大模型笔记带实操记录
大模型训练的三个关键步骤:预训练(自监督学习,学习语言规律)、监督微调(SFT,将知识转化为人类可理解的回答)和优化阶段(RLHF/DPO,提升回答质量)。训练双模态模型时,需融合视觉与语言模型,通过图像嵌入转换和参数微调实现图文联合理解。代码展示了如何将视觉特征压缩后输入语言模型,保留原始空间关系。整个流程强调数据质量与高效参数更新的平衡。
文章目录
三个步骤
预训练
- 自监督学习
- 对预料质量要求不高,但量大
- 通过 「预测下一个词」(GPT)或 「填空」(BERT)等自监督任务学习 接龙 词语搭配 句子逻辑等语法语义。学习大量知识。
- 本质是学会接龙
SFT监督微调
- 从知识库转化为 按照人类的方式正确回答问题
-
数据格式:
{ "instruction": "解释量子纠缠", "input": "", "output": "量子纠缠是量子力学现象,指两个粒子状态相互关联。即使相隔遥远,测量一个粒子会瞬间影响另一个。爱因斯坦称其为'鬼魅般的超距作用',但实验已证实其存在。" } -
预料质量高,数量远少于预训练数据
-
学习率低,高会导致知识遗忘
-
参数高效微调(PEFT)
LoRA:低秩分解增量(仅更新0.1%参数)
Prefix Tuning:添加可学习前缀向量
Adapter:插入小型神经网络模块 -
LoRA – QLoRA (Q:量化)
Lora Rank大小和参数的关系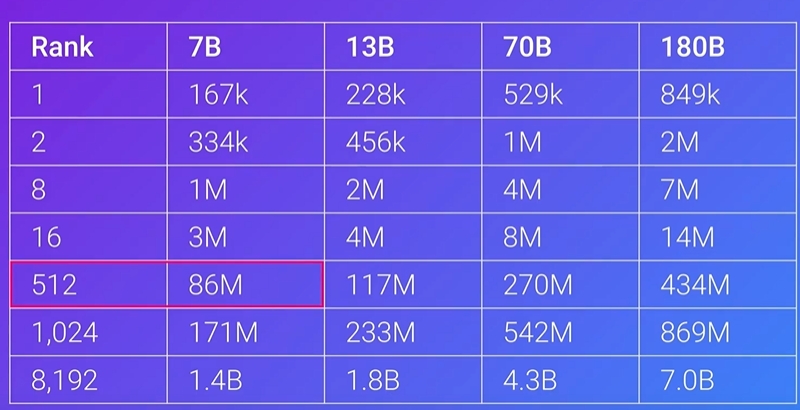
QLoRA是量化预训练后的权重,进行推理的时候再反量化成16bit(只处理当前计算的层),LoRA适配器仍为16bit,sft之后的结果应该是 4bit模型+16bit小配件的形式。
第三个阶段两个方案
- RLHF:人类偏好Reward Model —> 强化学习PPO —> 最终模型
- DPO: 直接训练DPO数据 —> 最终模型
- 两者的作用都是 让大模型从正确回答转向更好回答
训练实操
1.训练双模态大模型
参考连接:https://www.bilibili.com/video/BV1HTzEYbEv3/?spm_id_from=333.1387.upload.video_card.click&vd_source=5cd9b442f08018f3dc856d0a91e9cab0
CLIP VS 文本模型+视觉模型
前者:像一个"图文匹配评分器",告诉你描述A比描述B更适合这张图片。独立的图像编码器和文本编码器,看是否对齐
后者:像一个"视觉翻译器",看到图片后能用语言描述你所见。图片特征映射到语言模型的输入,图片转token 经过几层MLP输入到语言模型中。
代码注释写得很清楚了
a.模型
这个项目借鉴了OmniVision-968M的项目,地址在:https://nexa.ai/blogs/omni-vision
其中用到的就是文本模型+视觉模型的方式,Qwen2.5-0. 5 B-Instruct 函数作为基本模型来处理文本输入,SigLIP-400 M 以 384 分辨率和 14×14 补丁大小运行,以生成图像嵌入;中间通过一两层MLP来进行空间转换;在转换中原文提到重塑机制,项目的模型是196patch,只压缩了四倍,也就是(b, 196, d) --> (b, 49, d*4);而原项目压缩的方式是逐行压缩,也就是会导致图片的patch出现上一行尾巴和下一行首相连接作为一个新的patch的情况,所以我做了改动,压缩之后的patch仍旧是原来2*2相邻接的,具体可以看下面的代码,讲得很清楚。附对比。

使用的数据是:
图片数据:
https://hf-mirror.com/datasets/liuhaotian/LLaVA-CC3M-Pretrain-595K
中文文本数据:
https://hf-mirror.com/datasets/LinkSoul/Chinese-LLaVA-Vision-Instructions
代码如下:
from transformers import AutoProcessor, PretrainedConfig, AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModel, PreTrainedModel
from torch.utils.data import Dataset
from typing import List, Dict, Any
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers.modeling_outputs import CausalLMOutputWithPast
from PIL import Image
import os
import json
from torch.utils.data import Dataset
from transformers import Trainer, TrainingArguments
class VLMConfig(PretrainedConfig):
# 需要指定模型参数名,要不然在AutoModelForCausalLM.from_pretrained()时可能会加载默认的模型,而不是自己定义的模型
model_type = "vlm_model"
def __init__(self, llm_model_path = '/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/model/Qwen2.5-0.5B-Instruct',
vision_model_path = '/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/model/siglip-base-patch16-224',
# 冻结参数
freeze_llm_model = True,
# 图片token数量
image_pad_num = 49,
**kwargs):
self.vision_model_path = vision_model_path
self.llm_model_path = llm_model_path
self.freeze_llm_model = freeze_llm_model
self.image_pad_num = image_pad_num
super().__init__(**kwargs)
class VLM(PreTrainedModel):
# 需要定义VLM的config_class
config_class = VLMConfig
def __init__(self, config):
super().__init__(config)
self.config = config
self.vision_model = AutoModel.from_pretrained(self.config.vision_model_path)
self.processor = AutoProcessor.from_pretrained(self.config.vision_model_path)
# AutoModelForCausalLM加载模型自到LM head;(batch_size,seq_len,hidden_size) - > (batch_size, seq_len, vocab_size) vocab_size = hidden_size @ embedding的转置(H, V)
self.llm_model = AutoModelForCausalLM.from_pretrained(self.config.llm_model_path)
self.tokenizer = AutoTokenizer.from_pretrained(self.config.llm_model_path)
self.linear1 = nn.Linear(self.vision_model.config.vision_config.hidden_size*4, self.llm_model.config.hidden_size)
self.linear2 = nn.Linear(self.llm_model.config.hidden_size, self.llm_model.config.hidden_size)
# 冻结参数
if self.config.freeze_llm_model:
for param in self.llm_model.parameters():
param.requires_grad = False
for param in self.vision_model.parameters():
param.requires_grad = False
def forward(self, input_ids, labels, pixel_values, attention_mask=None):
# 将输入经过embedding
text_embeds = self.llm_model.get_input_embeddings()(input_ids)
# 获取图片输入的特征
# last_hidden_state会将图片原输入(batch_size,channel,height,width)
# 转换为(batch_size,seq_len(N_patches),hidden_size)
image_embeds = self.vision_model.vision_model(pixel_values).last_hidden_state
b, s, d = image_embeds.shape
# 压缩图片tokens, (b, 196, d) --> (b, 49, d*4)
#image_embeds = image_embeds.view(b, -1, d*4)
# 改动切割方式,让其真正的左右相邻2*2
if s == 197:
image_embeds = image_embeds[:, 1:, :] # (B, 196, D)
s = 196
'''
拿6*6举例:
# 00 01 02 03 04 05
# 06 07 08 09 10 11
# 12 13 14 15 16 17
# 18 19 20 21 22 23
# 24 25 26 27 28 29
# 30 31 32 33 34 35
要相邻的4个token,那么就是
# [ 0, 1, 6, 7],
# [ 2, 3, 8, 9],
# [ 4, 5, 10, 11],
# [12, 13, 18, 19],
# [14, 15, 20, 21],
# [16, 17, 22, 23],
# [24, 25, 30, 31],
# [26, 27, 32, 33],
# [28, 29, 34, 35]
'''
# 根据当前 patch 数量 s 恢复网格尺寸(例如 196 -> 14x14),避免硬编码
H = W = int(s ** 0.5)
assert H * W == s, f"Patch count {s} is not a perfect square"
image_grid = image_embeds.view(b, H, W, d)
# 取四个相邻位置:左上、右上、左下、右下(步长为2实现下采样)
tl = image_grid[:, 0::2, 0::2, :] # top-left rows [0,2,4,...] × cols [0,2,4,...]
tr = image_grid[:, 0::2, 1::2, :] # top-right rows [0,2,4,...] × cols [1,3,5,...]
bl = image_grid[:, 1::2, 0::2, :] # bottom-left rows [1,3,5,...] × cols [0,2,4,...]
br = image_grid[:, 1::2, 1::2, :] # bottom-right rows [1,3,5,...] × cols [1,3,5,...]
# 将四个相邻位置的特征拼接在一起
image_embeds = torch.cat([tl, tr, bl, br], dim=-1) # (b, H//2, W//2, 4d)
image_embeds = image_embeds.view(b, (H // 2) * (W // 2), 4 * d)
image_features = self.linear2(F.silu(self.linear1(image_embeds)))
text_embeds = text_embeds.to(image_features.dtype)
# 将图片特征和文本特征合并
inputs_embeds = self.merge_input_ids_with_image_features(image_features, text_embeds, input_ids )
# 将合并后的特征输入到LLM模型中
output = self.llm_model(inputs_embeds=inputs_embeds, attention_mask=attention_mask)
# 获取logits:语言模型在每个时间步对“下一个词”的打分 (batch_size, sequence_length, vocab_size) vocab_size对应的就是每个词的打分情况
logits = output.logits
loss = None
# CrossEntropyLoss的输入计算方式:(N, C) 和 (N,) N:batch_size × sequence_length C:vocab_size
# logits.view(-1, logits.size(-1)): (batch_size × sequence_length, vocab_size)
# labels.view(-1).to(logits.device): (batch_size × sequence_length)
if labels is not None:
loss_fct = nn.CrossEntropyLoss(ignore_index=self.tokenizer.pad_token_id)
loss = loss_fct(
logits.view(-1, logits.size(-1)), labels.view(-1).to(logits.device)
)
return CausalLMOutputWithPast(loss=loss, logits=logits)
# 将图片特征和文本特征合并
# image_features:图片embedding且经过Linear后的结果 (batch_size,seq_len,hidden_size)
# inputs_embeds:文本embedding后的结果 (batch_size,seq_len,hidden_size)
# input_ids:文本每个token对应在词表中的位置 (batch_size,seq_len)
def merge_input_ids_with_image_features(self, image_features, inputs_embeds, input_ids):
_, _, embed_dim = image_features.shape
# 获取<image>的token id {'input_ids': [50290], 'attention_mask': [1]}
image_token_id = self.tokenizer('<|image_pad|>')['input_ids'][0]
# torch.where 返回 (batch_size, seq_len)中等于image_token_id的元素的索引;返回的是一维向量例如tensor([0, 1, 1]),tensor([1, 0, 2])
batch_id, image_id = torch.where(input_ids == image_token_id)
# 高级索引自动配对位置下标;将图片编码后的特征替换到文本编码后的特征中
# 相当于 inputs_embeds[batch_indices[k], image_indices[k], :] = image_features.view(-1, embed_dim)[k]
inputs_embeds[batch_id, image_id] = image_features.view(-1, embed_dim)
return inputs_embeds
# 注册(进程内一次即可)
AutoConfig.register("vlm_model", VLMConfig) # 绑定字符串 model_type -> 你的配置类
AutoModelForCausalLM.register(VLMConfig, VLM) # 绑定配置类 -> 你的模型类
# 数据集
class MyDataset(Dataset):
def __init__(self, images_path, data_path, tokenizer, processor, config):
super().__init__()
self.data_path = data_path # data是文本数据
self.images_path = images_path
self.tokenizer = tokenizer
self.processor = processor
self.config = config
with open(self.data_path, 'r', encoding='utf-8') as f:
self.datas = json.load(f)
def __len__(self):
return len(self.datas)
# 定义数据集的获取方式
def __getitem__(self, index):
sample = self.datas[index]
# 根据数据格式来获取制作输入
try:
image_name = sample['image']
conversations = sample['conversations']
# 制作qa对
q_text = self.tokenizer.apply_chat_template([{"role":"system", "content":'You are a helpful assistant.'}, {"role":"user", "content":conversations[0]['value']}], \
tokenize=False, \
add_generation_prompt=True).replace('<image>', '<|image_pad|>'*self.config.image_pad_num)
a_text = conversations[1]['value'] + self.tokenizer.eos_token
q_input_ids = self.tokenizer(q_text)['input_ids']
a_input_ids = self.tokenizer(a_text)['input_ids']
input_ids = q_input_ids + a_input_ids
# 自监督训练,q设置为空,a才是预测答案。
labels = [self.tokenizer.pad_token_id] * len(q_input_ids) + a_input_ids
# 做 next-word预测对齐
input_ids = input_ids[:-1]
labels = labels[1:]
# 读取图片
image = Image.open(os.path.join(self.images_path, image_name)).convert("RGB")
pixel_values = self.processor(text=None, images=image)['pixel_values']
except:
# 有异常设置为空图片
default_image = Image.new('RGB', (224, 224), color='white')
pixel_values = self.processor(text=None, images=default_image)['pixel_values']
q_text = self.tokenizer.apply_chat_template([{"role":"system", "content":'You are a helpful assistant.'}, {"role":"user", "content":"图片内容是什么\n<image>"}], \
tokenize=False, \
add_generation_prompt=True).replace('<image>', '<|image_pad|>'*self.config.image_pad_num)
a_text = '图片内容为空' + self.tokenizer.eos_token
q_input_ids = self.tokenizer(q_text)['input_ids']
a_input_ids = self.tokenizer(a_text)['input_ids']
input_ids = q_input_ids + a_input_ids
labels = [tokenizer.pad_token_id] * len(q_input_ids) + a_input_ids
input_ids = input_ids[:-1]
labels = labels[1:]
return {
'input_ids': input_ids,
'labels': labels,
'pixel_values': pixel_values
}
# 对数据做对齐处理
class MyDataCollator:
def __init__(self, tokenizer):
self.tokenizer = tokenizer
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
max_len = max(len(feature['input_ids']) for feature in features)
input_ids = []
labels = []
pixel_values = []
for feature in features:
input_ids.append(feature['input_ids'] + [self.tokenizer.pad_token_id] * (max_len - len(feature['input_ids'])))
labels.append(feature['labels'] + [self.tokenizer.pad_token_id] * (max_len - len(feature['labels'])))
pixel_values.append(feature['pixel_values'])
# AutoProcessor常返回带 batch 维的 1,所以需要在 dim=0 上连接 (1,3,height,width) --> (batch_size, 3, height, width)
return {'input_ids': torch.tensor(input_ids, dtype=torch.long),
'labels': torch.tensor(labels, dtype=torch.long),
'pixel_values': torch.cat(pixel_values, dim=0)}
# 训练
if __name__ == '__main__':
config = VLMConfig()
model = AutoModelForCausalLM.from_config(config).cuda()
print(model)
print(f'模型参数量为:{sum(p.numel() for p in model.parameters() if p.requires_grad)}')
images_path = '/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/pre_data/LLaVA-CC3M-Pretrain-595K'
data_path = '/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/pre_data/LLaVA-CC3M-Pretrain-595K/chat-translated.json'
tokenizer = AutoTokenizer.from_pretrained(config.llm_model_path)
processor = AutoProcessor.from_pretrained(config.vision_model_path)
output_dir = 'save_/pretrain'
args = TrainingArguments(
output_dir=output_dir,
do_train=True,
per_device_train_batch_size=8,
learning_rate=1e-4,
num_train_epochs=1,
save_steps=500,
save_total_limit=2,
fp16=True,
gradient_accumulation_steps=8,
logging_steps=100,
report_to='tensorboard',
dataloader_pin_memory=True,
dataloader_num_workers=1
)
trainer = Trainer(
model=model,
args=args,
train_dataset=MyDataset(images_path, data_path, tokenizer, processor, config),
data_collator=MyDataCollator(tokenizer)
)
trainer.train(resume_from_checkpoint=False)
trainer.save_model('save_/pretrain')
trainer.save_state()
b.开始预训练
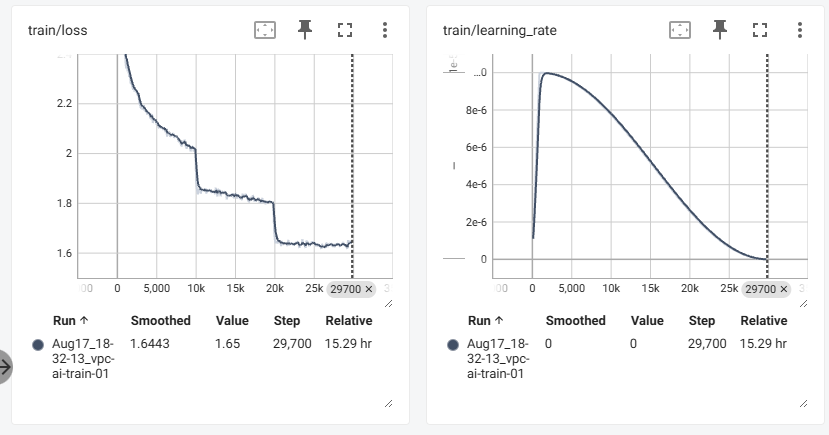
以下是训练所需的时间和占用的内存
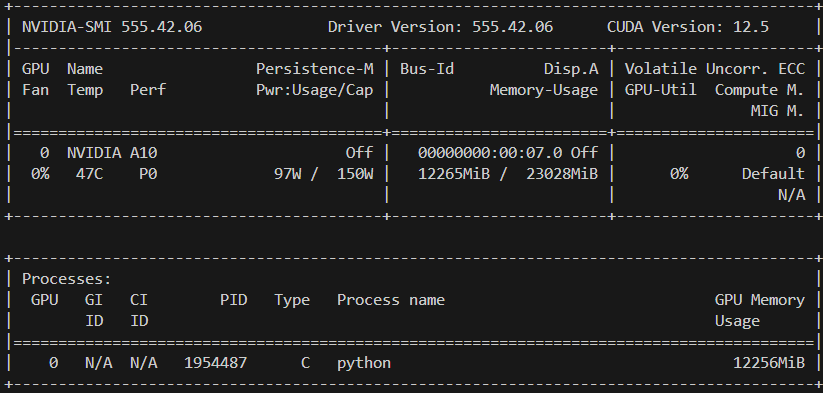
c.预训练结果
训练了一个epoch,学习率就降到0了,而预训练一般只需要一个epoch就足够了,loss降到3.3,测试的结果还算可以(以下是原版本,压缩token的时候没有进行2*2相邻接)。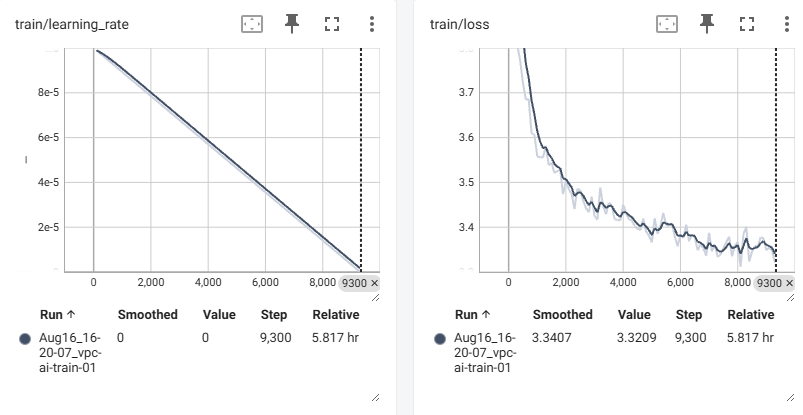
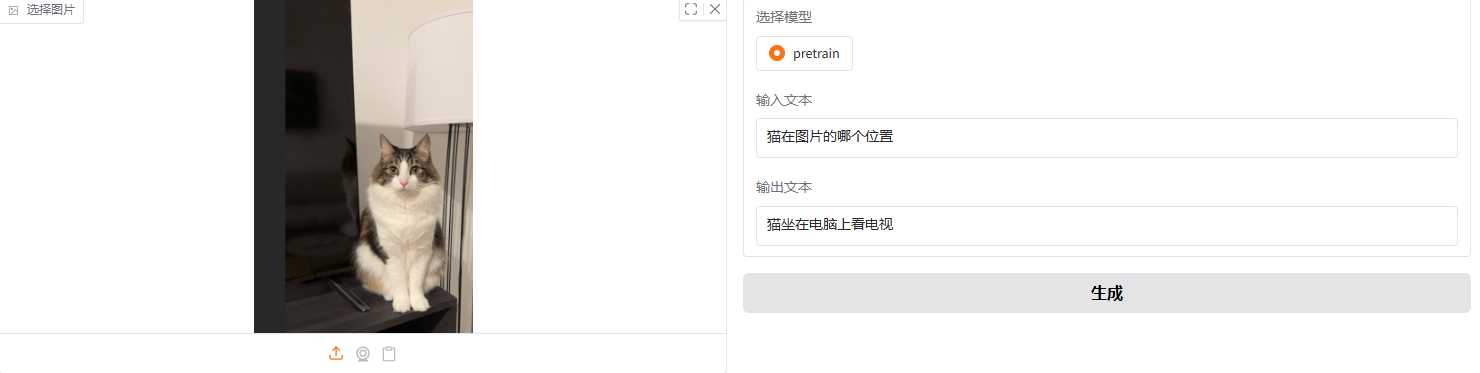
2*2相邻接: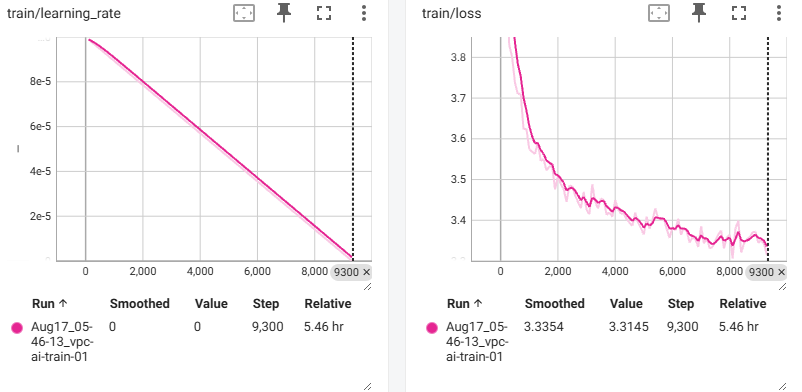
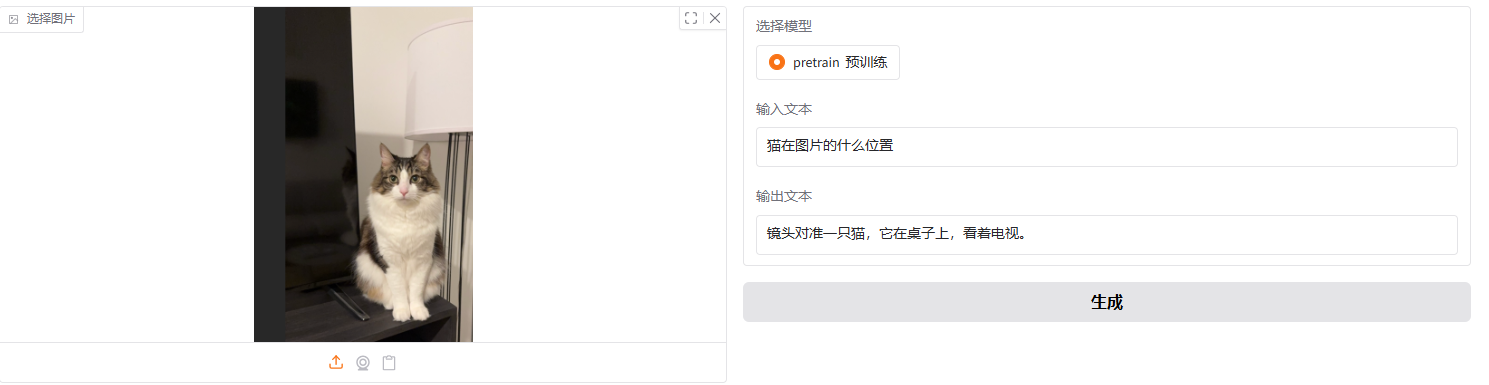
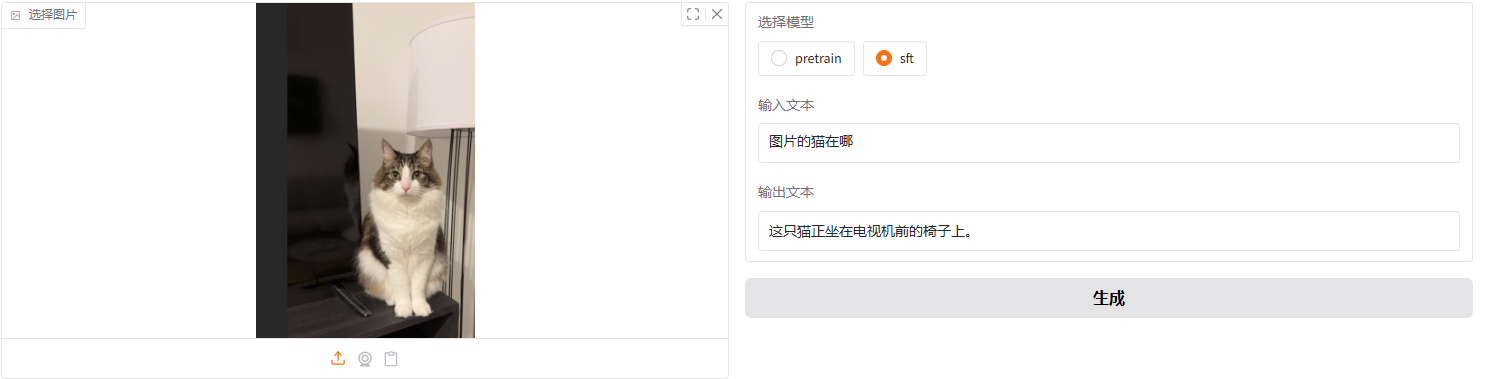
简单拿一张图片进行测试,感觉好像描述确实会变得准一些。具体后面再进行更多的测试。
d.sft监督微调
这里用的数据是 https://hf-mirror.com/datasets/jingyaogong/minimind-v_dataset/tree/main 下的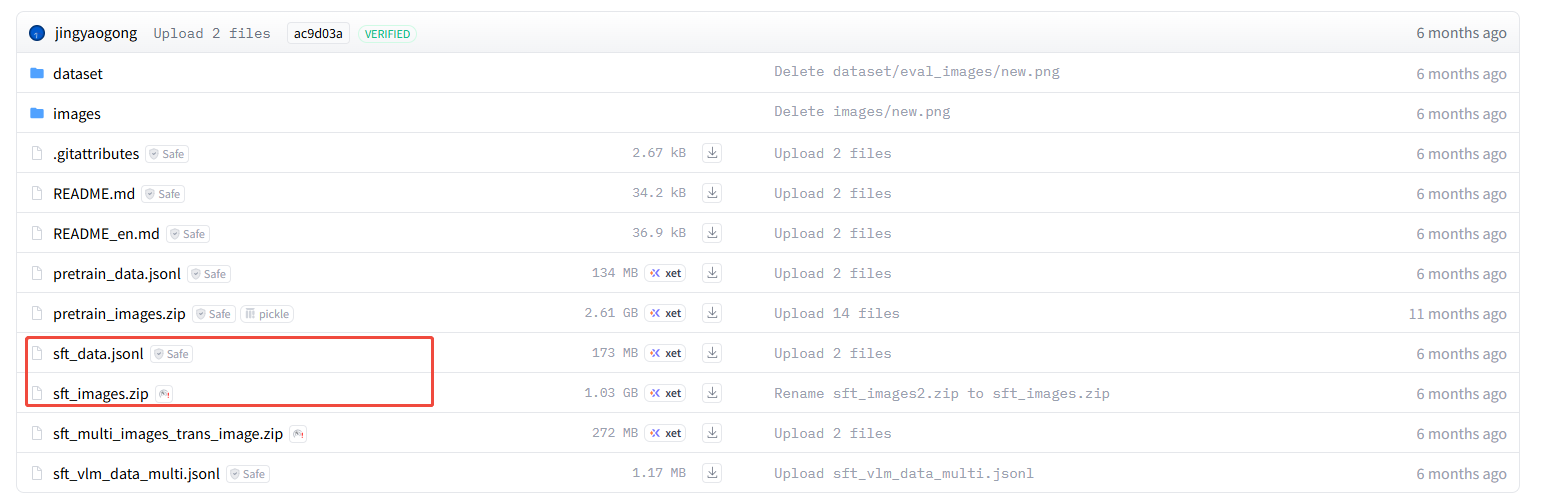
因为是sft,所以数据的处理方式会不一样,预训练:对整段文本做“下一个词预测”(next-token prediction)。所以只需要labels 等于 input_ids 的右移版。
而sft仍然是 next-token loss,但只对“assistant 回复部分”的 token 计算损失,也就是label是input_ids只填充了“assistant 回复部分”的右移版,这样才可以学会人类希望的回答方式,具体操作见代码注释。 为了学“人类式回答/对齐风格/多轮格式”,同时需要解冻llm_model的参数,让其参与训练才行;而多模态预训练阶段常“尽量不动 LLM 主干”,主要训练视觉侧与投影头来完成模态对齐。
训练参数也改小了学习率,设置了学习率调度以及warmup。
代码如下:
from train_ import VLM, VLMConfig
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoProcessor, TrainingArguments, Trainer
from torch.utils.data import Dataset
from PIL import Image
import os
import json
from torch.utils.data import Dataset
from transformers import Trainer, TrainingArguments
from typing import List, Dict, Any
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoProcessor, AutoConfig
from PIL import Image
def find_assistant_tokens(tokenizer, target):
result = []
start_index =0
end_index = 0
while start_index <= len(target) - 1:
# 如果当前位置不是 'assistant' 的“开头标记”
if target[start_index] != tokenizer('assistant')['input_ids'][0]:
# 两个指针一起往右移动一步,继续找开头
start_index += 1
end_index += 1
else:
# 命中 'assistant' 开头后,只移动 end_index,向右寻找 <|im_end|>
end_index += 1
# 可以print(tokenizer.chat_template查看assistant的结束标记)
if target[end_index] == tokenizer('<|im_end|>')['input_ids'][0]:
# 找到一段回复的结尾,把正文区间加入结果
result.append((start_index + 1, end_index + 1))
# 跳过这一段,继续从结尾后一个位置开始扫描下一段
start_index = end_index + 1
return result
class SFTDataset(Dataset):
def __init__(self, images_path, data_path, tokenizer, processor, config):
super().__init__()
self.data_path = data_path
self.images_path = images_path
self.tokenizer = tokenizer
self.processor = processor
self.config = config
self.datas = []
with open(self.data_path, 'r', encoding='utf-8') as f:
for line in f:
if line.strip():
self.datas.append(json.loads(line ))
def __len__(self):
return len(self.datas)
def __getitem__(self, index):
sample = self.datas[index]
try:
image_name = sample['image']
messages = [{"role":"system", "content":'You are a helpful assistant.'}]
conversations = sample['conversations']
for conversation in conversations:
if conversation['role'] == 'user':
messages.append({"role":"user", "content":conversation['content']})
else:
messages.append({"role":"assistant", "content":conversation['content']})
text = self.tokenizer.apply_chat_template(messages, tokenize=False).replace("<image>", 'য়'*self.config.image_pad_num)
input_ids = self.tokenizer(text)['input_ids']
indexs = find_assistant_tokens(self.tokenizer, input_ids)
# 将input_ids中的assistant的内容填充到labels中
labels = len(input_ids) * [self.tokenizer.pad_token_id]
for index in indexs:
labels[index[0]:index[1]] = input_ids[index[0]:index[1]]
input_ids = input_ids[:-1]
labels = labels[1:]
image = Image.open(os.path.join(self.images_path, image_name)).convert('RGB')
pixel_values = self.processor(text=None, images=image)['pixel_values']
except:
default_image = Image.new('RGB', (224, 224), color='white')
pixel_values = self.processor(text=None, images=default_image)['pixel_values']
q_text = self.tokenizer.apply_chat_template([{"role":"system", "content":'You are a helpful assistant.'}, {"role":"user", "content":"图片内容是什么\n<image>"}], \
tokenize=False, \
add_generation_prompt=True).replace('<image>', '<|image_pad|>'*self.config.image_pad_num)
a_text = '图片内容为空' + self.tokenizer.eos_token
q_input_ids = self.tokenizer(q_text)['input_ids']
a_input_ids = self.tokenizer(a_text)['input_ids']
input_ids = q_input_ids + a_input_ids
labels = [tokenizer.pad_token_id] * len(q_input_ids) + a_input_ids
input_ids = input_ids[:-1]
labels = labels[1:]
return {
'input_ids': input_ids,
'labels': labels,
'pixel_values': pixel_values
}
class MyDataCollator:
def __init__(self, tokenizer):
self.tokenizer = tokenizer
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
max_len = max(len(feature['input_ids']) for feature in features)
input_ids = []
labels = []
pixel_values = []
for feature in features:
input_ids.append(feature['input_ids'] + [self.tokenizer.pad_token_id] * (max_len - len(feature['input_ids'])))
labels.append(feature['labels'] + [self.tokenizer.pad_token_id] * (max_len - len(feature['labels'])))
pixel_values.append(feature['pixel_values'])
return {'input_ids': torch.tensor(input_ids, dtype=torch.long),
'labels': torch.tensor(labels, dtype=torch.long),
'pixel_values': torch.cat(pixel_values, dim=0)}
if __name__ == '__main__':
config = VLMConfig()
processor = AutoProcessor.from_pretrained("/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/model/siglip-base-patch16-224")
tokenizer = AutoTokenizer.from_pretrained("/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/model/Qwen2.5-0.5B-Instruct")
AutoConfig.register("vlm_model", VLMConfig)
AutoModelForCausalLM.register(VLMConfig, VLM)
model = AutoModelForCausalLM.from_pretrained('/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/save_/pretrain')
for name, param in model.named_parameters():
if 'linear' in name or 'vision_model':
param.requires_grad = False
if 'llm_model' in name:
param.requires_grad = True
print(f'模型参数量为:{sum(p.numel() for p in model.parameters())}')
print(f'模型可训练参数量为:{sum(p.numel() for p in model.parameters() if p.requires_grad)}')
images_path = '/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/sft_data/sft_images'
data_path = '/mnt/train1/yonbin/多模态大模型/llm_related-train_multimodal_from_scratch/sft_data/sft_data.jsonl'
output_dir = 'save_/sft'
args = TrainingArguments(
output_dir=output_dir,
do_train=True,
per_device_train_batch_size=2,
learning_rate=1e-5,
num_train_epochs=3,
save_steps=500,
save_total_limit=2,
fp16=True,
gradient_accumulation_steps=8,
logging_steps=100,
report_to='tensorboard',
dataloader_pin_memory=True,
dataloader_num_workers=1,
lr_scheduler_type="cosine", # 或 "linear"
warmup_ratio=0.03, # 或者 warmup_steps=1000
)
trainer = Trainer(
model=model,
args=args,
train_dataset=SFTDataset(images_path, data_path, tokenizer, processor, config),
data_collator=MyDataCollator(tokenizer)
)
# 第一次训练设置为False
trainer.train(resume_from_checkpoint=False)
trainer.save_model('save_/sft')
trainer.save_state()
e.开始sft训练

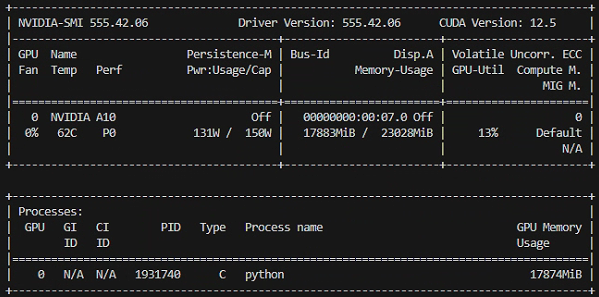
f.sft训练结果
后续再进行DPO训练

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 28
28 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)