零基础入门PyTorch肺部感染案例实践(ResNet迁移学习)——超详细保姆级教程系列
本文为零基础开发者提供PyTorch肺部感染分类实战指南,基于ResNet迁移学习技术,详解从数据集预处理(随机裁剪/旋转/色彩增强)、模型微调(池化层重构+全连接层改造)到训练流程搭建(梯度管理/损失优化/TensorBoard监控)的全链路实践,重点解决Loss震荡、GPU显存不足等常见问题,最终通过可视化训练结果验证模型效果,配套完整项目源码助力医疗影像分析入门。
目录
五、获取并微调预训练模型(替代ResNet池化层与全连接层)
模型训练流程
- 1、数据集预处理
- 2、加载数据集
- 3、获取微调预训练模型
- 4、定义训练方法
- 5、定义测试方法
- 6、开始训练
一、项目准备
(一)数据集下载(肺部感染数据集)
Kaggle官网下载地址:Chest X-Ray Images (Pneumonia) | Kaggle
嘻嘻,当然你也可以网盘下载:Chest X-Ray数据集下载——百度网盘
呜呜,数据集1.14G,上传蓝奏云不太方便哩
下载后解压后如下图所示(注意放到代码所在的同级文件夹下哦~):
数据集共分三个类别,如下所示:
| 数据类别 | NORMAL | PNEUMONIA |
| train | 1341 | 3875 |
| val | 8 | 8 |
| test | 234 | 390 |
(二)项目必要库
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torchvision import transforms, datasets, models, utils
from torchsummary import summary # 可视化训练过程
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
import os
import seaborn as sns
import pandas as pd
from mlxtend.plotting import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from PIL import Image本项目torch、numpy、torchvision、torchsummary、seaborn、pandas、mlxtend、sklearn需要提前下载哦~
除了Pytorch,其他都可以在当前虚拟环境下直接使用 pip 安装。
pip install 包名PyTorch未安装的同学可以参考下方博客哦~零基础入门PyTorch手写数字识别实战教程(含PyTorch环境搭建)——CNN篇_阿里云 cu126-CSDN博客![]() https://blog.csdn.net/2401_83325465/article/details/145535002
https://blog.csdn.net/2401_83325465/article/details/145535002
二、数据集预处理(构建transforms)
(一)不同数据的预处理
本数据集共分为'train','val','test'三种数据,其中我们只需要对'train'的数据进行随机化处理,其他两种数据只需要标准化处理即可
随机化处理包括但不限于:随机长宽比裁剪,随机角度旋转,亮度、对比度和饱和度随机改变,随机水平翻转。
1、随机长宽比裁剪
功能:随机长宽比裁剪原始图片, 表示随机 crop 出来的图片会在的 0.08 倍至 1.1 倍之间
transforms.RandomResizedCrop(size=300, scale=(0.8, 1.1))2、 随机角度旋转
功能:根据 degrees 随机旋转一定角度, 则表示在(-10,+10)度之间随机旋转
transforms.RandomRotation(degrees=10)3、亮度、对比度和饱和度随机改变
功能:修改亮度、对比度和饱和度
transforms.ColorJitter(0.4, 0.4, 0.4)4、随机水平翻转
功能:水平翻转
transforms.RandomHorizontalFlip()5、中心裁剪
功能:根据给定的 size 从中心进行裁剪
transforms.CenterCrop(size=256)6、转换数据格式
功能:将数据从 numpy 格式转换成 tensor
transforms.ToTensor()7、标准化处理
功能:对数据按通道进行标准化处理
transforms.Normalize([0.485, 0.456, 0.406], # mean
[0.229, 0.224, 0.225]) # std (二)处理源代码
# 分为为train, val, test定义transform
image_transforms = {
'train' : transforms.Compose([
transforms.RandomResizedCrop(size=300, scale=(0.8, 1.1)),
transforms.RandomRotation(degrees=10),
transforms.ColorJitter(0.4, 0.4, 0.4),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'val' : transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
]),
'test' : transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
}三、加载数据集
(一)从文件中读取数据
由于我们已经提前创建好了 transforms 通道,因此此处只需调用ImageFolder函数就行啦!
datasets = {
'train' : datasets.ImageFolder(train_dir, transform=image_transforms['train']), # 读取train中的数据集,并transform
'val' : datasets.ImageFolder(val_dir, transform=image_transforms['val']), # 读取val中的数据集,并transform
'test' : datasets.ImageFolder(test_dir, transform=image_transforms['test']) # 读取test中的数据集,并transform
}(二)通过 DataLoader 读取数据
dataloaders = {
'train' : DataLoader(datasets['train'], batch_size=BATCH_SIZE, shuffle=True), # 训练集
'val' : DataLoader(datasets['val'], batch_size=BATCH_SIZE, shuffle=True), # 验证集
'test' : DataLoader(datasets['test'], batch_size=BATCH_SIZE, shuffle=True) # 测试集
}(三)创建 Label 键值对
此处是为了提高后续代码的可读性。
LABEL = dict((v, k) for k, v in datasets['train'].class_to_idx.items())四、定义日志函数,记录错误分类的图片
在模型训练过程中,记录错误分类的样本对改进模型性能具有重要意义。本章将详细讲解如何使用TensorBoard的日志功能记录错误分类的肺部影像,帮助后续进行错误分析。
(一)日志系统搭建
我们通过 tb_writer()函数创建 TensorBoard 日志记录器:
from torch.utils.tensorboard import SummaryWriter
import time
def tb_writer():
timestr = time.strftime("%Y%m%d_%H%M%S") # 生成时间戳
writer = SummaryWriter('logdir/' + timestr) # 创建带时间戳的日志目录
return writer实现特点:
- 使用
%Y%m%d_%H%M%S时间格式确保日志目录唯一性 - 日志存储在
logdir /目录下(需提前创建该目录) - 返回的 writer 对象用于后续所有日志记录
(二)错误分类记录函数
核心函数 misclassified_images 实现错误样本记录:
def misclassified_images(pred, writer, target, images, output, epoch, count=10):
# 定位错误分类样本
misclassified = (pred != target.data)
# 记录前count个错误样本
for index, image_tensor in enumerate(images[misclassified][:count]):
# 生成带语义的图片名称
img_name = f'Epoch:{epoch}-->Predict:{LABEL[pred[misclassified].tolist()[index]]}-->Actual:{LABEL[target.data[misclassified].tolist()[index]]}'
# 写入TensorBoard
writer.add_image(img_name, image_tensor, epoch)参数说明:
pred: 模型预测结果target: 真实标签images: 原始图像张量count: 每个epoch最多记录的错误样本数
(三)集成到训练流程
在训练主函数中调用记录函数:
def train_epochs(...):
for epoch in range(epochs):
# 训练验证流程...
# 在适当位置调用错误分类记录
with torch.no_grad():
outputs = model(images)
_, preds = torch.max(outputs, 1)
misclassified_images(preds, writer, labels, images, outputs, epoch)
writer.flush() # 确保日志写入磁盘五、获取并微调预训练模型(替代ResNet池化层与全连接层)
(一)获取预训练模型
我们采用经典的ResNet50作为基础模型,通过PyTorch官方提供的预训练权重进行初始化:
model = models.resnet50(pretrained=True)
这里使用pretrained=True参数会自动下载在ImageNet数据集上预训练的模型参数。对于医学图像任务,预训练模型已经具备良好的特征提取能力,特别适合数据量相对较小的肺部感染分类任务。
冻结参数操作:
for param in model.parameters():
param.requires_grad = False
通过将requires_grad设为False,可以冻结所有网络层的参数更新。这样做既能保留预训练模型的特征提取能力,又能显著减少训练时的计算量。
(二)改进池化层结构
原ResNet的池化层结构较为简单,我们通过自定义的AdaptiveConcatPool2d实现特征增强:
改进方案解析
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super().__init__()
self.avgPooling = nn.AdaptiveAvgPool2d(size or (1,1))
self.maxPooling = nn.AdaptiveMaxPool2d(size or (1,1))
def forward(self, x):
return torch.cat([self.maxPooling(x), self.avgPooling(x)], dim=1)| 设计特点 | 作用说明 |
|---|---|
| 双路池化 | 同时保留最大响应特征和平均分布特征 |
| 自适应池化 | 自动调整池化核尺寸,适配不同尺寸的特征图 |
| 通道维度拼接 | 将两种池化结果在通道维度拼接(dim=1),使特征信息量翻倍 |
为何改进池化层? 最大池化擅长捕捉显著特征,平均池化反映整体分布特征。肺部感染病灶的形态多样性需要这种互补的特征表达方式。
(三)重构全连接层
原模型的1000类分类头不适合二分类任务,我们重新设计分类器:
model.fc = nn.Sequential(
nn.Flatten(),
nn.BatchNorm1d(4096),
# 输入特征维度计算:ResNet50最终特征图通道数2048 * 双路池化2 = 4096
nn.Dropout(0.5),
nn.Linear(4096, 512),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 2),
nn.LogSoftmax(dim=1)
)关键组件说明
-
Batch Normalization
加速训练收敛,缓解梯度消失/爆炸问题。在Flatten后立即使用,标准化高维特征 -
Dropout正则化
设置0.5的丢弃概率,强制网络学习冗余特征,有效防止过拟合 -
阶梯式降维
从4096→512→2的维度设计,逐步压缩特征空间,保留关键分类信息 -
LogSoftmax输出
配合NLLLoss损失函数,直接输出对数概率,提升数值稳定性
(四)模型微调策略
本方案采用部分微调策略:
- 冻结特征提取器:保留卷积层的预训练参数,防止小数据过拟合
- 微调分类器:仅训练新增的池化层和全连接层参数
- 可扩展方案:若数据量允许,可解冻最后2-3个卷积块进行微调
通过这种设计,既利用了预训练模型的强大特征提取能力,又让模型能够学习到适应特定任务的分类决策边界。这种策略在医学影像处理中尤为有效,因为底层特征(如边缘、纹理)在不同图像领域具有通用性,而高层特征组合需要针对具体病症进行调整。
(五)截取源码
自适应池化层:
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super(AdaptiveConcatPool2d,self).__init__()
size = size or (1, 1) # kernel大小
# 自适应算法能够自动帮助我们计算核的大小和每次移动的步长。
self.avgPooling = nn.AdaptiveAvgPool2d(size) # 自适应平均池化
self.maxPooling = nn.AdaptiveMaxPool2d(size) # 最大池化
def forward(self, x):
# 拼接avg和max
return torch.cat([self.maxPooling(x), self.avgPooling(x)], dim=1)迁移学习:
# 迁移学习:获取预训练模型,并替换池化层和全连接层
def get_model():
# 获取欲训练模型 restnet50
model = models.resnet50(pretrained=True)
# 冻结模型参数
for param in model.parameters():
param.requires_grad = False
# 替换最后2层:池化层和全连接层
# 池化层
model.avgpool = AdaptiveConcatPool2d()
# 全连接层
model.fc = nn.Sequential(
nn.Flatten(), # 拉平
nn.BatchNorm1d(4096), # 加速神经网络的收敛过程,提高训练过程中的稳定性
nn.Dropout(0.5), # 丢掉部分神经元
nn.Linear(4096, 512), # 全连接层
nn.ReLU(), # 激活函数
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 2), # 2个输出
nn.LogSoftmax(dim=1) # 损失函数:将input转换成概率分布的形式,输出2个概率
)
return model六、定义训练方法(理解迁移学习的核心训练流程)
本环节将详细解析ResNet迁移学习的核心训练流程,通过代码逐层拆解训练方法的设计原理,帮助读者掌握PyTorch模型训练的核心技术点。
(一)训练函数整体架构
def train_val(model, device, train_loader, val_loader, optimizer, criterion, epoch, writer):
# 训练阶段
model.train()
[...] # 训练逻辑
# 验证阶段
model.eval()
[...] # 验证逻辑
return train_loss, val_loss, val_acc关键设计要点:
- 双阶段架构:集成训练与验证流程,实时监控模型表现
- 设备部署:
device参数实现CPU/GPU自适应部署 - 日志记录:TensorBoard的
SummaryWriter记录训练指标 - 返回值设计:同时返回训练损失、验证损失、验证准确率
(二)训练阶段详解
1、梯度清零(Zero Grad)
optimizer.zero_grad()
- 必要性:PyTorch默认梯度会累计,不清零会导致梯度异常叠加
- 实现原理:将参数
requires_grad=True的张量梯度归零
2、前向传播
outputs = model(images) # ResNet特征提取
loss = criterion(outputs, labels)
- ResNet特性:使用预训练模型的卷积层提取高级特征
- 损失计算:交叉熵损失自动处理分类概率分布
3、反向传播
loss.backward()
- 计算图构建:自动微分系统构建计算图
- 梯度计算:
沿计算图反向传播
4、 参数更新
optimizer.step()- 优化策略:Adam/SGD等优化器执行参数更新
- 更新公式:
(三) 验证阶段设计
1、评估模式切换
model.eval()
with torch.no_grad():
- 模式区别:关闭Dropout和BatchNorm的随机性
- 内存优化:
no_grad上下文管理器禁用梯度计算
2、 准确率计算
_, pred = torch.max(outputs, 1) # 获取预测类别
correct = pred.eq(labels.view_as(pred)) # 对比标签
accuracy = torch.mean(correct.float()) # 计算正确率
- 维度处理:
dim=1表示在类别维度取最大值 - 类型转换:布尔张量转FloatTensor计算均值
(四)损失计算技巧
1、累计损失计算
total_loss += loss.item() * images.size(0)
train_loss = total_loss / len(train_loader.dataset)
- 设计原理:单个样本损失的平均值 × 样本数量
- 数学表达:
2、损失类型对比
| 损失类型 | 计算公式 | 适用场景 |
|---|---|---|
| 交叉熵损失 | 多分类问题 | |
| MSE损失 | 回归问题 |
(五)训练监控策略
1、TensorBoard集成
writer.add_scalar('Training Loss', train_loss, epoch)
writer.flush()
- 可视化优势:实时观测损失曲线变化
- 调试应用:识别过拟合/欠拟合现象
2、验证指标分析
val_acc = val_acc / len(val_loader.dataset)
- 早停依据:连续多个epoch验证损失无改善时终止训练
- 模型选择:保存验证集表现最佳的模型参数
七、定义测试方法
(一)测试函数框架解析
def test(model, device, test_loader, criterion, epoch, writer):
model.eval()
total_loss = 0.0
correct = 0.0
# ...(后续代码)参数说明:
model:训练完成的PyTorch模型device:计算设备(GPU/CPU)test_loader:测试集数据加载器criterion:损失函数epoch:当前训练轮次writer:TensorBoard记录器
(二)截取源码
# 定义测试函数
def test(model, device, test_loader, criterion, epoch, writer):
model.eval()
total_loss = 0.0
correct = 0.0 # 正确数
with torch.no_grad():
for batch_id, (images, labels) in enumerate(test_loader):
images, labels = images.to(device), labels.to(device)
# 输出
outputs = model(images)
# 损失
loss = criterion(outputs, labels)
# 累计损失
total_loss += loss.item()
# 获取预测概率最大值的索引
_, predicted = torch.max(outputs, dim=1)
# 累计正确预测的数
correct += predicted.eq(labels.view_as(predicted)).sum().item()
# 错误分类的图片
misclassified_images(predicted, writer, labels, images, outputs, epoch)
# 平均损失
avg_loss = total_loss / len(test_loader.dataset)
# 计算正确率
accuracy = 100 * correct / len(test_loader.dataset)
# 将test的结果写入write
writer.add_scalar("Test Loss", total_loss, epoch)
writer.add_scalar("Accuracy", accuracy, epoch)
writer.flush()
return total_loss, accuracy八、定义训练流程
(一)设备配置与模型部署
代码实现:
# 检测GPU可用性
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"当前运行设备: {device.type}")
# 模型部署到指定设备
model = get_model().to(device)核心要点:
-
设备检测逻辑
torch.cuda.is_available()自动检测CUDA环境,优先使用GPU加速训练。对于医学图像这类高分辨率数据,GPU可显著提升卷积运算效率。 -
模型部署方法
.to(device)操作将模型参数和缓存数据统一迁移到指定设备。对于ResNet等大型模型,必须使用GPU才能保证训练效率。 -
设备兼容性
代码自动适配CPU/GPU环境,保证在没有显卡的机器上仍可运行(但训练速度会显著下降)
(二)损失函数与优化器配置
代码实现:
criterion = nn.NLLLoss() # 负对数似然损失
optimizer = optim.SGD(model.parameters(), lr=0.001) # 随机梯度下降选择依据:
-
损失函数
- NLLLoss适用于分类问题,需配合LogSoftmax使用(通常在模型最后一层实现)
- 对于医学二分类问题(如感染/未感染),BCEWithLogitsLoss也是常用选择
-
优化器配置
- SGD虽然收敛速度较慢,但在医学图像分类中表现稳定
- 建议后期优化可尝试Adam优化器(需调整学习率)
-
学习率设定
初始学习率0.001是迁移学习的常用设置,后续可通过学习率调度器动态调整
(三)训练循环核心逻辑
def train_epochs(model, device, dataloaders, criterion, optimizer, epochs, writer):
# 训练过程监控表头
header_format = "{0:>15} | {1:>15} | {2:>15} | {3:>15} | {4:>15} | {5:>15}"
print(header_format.format('Epoch', 'Train Loss', 'val_loss', 'val_acc', 'Test Loss', 'Test_acc'))
best_loss = np.inf # 记录最优损失值
for epoch in range(epochs):
# 训练验证阶段
train_loss, val_loss, val_acc = train_val(model, device, dataloaders['train'],
dataloaders['val'], optimizer, criterion, epoch, writer)
# 测试阶段
test_loss, test_acc = test(model, device, dataloaders['test'], criterion, epoch, writer)
# 模型保存策略
if test_loss < best_loss:
best_loss = test_loss
torch.save(model.state_dict(), 'model.pth') # 保存最优模型参数
# 实时输出训练指标
print(header_format.format(epoch, round(train_loss,4), round(val_loss,4),
round(val_acc,4), round(test_loss,4), round(test_acc,4)))
writer.flush() # 确保日志写入(四)常见问题排查
-
Loss不下降
- 检查学习率是否过小
- 验证数据预处理是否正确
- 确认模型最后一层是否添加了LogSoftmax
-
验证集准确率震荡
- 减小学习率
- 增加批量大小(batch size)
- 添加正则化项(如Dropout)
-
GPU内存不足
torch.cuda.empty_cache() # 手动释放缓存 # 或减小batch_size dataloaders = DataLoader(..., batch_size=16)
九、训练结果结果
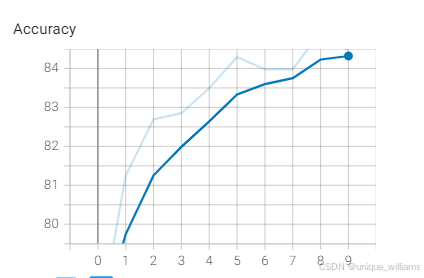
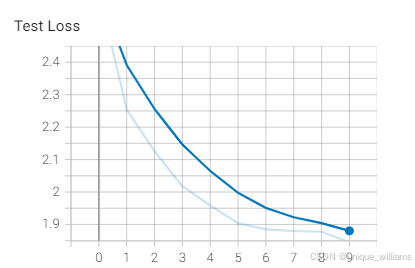
(一)训练结果(数据版)
| Epoch | Train Loss | Val Loss | Val Acc | Test Loss | Test Acc |
| 0 | 0.69078 | 0.48474 | 87.5 | 2.58762 | 78.69 |
| 1 | 0.58548 | 0.41656 | 81.25 | 2.28625 | 80.45 |
| 2 | 0.53246 | 0.40368 | 75 | 2.22654 | 81.25 |
| 3 | 0.48331 | 0.38487 | 81.25 | 2.14328 | 82.53 |
| 4 | 0.45751 | 0.36613 | 81.25 | 2.08483 | 83.17 |
| 5 | 0.44494 | 0.36147 | 81.25 | 2.0495 | 83.49 |
| 6 | 0.42641 | 0.34505 | 75 | 1.97448 | 83.97 |
| 7 | 0.41421 | 0.34601 | 75 | 1.95305 | 84.62 |
| 8 | 0.40089 | 0.34569 | 75 | 1.93494 | 84.78 |
| 9 | 0.39829 | 0.33759 | 75 | 1.93299 | 84.94 |
(二)使用TensorBoard可视化结果
1、安装tensorboard
TensorBoard 原本是 TensorFlow 的附属工具,但也可以独立安装,可以使用如下指令安装Tensorboard。
pip install tensorboard2、查看是否安装成功
编译器中运行如下代码:
from torch.utils.tensorboard import SummaryWriter入不提示错误,则安装成功,若提示错误可参考下方博客。
3、启动Tensorboard
进入项目运行的虚拟环境,在控制台输入如下指令:
tensorboard --logdir=<directory_name>注意:此处的 <directory_name>为日志存储的地址,一般不能出现空格或中文符号。
运行成功后,会出现如下提示:
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.18.0 at http://localhost:6006/ (Press CTRL+C to quit)接着我们就可以通过浏览器打开http://localhost:6006/进行查看了。
打开后会如下显示:
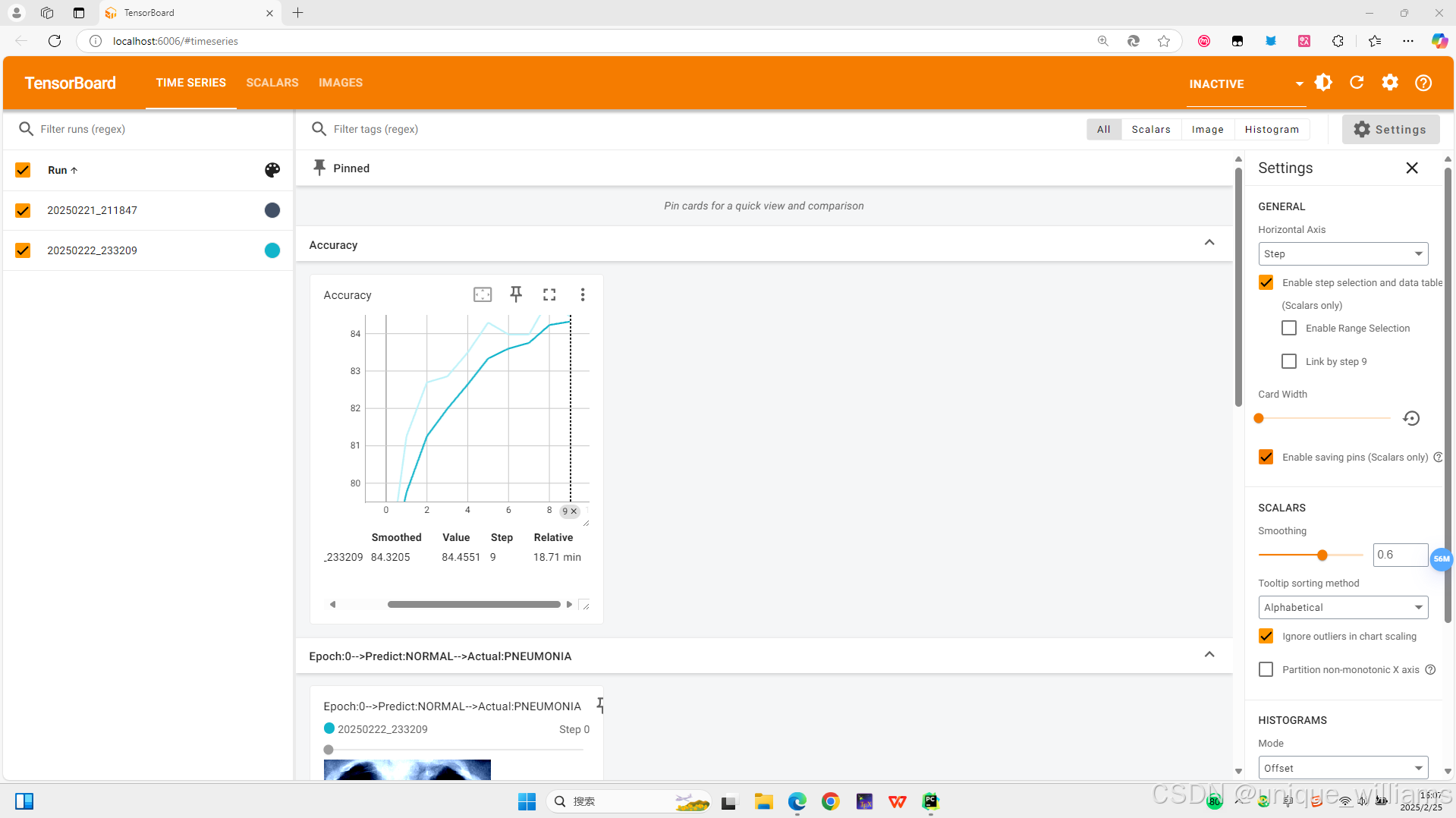
4、Tensorboard显示训练结果
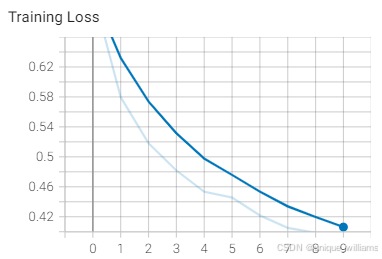
预测结果错误的图片记录:
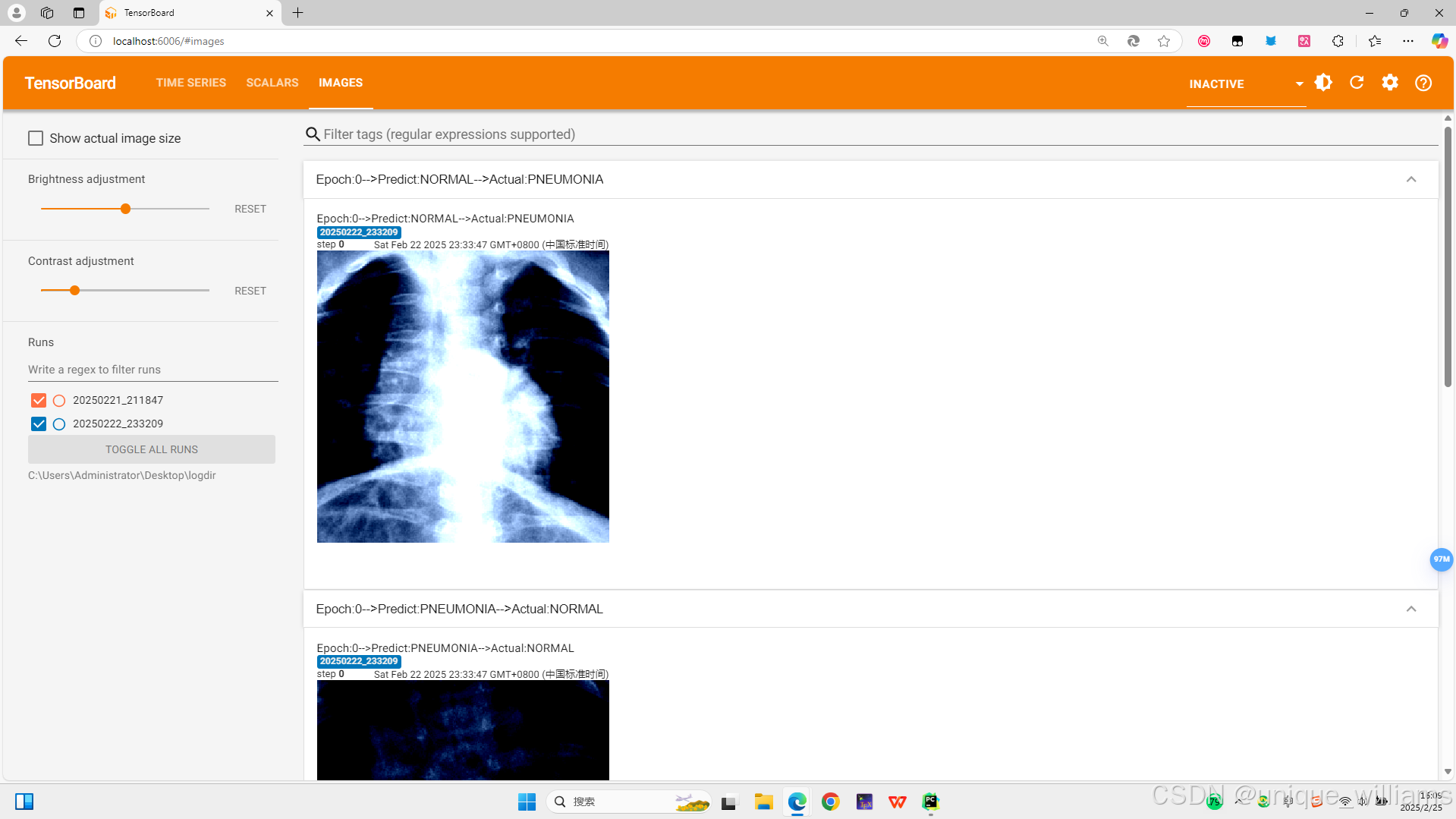

十、项目源码
# 导入必要的库
import torch
import torch.nn as nn
import numpy as np
import torch.optim as optim
from torchvision import transforms, datasets, models, utils
from torchsummary import summary # 可视化训练过程
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
import os
import seaborn as sns
import pandas as pd
from mlxtend.plotting import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from PIL import Image
# 分为为train, val, test定义transform
image_transforms = {
'train' : transforms.Compose([
transforms.RandomResizedCrop(size=300, scale=(0.8, 1.1)), #功能:随机长宽比裁剪原始图片, 表示随机crop出来的图片会在的0.08倍至1.1倍之间
transforms.RandomRotation(degrees=10), #功能:根据degrees随机旋转一定角度, 则表示在(-10,+10)度之间随机旋转
transforms.ColorJitter(0.4, 0.4, 0.4), #功能:修改亮度、对比度和饱和度
transforms.RandomHorizontalFlip(), #功能:水平翻转
transforms.CenterCrop(size=256), #功能:根据给定的size从中心裁剪,size - 若为sequence,则为(h,w),若为int,则(size,size)
transforms.ToTensor(), #numpy --> tensor
# 功能:对数据按通道进行标准化(RGB),即先减均值,再除以标准差
transforms.Normalize([0.485, 0.456, 0.406],# mean
[0.229, 0.224, 0.225])# std
]),
'val' : transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],# mean
[0.229, 0.224, 0.225])# std
]),
'test' : transforms.Compose([
transforms.Resize(300),
transforms.CenterCrop(256),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],# mean
[0.229, 0.224, 0.225])# std
])
}
# 加载数据集
# 数据集所在目录路径
data_dir = './chest_xray/'
# train路径
train_dir = data_dir + 'train/'
# val路径
val_dir = data_dir + 'val/'
# test路径
test_dir = data_dir + 'test/'
# 从文件中读取数据
datasets = {
'train' : datasets.ImageFolder(train_dir, transform=image_transforms['train']), # 读取train中的数据集,并transform
'val' : datasets.ImageFolder(val_dir, transform=image_transforms['val']), # 读取val中的数据集,并transform
'test' : datasets.ImageFolder(test_dir, transform=image_transforms['test']) # 读取test中的数据集,并transform
}
# 定义BATCH_SIZE
BATCH_SIZE = 128 # 每批读取128张图片
# DataLoader : 创建iterator, 按批读取数据
dataloaders = {
'train' : DataLoader(datasets['train'], batch_size=BATCH_SIZE, shuffle=True), # 训练集
'val' : DataLoader(datasets['val'], batch_size=BATCH_SIZE, shuffle=True), # 验证集
'test' : DataLoader(datasets['test'], batch_size=BATCH_SIZE, shuffle=True) # 测试集
}
# 创建label的键值对
LABEL = dict((v, k) for k, v in datasets['train'].class_to_idx.items())
# 导入SummaryWriter
from torch.utils.tensorboard import SummaryWriter
# SummaryWriter() 向事件文件写入事件和概要
# 定义日志路径
log_path = 'logdir/'
# 定义函数:获取tensorboard writer
def tb_writer():
timestr = time.strftime("%Y%m%d_%H%M%S") # 时间格式
writer = SummaryWriter(log_path+timestr) # 写入日志
return writer
writer = tb_writer()
# 第1种方法:显示部分图片集
images, labels = next(iter(dataloaders['train'])) # 获取到一批数据
# 定义图片显示方法
def imshow(img):
img = img / 2 + 0.5 # 逆正则化
np_img = img.numpy() # tensor --> numpy
plt.imshow(np.transpose(np_img, (1, 2, 0))) # 改变通道顺序
plt.show()
grid = utils.make_grid(images) # make_grid的作用是将若干幅图像拼成一幅图像
imshow(grid) # 展示图片
# 在summary中添加图片数据
writer.add_image('X-Ray grid', grid, 0) # add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')
writer.flush() # 把事件文件写入到磁盘
# 记录错误分类的图片
def misclassified_images(pred, writer, target, images, output, epoch, count=10):
misclassified = (pred != target.data) # 判断是否一致
for index, image_tensor in enumerate(images[misclassified][:count]):
img_name = 'Epoch:{}-->Predict:{}-->Actual:{}'.format(epoch, LABEL[pred[misclassified].tolist()[index]],
LABEL[target.data[misclassified].tolist()[index]])
writer.add_image(img_name, image_tensor, epoch)
# 自定义池化层
class AdaptiveConcatPool2d(nn.Module):
def __init__(self, size=None):
super(AdaptiveConcatPool2d,self).__init__()
size = size or (1, 1) # kernel大小
# 自适应算法能够自动帮助我们计算核的大小和每次移动的步长。
self.avgPooling = nn.AdaptiveAvgPool2d(size) # 自适应平均池化
self.maxPooling = nn.AdaptiveMaxPool2d(size) # 最大池化
def forward(self, x):
# 拼接avg和max
return torch.cat([self.maxPooling(x), self.avgPooling(x)], dim=1)
# 迁移学习:获取预训练模型,并替换池化层和全连接层
def get_model():
# 获取欲训练模型 restnet50
model = models.resnet50(pretrained=True)
# 冻结模型参数
for param in model.parameters():
param.requires_grad = False
# 替换最后2层:池化层和全连接层
# 池化层
model.avgpool = AdaptiveConcatPool2d()
# 全连接层
model.fc = nn.Sequential(
nn.Flatten(), # 拉平
nn.BatchNorm1d(4096), # 加速神经网络的收敛过程,提高训练过程中的稳定性
nn.Dropout(0.5), # 丢掉部分神经元
nn.Linear(4096, 512), # 全连接层
nn.ReLU(), # 激活函数
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 2), # 2个输出
nn.LogSoftmax(dim=1) # 损失函数:将input转换成概率分布的形式,输出2个概率
)
return model
# 定义训练函数
def train_val(model, device, train_loader, val_loader, optimizer, criterion, epoch, writer):
model.train()
total_loss = 0.0
val_loss = 0.0
val_acc = 0
for batch_id, (images, labels) in enumerate(train_loader):
# 需要详解原理
# 部署到device上
images, labels = images.to(device), labels.to(device)
# 梯度置0
optimizer.zero_grad()
# 模型输出
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 累计损失
total_loss += loss.item() * images.size(0)
# 平均训练损失
train_loss = total_loss / len(train_loader.dataset)
#写入到writer中
writer.add_scalar('Training Loss', train_loss, epoch)
# 写入到磁盘
writer.flush()
model.eval()
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images) # 前向传播输出
loss = criterion(outputs, labels) # 损失
val_loss += loss.item() * images.size(0) # 累计损失
_, pred = torch.max(outputs, dim=1) # 获取最大概率的索引
correct = pred.eq(labels.view_as(pred)) # 返回:tensor([ True,False,True,...,False])
accuracy = torch.mean(correct.type(torch.FloatTensor)) # 准确率
val_acc += accuracy.item() * images.size(0) # 累计准确率
# 平均验证损失
val_loss = val_loss / len(val_loader.dataset)
# 平均准确率
val_acc = val_acc / len(val_loader.dataset)
return train_loss, val_loss, val_acc
# 定义测试函数
def test(model, device, test_loader, criterion, epoch, writer):
model.eval()
total_loss = 0.0
correct = 0.0 # 正确数
with torch.no_grad():
for batch_id, (images, labels) in enumerate(test_loader):
images, labels = images.to(device), labels.to(device)
# 输出
outputs = model(images)
# 损失
loss = criterion(outputs, labels)
# 累计损失
total_loss += loss.item()
# 获取预测概率最大值的索引
_, predicted = torch.max(outputs, dim=1)
# 累计正确预测的数
correct += predicted.eq(labels.view_as(predicted)).sum().item()
# 错误分类的图片
misclassified_images(predicted, writer, labels, images, outputs, epoch)
# 平均损失
avg_loss = total_loss / len(test_loader.dataset)
# 计算正确率
accuracy = 100 * correct / len(test_loader.dataset)
# 将test的结果写入write
writer.add_scalar("Test Loss", total_loss, epoch)
writer.add_scalar("Accuracy", accuracy, epoch)
writer.flush()
return total_loss, accuracy
# 定义训练流程
# 是否有GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device.type)
# 模型部署到device
model = get_model().to(device)
# 损失函数
criterion = nn.NLLLoss()
# 优化器
optimizer = optim.SGD(model.parameters(), lr=0.001)
# 定义训练流程函数
def train_epochs(model, device, dataloaders, criterion, optimizer, epochs, writer):
# 输出信息
print("{0:>15} | {1:>15} | {2:>15} | {3:>15} | {4:>15} | {5:>15}".format('Epoch', 'Train Loss', 'val_loss', 'val_acc', 'Test Loss', 'Test_acc'))
# 初始最小的损失
best_loss = np.inf
# 开始训练、测试
for epoch in range(epochs):
# 训练,return: loss
train_loss, val_loss, val_acc = train_val(model, device, dataloaders['train'], dataloaders['val'], optimizer, criterion, epoch, writer)
# 测试,return: loss + accuracy
test_loss, test_acc = test(model, device, dataloaders['test'], criterion, epoch, writer)
# 判断损失是否最小
if test_loss < best_loss:
best_loss = test_loss # 保存最小损失
# 保存模型
torch.save(model.state_dict(), 'model.pth')
# 输出结果
print("{0:>15} | {1:>15} | {2:>15} | {3:>15} | {4:>15} | {5:>15}".format(epoch, train_loss, val_loss, val_acc, test_loss, test_acc))
writer.flush()
# 调用函数
epochs=10
train_epochs(model, device, dataloaders, criterion, optimizer, epochs, writer)
writer.close()
def plot_confusion(cm):
plt.figure()
plot_confusion_matrix(cm, figsize=(12, 8), cmap=plt.cm.Blues) # 参数设置
plt.xticks(range(2), ['Normal', 'Pneumonia'], fontsize=14)
plt.yticks(range(2), ['Normal', 'Pneumonia'], fontsize=14)
plt.xlabel('Predicted Label', fontsize=16)
plt.ylabel('True Label', fontsize=16)
plt.show()
def accuracy(outputs, labels):
# 计算正确率
_, preds = torch.max(outputs, dim=1)
correct = torch.tensor(torch.sum(preds == labels).item() / len(preds))
return correct
def metrics(outputs, labels):
_, preds = torch.max(outputs, dim=1)
# precision, recall, F1
# 混淆矩阵
cm = confusion_matrix(labels.cpu().numpy(), preds.cpu().numpy())
# 绘制混淆矩阵
plot_confusion(cm)
# 获取tn, fp, fn, tp
tn, fp, fn, tp = cm.ravel()
# 精准率
precision = tp / (tp + fp)
# 召回率
recall = tp / (tp + fn)
# f1 score
f1 = 2 * ((precision * recall) / (precision + recall))
return precision, recall, f1
# 计算testloader
precisions = []
recalls = []
f1s = []
accuracies = []
with torch.no_grad():
model.eval()
for datas, labels in dataloaders['test']:
datas, labels = datas.to(device), labels.to(device)
# 预测输出
outputs = model(datas)
# 计算metrics
precision, recall, f1 = metrics(outputs, labels)
acc = accuracy(outputs, labels)
# 保存结果
precisions.append(precision)
recalls.append(recall)
f1s.append(f1)
accuracies.append(acc.item())
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 88
88 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)