Java 让 AI 自己爬网页存数据,MCP 这个新玩意儿真好用
以前给 AI 加能力,得写一堆胶水代码拼 JSON。现在 MCP 出来,把“工具”标准化了,Java 这边实现一次,多种 AI 都能用。核心就三步用 Java 写工具类(爬虫、存库);注册到 MCP Server,定义好参数 Schema;AI 通过 MCP Client 调用这些工具,自主决策。对于后端来说,这玩意儿就是“可以让 AI 调你的业务接口”的工程化方案,一点都不虚。别再手动抓数据拼
一、又是我,这次想让 AI 帮我扒数据
前阵子搞个小需求:每天从竞品网站抓一些公开的产品参数,整理后写进数据库,然后让 AI 帮我做分析。
传统做法很无聊:写个爬虫,把数据跑下来清洗好,再拼成 Prompt 喂给大模型。整个过程我管 80% 的脏活累活,AI 就最后动动嘴皮子。
我就在想,能不能让 AI 直接去扒数据?你说“去把 XX 页面的价格爬下来存库里”,它自己就去干了,全程我不管。
还真能。最近 Anthropic 搞了个东西叫 MCP(Model Context Protocol),说白了就是一套让大模型调用外部工具的协议。你把“爬虫”包装成工具,AI 就能直接用了。
今天就结合 Java 把这条链路跑一遍,代码都给你。
二、MCP 是什么,说人话
别被名词吓住。MCP 就干一件事:定义了一套 Client 和 Server 之间的通信标准,让 AI 模型可以像调函数一样调用你写好的“工具”。
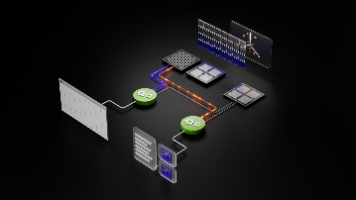
架构长这样:
你的 Java 应用(AI 模型) ←— MCP Client —→ MCP Server(你写的工具)
MCP Server 里可以注册多个工具,比如:
web_fetch:爬取网页文本save_to_db:存数据库web_search:联网搜索
AI 模型能自己决定在什么时候调用哪个工具。你只需要用 Java 实现这些工具,注册到 Server 上,剩下全交给模型。
最关键的是,它和模型无关。你用 GPT、Claude、DeepSeek,只要是支持 Function Calling 的模型,都能接。
三、动手前的技术选型
目前 Java 生态里有两个选择:
- 用 Spring AI 的 MCP 支持:Spring AI 1.0 M3 之后内置了 MCP Client 和 Server 的抽象,适合 Spring 项目;
- 直接用官方 SDK:Anthropic 提供了 Java 的 MCP SDK(
io.modelcontextprotocol),不挑框架。
我这为了最快出活,用了官方 SDK + Spring Boot。Spring Boot 负责起服务和依赖注入,MCP Server 单独跑一个端口。
整体依赖:
<!-- MCP Server 官方SDK -->
<dependency>
<groupId>io.modelcontextprotocol</groupId>
<artifactId>mcp-server</artifactId>
<version>0.4.0</version>
</dependency>
<!-- 爬虫用 Jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.1</version>
</dependency>
<!-- 数据库随便,我用 MyBatis-Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.7</version>
</dependency>
四、写一个 MCP Server,注册工具
MCP Server 启动后,会通过 JSON-RPC 跟 Client 通信。我们要做的,是定义工具并注册进去。
先写工具类,把爬虫和存储逻辑都放在里面:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.stereotype.Component;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import javax.annotation.Resource;
@Component
public class WebTools {
@Resource
private ProductDataMapper productDataMapper;
/**
* 工具:爬取网页纯文本
*/
public String fetchWebPage(String url) {
try {
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0")
.timeout(10000)
.get();
// 只取正文文本,去掉 script/style
return doc.body().text();
} catch (Exception e) {
return "爬取失败: " + e.getMessage();
}
}
/**
* 工具:将产品数据存入数据库
*/
public String saveProductData(String productName, String price, String sourceUrl) {
ProductData data = new ProductData();
data.setProductName(productName);
data.setPrice(price);
data.setSourceUrl(sourceUrl);
data.setCreateTime(LocalDateTime.now());
productDataMapper.insert(data);
return "已保存:" + productName + " 价格:" + price;
}
/**
* 工具:查询已存的产品列表
*/
public String queryProducts(String keyword) {
List<ProductData> list = productDataMapper.selectList(
new QueryWrapper<ProductData>().like("product_name", keyword)
);
if (list.isEmpty()) return "没找到相关产品";
return list.stream()
.map(p -> p.getProductName() + " : " + p.getPrice())
.collect(Collectors.joining("\n"));
}
}
然后在配置类里启动 MCP Server,把这些方法注册为工具:
import io.modelcontextprotocol.server.*;
import io.modelcontextprotocol.server.transport.StdioServerTransport;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
public class McpServerStarter {
@Autowired
private WebTools webTools;
@PostConstruct
public void start() {
McpServer server = McpServer.create();
// 注册工具:爬取网页
server.addTool(
McpTool.newBuilder()
.name("web_fetch")
.description("爬取指定URL的网页文本内容")
.inputSchema(JsonSchema.builder()
.addProperty("url", JsonType.STRING, "要爬取的网页地址")
.required("url")
.build())
.handler(params -> {
String url = params.get("url").getAsString();
String result = webTools.fetchWebPage(url);
return ToolCallResult.success(new TextContent(result));
})
.build()
);
// 注册工具:保存数据
server.addTool(
McpTool.newBuilder()
.name("save_product")
.description("将产品信息保存到数据库")
.inputSchema(JsonSchema.builder()
.addProperty("productName", JsonType.STRING, "产品名称")
.addProperty("price", JsonType.STRING, "价格")
.addProperty("sourceUrl", JsonType.STRING, "来源URL")
.required("productName", "price", "sourceUrl")
.build())
.handler(params -> {
String result = webTools.saveProductData(
params.get("productName").getAsString(),
params.get("price").getAsString(),
params.get("sourceUrl").getAsString()
);
return ToolCallResult.success(new TextContent(result));
})
.build()
);
// 注册工具:查询数据库
server.addTool(
McpTool.newBuilder()
.name("query_products")
.description("按关键字查询已保存的产品数据")
.inputSchema(JsonSchema.builder()
.addProperty("keyword", JsonType.STRING, "产品名称关键字")
.required("keyword")
.build())
.handler(params -> {
String result = webTools.queryProducts(params.get("keyword").getAsString());
return ToolCallResult.success(new TextContent(result));
})
.build()
);
// 使用 STDIO 传输启动(也可用 HTTP SSE)
server.start(new StdioServerTransport());
}
}
到这里,MCP Server 已经跑起来了。它通过标准输入输出跟客户端通信(也可以用 HTTP SSE,但 STDIO 最简单)。
五、让 AI 调用这些工具
MCP Client 我直接用 Python 写了(因为很多 MCP Client 库最成熟),负责连接上面的 Java Server,并调用大模型。
但按你公众号的尿性,你们肯定要 Java 的。Java 侧的 MCP Client 示例:
import io.modelcontextprotocol.client.McpClient;
import io.modelcontextprotocol.client.transport.StdioClientTransport;
public class AiClient {
public static void main(String[] args) {
// 连接刚才的 Java MCP Server(启动命令)
McpClient client = McpClient.withTransport(
new StdioClientTransport("java -jar your-mcp-server.jar")
).build();
// 列出可用工具
client.listTools().forEach(t ->
System.out.println(t.getName() + ": " + t.getDescription())
);
// 调用工具示例
String pageContent = client.callTool("web_fetch",
Map.of("url", "https://example.com/product/123"));
System.out.println(pageContent);
}
}
但要让 AI 自动决策,就得把 MCP 工具列表发给大模型(比如 GPT-4),让模型根据用户指令自己选工具。这部分标准流程是这样的:
- 把工具列表转成 Function Calling 的定义;
- 用户说“去XX网站爬下价格存起来”,发给大模型;
- 模型返回它想调的工具名和参数;
- 你用 MCP Client 执行该工具,把结果再发给模型;
- 模型根据结果回复用户“已经存好了,XX 价格是 XX”。
这些逻辑可以封装在一个 Service 里。因为篇幅不展开,但核心就是 MCP 负责工具的统一调用,AI 负责决策。
六、进阶:用 MCP 实现“AI 上网自由”
上面是最小闭环。更高级的玩法是注册一个 web_search 工具,接上 Bing API 或 SearXNG,那 AI 就真能自主搜索+爬取+存储了。
我前几天就试了一次:对它说“帮我把最近一周‘Java 25 新特性’的文章标题和链接抓过来存库里”,它自己搜、自己爬、自己存,我就喝茶等着。那一刻感觉真值。
踩坑提醒:
- MCP Server 如果用 STDIO 模式,启动命令必须非常可靠,否则 Client 连不上;
- 爬虫注意遵守 robots.txt,别给人家服务器压力;
- 大模型挑选工具有时会抽风,Prompt 里最好加一句“优先使用 web_fetch 工具”;
- 数据库操作记得加事务,爬了半天下不来别写个残废数据进去。
七、总结
以前给 AI 加能力,得写一堆胶水代码拼 JSON。现在 MCP 出来,把“工具”标准化了,Java 这边实现一次,多种 AI 都能用。
核心就三步:
- 用 Java 写工具类(爬虫、存库);
- 注册到 MCP Server,定义好参数 Schema;
- AI 通过 MCP Client 调用这些工具,自主决策。
对于后端来说,这玩意儿就是 “可以让 AI 调你的业务接口” 的工程化方案,一点都不虚。
别再手动抓数据拼 Prompt 了,把爬虫扔给 AI,你会发现自己像个在幕后操控一切的大反派,爽得很。
程序员小白条的编程日记:https://xbt.xiaobaitiao.top/ (分享如何拿到腾讯实习 Offer 和多个中大厂的面试机会,大学经历、求职经历、职场工作、创作经历、生活日常、面经、技术分享、毕设项目指导)定期更新内容,成长打怪系列,分享从大一到大四的完整面经,更新好玩的,有趣的事!看完可冲中大厂!dy同名程序员小白条,主要口述面试经历和分享我认为的实用网站,会比面经讲的详细很多,以真实面试录音为主!公粽号:程序员落叶(秋招技巧、面经、公司投递表、谈offer)
欢迎关注上方公众号!感谢支持!一起进步,共勉!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)