第八节:自然语言处理与bert
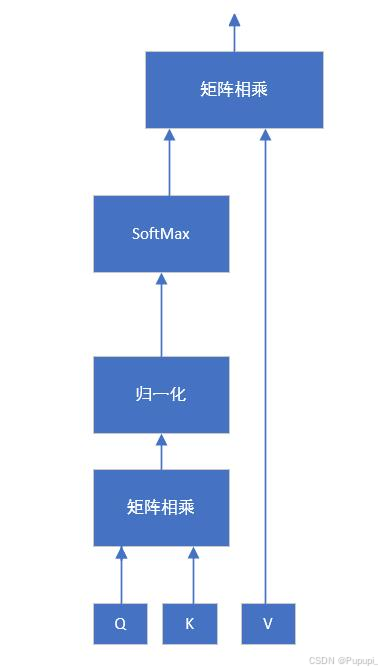
查询(Query):当前元素想要关注什么。键(Key):其他元素是否值得被关注。值(Value):基于注意力分数,实际用于计算输出的信息。每个元素的输出是基于其对所有元素值的加权和,权重即为注意力分数。这样,每个元素的输出都融入了整个输入序列的信息,根据注意力分数的不同,对不同元素的信息给予了不同的重视。
1、怎么用向量表示一个字?
通常使用one-hot encoding(独热编码),但是需要两万多的长度表示一个字(汉字数量两万+),太浪费空间且体现不出字与字之间的关系,因此出现了Word Embedding:根据词的含义对字的向量进行邻近,让不同含义的字的关系离得更远。
2、如何更改想要编码的维度?
通过全连接就可以减少编码的维度以及表示的含义,把全连接理解成万能工具,把汉字编码成你想要的文字之间的关系就可以通过全连接训练得出。
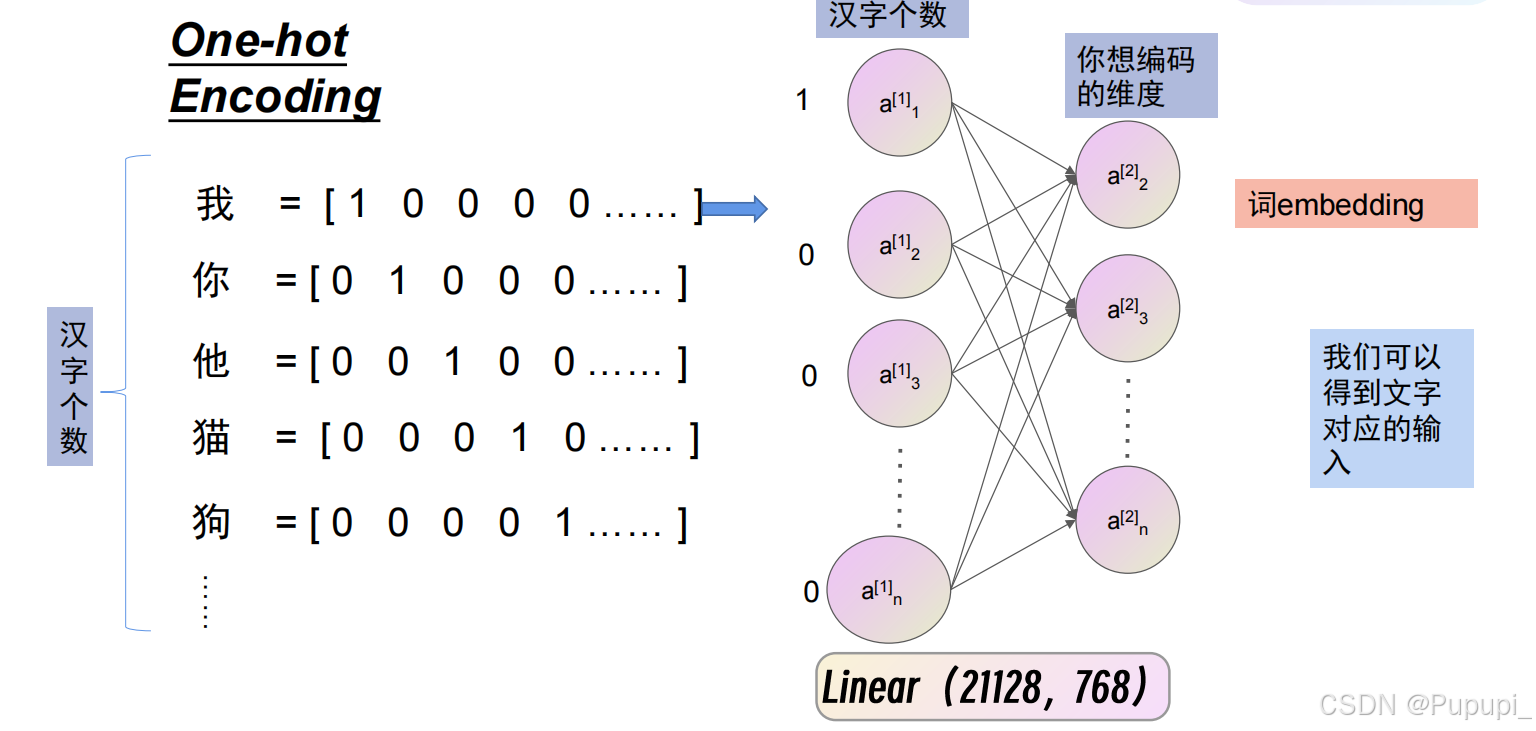
3、常见的文字输入?
输入文字的编号抛给模型训练即可(句号也算)
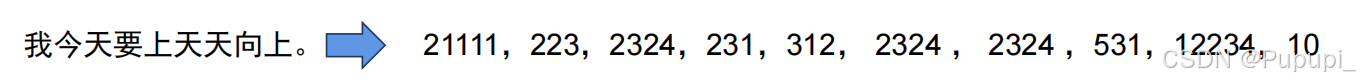
4、nlp常见的输出有哪些?
①每个词都有输出一个值(例如:将输入的文字输出其词性)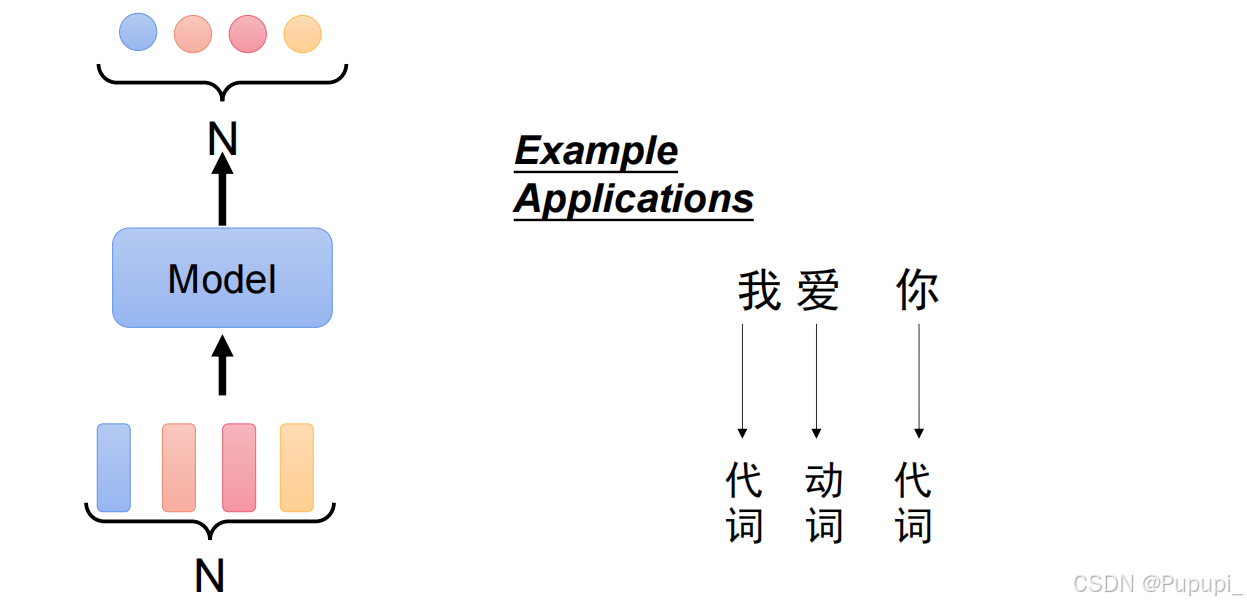
②所有词都输出一个值(例如:判断一句话是什么情感)(情感分类任务)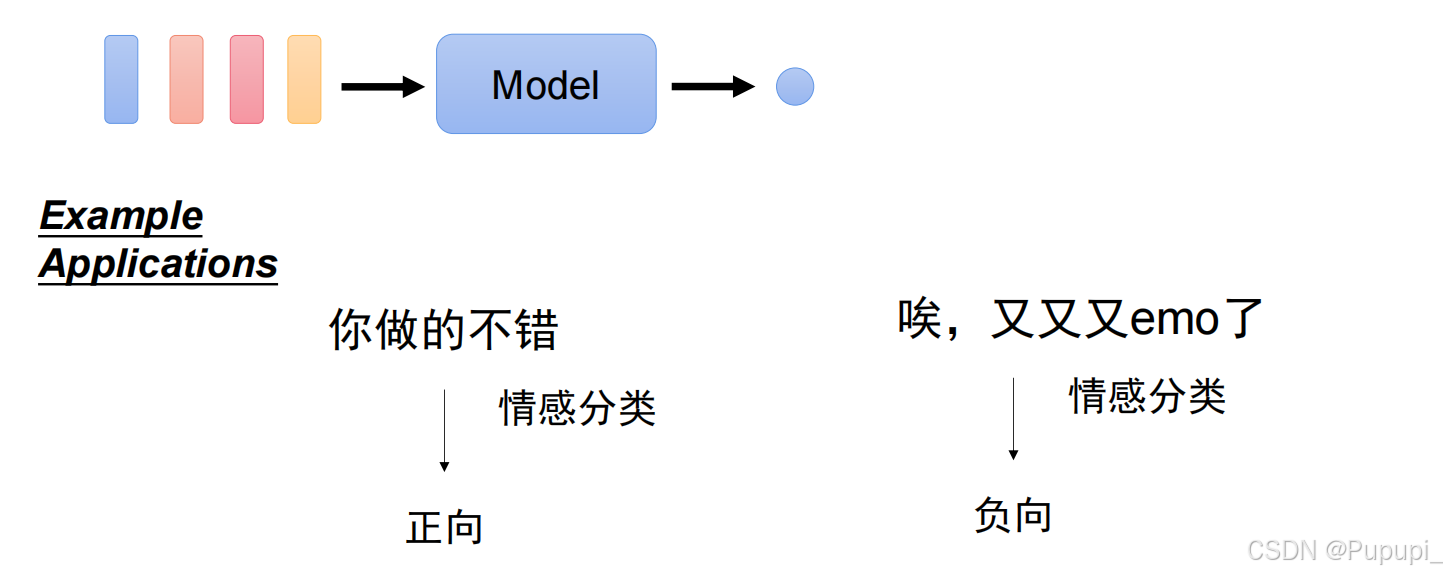
③输出长度不确定(例如:四个汉字翻译为三个英文单词)(翻译任务)(生成任务学)
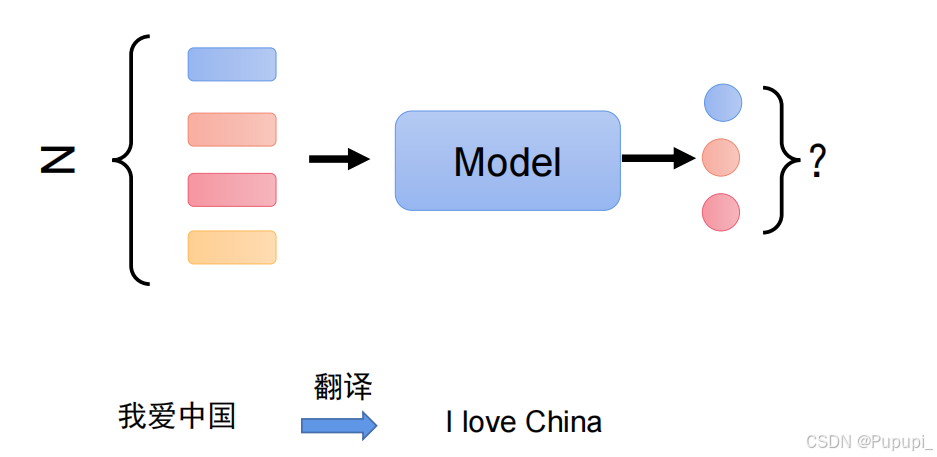
4、序列和图片输入的区别?
“这爱爱的够深吗?”这句话中的“爱”分别表示一个名字和一个动词,那么根据模型输出一个字只能表示一种词性这和图片输出一个原理,对于序列来说,每个字之间都可能存在某种关系,那么如何表示这种关系呢?(RNN循环网络)
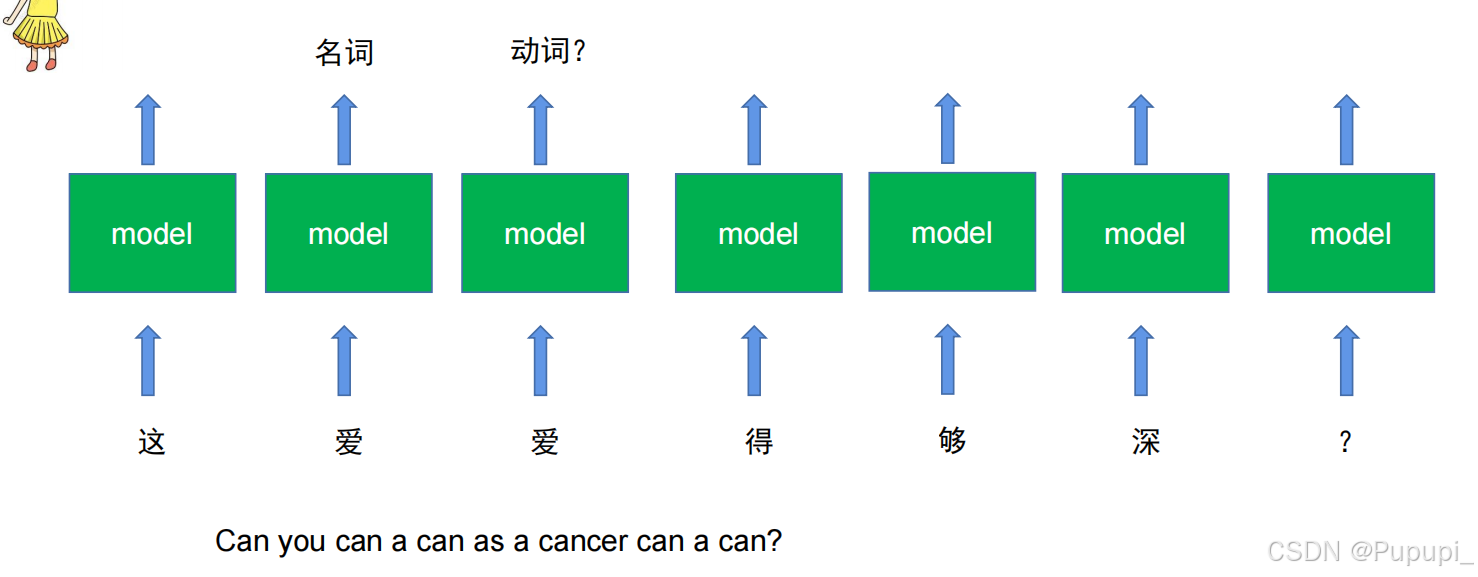
5、RNN循环网络(最早研究序列问题的网络)
①解释:
在当前模型输入的时候,不仅输入一个“这”字,还输入一个“传家宝”(一代一代传下去的东西 )模型输出的时候不仅输出结果代词,还要输出“传家宝”(代词“这”)然后可以根据“传家宝”和输入“爱” 得到这个“爱”表示名词,随后输出名词和"传家宝"(可能是“这爱”),通过模型的输入变化使得模型的输出也会改变。“传家宝”称为向量或者记忆单元(是由一组向量来存储的数据)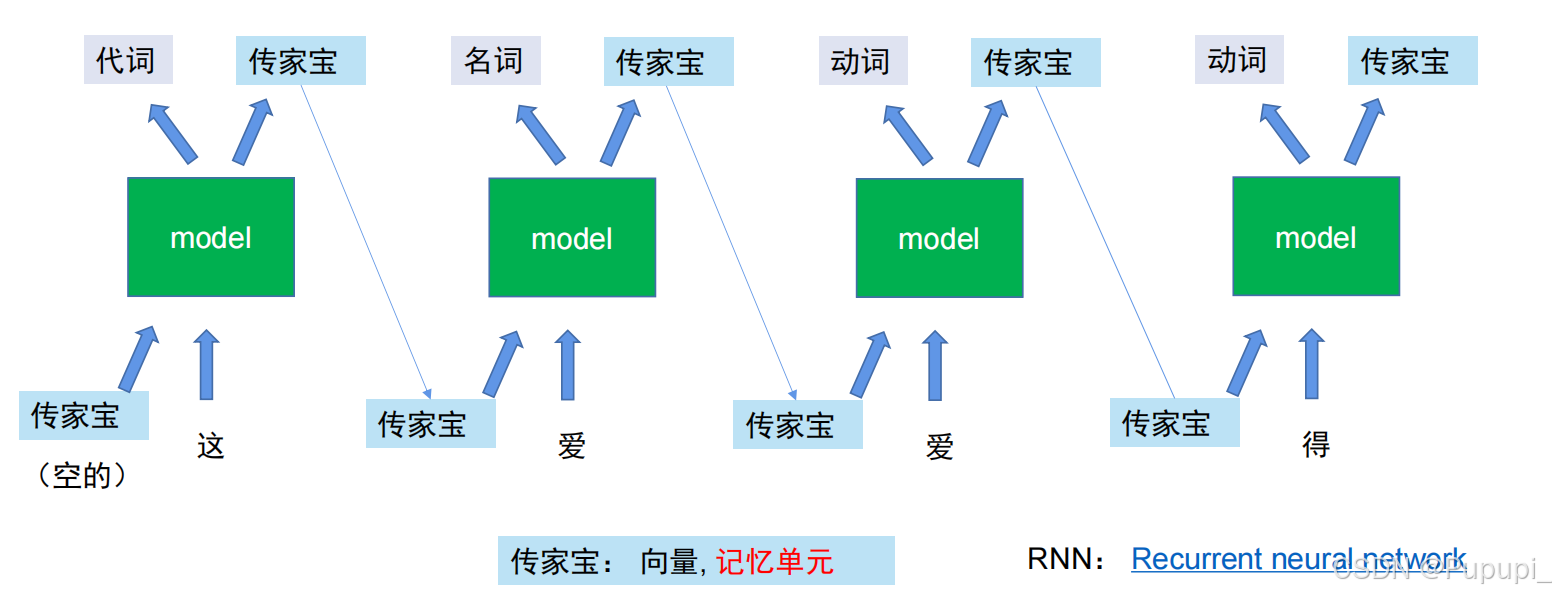
②问题:
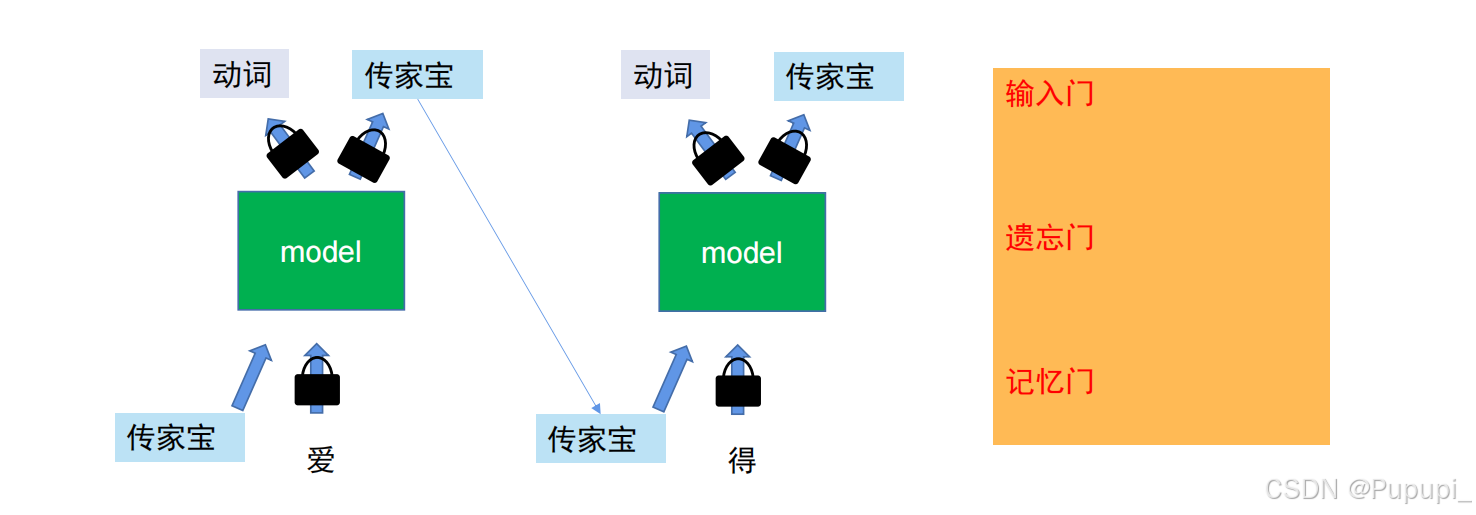
可能会出现“不肖子孙”(有可能出现在某一代模型训练时不仅没有作业反而干扰了正确的选择)解决是长短期记忆(Long short-term memory, LSTM)
6、长短期记忆(Long short-term memory, LSTM)
长短期记忆网络是循环神经网络(RNN)的一种变形,用于解决传统循环神经网络在处理长序列数据时梯度消失或爆炸问题,其主要是由三部分组成,分别为遗忘门、输入门和输出门。
做法是把路径都上锁,如果出现影响模型训练的就锁上不进入模型或者不进入记忆单元
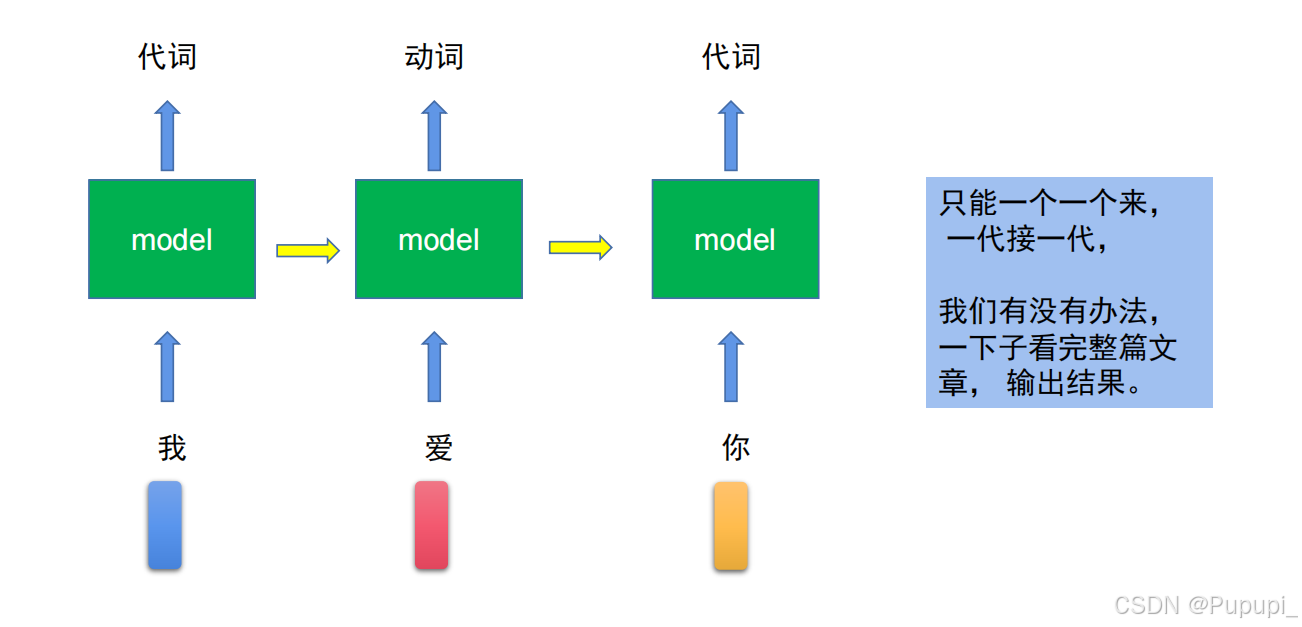
7、RNN、LSTM存在的问题
串行的进行模型迭代训练太慢了,故可以使用self-attention自注意力机制
8、Self-attention:自注意力机制
①概念
注意力机制(Attention mechanism)是目前较为热门的自然语言处理机制。它能够根据输入文本的上下文语境动态地分配注意力,以处理不同部分的信息。注意力机制首次在 Transformer 模型中提出,如今被广泛应用于机器翻译、命名实体识别、文本摘要等任务中。
相对于传统的循环神经网络(RNN)和长短期记忆网络(LSTM),注意力机制具有以下优势。首先,RNN 和 LSTM 模型在计算时只能单向顺序处理数据,导致模型的并行能力受到限制,而注意力机制则能够克服这一问题,提升模型的并行化能力。其次,RNN 和 LSTM 模型常常会面临梯度消失或梯度爆炸等问题,这些问题限制了模型对长期依赖关系的准确建能模力。引入注意力机制后,模型可以根据不同部分在序列中分配不同的注意力权重,更好地捕捉序列中的长期依赖关系,从而提升模型的表现和效果。
②什么是注意力
- 查询(Query):当前元素想要关注什么。
- 键(Key):其他元素是否值得被关注。
- 值(Value):基于注意力分数,实际用于计算输出的信息。
每个元素的输出是基于其对所有元素值的加权和,权重即为注意力分数。这样,每个元素的输出都融入了整个输入序列的信息,根据注意力分数的不同,对不同元素的信息给予了不同的重视。
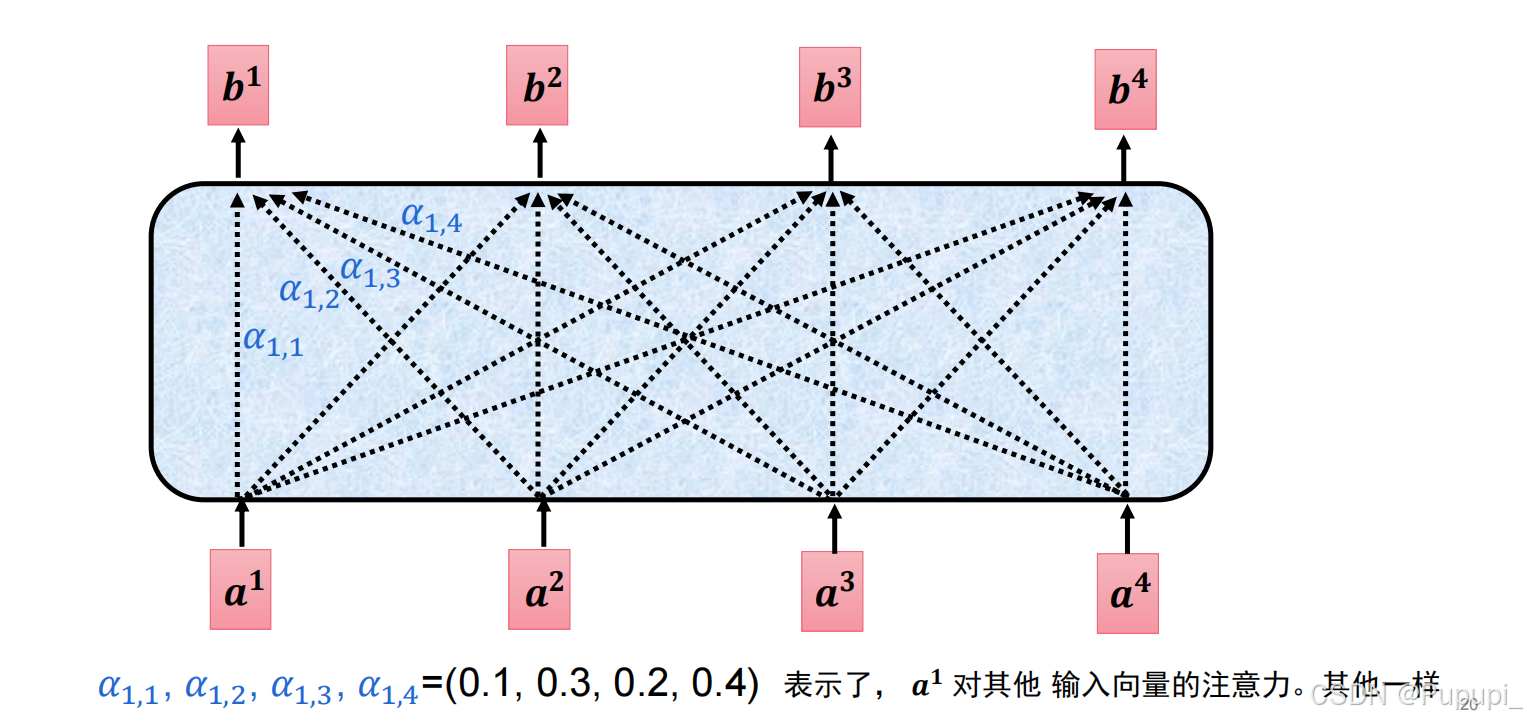
③如何计算注意力
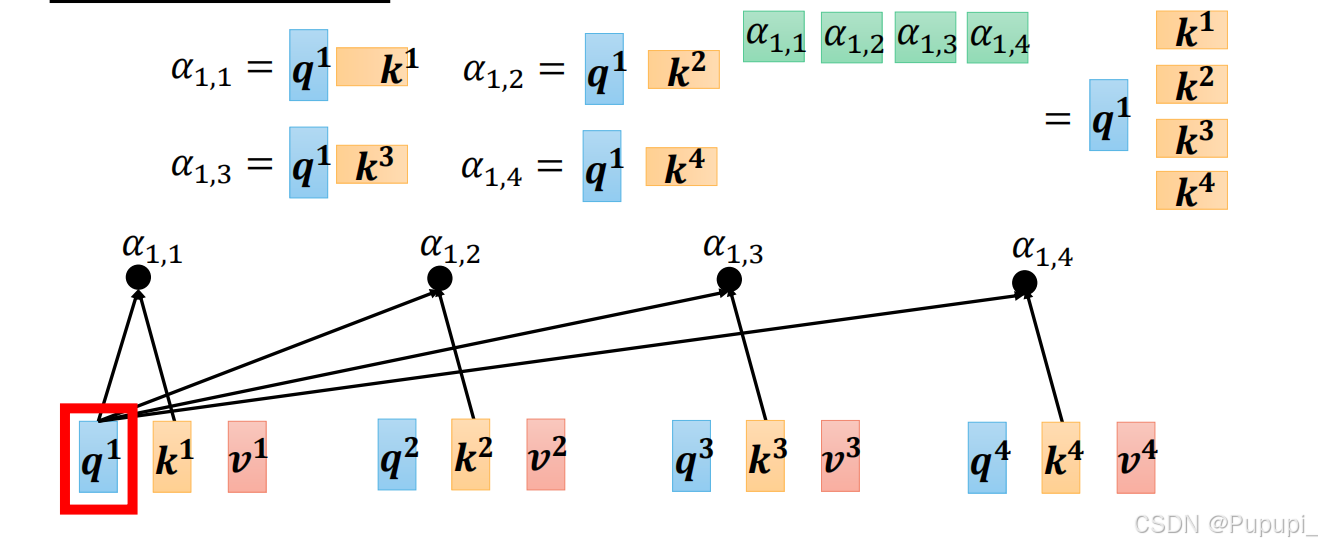
第一种直接点乘没有运用模型,因此不用。第二种是在点乘的基础上乘上相应的矩阵将嵌入向量 X 与模型训练得出的参数权重(Wq 、Wk )分别相乘(与一个矩阵相乘相当于一个全连接),然后得到q、k,再把q、k点乘。其中a1通过Wq矩阵相乘得到的q的过程称为query,再去与k点乘,即q扫k的码得到注意力值,即得到α1,2应该分配的注意力值

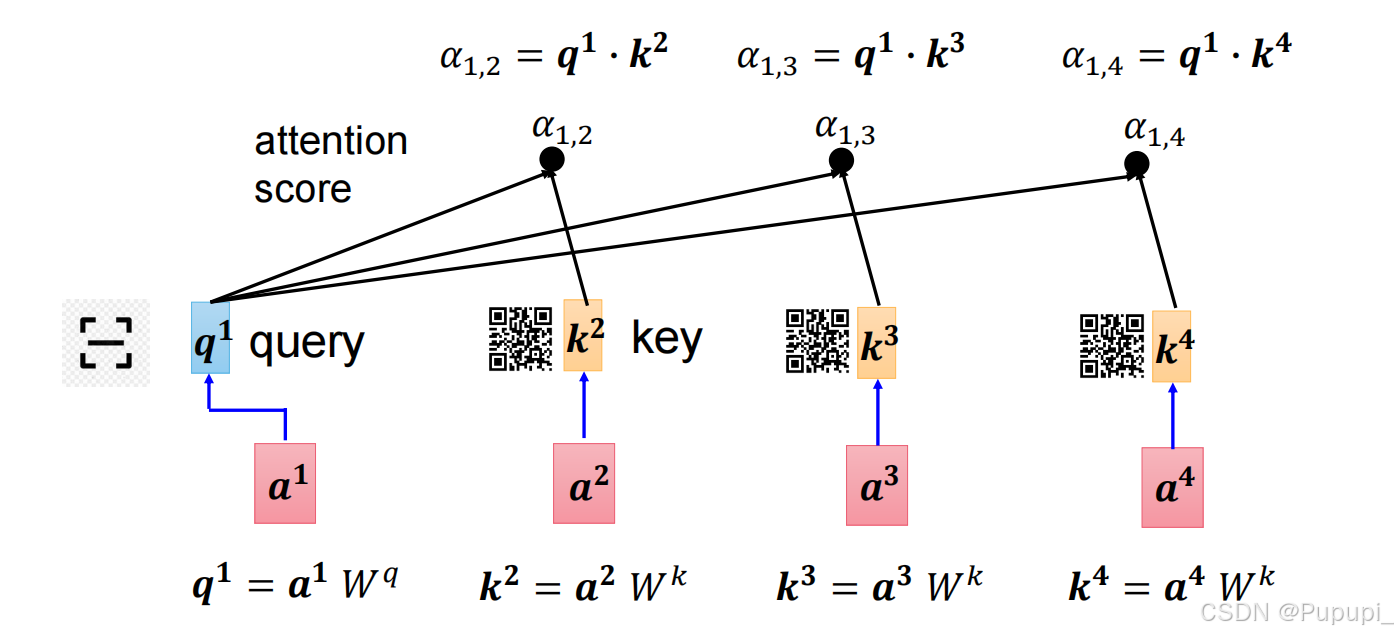
再将得到的值通过soft-max进行归一化得到和为1的注意力就可以明白每个向量所分配的注意力值,即得到了a1应该分配每个字多少注意力的值。
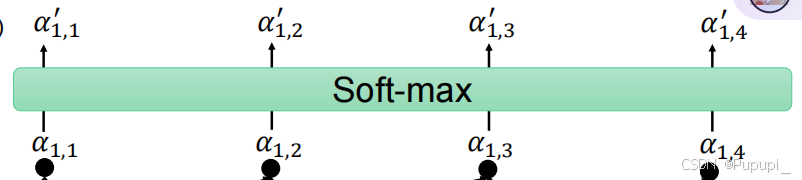
让各个注意力值和v相乘再相加得到b1(即a1看到整句话得到的结果)

对于b2来说同理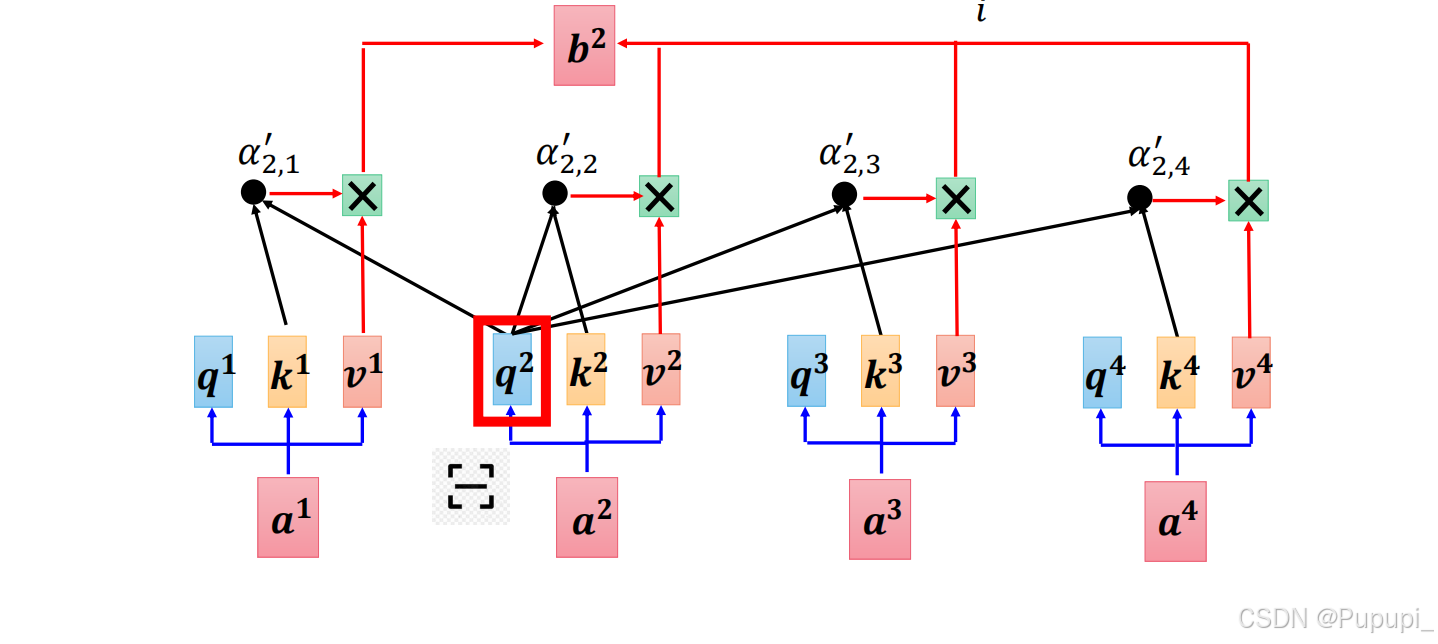
由于各个结果的计算不需要前置条件即可以并行,故结果的得出是同时的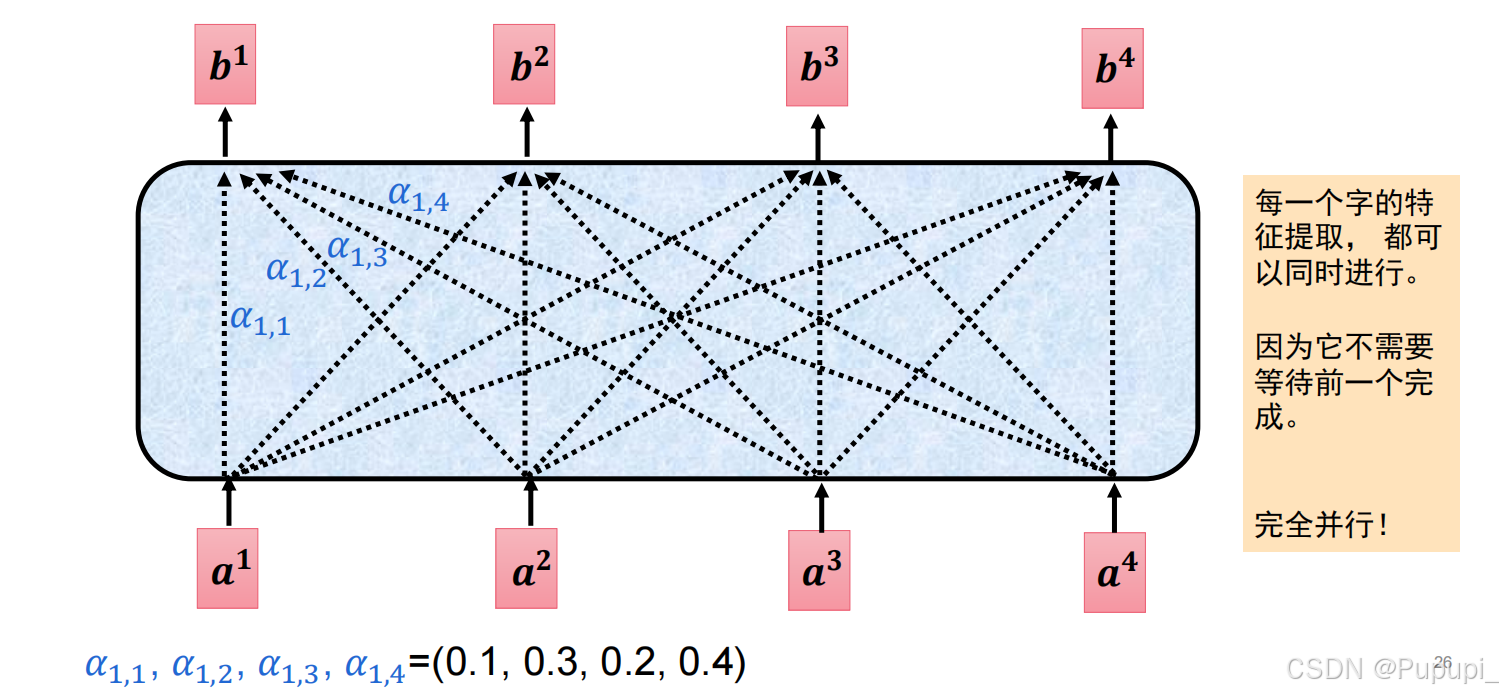
通过a1和Wq相乘得到q1,a1和Wk相乘得到k1,q2,k2,q3,k3,q4,q4,k4同理,再将q1和k1做点乘得到值α1,1、q1和k2、k3、k4分别做点乘得到α1,2、α1,3、α1,4.得到了一行的注意力值。
再把q2、q3、q4和k1、k2、k3、k4分别点乘得到A=α2,1、α2,2、α2,3......α4,4,得到之后进行soft-max得到A',注意是一行一行进行soft-max。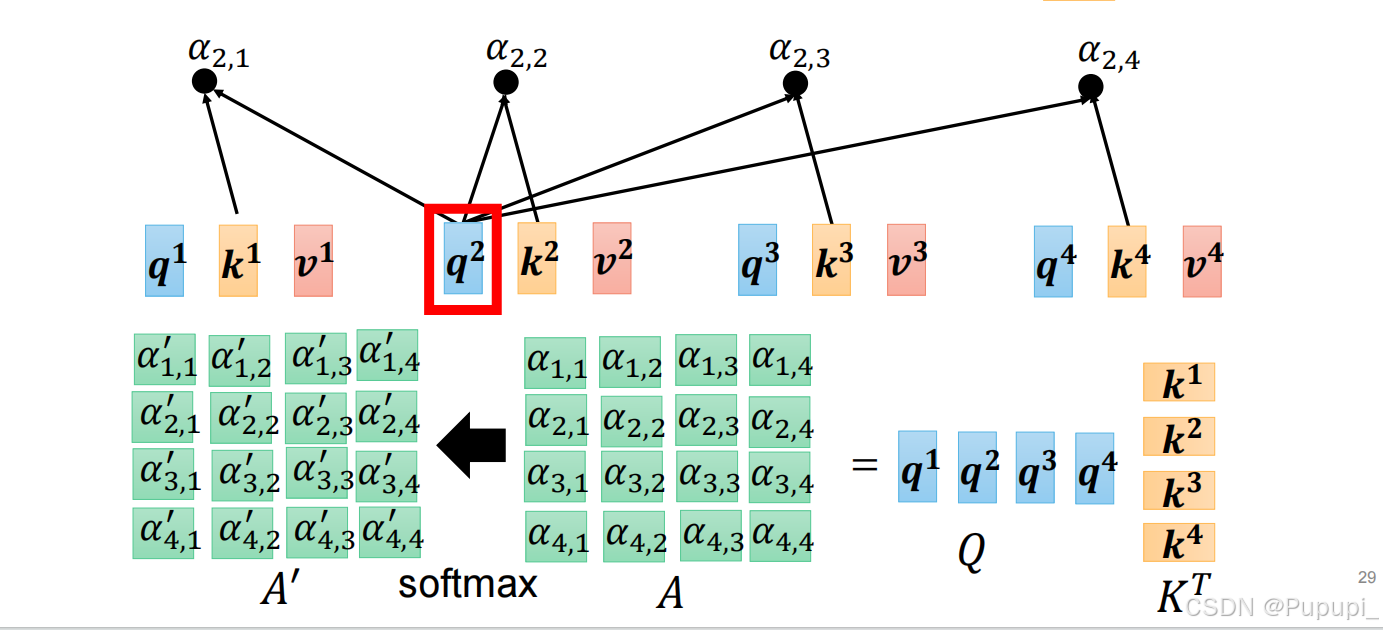
得到A'后把A'与V相乘得到b1、b2、b3、b4(A'为4×4,V为4×768,O为4×768)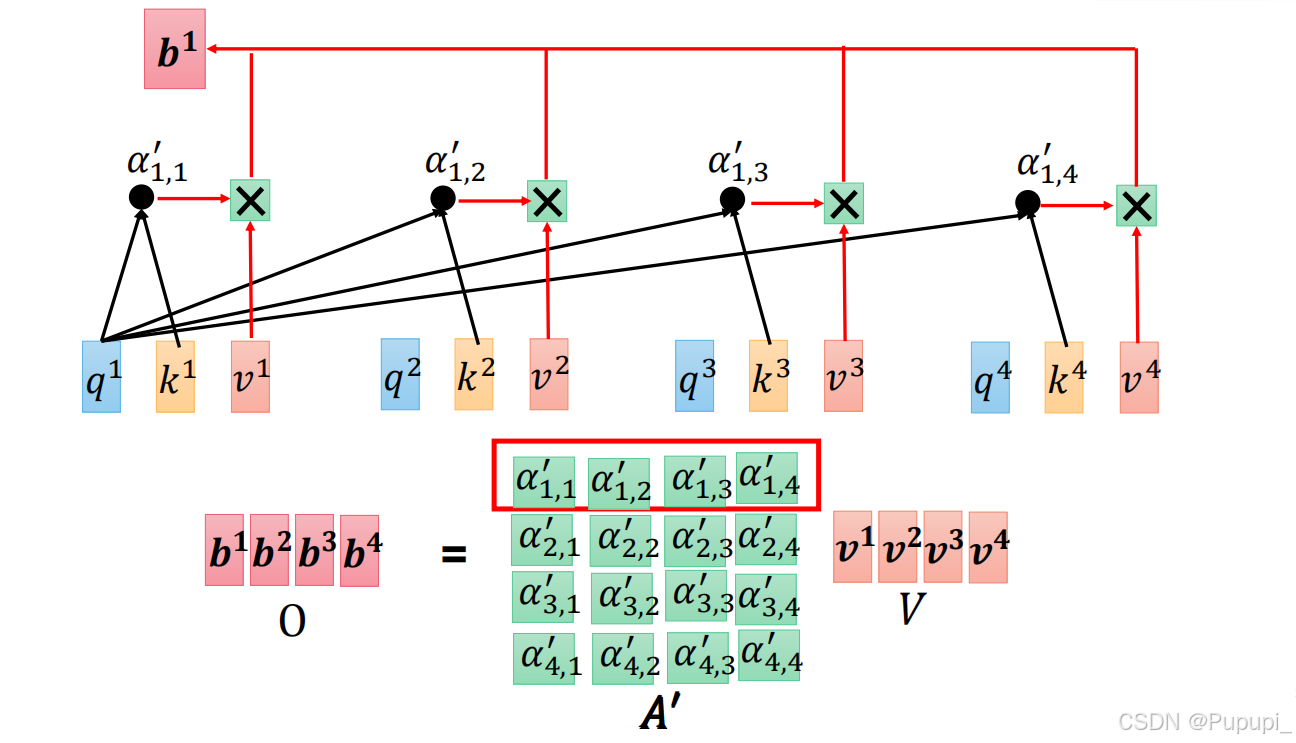
其中需要模型训练的只有Wq、Wk、Wv。99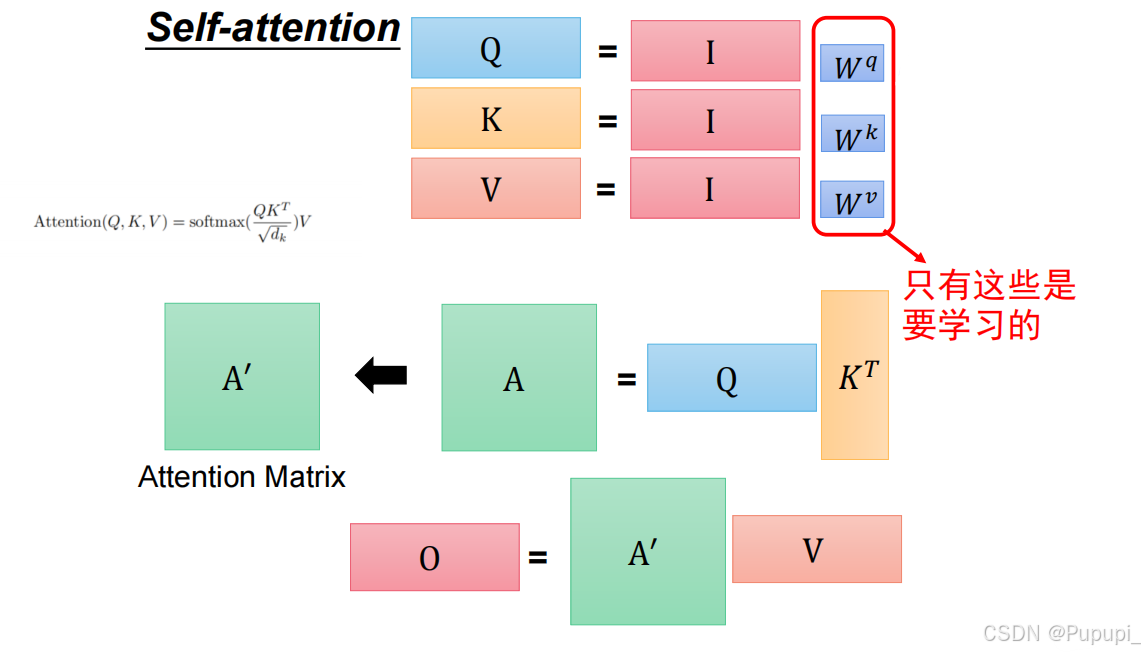
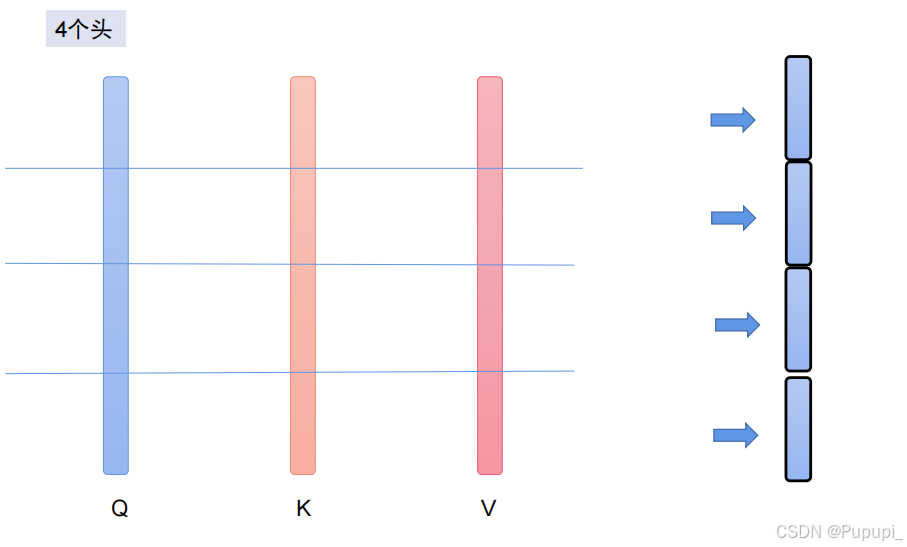
④多头注意力机制(Multi-Head Attention)
一般采用的是把768分成四块,一块即192的长度分别计算Q、K、V,实际操作中可能会涉及这种机制
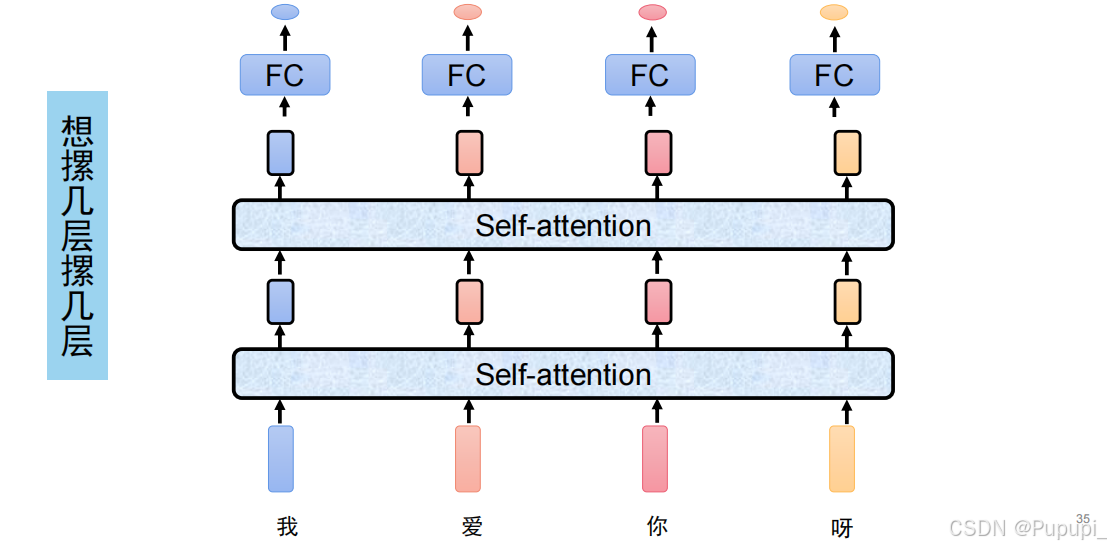
⑤模型深度
模型输出后维度不变,只要有钱,想叠几层叠几层
⑥位置信息
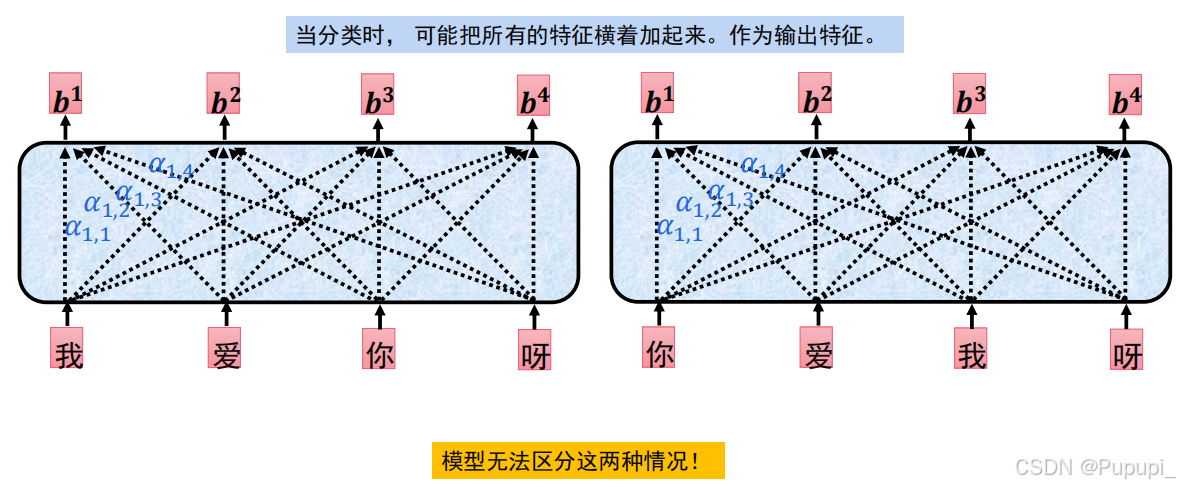
下面两句话中的“我”字通过计算会得到相同的结果,因此为了区分两个“我”字代表的意思,需要加上位置信息。
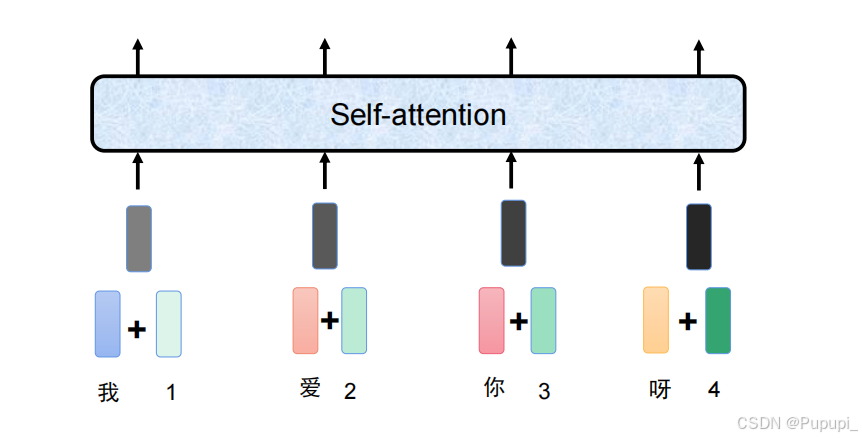
直接把字表示的向量与位置向量直接相加,即词编码的向量和位置编码的向量直接相加。
⑦token
在实际工作当中,通常把一个词编码后的向量加上位置信息称为一个token
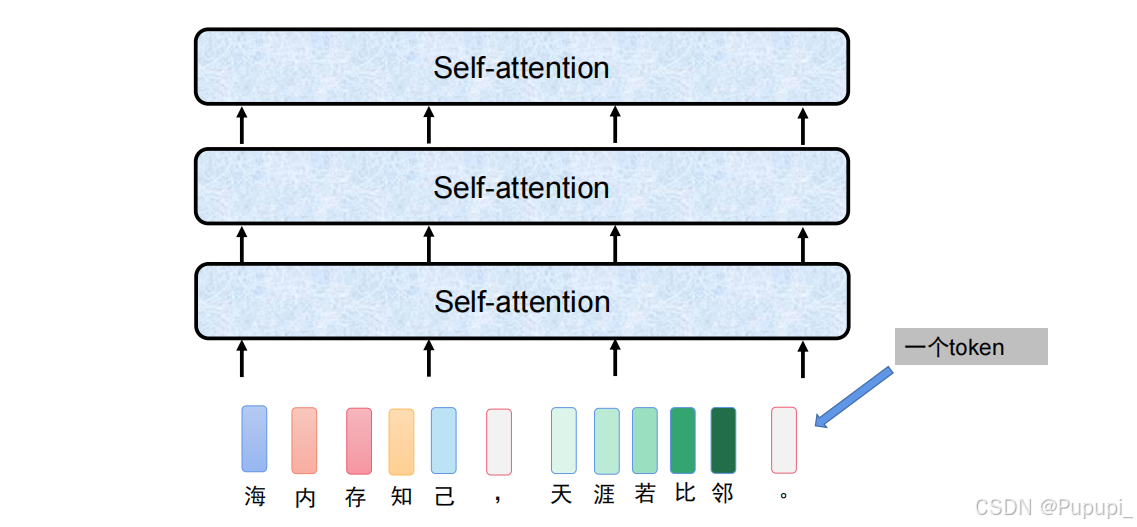
⑧流程
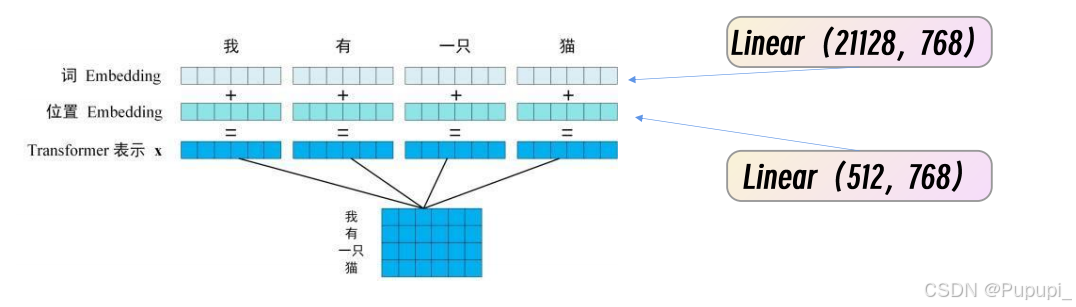
1、输入词并经过one-hot编码。
2、经过Embaedding即Linear(21128,768)变成768维。
3、降维之后与位置向量直接相加后进入transform(self-attention)
4、得到q、k、v后进入Multi-Head Attention多头注意力机制
5、进入Feed Forward(两个全连接)mlp多层感知即nn.learn(768,3072),nn.learn(3072,768)后经过残差链接和归一化得到输出
6、可以叠n层(输出都是768)
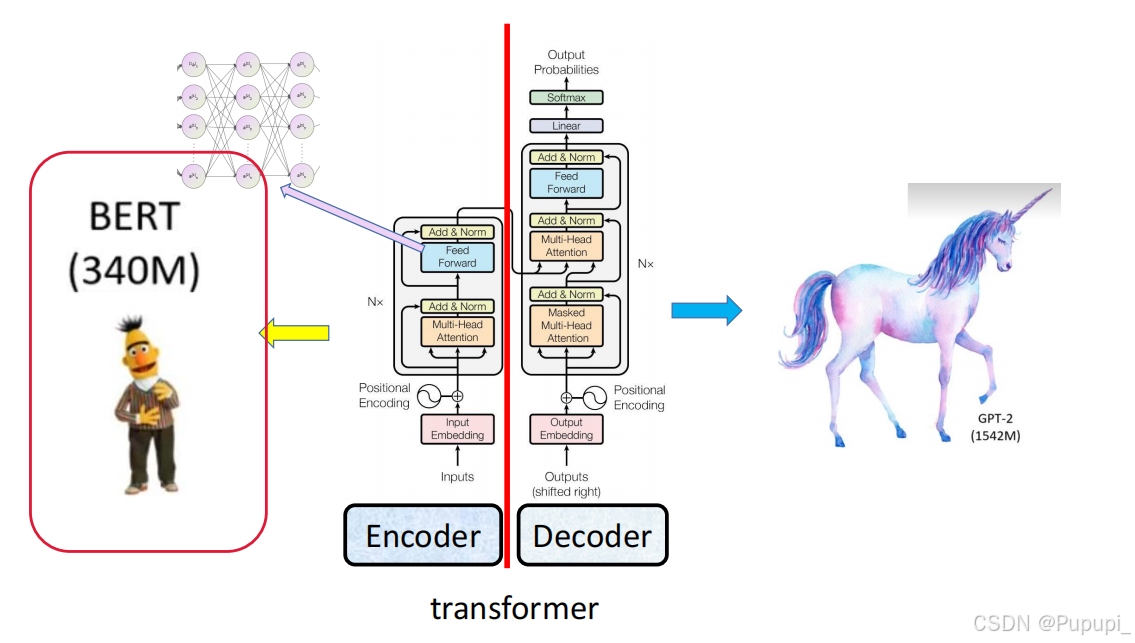
9、bert模型
①概念
BERT是一种基于深度学习的语言处理模型。它采用双向的Transformer 结构,能够实现自编码语言处理。它使用掩码语言模型(MaskedLanguage Model)进行预训练,同时利用文本前后两个方向的信息,并且全面考虑上下文的语义环境,这种方式能提高信息抽取的准确性。BERT 本质上是由Transformer 的 Encoder 部分构成的。
利用mask把模型中某些地方遮住进行训练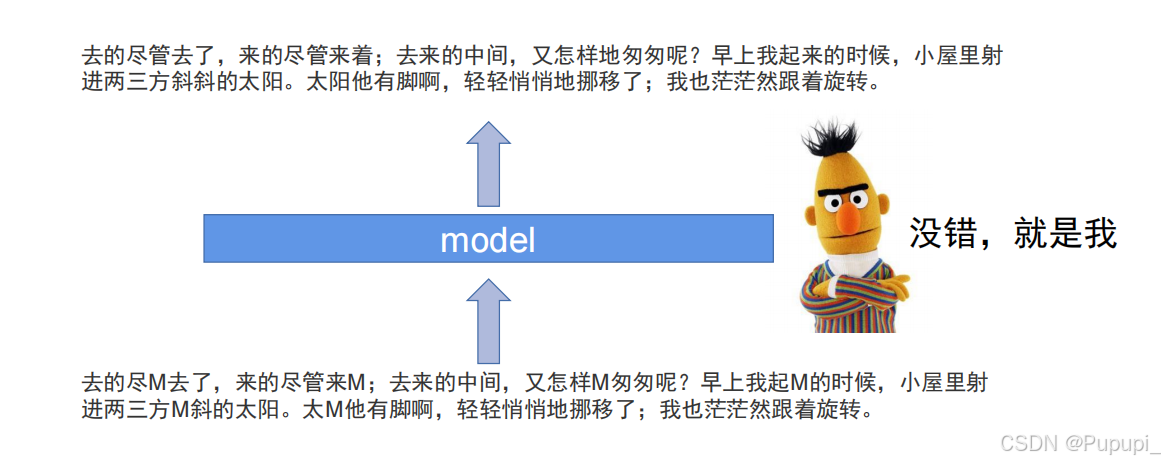
②结构
embedding为嵌入层,bert layers为transformer结构叠加,每一层都是一个transformer,pooler output是池化输出
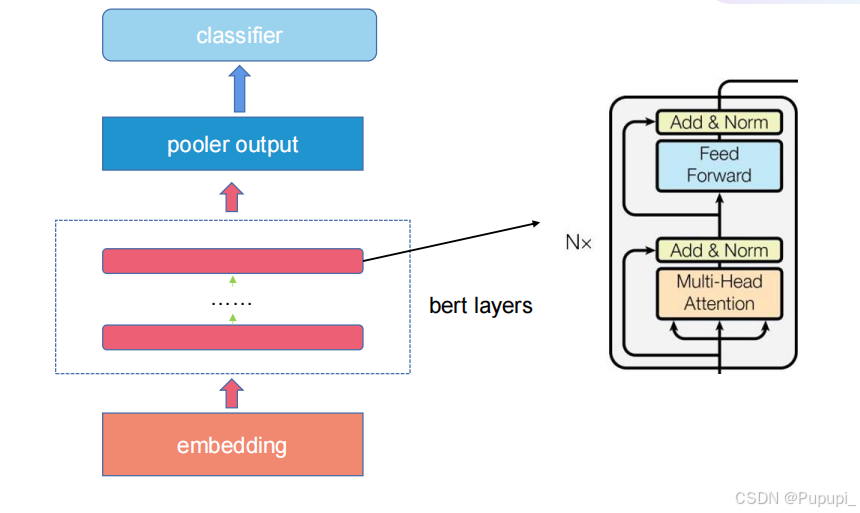
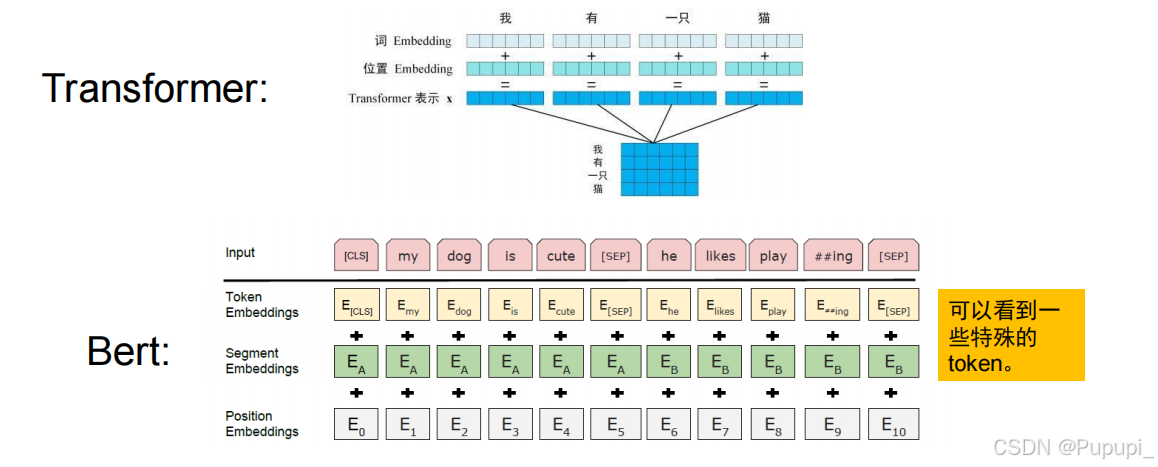
③Bert输入embedding
token表示的是句子编码后的向量,segment表示在第几个句子,position表示字词在的位置,这三个相加得到了embedding的输出。其中特殊的token比如CLS表示classification被用来做分类任务,可以统揽全局。SEP表示逗号或者句号即句子的中断
④Bert输出pooler
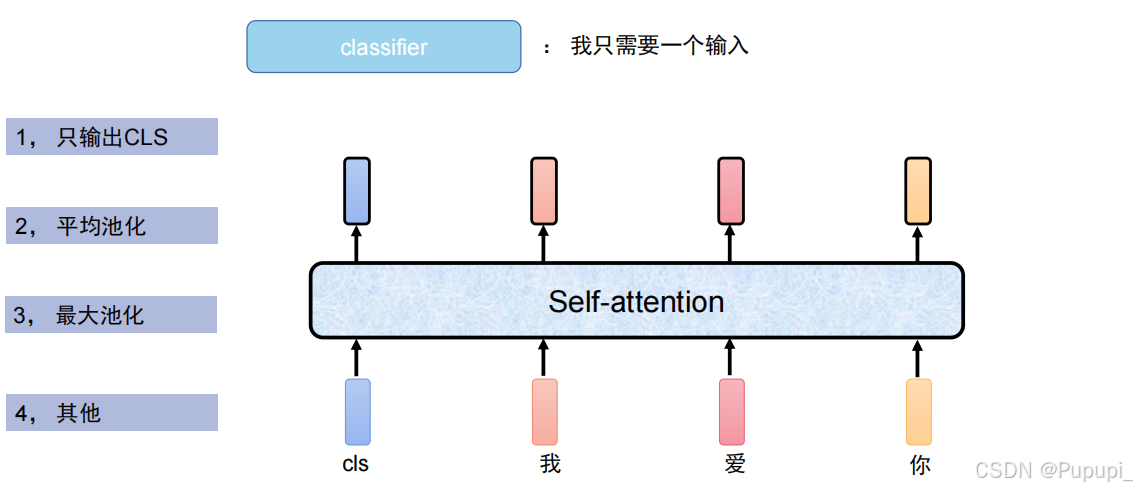
比如向量输出后是4×768,那么如何变成分类任务中的一个输出即768呢,
1、只输出CLS(常用):把CLS这个特征拿出来进行判别分类。
2、平均池化(少用):把输出的四个768向量相加除以4即可
3、最大池化(少用):选最大的向量(不易比较最大)
4、其他

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)