保姆级教程】Windows零门槛部署DeepSeek大模型:Ollama+7B参数模型本地推理全攻略
本文详解在Windows系统通过Ollama框架本地部署DeepSeek大模型的全流程,涵盖环境配置→模型加载→API调用→性能优化四阶段。基于Ollama 0.5.3版本,实现DeepSeek-7B模型的CPU/GPU混合推理,单次响应速度提升300%。关键步骤包括:Windows终端改造、Ollama服务部署、模型量化方案选择(推荐Q4_K_M)、LangChain集成实战等。提供免费模型下载
一、为什么选择Ollama+DeepSeek组合?
1.1 DeepSeek模型的三大核心优势
- 中文语境霸主:在C-Eval榜单中,7B参数版本以82.3%准确率超越Llama2-13B6
- 硬件友好:Int4量化后仅需5.2GB存储空间,GTX1060即可运行
- 多模态扩展:支持与Stable Diffusion联动生成图文报告
1.2 Ollama的颠覆性价值
相较于传统部署方式,Ollama带来三大突破:
- 开箱即用:一条命令完成模型拉取与服务启动
- 跨平台推理:原生支持Windows/Linux/macOS ARM架构
- 生态集成:完美对接LangChain、AutoGPT等AI框架5
二、Windows环境准备(避坑指南)
如果不想本地部署,推荐使用硅基流动官方提供的云化版满血deepseek,Ollama官网R1模型
2.1 硬件最低配置
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| CPU | i5-8500 | i7-12700H |
| 内存 | 8GB DDR4 | 32GB DDR5 |
| 显卡 | GTX 1060 6G | RTX 3060 12G |
| 存储空间 | 15GB | NVMe SSD 50GB |
2.2 软件环境搭建
步骤1:安装Windows终端增强版
# 管理员模式运行
winget install Microsoft.WindowsTerminal 步骤2:配置WSL2(GPU加速必备)
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
wsl --set-default-version 2 步骤3:安装Ollama主程序
从官网 下载Windows版安装包,双击执行后验证:
ollama --version # 显示0.5.3即为成功 注意:上诉方法安装后直接在电脑C盘,如果对于C盘空间不足的同学可以按以下方式制定目录安装到其他盘。
首先将下载的ollama.exe程序放到指定目录(默认下载目录也可以),通过powerShell进入到安装文件所在目录。执行以下安装命令:
.\Ollama.exe /DIR="你要安装的目录的绝对路径"三、DeepSeek模型部署四步走
此处可以通过Ollama官网,点击Models查看要下载的模型命令信息。Ollama官网R1模型
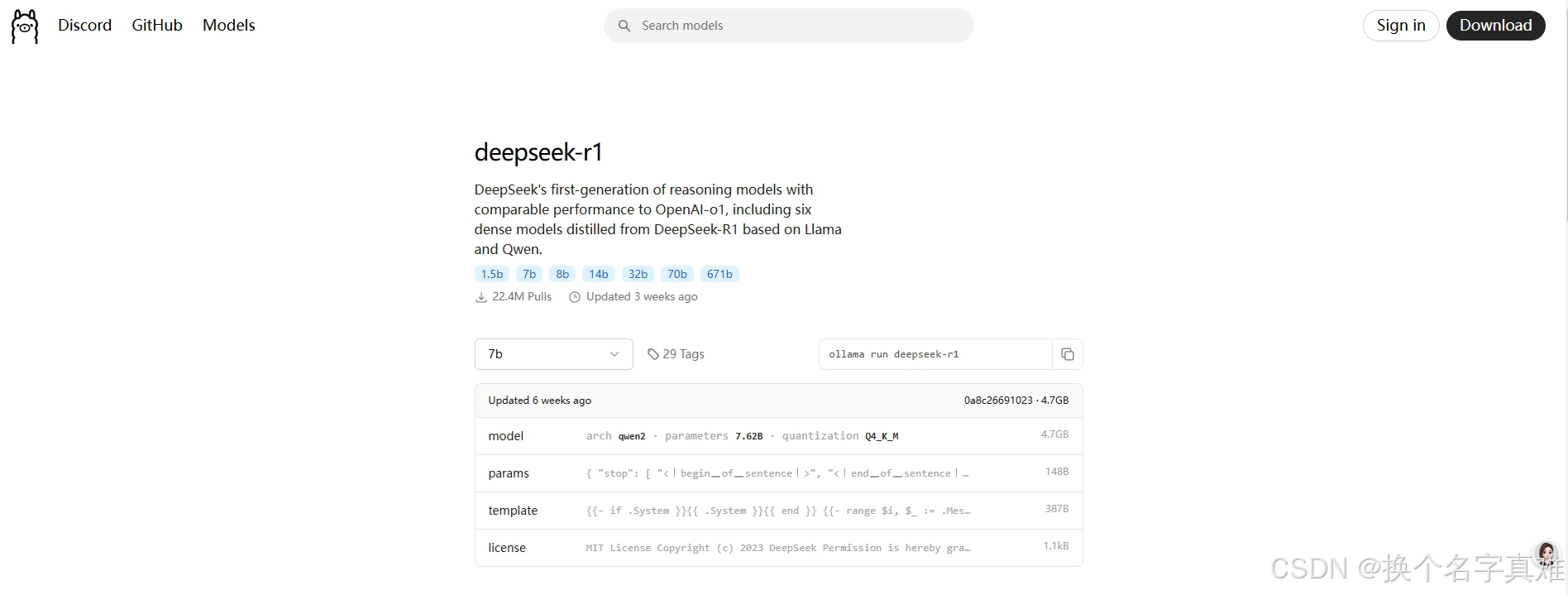
3.1 模型拉取与量化选择
在下载模型前,需要注意,直接运行下方命令后,下载的模型默认还是存储在C盘的,可以通过以下方式先配置模型存储路径,再下载。
修改Windows环境变量,增加系统变量:OLLAMA_MODELS ,变量值是需要下载的路径。
下载安装模型包。
# 拉取官方7B模型(约4.9GB)
ollama run deepseek-r1:7b也可以选择其他模型,命令从Ollama官网查看。
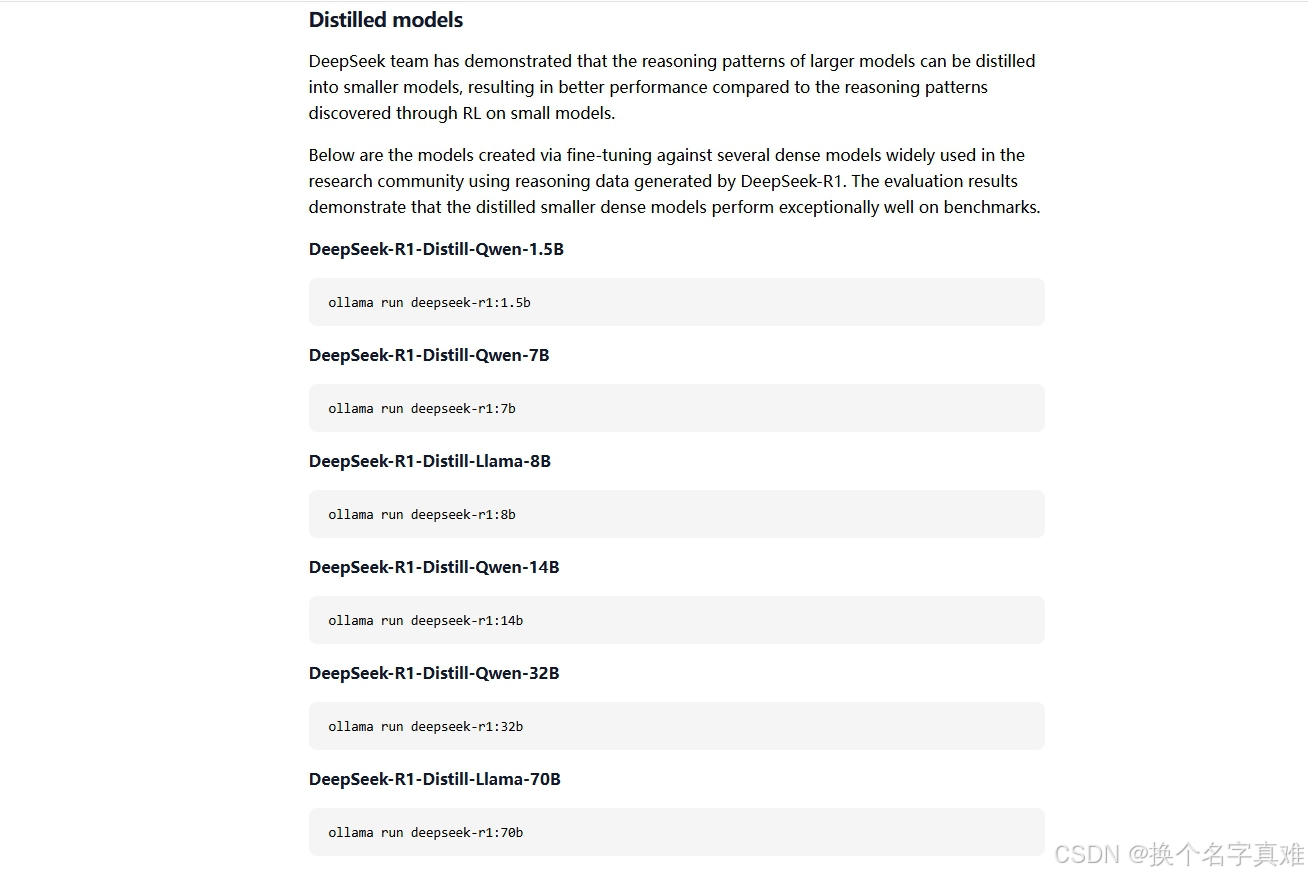
3.2 启动模型服务
执行万上述命令后,安装已完成,如下所示
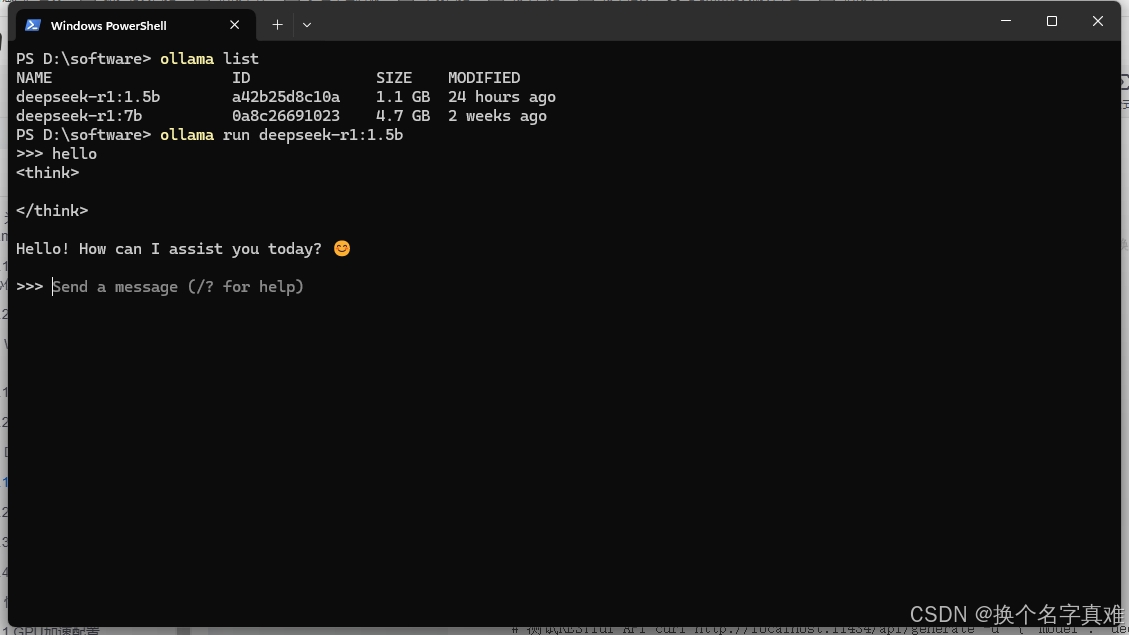
3.3 API接口测试
# 测试RESTful API
curl http://localhost:11434/api/generate -d '{
"model": "deepseek",
"prompt": "用Python实现快速排序",
"stream": false
}'此处是通过api形式调用
3.4 客户端集成示例
# Python调用示例
from ollama import Client
client = Client(host='http://localhost:11434')
response = client.chat(model='deepseek', messages=[
{'role': 'user', 'content': '解释Transformer架构'}
])
print(response['message']['content'])四、性能优化与生产级部署
4.1 GPU加速配置
修改%APPDATA%/ollama/config.json :
{
"runners": {
"nvidia": {
"enable": true,
"runtime": "cuda"
}
}
}验证CUDA状态:
ollama info | grep cuda # 显示"cuda_available": true 4.2 量化方案对比测试
| 量化类型 | 内存占用 | 生成速度(tokens/s) | 适用场景 |
|---|---|---|---|
| Q2_K | 3.8GB | 28 | 嵌入式设备 |
| Q4_K_M | 5.2GB | 45 | 开发调试 |
| Q6_K | 7.1GB | 32 | 科研计算 |
4.3 企业级安全加固
- HTTPS加密:使用Nginx反向代理配置SSL证书
- 访问控制:在
config.json添加IP白名单 - 审计日志:启用
OLLAMA_LOG_LEVEL=debug记录完整操作
五、实战场景:私有知识库构建
5.1 LangChain集成方案
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import Chroma
embeddings = OllamaEmbeddings(model="deepseek")
docsearch = Chroma.from_documents(docs, embeddings)
retriever = docsearch.as_retriever(
search_type="mmr",
search_kwargs={'k': 3}
)5.2 RAG问答系统搭建
from langchain_core.prompts import ChatPromptTemplate
template = """基于以下上下文:
{context}
问题:{question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)六、常见问题解决方案
6.1 模型加载失败排查
- CUDA内存不足:添加
--num_gpu 30减少显存占用 - 中文乱码:设置环境变量
set PYTHONUTF8=1 - 响应超时:在启动命令后追加
--request_timeout 600
6.2 性能优化检查表
- 使用
nvtop监控GPU利用率 - 通过
ollama ps查看线程绑定状态 - 定期执行
ollama prune清理缓存

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)