从Claude Code源码泄露到自主Agent:我学到了哪些Agent编排技巧?
写在前面
2026年3月31日,AI圈炸了。因为一个59.8MB的source map文件没有被从npm包里排除,Anthropic旗下Claude Code超过51万行TypeScript源码被完整公开。安全研究员Chaofan Shou披露后,数小时内GitHub上就涌现大量镜像仓库,一个仓库几小时内就拿了3万星标、4万多个fork。这不是模型权重的泄露,没有用户数据被暴露——但它暴露了什么?一套完整的工业级AI Agent编排架构。作为正在搭建多Agent系统的开发者,这次的泄露比任何官方文档都更有价值。我用两周时间研读了这些源码和相关分析报告,提炼出了一套可以复用的编排设计模式。今天,我把这套方法论完整拆解出来。

一、事件复盘:51万行TypeScript的意外“开源”
2026年3月31日,Anthropic向npm推送Claude Code v2.1.88版本时,因.npmignore配置疏漏,将59.8MB的source map文件一起打包进了公开发布的npm包中。这份source map文件中包含了完整的未混淆TypeScript源码,共计约51.2万行,覆盖1,906个源文件、超过40个工具模块及多项未发布功能。
泄露的代码库构建在Bun运行时上,用React和Ink驱动终端UI。包含一个大型QueryEngine、集中式工具注册表、数十个斜杠命令、持久化记忆、IDE桥接、MCP集成、远程会话、插件、技能,以及支持后台和并行工作的任务层。Anthropic发言人将事故定性为“人为失误”,但即便是这样一次失误,也让全球开发者得以一窥顶级AI Agent的工业级架构。
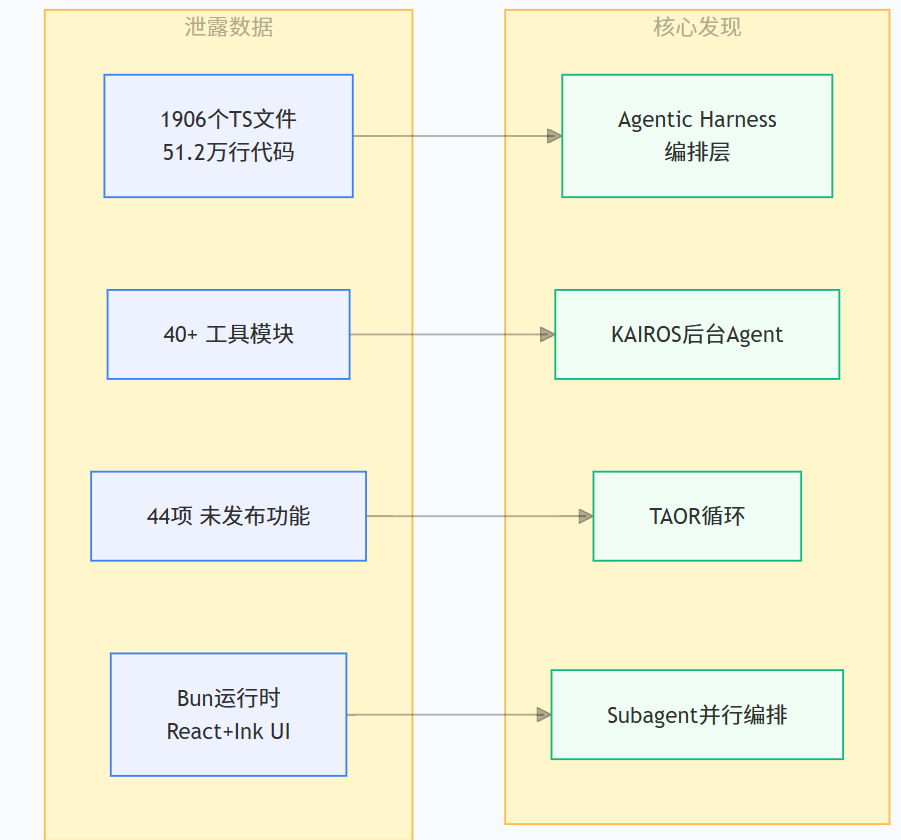
二、Agentic Harness:模型之外的真正护城河
这次泄露揭示了Claude Code最核心的设计哲学:模型本身正在商品化,真正的竞争壁垒在于围绕模型构建的编排层(Harness) 。
Claude Code的架构核心,是一个“Harness”本地运行时的外壳,更像是一个用于软件工作的操作系统,围绕模型堆叠了权限管理、记忆层、后台任务、IDE桥接、MCP管道和多代理编排。
Vikash Rungta在他的逆向工程分析里把这个结构总结为:把LLM(Brain)包裹在工具、记忆和编排逻辑(Body)之中,让模型能在现实世界里行动。
Claude Code = Agentic Harness
├── 工具与执行:Read/Write/Execute/Connect原语
├── 权限系统:七层审批 + ML分类器
├── 记忆与上下文:五层上下文压缩管线
├── 子代理编排:Worktree隔离的并行分发
├── 扩展生态:MCP + Plugins + Skills + Hooks
├── 后台能力:KAIROS常驻守护进程
└── UI与交互:React + Ink终端界面从更宏观看,Agent架构经历了三个代际的演进:第一代是Chatbot,无状态问答;第二代是Workflow,用n8n、LangChain这类工具把LLM嵌进代码驱动的DAG流里;第三代是Autonomous Agent,模型控制循环,运行时只是执行器。Claude Code属于商业化落地的第三代产品。
这个架构最核心的设计原则是:LLM本身日益商品化,真正的长期竞争力在于编排层——工具定义、安全围栏、记忆系统和工作流逻辑的设计与工程化。
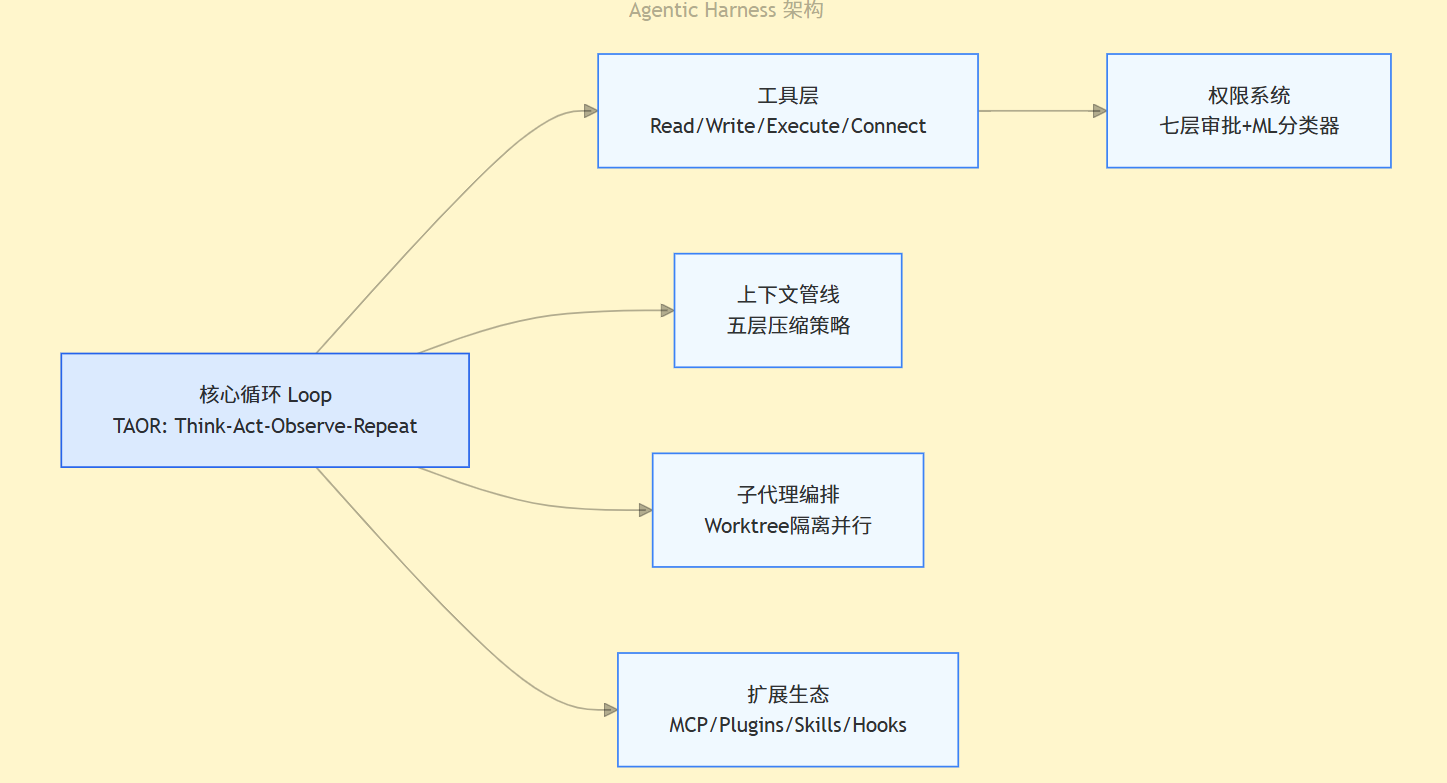
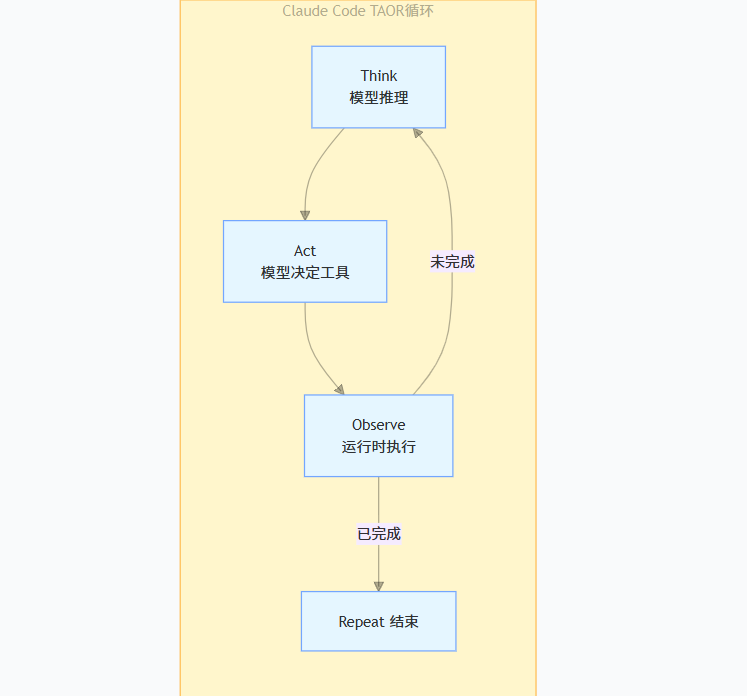
三、编排模式一:TAOR循环——让运行时变“笨”
Claude Code的执行引擎是一个叫TAOR的循环:Think-Act-Observe-Repeat。它的核心逻辑简单到让人意外——大约只有50行:
// Claude Code 核心循环伪代码
async function agentLoop(messages: Message[]) {
while (true) {
// 1. 调用模型
const response = await callModel(messages);
// 2. 如果没有工具调用,结束
if (!response.toolCalls?.length) {
return response.text;
}
// 3. 执行工具,收集结果
const toolResults = await executeTools(response.toolCalls);
// 4. 追加结果到消息列表,继续循环
messages = [...messages, response, ...toolResults];
}
}这段while-loop代码看起来平平无奇,任何写过LangChain的开发者都能在20行内实现同样的逻辑。但Claude Code的50万行代码里,95%不在这个循环本身,而在围绕它构建的五个核心子系统:权限系统、上下文管线、扩展机制、子代理编排和会话存储。
这种设计的哲学思考是:Orchestrator越笨,架构越稳定。
运行时不知道代码是什么、不知道文件在哪,它只是跑循环,让模型决定下一步。把所有推理、决策、何时停止的判断,全部交给模型。硬编码的脚手架应该随着模型能力提升而被主动删除,让架构随时间推移越来越薄。
这与早期LangChain试图在框架层做各种“聪明编排”的路线形成了鲜明对比。LangChain倾向于把编排逻辑写进代码,用复杂的Orchestrator控制每一步;Claude Code的做法是,把智能下沉到模型,把确定性留给框架。
在工具层也遵循同样的“笨”哲学。Claude Code没有给模型配备100个专项工具,而是只提供四种能力原语:Read、Write、Execute、Connect。其中Bash是通用适配器,允许模型使用任何人类开发者会用的工具——git、npm、docker,全部通过shell组合完成。
核心启示:不是构建100个工具,而是给模型一个shell,让它自己组合。
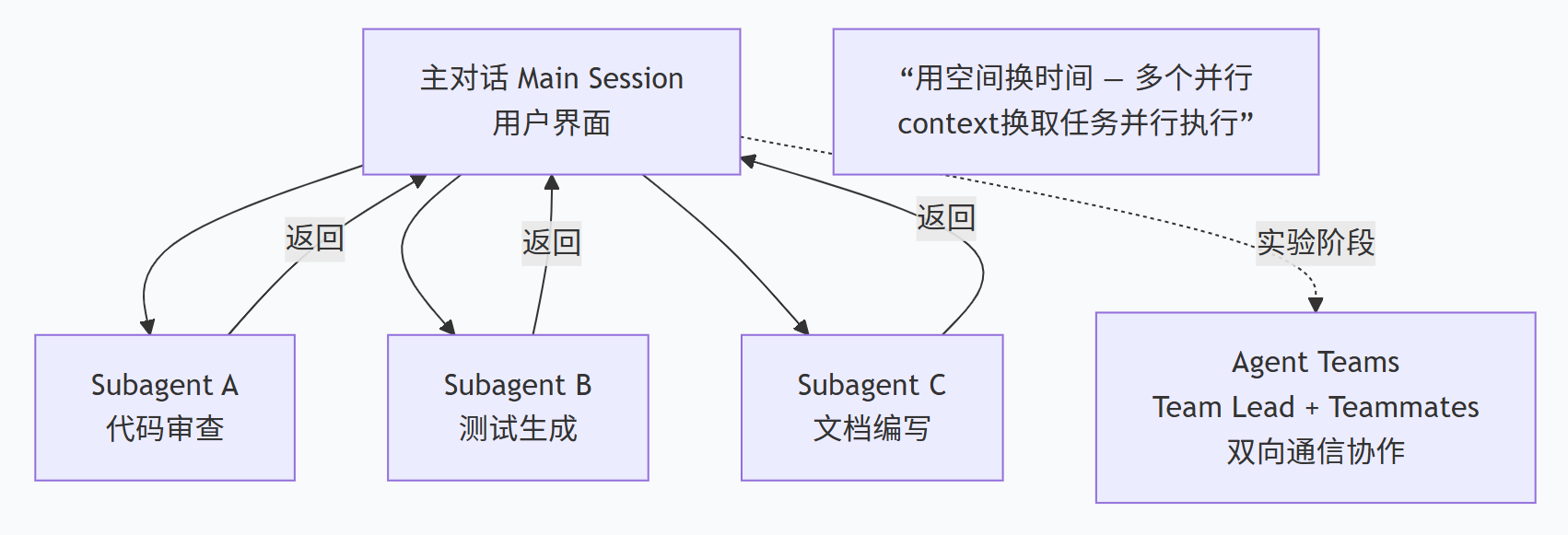
四、编排模式二:三层并行架构——Subagents + Agent Teams + Git Worktree
Claude Code的多智能体编排是这次泄露中另一个极具价值的亮点。它的系统设计了三层并行架构:
-
第一层:主对话 — 用户直接交互的界面窗口
-
第二层:Sub-agents — 由主对话按需创建的专家实例,有独立context window和预设的工具权限范围
-
第三层:Agent Teams — 实验阶段的高级功能,引入Team Lead + Teammates,支持多Agent双向讨论
Subagent模式下,通信是单向的:主对话分发任务,Subagent上报结果,Subagent之间不能直接通信。Subagent最多可并行运行49个,完全满足大多数并行处理需求。Claude Code预置了多个内置Subagent:Explore(快速文件发现)、Plan(规划模式研究)、General-purpose(复杂多步骤操作)等。
Subagent的定义采用YAML frontmatter加Markdown中的系统提示。核心配置字段包括name、description、tools(可用的工具列表)、model(sonnet/opus/haiku/inherit)和permissionMode等。
多智能体的本质不是“更聪明的AI”,而是“用空间换时间”——用多个并行context换取任务的并行执行。
五、编排模式三:七层权限系统 + ML分类器
这是Claude Code架构中最被低估的设计。大多数开源Agent框架对安全的态度是“加个确认弹窗”,而Claude Code构建了一套完整的分级权限体系。
七种权限模式覆盖了从只读到高危操作的完整梯度:
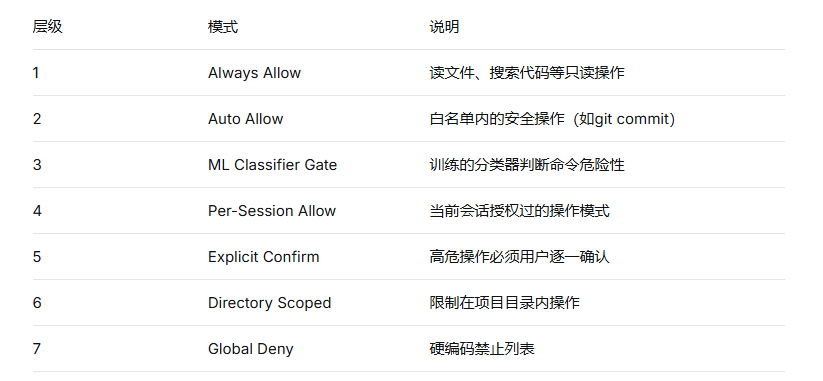
传统方案靠正则黑名单,而Claude Code引入了ML分类器作为第三层审批,用训练过的模型判断命令危险性,比关键词匹配灵活得多。
权力并非越大越好,可靠的分级控制才是生产级Agent的基石。
六、编排模式四:KAIROS——7×24小时的常驻后台Agent
泄密源码中最引人瞩目的,是一个代号为KAIROS的feature flag。它被命名为“KAIROS (assistant mode)”,配置描述将其定义为:“Start Claude in assistant mode (custom system prompt, brief view, scheduled check-in skills)”。在源码注释里直接写着:KAIROS的目标是一个7×24小时在线的全能助手。
更具体地说,KAIROS是一个完整的“常驻守护进程”能力,包含三个核心模块:
-
夜间“记忆蒸馏” — 将零散观察合并,修剪不一致的状态,重写模糊记录为确定性断言
-
主动信息刷新 — 订阅GitHub webhook,用cron调度周期刷新
-
异步后台任务 — fork子Agent执行后台任务,避免污染主推理线程
KAIROS的定位非常明确:它要让Claude Code彻底变成一个像《钢铁侠》里贾维斯那样的全能助手——有自定义系统提示词、适合助手的简化交互视图、支持定时检查和定时触发的Skills,并能订阅GitHub等外部信号随时响应。
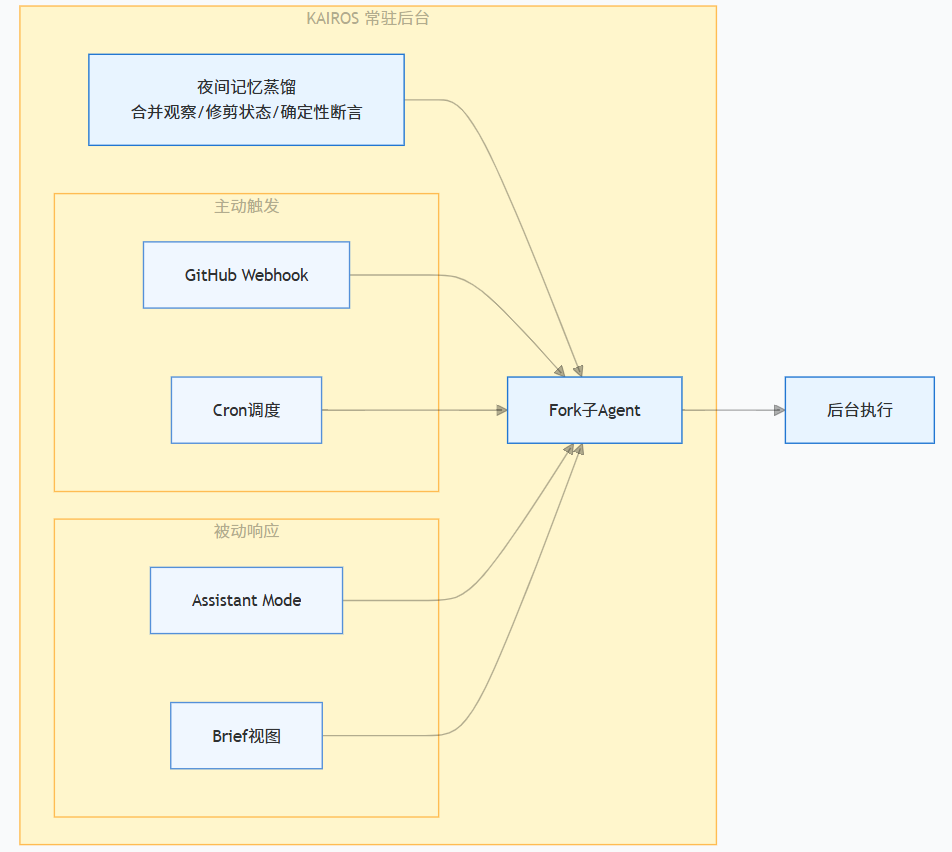
记忆蒸馏的设计理念对构建企业的长期记忆系统和跨会话状态持久化有重要借鉴意义。
七、从Claude Code到你的Agent项目:可复用的实战设计
7.1 总体架构启示
-
编排层是核心竞争壁垒。当基础模型能力趋于同质化时,Harness层的设计决定了Agent的生产级能力——工具定义、权限安全、记忆系统和编排逻辑才是关键。所有开发者在搭建Agent时都应优先投资编排层,而非把时间和预算全花在调模型上。
-
从TAOR循环开始。一个智能循环引擎是Agent调用的核心。你甚至可以从那50行核心循环开始,逐步添加Harness层的功能——先实现基本的thinking-action-observation闭环,然后根据需求逐步叠加权限、记忆和并行能力。
-
权限安全从第一天就要设计。七层权限系统听起来复杂,但在实际构建生产级Agent时,明确评估工具操作风险、配置相应审批模式,远比事后补救更可靠。
7.2 Subagent的Java实现思路
基于Spring AI Alibaba和Java生态,可以这样设计Subagent系统:
// Subagent定义(借鉴Claude Code的设计)
public class SubagentConfig {
private String name; // 唯一标识符
private String description; // 何时委托给此Subagent
private List<String> tools; // 可用工具列表
private String model; // sonnet/opus/haiku
private PermissionMode permMode; // default/acceptEdits/auto
}
// Subagent执行器
public class SubagentExecutor {
// 主对话创建Subagent实例,每个实例独立context
public CompletableFuture<SubagentResult> execute(
SubagentConfig config,
String task
) {
// 1. 隔离上下文窗口(避免相互污染)
// 2. 在独立工作空间中执行
// 3. 返回结果给主Agent,不直接通信
// 4. 支持最多49个并行实例
}
}7.3 权限分级的设计原则
借鉴Claude Code的权限分级思想,在生产级Agent中可设计如下:
-
只读操作自动放行(如代码读取、文件搜索)
-
安全写入自动授权(如git commit、标准目录写入)
-
高危操作人工确认(如rm -rf、网络请求、系统调用)
-
加上ML分类器辅助判断,代替简单的正则黑名单
7.4 Agent编排的核心经验
-
先单Agent后多Agent。先用ReAct Agent加几个工具解决问题,只有遇到任务可清晰分解、子任务并行度高、错误容忍度高的场景,才引入多智能体编排。
-
隔离比协作更重要。每个Subagent应运行在独立的上下文窗口中,避面跨消息相互污染。
-
编排拓扑决定成败。Google DeepMind已证实,无拓扑结构的多Agent系统会将误差放大至17倍,结构化编排则能提升90%以上的性能。
-
优雅降级。当Agent遇到不确定或不安全的操作时,有人工介入的兜底选项。
八、总结
Claude Code源码泄露是一次经典的“工业透明度”事件。它让外界看到了一个生产级AI Agent的完整架构:Agentic Harness编排层、TAOR循环、七层权限系统、Subagent并行编排模式、KAIROS常驻后台记忆系统以及MCP协议集成。
对正在构建Agent应用的开发者而言,以下核心启示值得记住:
-
LLM正在商品化,真正的长期竞争力在于编排层——工具定义、安全围栏、记忆系统和工作流逻辑的设计与工程化
-
TAOR循环是核心引擎,但95%的工程量在循环外的编排层——从50行代码开始迭代,逐步扩展权限和记忆能力
-
编排拓扑比框架选择重要,无结构的多Agent系统误差放大到17倍,结构化编排能提升90%以上的性能
-
KAIROS的设计理念——后台常驻、记忆蒸馏、异步执行——为构建长时记忆Agent提供了清晰的思路
技术栈或许会变,但这些工程设计原则在任何Agent项目中都是通用的。用工程思维去设计Agent系统,是走向成熟的关键一步。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)