大模型入门:文本分类任务(基于Bert进行微调)
在上一篇文章中我介绍了如何通过fasttext来对文本进行分类,然而fasttext的训练过程非常短,对算力的需求很低,且对于参数的要求比较模糊,所以可能有朋友对模型的训练与迭代还是没有一个清晰的理解,下面我们换一种方法来对同样的文本进行分类任务,应该能让你对模型训练与微调有更加清晰的理解。
前言
前文:大模型入门:文本分类任务(基于fasttext与jieba)-CSDN博客
在上一篇文章中我介绍了如何通过fasttext来对文本进行分类,然而fasttext的训练过程非常短,对算力的需求很低,且对于参数的要求比较模糊,所以可能有朋友对模型的训练与迭代还是没有一个清晰的理解,下面我们换一种方法来对同样的文本进行分类任务,应该能让你对模型训练与微调有更加清晰的理解。
先来解释一下什么是微调(Finetune),简单来说,微调就是指在一个预训练好的模型上使用一些数据集进行加强训练,使其能够完成特定的任务。预训练模型(Pre-training model)是指别人事先用自己的数据集训练好的,在一些任务上普适性的模型,而微调能够加强这个模型在某一方面的性能,至于是哪一方面就看你用什么数据来进行微调了。就比如我们这篇文章中使用到的数据是分类对酒店评价文本的,那么微调后的模型在分类酒店评价任务上的能力就会大大增强。
与上一篇文章类似,我将从数据收集与预处理,训练模型,模型评估这几步来展开任务。
数据收集与预处理
你可以在上一篇文章中下载需要用到的数据集,没有用到任何爬虫与采集工具,所以我们跳过数据收集的部分来看数据打打预处理。由于我使用的数据处理库是Hugging Face的Dataset库,这个库需要读入csv格式的文件,所以我们要将原始的txt文件中的评论全部整合到一个csv文件中去。转化成如下的格式:
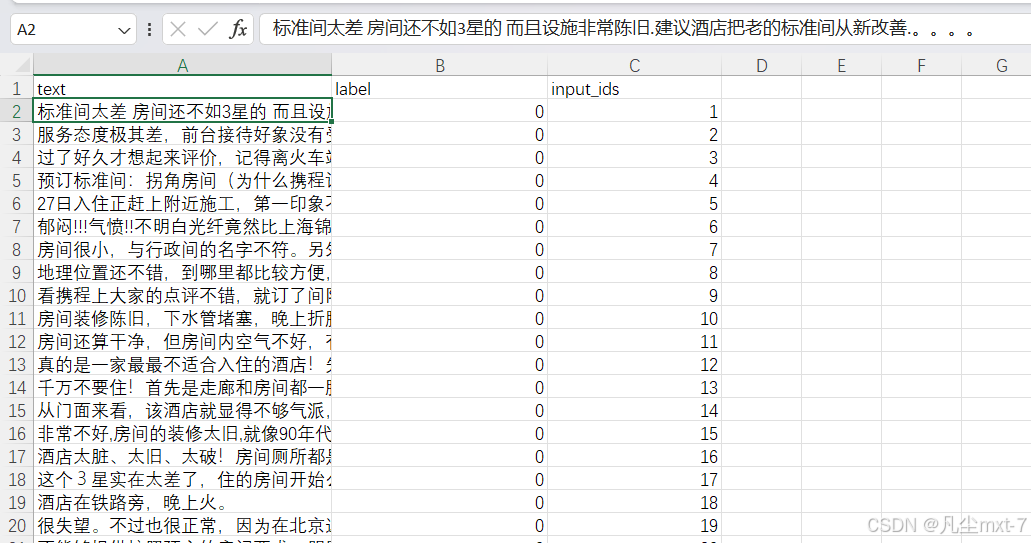
其中text是具体的评论内容,label是情绪标签,1代表正面情绪,0代表负面情绪。input_ids只是对数据进行一个编号,不用太在意。下面是进行数据预处理的python脚本:
import openpyxl
# 参数
excel_save_path1 = "train_data.xlsx" # 训练集路径,python无法像.txt一样自动为您创建.xlsx文件,请先在对应的位置先创建一个空白的文件
excel_save_path2 = "test_data.xlsx" # 测试集路径
test_set_num = 200 # 积极与消极各2000条数据,用几条作为测试集?
file_path = r"C:\Users\凡尘\PycharmProjects\pythonProject\课外\LLM\文本分类\fasttext" # 使用的绝对路径
# 训练集-读取数据
list_neg_train = []
list_pos_train = []
for i in range(0, 2000 - test_set_num):
with open(fr"{file_path}\neg\neg.{i}.txt", "r", encoding="utf-8") as f1:
str_temp = ""
for text in f1.readlines():
str_temp += text.strip() + "。"
if str_temp.strip() not in list_neg_train:
list_neg_train.append(str_temp.strip())
with open(fr"{file_path}\pos\pos.{i}.txt", "r", encoding="utf-8") as f2:
str_temp = ""
for text in f2.readlines():
str_temp += text.strip() + "。"
if str_temp.strip() not in list_pos_train:
list_pos_train.append(str_temp.strip())
print(len(list_neg_train)) # 数据集有重复的部分,我对数据集进行了去重,所以你会发现2000条里面少了几百条
print(len(list_pos_train))
# 训练集-写入数据
workbook = openpyxl.Workbook()
sheet = workbook["Sheet"]
sheet["A1"] = "label" # 制表头
sheet["B1"] = "text"
sheet["C1"] = "input_ids"
for i, v in enumerate(list_neg_train):
sheet[f"A{i + 2}"] = "消极"
sheet[f"B{i + 2}"] = v
sheet[f"C{i + 2}"] = i
for i, v in enumerate(list_pos_train):
sheet[f"A{i + 2 + len(list_neg_train)}"] = "积极"
sheet[f"B{i + 2 + len(list_neg_train)}"] = v
sheet[f"C{i + 2 + len(list_neg_train)}"] = i
workbook.save(excel_save_path1)
workbook.close()
exit()
# 测试集(操作与上面相同)
list_neg_text = []
list_pos_text = []
for i in range(0, test_set_num):
with open(fr"{file_path}\neg\neg.{i + 2000 - test_set_num}.txt", "r", encoding="utf-8") as f1:
str_temp = ""
for text in f1.readlines():
str_temp += text.strip() + "。"
if str_temp.strip() not in list_neg_text:
list_neg_text.append(str_temp.strip())
with open(fr"{file_path}\pos\pos.{i + 2000 - test_set_num}.txt", "r", encoding="utf-8") as f2:
str_temp = ""
for text in f2.readlines():
str_temp += text.strip() + "。"
if str_temp.strip() not in list_pos_text:
list_pos_text.append(str_temp.strip())
workbook2 = openpyxl.Workbook()
sheet2 = workbook2["Sheet"]
sheet2["A1"] = "label" # 制表头
sheet2["B1"] = "text"
sheet2["C1"] = "input_ids"
for i, v in enumerate(list_neg_text):
sheet2[f"A{i + 2}"] = "消极"
sheet2[f"B{i + 2}"] = v
sheet2[f"C{i + 2}"] = i
for i, v in enumerate(list_pos_text):
sheet2[f"A{i + 2 + len(list_neg_text)}"] = "积极"
sheet2[f"B{i + 2 + len(list_neg_text)}"] = v
sheet2[f"C{i + 2}"] = i
workbook2.save(excel_save_path2)
workbook2.close()
运行完后会在对应的目录下生成train_data.xlsx与test_data.xlsx这两个文件,然后你用Excel打开后保存为csv格式就行了。同样的,为了防止你在这一步因为各种各样奇奇怪怪的Bug卡住而无法学习下面的内容,我已经将预处理好的文件上传了,你可以直接下载。
(这时候可能有人要问了,唉博主博主为什么你要用openpyxl这个库呢,它不能直接用存csv文件,不是很麻烦吗?那是因为我当时还只会用这一个库,还没有成为简介中的自己呀~)
模型训练
下面我们使用Dataset库读入csv数据,使用BertTokenizer来作为分词器(上一次我们使用的是jieba),对文本进行分词操作。然后设置好训练参数并开始训练:
from transformers import BertTokenizer, BertForSequenceClassification, Trainer, TrainingArguments
from torch import save # 用于保存模型
from datasets import Dataset
train_dataset = Dataset.from_csv('train_data.csv') # 加载CSV文件为Dataset对象,train_dataset是一个iterator,可以通过for输出
model_name = 'bert-base-chinese' # 加载预训练模型和分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=len(train_dataset.unique('label')))
# train_dataset.unique('label') = [0, 1]
def tokenize_function(examples): # 分词操作
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
train_dataset = train_dataset.map(tokenize_function, batched=True) # 分词后的dataset已经是torch张量了,是每个词代表的向量
train_dataset.set_format(type='torch', columns=['input_ids', 'attention_mask', 'label']) # 将数据改为torch的格式
training_args = TrainingArguments( # 设置训练参数,下面是我的,你也可以自己调
learning_rate=0.00001,
num_train_epochs=1, # 训练轮次
per_device_train_batch_size=16, # 每个设备的批处理大小
output_dir='./results', # 输出文件夹
# warmup_steps=500, # 预热步数
weight_decay=0.05, # 权重衰减
# logging_dir='./logs', # 日志文件夹,注掉以不保存日志
logging_steps=1, # 多少步print一次日志?
)
# 初始化Trainer
trainer = Trainer(
model=model, # 模型
args=training_args, # 训练参数
train_dataset=train_dataset, # 训练数据集
)
# 开始训练
print("开始训练")
trainer.train()
print("训练结束")
save(model, 'model.pth')
print("保存完毕,程序结束")
首次运行时你会自动下载Bert模型到本地,这回花费一些时间。下面是我训练过程中的截图:
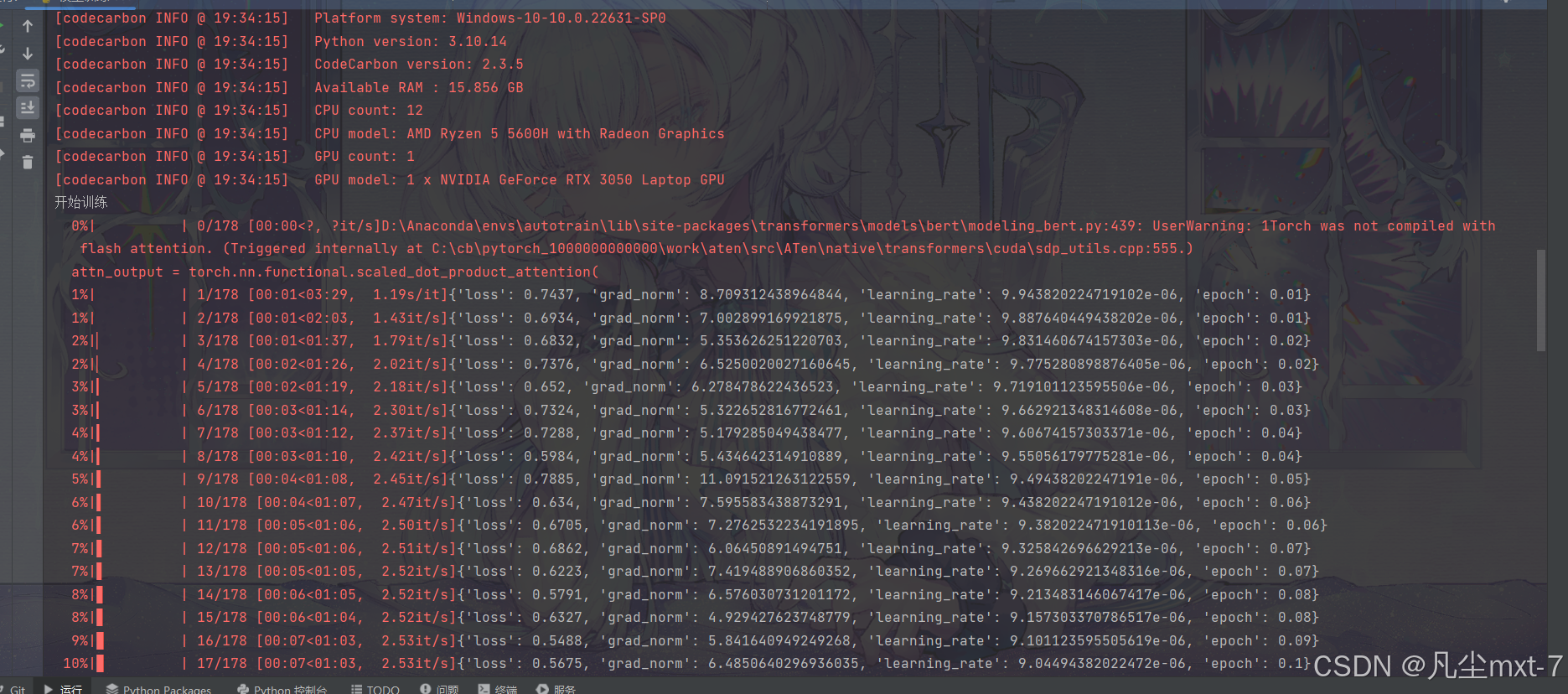
trainer.train()函数似乎会自动识别你是否安装了CUDA,能否启用GPU加速训练,而不需要你手动设置。如你所见,这个任务在RTX3060上的运行时间是<3min的。如果你的硬件不是很好,稍加等待也能完成。
模型测试
import torch
from datasets import Dataset
from transformers import BertTokenizer
from torch.utils.data import DataLoader
from sklearn.metrics import accuracy_score
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = torch.load('model.pth') # 加载你的模型
model.eval()
def tokenize_function(examples): # 同样的分词处理
return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=128)
# 加载数据集并应用tokenizer
test_dataset = Dataset.from_csv('test_data.csv')
test_dataset = test_dataset.map(tokenize_function, batched=True)
test_dataset.set_format(type='torch', columns=['input_ids', 'attention_mask', 'label', 'text'])
# 上面columns这个参数表示转换后的数据格式,input_ids,attention_mask,是torch格式需要的,label是你定义的标签列名,
# text是你想要新格式里带有的内容,是可选的,如果出现了不属于torch也不属于你定义的列名的参数就会报错
# 创建DataLoader
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False) # 根据你的硬件调整batch_size
# 似乎这一步的数据匹配是多余的?但是我也懒得调了
# 预测函数
def predict(dataloader):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 检测cuda是否可用
model.to(device) # 把数据移动到相应的硬件中去处理
prediction = [] # 存放预测标签
true_label = [] # 存放真实标签
list_text = [] # 存放预测文本
with torch.no_grad():
for batch in dataloader: # 从这里可以看出dataloader也是一个迭代器,其中的每一个元素都是一个字典
inputs, masks, labels, text = batch['input_ids'].to(device), batch['attention_mask'].to(device), batch[
'label'].to(device), batch['text']
outputs = model(inputs, attention_mask=masks)
preds = torch.argmax(outputs.logits, dim=1) # 假设模型的输出是logits,你需要根据具体情况修改这里
prediction.extend(preds.cpu().numpy()) # 得到预测标签
true_label.extend(labels.cpu().numpy()) # 得到真实标签
list_text.extend(text) # 注意text是包含了一个批次的text内容的list类型,所以要使用extend
return prediction, true_label, list_text
# 调用预测函数并计算准确率
predictions, true_labels, text = predict(test_loader)
print(len(predictions), len(true_labels), len(text))
for i in range(len(predictions)):
print(f"第{i}条信息,预测为{predictions[i]},实际为{true_labels[i]},内容为:\n{text[i]}")
accuracy = accuracy_score(true_labels, predictions) # 仔细看这个函数的结构,它可以用来快速评估模型的准确率
print(f'Accuracy: {accuracy:.4f}')
运行结果:
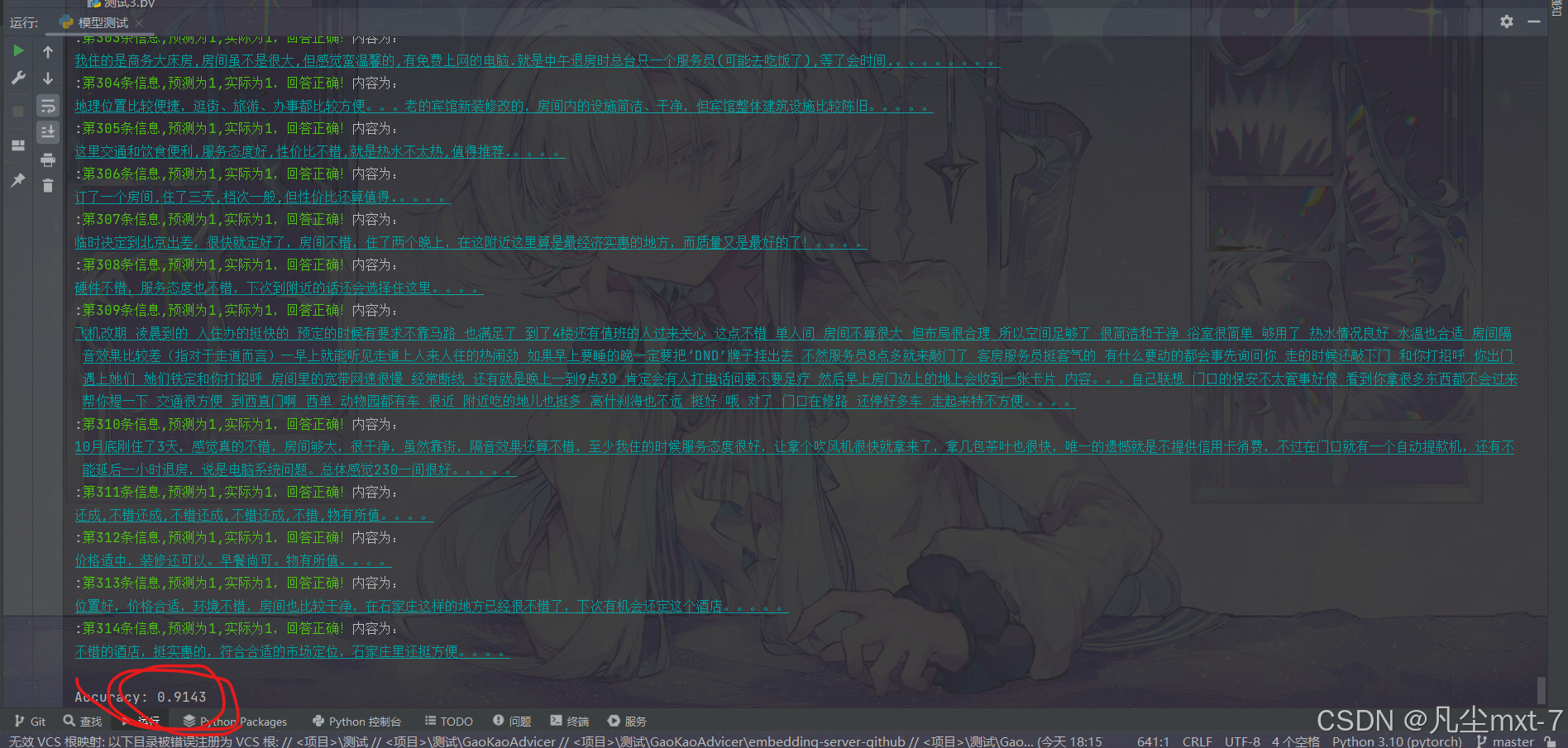
可以看到我们这次的准确率居然高达九成多,模型在大多数测试集上的评测结果都是正确的。 可见预训练过的Bert模型的性能是要比fasttext要更高的。
最后
文本分类任务暂时就告一段落了,我接下来还会出一些关于音频分类与图像分类的文章,敬请期待吧~希望本文对你学习人工智能和大模型有帮助。有任何问题可以向作者提出。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 48
48 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)