Memory组件运行流程及不同记忆分类
在 LangChain 中使用缓冲记忆组件要不就保存所有信息(占用过多容量),要不就保留最近的记忆信息(丢失太多重要信息),那么有没有一种情况是既要又要呢?所以折中方案就出现了 —— 保留关键信息(重点记忆),移除冗余噪音(流水式信息)。ConversationSummaryMemory,摘要总结记忆组件,将传递的历史对话记录总结成摘要进行保存(底层使用 LLM 大语言模型进行总结),使用时填充的
Memory组件
在LangChain中,大多数与记忆相关的功能都被标记beta,无论是0.1还是0.2的版本,这有两个原因:
- 大多数功能(有些例外,见下文)尚未准备好投入生产
- 大多数功能(有些例外,见下文)适用于传统链,而不是较新的LECL语法。
例外的案例是 chatMessageHistory 功能,这一功能目前可以无缝接入 LCEL 进行集成,并且根据源码的注释及更新路线说明,预计 LangChain 团队会在 0.3.0 ~ 0.4.0 版本,开始支持将 Memory 组件纳入到 LCEL 语法,目前版本的 Memory 组件均是 0.0.X 版本的产物。
Memory 组件的基类是 BaseMemory,封装了大量的基础方法,例如:memory_variables、load_memory_variables、aload_memory_variables、save_context、asave_context、clear、aclear 函数。
基于 BaseMemory 基类,衍生出了两个子类 SimpleMemory 和 BaseChatMemory,当 LLM 应用不需要记忆功能,又不想更换代码结构时,可以将记忆组件使用 SimpleMemory 组件进行代替,SimpleMemory 实现了记忆组件的相关方法,但是不存储任何记忆,可以在不修改代码结构的情况下替换记忆组件,实现无记忆功能。
而 BaseChatMemory 组件是 LangChain 中内置的其他记忆组件的基类,针对对话历史进行了特定的封装,以适用聊天模型对话的场合。
LangChain 记忆组件的流程图如下: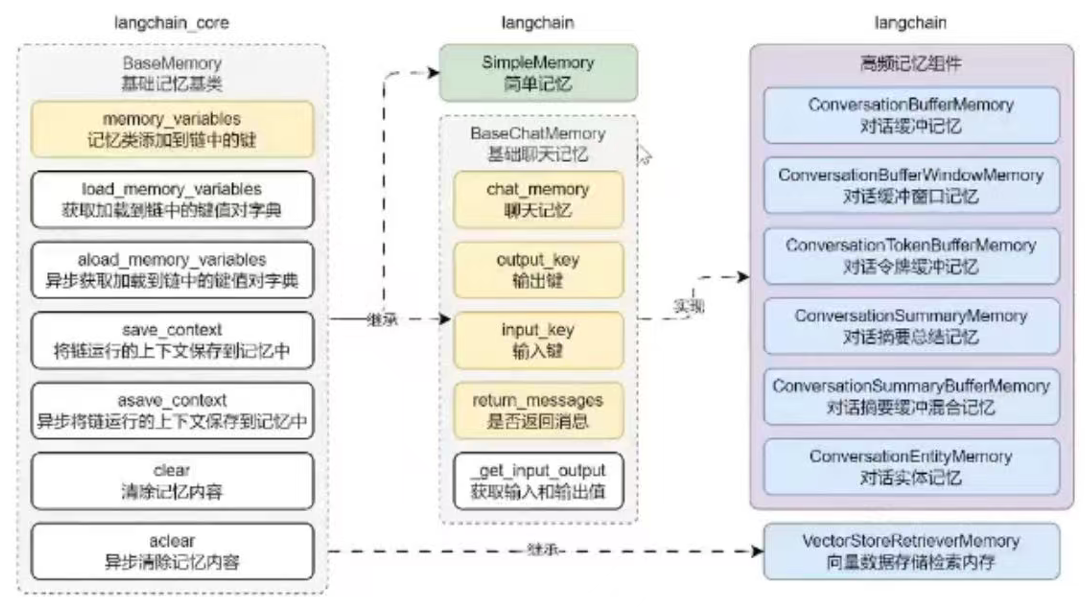
BaseChatMemory运行流程
在LangChain的BasechatMemory 组件中,不同的属性与方法有不同的作用:
- chat_memory:用于管理记忆中的历史消息对话。
- output_key:定义AI内容输出键。
- input_key:定义Human内容输入键。
- return_messages:l oad_memory_variables 函数是否返回消息列表,默认为 False 代表返回字符串。
- save_context:存储上下文到记忆组件中(存储消息对话)
- load_memory_yariables:生成加载到链的记忆字典信息。
- clear:清除记忆中的对话消息历史。
在聊天机器人的运行流程中,添加BasechatMemory组件后,整体流程变化如下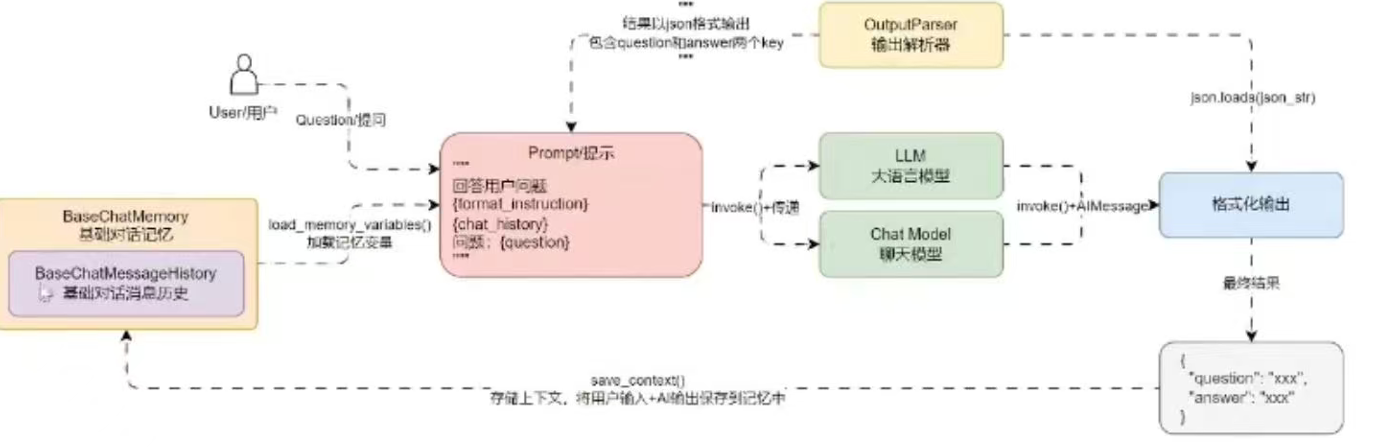
缓冲记忆组件的类型
缓冲记忆组件是LangChain中最简单的记忆组件绝大部分都不对数据结构和提取算法做任何处理,就是简单的原进原出,也是使用pin率最高的记忆组件,在LangChain中封装了几种内置的缓冲记忆组件,涵盖:
-
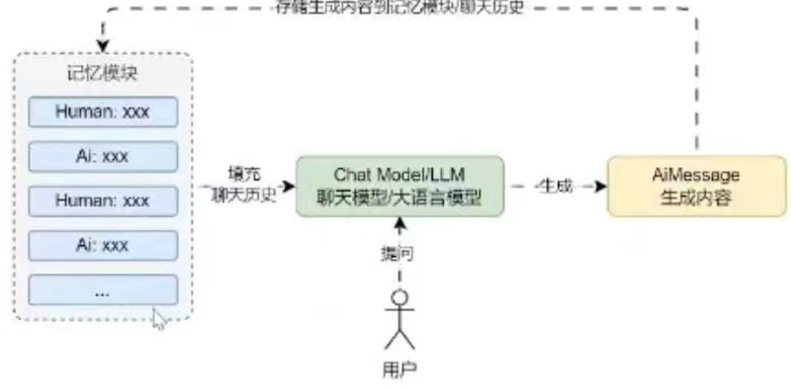
conversationBufferMemory: 缓冲记忆,最简单,对数据结构和提取算法不做任何处理,将所有对话信息全部存储作为记忆。
-
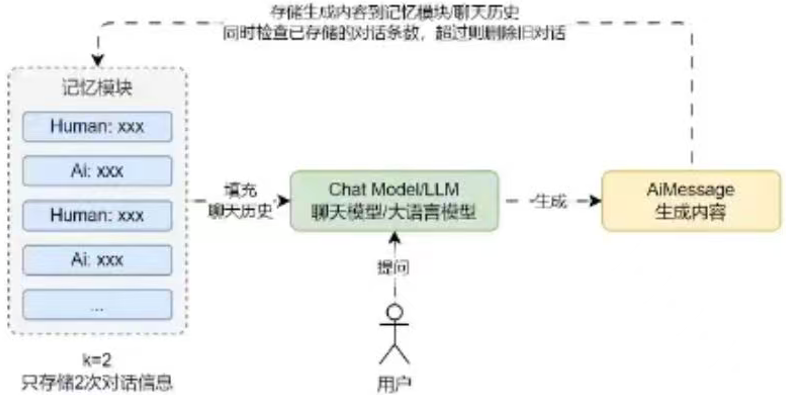
conversationBufferwindowMemory: 缓冲窗口记忆,通过设定K值,只保留一定数量(2*k)的对话信息作为历史。
-
conversationTokenBufferMemory: 令牌缓冲记忆,通过设置最大标记数量(max_token_limits)来决定何时清除交互信息,当对话信息超过max_token_limits时,抛弃旧对话信息
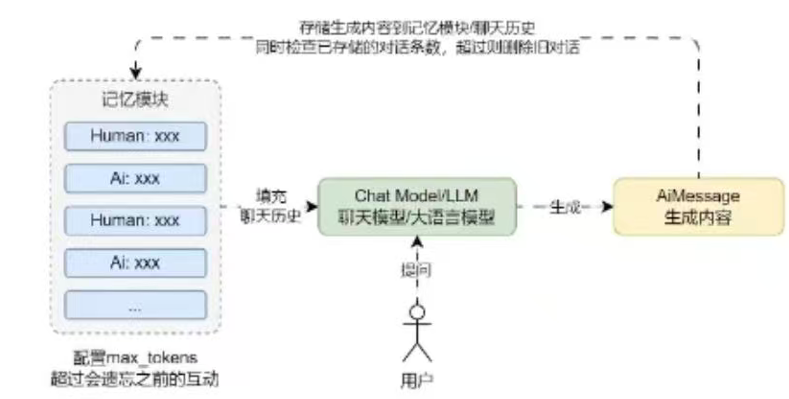
-
conversationStringBufferMemory: 字符串缓存记忆(早期LangChain封装的记忆组件),等同于缓存记忆,固定返回字符串。
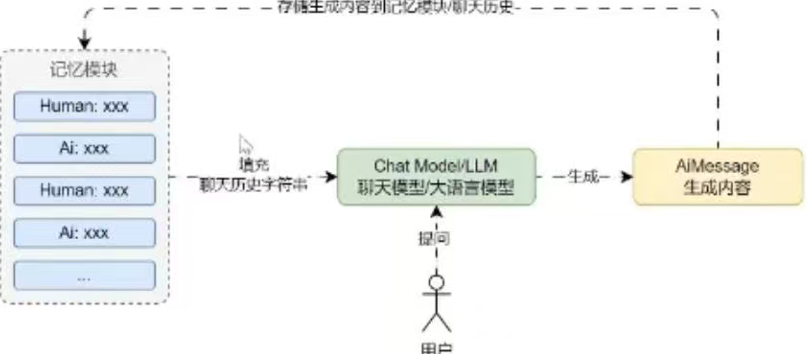
缓冲窗口记忆示例
from operator import itemgetter
import dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferWindowMemory
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
dotenv.load_dotenv()
# 1. 创建提示模版
prompt = ChatPromptTemplate.from_messages([
("system", "你是OpenAI开发的聊天机器人,请根据对应的上下文回复用户问题"),
MessagesPlaceholder('history'),
("human", "{query}")
])
memory = ConversationBufferWindowMemory(k=2, return_messages=True, input_key="query")
# 2. 创建大语言模型
# memory_variable = memory.load_memory_variables({}) # 返回的值是一个字典
llm = ChatOpenAI(model='gpt-3.5-turbo-16k')
# 3. 构建链应用
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
# 4.si循环构建对话命令行
while True:
query = input("Human: ")
if query == "q":
exit(0)
chain_input = {"query": query}
response = chain.stream(chain_input)
print("AI: ", flush=True, end="")
output = ''
for chunk in response:
output += chunk
print(chunk, flush=True, end="")
memory.save_context(chain_input, {"output": output})
print("")
LangChain摘要记忆组件的使用
摘要记忆组件的类型
在 LangChain 中使用缓冲记忆组件要不就保存所有信息(占用过多容量),要不就保留最近的记忆信息(丢失太多重要信息),那么有没有一种情况是既要又要呢?
所以折中方案就出现了 —— 保留关键信息(重点记忆),移除冗余噪音(流水式信息)。
在 LangChain 中 摘要记忆组件 就是一种折中的方案,内置封装的摘要记忆组件有以下几种:
- ConversationSummaryMemory,摘要总结记忆组件,将传递的历史对话记录总结成摘要进行保存(底层使用 LLM 大语言模型进行总结),使用时填充的记忆为摘要,并非对话数据。这种策略融合了记忆质量和容量的考量,只保留最核心的语义信息,有效减少了冗余,同时质量更高。
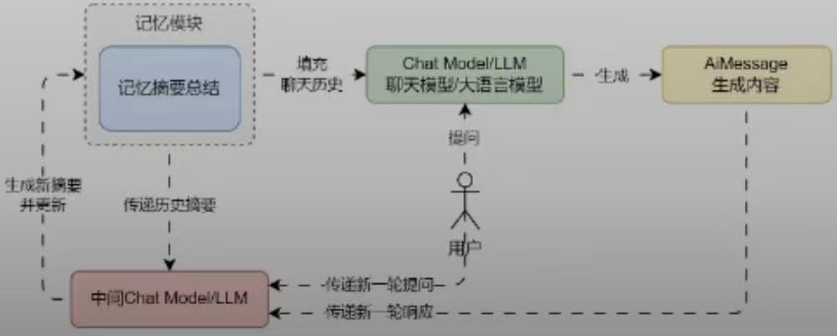
- ConversationSummaryBufferMemory,摘要缓冲混合记忆,在不超过max_token_limit 的限制下,保存对话历史数据,对于超过的部分,进行信息的提取与总结(底层使用 LLM 大语言模型进行总结),兼顾了精确的短期记忆与模糊的长期记忆。
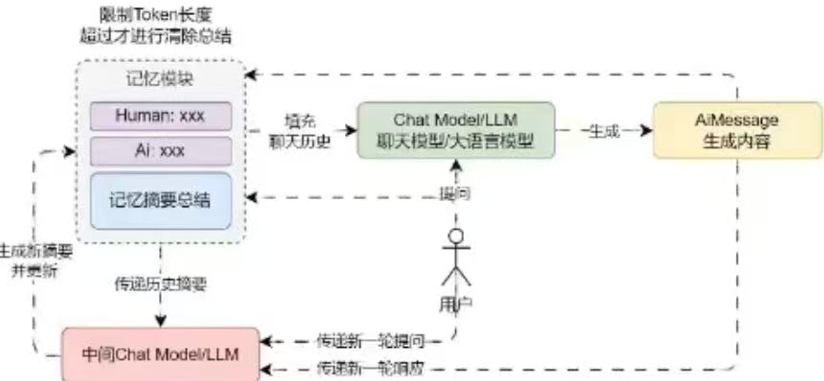
摘要缓冲混合记忆示例与注意事项
摘要缓冲混合记忆示例
使用LangChain实现一个案例,让LLM应用拥有多轮对话,并将历史记忆max_token_limit限制为300,超过的部分进行总结产生总结记忆。代码:
from operator import itemgetter
import dotenv
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferWindowMemory,ConversationSummaryBufferMemory
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
dotenv.load_dotenv()
# 1. 创建提示模版
prompt = ChatPromptTemplate.from_messages([
("system", "你是OpenAI开发的聊天机器人,请根据对应的上下文回复用户问题"),
MessagesPlaceholder('history'),
("human", "{query}")
])
memory = ConversationSummaryBufferMemory(
max_token_limit=300,
return_messages=True,
input_key="query",
llm=ChatOpenAI(model='gpt-3.5-turbo-16k')
)
# 2. 创建大语言模型
llm = ChatOpenAI(model='gpt-3.5-turbo-16k')
# 3. 构建链应用
chain = RunnablePassthrough.assign(
history=RunnableLambda(memory.load_memory_variables) | itemgetter("history")
) | prompt | llm | StrOutputParser()
# 4.si循环构建对话命令行
while True:
query = input("Human: ")
if query == "q":
exit(0)
chain_input = {"query": query}
response = chain.stream(chain_input)
print("AI: ", flush=True, end="")
output = ''
for chunk in response:
output += chunk
print(chunk, flush=True, end="")
memory.save_context(chain_input, {"output": output})
print("")
使用注意事项
ConversationSummaryBufferMemory 会将汇总摘要的部分默认设置为 system 角色,创建系统角色信息,而其他消息则正常显示,传递的消息列表就变成:[system, system, human, ai, human, ai, human ]。
但是部分聊天模型是不支持传递多个角色为 System 的消息,并且在 langchain_community 中集成的模型并没有对多个 System 进行集中合并封装(Chat Model 未更新同步),如果直接使用可能会出现报错。
而且绝大部分聊天模型在传递历史信息时,传递的信息必须是信息组,也就是 1 条 Human 消息 + 1 条 AI 消息这种格式,例如百度的文心大模型,链接:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/clntwmy7t。
所有在使用ConversationSummaryBufferMemory这种类型的记忆组件时,需要检查对应的模型传递的messages的规则,以及LangChain是否对特定的模型封装进行更新
除此之外,在某些极端的场合下,列如第一条提问回复内容比较短,第二条提问内容比较长,ConversationSummaryBufferMemory执行两次Token长度计算,如果不异步执行任务,对话速度会变得非常慢。
记忆组件的持久化与第三方集成
记忆组件的持久化
在 LangChain 中记忆组件本身没有持久化功能,但是可以通过 chat_memory 来将对话信息历史持久化,通过额外的数据库来存储汇总信息、摘要等技巧,从而实现记忆的持久化。
以 conversationSummaryBufferMemory 为例,如果想要持久化,可以使用带有持久化功能的 chat_memory,并且利用外部的文件或者数据库管理 moving_summary_buffer 字段数据,从而实现整个记忆组件的持久化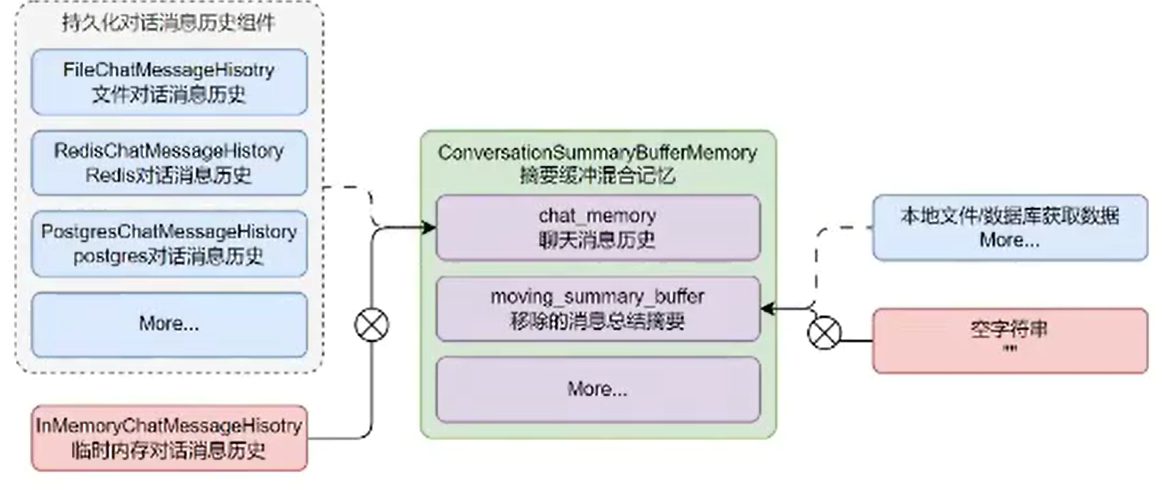
在 LangChain 中,集成接入的第三方对话消息历史有近 50+ 个,涵盖了:Postgres、Redis、Kafka、MongoDB、SQLite 等,并且 ChatMessageHistory 可以完美接入到 Runnable 可运行协议的链条。
LangChain 第三方记忆组件官网:https://python.langchain.com/v0.2/docs/integrations/memory/
实现记忆功能的聊天机器人API
在 Flask 中,每一个请求结束后,所执行的线程 / 协程会被释放,所以没法像命令行聊天机器人一样,将记忆内容存储到临时内存中,所以需要一种中介来存储相应的对话历史,这个中介可以是文件,也可以是数据库,甚至是另外的程序。
为了降低学习难度,我们先将基础的聊天机器人通过本地文件的方式来存储最近 3 轮对话信息,实现 3 轮内记忆,下一阶段掌握 RAG、工具回调后,再将聊天机器人的数据统一使用 Postgres 进行管理(涵盖配置、聊天历史、对话信息等)。
更新后的聊天机器人的运行流程图如下: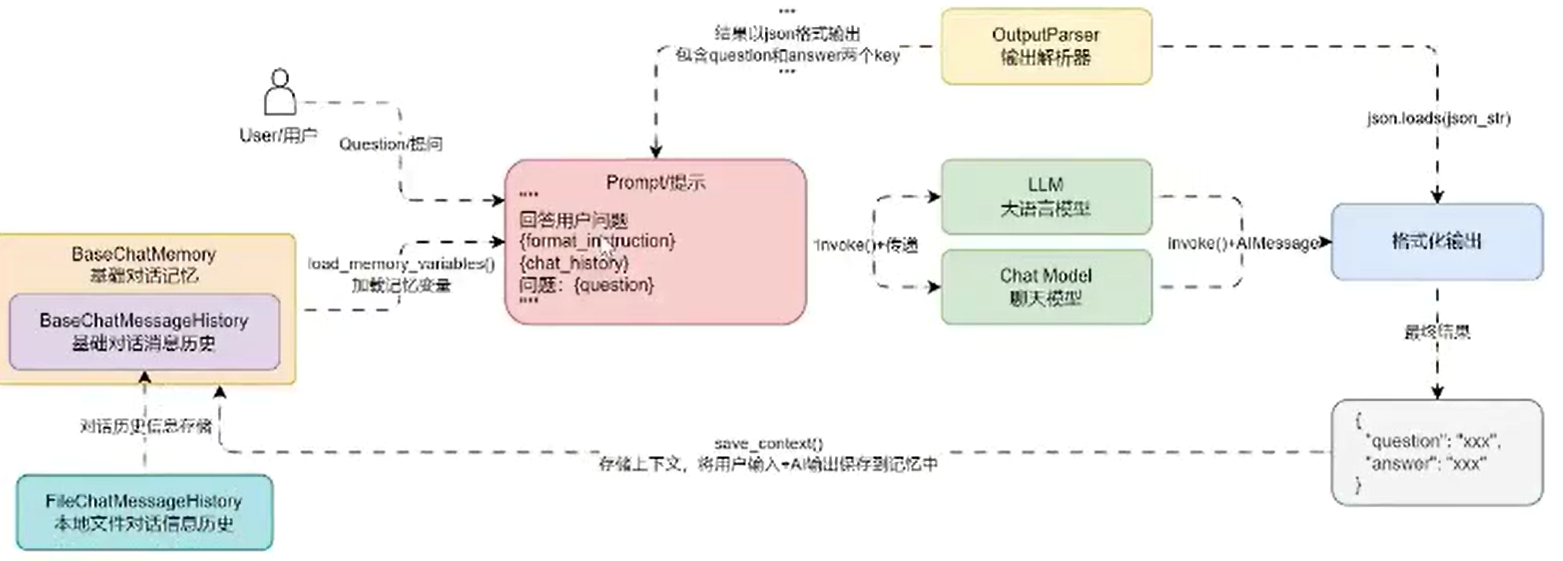

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)