Cursor 一周写 300 万行代码做浏览器,但别急着为 AI Agent 欢呼
AI代码生成能力被高估:Cursor一周生成300万行浏览器代码引热议,但实验显示AI仍无法完全替代人类开发。虽然GPT-5.2在标准化任务上表现优异,但在核心业务逻辑、创新功能等场景仍存在幻觉累积、错误放大等致命缺陷。研究指出,AI代码质量更多依赖人为设计的约束机制(如分层架构、测试驱动),而非自主创造能力。专家建议将AI用于重复性任务、内部工具等低风险场景,但需保持人类对核心业务逻辑的掌控。当
Cursor 一周写 300 万行代码做浏览器,但别急着为 AI Agent 欢呼
AI Agent 连续开发产品的能力被高估了。目前为止还没有AI可以完全全自动化的完成开发。而且做出来的东西有没有安全问题、符不符合需求还是需要人来监督评判。目前AI可是会改需求来适配他的错误结果的。未来可能出现完全AI化这种情况,但是现在还不具备。
2026年1月15日,Cursor 公司 CEO Michael Truell 在 Twitter 上发布了一条引人注目的消息:使用 GPT-5.2 在 Cursor 中连续运行一周,生成了超过 300 万行代码,构建了一个能"基本运行"的浏览器。
这个数字令人震撼——一周 7 天,168 小时,平均每小时写 1.8 万行代码。按人类工程师的工作量计算,这相当于一个 10 人的团队连续工作 2-3 年 才能完成的工作量。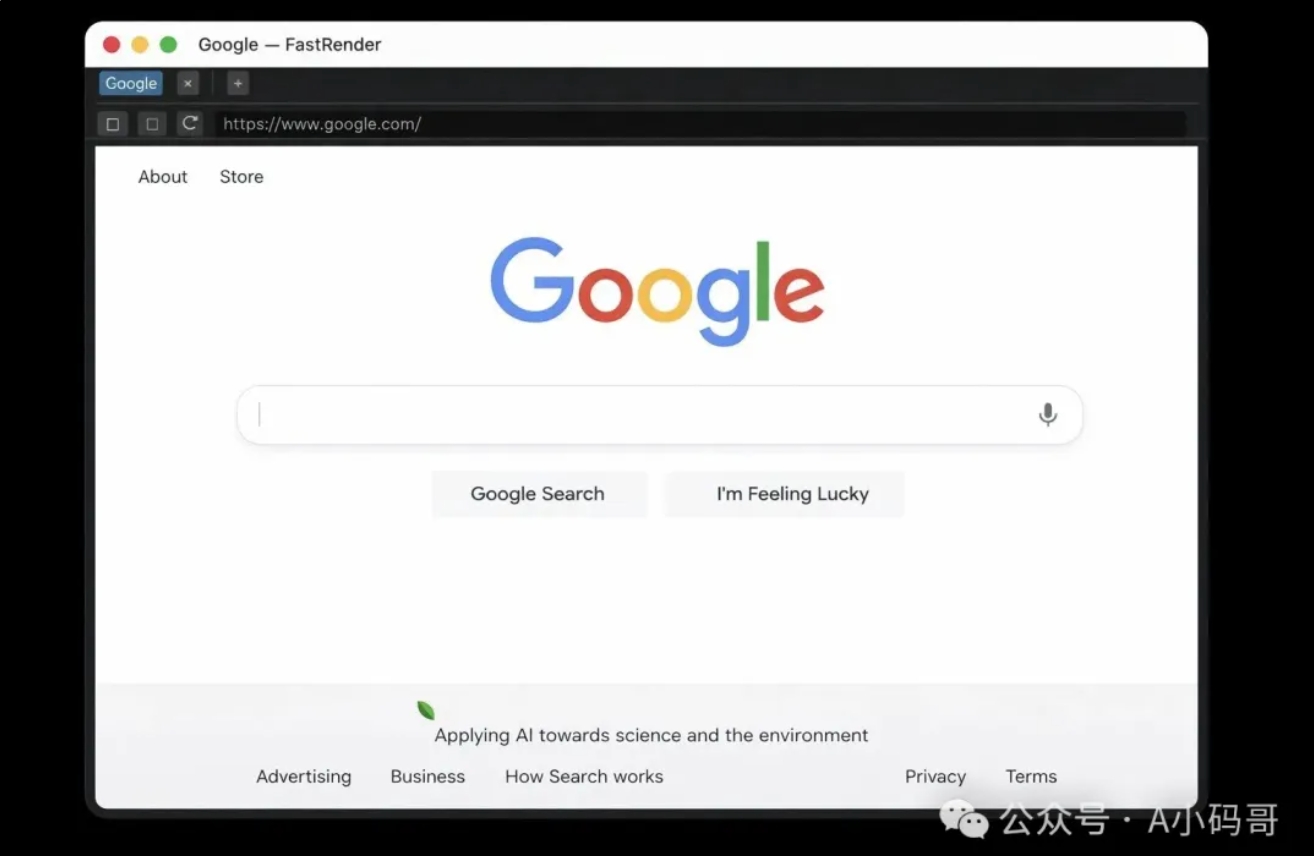
根据公开资料 Chromium 的代码量已经超过 3,500 万行(不含第三方依赖),开发了近20年。如果加上第三方库、测试代码、构建脚本等,整体可能接近 4,000 万行。参考对比:Linux 内核(2023 年)约 2,800 万行。相对于完整的浏览器还是有差距,但是这个量级已经十分惊人了。
但在这个数字背后,我们需要冷静看待 AI Agent 连续开发的真实能力边界。
一、实验的本质:复制还是创造?
Chromium 的 20 年积累被"消化"了
Michael 在推文中提到,这个浏览器包含了完整的渲染引擎:HTML 解析、CSS 级联、布局、文本塑形、绘制,甚至还有一个自定义的 JavaScript 虚拟机。这些功能使用 Rust 从零构建。
图:浏览器渲染引擎架构示意图
但关键问题是:这些实现是凭空创造的吗?
Chromium 作为开源项目,自 2006 年开源以来,已经积累了近 20 年 的工程实践、Bug 修复、性能优化和标准化实现。WebKit 更有更长的历史。这意味着:
- 渲染引擎的设计模式和架构决策已经被反复验证
- HTML/CSS 解析器的边界情况处理有大量现成案例
- 浏览器标准(W3C/WHATWG)的实现细节有完整文档
Michael 自己在推文中承认:
“It still has issues and is of course very far from WebKit/Chromium parity”
(它仍有问题,当然离 WebKit/Chromium 的成熟度还很远)
换句话说,AI Agent 不是"发明"了浏览器,而是**"复制"了已经被人类验证过的工程成果**。
这为什么不适合普通业务开发?
普通企业的业务场景与浏览器开发有本质区别:
| 维度 | 浏览器项目 | 普通业务开发 |
|---|---|---|
| 技术文档 | W3C/WHATWG 标准文档完善,代码库丰富 | 需求文档模糊,业务逻辑无标准 |
| 代码参考 | Chromium/WebKit 有 20 年开源历史可参考 | 可能是首次开发此类功能,无参考 |
| 边界情况 | 标准化明确,有完整测试套件 | 业务规则复杂,边界情况无法穷举 |
| 失败成本 | 渲染错误导致显示问题 | 数据错误可能导致资金损失、合规风险 |
在普通业务开发中,AI Agent 缺乏的正是那些"被验证过的工程积累"。
二、AI Agent 的致命伤:幻觉与不稳定性
幻觉问题:任务规模越大越明显
根据 OpenAI 的研究(《Why language models hallucinate》),大语言模型的幻觉源于概率性生成本质,而不仅仅是模型规模问题。即使像 GPT-5.2 这样的先进模型,仍然会产生幻觉。
在连续开发场景中,这个问题被放大:
-
单步错误累积
- 第一个 Agent 写错了一个 API 接口
- 第二个 Agent 基于这个错误接口写调用逻辑
- 第三个 Agent 为错误的接口写测试
- 错误在系统中扩散,越来越难追踪
-
上下文漂移
- 长时间运行后,Agent 可能忘记最初的业务目标
- 开始"优化"不重要的功能(Michael 在实验中观察到这种现象)
- 项目偏离原本的方向
-
协调失败
- 多个 Agent 同时工作时,可能出现"各自为战"
- 没人愿意修改核心的"硬骨头"模块
- 协作成本甚至超过人类团队
研究显示(Galileo AI, 2025),在多 Agent 系统中,幻觉主要来自协调失败,而非单个模型的能力问题。Agent 数量越多,潜在交互路径呈指数级增长,协调崩溃的机会也随之增加。
实际案例:错误会被 AI 放大
假设在一个电商系统中:
- Agent A 识别折扣逻辑时漏掉了"不适用于会员"的规则
- Agent B 基于这个逻辑写订单计算函数
- Agent C 为这个函数写单元测试(测试用例也错了)
- Agent D 写前端展示逻辑
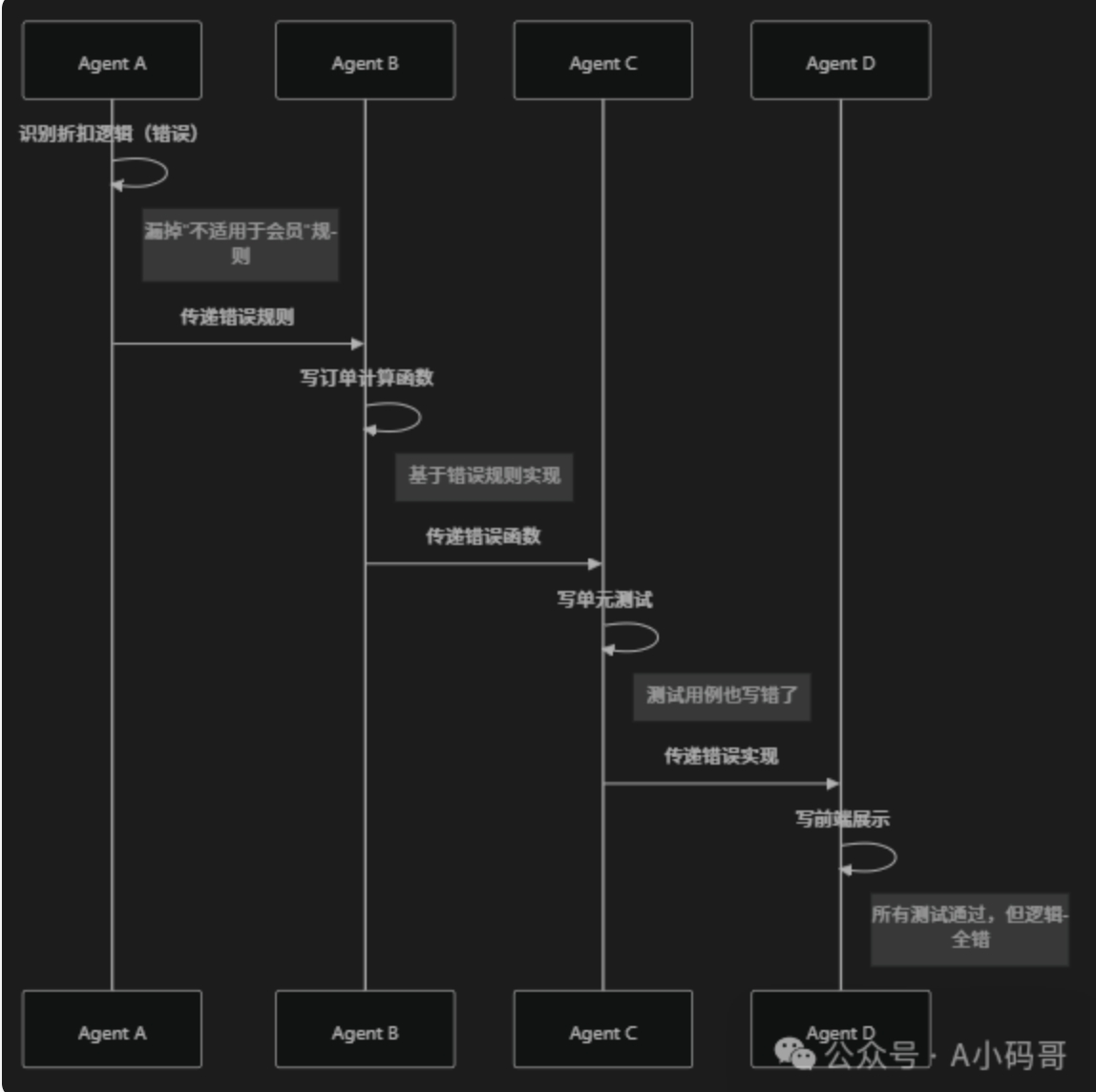
图:AI Agent 连续开发中的错误累积链
最终结果:整个系统的折扣逻辑从上到下都是错的,而且所有测试都通过。
这比人类开发的危险之处在于:人类团队在 code review 时可能发现问题,但 AI Agent 可能"一致地"犯同样的错误。
三、GPT-5.2 的真正优势,但没有解决根本问题
Cursor 的实验确实证明了 GPT-5.2 相比 Claude Opus 4.5 在长时间任务上的优势:
| 能力 | GPT-5.2 | Claude Opus 4.5 |
|---|---|---|
| 指令遵循 | 更稳定 | 中等 |
| 任务聚焦 | 更长时间保持专注 | 容易偏航 |
| 精确实现 | 更准确 | 有时过度抽象 |
但根据 Cursor 官方文章《Scaling long-running autonomous coding》,他们使用了分层架构来控制 Agent: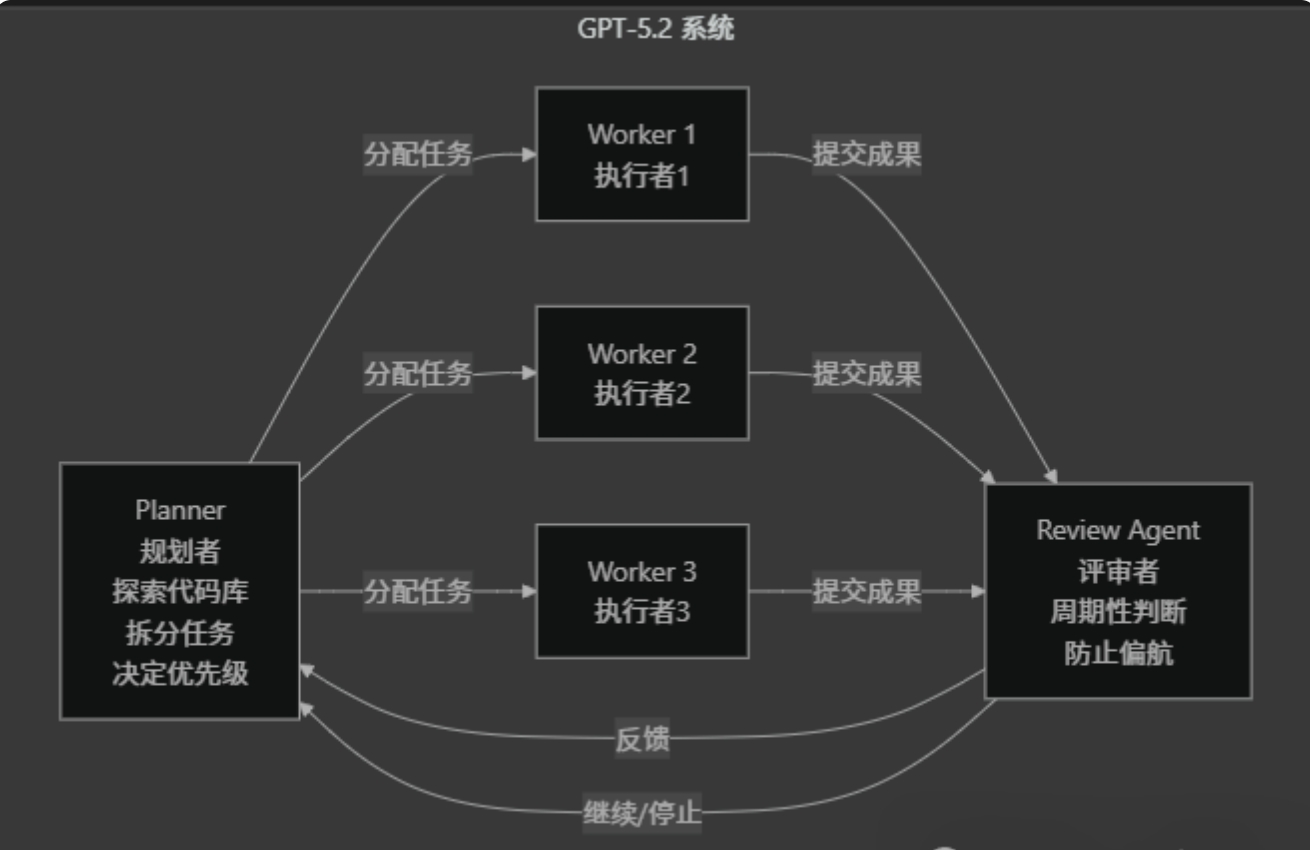
图:Cursor 使用的 AI Agent 分层协作架构
- Planner(规划者):探索代码库、拆分任务、决定优先级
- Worker(执行者):只拿清晰任务,专注完成
- Review Agent(评审者):周期性判断是否继续,防止偏航
这说明什么?
即使是最强的 GPT-5.2,仍然需要:
- 人为设计的架构约束(Planner/Worker 分工)
- 周期性的人类干预(Review Agent 决定是否继续)
- 完成信号约束(测试、lint、明确的验收标准)
这些约束的本质是:人类工程管理的思想被嵌入到了 AI 系统中。
四、AI Agent 什么时候真的有效?
基于 Cursor 的实验和研究分析,AI Agent 连续开发在以下场景可能有优势:
✅ 有效场景
-
重复性、标准化任务
- 大量 CRUD 操作
- 数据迁移脚本
- 自动化测试用例生成
-
有完整参考的项目
- 从成熟开源项目复制架构
- 有详细 API 文档的 SDK 封装
- 标准协议的实现(如 HTTP、WebSocket)
-
内部工具开发
- 不面向外部用户,容错率高
- 可以快速迭代,不追求完美
- 有明确的功能边界
❌ 高风险场景
-
核心业务逻辑
- 涉及资金计算、合规要求
- 复杂的审批流程、权限控制
- 需要理解隐式业务规则
-
高可用系统
- 需要处理极端边界情况
- 性能优化依赖经验
- 故障恢复机制复杂
-
创新性功能
- 没有现成参考实现
- 需要多轮需求澄清
- 设计决策影响系统演进
五、普通人该如何使用 Cursor 这套方法论?
虽然我对 AI Agent 连续开发持悲观态度,但 Cursor 提炼的 8 条实操建议确实有价值——前提是人类在掌控方向盘:
1. 先写计划,再写代码
不要直接说:"帮我实现用户登录"
改成:"先阅读代码库,找出认证相关的文件,
然后输出一个实现计划:每一步改哪些文件、为什么改、
验收标准是什么、风险点和回滚策略"
2. 明确完成信号
- 测试全绿
- Lint 全绿
- 指定命令的输出符合预期
没有完成信号,Agent 就会靠"主观判断"结束——这是幻觉的温床。
3. 不要把所有文件塞给它
给它目标和约束,让它自己用搜索工具找上下文。你只需要在两种情况下手动指定文件:
- 你知道准确的入口文件
- 要它模仿某个既有写法
4. 用 TDD(测试驱动开发)
- 先让 Agent 写失败的测试(禁止写实现)
- 你确认测试写得对
- 再让 Agent 写实现(禁止改测试)
- 循环直到全绿
5. 周期性重启对话
Cursor 的建议:对话太长会积累噪音。噪音越多,Agent 越容易变慢、变乱、变自信。
6. 并行探索,不要并行修改核心
可以:
- 同一个需求,让两个 Agent 分别给两套方案,然后你选
- 同一个 bug,让两个 Agent 分别定位,然后你对比
不可以:
- 让多个 Agent 同时修改核心模块同一片区域
- 这会把时间浪费在合并冲突和沟通上
7. 证据驱动调试
不要说:"帮我修这个 bug"
改成:"先提出 3 个可能原因,
然后在最小范围内加日志来验证,
只在拿到运行数据后再写修复"
8. 用 Rules 管长期偏好,用 Skills 管可复用流程
- Rules:项目固定命令、代码风格偏好、目录约定
- Skills:生成 PR 描述、反复跑测试、按模板写单测
六、结论:AI Agent 不会替代工程管理
Cursor 的浏览器实验证明了一件事:长时间运行的 Agent 在工程上是可行的。
但它也暴露了更根本的问题:
-
高质量来自约束,而非能力
- Agent 写得很快,但质量来自测试、lint、清晰的完成信号
- 没有这些约束,它会生成"自信但错误"的代码
-
长跑型 Agent 不会消灭工程管理
- 它会让工程管理更重要
- 瓶颈从"写代码"变成"定方向、设护栏、做 review"
-
人类的价值从"写每一行"转向"判断与验证"
- 你不需要写重复代码,但你需要写好的测试
- 你不需要调试所有问题,但你需要验证 Agent 的推理
- 你不需要实现所有功能,但你需要拆解需求、定义边界
七、给决策者的建议
如果你是技术负责人,看到 Michael 的实验后想引入 AI Agent 连续开发,建议这样评估:
| 评估维度 | 问题示例 |
|---|---|
| 项目类型 | 是否有成熟的参考实现?是否有标准化文档? |
| 风险容忍度 | 如果代码有 bug,成本是否可控? |
| 团队能力 | 是否有工程师能设计好的约束机制(测试、lint、验收标准)? |
| 基础设施 | 是否有自动化的测试、部署、监控流程? |
如果答案是"否"或"不确定",先别急着上 AI Agent。
八、最后的思考
Michael 的浏览器实验是 AI Agent 能力的一次重要演示,但它更像是一份"压力测试报告",而不是"产品成功案例"。
它告诉我们:
- ✅ AI 可以在有完整参考的情况下快速复制工程成果
- ✅ GPT-5.2 在长时间任务上比之前的模型更稳定
- ✅ 分层架构(Planner/Worker/Reviewer)是有效的组织方式
但它也提醒我们:
- ❌ 没有约束机制的 Agent 会产生系统性错误
- ❌ 幻觉问题在长时间、大规模任务中仍然显著
- ❌ 普通业务开发缺乏浏览器项目那样的"参考代码库"
AI Agent 是强大的工具,但它不是魔法。它需要人类用工程思维去驾驭——就像任何其他工具一样。
参考来源
- Michael Truell Twitter (@mntruell), January 15, 2026
- Cursor 官方博客:《Scaling long-running autonomous coding》
- 微信公众号《AI智见录》:《Cursor 连续一周写出百万行代码,提炼出 8 条可直接复用的实操》
- OpenAI Research:《Why language models hallucinate》
- Galileo AI:《How Multi-Agent Coordination Failures Unleash Dangerous Hallucinations》
- Research Aimultiple:《12 Reasons AI Agents Still Aren’t Ready in 2026》
- DevGenius:《AI Agents & Hallucinations: The hidden systematic risk》
刚写完看到 cursor 公布了过程,等我下一篇接着解析。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 21
21 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)