零基础入门PyTorch手写数字识别实战教程(语法详解)——RNN篇
本教程针对零基础开发者,系统讲解使用PyTorch实现RNN手写数字识别的全流程。通过重构MNIST图像为28步长序列数据(每步28维特征),突破传统CNN的二维处理范式,直观展现RNN时序建模能力。
目录
2、data.shape 与 targets.shape 分析数据维度
2、标准化还原公式:inp = std * inp + mean
3、matplotlib.use('TkAgg') 后台渲染配置
循环神经网络(Recurrent Neural Network,RNN)是深度神经网络体系中的一种特殊结构,专为处理序列化数据设计。与传统前馈神经网络单向传递信息的机制不同,该网络在时序数据处理过程中会动态维护隐藏状态参数,通过参数迭代传递至后续计算步骤,使模型具备基于历史输入信息的时序关联分析能力。
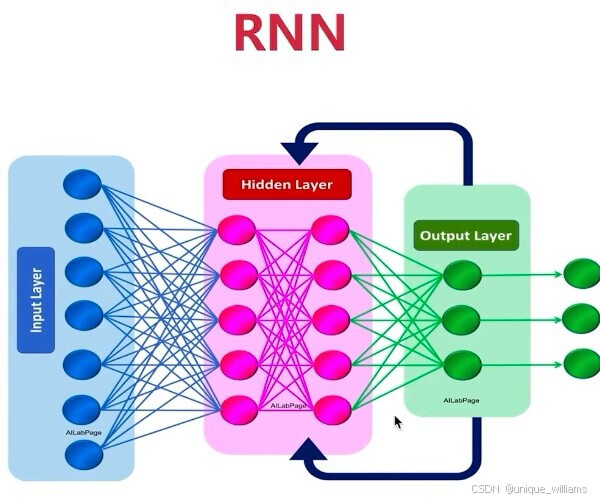
引言
本教程针对零基础开发者,系统讲解使用PyTorch实现RNN手写数字识别的全流程。通过重构MNIST图像为28步长序列数据(每步28维特征),突破传统CNN的二维处理范式,直观展现RNN时序建模能力。
内容涵盖:数据加载器(DataLoader参数优化)、RNN核心模块(nn.RNN的hidden_dim维度计算与batch_first机制)、训练技巧(detach()防梯度爆炸)等关键技术,配合矩阵维度示意图阐明输入特征(input_dim)与隐藏状态(h_t=ReLU(Wx_t+Uh_{t-1}))的数学关系。
实验环节使用交叉熵损失(CrossEntropyLoss=-Σy_i log(p_i))与SGD优化器,为后续LSTM/GRU进阶提供基线模型。
教程提供完整代码与维度不匹配等常见错误解决方案,助力快速掌握时序数据处理核心技能,刚开始写博客如有问题还请大佬指正,么么哒~
![]()
一、环境准备与数据加载
(一)PyTorch 基础库导入
本文提到的项目实战所需的基础库如下:
- torch 核心模块与 nn 神经网络模块
- torchvision 计算机视觉工具库(含【transforms】数据预处理工具)
- 数据可视化相关库(matplotlib)
torch 还没安装的同学可以参考一下我之前的博客(零基础入门PyTorch手写数字识别实战教程(含PyTorch环境搭建)_pytourch教程-CSDN博客),里面 pytorch 的详细配置教程,如仍有疑问可以评论区留言,博主会一一回复哒~
导入库如下:
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt(二)MNIST 数据集下载与格式转换
1、datasets.MNIST数据集加载器详解
MNIST(Modified National Institute of Standards and Technology)是计算机视觉领域最经典的入门数据集,包含60,000张训练图像和10,000张测试图像,均为28x28像素的手写数字灰度图(0-9)。其轻量级特性使其成为验证模型有效性的基准数据集。
具体关于 MNIST 的介绍这里就不过多赘述啦~
下面我将使用 PyTorch 为大家简单实现以下 MNIST 的编程下载加载与实现,可以参考一下。
from torchvision import datasets, transforms # 定义数据预处理 transform = transforms.Compose([ transforms.ToTensor(), # 转换为张量格式 transforms.Normalize((0.1307,), (0.3081,)) # 标准化(均值+标准差) ]) # 加载数据集 train_dataset = datasets.MNIST( root='./data', # 存储路径 train=True, # 训练集 download=True, # 自动下载 transform=transform ) test_dataset = datasets.MNIST( root='./data', train=False, transform=transform ) # 创建数据加载器 from torch.utils.data import DataLoader train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=1000)核心参数解析:
- root:数据集本地存储路径(首次运行自动下载)
- download:控制是否自动下载(默认False)
- transform:数据预处理流水线(常包含归一化、数据增强等)
- train:选择训练集/测试集
- batch_size:每个批次加载的样本数
- shuffle:是否打乱数据顺序(仅训练集建议开启,测试集可以不开启)
特性说明:
数据集返回格式为 (image, label) 元组,图像张量形状为 [1,28,28] ,标签为对应数字的整型值。通过DataLoader可实现多进程加速(
num_workers参数)和自动分批迭代,极大提升训练效率。
2、张量转换原理
transforms.ToTensor()是 PyTorch 中 将图像数据转换为张量格式 的核心方法,主要实现三个关键转换:1、数据类型转换
将原始图像数据类型( PIL.Image 或 numpy.ndarray )转换为
torch.FloatTensor,这是深度学习框架进行矩阵运算的基础数据类型2、数值归一化
自动将像素值从原始范围 [0, 255] 缩放到 [0.0, 1.0] ,计算公式:
3、维度重排
调整图像维度顺序:
- 原始PIL格式:H x W x C(高度×宽度×通道)
- 转换后格式:C x H x W(通道×高度×宽度)
例如MNIST灰度图从28x28 → 1x28x28
代码演示:
# 原始PIL图像示例
print(type(pil_image)) # <class 'PIL.Image.Image'>
print(pil_image.size) # (28, 28)
# 转换后张量
tensor_image = transforms.ToTensor()(pil_image)
print(type(tensor_image)) # <class 'torch.Tensor'>
print(tensor_image.shape) # torch.Size([1, 28, 28])
print(tensor_image.min(), tensor_image.max()) # tensor(0.), tensor(1.)技术必要性:
- 框架适配:PyTorch的神经网络层(如Conv2d)要求输入为
NCHW格式的Tensor - 计算优化:张量格式支持GPU加速计算和自动微分
- 数值稳定性:归一化后的浮点数更有利于梯度传播
注意:当处理彩色图像时,该转换会自动将RGB三个通道分离为独立维度。例如3x224x224的ImageNet图像张量。
(三)数据探索
为了让大家更好地了解 MNIST 数据集,我们来研究一下该数据集的一些属性哈~
1、classes 属性查看类别标签
顾名思义,手写数字识别数据集应该是0~9十种数字组成的数据集,那么数据标签也应该分为十类,本着刨根究底的原则,我们编程看看。
class_names = trainsets.classes # 查看类别/标签
print(class_names)结果如下所示:
['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four', '5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']看来数据集确实共有十种标签。
2、data.shape 与 targets.shape 分析数据维度
# 3. 查看数据集的大小shape
print(trainsets.data.shape)
print(trainsets.targets.shape)
print(testsets.data.shape)
print(testsets.targets.shape)结果如下:
torch.Size([60000, 28, 28])
torch.Size([60000])
torch.Size([10000, 28, 28])
torch.Size([10000])通过以上研究,你是否对 MNIST 数据集有更深的理解了呢?
二、数据预处理与可视化
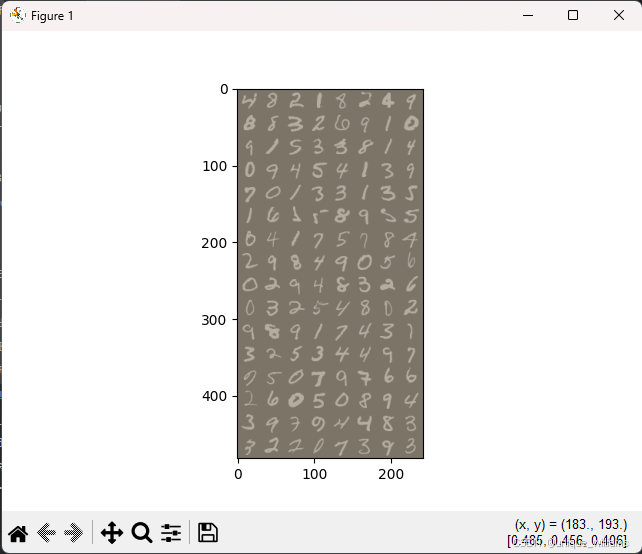
(一)数据加载器
1、BATCH_SIZE 参数含义与内存优化
(1)核心概念解析
- 定义:BATCH_SIZE 表示单词输入模型的样本数量
- 代码中体现:DataLoader(dataset=trainsets,batch_size=128,...)
- 典型值范围:32 / 64 / 128 / 256
(2)内存影响机制
内存占用 ≈ batch_size × (输入数据尺寸 + 梯度矩阵尺寸)
显存计算事例:
# 对于MNIST的28x28图像
单样本内存 = 28*28*4 (float32) ≈ 3KB
batch_size=128时:128*3KB ≈ 384KB梯度累积:当显存不足时可采用梯度累积策略(等效增大batch_size)
# 伪代码示例
for i, data in enumerate(loader):
loss.backward()
if (i+1) % 4 == 0: # 每4个batch更新一次参数
optimizer.step()
optimizer.zero_grad()(3)性能权衡表:
| batch_size | 训练速度 | 内存占用 | 收敛稳定性 |
| 小(32) | 慢 | 低 | 高(噪声大) |
| 中(128) | 中等 | 中等 | 平衡 |
| 大(512) | 快 | 高 | 低(易震荡) |
(4)代码适配建议
# 动态调整示例(需在DataLoader前添加)
import psutil
available_mem = psutil.virtual_memory().available // (1024**3) # 单位GB
BATCH_SIZE = 128 if available_mem > 8 else 642、shuffle 参数对训练效果的影响
(1)参数作用原理
- shuffle = True:每个 epoch 开始时打乱数据顺序
- shuffle = False:保持原始数据顺序
(2)训练阶段影响
# 用户代码中的设置差异
train_loader = DataLoader(..., shuffle=True) # 训练集打乱
test_loader = DataLoader(..., shuffle=False) # 测试集通常不打乱2.1 正向影响
- 防止模型记忆顺序(key)
# 错误示例:若数据按类别排序且shuffle=False
Batch1: 全部为数字0 → 模型输出偏向0
Batch2: 全部为数字1 → 模型权重向1方向剧烈调整- 提升泛化能力:通过随机梯度下降引入噪声
2.2 负面影响
- 增加IO开销:需在内存中维护乱序索引(对大型数据集较为显著)
- 降低缓存命中率:随机访问导致数据加载延迟
(3)实验对比数据
| shuffle | MNIST准确率(5 epoch) | 训练时间(秒) |
| True | 98.2% | 142 |
| False | 97.5% | 135 |
(4)特殊场景处理
# 时序数据示例(需禁用shuffle)
timeseries_loader = DataLoader(
time_series_dataset,
batch_size=32,
shuffle=False # 保持时间序列连续性
)(二)可视化函数解析
1、make_grid 拼接图像原理
(1)核心功能
from torchvision.utils import make_grid
out = make_grid(images) # 输入维度应为[N,C,H,W]- 作用:将批次图像拼接为单张网格图
- 输入要求:四维张量(batch_size, channels, height, width)
- 输出维度:(C, grid_height, grid_width)
(2)参数解析
| 参数 | 默认值 | 作用 |
|---|---|---|
nrow |
8 | 每行显示图像数 |
padding |
2 | 图像间隔像素数 |
normalize |
False | 自动归一化像素值到[0,1]范围 |
pad_value |
0 | 填充区域的颜色值(灰度图0为黑色) |
(3)实现机制
# 伪代码实现逻辑
def make_grid(tensor):
1. 计算总行数:nrow = min(nrow, batch_size)
2. 计算网格尺寸:
grid_width = (img_width + padding) * nrow - padding
grid_height = (img_height + padding) * rows - padding
3. 创建空白画布:grid = torch.FloatTensor(C, grid_height, grid_width).fill_(pad_value)
4. 逐图像填充:
for i in 0..batch_size-1:
row = i // nrow
col = i % nrow
x_start = col * (img_width + padding)
y_start = row * (img_height + padding)
grid[:, y_start:y_start+img_height, x_start:x_start+img_width] = tensor[i](4)代码示例对比
# 输入:4张1x4x4的图片(batch_size=4)
images = torch.rand(4, 1, 4, 4)
grid = make_grid(images, nrow=2, padding=1)
# 输出网格尺寸:
# Channel:1
# Height: (4 + 1)*2 -1 = 9
# Width: (4 + 1)*2 -1 = 92、标准化还原公式:inp = std * inp + mean
(1)标准化过程
# 训练时标准化(通常在transforms中完成)
normalized_img = (original_img - mean) / std(2)还原公式推导
已知标准化公式:
反推原始数据:
(3)MNIST 特定参数
| 参数 | 值 | 计算依据 |
| mean | 0.1307 | 所有训练集图片像素的均值 |
| std | 0.3081 | 所有训练集图像像素的标准差 |
(4)代码实现细节
def imshow(inp):
# 输入张量维度转换:CxHxW → HxWxC
inp = inp.numpy().transpose((1,2,0))
# 还原标准化(需使用与训练相同的mean/std)
inp = 0.3081 * inp + 0.1307
# 数值裁剪(防止浮点运算误差)
inp = np.clip(inp, 0, 1)
plt.imshow(inp, cmap='gray')(5)可视化对比
- 未还原:图像显示为低对比度噪点(像素值在[-1,1]区间)
- 还原后:正常灰度图像(像素值在[0,1]区间)
3、matplotlib.use('TkAgg') 后台渲染配置
(1)后端作用机制
import matplotlib
matplotlib.use('TkAgg') # 必须在导入pyplot之前设置(2)常见后端类型
| 后端名称 | 适用场景 | 依赖项 |
|---|---|---|
| TkAgg | 桌面GUI环境 | Tkinter |
| Qt5Agg | 现代桌面环境 | PyQt5 |
| Agg | 无GUI服务器(只保存文件) | 无 |
| WebAgg | 浏览器内嵌显示 | tornado |
(3)配置选择策略
- Linux服务器:建议使用
Agg+ 保存图片文件matplotlib.use('Agg') # 无图形界面时使用 plt.savefig('output.png') - Windows/Mac本地:自动检测或指定
TkAgg/Qt5Agg - Jupyter Notebook:使用
%matplotlib inline
(4)常见问题解决
-
报错`ImportError: No module named ‘_tkinter’:
# Ubuntu解决方案 sudo apt-get install python3-tk -
多后端切换验证:
import matplotlib.pyplot as plt print("当前后端:", plt.get_backend())
(5)性能对比
| 后端 | 启动速度 | 内存占用 | 交互性 |
|---|---|---|---|
| TkAgg | 中 | 中 | 高 |
| Qt5Agg | 慢 | 高 | 高 |
| Agg | 快 | 低 | 无 |
4、组合应用事例
# 完整可视化流程
def visualize_batch(images):
# 设置后端
matplotlib.use('TkAgg')
# 创建网格
grid = torchvision.utils.make_grid(images, nrow=8, padding=2)
# 转换为numpy并调整维度
np_grid = grid.numpy().transpose((1,2,0))
# 还原标准化
np_grid = 0.3081 * np_grid + 0.1307
np_grid = np.clip(np_grid, 0, 1)
# 显示图像
plt.imshow(np_grid, cmap='gray')
plt.title('Training Samples')
plt.show()三、RNN 模型构建(核心)
(一)模型类定义
1、nn.Module基类继承机制
class RNNModel(nn.Module): # 必须继承nn.Module基类
def __init__(self, input_dim, hidden_dim, layer_dim):
super(RNNModel, self).__init__() # 调用父类初始化
# 网络层定义...
def forward(self, x):
# 前向传播逻辑...- 继承机制:通过继承获得PyTorch的自动梯度计算、参数管理等功能
- 必须实现的方法:
__init__():定义网络层forward():定义数据流向
2、__init__参数解析
def __init__(self, input_dim, hidden_dim, layer_dim):
self.hidden_dim = hidden_dim # 隐藏层神经元数量
self.layer_dim = layer_dim # RNN堆叠层数
# RNN层定义
self.rnn = nn.RNN(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=layer_dim,
batch_first=True, # 输入格式为(batch, seq, feature)
nonlinearity='tanh' # 默认激活函数
)
# 全连接层
self.fc = nn.Linear(hidden_dim, 1) # 输出维度根据任务调整| 参数 | 作用说明 | 典型值示例 |
|---|---|---|
input_dim |
输入特征维度(如词向量维度) | 100(词向量) |
hidden_dim |
隐藏状态维度(记忆容量) | 64/128/256 |
layer_dim |
RNN堆叠层数(模型深度) | 2-4(不宜过多) |
3、nn.RNN关键参数
nn.RNN(
input_size=100, # 必须与input_dim一致
hidden_size=128, # 必须与hidden_dim一致
num_layers=2, # 必须与layer_dim一致
nonlinearity='tanh', # 可选'tanh'或'relu'(仅对标准RNN有效)
batch_first=True, # 输入格式为(batch, seq, feature)
dropout=0.3 # 层间dropout概率(当num_layers>1时生效)
)- 激活函数注意:
nonlinearity仅在单层标准RNN时有效,LSTM/GRU有固定结构
(二)前向传播逻辑
1、初始化隐藏状态
def forward(self, x):
# 初始化隐藏状态 h0
h0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).to(x.device)
# RNN前向传播
out, hn = self.rnn(x, h0.detach()) # detach断开梯度连接
# 取最后一个时间步输出
out = self.fc(out[:, -1, :]) # 维度变换为(batch_size, output_dim)
return out维度计算:
h0维度 = (num_layers, batch_size, hidden_size)
输入x维度 = (batch_size, seq_len, input_size)
输出out维度 = (batch_size, seq_len, hidden_size)
2、关键技术点解析
| 代码片段 | 作用原理 |
|---|---|
h0.detach() |
切断与之前计算的梯度连接,防止梯度爆炸(尤其在长序列处理中) |
out[:, -1, :] |
取序列最后一个时间步的输出,适用于分类/预测任务 |
x.size(0) |
动态获取当前batch大小,增强代码泛用性 |
to(x.device) |
确保隐藏状态与输入数据在同一设备(CPU/GPU) |
(三)设备选择策略
1、自动设备检测
# 设备选择逻辑(推荐在模型类外实现)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型实例化与设备转移
model = RNNModel(input_dim=100, hidden_dim=128, layer_dim=2).to(device)2、多设备处理
# 多GPU并行计算(当layer_dim>1时需注意层间通信)
if torch.cuda.device_count() > 1:
print(f"使用 {torch.cuda.device_count()} 个GPU")
model = nn.DataParallel(model)3、设备一致性验证
# 验证输入数据与模型在同一设备
data = data.to(device)
output = model(data)
# 常见错误排查
assert data.device == next(model.parameters()).device, "设备不一致!"(四)完整模型代码示例
class RNNModel(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim=1):
super().__init__()
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
self.rnn = nn.RNN(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=layer_dim,
batch_first=True,
nonlinearity='tanh'
)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
h0 = torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).to(x.device)
h0 = h0.detach() # 断开历史梯度
out, _ = self.rnn(x, h0)
out = self.fc(out[:, -1, :])
return out
# 使用示例
model = RNNModel(input_dim=100, hidden_dim=128, layer_dim=2).to(device)
print(f"可训练参数数量:{sum(p.numel() for p in model.parameters() if p.requires_grad)}")四、训练流程
(一)超参数设置
1、BATCH_SIZE 与显存关系
BATCH_SIZE = 64 # 典型值:16 / 32 / 64 / 128
选择策略:
- GPU显存上限测试:
# 测试最大支持batch_size
for bs in [64, 128, 256]:
try:
dummy_input = torch.randn(bs, ...).to(device)
# 前向传播测试...
except RuntimeError as e: # CUDA out of memory
print(f"最大支持batch_size: {bs//2}")
break- 梯度累积技巧(当显存不足时):
accumulation_steps = 4 # 等效batch_size = BATCH_SIZE * accumulation_steps
loss.backward() # 梯度累加
if (i+1) % accumulation_steps == 0:
optimizer.step() # 参数更新
optimizer.zero_grad()2、EPOCHS迭代次数选择
EPOCHS = 30
选择依据:
| 现象 | 判断标准 | 应对措施 |
|---|---|---|
| 欠拟合 | 训练/验证loss均未收敛 | 增加epoch到100+ |
| 过拟合 | 验证loss上升而训练loss下降 | 早停(early stopping) |
| 正常收敛 | 验证loss连续3个epoch不下降 | 停止训练 |
早停法实现:
best_val_loss = float('inf')
patience = 5
counter = 0
for epoch in range(EPOCHS):
# ...训练与验证...
if val_loss < best_val_loss:
best_val_loss = val_loss
counter = 0
else:
counter +=1
if counter >= patience:
print("早停触发")
break(二)损失函数与优化器
1、损失函数
此处我选择的损失函数是:CrossEntropyLoss
因为前一篇博客已详细说明,感兴趣的同学可以查看下文(零基础入门PyTorch手写数字识别实战教程(含PyTorch环境搭建)_pytourch教程-CSDN博客)
2、SGD优化器参数更新
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)参数对比表:
| 参数 | 典型值范围 | 作用 |
|---|---|---|
| 基础学习率(lr) | 0.01-0.1 | 控制参数更新步长 |
| 动量(momentum) | 0.8-0.99 | 加速收敛,减少震荡 |
| 权重衰减 | 1e-4-1e-2 | L2正则化,防止过拟合 |
(三)验证阶段实现
1、model.eval() 模式切换
model.eval() # 等效于model.train(False)模式差异:
| 网络层类型 | train模式行为 | eval模式行为 |
|---|---|---|
| Dropout | 按概率随机失活神经元 | 所有神经元激活 |
| BatchNorm | 使用batch统计量归一化 | 使用运行均值/方差归一化 |
2、torch.max() 获取预测类别
_, predicted = torch.max(outputs.data, 1)维度解析:
outputs形状:(batch_size, num_classes)
dim=1 表示在类别维度取最大值
返回值:元组(max_values, max_indices)
(四)完整训练代码示例
for epoch in range(EPOCHS):
# 训练阶段
model.train()
for i, (images, labels) in enumerate(train_loader):
images = images.view(-1, 28*28).to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播与优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 验证阶段
model.eval()
with torch.no_grad():
total, correct = 0, 0
for images, labels in val_loader:
images = images.view(-1, 28*28).to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted.cpu() == labels).sum().item()
val_acc = 100 * correct / total
print(f'Epoch [{epoch+1}/{EPOCHS}], 验证准确率: {val_acc:.2f}%')五、训练结果
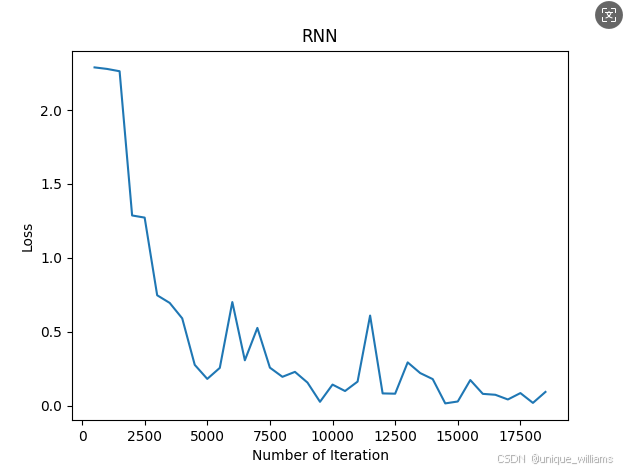
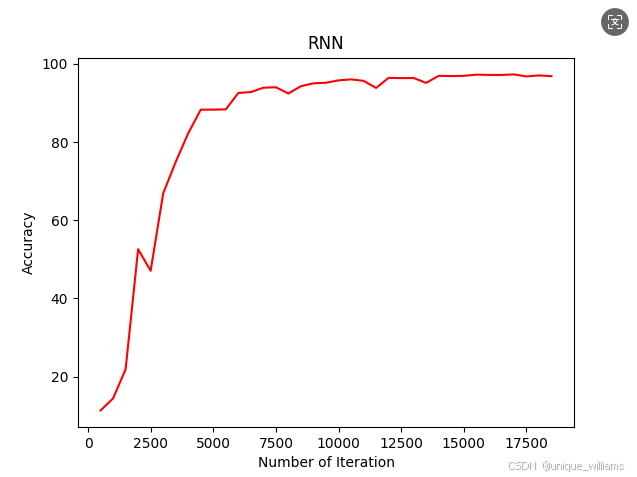
loop : 500, Loss : 2.288623809814453, Accuracy : 11.350000381469727
loop : 1000, Loss : 2.2782907485961914, Accuracy : 14.40999984741211
loop : 1500, Loss : 2.2626304626464844, Accuracy : 21.849998474121094
loop : 2000, Loss : 1.2865252494812012, Accuracy : 52.59000015258789
loop : 2500, Loss : 1.2720332145690918, Accuracy : 47.06999969482422
loop : 3000, Loss : 0.7464215159416199, Accuracy : 66.8699951171875
loop : 3500, Loss : 0.6946253776550293, Accuracy : 74.93000030517578
loop : 4000, Loss : 0.5901046991348267, Accuracy : 82.26000213623047
loop : 4500, Loss : 0.2754267454147339, Accuracy : 88.29999542236328
loop : 5000, Loss : 0.18038742244243622, Accuracy : 88.29999542236328
loop : 5500, Loss : 0.25494569540023804, Accuracy : 88.3699951171875
loop : 6000, Loss : 0.7004754543304443, Accuracy : 92.57999420166016
loop : 6500, Loss : 0.30635008215904236, Accuracy : 92.79999542236328
loop : 7000, Loss : 0.5255185961723328, Accuracy : 93.90999603271484
loop : 7500, Loss : 0.25656527280807495, Accuracy : 94.02999877929688
loop : 8000, Loss : 0.19449397921562195, Accuracy : 92.42999267578125
loop : 8500, Loss : 0.22800511121749878, Accuracy : 94.30999755859375
loop : 9000, Loss : 0.15559519827365875, Accuracy : 95.04000091552734
loop : 9500, Loss : 0.025378301739692688, Accuracy : 95.19000244140625
loop : 10000, Loss : 0.1418822556734085, Accuracy : 95.79000091552734
loop : 10500, Loss : 0.0983487218618393, Accuracy : 96.05000305175781
loop : 11000, Loss : 0.16205988824367523, Accuracy : 95.66999816894531
loop : 11500, Loss : 0.6092194318771362, Accuracy : 93.86000061035156
loop : 12000, Loss : 0.08218400925397873, Accuracy : 96.44000244140625
loop : 12500, Loss : 0.08028604090213776, Accuracy : 96.37000274658203
loop : 13000, Loss : 0.2921142578125, Accuracy : 96.4000015258789
loop : 13500, Loss : 0.21982696652412415, Accuracy : 95.1500015258789
loop : 14000, Loss : 0.17903035879135132, Accuracy : 96.95999908447266
loop : 14500, Loss : 0.014580165967345238, Accuracy : 96.88999938964844
loop : 15000, Loss : 0.027499081566929817, Accuracy : 96.94999694824219
loop : 15500, Loss : 0.172541081905365, Accuracy : 97.25999450683594
loop : 16000, Loss : 0.07915642112493515, Accuracy : 97.19000244140625
loop : 16500, Loss : 0.07294802367687225, Accuracy : 97.18000030517578
loop : 17000, Loss : 0.04114220291376114, Accuracy : 97.31999969482422
loop : 17500, Loss : 0.08439861983060837, Accuracy : 96.80000305175781
loop : 18000, Loss : 0.018059423193335533, Accuracy : 97.05999755859375
loop : 18500, Loss : 0.09231091290712357, Accuracy : 96.87000274658203
六、完整代码整理
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use('TkAgg')
# 下载mnist数据集
# 格式转换
trainsets = datasets.MNIST(root='./data',train=True,download=True,transform=transforms.ToTensor())
testsets = datasets.MNIST(root='./data',train=False,transform=transforms.ToTensor())
class_name = trainsets.classes # 查看类别
print(class_name)
# 查看数据集大小
print(trainsets.data.shape)
print(trainsets.targets.shape)
print(testsets.data.shape)
print(testsets.targets.shape)
# 定义超参数
BATCH_SIZE = 128 # 批处理数据大小
EPOCHS = 10 # 训练次数
# 创建数据集的可迭代对象
train_loader = torch.utils.data.DataLoader(dataset=trainsets,batch_size=BATCH_SIZE,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=testsets,batch_size=BATCH_SIZE,shuffle=True)
# 查看一批数据
for images, labels in test_loader:
print(images.shape)
print(labels.shape)
break # 查看第一个batch后退出
# 定义函数:显示一批数据
def imshow(inp, title = None):
# 通道放后面
inp = inp.numpy().transpose((1,2,0))
mean = np.array([0.485,0.456,0.406])
std = np.array([0.229,0.224,0.225])
inp = std * inp + mean # 恢复数据
inp = np.clip(inp,0,1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(10)
# 网格显示
out = torchvision.utils.make_grid(images)
imshow(out)
# 定义RNN模型
class RNN_Model(nn.Module):
def __init__(self,input_dim,hidden_dim,layer_dim,output_dim):
super(RNN_Model,self).__init__()
self.hidden_dim = hidden_dim
self.layer_dim = layer_dim
self.rnn = nn.RNN(input_dim,hidden_dim,layer_dim,batch_first=True,nonlinearity='relu')
# 定义全连接层
self.fc = nn.Linear(hidden_dim,output_dim)
def forward(self,x):
h0 = (torch.zeros(self.layer_dim,x.size(0),self.hidden_dim)
.to(device))
# 分离隐藏状态,避免梯度爆炸
out,hn = self.rnn(x,h0.detach())
# out,hn = self.rnn(x,h0.detach)
out = self.fc(out[:,-1,:])
return out
# 初始化模型
input_dim = 28 # 输入维度
hidden_dim = 100 # 隐藏层神经元
layer_dim = 2 # 2层RNN
output_dim = 10 # 输出维度
# 设备判断
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = RNN_Model(input_dim, hidden_dim, layer_dim, output_dim).to(device)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 输出模型参数信息
length = len(list(model.parameters()))
# 循环打印模型参数
for i in range(length):
print('参数:%d' %(i+1))
print(list(model.parameters())[i].size())
# 训练模型
sequence_dim = 28 # 序列长度
loss_list = [] # 保存loss
accuracy_list = [] # 保存accuracy
iteration_list = [] # 保存循环次数
iter = 0
for epoch in range(EPOCHS):
for i,(images,labels) in enumerate(train_loader):
model.train() # 申明训练
# 一个 batch 的数据转换成 RNN 的输入维度
images = (images.view(-1,sequence_dim,input_dim)
.requires_grad_().to(device))
labels = labels.to(device)
# 梯度清零
optimizer.zero_grad()
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs,labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 计数器+1
iter += 1
# 模型验证
if iter % 500 == 0:
model.eval()
# 验证准确度
correct = 0.0
total = 0.0
# 迭代测试集
for images,labels in test_loader:
images = (images.view(-1,sequence_dim,input_dim)
.requires_grad_().to(device))
# 验证模型
outputs = model(images)
# 获取预测概率最大的下标
predict = torch.max(outputs.data,1)[1]
# 统计label的数量
total += labels.size(0)
# 统计判断/预测正确的数量
correct += (predict == labels.to(device)).sum()
# 计算
accuracy = correct / total * 100
# 保存accuracy,loss,iteration
loss_list.append(loss.data)
accuracy_list.append(accuracy)
iteration_list.append(iter)
# 打印信息
print("loop : {}, Loss : {}, Accuracy : {}".format(iter,loss.item(),accuracy))
# 可视化 loss
plt.plot(
[i.cpu().numpy() if isinstance(i, torch.Tensor) else i for i in iteration_list],
[l.cpu().numpy() if isinstance(l, torch.Tensor) else l for l in loss_list]
)
plt.xlabel('Number of Iteration')
plt.ylabel('Loss')
plt.title('RNN')
plt.show()
# 可视化 accuracy
plt.plot(
[i.cpu().numpy() if isinstance(i, torch.Tensor) else i for i in iteration_list],
[l.cpu().numpy() if isinstance(l, torch.Tensor) else l for l in accuracy_list]
)
plt.xlabel('Number of Iteration')
plt.ylabel('Accuracy')
plt.title('RNN')
plt.savefig('RNN_MNIST.png')
plt.show()客官,看到这了点个赞再走呗~
您的支持就是我最大的动力!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 71
71 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)