基于卷积神经网络的文本分析研究【课程设计】
近些年,随着深度学习的火热发展,深度学习在文本分析和自然语言理解方面的应用和研究越来越多,本文情感分析作为文本分析的一个支流,也取得一定进展,情感分析的应用广阔,比如商品评价分析、影评分析和舆情监控等。本文基于卷积神经网络使用TextCNN对文本分析领域进行了一定探索和试验,经过试验表明,TextCNN可以进行文本分析。
基于卷积神经网络的文本分析研究
今天分享几个课程设计,这是第一个。
摘要:近些年,随着深度学习的火热发展,深度学习在文本分析和自然语言理解方面的应用和研究越来越多,本文情感分析作为文本分析的一个支流,也取得一定进展,情感分析的应用广阔,比如商品评价分析、影评分析和舆情监控等。本文基于卷积神经网络使用TextCNN对文本分析领域进行了一定探索和试验,经过试验表明,TextCNN可以进行文本分析。
关键词:卷积神经网络;CNN;TextCNN;文本分析
课程设计下载
一、前言
随着电商服务水平的提升,平台方为了扮演一个公平公正的中间角色,在自己的电商平台上推出了客户评论功能,并可以对其他消费者展示结果。在淘宝、京东、拼多多这些购物平台上有大量用户发表自己对于产品、客服、物流等的评价;在微博、微信、QQ等社交平台上,也有大量的用户发表自己对于某些社会热点、朋友圈等的评价。随着互联网在我国的普及,电子商务等应用场景呈现出从城市向农村蔓延,从青年人向老年人传递的态势,越来越多的人在互联网上进行购物、观影、娱乐、游戏、直播等活动,这些内容提供商为了提升客户服务水平,一般都提供有评论功能,消费者和用户可以在这些平台发表个人观点,并可以根据一定等级进行评价,其他用户和消费者可以根据他们的评价信息来甄别和遴选自己所需的内容,提升了搜索效率,增加了信息过滤的效率。针对不同类型的软件、网站,用户可以发表自己的观点,表达自己的情感,产生海量带有用户情感的文本数据。在互联网中,这些文本数据并不只是简单的文字,它还蕴藏着用户的情感,可以帮助企业以及用户做出相应决策,以网上购物为例,这些用户评论数据可以帮助商家做出对应决策,同时也可以为其他购物者提供参考。
二、文本向量化介绍
在图像识别等机器学习的应用中,图像的灰度可以直接进行数字化,不同的数字表示的灰度不一样,相近的数字表示的灰度比较相近。然而,在文本分析中,也需要把文本转换为在数字空间中表示的形式,需要把文本转换成二维数组,这一过程也称之为特征提取或者向量化。特征提取过程中,需要把语料库中的每一个字符都对应到数字空间中来,因此,文本向量化中,向量的维度和所有文本中的词汇量是一致的,可以使用字母顺序来排列,这也是最基本的词袋模型。北京2022冬奥会相关的主题的词汇量换成维度如图1所示。
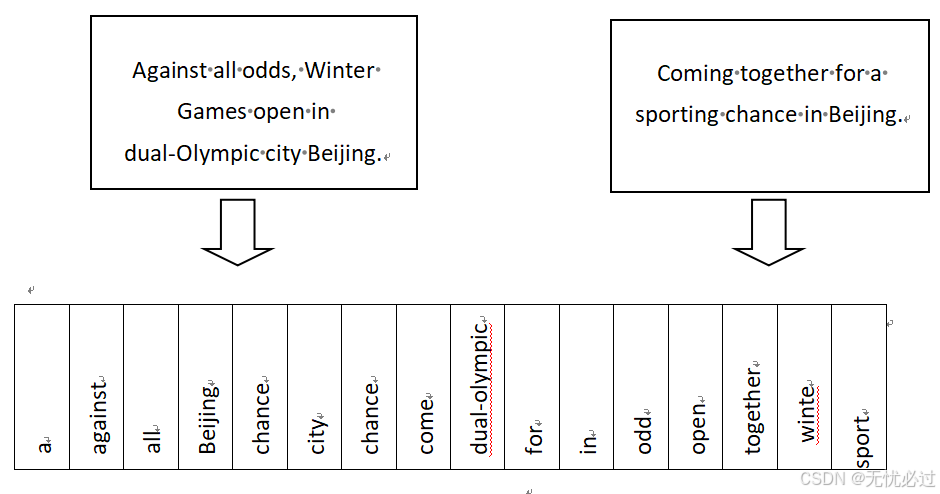
图1 词向量维度表示
词频向量也是一种常见的向量化方式,具体的方式是首先正向扫描所有的文本,生成向量的维度,使得每一个词语都在向量中有对应的表示。然后将每一个段落和句子都按照向量化方式表示,一个句子向量化的方法是扫描这个句子,然后把这个句子中的词语对应到向量上来,如果一个句子中有一个词语出现了很多次,在词频向量表示的时候这个数字就是词语出现的次数。
词频向量的表示方法可以表示文本,但在实践中却会出现问题,比如一些语气词语和辅助词在文本的语意表示中作用不大,但是其在文本中出现的次数却很多,因此,并不能真正反应出文本的真实语意。
为了解决上述问题,又提出了使用独热编码(One - Hot 编码)的方式来向量化文本,独热编码技术中,无论文本中的词语出现了多少次,都用“1”来表示,如果相应的词语没有出现,就用“0”来表示。独热编码技术可以有效解决那些无用但是出现次数很多的词语,解决了自然语言中存在的非对称问题。
词频-逆文档编码(TF - IDF 编码)也是一种向量化方式,它的出现是因为有些术语在文档中出现的次数很少,但是其却有很重要的意义,比如在北京2022冬奥会的短道速滑中,“北京”、“加速”、“裁判”等词语出现的次数很频繁,但是却意义不大,但是“冲撞”虽然只出现了一次却可能有重要意义。词频-逆文档的计算公式如下式1所示。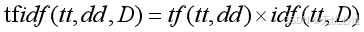
(1)
其中,tf代表的是词频,词频就是在一个文档中具有统计意义的出现的次数。而逆文档频率idf表示如2所示。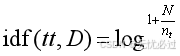
(2)
上面的式子中,N是指所有文档的数量,nt就是统计所有的文档中有该词项的次数。
上述技术虽然可以对文本进行向量化,但是却无法表示词语之间的相似性,这些方法生成的向量都是正数,如果基于文本中的所有词语生成词向量,并附带有词语之间的相似性那在很多场景下就会更有用。
三、实验原理以及试验过程
深度神经网络一般由一个输入层、若干个隐藏层、一个输出层构成,输入层是原始数据,可以是一个图像的表示数据,也可以是文本的向量化表示数据。隐藏层一般有若干层,隐藏层主要用来拟合数据,经过隐藏层的层层转换和表示,最终可以输出结果,可以是离散结果也可以是连续结果,如果是离散结果一般是分类问题,如果是连续结果则是回归问题,神经网络更倾向于表示分类问题,进行模式识别任务。
当原始数据的维度增多的时候,比如文本的表示,文本的维度是文本中所有出现的字或者词剔除重复之后的个数,可以通过一定手段进行压缩,比如相似词语归并,但是即使是这样,由于文本语义的丰富性和复杂性,当文本本身表示的领域问题复杂的时候,其向量的维度自然不会低。当一个输入层的数据维度很高的时候,神经网络的训练在相邻两层进行计算的时候就会出现维数灾难。一般可以使用一定大小的滤波器在一定程度上消除维度灾难问题。形式化表示如下,神经网络中当某一层的维度是m的时候,可以构造n维的滤波器,使得上一层的m维数据和下层的n维数据有一定的函数映射关系,从而大幅降低神经网络的计算量,提升神经网络的训练效率。从m维数据中按照自上而下,自左而右的方式用n维数据去扫描表示,这种映射和表示方式也称之为局部感受野。卷积神经网络就是基于这种思想发展起来的神经网络,其滤波器的表示如图2所示。
图2 n维滤波器过滤m维数据
上图中的原始数据是m维,滤波器基于n×n维原始数据进行过滤,过滤器是m×m(这里m=3)的滤波器,在下一层就生成了m-n+1维的数据。滤波器有时候也被叫做核函数,卷积的核心可以认为是核函数,它就是在此基础上发展的。
卷积神经网络是在深度神经网络的基础之上,由输入层、卷积层、激活函数、池化层和全连接层构成的前馈型神经网络。输入层和神经网络中的输入层含义一致,前述滤波器主要在卷积层工作,激活函数是一类具有映射关系的过程或者函数,典型的有ReLU函数,池化层是指利用降低采样率的方式去表示上一层的数据,一般有平均池化函数和最大池化函数,而全连接层在整个网络的尾部,也算是隐藏层中的一部分。
在机器学习中,大多数时候CNN都应用在计算机CV领域,然而,在2014年,Yoon Kim基于CNN做了某些调整和优化,使得CNN可以应用到文本分析和自然语言理解领域,他提出的模型就是TextCNN。TextCNN是一个只有一层卷积、一层max-pooling(最大池化方法),最后将输出通过softmax来分类的一种CNN分类方法。其输入层采用词嵌入向量表示。
实验过程描述如下,首先,确定要训练的数据集,本文采用公开数据集IMDB。IMDB是美国亚马逊公司下设的一个互联网公司的电影评论网站,这个网站实时更新观众对电影的评论,这些评论涉及电影的各个方面,是目前全球使用最广泛的电影评论数据集。选用IMDB数据集的原因有三,一是这个数据集收集数据全面,丰富,非常适合做文本分析,是不可多见的公开数据集;二是因为这个数据集中含有部分已经标记好的数据,这非常适合本课题的有师训练,由于标记是一项耗时耗资的巨大的工程,本课题无法独立完成,因此依靠本数据集可以解决标记问题;三是数据集质量高,没有由于“水单”、“刷单”等问题导致的爬取到的低质量数据。其次,利用上一章节中提到的Word2Vec的技术和算法完成数据集的向量表示,并嵌入到模型的输入层。接着设定模型核函数,这里的3维核函数、4维核函数就对应3-gram、4-gram等文本模型。然后设定其他参数,进行训练。训练完毕,采用混淆矩阵表示结果。
TextCNN实验的训练结果如表1所示。
表1 TextCNN训练结果
| 算法 | 准确率 | 召回率 | F1 |
|---|---|---|---|
| textCNN | 87.45 | 89.34 | 87.4 |
参考文献
[1]Yann LeCun,Yoshua Bengio,Geoffrey Hinton.Deep learning[J].Nature,2015
[2]XIE R B, YUAN X C, LIU Z Y, et al. Lexical Sememe Prediction via Word Embeddings and Matrix Factorization[C]. //Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Australia, August 19-25, 2017: 4200-4206.
[3]YAO T F, LOU D C. Study of discrimination of Chinese emotional words meaning tendency[C]. //International Conference on Chinese Computing, Wuhan, China, August 21-24, 2007: 221- 225.
[4]Baccianella S, Esuli A, Sebastiani F.SentiWordNet3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining[C]. //Proceedings of the Seventh conference on International Language Resources and Evaluation, Valletta,Malta, May 17-23, 2010: 2200-2204.
[5] Zhang X , Zhao J , Lecun Y . Character-level Convolutional Networks for Text Classification[J]. MIT Press, 2015.
[6]栗雨晴, 礼欣, 韩煦, 等. 基于双语词典的微博多类情感分析方法[J]. 电子学报, 2016,44(9): 2068-2073.
[7]洪巍, 李敏. 文本情感分析方法研究综述[J]. 计算机工程与科学, 2019,41(04): 750-757.
[8]陶杨明. 基于深度学习的细粒度文本情感分析研究[D]. 浙江:浙江工商大学, 2020.
汤凌燕, 熊聪聪, 王嫄, 等. 基于深度学习的短文本情感倾向分析综述[J]. 计算机科学与探索, 2021.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)