NORA-1.5:一种基于世界模型和基于动作偏好奖励训练的视觉-语言-动作模型
25年11月来自南洋理工、Lambda实验室和新加坡技术和设计大学的论文“NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards”。视觉-语言-动作(VLA)模型近年来在各种具身任务中展现出令人瞩目的性能,但其可靠性和泛化能力仍有待提高,尤其是在不
25年11月来自南洋理工、Lambda实验室和新加坡技术和设计大学的论文“NORA-1.5: A Vision-Language-Action Model Trained using World Model- and Action-based Preference Rewards”。
视觉-语言-动作(VLA)模型近年来在各种具身任务中展现出令人瞩目的性能,但其可靠性和泛化能力仍有待提高,尤其是在不同具身或真实世界环境中部署时。本文提出一种基于预训练NORA主干网络的VLA模型NORA-1.5,并为其添加一个基于流匹配的动作专家。仅这一架构改进就带来显著的性能提升,使得NORA-1.5在模拟和真实世界的基准测试中均优于NORA以及多种VLA模型。为了进一步提高模型的鲁棒性和任务成功率,开发一套用于后训练VLA策略的奖励模型。奖励模型结合:(i)一个动作条件世界模型(WM),用于评估生成的动作是否指向预期目标;(ii)一个与真实世界偏差的启发式方法,用于区分好的动作和坏的动作。利用这些奖励信号,构建偏好数据集,并通过直接偏好优化(DPO)将NORA-1.5适配到目标具身模型上。大量的评估表明,奖励驱动的后训练能够持续提升仿真和真实机器人环境下的性能,并通过简单而有效的奖励模型显著提高VLA模型的可靠性。
NORA 和NORA-1.5的概览如图所示:
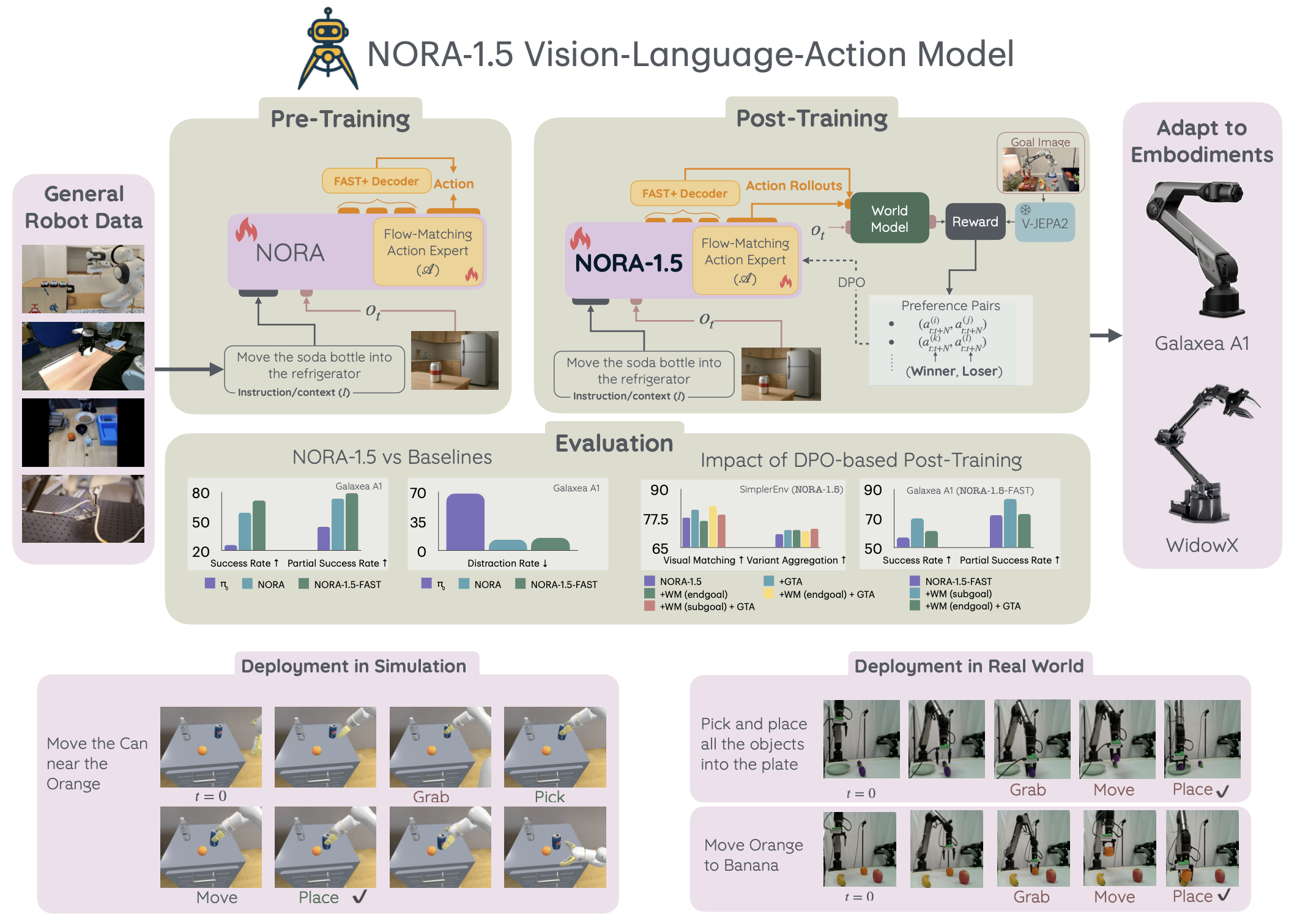
NORA-1.5,它通过逐层自注意机制,将基于流匹配的动作专家与预训练的自回归 VLA 模型 NORA [16] 相结合。虽然先前的研究表明流匹配主要提高推理速度,但并未研究其对策略性能的影响。基于流匹配的动作生成在多个基准测试中均能持续提升性能,其归因于强大的架构协同效应:流匹配专家利用自回归 VLA 编码的丰富表征,而 VLA 则从专家那里接收信息丰富的梯度,从而引导其规划出专家能够有效实现的连贯的多步轨迹。然而,在数据量较少的数据集上,流匹配专家模型可能表现不佳,这可能是由于与 VLA 主干网络的联合训练不足所致。总体而言,NORA-1.5 在 SimplerEnv 和 LIBERO 等模拟基准测试中取得最先进的性能,并且其性能能够很好地迁移到基于新机器人模型的真实世界实验中。
此外,其探索基于奖励的后训练方法,用从紧凑的动作条件世界模型中提取的轻量级但有效的奖励信号。在这种方法中,奖励的估计是通过在世界模型中展开候选动作序列并评估其达到目标的能力来实现的。由于机器人中的奖励建模通常需要估计动作序列达到预期结果的程度,因此世界模型提供一种自然的机制:它们可以直接预测未来帧或其基于动作的潜嵌入。其采用一个13亿参数的动作条件世界模型V-JEPA2-AC [2] 作为基于目标的奖励估计器。然而,由于V-JEPA2-AC是在有限的数据上进行自适应训练的,其预测结果可能存在噪声。为了缓解这一问题,引入一个互补的启发式奖励,用于衡量训练数据中采样动作与真实动作之间的距离。这两个奖励组成部分发挥着不同的作用:基于目标的世界模型捕捉各种可行的轨迹,而基于距离的启发式方法则有助于抵消噪声并提供稳定的参考。
这种后训练范式定义一种大型视觉-语言-动作(VLA)模型策略优化方法。NORA-1.5 不依赖人工标注标签或大量的机器人实战演练,而是构建学习型评估器——一种基于世界模型的预测器,结合几何/启发式检查——作为奖励代理(proxies),对模型生成的轨迹进行排序,形成偏好对;这些排序后的偏好对随后被直接偏好优化(DPO)算法使用。
NORA-1.5的训练流水线如图所示:预训练和后训练
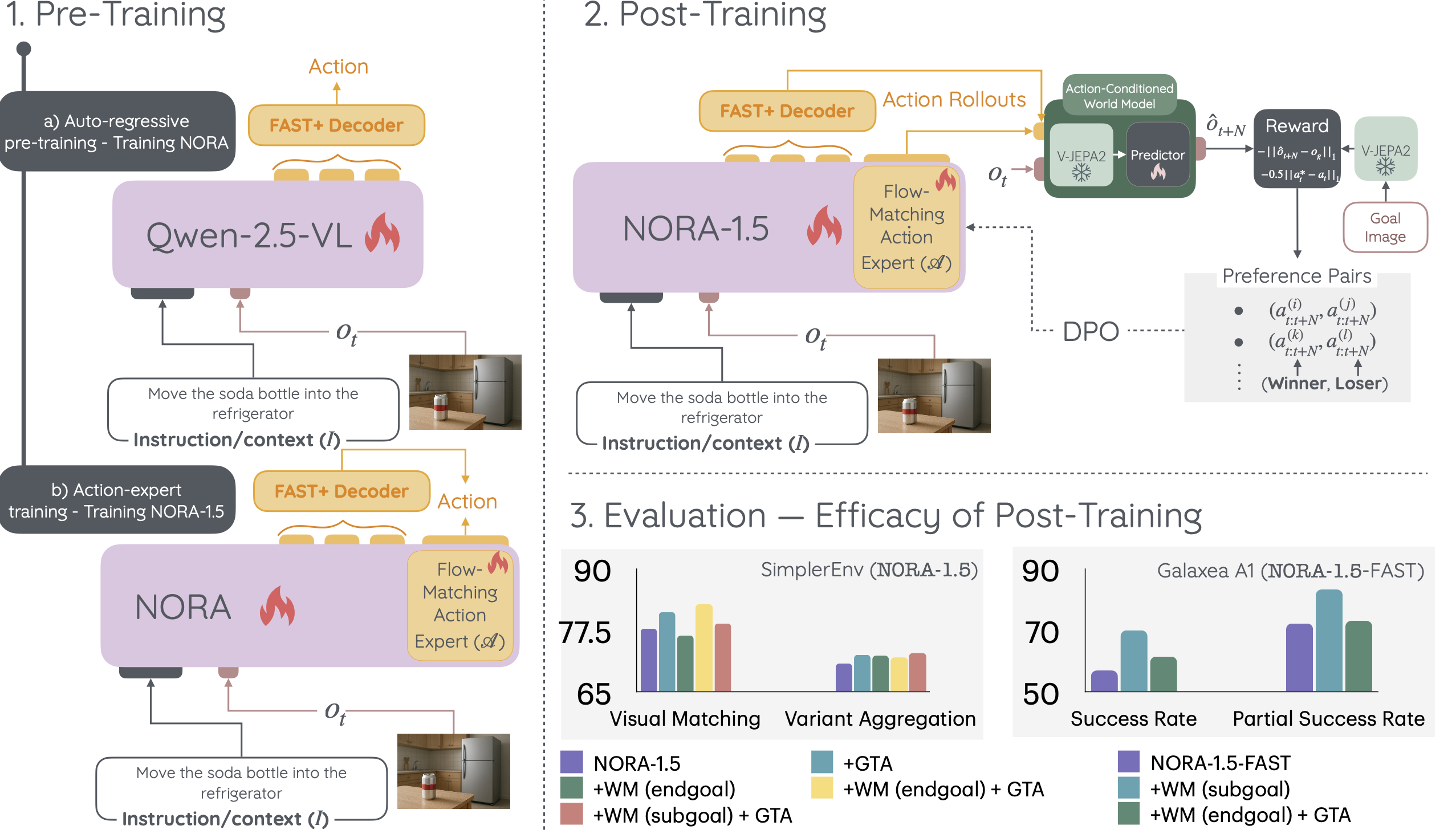
架构
为了克服 NORA 中通常较慢的自回归动作解码,用一个独立的动作专家 A,它基于 NORA 的联合自然语言指令 I 和视觉观察编码 (VL),直接在长度为 N 的范围内,回归动作序列 a_t:t+N。
使用 NORA (VL) 进行输入编码。NORA 基于强大的视觉语言模型 Qwen-2.5-VL-3B,使其在视觉语言联合理解方面拥有坚实的基础。同时,其在大量不同轨迹上的模仿学习阶段赋予 NORA 为各种机器人生成动作的能力。后者是 NORA 相对于典型视觉语言模型的优势所在,使其成为机器人相关视觉语言编码的理想选择,能够联合编码自然语言指令和视觉观察结果。为此,NORA 组成 Transformer 层的KV对被用于对动作专家进行条件化。
动作专家 (A)。动作专家被定义为一个流匹配头,它根据视觉语言模型的KV对,回归出 N 个时域的动作序列。给定时刻 t+N 的动作序列,噪声动作序列定义为 aτ_t:t+N = (1 − τ ) a_t:t+N + τ a_0 其中 τ 是流匹配时间步长,a_0 ∼ N (0, 1)。动作专家 A 通过最小化流匹配损失,直接将真实速度 v = a_0 − a_t:t+N 与预测速度进行回归。
矢量场回归器 A(aτ_t:t+N, K_VL,t, V_VL,t) 被参数化为堆叠式 Transformer 网络,其架构与 NORA 完全相同,其中 K_VL,t 和 V_VL,t 分别是 VL 的 Transformer 层中的K和V,x(0) = a_τ,Tr 是 Transformer 层,Q、K 和 V 分别是其中多头注意机制的查询、键和值输入。
后训练视觉语言动作(VLA)的奖励建模
在LLM研究中,通过使用强化学习进行大量的后训练,系统II级智能和任务性能得到显著提升。其核心思想是,模型通过生成多个方案来探索解空间。然后,奖励模型基于任务完成度、效率和最优性等标准评估这些方案。奖励信号用于更新策略,使模型能够逐步改进其动作选择,并倾向于选择能够获得更高奖励的策略。这一过程有效地将探索可能的动作与基于反馈的引导学习相结合,使模型能够发现越来越有效的行为。将这种范式扩展到视觉语言动作(VLA)模型面临着一个根本性的挑战:如何为这些模型定义和提供奖励信号?训练奖励模型需要数据,其中每个动作都基于其与成功完成目标的关联性进行评估。
一种简单的策略是从VLA模型中采样N个动作序列,在仿真环境中或物理机器人上执行这些动作序列,然后根据观察到的结果构建手工设计的奖励信号。这些收集的轨迹可以用来拟合奖励或价值函数,从而评估新生成的展开动作并分配相应的分数,进而形成传统的强化学习(RL)流程。然而,在实践中,这种方法的前提是能够使用高精度、快速且针对特定实体设计的仿真器,或者使用庞大的真实机器人基础设施——而这两者都成本高昂,且通常难以大规模实现。作为一种更简单的替代方法,可以通过测量模型生成的动作与其对应的真实动作之间的距离来定义奖励;然而,这种启发式方法继承了底层演示的局限性。对于存在多条有效轨迹的任务,基于距离的奖励可能会使学习者偏向于单一的示范路径,从而导致局部最优解,并抑制对其他成功行为的探索。此外,由于一旦策略偏离示范流形,这些奖励就无法提供任何指导,因此可能导致较差的失败恢复能力,并可能导致策略在评估过程中遇到的分布外状态崩溃。
世界模型和视频生成模型的最新进展提供一种很有前景的替代方案。这些模型可以通过预测动作的后果并评估是否实现了期望的子目标,从而作为隐奖励估计器。利用这些学习的模型作为奖励函数,可以实现对VLA策略进行可扩展的后训练,而无需完全工程化的模拟器,从而为具身环境下的强化学习提供一条切实可行的途径。
通过奖励改进动作专家。给定动作专家提供的 N 个展开结果,利用多种技术来计算奖励。
奖励模型训练完成后,可以采用偏好优化技术(例如直接偏好优化 (DPO) [37]、强化学习 (RL) 和群体奖励偏好优化 (GRPO) [39])来改进动作专家。本例用 DPO。
奖励设计。奖励模型包含两个部分:(i) 基于WM的目标导向奖励和 (ii) 基于动作的奖励。基于WM的目标导向奖励旨在量化生成动作与指定目标的一致性。为此,可以使用动作条件世界模型来预测最终的未来状态。然后可以将这些状态与真实目标状态进行比较——实验最终目标(记为 WM(endgoal)奖励)和即时子目标状态(记为 WM(subgoal)奖励)——并使用合适的指标来获取动作专家的奖励信号。即时子目标状态WM(subgoal)可以引导模型实现短期目标,而最终目标状态WM(endgoal)则可以引导模型实现长期目标。基于此假设,为了评估动作在实现最终目标或子目标方面的质量,训练一个基于预训练 V-JEPA2【1】的动作条件世界动力学模型 W,该模型已训练用于编码图像和图像序列。受 Assran [1] 的启发,训练一个预测器 Transformer 模型 (P_θ),该模型接受由 V-JEPA2 编码的当前观测值 o_t (J) 和动作序列 a_t:t+N 作为输入,以回归下一个观测值 oˆ_t+N 的嵌入。
基于WM引导的目标导向奖励 R_g 是最终目标图像 o_endgoal 或即时子目标图像 o_subgoal-t 与候选动作 a_t:t+N 的世界模型估计结果图像之间的差异。该差异可以指示动作 a_t:t+N 与最终目标或即时子目标之间的接近程度。时刻 t 的真实子目标图像 o_subgoal-t 被选为第 t + N 的帧 o_t+N。
另一方面,基于动作的奖励[20](在实验结果中称为GTA) R_a,量化动作a_t:t+N与目标动作a∗_t:t+N的接近程度。总奖励R_tot结合这两个部分(R_g 和R_a),其中基于动作的奖励权重是WM引导的目标导向奖励的一半(0.5)。这种组合可以减轻WM引导的目标导向奖励的噪声,该奖励源于基于动作条件的世界模型W,该模型在有限数据上训练,可能无法很好地泛化到所有场景。另一方面,基于动作的奖励可能过于局限,因为真实轨迹可能不唯一,在这种情况下,目标导向的奖励可能效果更好。
本文使用的奖励模型提供密集的、逐步的评估,允许模型在每个时间步对采样的候选动作进行排序。具体而言,给定一个固定的任务规范和观测值 s_t,该模型会为不同的候选动作 {a(1)_t:t+N ,…,a(N)_t:t+N} 分配相对分数,从而使 VLA 能够区分这些动作的相对质量,进而鼓励在直接偏好优化 (DPO) 过程中进行更深层次的步级探索。由于排序是在动作层面进行的,因此该策略可以探索不同的局部决策分支,并传播随时间局部化的偏好信息。该奖励模型还可以直接集成到传统的强化学习目标中(例如,作为每步奖励 r_t 或作为辅助评价器),从而实现混合训练机制。
相比之下,另一种方法是收集数据,其中使用从最终轨迹结果导出的稀疏每步奖励,用这些奖励来训练一个价值函数,最后通过学习的价值函数执行强化学习;虽然重复的轨迹级展开也能促进探索,但它们通常只会产生较浅的探索,因为功劳(credit)是分配给整个轨迹而不是单个时间步的。
偏好数据集构建。分别基于定义的奖励,构建(赢家,输家)动作偏好对 (aW_t:t+N, aL_t:t+N) 的偏好数据集 D_goal 和 D_act,其中 aW,L_t:t+N ∼ VLA_θ(o_t, I),VLA := A_θ ◦ VL_θ,且 R(aW_t:t+N, ·) > R(aL_t:t+N, ·)。给定当前状态、指令和这些偏好对,根据奖励对给定观测值的动作进行排序,并据此构建偏好对。
训练
训练分为两个主要阶段:
i. 动作专家训练。动作专家参数随机初始化,随后与 VLA 主干网(NORA)参数联合训练。训练过程中,动作专家输出采用组合流匹配损失,NORA FAST+ 的输出tokens采用交叉熵损失。
ii. 基于奖励的后训练。将动作专家生成的动作序列和 DPO 目标进行对齐。另一方面,还将 VLA 解码器头的 FAST+ 动作输出与 Rafailov [37] 提出的 DPO 目标进行对齐。FAST+ 输出的评估结果以“-FAST”后缀表示。基于 DPO 的后训练应用于 SFT 模型,即在目标模型的监督数据上VLA 微调之后。
基线
用现有的知名 VLA 模型作为基线,包括自回归 VLA 模型,例如 SpatialVLA [35]、RT-1 [7]、MolmoAct [21]、Emma-X [41]、NORA [15] 和 OpenVLA [19],以及基于扩散或流匹配的模型,例如 π0 [5] 等。
基准测试和评估设置
用 LIBERO、SimplerEnv 和 Galaxea A1 机械臂在模拟和真实场景下评估 VLA 模型。LIBERO 基准测试包含四个子集——spatial、goal、object和long-distance——每个子集评估 500 个回合,结果取自使用不同随机种子运行的三次运行的平均值;微调通过合并所有四个子集的数据(去除空操作)来实现。 SimplerEnv 致力于通过优化 PD 参数来缩小模拟与现实之间的差距,并在两种协议(视觉匹配和变型聚合)下评估了四项任务(拿起可乐罐、将物体移动到物体附近、打开抽屉、关闭抽屉),总共涵盖超过 1000 个episodes;结果取两次运行的平均值。为了进行真实世界的跨具身评估,用 Galaxea A1 机器人(该机器人未包含在预训练数据集中),并收集 1000 个远程操控的抓取和放置回合,其中物体放置位置随机,涵盖九项独特的任务(例如,“将苹果放在盘子上”)。评估在九项任务上进行,这些任务分为三类(已见任务、未见物体-已见干扰物任务和未见指令-已见干扰物任务),每项任务重复 10 次试验,且起始位置在所有基线中保持一致。仿真基准测试报告的是二元成功率(任务完成为 1,否则为 0),而真实机器人评估则同时报告成功率(Succ.↑)和部分成功率(Part. Succ.↑),以捕捉更精细的性能差异,例如,如果机器人成功抓取正确的物体,则奖励 1 分。此外,还会报告机器人在环境中抓取干扰物(Dist.↓)的次数,在这种情况下,较低的分数是可接受的。
OpenVLA [19]:该 VLA 模型基于 Llama 2 语言模型 [44] 构建,并结合了视觉编码器,该编码器集成了来自 DINOv2 [30] 和 SigLIP [48] 的预训练特征。它在 Open-X-Embodiment 数据集 [11] 上进行预训练,该数据集包含 97 万个真实世界的机器人演示。
SpatialVLA [35]:该 VLA 模型专注于机器人操作的空间理解,并融合空间运动等 3D 信息。它学习了一种适用于不同机器人和任务的通用空间操作策略。SpatialVLA 一次预测四个动作。
TraceVLA [50]:该 VLA 模型通过视觉轨迹提示增强时空推理能力。它通过在机器人操作轨迹上微调 OpenVLA 构建,将状态-动作历史编码为视觉提示,以提高交互式任务中的操作性能。
RT-1 [8]:一种可扩展的机器人Transformer模型,旨在从大型任务无关数据集中迁移知识。RT-1在多样化的机器人数据上进行训练,在各种机器人任务中均实现了高水平的泛化能力和任务特定性能,证明了开放式任务无关训练高容量模型的价值。
HPT [45]:异构预训练Transformer (HPT) 在大量异构机器人和视频数据集上预训练一个共享的Transformer主干,将本体感觉和视觉输入对齐到统一的token序列中。由此产生的策略提高了跨实例和任务的泛化能力,发布的HPT策略用作SimplerEnv的基线。
Octo-Base [29]:Octo是一种基于Transformer的扩散策略,在来自Open X-Embodiment的约80万条轨迹上进行训练。用 Octo-Base 变型,一个 ViT-B 大小的模型,支持灵活的动作和观察空间,并且可以针对新的机器人设置进行高效微调。
RoboVLM [26]。RoboVLM 是一个框架,用于系统地研究视觉-语言-动作 (VLA) 中的设计选择,并从不同的 VLM 主干网、架构和跨具身数据构建通用策略。采用其性能最佳的 RoboVLM 策略作为强大的通用 VLA 基线。
π0 和 π0-FAST [6]。π0 是一个视觉-语言-动作模型,它将一个流匹配动作专家附加到预训练的 VLM 上,并在大型跨具身数据集上进行训练,以实现高频灵巧控制。π0-FAST 使用 FAST token化器将动作token化为离散tokens。这使得模型能够以更少的训练计算量更快地收敛。这两个模型都可以作为强大的通用基线。
MolmoAct / MolmoAct-7B-D [22]。MolmoAct 是一种动作推理视觉语言动作模型 (VLA),它将控制过程分为三个阶段:深度-觉察的感知tokens、中层空间轨迹和底层动作。用 7B-D 变体 MolmoAct-7B-D,该变体在 SimplerEnv 和 LIBERO 数据集上实现了优异的零样本和微调性能。
Emma-X [43]。Emma-X 是一种 7B VLA,它是通过在源自 BridgeV2 的分层数据集上对 OpenVLA 进行微调而得到的,具有扎实的思维链推理和前瞻空间引导。
Magma [47]。Magma 是一种多模态智体基础模型,它统一视觉、语言和动作,可用于数字用户界面导航和物理机器人操作。它引入视觉规划轨迹,并作为真实机器人比较中的大规模通用基线。
GR00T N1.5 [4, 28]。 GR00T N1 是一个面向人形机器人的开放式视觉-语言-动作 (VLA) 基础模型,采用双-系统设计:视觉语言骨干网络和基于扩散的动作策略。GR00T N1.5 是其改进版本,在架构和数据方面进行了更新;用 3B N1.5 策略作为强大的通用基线。
CoT-VLA [49]。CoT-VLA 通过视觉思维链推理增强 VLA:它首先预测子目标图像作为视觉规划,然后生成短动作序列来实现这些子目标,从而提高长时程和多步骤操作的性能。
WorldVLA [10]。WorldVLA 将 VLA 策略和图像世界模型统一到一个自回归transformer中,联合建模图像、语言和动作。世界模型根据动作预测未来的图像,动作头可以从世界模型的反馈中受益,从而获得更好的规划。
ThinkAct [14]。ThinkAct 是一种双-系统视觉学习算法 (VLA),它将高层推理与低层动作分离。多模态低层动作模型 (LLM) 生成结构化的具身规划,这些计划被压缩成视觉潜变量,从而为下游动作策略提供条件,以实现少样本自适应和长时程控制。
NORA 和 NORA-Long [16]。NORA 是一种基于 Qwen2.5-VL-3B 构建的 3B 视觉学习算法,使用 FAST token化器在 Open X-Embodiment 数据集上进行训练,旨在在有限的计算资源下提供强大的性能。NORA-Long 是 NORA 的变体,扩展动作时程,并且是原始 NORA 视觉学习算法的衍生版本。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)