Kimi K2.5 深度分析:1万亿参数多模态智能体的技术突破
Kimi K2.5深度解析:万亿参数多模态模型的突破与局限 摘要:Moonshot AI发布的Kimi K2.5模型在技术上实现了多项突破,包括256K上下文窗口、384个专家模块的MoE架构及原生多模态支持。该模型在数学视觉理解(MathVista 90.1%)和视频分析等任务中表现突出,Agent Swarm模式使复杂任务处理效率提升29.4%。但实际工程应用中,其代码生成能力(SWE-Ben
Kimi K2.5 深度分析:1万亿参数多模态智能体的技术突破
总结:国内的模型数值评比没输过,软件编码开发工程没赢过。整个Kimi K2.5 目前来看最大的改进是万亿参数的多模态能力提示,官方说适合处理超长文档和图文混排的复杂任务,这个有待真实测评。相对20250905 Kimi2来说上下文由128K 扩展到了 256K。当前开发任务来说,多任务工具的配合处理可能比模型的更新能带来更大的收益。
2026年1月26日,Moonshot AI(月之暗面)发布了 Kimi K2.5 模型,这是继 Kimi K2 之后的又一重磅开源作品。作为基于 1 万亿参数 MoE 架构的原生多模态智能体模型,Kimi K2.5 不仅在多项基准测试中刷新开源模型记录,更在部分指标上超越了 GPT-5.2、Claude 4.5 Opus 等顶级闭源模型。
本文将从技术架构、核心能力、基准表现和应用前景四个维度,深入分析 Kimi K2.5 的技术特点和市场价值。
二、技术架构:超大规模 MoE 架构的极致优化
2.1 模型参数配置
Kimi K2.5 延续了 Kimi K2 的 MoE(混合专家)架构设计,通过稀疏激活机制实现了高效的参数利用:
| 参数项 | Kimi K2.5 | Kimi K2 |
|---|---|---|
| 总参数量 | 1T | 1T |
| 激活参数 | 32B | 32B |
| 专家数量 | 384 | 256 |
| 每层选择专家 | 8 | 8 |
| 上下文长度 | 256K tokens | 128K tokens |
| 视觉编码器 | MoonViT (400M) | 无 |
| 词表大小 | 160K | 160K |
| 注意力机制 | MLA | MLA |
| 层数 | 61 | 61 |
(数据来源:Moonshot AI Hugging Face 模型卡,2026-01-27)
从参数配置可以看出,K2.5 在保持 K2 核心架构的同时,主要升级体现在:
- 上下文长度翻倍:从 128K 扩展至 256K,可处理约 20 万字的长文档
- 专家数量提升:从 256 个专家增至 384 个,提升了模型的专业化能力
- 原生多模态能力:新增 4 亿参数的 MoonViT 视觉编码器
2.2 MoE 架构的工程优化
Kimi K2.5 采用了以下关键技术优化:
(1)MLA(Multi-head Latent Attention)注意力机制
- 隐藏维度:7168
- 注意力头数:64
- 相比传统 MHA 显著降低了 KV 缓存开销
(2)原生 INT4 量化
- Group size: 32
- 针对 Hopper 架构优化
- 大幅降低推理时的显存需求
(3)训练数据规模
- 在 Kimi-K2-Base 基础上持续预训练
- 使用约 15 万亿混合视觉和文本 token
- 训练过程零不稳定问题(据官方报告)
三、核心能力:从单一智能体到智能体群
3.1 双模式推理系统
Kimi K2.5 创新性地支持两种推理模式:
| 模式 | 特点 | 推荐参数 | 适用场景 |
|---|---|---|---|
| Thinking 模式 | 显示推理过程,输出 reasoning_content | temperature=1.0, top_p=0.95 | 复杂推理、数学问题、代码生成 |
| Instant 模式 | 直接输出结果,无思考痕迹 | temperature=0.6 | 日常对话、快速响应场景 |
(数据来源:NVIDIA NIM Model Card,2026-01-26)
这种设计让用户可以根据任务复杂度灵活选择:需要深度思考时开启 Thinking 模式,追求响应速度时切换到 Instant 模式。
3.2 原生多模态理解
Kimi K2.5 实现了真正的视觉-语言融合:
视觉理解能力:
- 支持图像、视频、PDF 输入
- 视频输入通过时空池化压缩视觉特征
- 视觉 token 和文本 token 统一处理
典型应用场景:
- UI 设计转代码:根据设计稿自动生成前端代码
- 视频内容分析:理解视频情节、提取关键信息
- 文档理解:处理包含图表、图片的复杂 PDF
3.3 Agent Swarm(智能体群)
这是 Kimi K2.5 最具前瞻性的功能设计:
传统单智能体模式:
用户请求 → AI Agent → 工具调用 → 结果返回
Agent Swarm 模式:
用户请求 → 主 Agent 分解任务
├── 子 Agent 1(代码专家)
├── 子 Agent 2(搜索专家)
├── 子 Agent 3(数据分析专家)
└── 结果汇总 → 返回给用户
这种架构让 Kimi K2.5 能够:
- 将复杂任务分解为并行子任务
- 动态实例化领域专家智能体
- 实现自协调的群体执行
在 BrowseComp(Agent Swarm 模式)测试中,Kimi K2.5 达到 78.4%,远超其他模型。
四、基准测试:全面对标顶级闭源模型
4.1 推理与知识能力
| 基准测试 | Kimi K2.5 (Thinking) | GPT-5.2 (xhigh) | Claude 4.5 Opus | DeepSeek V3.2 |
|---|---|---|---|---|
| AIME 2025 | 96.1% | 100% | 92.8% | 93.1% |
| HMMT 2025 | 95.4% | 99.4% | 92.9% | 92.5% |
| IMO-AnswerBench | 81.8% | 86.3% | 78.5% | 78.3% |
| GPQA-Diamond | 87.6% | 92.4% | 87.0% | 82.4% |
| MMLU-Pro | 87.1% | 86.7% | 89.3% | 85.0% |
(数据来源:Hugging Face Kimi-K2.5 Model Card,2026-01-27)
关键发现:
- 在数学竞赛类测试(AIME、HMMT)中,Kimi K2.5 表现仅次于 GPT-5.2
- 在需要深度推理的 IMO-AnswerBench 上,超越 Claude 4.5 Opus
- 在 MMLU-Pro 通用知识测试中,与顶级闭源模型差距在 3% 以内
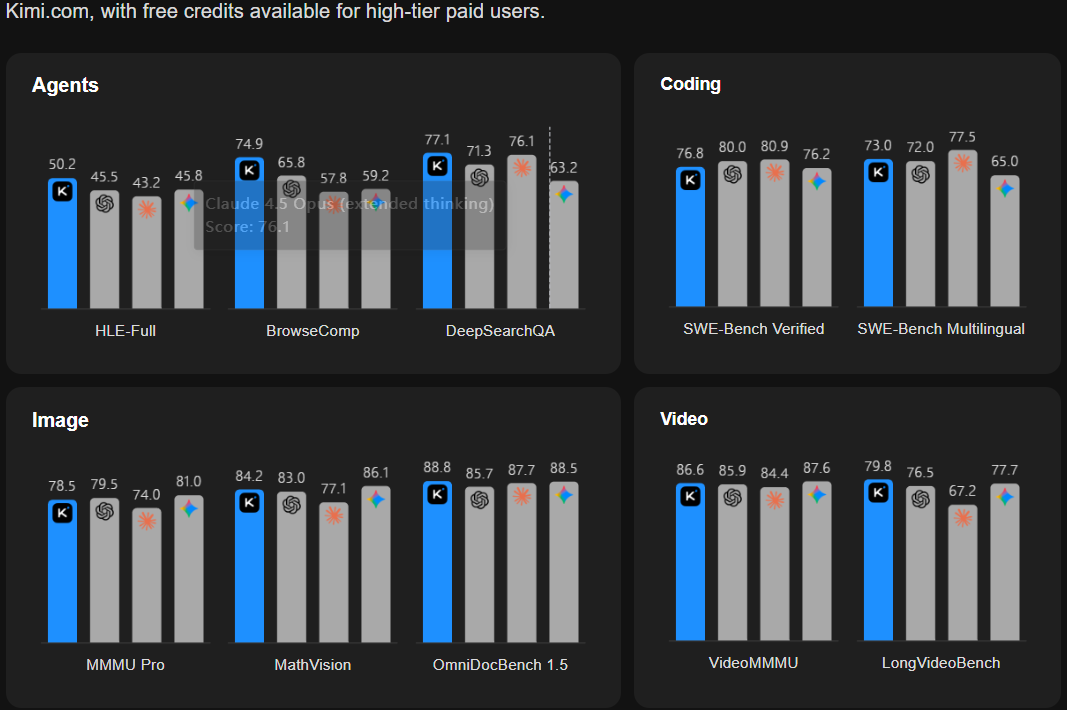
4.2 视觉与视频理解
| 基准测试 | Kimi K2.5 | GPT-5.2 | Claude 4.5 | Qwen3-VL |
|---|---|---|---|---|
| MMMU-Pro | 78.5% | 79.5%* | 74.0% | 69.3% |
| MathVision | 84.2% | 83.0% | 77.1%* | 74.6% |
| MathVista | 90.1% | 82.8%* | 80.2%* | 85.8% |
| VideoMMMU | 86.6% | 85.9% | 84.4%* | 80.0% |
| VideoMME | 87.4% | 86.0%* | - | 79.0% |
(带 * 号为第三方复测结果)
突出表现:
- 数学视觉理解(MathVision、MathVista)领先所有对比模型
- 视频理解能力达到 SOTA 水平
- OCRBench 达到 92.3%,超越 GPT-5.2(80.7%)
4.3 代码生成能力

| 基准测试 | Kimi K2.5 | GPT-5.2 | Claude 4.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.0% | 80.9% | 73.1% |
| LiveCodeBench v6 | 85.0% | - | 82.2%* | 83.3% |
| Terminal Bench 2.0 | 50.8% | 54.0% | 59.3% | 46.4% |
| PaperBench | 63.5% | 63.7%* | 72.9% | 47.1% |
分析:
- 在实时编程竞赛(LiveCodeBench)中表现最佳
- SWE-Bench 已接近顶级水平
- PaperBench 指标仍有提升空间
4.4 长上下文与 Agentic 能力
| 基准测试 | Kimi K2.5 | GPT-5.2 | Claude 4.5 | Gemini 3 Pro |
|---|---|---|---|---|
| LongBench v2 | 61.0% | 54.5%* | 64.4%* | 68.2%* |
| AA-LCR | 70.0% | 72.3%* | 71.3%* | 65.3%* |
| BrowseComp (普通) | 60.6% | 65.8% | 37.0% | 37.8% |
| BrowseComp (Swarm) | 78.4% | - | - | - |
| DeepSearchQA | 77.1% | 71.3%* | 76.1%* | 63.2%* |
重要发现:
- 在 Agent Swarm 模式下,BrowseComp 性能提升 29.4%(从 60.6% 到 78.4%)
- 长文档理解(LongBench v2)领先 GPT-5.2 6.5 个百分点
- 深度搜索问答(DeepSearchQA)超越所有对比模型
五、应用前景与市场定位
5.1 适用场景分析
高适用性场景:
-
企业级知识库问答
- 256K 上下文支持长文档处理
- 多模态能力可处理图文混排资料
- Agent Swarm 支持复杂查询分解
-
代码开发与自动化
- LiveCodeBench 85% 的优异成绩
- UI 转代码功能提升开发效率
- 支持代码审查和重构建议
-
多语言内容处理
- 16 万词表支持多语言混合
- 中英双语表现均衡
- 适合全球化产品应用
-
视觉内容分析
- 图表理解与生成的结合
- 视频内容自动摘要
- 视觉信息提取与结构化
5.2 与竞品的对比定位
| 维度 | Kimi K2.5 | GPT-5.2 | Claude 4.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| 开源程度 | 完全开源 | 闭源 | 闭源 | 开源 |
| 推理成本 | 中等 | 高 | 高 | 低 |
| 多模态能力 | 原生支持 | 原生支持 | 原生支持 | 文本为主 |
| 上下文长度 | 256K | 128K | 200K | 128K |
| Agent 能力 | Swarm 架构 | 基础 | 基础 | 基础 |
| 中文优化 | 优秀 | 良好 | 良好 | 优秀 |
5.3 部署建议
硬件配置(官方推荐):
- 支持推理引擎:vLLM、SGLang、KTransformers
- 推荐 GPU:NVIDIA H100、H200(Hopper 架构)
- 量化支持:原生 INT4 可大幅降低显存需求
- 最低 transformers 版本:4.57.1
成本评估:
- 相比 Llama 3.1 405B,部署成本约降低 75%
- INT4 量化后推理效率提升显著
- 32B 激活参数设计平衡了性能与成本
六、总结与展望
6.1 核心优势
- 技术架构领先:1T 参数 MoE + 256K 上下文 + 原生多模态
- 性能表现均衡:在推理、代码、视觉等多个维度达到顶级水平
- Agent 能力突破:Swarm 架构代表了智能体技术的新方向
- 开源生态友好:修改版 MIT 许可证支持商业应用
6.2 局限性分析
- 部分指标仍有差距:在 GPQA-Diamond、MMLU-Pro 等知识密集型任务上略逊于 GPT-5.2
- 长上下文优化空间:LongBench v2 指标有提升潜力
- 视频功能实验性:官方标注视频输入为实验性功能
6.3 未来展望
Kimi K2.5 的发布标志着国产开源大模型在技术上已能与全球顶级模型同台竞技。其 Agent Swarm 架构可能引领下一代 AI 应用的发展方向。
对于企业和开发者而言,Kimi K2.5 提供了一个性能强劲、成本可控、可私有化部署的优质选择。特别是在需要长上下文处理、多模态理解和复杂 Agent 工作流的场景中,Kimi K2.5 展现出独特的竞争优势。
随着后续优化和社区生态的发展,Kimi K2.5 有望在更多垂直领域发挥价值,推动大模型技术的普惠化进程。
参考资料
- Moonshot AI, “Kimi K2.5 Model Card”, Hugging Face, 2026-01-27
- Moonshot AI, “Kimi K2: Open Agentic Intelligence”, GitHub, 2025-07
- NVIDIA, “kimi-k2.5 Model Card”, NVIDIA NIM, 2026-01-26
- Moonshot AI Technical Team, “Kimi-K2 Performance Benchmarks and Model Comparison Analysis”, 2025-07-13
本文部分数据来源于 Moonshot AI 官方发布的模型卡和技术报告,基准测试数据截至 2026 年 1 月。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)