词放在TermAttribute类型变量termAtt中
scanner.getText(termAtt);
//获得当前token的开始offset和结束出offset
final int start = scanner.yychar();
//将当前token开始和结束处的偏移量存在OffsetAttribute型变量offsetAtt中
offsetAtt.setOffset(correctOffset(start), correctOffset(start+termAtt.length()));
typeAtt.setType(StandardTokenizer.TOKEN_TYPES[tokenType]);
return true;
} else
// When we skip a too-long term, we still increment the
// position increment
skippedPositions++;
}
}
Analyzer:
public final TokenStream tokenStream(final String fieldName, final String text) { //text是field域信息
TokenStreamComponents components = reuseStrategy.getReusableComponents(this, fieldName);
@SuppressWarnings("resource") final ReusableStringReader strReader =
(components == null || components.reusableStringReader == null) ?
new ReusableStringReader() : components.reusableStringReader;
strReader.setValue(text); //存在了这里
final Reader r = initReader(fieldName, strReader);
if (components == null) {
//返回的components是StandardAnalyzer
components = createComponents(fieldName);
reuseStrategy.setReusableComponents(this, fieldName, components);
}
//要看一下field域的内容是怎么传入scanner
components.setReader(r);
components.reusableStringReader = strReader;
return components.getTokenStream();
}
StandardAnalyzer:
protected TokenStreamComponents createComponents(final String fieldName) {
//这个函数会组装过滤器,一个套一个
final StandardTokenizer src = new StandardTokenizer();
src.setMaxTokenLength(maxTokenLength);
TokenStream tok = new StandardFilter(src);
tok = new LowerCaseFilter(tok);
tok = new StopFilter(tok, stopwords);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(final Reader reader) {
// So that if maxTokenLength was changed, the change takes
// effect next time tokenStream is called:
//当调这个函数的时候,就会把reader对象赋值给Tokenizer(父类)的inputPending
src.setMaxTokenLength(StandardAnalyzer.this.maxTokenLength);
super.setReader(reader);
}
};
}
4.3 建索引的过程
4.3.1 原理
大家或多或少都听说过倒排索引,倒排索引的过程其实就是对文档进行分词,然后记录分词与文档的关系,在检索的过程就是看检索词中包含哪些词,Lucene中成为Term,然后再通过Term和文档的关联关系,找到对应的文档,从而起到了快速检索的目的,存储这些关联关系的数据结构在Lucene中被称为Posting。Posting的结构:左边是Terms列表,记录Field中出现的所有的Terms,也是叫TermsDictionary;右边是Postings,记录Term所对应的所出现哪些文档的文档号,出现次数,位置信息等。示意图如下:
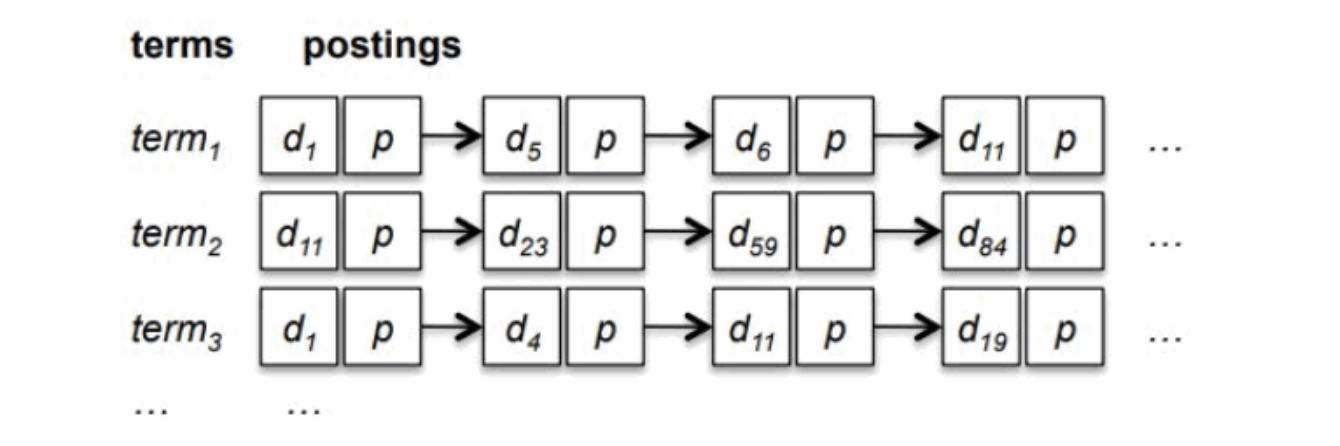
这是一种理想的模型,也就是假如文档d1中包含term1,那么在构建索引的时候就会将d1放在term1对应的postings中,当通过term1进行索引的时候,就可以去term1对应的postings中获取对应的文档。
Lucene构建postings的过程:在实时索引时,Postings先在内存中临时构建。Field被分词后变成一系列Terms的集合,而后遍历这个Terms的集合,为每个Term分配一个ID,叫TermID。Lucene用一个类HashMap的数据结构来存储Term与TermID的映射关系,同时实现去重的目的。分配完TermID之后,后续就可以使用TermID来表示Term。
Lucene有几个对象ByteBlockPool、ByteRefHash、PostingsArray,那么posting数据是存在哪里呢?从名字上看,大家可能会以为是存在PostingsArray,其实不是的,真正存储的地方是ByteBlockPool。
PostingsArray用多个int[]存储Term的各种信息,一个int[]存放TermID的一种信息。Lucene为了能够直接使用基本数据类型(基本类型有两大好处:减少内存开销和提升性能),所以有才了PostingsArrays结构。
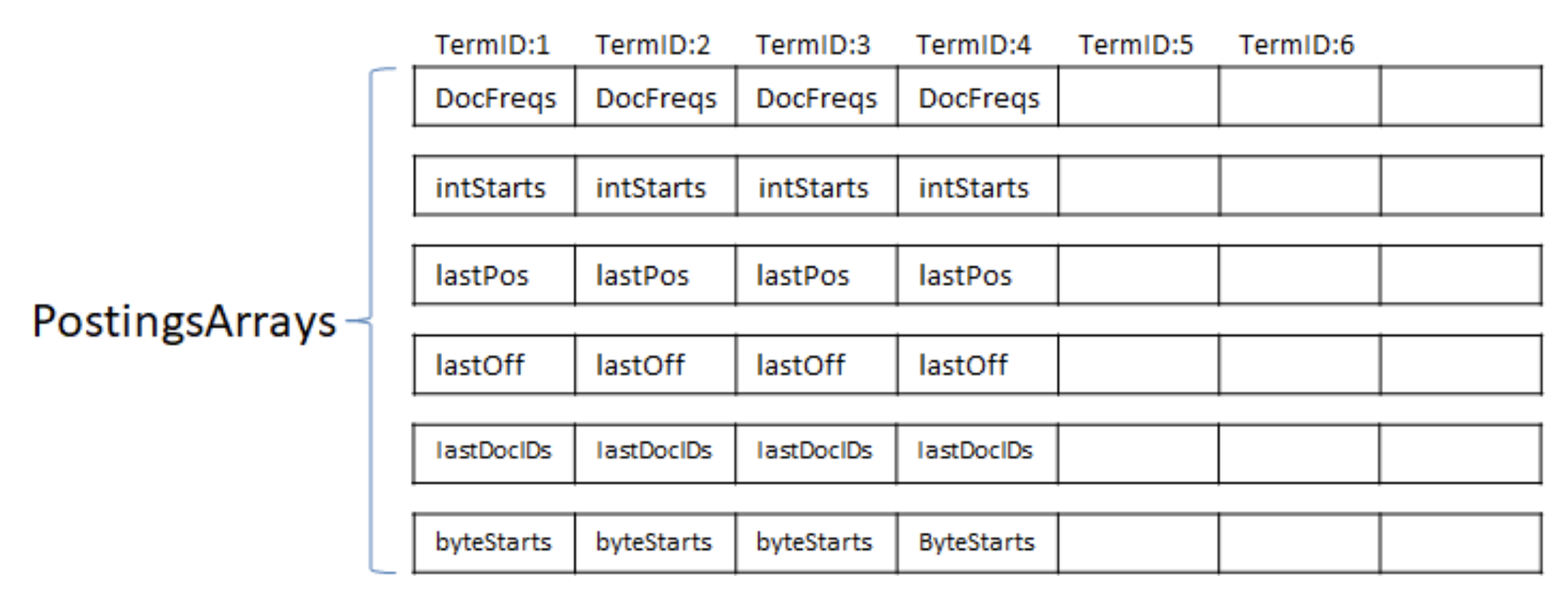
PostingsArrays这个结构只保留每个TermID最后出现的情况,对于TermID每次出现的具体信息则需要存在其它的结构之中。它们就是IntBlockPool&ByteBlockPool。Postings的数据实际只存储在BytesBlockPool(byte[])一个地方,IntBlockPool(int[])中存储的是索引。为什么需要postingsArrays? 因为写到byte[]的只是增量,那么就需要找到上次的Term出现情况才能计算。如果总是在byte[]上查找则显得过重,因为Postings存储在byte[]时,它的结构是一个单向链表。有了PostingsArrays中记录的上条信息,则便于计算增量。
在Postings构建过程中,会在PostingsArrays存储上个文档的DocID和TermFreq,还有Term上次出现的位置和位移信息。就是说,Lucene用多个int[]存储Term的各种信息,一个int[]存放TermID的一种信息。
Postings在byte[]存储的结构是一个表尾增加的链表结构,在构建索引的时候用IntBlockPool来记录Term下一次要写的位置。也就是说,PostingsArrays的intStarts[]是Term的byte[]的表尾,而表头是记录在PostingsArrays的byteStart上,这也是一个int数组*,记录每个Term的在BytesBlockPool的起始位置。*有了表头和表尾之后,我们就可以从ByteBlockPool里拿到整个链表了。
下面针对PostingsArrays中各个数组进行解释:
- int textStart; //此词在 ByteBlockPool 中的偏移量,由此可以知道是哪个词。
- int intStart; //此词在 IntBlockPool 中的偏移量,在指向的位置有两个 int,一个是 docid + freq信息的偏移量,一个是 prox 信息的偏移量。
- int byteStart; //此词的slice在 ByteBlockPool 中的起始偏移量
- int docFreq; // 此词在此文档中出现的次数
- int lastDocID; // 上次处理完的包含此词的文档号。
- int lastDocCode; // 文档号和词频按照或然跟随原则形成的编码
- int lastPosition; // 上次处理完的此词的位置
我们上面讲了postingArray、intBlockPool以及byteBlockPool的关系。并且知道了byteBlockPool会存储term文本、docId、词频以及位置等信息。由于ByteBlockPool为了优化存储空间,底层是采用数组存储的,但是了解java基础的都知道,数组是不可变长的,若要扩展容量,则需要重新new一个数组然后将原来数组中的数据拷贝到新数组中。但是这样的话,就会极大的降低存储的效率,为此Lucene自己设计的高效的可变长的基本类型数组。在ByteBlockPool中,其实是通过二维数组实现的,从而可以高效的扩展容量。如下图所示

左侧的数字则代表了每一个Buffer在这个二维数组中的Index位置。Buffer的长度是固定的,当一个Buffer被写满以后,需要申请一个新的Buffer,如果这个Buffer数组要扩展,仅仅是将已有Buffer的引用拷贝了一次,而不需要拷贝数据本身。
索引构建过程需要为每个Term分配一块相对独立的空间来存储Posting信息,posting中包含term文本、关联的docId、词频、位置等信息。由于一个Term可能会出现在几个文档中,而且在每个文档出现的次数和位置都无法确定,所以Lucene无法预知Term需要多大的数组来存储Posting信息。为此Lucene在ByteBlockPool之上设计了可变长的逻辑结构,这结构就是Slice链表。它的节点称之为Slice,Lucene将Slice分成十个级别,逐层递增,十层之后长度恒定。Slice的最后几个位置用于存储下个节点Offset。
为什么byteStart和intStart需要先指向IntBlockPool呢? 主要是因为TermID可能对应了两条Slice链表,以TermID为索引的数组不方便存储。通过IntBlockPool可以方便处理,仅需要IntBlockPool连续两个位置,IntBlockPool的职责就是用来记录ByteBlockPool中slice在buffer中的位置序号。每一个token都会有两种信息同时存储在ByteBlockPool的slice中。也就是说每一次ByteBlockPool都会同时分配两个相同大小的slice,一个用来存储docID+词频;另一个用来存储位置信息。而这两个块的初始位置序号都会同时记录在IntBlockPool中的。
postingsArray是一个二维数组,每一行是一个term,textstart记录了这个term的值在bytepool中的偏移量,bytestart是开始地址,intstart是在intpool中的偏移量。intpool和byte是所有field共享的,postingsArray是每个field独有的,所以真正写入段的信息是通过bytepool和intpool,这一点很重要,所以操作这两个空间一定是串行的。而lucene的执行流程也保证了这一点。
从上图中的例子,我们来解释一下postingArray和intBlockPoll和byteBlockPool的关系:textStarts,它主要作用是指示term文本内容的位置,这样,每个term都能根据textStarts迅速定位到term文本。
索引构建过程中,termA,termC,termC在文档中出现的顺序可能是交替的。当再次遇到termA的时候,有二种情况:或者当前termA关联的slice元素有足够空间可以存储新的信息;或者关联的slice元素没有足够空间,此时申请一个新的slice链表元素(不连续的空间)来存储termA的posting信息,与此同时,需要将前一个termA的slice链表元素与新申请创建的termA的slice链表元素通过next连接起来。
4.3.2 案例
下面通过实例的例子,以图示的形式给大家解释一下创建索引的过程。
我们依次处理以下这三个文档:
lucene lucene lucene lucene lucene lucene action
lucene
action
处理第一个文档:
处理第一个Lucene:
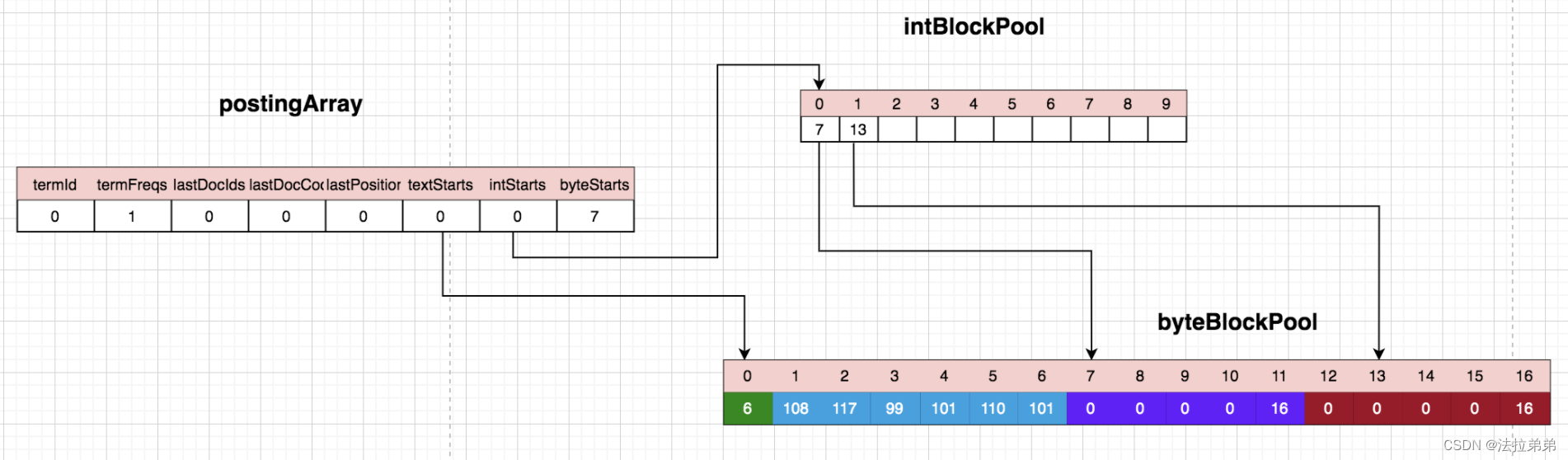
“lucene”作为第一个term,termId为0,termRreqs为1,代表出现了一次,textStarts=0代表term文本在byteBlockPool中从位置0开始,我们跟着看byteBlockPool的位置0,该位置的数值为6,代表‘lucene’这个term的长度是6,存储于接下来的6个字节里—1~6。intStarts=0,我们看intBlockPool的位置0,该位置是7,代表该term的docId+freqs的结尾,由于一个文档处理完成之后才能知道该文档中该term出现的次数,所以目前并没有真正把docId和reqs写入byteBlockPool,而是在postingArray中存储的。位置1是13,代表term的下一个存储position的位置,所以byteBlockPool的位置12显示的0,其实含义是该term在文档中的位置是0。
处理第二个lucene:
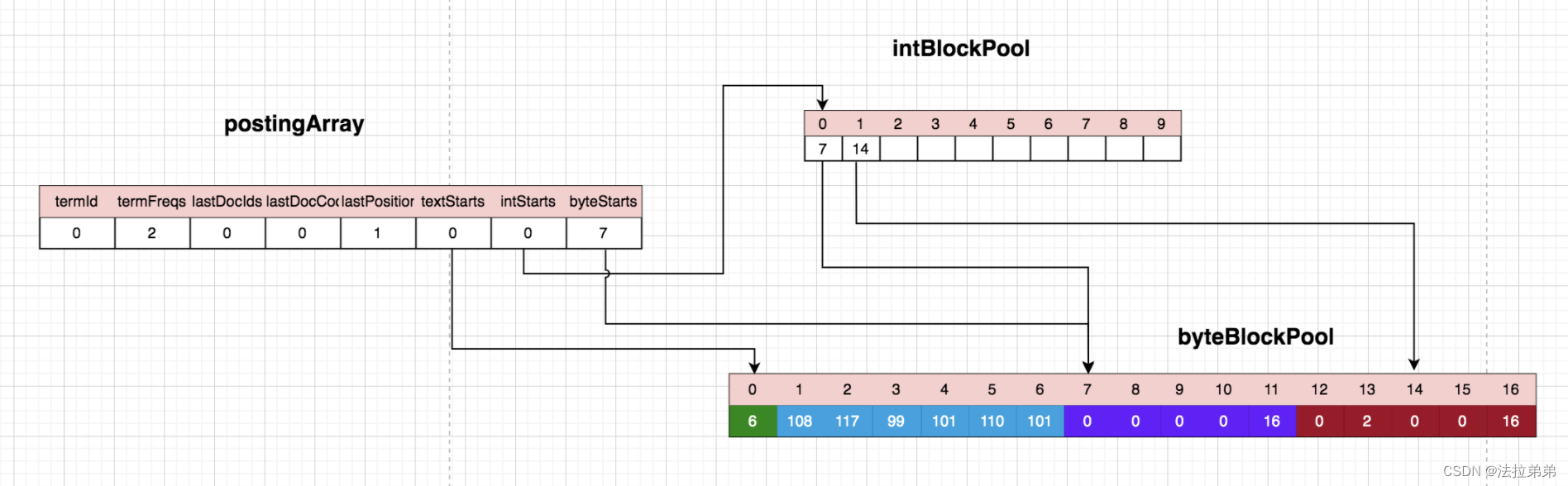
第二个单词还是‘lucene’,所以term还是0,termFreqs=2代表出现了2次,intBlockPool中位置1的数值已经由原来的13变成了14,所以byteBlockPool的位置13代表的是第二个‘lucene’在文档中的位置,这里存储的是偏移量,也就是第二个‘lucene’与第一个‘luecene’的位置的差值,这样存储是为了优化存储空间。
处理第三个lucene:
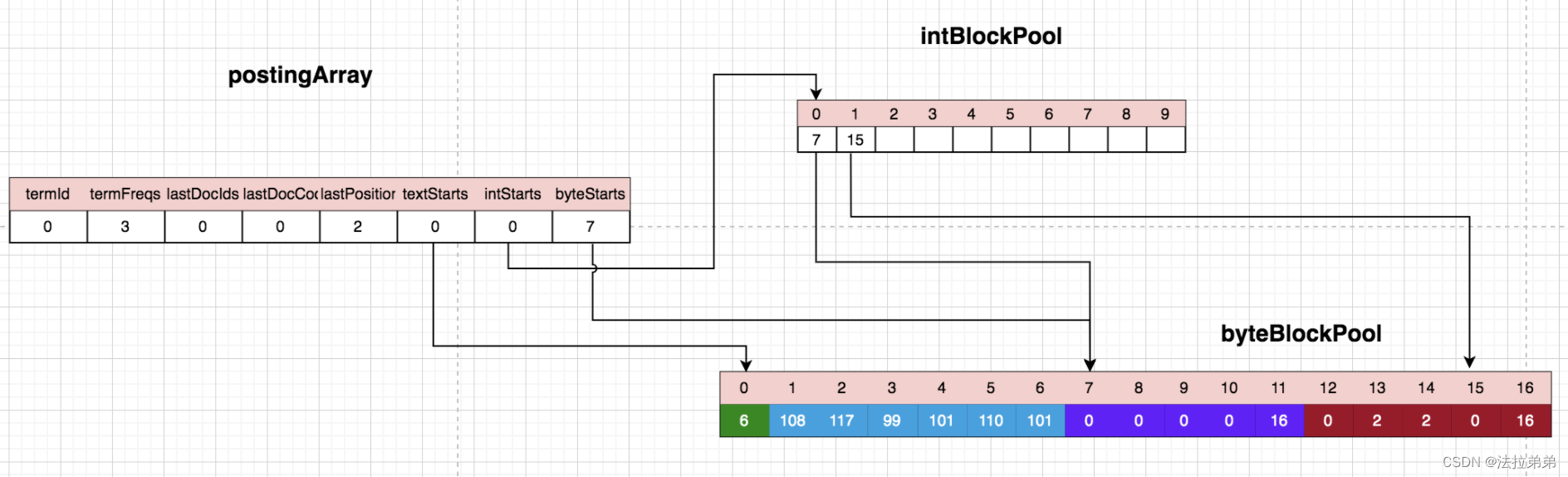
byteBlockPool中位置14被填充了2,同样是第三个lucene和第二个lucene的位置的差值。
处理第四个lucene:
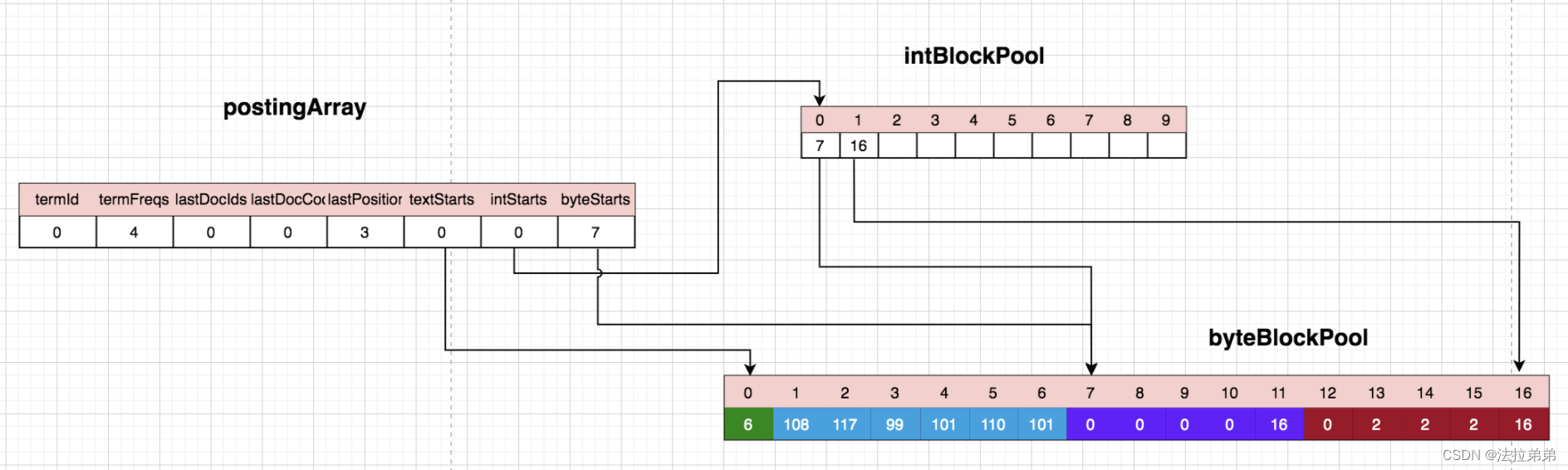
byteBlockPool中位置15被填充了2。
处理第五个lucene:
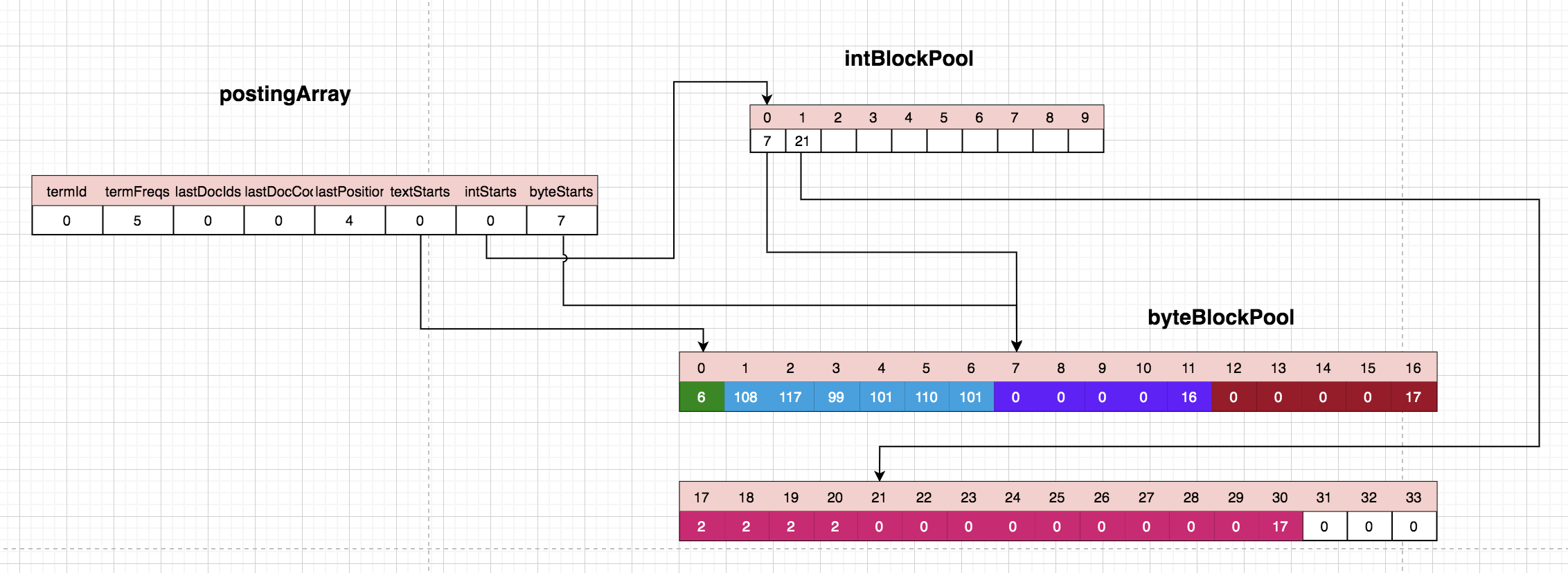
当存储第五个‘lucene’的时候,发现被分配的存储position的slice节点已经用完了(第一层slice的结束标志是16),所以需要扩充一个slice节点。
这里要先解释为什么我们目前遇到的slice节点5个字节,结束位置是16. 请看ByteBlockPool代码,每次空间不够时,会按照固定好的数组来分配空间。每次分配时按照层级,一共有9层,NEXT_LEVEL_ARRAY规定了这点,每层的byte数量在LEVEL_SIZE_ARRAY中规定,比如刚开始是第一层,会分配好5个bytes,(byte) (16|newLevel)便定义了第1层的结束标志为16,第2层(实际上newLevel为1)为17,以此类推……而这个结束标志16不仅表明该块结束,而且还能通过该数字反推出目前的块到底是第几层。
/**
* An array holding the offset into the {@link ByteBlockPool#LEVEL_SIZE_ARRAY}
* to quickly navigate to the next slice level.
*/
public final static int[] NEXT_LEVEL_ARRAY = {1, 2, 3, 4, 5, 6, 7, 8, 9, 9};
/**
* An array holding the level sizes for byte slices.
*/
public final static int[] LEVEL_SIZE_ARRAY = {5, 14, 20, 30, 40, 40, 80, 80, 120, 200};
按照上面的规定,扩展的第二个slice的长度是14。前后两个slice需要关联在一起,即上层的slice需要保存一个指向下一层slice的引用,一般用4个字节保存。所以这一步需要将13-15位置的position数据拷贝到下个slice节点的17-19位置,然后上个slice的13-17四个字节保存了下个slice首地址,及17。这样,存储position的slice就扩充完了,这时可以把第五个‘lucene’的position存储到20位置。
处理第六个lucene:
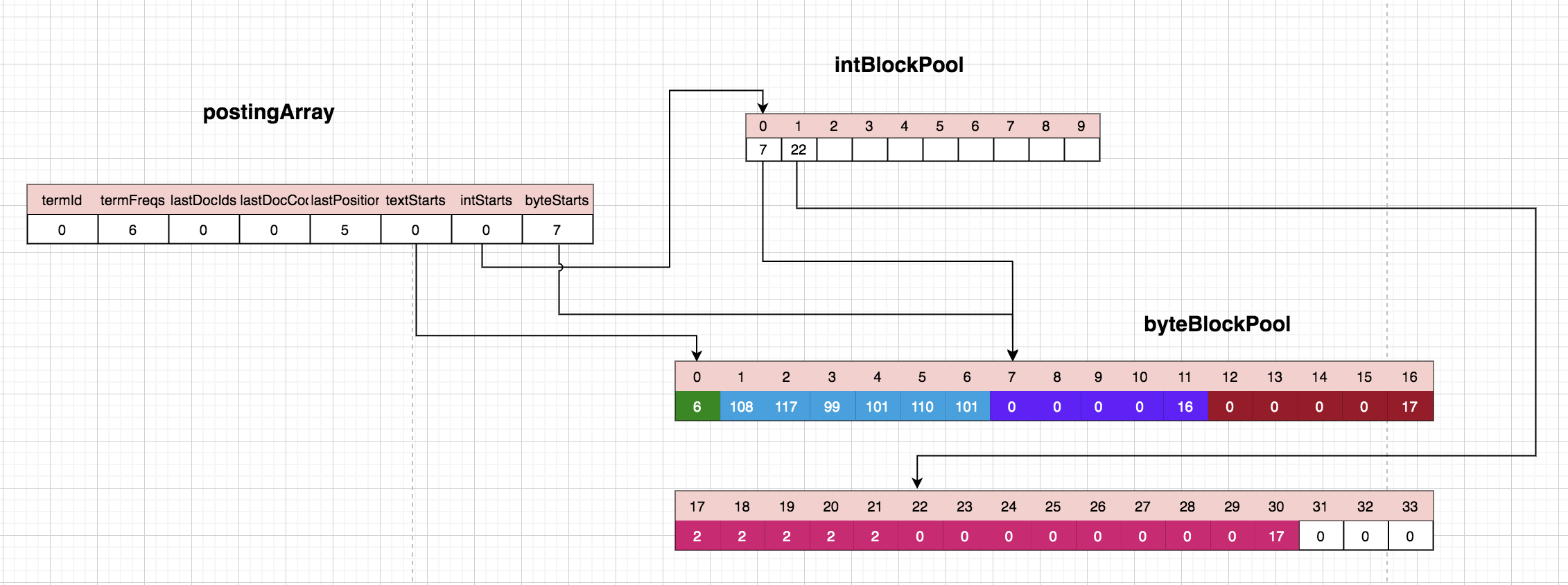
将第六个‘lucene’的position存储在byteBlockPool的位置21。
处理第一个文档的最后一个单次‘action’:
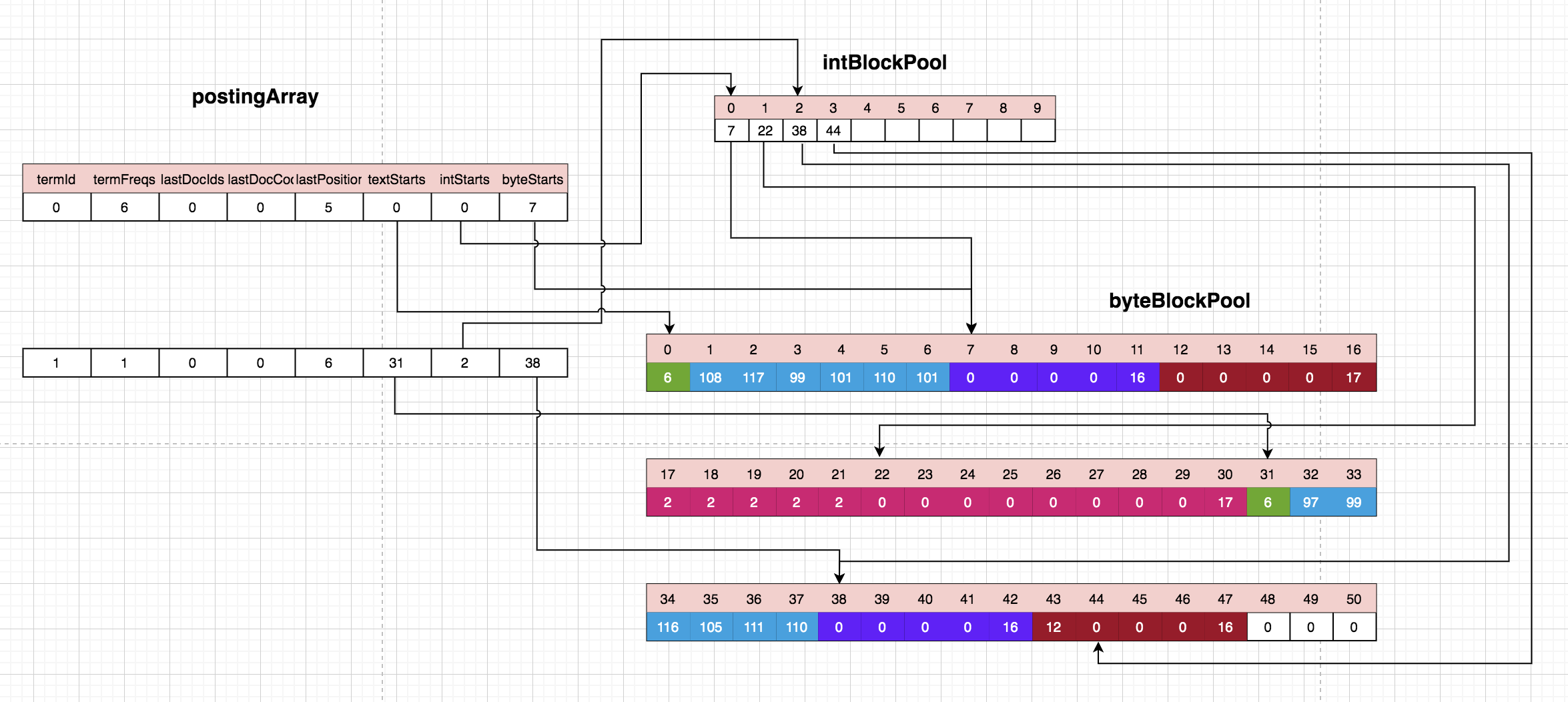
这个单次是前面没有出现过的,所以是一个新的term,被分配的termid是1,对应的termFreq是1,lastPosition是6,textStarts指向了byteblockPool的31的位置,byteBlockPool[31]=6代表action这个单次占后面的6个字节,byteStarts指向了byteBlockPool的38位置,intStarts指向了intBlockPool的位置2,intBlockPool[2]指向了byteBlockPool的位置38,代表docId+freqs的结束位置,intBlockPool[3]指向了byteBlockPool的位置 44,代表下个存储position的位置,前面的位置42存储了12,代表的就是当前这个term在该文档中的位置。(怎么知道是哪个文档的?)
处理第二个文档:
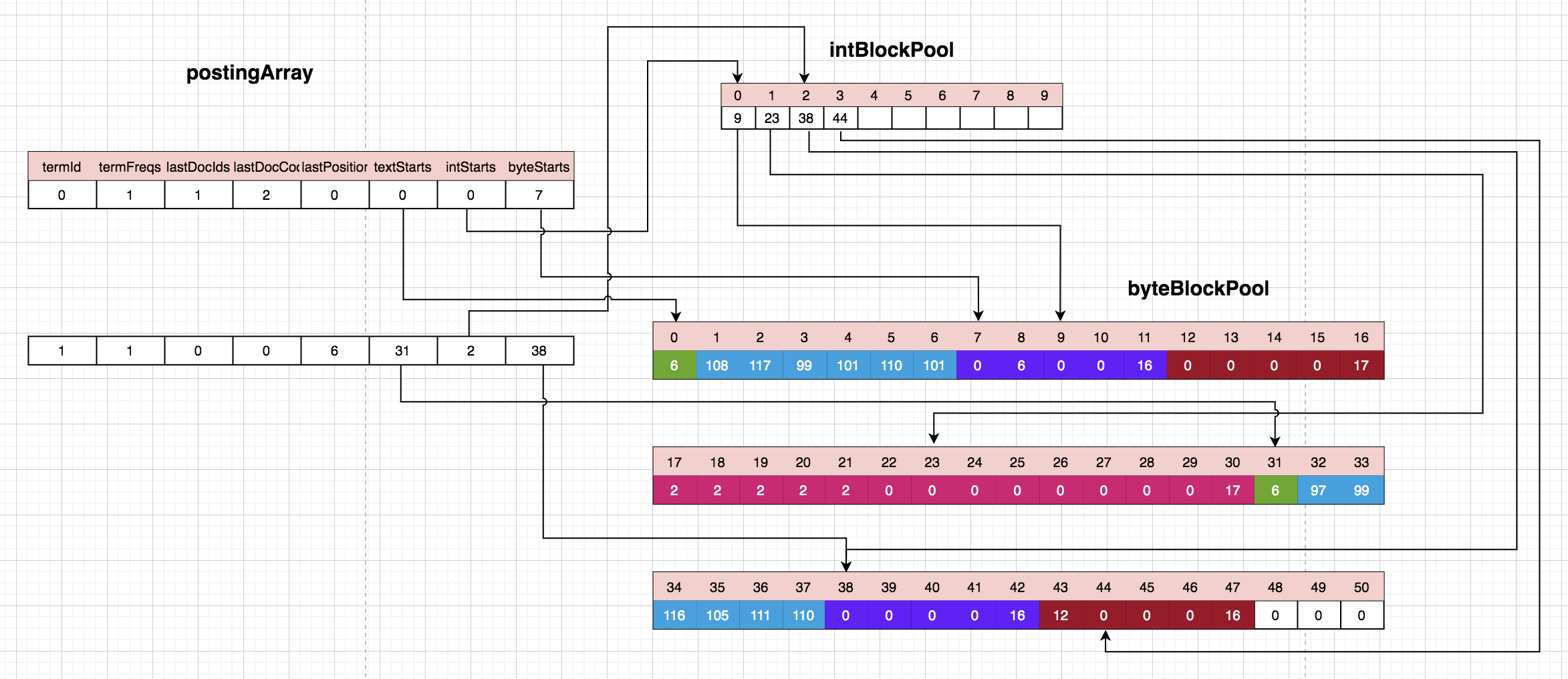
该文档中只有一个单次lucene,发现该单词对应的term已经存在,而且判断了当天处理的文档跟上一次已经不一样了,所以需要将上一次保存在posingArray中的lastDocIds和termFreqs存储在byteBlockPool中,即byteBlockPool[7]存储了上一个文档的docId 0,byteBlockPool[8]存储了‘lucene’单词在上个文档中出现的次数6,同时intBlockPool[0]指向了byteBlockPool[9],作为下一个存储docId和freqs的位置。
处理第三个文档:
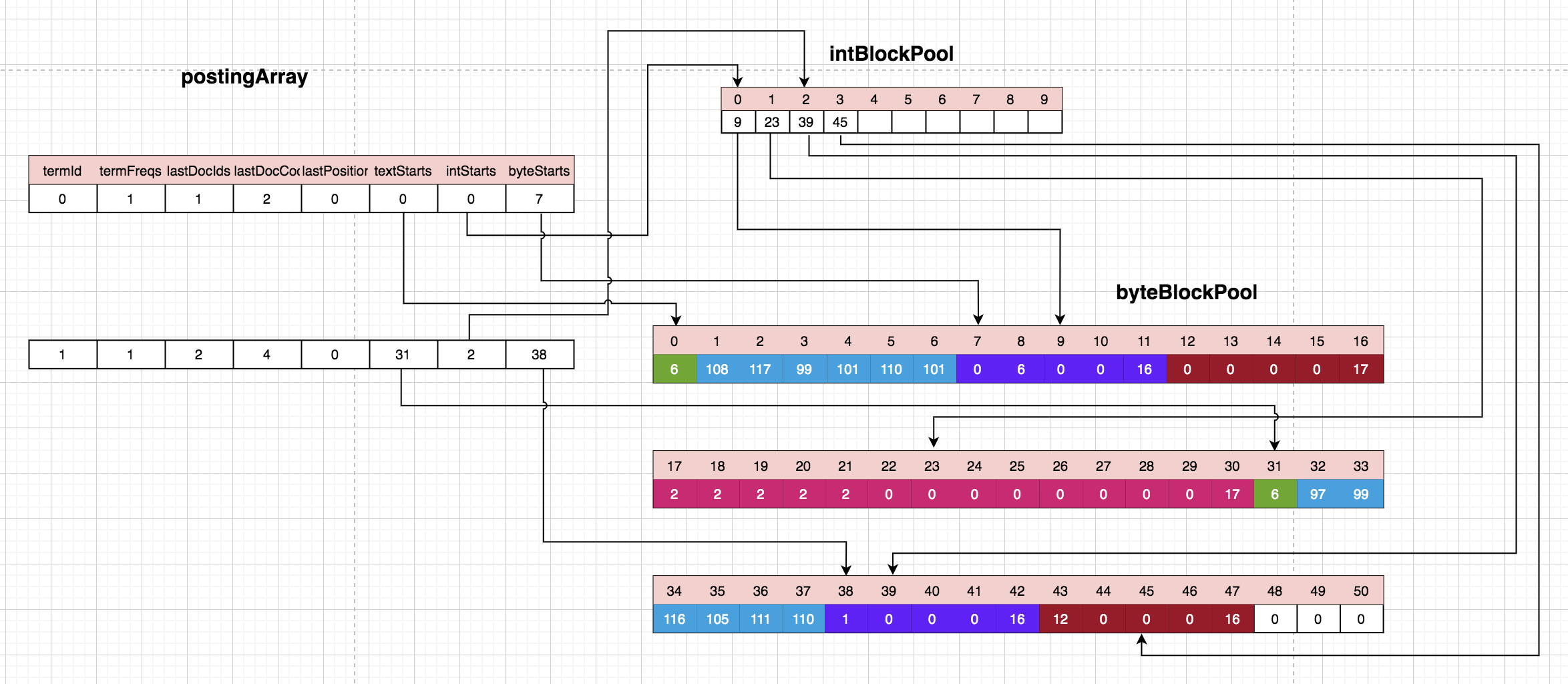
第三个文档只有一个单词’action’,发现也是之前出现过的,并且是跟现在的docId不同,所以需要将上个文档的docId和该term在上个文档出现次数freqs存储下来,由于’action’在上个文档只出现了一次,lucene组价为了减少存储空间,所以只存储了上个文档的docId,并没有存储对应的freqs。
至此,我们通过一个简单的案例对索引的添加过程进行了描述,结合上一节介绍的原理,能够更容易理解lucene对倒排索引的处理过程。
4.3.3 源代码
TermsHashPerField:
void add() throws IOException {
//在BytesRefHash中为term分配一个唯一id,并将term信息写入到缓冲区中、PostingsArray中
int termID = this.bytesHash.add(this.termAtt.getBytesRef());
int i;
if (termID >= 0) {
//之前没有处理过这个term
//判断是否需要开辟一个新空间,初始情况下都是需要的
this.bytesHash.byteStart(termID);
if (this.numPostingInt + this.intPool.intUpto > 8192) {
this.intPool.nextBuffer();
}
if ('耀' - this.bytePool.byteUpto < this.numPostingInt * ByteBlockPool.FIRST_LEVEL_SIZE) {
this.bytePool.nextBuffer();
}
this.intUptos = this.intPool.buffer;
this.intUptoStart = this.intPool.intUpto;
this.intPool.intUpto += this.streamCount;
// 往PostingsArray.intStarts[termID]中存储指针信息,指针指向term信息在iniPool中的存储位置
this.postingsArray.intStarts[termID] = this.intUptoStart + this.intPool.intOffset;
for(i = 0; i < this.streamCount; ++i) {
int upto = this.bytePool.newSlice(ByteBlockPool.FIRST_LEVEL_SIZE);
this.intUptos[this.intUptoStart + i] = upto + this.bytePool.byteOffset;
}
// 往PostingsArray.byteStarts[termID]中存储指针信息,指针指向term信息[term长度,term字节值]在bytePool中的结尾位置
this.postingsArray.byteStarts[termID] = this.intUptos[this.intUptoStart];
// 往intPool缓冲池中写入信息,存指针信息,指针指向的是term信息在bytePool中的存储位置
this.newTerm(termID);
} else {
//下面是之前已经处理过这个term,直接执行addTerm()方法即可
//获取termID
termID = -termID - 1;
//根据termID从PostingsArray找到term的所属信息,从intStarts中获取term在initPool中的起始位置
i = this.postingsArray.intStarts[termID];
//从intPool中获取当前使用的buffer
this.intUptos = this.intPool.buffers[i >> 13];
this.intUptoStart = i & 8191;
//执行addTerm操作
this.addTerm(termID);
}
if (this.doNextCall) {
this.nextPerField.add(this.postingsArray.textStarts[termID]);
}
}
void newTerm(int termID) {
//使用postings引用Filed层面的freqProxPostingsArray对象,每一个Field都拥有一个词对象。
FreqProxTermsWriterPerField.FreqProxPostingsArray postings = this.freqProxPostingsArray;
//记录当前term当前的文档id
postings.lastDocIDs[termID] = this.docState.docID;
//判断是否记录词频
if (!this.hasFreq) {
postings.lastDocCodes[termID] = this.docState.docID;
} else {
postings.lastDocCodes[termID] = this.docState.docID << 1;
//由于term是第一次出现,因此词频为1
postings.termFreqs[termID] = 1;
//判断是否记录term在文档中的位置信息
if (this.hasProx) {
//这里将term的位置信息写入到bytePool中去 (注1)
this.writeProx(termID, this.fieldState.position);
//判断是否记录term的偏移量信息
if (this.hasOffsets) {
this.writeOffsets(termID, this.fieldState.offset);
}
} else {
assert !this.hasOffsets;
}
}
//将词频值1赋予fieldState.maxTermFrequency
this.fieldState.maxTermFrequency = Math.max(1, this.fieldState.maxTermFrequency);
}
void writeProx(int termID, int proxCode) {
//Lucene并不直接存储term的位置信息,而是存储的是位置的差值信息,再<<1操作的值
this.writeVInt(1, proxCode << 1);
}
void writeVInt(int stream, int i) {
this.writeByte(stream, (byte)i);
}
void writeByte(int stream, byte b) {
//term的位置信息应该写入到bytePool中的位置,是由intPool中的有关该term的第二个元素决定的
int upto = this.intUptos[this.intUptoStart + stream];
//指向了bytePool缓冲池中当前使用的buffer
byte[] bytes = this.bytePool.buffers[upto >> 15];
//确定位置信息要写入的位置
int offset = upto & 32767;
//buffer不够的话,先扩容
if (bytes[offset] != 0) {
offset = this.bytePool.allocSlice(bytes, offset);
bytes = this.bytePool.buffer;
this.intUptos[this.intUptoStart + stream] = offset + this.bytePool.byteOffset;
}
//写入
bytes[offset] = b;
//intPool中有关该term的第二个元素值加1
int var10002 = this.intUptos[this.intUptoStart + stream]++;
}
void addTerm(int termID) {
//使用postings引用Filed层面的freqProxPostingsArray对象,每一个Field都拥有一个词对象。
FreqProxTermsWriterPerField.FreqProxPostingsArray postings = this.freqProxPostingsArray;
//是否记录词频
if (!this.hasFreq) {
if (this.docState.docID != postings.lastDocIDs[termID]) {
assert this.docState.docID > postings.lastDocIDs[termID];
this.writeVInt(0, postings.lastDocCodes[termID]);
postings.lastDocCodes[termID] = this.docState.docID - postings.lastDocIDs[termID];
postings.lastDocIDs[termID] = this.docState.docID;
++this.fieldState.uniqueTermCount;
}
} else if (this.docState.docID != postings.lastDocIDs[termID]) {
//记录词频,且当前文档id与term的上一个docID不一致,说明上一个文档已经处理完了
/**
Lucene在倒排索引中并不直接存储文档的docID,而是存储的docCodes
**/
//如果文档中的term词频为1的话,词频信息和docID信息存在一个字节中
if (1 == postings.termFreqs[termID]) {
this.writeVInt(0, postings.lastDocCodes[termID] | 1);
} else {
//如果term的词频不为1的话,使用2个字节存储词频和docID
this.writeVInt(0, postings.lastDocCodes[termID]);
this.writeVInt(0, postings.termFreqs[termID]);
}
//因为又是一个新文档,因此词频重新计数
postings.termFreqs[termID] = 1;
this.fieldState.maxTermFrequency = Math.max(1, this.fieldState.maxTermFrequency);
//docCodes大致可以理解为记录的是docID与上一个docID的差值
postings.lastDocCodes[termID] = this.docState.docID - postings.lastDocIDs[termID] << 1;
postings.lastDocIDs[termID] = this.docState.docID;
if (this.hasProx) {
//继续写入term的位置信息到缓冲区中
this.writeProx(termID, this.fieldState.position);
if (this.hasOffsets) {
postings.lastOffsets[termID] = 0;
this.writeOffsets(termID, this.fieldState.offset);
}
} else {
assert !this.hasOffsets;
}
++this.fieldState.uniqueTermCount;
} else {
//如果还是在处理同一个文档,那么执行此段逻辑
this.fieldState.maxTermFrequency = Math.max(this.fieldState.maxTermFrequency, ++postings.termFreqs[termID]);
if (this.hasProx) {
this.writeProx(termID, this.fieldState.position - postings.lastPositions[termID]);
if (this.hasOffsets) {
this.writeOffsets(termID, this.fieldState.offset);
}
}
}
}
参考:
https://mp.weixin.qq.com/s/LNlKcpshPDiQ3pN3MUCUxw
https://mp.weixin.qq.com/s?__biz=MzI4Njk3NjU1OQ==&mid=2247484038&idx=1&sn=d2f82c389f5a595dfe85ddfe887268b4&chksm=ebd5fdc6dca274d0823ed02214971b939cb100cd5d860f4e063c89bf5199e79b3bedfbba5238&scene=21#wechat_redirect
https://zhuanlan.zhihu.com/p/435938025
https://mp.weixin.qq.com/s/_oT38Ra9QXiDKNjG3r7mAQ
https://blog.csdn.net/lu__peng/article/details/108614943
https://www.bbsmax.com/A/A7zgmv3154/
https://blog.csdn.net/Mr_Tank_/article/details/11114581
https://blog.csdn.net/qq_39652397/article/details/124197188
https://blog.csdn.net/chuanyangwang/article/details/121099476
https://www.jianshu.com/p/ac624e2b148c
https://blog.csdn.net/jj380382856/article/details/52688245
https://blog.csdn.net/liweisnake/article/details/11364597
https://blog.csdn.net/wenbingoon/article/details/8808585
https://blog.csdn.net/uniorg/article/details/6094090
https://mp.weixin.qq.com/s/AmD_-O2u_VAmDZYHs_dvkw
https://www.freesion.com/article/8702448175/
http://blog.chinaunix.net/uid-26148869-id-3535888.html
https://www.jianshu.com/p/083b07fd1dbb
https://www.docin.com/p-660539604.html
https://blog.csdn.net/u011663071/article/details/82316557
https://blog.csdn.net/truelove12358/article/details/105845002/
https://mp.weixin.qq.com/s/LNlKcpshPDiQ3pN3MUCUxw
https://blog.csdn.net/ccnunlp/article/details/83599336
https://zhuanlan.zhihu.com/p/510792702

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)