从零开始构建Agent(二):Gemini-fullstack-langgraph-quickstart项目,一个很经典的Reflection模型
解析gemini-fullstack-langgraph-quickstart项目的后端架构并优化。
文章目录
一.项目介绍。
这个项目是谷歌使用 React 前端和 LangGraph 支持的后端代理的全栈应用程序。针对用户查询进行全面研究,动态生成搜索词,通过 Google Search API 搜索结果,并进行反思分析,迭代优化搜索,最终提供有引用支持的回答。后端用的架构是langgraph,需要对langgraph有一定的了解,可以看一下这篇文章。
这个项目与传统的问答模型不同,传统的问答模型只能针对你的问题进行回答,就算带联网功能也只是简单的收集了一下网页的信息综合回答。这个项目是一个会进行Reflection的Agent,会先根据你的问题生成多个类似的问题去进行搜索,接着判断收集到的信息是否满足回答你的问题,若不满足则会一直搜索,直到满足回答你的问题才进行输出。接下来我将会根据后端架构图逐个结点介绍这个项目。
二.项目架构。
项目架构如下: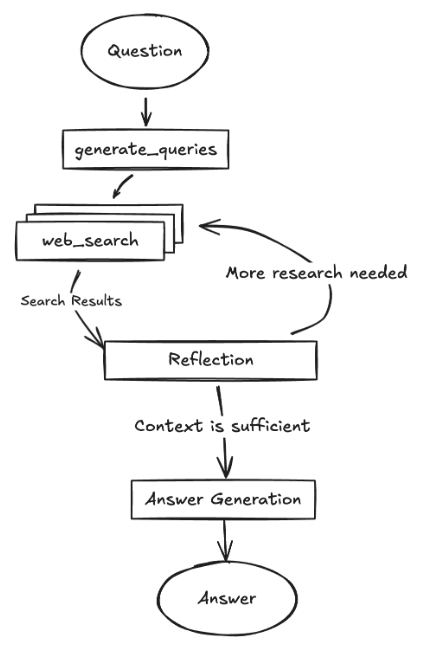
1.Generate_queries结点
这个结点的作用是 使用大模型基于用户的问题生成类似的搜索查询列表,其prompt汉化的意思如下:
query_writer_instructions = '''
你的目标是生成复杂且多样的网络搜索查询。这些查询是为一个先进的自动化网络研究工具设计的,该工具能够分析复杂的结果、跟踪链接并综合信息。
指令:
- 尽量优先使用单一知识库查询语句,只有在原始问题涉及多个不同方面或元素且一个查询语句无法充分涵盖时,才添加另一个查询语句。
- 每个查询语句应聚焦于原始问题的一个特定方面,精准定位知识库中的相关知识条目。
- 生成的查询语句数量不要超过 {number_queries} 个。
- 查询语句应具有多样性,如果主题宽泛,应从不同角度生成多个查询语句。
- 避免生成多个相似的查询语句,一个精心设计的查询语句就足够了。
- 查询应确保收集到最新的信息。当前日期是 {current_date}
格式:
- 将你的回复格式化为一个 JSON 对象,必须包含以下三个完全匹配的键:
- "rationale":简要解释这些查询语句的相关性原因,说明它们如何能够从知识库中检索到有用的信息
- "query":知识库查询语句列表
示例:
主题:我目前的工作是上班族,同时还要带孩子,这对学习课程会有影响吗?
```json
{{
"rationale": "为了帮助上班族家长了解在工作和带孩子的双重压力下学习课程的可行性和建议,这些查询语句聚焦于时间管理、家庭与工作的平衡、以及家长学员的学习经验等实际问题,能够精准检索到与用户处境高度相关的知识库内容。",
"query": [
"上班族如何平衡工作、带孩子与学习课程",
"家长学员在学习课程时常见的挑战与应对方法",
"时间管理技巧:上班族家长如何高效利用碎片时间学习",
"有孩子的学员在课程学习中的真实经验分享",
"家庭和工作压力对学习课程的影响及建议"
]
}}
历史对话上下文: {research_topic}
'''
函数代码部分:
def generate_query(state: OverallState, config: RunnableConfig) -> QueryGenerationState:
"""LangGraph node that generates a search queries based on the User's question.
Uses Gemini 2.0 Flash to create an optimized search query for web research based on
the User's question.
Args:
state: Current graph state containing the User's question
config: Configuration for the runnable, including LLM provider settings
Returns:
Dictionary with state update, including search_query key containing the generated query
"""
configurable = Configuration.from_runnable_config(config)
# check for custom initial search query count
if state.get("initial_search_query_count") is None:
state["initial_search_query_count"] = configurable.number_of_initial_queries
# init Gemini 2.0 Flash
llm = ChatGoogleGenerativeAI(
model=configurable.query_generator_model,
temperature=1.0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
structured_llm = llm.with_structured_output(SearchQueryList)
# Format the prompt
current_date = get_current_date()
formatted_prompt = query_writer_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
number_queries=state["initial_search_query_count"],
)
# Generate the search queries
result = structured_llm.invoke(formatted_prompt)
return {"query_list": result.query}
简单来说就是定义了一个大模型,将prompt需要的参数填入后进行回复生成,根据用户的输入返回生成的问题列表给下一节点。此处的字典是定义的state中的一种,因为langgraph是通过state来更新获取对应的数据。
2.Web_research结点
这个结点的作用是进行网络查询并返回查询的结果 prompt汉化的意思大概是:
web_searcher_instructions = """进行针对性的搜索,收集关于 "{research_topic}" 的最新、可信信息,并将其整合成一个可验证的文本作品。
指令:
查询应确保收集到最新的信息。当前日期是 {current_date}。
进行多次多样化的搜索,以收集全面的信息。
整理关键发现,同时仔细跟踪每条具体信息的来源。
输出内容应是基于搜索发现的精心撰写的总结或报告。
仅包含搜索结果中的信息,不要编造任何信息。
研究主题:
{research_topic}
"""
- research_topic这个state就是聊天记录,最新的输入也就是research_topic的最新一条,所以上面Generate_queries的prompt说的是历史上下文,这边Web_research的prompt就是最新的输入,在函数部分可以看到。这里其实可以用langgraph的性质来携带记录,而不是写在prompt里面。后面我会上传我改好的版本的文件。
代码部分:
def web_research(state: WebSearchState, config: RunnableConfig) -> OverallState:
"""LangGraph node that performs web research using the native Google Search API tool.
Executes a web search using the native Google Search API tool in combination with Gemini 2.0 Flash.
Args:
state: Current graph state containing the search query and research loop count
config: Configuration for the runnable, including search API settings
Returns:
Dictionary with state update, including sources_gathered, research_loop_count, and web_research_results
"""
# Configure
configurable = Configuration.from_runnable_config(config)
formatted_prompt = web_searcher_instructions.format(
current_date=get_current_date(),
research_topic=state["search_query"],
)
# Uses the google genai client as the langchain client doesn't return grounding metadata
response = genai_client.models.generate_content(
model=configurable.query_generator_model,
contents=formatted_prompt,
config={
"tools": [{"google_search": {}}],
"temperature": 0,
},
)
# resolve the urls to short urls for saving tokens and time
resolved_urls = resolve_urls(
response.candidates[0].grounding_metadata.grounding_chunks, state["id"]
)
# Gets the citations and adds them to the generated text
citations = get_citations(response, resolved_urls)
modified_text = insert_citation_markers(response.text, citations)
sources_gathered = [item for citation in citations for item in citation["segments"]]
return {
"sources_gathered": sources_gathered,
"search_query": [state["search_query"]],
"web_research_result": [modified_text],
}
简单来说这个函数就是定义大模型并且配备了谷歌搜索的tools,并不单单是简单的url搜索引擎,所以可以传递进整个prompt,让大模型根据要求和搜索内容去进行搜索,并且根据返回的格式进行处理获取到对应的信息。这里调用工具的方式其实跟mcp的用法是差不多的,给大模型配备tools,让大模型根据用户的问题去自由选择工具实现用户的问题。
- 注意:这里搜索的内容是:state[“search_query”],而上面generate_query返回的内容是”query_list“,这是因为中间还有一个步骤,就是continue_to_web_research,是一个实现异步搜索的函数。
3.Continue_to_web_research结点
这个函数的作用是实现异步查询,因为生成了query_list,也就是多个问题,如果直接让web_research遍历去查询的话会增加很多时间,其实也可以将web_research写成异步函数,但是在langgraph中,异步函数的效果不如分发任务多路执行的结构好,也就是并发多查询结构。
代码:用Send实现并发多路查询
def continue_to_web_research(state: QueryGenerationState):
"""LangGraph node that sends the search queries to the web research node.
This is used to spawn n number of web research nodes, one for each search query.
"""
return [
Send("web_research", {"search_query": search_query, "id": int(idx)})
for idx, search_query in enumerate(state["query_list"])
]
这里将state[“query_list”]进行提取了,也就解释了上面说的搜索的内容是:state[“search_query”]
4.Reflection结点
这个结点是判断web_research的结果是否满足回答用户的问题,如果不满足还会生成新的问题继续一轮web_research,是整个架构的核心所在。如果满足的话就会根据搜索到的内容总结成回复。
prompt汉化的意思是:
reflection_instructions = """你是一位分析关于 "{research_topic}" 的总结的专家研究助理。
指令:
- 识别知识空白或需要深入探索的领域,并生成后续查询。(一个或多个)
- 如果提供的总结足以回答用户的问题,则不要生成后续查询。
- 如果存在知识空白,生成一个后续查询,以帮助扩展你的理解。
- 重点在于未充分涵盖的技术细节、实施细节或新兴趋势。。
要求:
- 确保后续查询是自包含的,并包含知识库查询所需的必要背景信息。
输出格式:
- 将你的回复格式化为一个 JSON 对象,必须包含以下完全匹配的键:
- "is_sufficient":true 或 false
- "knowledge_gap":描述缺失的信息或需要澄清的内容
- "follow_up_queries":编写一个具体问题以解决这一空白
示例:
```json
{{
"is_sufficient": true, // 或 false
"knowledge_gap": "总结中缺少关于性能指标和基准测试的信息", // 如果 is_sufficient 为 true 则为空
"follow_up_queries": ["用于评估 [特定技术] 的典型性能基准和指标是什么?"] // 如果 is_sufficient 为 true 则为空列表
}}
请仔细反思总结,识别知识空白并生成后续查询。然后,按照此 JSON 格式生成你的输出:
总结:
{summaries}
"""
代码部分:
def reflection(state: OverallState, config: RunnableConfig) -> ReflectionState:
"""LangGraph node that identifies knowledge gaps and generates potential follow-up queries.
Analyzes the current summary to identify areas for further research and generates
potential follow-up queries. Uses structured output to extract
the follow-up query in JSON format.
Args:
state: Current graph state containing the running summary and research topic
config: Configuration for the runnable, including LLM provider settings
Returns:
Dictionary with state update, including search_query key containing the generated follow-up query
"""
configurable = Configuration.from_runnable_config(config)
# Increment the research loop count and get the reasoning model
state["research_loop_count"] = state.get("research_loop_count", 0) + 1
reasoning_model = state.get("reasoning_model") or configurable.reasoning_model
# Format the prompt
current_date = get_current_date()
formatted_prompt = reflection_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
summaries="\n\n---\n\n".join(state["web_research_result"]),
)
# init Reasoning Model
llm = ChatGoogleGenerativeAI(
model=reasoning_model,
temperature=1.0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
result = llm.with_structured_output(Reflection).invoke(formatted_prompt)
return {
"is_sufficient": result.is_sufficient,
"knowledge_gap": result.knowledge_gap,
"follow_up_queries": result.follow_up_queries,
"research_loop_count": state["research_loop_count"],
"number_of_ran_queries": len(state["search_query"]),
}
函数的内容是 将网络搜索的结果和用户的问题传递给大模型,让大模型判断并输出对应的结果。同时也可以看到,Reflection结点生成的是follow_up_queries,是一个列表,而Web_research结点查询的参数是一个问题,是因为还有另外一个结点:Evaluate_research
5.Evaluate_research结点
这个结点的作用与continue_to_web_research的作用差不多,负责把reflection生成的follow_up_query传递给web_research实现并行多查询。其中还加了一个循环轮次的判断,防止一直在循环中。
代码:
def evaluate_research(
state: ReflectionState,
config: RunnableConfig,
) -> OverallState:
"""LangGraph routing function that determines the next step in the research flow.
Controls the research loop by deciding whether to continue gathering information
or to finalize the summary based on the configured maximum number of research loops.
Args:
state: Current graph state containing the research loop count
config: Configuration for the runnable, including max_research_loops setting
Returns:
String literal indicating the next node to visit ("web_research" or "finalize_summary")
"""
configurable = Configuration.from_runnable_config(config)
max_research_loops = (
state.get("max_research_loops")
if state.get("max_research_loops") is not None
else configurable.max_research_loops
)
if state["is_sufficient"] or state["research_loop_count"] >= max_research_loops:
return "finalize_answer"
else:
return [
Send(
"web_research",
{
"search_query": follow_up_query,
"id": state["number_of_ran_queries"] + int(idx),
},
)
for idx, follow_up_query in enumerate(state["follow_up_queries"])
]
6.Finalize_answer结点
这个结点是进行总结并给出回复的。
prompt汉化的意思是:
answer_instructions = """
根据提供的摘要,为用户的问题生成高质量的回答。
指南:
- 当前日期为 {current_date}。
- 你是多步研究流程的最后一步,不要提及你处于最后一步。
- 你可以访问前几步收集的所有信息。
- 你可以访问用户的问题。
- 根据提供的摘要和用户的问题,生成高质量的回答。
- 你必须正确地在回答中包含摘要中的所有引用。
用户背景:
- {research_topic}
摘要:
{summaries}
"""
代码部分:
def finalize_answer(state: OverallState, config: RunnableConfig):
"""LangGraph node that finalizes the research summary.
Prepares the final output by deduplicating and formatting sources, then
combining them with the running summary to create a well-structured
research report with proper citations.
Args:
state: Current graph state containing the running summary and sources gathered
Returns:
Dictionary with state update, including running_summary key containing the formatted final summary with sources
"""
configurable = Configuration.from_runnable_config(config)
reasoning_model = state.get("reasoning_model") or configurable.answer_model
# Format the prompt
current_date = get_current_date()
formatted_prompt = answer_instructions.format(
current_date=current_date,
research_topic=get_research_topic(state["messages"]),
summaries="\n---\n\n".join(state["web_research_result"]),
)
# init Reasoning Model, default to Gemini 2.5 Flash
llm = ChatGoogleGenerativeAI(
model=reasoning_model,
temperature=0,
max_retries=2,
api_key=os.getenv("GEMINI_API_KEY"),
)
result = llm.invoke(formatted_prompt)
# Replace the short urls with the original urls and add all used urls to the sources_gathered
unique_sources = []
for source in state["sources_gathered"]:
if source["short_url"] in result.content:
result.content = result.content.replace(
source["short_url"], source["value"]
)
unique_sources.append(source)
return {
"messages": [AIMessage(content=result.content)],
"sources_gathered": unique_sources,
}
函数的内容是就是传递搜索的内容和用户的问题进行最终总结。
7.Graph
根据架构图将结点进行连接即可。
# Create our Agent Graph
builder = StateGraph(OverallState, config_schema=Configuration)
# Define the nodes we will cycle between
builder.add_node("generate_query", generate_query)
builder.add_node("web_research", web_research)
builder.add_node("reflection", reflection)
builder.add_node("finalize_answer", finalize_answer)
# Set the entrypoint as `generate_query`
# This means that this node is the first one called
builder.add_edge(START, "generate_query")
# Add conditional edge to continue with search queries in a parallel branch
builder.add_conditional_edges(
"generate_query", continue_to_web_research, ["web_research"]
)
# Reflect on the web research
builder.add_edge("web_research", "reflection")
# Evaluate the research
builder.add_conditional_edges(
"reflection", evaluate_research, ["web_research", "finalize_answer"]
)
# Finalize the answer
builder.add_edge("finalize_answer", END)
graph = builder.compile(name="pro-search-agent")
三.项目优化。
这是一个结合了联网搜索+反思的agent,在处理较复杂的问题时具有不错的效果,但是对于简单的问题例如”你好“仍要进行搜索+反思,导致时间过长,并且在正常对话中每次都会携带网络搜索的全部内容,几轮对话会消耗巨大的token,且速度会越来越慢。我觉得可以尝试以下优化:
- 新增一个结点,判断用户输入的问题是否能够直接回答,如果可以则不走Generater_queries结点,直接让大模型回答。
- 使用langgraph的记忆函数MemorySaver来存储记忆,或者是总结式的记忆存储方式,防止token消耗过多,也能减少一定的时间消耗。
相关文章。
从零开始构建Agent(一):认识Agent
从零开始构建Agent(三):手搓一个基于langgraph的agent,简略版“Manus”,实现分析文档等小部分功能
待更中。。。。
觉得还不错的可以点点赞和关注,这个专栏会持续更新!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)