机器学习(吴恩达)
机器学习涵盖监督学习、无监督学习与强化学习。核心算法包括线性模型、树模型、集成方法、核技巧及概率模型。深度学习以神经网络为基础,涉及CNN、RNN、Transformer、激活函数及优化技术。评估指标含分类、回归与聚类,正则化手段应对过拟合,交叉验证保障泛化性,强化学习结合值函数与策略优化,形成从传统统计到深度强化学习的完整体系
一, 概述
机器学习定义: 计算机能够在没有明确的编程情况下学习
特征: 特征是描述样本的属性或变量,是模型用来学习和预测的基础。如: 房屋面积, 地理位置
标签: 监督学习中需要预测的目标变量,是模型的输出目标。如: 房屋价格
样本: 如: {面积=100㎡, 卧室=3, 位置=市中心, 价格=500万}, 数据集中的一个独立实例, 包含一组特征及对应的标签。
样本向量形式:

独热编码举例:

机器学习的分类:
1) 监督学习: 根据带标签的数据训练模型,预测新样本的标签。如回归, 分类。
回归应用: 房价预测

分类算法: 根据年龄和肿瘤大小判断肿瘤良/恶性

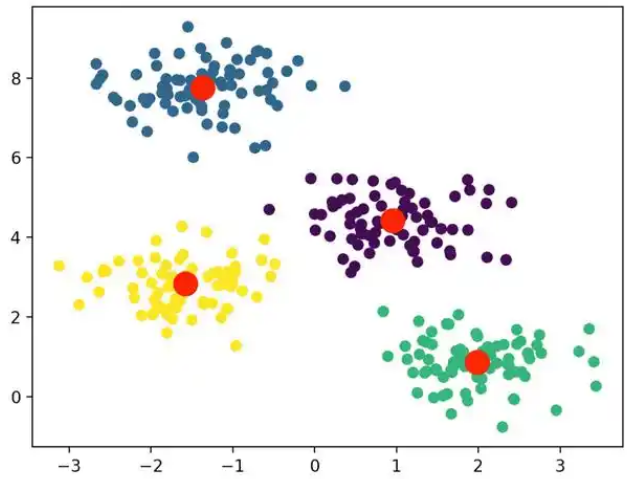
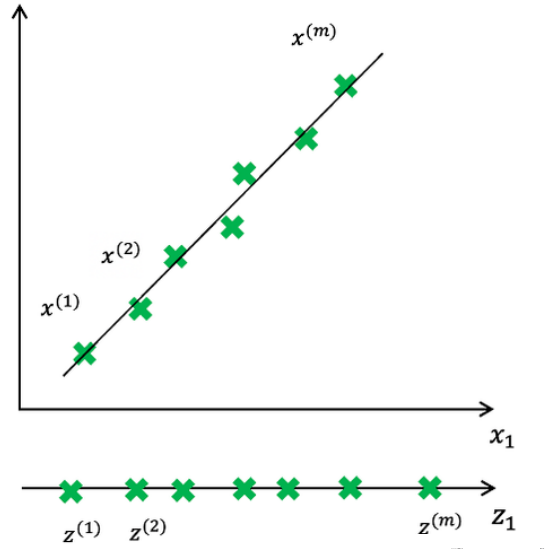
2) 无监督学习: 从未标注数据中发现潜在结构或模式。如聚类, 异常检测, 降维
聚类:
降维:
3) 半监督学习: 结合少量标注数据和大量未标注数据进行训练。如医学图像分析
4) 强化学习: 通过与环境交互学习策略,最大化累积奖励。如游戏AI, 自动驾驶
二、模型训练与优化
2.1 损失函数与成本函数
第i个数据特征:

损失函数(Loss Function):衡量单个样本的预测值与真实值的差异。
成本函数(Cost Function):衡量整个训练集的平均损失。
平方误差损失:

平方误差成本函数: 一定是凸函数,确保只有一个全局最小值

模型(y=wx)与成本函数示例 (左图w=-0.5、0、0.5、1时的情况):

模型(y=wx+b)下的成本函数:

模型 与 J(w,b)的平面等高线:



2.2 学习率与梯度下降算法
学习率(α):控制模型参数更新步长的超参数。
学习率的取值的两种情况:
1) 学习率过大:参数更新步长过大,可能导致损失值震荡甚至发散。
2) 学习率过小:收敛速度极慢,可能陷入局部极小值。
示例:

梯度下降公式:


推导过程:

梯度算法演示:

两个特征的多元线性回归举例:






2.3 特征缩放
加速模型收敛。有如下方法
标准化(Z-Score标准化):

标准差:

归一化(Min-Max缩放):

标准化与归一化的区别:
| 技术 | 目标 | 公式 |
|---|---|---|
| 标准化 | 服从标准正态分布 | x′′ ∼ N(0,1) |
| 归一化 | 压缩值域到 [0,1] |
举例 (标准化前后的数据集) :

2.4 正则化
基本形式
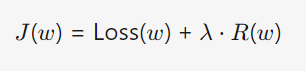
L1正则化(Lasso)
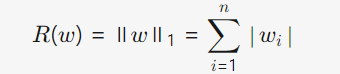
L2正则化(Ridge)
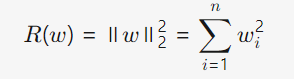
添加正则化项后的梯度算法:

原理: 通过在损失函数中添加与模型参数相关的惩罚项,限制参数的复杂度,从而提升模型的泛化能力。 (使得W尽可能小以此使得函数趋于平滑)
λ过大: 参数被过度压缩,模型过于简单,无法捕捉数据中的有效规律。
λ过小: 正则化作用微弱,模型过度依赖训练数据中的噪声或局部特征。
备注: 只要正则化得当, 更大的神经网络总是更好的。
例图:

根据交叉验证误差找到适合的λ:

λ取值与交叉验证误差及训练集误差的关系:

常用的正则化:
- Lasso (L1 正则化): 收缩系数并执行自动特征选择,将不重要特征的系数设为零,产生稀疏模型。特别适用于特征选择和简化高维模型。
- Ridge (L2 正则化): 收缩系数以稳定模型和减少过拟合,但保留所有特征。是处理共线性的好选择。
区别:
| 场景 | L1 (Lasso) | L2 (Ridge) |
|---|---|---|
| 特征选择需求 | ✅(产生稀疏模型) | ❌(保留所有特征) |
| 高维数据 | ✅(如 p≫n) | ⚠️(效果不如L1) |
| 特征高度相关 | ❌(可能随机选择一个) | ✅(均匀压缩相关特征权重) |
| 模型解释性要求 | ✅(零权重=特征不重要) | ❌(权重非零,解释性弱) |
| 抗噪声能力 | ❌(对异常值敏感) | ✅(权重平滑,稳定性强) |
| 使用场景 | ✅特征维度高, 需减少模型复杂度 | ✅特征数适中, 特征都有潜在意义 |
备注: OLS(普通最小二乘法), 如线性回归的损失函数
2.5 特征映射
通过数学变换将原始特征空间转换到新空间, 解决非线性问题 或 增强模型表达能力
多项式映射代码示例:
def feature_mapping(x1,x2,power):
HashMap={}
for i in range(power+1):
for j in range(i+1):
HashMap[f'{i-j}_{j}']=np.power(x1,i-j)*np.power(x2,j)
# data['F{}{}'.format(i-j,j)] = np.power(x1,i-j) * np.power(x2,j)
return pd.DataFrame(HashMap)上述代码是将二维[X1,X2]映射为如下: 共10项

2.6 模型评估
数据集划分:
1) 训练集(Training Set):用于模型训练(通常占70%)。
2) 验证集: 用于调参, 学习数据中的潜在规律。(通常占15%)
3) 测试集(Test Set):模拟“未知数据”,用于最终评估。(通常占15%)
意义: 若模型仅在训练集上表现好,但在测试集上差,说明模型过拟合(过度记忆训练数据细节),泛化能力弱。
备注: 避免测试集调参, 若根据测试集结果反复调整模型,导致模型间接拟合测试集。
交叉验证:
通过多次数据划分减少评估结果的方差, 防止模型因单次数据划分的随机性导致评估结果不稳定。
1) K折交叉验证: 将数据均等分为K个子集, 每次用1个子集作为验证集,其余K-1个作为训练集,重复K次。计算K次验证结果的平均值作为最终评估指标
2) 留一交叉验证: K折交叉验证的极端情况(K=N,N为样本总数)适合小数据集。
3) 分层交叉验证: 分类任务中类别分布不均衡时,确保每折的类别比例与原始数据一致。(如数据中90%为类别A,10%为类别B,分层交叉验证会保证每折中类别A和B的比例仍为9:1。)
2.6.1 偏差与方差
分解公式:泛化误差 = 偏差² + 方差 + 噪声。
偏差(Bias):指模型预测值的期望与真实值之间的差距,反映了模型对数据的拟合能力。高偏差意味着模型过于简单,无法捕捉数据中的潜在关系,导致欠拟合(Underfitting)。
方差(Variance):指模型对训练数据中微小变化的敏感程度,反映了模型的稳定性。高方差意味着模型过于复杂,过度拟合训练数据中的噪声,导致过拟合(Overfitting)。
高偏差(左), 高方差(右)

解决过拟合情况:
1) 收集更多数据
2) 仅用特征的一个子集
3) 正则化
欠拟合(高偏差), 适中, 过拟合(高方差)

2.6.2 诊断偏差与方差
高偏差(欠拟合):训练集和验证集误差均高。
解决方案:
1) 可增加模型复杂度(如使用更高阶多项式、深层神经网络)
2) 添加更多特征或改进特征工程
3) 减少正则化强度(如降低λ值)
高方差(过拟合):训练误差低,验证误差高且差距大。表现: J(验证集)>>J(训练集)
解决方案:
1) 可降低模型复杂度(如减少神经网络层数、剪枝决策树)。
2) 增加训练数据量或使用数据增强。
3) 增强正则化
多项式阶数(x轴) 与 交叉验证误差 及 训练集误差 的关系:

学习曲线:

高偏差学习曲线情况(红线, 较人类水平相比):

高方差学习曲线情况(前半段):

2.6.3 查准率与查全率
混淆矩阵:TP(真正例)、TN(真负例)、FP(假正例)、FN(假负例)。
1) 真正例(TP, True Positive):实际为正类,预测也为正类。
2) 假正例(FP, False Positive):实际为负类,预测为正类(误报)。
3) 真负例(TN, True Negative):实际为负类,预测也为负类。
4) 假负例(FN, False Negative):实际为正类,预测为负类(漏报)。
查准率(Precision):(预测为正的样本中实际为正的比例)。关注预测的准确性
查全率(Recall):(实际为正的样本中被正确预测的比例)。关注正类的覆盖率
高精率确低召回率: 预测产品质量永远为合格(绝大部分产品都合格)
实际场景举例:
- 查准率优先:垃圾邮件分类(宁可漏判也要避免误判正常邮件)
- 查全率优先:疾病检测(宁可误诊也要减少漏诊)。
例子:癌症检测
设测试集有 100 名患者,其中 10 人患癌(正类) , 90 人健康(负类)。模型预测结果如下
- 正确预测:
- 癌症患者:8 人(TP = 8)。
- 健康患者:83 人(TN = 83)。
- 错误预测:
- 将 7 名健康人误诊为癌症(FP = 7)。
- 漏诊 2 名癌症患者(FN = 2)。
混淆矩阵:
| 预测患癌 | 预测健康 | |
|---|---|---|
| 实际患癌 | TP = 8 | FN = 2 |
| 实际健康 | FP = 7 | TN = 83 |
三、分类算法
3.1 线性逻辑回归
通过线性组合特征与参数,结合Sigmoid函数将输出映射到概率区间(0-1),用于解决分类问题(尤其是二分类)。
Sigmoid函数模型:

图形:

对数损失函数(交叉熵损失):

对应图形:


为什么不使用均方误差(MSE)作为损失函数: 当预测值接近 0 或 1 时, 梯度接近于0, 权重几乎无法更新。

对应成本函数:



为什么选择对数损失函数:
1) 概率视角:最大似然估计(MLE)
2) 优化视角:凸性
梯度下降算法:
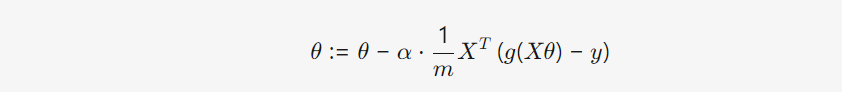
与线性回归梯度算法的区别: 模型定义不同

线性回归与逻辑回归区别:

决策边界:

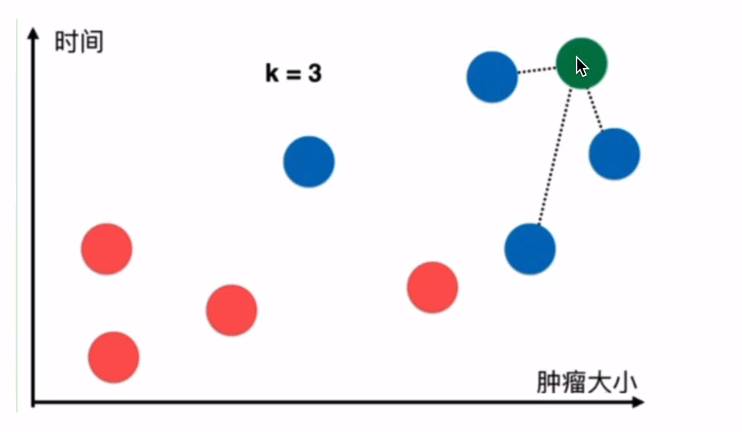
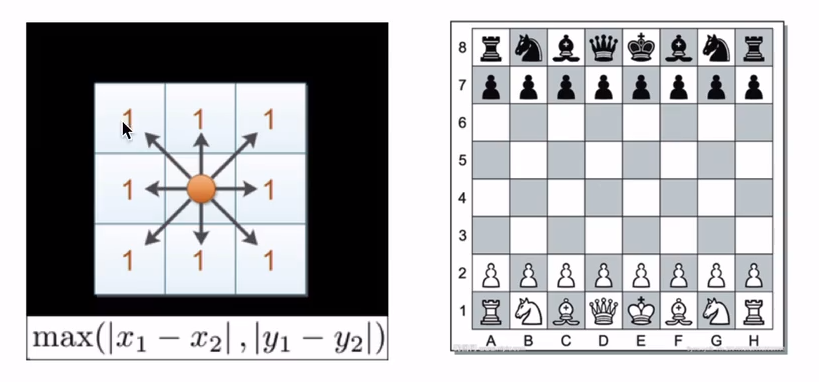
3.2 KNN算法
KNN是一种基于实例的学习 或懒惰学习, 其核心思想是:物以类聚。在分类任务中,一个样本的类别由其k个最近邻居的多数投票决定。
算法工作原理:
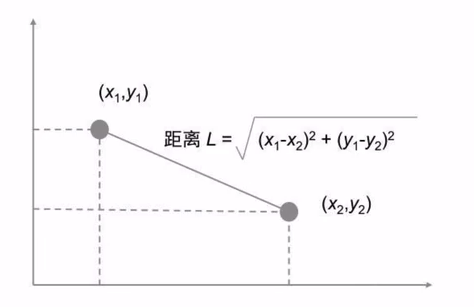
- 计算距离:给定待预测样本,计算它与训练集中每个样本的距离(常用欧氏距离)。
- 选择邻居:选取距离最近的k个训练样本(k为预设值)。
- 投票决策:统计k个邻居中的类别分布,将待预测样本归为最频繁的类别。
示例图: 判断是否肿瘤, 当k=3时
距离度量方法
1) 欧氏距离:
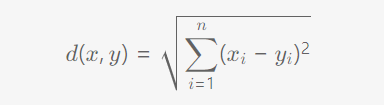
示例:
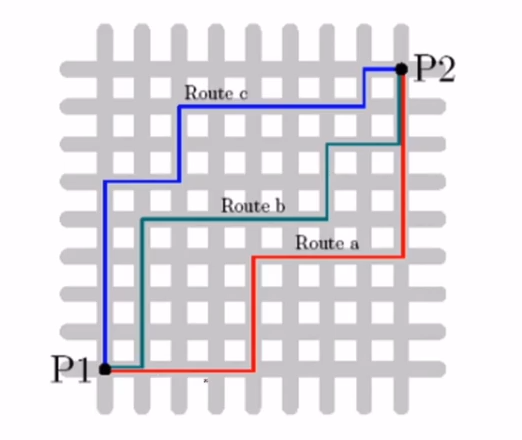
2) 曼哈顿距离
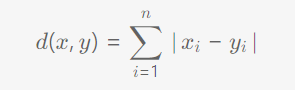
示例:
3) 切比雪夫距离
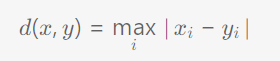
示例:
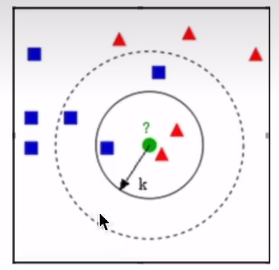
关键超参数 k 的选择:
- k过小:模型复杂,容易过拟合(对噪声敏感)。
- k过大:模型简单,可能导致欠拟合(边界模糊)。
示例:
缺点:
1) 计算开销大, 预测时需要计算所有样本距离。
2) 少数类样本易被主导
3.3 Naive Bayes
贝叶斯公式:
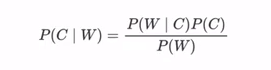
朴素 ( Naive ) 的核心假设:条件独立性, 简化计算。
示例:
- 当 x1,x2,x3 在给定 C 的条件下相互独立:
P(x1,x2,x3∣C) = P(x1∣C) ⋅ P(x2∣C) ⋅ P(x3∣C)
- 当 x1,x2,x3 在给定 C 的条件下不相互独立:
P(x1,x2,x3∣C) = P(x1∣x2,x3,C) ⋅ P(x2∣x3,C) ⋅ P(x3∣C)
拉普拉斯平滑系数: 解决朴素贝叶斯中离散特征的零概率问题,确保所有特征值在任何类别下都有非零概率。
数学公式:
P(x_i = v | C_k) = [count(x_i = v and C_k) + α] / [count(C_k) + α * S_i]
举例: 训练数据集: (10个水果样本)
| 样本ID | 颜色 (Color) | 形状 (Shape) | 类别 (Class) |
|---|---|---|---|
| 1 | 红色 | 圆形 | Apple |
| 2 | 红色 | 圆形 | Apple |
| 3 | 红色 | 圆形 | Apple |
| 4 | 黄色 | 圆形 | Apple |
| 5 | 红色 | 圆形 | Apple |
| 6 | 黄色 | 长形 | Banana |
| 7 | 黄色 | 长形 | Banana |
| 8 | 绿色 | 长形 | Banana |
| 9 | 黄色 | 长形 | Banana |
| 10 | 黄色 | 长形 | Banana |
1) 计算先验概率:
P(Apple) = 5/10 =1/2
P(Banana)= 5/10 =1/2
2) 计算条件概率(使用平滑):
特征“颜色”(Color): 取值有 红色、黄色、绿色 (即 S_Color = 3)
特征“形状”(Shape): 取值有 圆形、长形 (即 S_Shape = 2)
拉普拉斯平滑: α = 1
对于类别 Apple:
- 苹果总样本数
count(C=Apple)= 5 P(Color=红|Apple)= (红苹果数 + α) / (苹果数 + α * S_Color) = (4 + 1) / (5 + 1 * 3) = 5 / 8 ≈ 0.625P(Color=黄|Apple)= (黄苹果数 + α) / (苹果数 + α * S_Color) = (1 + 1) / (5 + 1 * 3) = 2 / 8 = 0.25P(Color=绿|Apple)= (绿苹果数 + α) / (苹果数 + α * S_Color) = (0 + 1) / (5 + 1 * 3) = 1 / 8 ≈ 0.125P(Shape=圆|Apple)= (圆苹果数 + α) / (苹果数 + α * S_Shape) = (5 + 1) / (5 + 1 * 2) = 6 / 7 ≈ 0.857P(Shape=长|Apple)= (长苹果数 + α) / (苹果数 + α * S_Shape) = (0 + 1) / (5 + 1 * 2) = 1 / 7 ≈ 0.143
对于类别 Banana:
- 香蕉总样本数
count(C=Banana)= 5 P(Color=红|Banana)= (红香蕉数 + α) / (香蕉数 + α * S_Color) = (0 + 1) / (5 + 1 * 3) = 1 / 8 ≈ 0.125P(Color=黄|Banana)= (黄香蕉数 + α) / (香蕉数 + α * S_Color) = (4 + 1) / (5 + 1 * 3) = 5 / 8 ≈ 0.625P(Color=绿|Banana)= (绿香蕉数 + α) / (香蕉数 + α * S_Color) = (1 + 1) / (5 + 1 * 3) = 2 / 8 = 0.25P(Shape=圆|Banana)= (圆香蕉数 + α) / (香蕉数 + α * S_Shape) = (0 + 1) / (5 + 1 * 2) = 1 / 7 ≈ 0.143P(Shape=长|Banana)= (长香蕉数 + α) / (香蕉数 + α * S_Shape) = (5 + 1) / (5 + 1 * 2) = 6 / 7 ≈ 0.857
3) 计算后验概论:
4) 将带预测的特征带入上式, 最后得出概率, 取概论最大即为预测值
算法缺点:
1) 训练集类别分布不平衡, 会影响模型效果。
2) 特征间的强相关性会显著降低模型性能。
3.4 SVM
在特征空间中找到一个最优超平面,将不同类别的样本分开, 并使超平面支持向量距离最大化。这个最大化的距离称为间隔(Margin)。
超平面: 在二维空间是一条直线,在三维空间是一个平面, 在更高维空间是一个线性决策边界。形式上是线性方程:
支持向量:位于间隔边界上的数据点, 决定了超平面的位置和方向。
间隔: 支持向量到该超平面的垂直距离之和。
示例图:
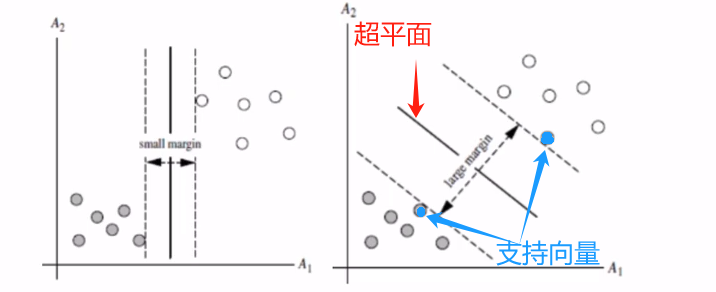
硬间隔分类器: 找到一个超平面使得所有样本都被正确分类,并且间隔尽可能大
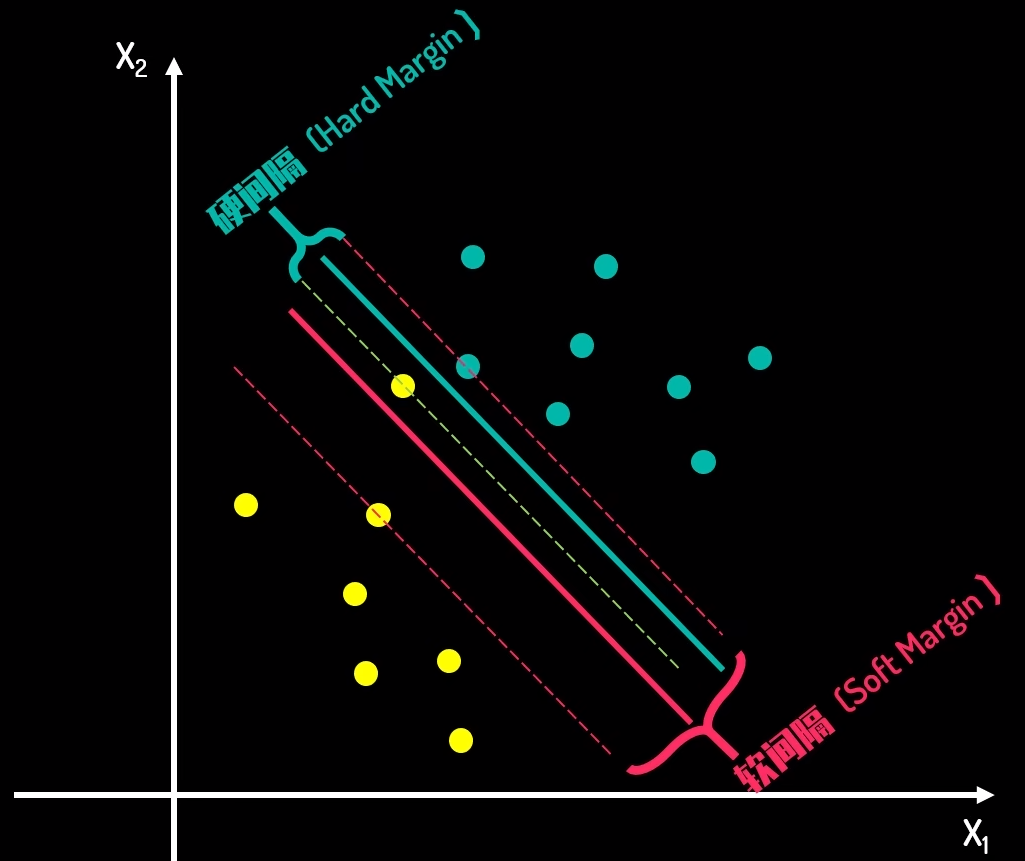
软间隔分类器: 存在噪声、重叠或异常值时, 引入惩罚系数 C, 用于平衡最大化间隔(模型复杂度低)和最小化分类错误(训练误差小)
- C值越大 → 对分类错误的惩罚越重 → 模型倾向于减少误分类(可能过拟合)(间隔窄)
- C值越小 → 允许更多分类错误 → 模型追求更大间隔(可能欠拟合)(间隔宽)
硬/软间隔:
核技巧: 当数据本质是非线性可分时, 通过一个非线性映射函数,将原始特征空间中的样本 X 映射到一个更高维的特征空间
常用核函数:
1) 线性核 (Linear Kernel): 相当于没有映射,在原始空间做线性SVM。
2) 多项式核(Polynomial Kernel): 引入多项式特征
3) 径向基函数核/高斯核 (RBF/Gaussian Kernel):最常用也最强大的核之一。理论上可以将数据映射到无限维空间。
4) Sigmoid核 (Sigmoid Kernel): 类似神经网络的激活函数。
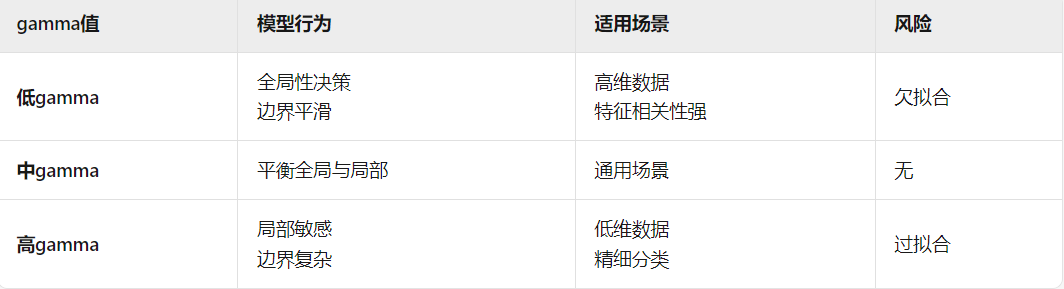
使用核函数为rbf时, gamma的取值问题:
3.5 决策树
一种树形结构的监督学习模型,通过选择最优特征对数据进行分割,目标是使子节点的数据尽可能“纯净”(同类样本集中)。
递归分裂过程:
- 从根节点开始,计算所有特征的分裂指标(如信息增益)。
- 选择最优特征作为当前节点的分裂特征。
- 根据特征的取值将数据集划分为子集,生成子节点。
- 对每个子节点递归执行步骤1-3,直到满足停止条件。
停止条件:
- 节点样本数小于预设阈值。
- 所有样本属于同一类别。
- 特征已用完或分裂后纯度提升不显著。
预剪枝: 在树生长过程中提前终止分裂。如设置最大深度
信息熵:度量数据集的混乱程度。值越小分类越明确。

示例图: H(D)=H(p1)+H(p2)=2

3.5.1 信息增益(IG)
IG(D, A)量化了特征 A 对降低数据集分类不确定性的贡献度。
经验熵H(D): 表示当前数据集 D 的分类不确定性。
条件经验熵 H(D|A): 表示在已知特征 A 的条件下,数据集 D 的分类不确定性。
信息增益公式: H(D)-H(D|A)

信息熵与经验熵的区别:
| 特征 | 信息熵 (Information Entropy) | 经验熵 (Empirical Entropy) |
|---|---|---|
| 本质 | 理论概念 | 经验估计 |
| 输入 | 精确、已知的概率分布 P |
具体的样本数据集 D |
概率 pᵥ |
事件的真实概率 | 事件在数据集中的样本频率/比例 |
举例: 预测是否打网球
| 序号 | 天气 (Outlook) | 温度 (Temp) | 湿度 (Humidity) | 刮风 (Windy) | Play Tennis (Target) |
|---|---|---|---|---|---|
| 1 | 晴 (Sunny) | 热 (Hot) | 高 (High) | 否 (False) | 否 (No) |
| 2 | 晴 (Sunny) | 热 (Hot) | 高 (High) | 是 (True) | 否 (No) |
| 3 | 多云 (Overcast) | 热 (Hot) | 高 (High) | 否 (False) | 是 (Yes) |
| 4 | 雨 (Rain) | 适中 (Mild) | 高 (High) | 否 (False) | 是 (Yes) |
| 5 | 雨 (Rain) | 凉 (Cool) | 正常 (Normal) | 否 (False) | 是 (Yes) |
| 6 | 雨 (Rain) | 凉 (Cool) | 正常 (Normal) | 是 (True) | 否 (No) |
| 7 | 多云 (Overcast) | 凉 (Cool) | 正常 (Normal) | 是 (True) | 是 (Yes) |
| 8 | 晴 (Sunny) | 适中 (Mild) | 高 (High) | 否 (False) | 否 (No) |
| 9 | 晴 (Sunny) | 凉 (Cool) | 正常 (Normal) | 否 (False) | 是 (Yes) |
| 10 | 雨 (Rain) | 适中 (Mild) | 正常 (Normal) | 否 (False) | 是 (Yes) |
| 11 | 晴 (Sunny) | 适中 (Mild) | 正常 (Normal) | 是 (True) | 是 (Yes) |
| 12 | 多云 (Overcast) | 适中 (Mild) | 高 (High) | 否 (False) | 是 (Yes) |
| 13 | 多云 (Overcast) | 热 (Hot) | 正常 (Normal) | 否 (False) | 是 (Yes) |
| 14 | 雨 (Rain) | 适中 (Mild) | 高 (High) | 是 (True) | 否 (No) |
1) 计算经验熵
- 总样本数
|D| = 14 Play Tennis = Yes: 9 个样本 (|C₁| = 9)Play Tennis = No: 5 个样本 (|C₂| = 5)
结果: H(D)= - [(9/14) * log₂(9/14) + (5/14) * log₂(5/14)]
2) 计算条件经验熵 :
根据 Outlook 分割数据集:
Outlook = Sunny: |D₁| = 5, [No, No, No, No, Yes] -> Yes: 2 (2/5), No: 3 (3/5)
H(D₁) = - [(2/5) * log₂(2/5) + (3/5) * log₂(3/5)]
Outlook = Overcast: |D₂| = 4, [Yes, Yes, Yes, Yes] -> Yes: 4 (4/4), No: 0 (0/4)
H(D₂) = - [(4/4) * log₂(4/4) + (0/4) * log₂(0/4)]
Outlook = Rain: |D₃| = 5, [Yes, Yes, No, Yes, No] -> Yes: 3 (3/5), No: 2 (2/5)
H(D₃) = - [(3/5) * log₂(3/5) + (2/5) * log₂(2/5)]
结果:H(D|Outlook) = (5/14) * H(D₁) + (4/14) * H(D₂) + (5/14) * H(D₃)
3) 将所有特征重复以上计算, 得出所有信息增益
二分类分裂决策举例:

3.5.2 信息增益率(IGR)
在信息增益的基础上,对特征本身的分布熵进行标准化。
信息增益的缺陷: 对多值特征的偏好
例如: 如果将一个唯一标识符(如样本ID) 作为一个特征
- 每个样本ID对应一个唯一的取值。
- 使用该特征划分后,每个子集
Dᵥ只包含一个样本,纯度最高(熵H(Dᵥ) = 0)。 - 条件熵
H(D|A) = Σ (1/|D|) * 0 = 0。 - 信息增益
IG(D, ID) = H(D) - 0 = H(D),达到最大值。 - 但这个特征对于预测新样本的类别毫无用处, 过拟合了训练数据, 无泛化能力
信息增益率公式:

3.5.3 基尼指数
衡量数据集不纯度, 可视为熵的近似, 但计算更高效
基尼值公式:

基尼指数公式:

举例: 共14个样本
| Outlook(天气) | Play Tennis | 样本数 |
|---|---|---|
| Sunny | No | 3 |
| Sunny | Yes | 2 |
| Overcast | Yes | 4 |
| Rain | Yes | 3 |
| Rain | No | 2 |
1) 计算划分前的基尼值 Gini(D)
- 类别占比:p(Yes) = 9/14, p(No) =5/14
2) 计算特征 Outlook 的基尼指数
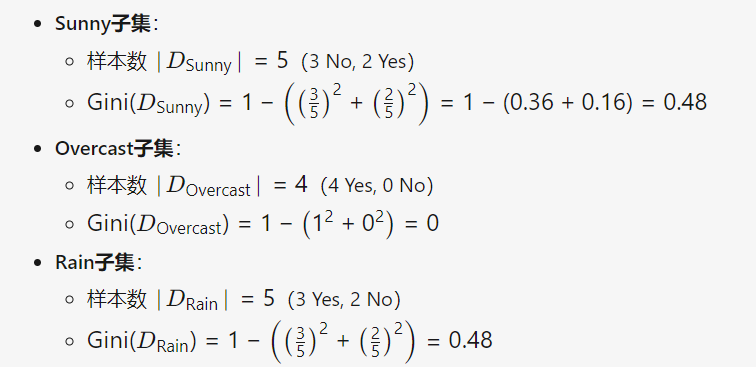
3) 加权平均基尼值(基尼指数):
4) 对其他特征重复上述过程, 选择基尼指数最小的特征作为当前节点的划分标准。
三种经典决策树算法:

3.5.4 回归问题
决策树处理处理连续值特征:
1) 特征排序: 从小到大排序
2) 候选分割点生成:相邻值的中间点作为候选分割点。
3) 计算分裂指标: 计算分裂后的信息增益(分类)或均方误差(回归)。
4) 选择最优分割点
5) 递归分裂
示例1: 体重(离散值)作为分裂点

示例2:
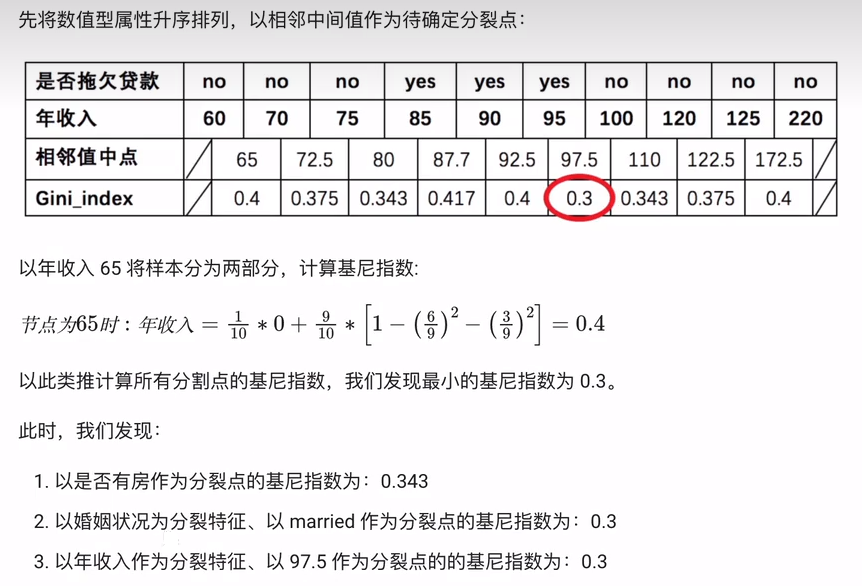
示例3: 根据特征预测体重(MSE)

示例四:
| 超市编号 | 店面面积 (平方米) | 日营业额 (万元) |
|---|---|---|
| 1 | 30 | 4 |
| 2 | 40 | 5 |
| 3 | 45 | 5.5 |
| 4 | 50 | 6.5 |
| 5 | 55 | 7 |
| 6 | 60 | 8.5 |
| 7 | 65 | 9 |
| 8 | 70 | 9.5 |
| 9 | 75 | 10.5 |
| 10 | 80 | 11 |
1) 排序, 并生成分割点: [35, 42.5, 47.5, 52.5, 57.5, 62.5, 67.5, 72.5, 77.5]。
2) 计算每个候选分割点,计算分割后左右两个区域的日营业额的平均值的均方误差 (MSE)。
计算示例:
左区域 (面积 <= 52.5): 面积: [30, 40, 45, 50]。营业额:[4, 5, 5.5, 6.5]
- 左区域平均值 = (4 + 5 + 5.5 + 6.5) / 4 = 21 / 4 = 5.25
- 左区域平方误差 = (4-5.25)² + (5-5.25)² + (5.5-5.25)² + (6.5-5.25)²
右区域 (面积 > 52.5): 面积: [55, 60, 65, 70, 75, 80]。营业额:[7, 8.5, 9, 9.5, 10.5, 11]
- 右区域平均值 = (7 + 8.5 + 9 + 9.5 + 10.5 + 11) / 6 = 55.5 / 6 = 9.25
- 右区域平方误差 = (7-9.25)² + (8.5-9.25)² + (9-9.25)² + (9.5-9.25)² + (10.5-9.25)² + (11-9.25)²
总平方误差和 = 左区域平方误差 + 右区域平方误差
3) 比较所有候选点, 选择当前特征的最小平方误差对应的分割点为分裂节点
4) 多特征待分裂, 则计算所有特征的最小平方误差对应的分割点, 并选取最小值对应特征的分割点
5) 预测值为叶子节点的平均值
1.4.5 剪枝
解决过拟合, 提升泛化能力, 降低复杂度
1) 预剪枝: 在训练过程中提前停止树的生长
常用停止条件:
| 条件 | 说明 |
|---|---|
| 最大树深度(Max Depth) | 限制树的总层数 |
| 最小样本分裂(Min Samples Split) | 节点分裂所需最少样本数(如<10不分裂) |
| 最小样本叶子(Min Samples Leaf) | 叶节点最少样本数(如<5则停止分裂) |
| 最大叶节点数(Max Leaf Nodes) | 限制整棵树叶节点数量 |
| 信息增益阈值 | 当最优分裂的增益低于阈值时停止 |
2) 后剪枝: 先构建完整树,再自底向上修剪冗余分支
随机森林
通过构建多棵决策树,结合投票(分类)或平均(回归)实现预测。
训练步骤:
1) Bootstrap抽样:从D中有放回地抽取N个样本,形成子集。
2) 构建决策树:在上训练一棵CART(分类与回归树)树,每次分裂时仅考虑m个随机选择的特征。m=math.sqrt(总特征数)
3) 保存模型:将训练好的树ht加入森林。
4) 预测:
· 多数投票法(分类):每棵树对样本预测一个类别,最终选择得票最多的类别。
· 平均值(回归):所有树的预测结果取平均。
放回抽样: 每次从总体中随机抽取一个样本后,将该样本放回总体,确保它在后续抽取中仍有可能被再次选中。
XGBoost思想: 在每一轮迭代中,通过拟合前序模型的预测残差(负梯度方向),并自动调整对预测不准样本的关注度,同时结合正则化防止过拟合。
决策树 vs 逻辑回归:

3.6 多分类与多标签分类
多分类: 输出每个类别的概率,选择最大概率对应的类别。如数字识别。
多标签分类: 为样本分配多个相关标签, 如图像标注(包含“山”“湖”“树”)
softmax公式:
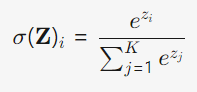
损失函数:

对应函数图形:

四、无监督学习
4.1 聚类算法
将未标记的数据划分为若干组(簇), 组内相似性高, 组间差异性大。
4.1.1 K-Means算法
K-means算法流程:
1) 初始化: 随机选择K个初始聚类中心, 分别为μ1, μ2, ... , μk
2) 分配阶段: 对每个数据点 xᵢ,使用 ||xᵢ - μₖ||² 计算它到所有质心的距离平方,将其分配到距离最小的那个簇。
3) 更新: 对每个簇 k,使用 质心公式重新计算其质心。
4) 迭代优化: 重复2)、3)步骤, 直到 J 收敛
数据点分配公式:
||pᵢ - mₖ||: 表示点 pᵢ 和质点 mₖ 之间的欧几里得距离
质心更新公式:
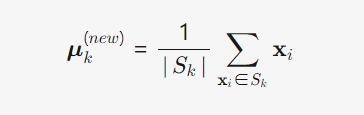
备注:

质心计算示例:
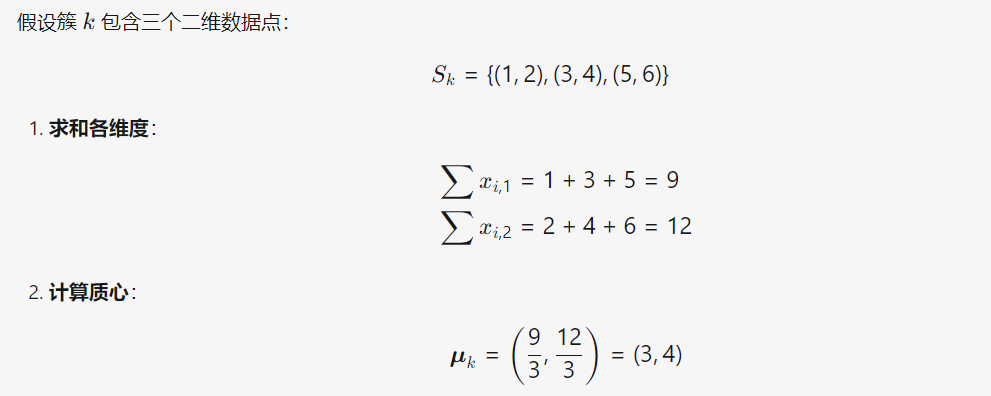
损失函数:
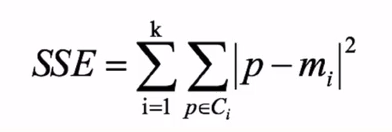
示例: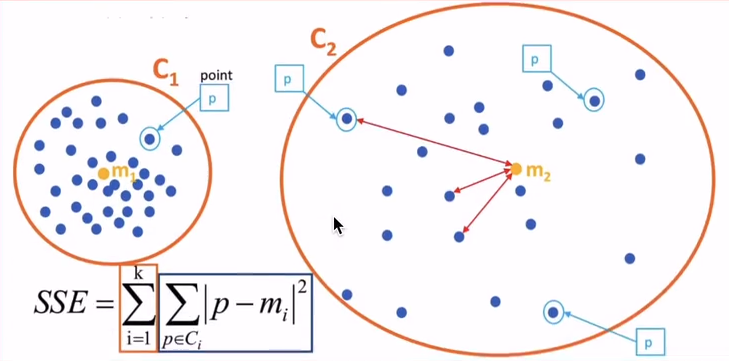
k-means工作示例:






质点不同初始化时的可能情况: 算法可能收敛到局部最优而非全局最优
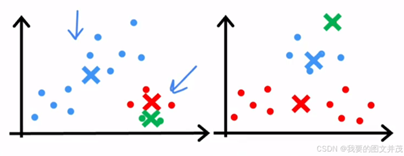
质点初始化解决方案: 多次运行取最优
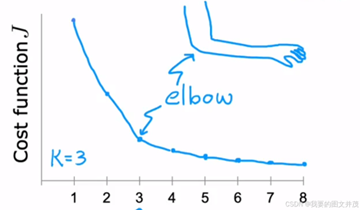
选取合适的K值:
1) 肘部法则: 绘制不同K值对应的目标函数, 寻找“拐点”
2) 轮廓系数: 衡量每个数据点与自身簇的紧密度 vs 其他簇的分离度,取平均值。
公式:
a(i) = xi 到同簇其他点的平均距离(簇内紧密度)。
b(i) = xi 到最近邻簇中所有点的平均距离(簇间分离度)。
点 xi 的轮廓系数:
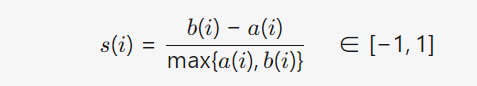
全局轮廓系数(对K的评价): 值越接近1,聚类质量越高。
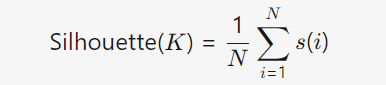
4.1.2 FCM (Fuzzy C-Means)
与K-Means相比, 数据点可以以不同的隶属度属于多个簇,而不是强制只属于一个簇
与 K-means 的区别:
| 特性 | K-Means | Fuzzy C-Means (FCM) |
|---|---|---|
| 聚类归属 | 硬划分:每个点严格属于一个簇 | 软划分:每个点以概率属于所有簇 |
| 隶属度 | 二元(0或1) | 连续值([0,1]区间) |
| 目标函数 | 最小化点到簇中心的平方距离和 | 最小化加权的平方距离和(含隶属度) |
| 算法宽容度 | 对噪声/异常值敏感 | 对噪声更鲁棒 |
| 簇边界处理 | 清晰线性边界 | 模糊边界 |
| 数学基础 | 欧氏空间硬划分 | 模糊集合论 |
| 收敛速度 | 通常更快(5-20次迭代) | 较慢(20-100次迭代) |
| 局部最优风险 | 高(依赖初始中心) | 更高(解空间更复杂) |
损失函数:
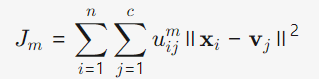
备注:

更新隶属度:
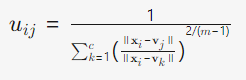
更新簇中心:
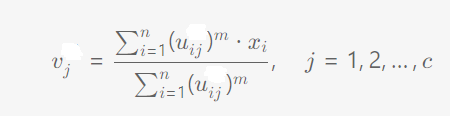
模糊指数 m 的影响:
| m值 | 效果 | 应用场景 |
|---|---|---|
| m→1+ | 接近K-Means硬划分 | 需要清晰分类 |
| m=1.5−2.5 | 典型模糊划分 | 大多数场景 |
| m>3.0 | 过度模糊化(隶属度趋于相同) | 不建议使用 |
算法流程:
1) 初始化隶属度矩阵
2)迭代更新聚类中心和隶属度矩阵
3)直到收敛
4.2 异常检测
密度评估: 当P(x)小于某个值时, 为可疑异常, 相比较监督算法, 更容易发现从未出现过的异常
正态分布(高斯分布)的概率密度函数

推广(向量):


非高斯特征转化 :

协调过滤:
回归成本函数:

梯度算法:

均值归一化作用: 若无评分数据,使用全局均值 μglobal 作为初始预测值。

预测值:

基于内容的过滤算法:



4.3 降维算法
4.3.1 PCA
无监督的线性降维方法,通过正交变换将高维数据投影到低维空间,保留数据中的最大方差(即信息量)。以期用更少的特征(主成分)解释原始数据中的大部分变异性。
数据线性变化:
1)拉伸:S为对角矩阵
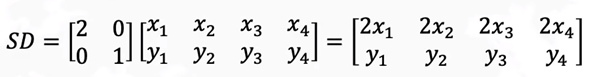
2)旋转:R为正交矩阵
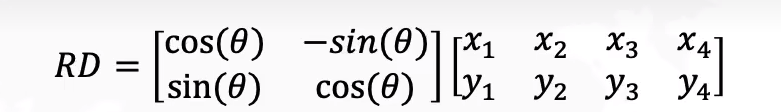
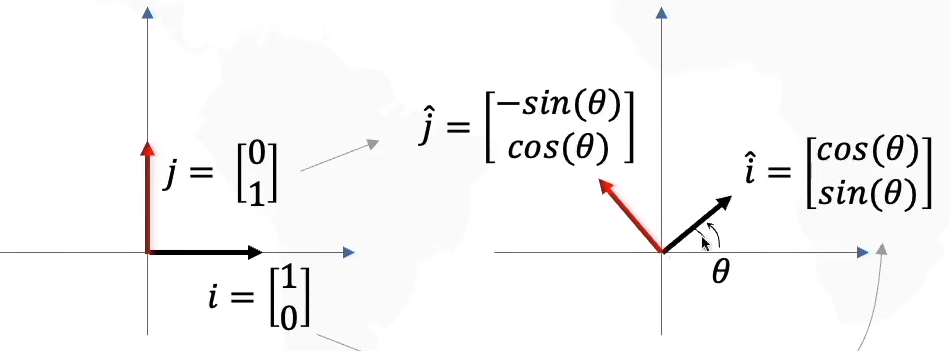
PCA原理:
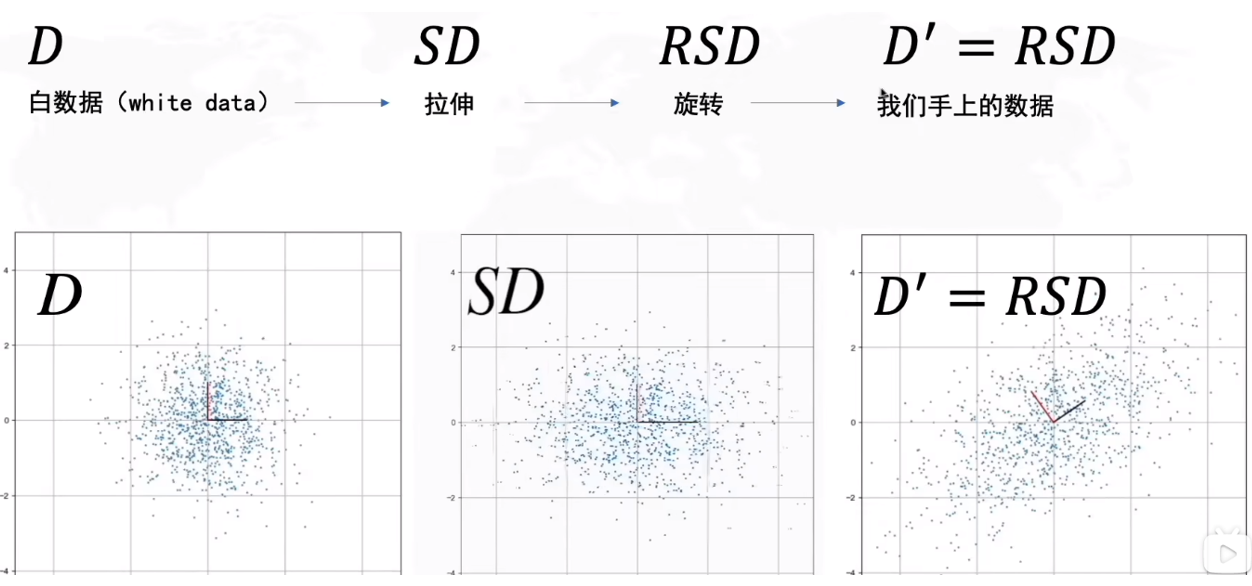
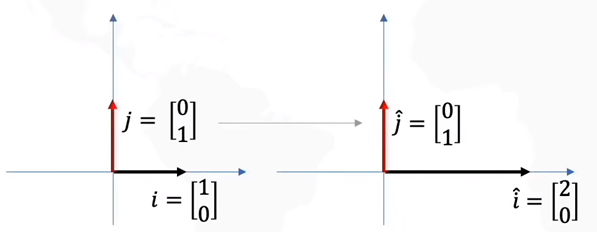
原坐标轴与新坐标轴:
主要步骤:
1)中心化:

2)计算协方差矩阵:协方差矩阵一定是对称矩阵

3)特征值分解:

特征值:代表对应主成分所携带的数据方差的大小。
特征向量:代表对应主成分方向(新坐标轴方向),其中每个元素代表了原始特征在该主成分上的线性权重。
4)选择主成分:将特征值从大到小排序,对应最大的 k 个特征值的特征向量,就是我们要保留的 k 个主成分方向,得W=[v1,v2,...,vk]
选择 k 的方法:

5) 投影到这 k 个主成分方向上
![]()
异常值对PCA的影响:
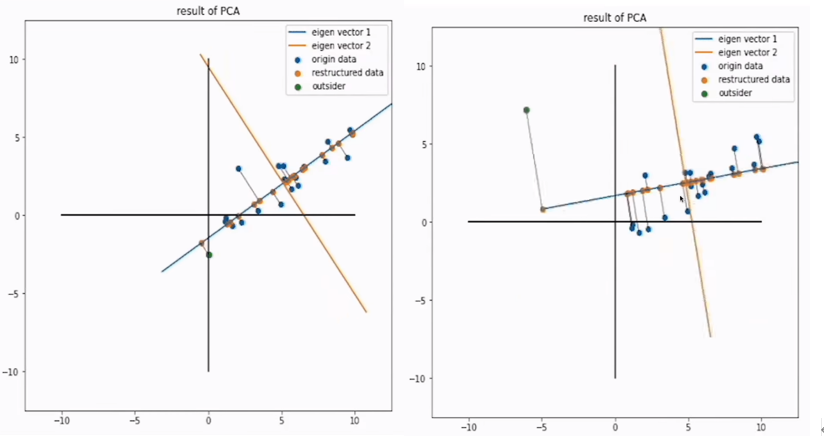
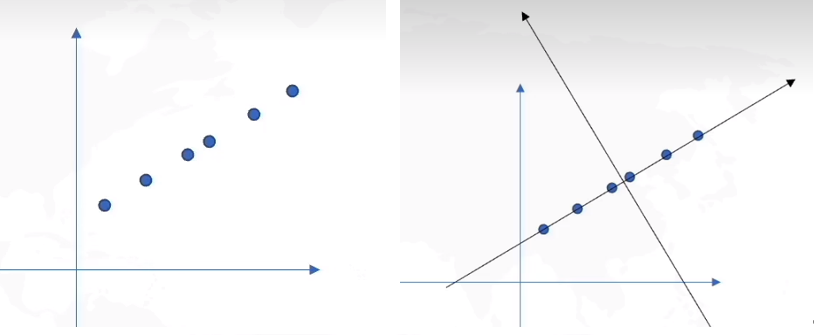
与线性回归的区别:

4.3.2 SVD
几何直观:一个线性变换可分解为旋转 (Vᵀ) → 缩放 (Σ) → 旋转 (U)。
SVD的标准形式:
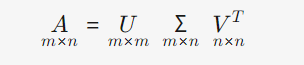
左奇异向量矩阵 (U):描述行空间的正交基(单位特征向量)。是正交矩阵
奇异值对角矩阵 (Σ):对角线上是奇异值 (σ) ,表示矩阵的“重要性”或“强度”。由大到小排列
右奇异向量矩阵 (Vᵀ):描述列空间的正交基(单位特征向量)。是正交矩阵
矩阵乘积的特征向量关系:
AAᵀ的特征向量 ⟹ 左奇异向量 (U)AᵀA的特征向量 ⟹ 右奇异向量 (V)
推导过程:
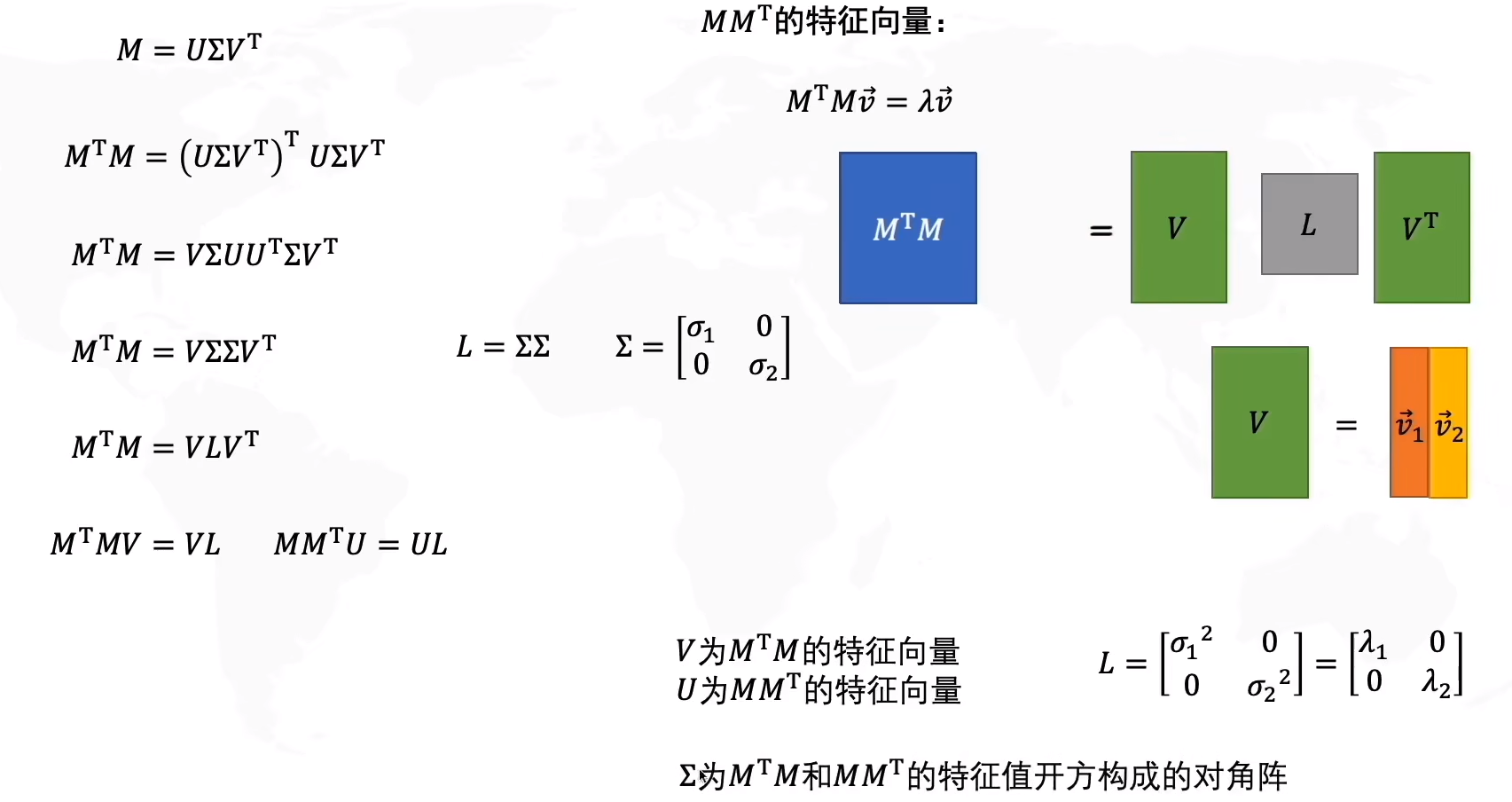
SVD与PCA的关系: 当用于数据降维时,右奇异向量 V 的列即为PCA的主成分方向。
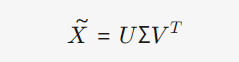
SVD与PCA的关系:
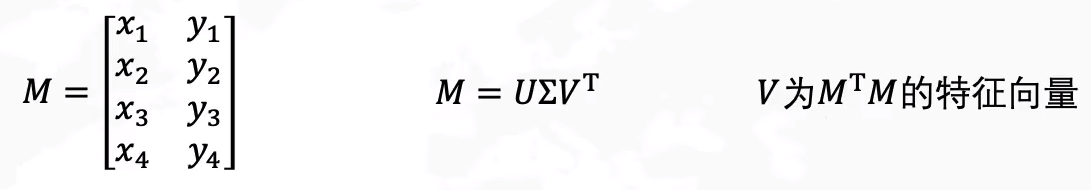

协方差的分解:(特征值与特征向量的矩阵形式)
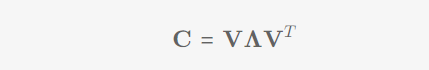
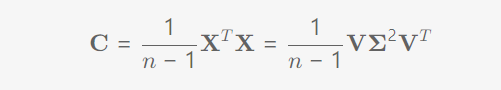
计算PCA时更偏向计算SVD的原因:
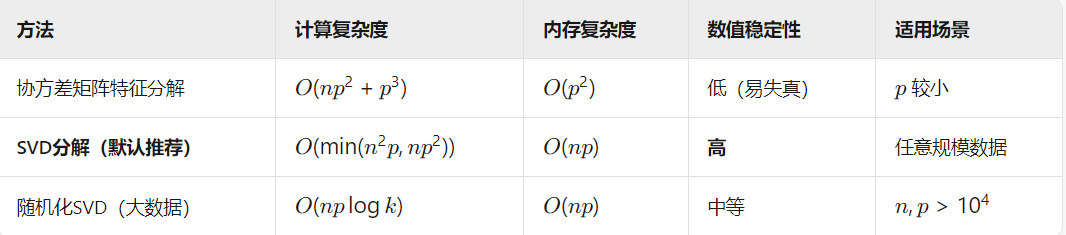
关键结论:SVD跳过了协方差矩阵的计算和分解, 仅在推导数学等价关系时需要 ,实际算法实现中完全不会计算它!
SVD降维为K维示例:
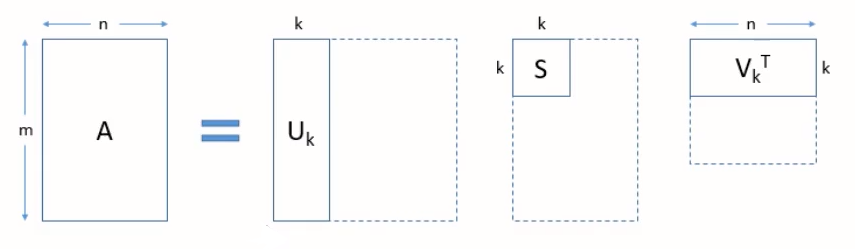
SVD的工作流程图:
假设:
1) 计算 和
2) 特征分解 (B 和 C 的非零特征值完全相同)
3) 提取奇异值, 构造 Σ
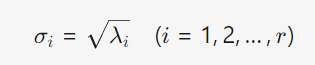
4) 构造分解结果, 得
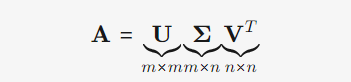
4.3.3 LSA
在大量文本语料中挖掘词语和文档之间隐含的潜在语义结构(主题)。
LSA 用于解决的问题:
1) 同义词问题: 如“汽车” 和 “轿车” 意思相近,但被当作完全不同的词。
2) 一词多义问题: 如 “苹果” 可以是水果也可以是公司,词频统计无法区分其在不同语境下的含义。
3) 主题关联问题: 如“价格” 和 “昂贵” 虽然不同义,但在讨论商品时经常共现并关联到同一个主题“价值”
停止词:一类高频出现但信息量较低的词汇。如 it、to、的、是、了等词。 一般预处理时先删除停止词。
主要内容分解:
1) 构建词-文档矩阵
2) 降维:奇异值分解 (SVD)
3) 截断: 只保留前 k 个最大的奇异值及其对应的左右奇异向量
4) 潜在语义空间: 降维后(k 维),词语和文档都被映射到一个新的、k 维的联合语义空间。
应用:
1) 词语的含义由其在 矩阵中的行向量表示。可以用于发现同义词、近义词、相关词。语义相似的词在空间中距离相近。
2) 文档的含义由其在 矩阵中的列向量表示。可以用于文档分类、聚类、推荐相似文档。主题相似的文档在空间中距离相近。
4.3.4 LDA
发现大规模文档集合(语料库)中隐藏的语义结构(即“主题”)用于主题建模和文档生成的概率生成模型
示例图:

模型运行可得到:
1)文档下主题的概率:

2)主题下词语分布概率:

LSA与LDA的区别:
| 特性 | LSA | LDA |
|---|---|---|
| 理论基础 | 线性代数(矩阵分解) | 概率图模型(贝叶斯生成模型) |
| 核心方法 | 奇异值分解(SVD) | 狄利克雷分布-多项式分布 |
| 数据表示 | 词-文档矩阵(TF-IDF权重) | 词频统计(词在文档中的出现次数) |
| 输出结果 | 隐含语义空间(数值向量) | 概率分布(主题-词、文档-主题) |
五、强化学习
贝尔曼方程:

- Agent(智能体):决策主体,执行动作(Action)。
- State(状态 s):环境在某一时刻的描述。
- Action(动作 a):Agent的行为选择。
- Reward(奖励 R(s)):环境对Agent动作的即时反馈。
- Value Function(价值函数):衡量状态或动作的长期价值(Q(s,a))。
- 其中γ∈[0,1]为折扣因子
软更新

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)