【昇腾CANN训练营·行业篇】MoE架构加速:深入解析TopK Routing与Grouped Matmul实现
摘要:2025年昇腾CANN训练营第二季推出专题课程,助力开发者提升算子开发技能,完成认证可获奖励。文章重点解析MoE模型的路由算子开发,通过交通枢纽类比说明路由过程,详细介绍了TopKGating算法三步流程及AscendC实现方案,包括Kernel类定义、核心计算逻辑和Token排列优化,并延伸讲解GroupedMatmul的高效计算策略,为开发者提供稀疏大模型优化的关键技术路径。
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
传统的 Dense 模型(如 LLaMA-70B)是“全员出动”,不管问题简单还是复杂,所有参数都要参与计算。 MoE (Mixture of Experts) 模型则是“专家会诊”。网络中包含多个专家层(Experts),对于每个 Token,Gating Network(门控网络) 会打分选出最合适的 Top-K 个专家(通常 K=2),只有被选中的专家才会处理该 Token。
这就带来了一个巨大的工程挑战:
-
路由(Routing):如何快速算出每个 Token 该去哪个专家?
-
分发(Dispatch):如何把 Token 搬运到对应的专家内存区?
-
计算(Grouped GEMM):不同专家分配到的 Token 数量不一样(有的专家忙死,有的闲死),如何并行计算?
本期文章,我们将聚焦于 MoE Routing 的算子开发,这是整个架构的调度中心。
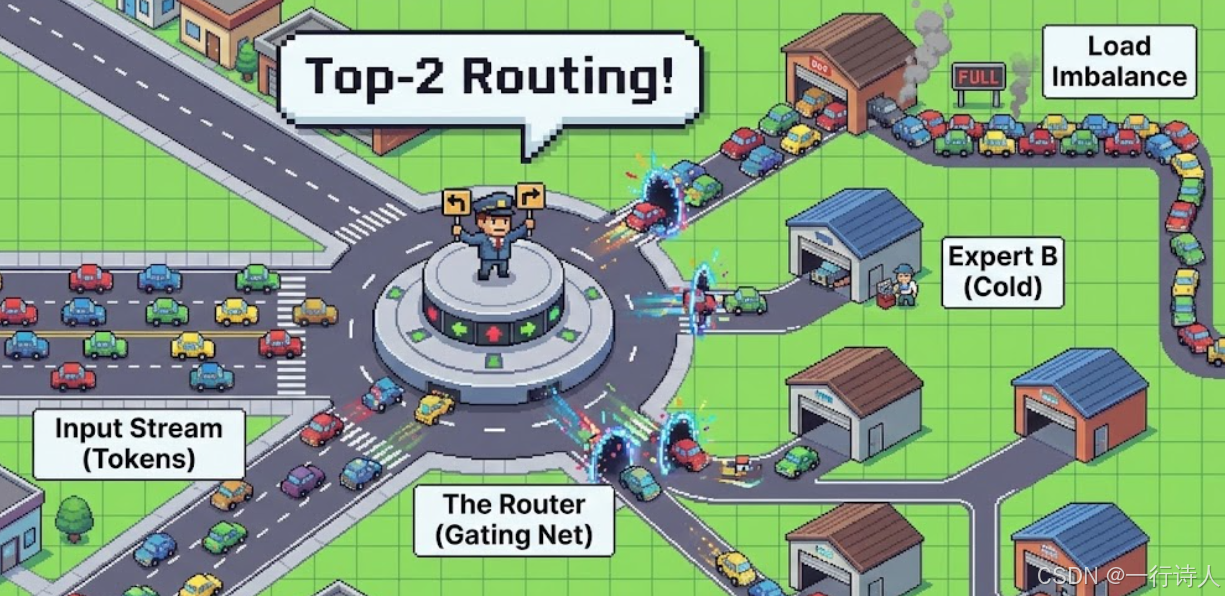
一、 核心图解:繁忙的交通枢纽
MoE 的路由过程就像是一个巨大的交通枢纽。
二、 核心算法:TopK Gating
假设输入 $X$ 是 [Batch, Seq, Hidden],专家数量 $E$。 路由过程分为三步:
-
Score: 计算每个 Token 对每个专家的打分 $S = X \times W_g$ (结果 Shape:
[TotalTokens, E])。 -
TopK: 对 $S$ 的最后一维做 TopK,选出分数最高的 K 个专家的
Index和Weight。 -
Permute: 根据
Index对 Token 进行重排,把去往同一个专家的 Token 聚在一起。
在 Ascend C 中,第 1 步是 MatMul,第 2、3 步则是我们要实现的 Router Kernel。
三、 实战:Ascend C 实现 Router
我们需要实现一个算子,输入 Scores,输出 DestIndices 和 DispatchMask。
3.1 Kernel 类定义
class KernelMoERouter {
public:
__aicore__ inline void Init(GM_ADDR scores, GM_ADDR indices, GM_ADDR weights,
uint32_t num_tokens, uint32_t num_experts, uint32_t k) {
// ... Init ...
this->K = k;
this->E = num_experts;
}
__aicore__ inline void Process() {
// Tiling: 按 Token 数量切分
for (int i = 0; i < tileNum; i++) {
Compute(i);
}
}
};
3.2 Compute 核心逻辑 (TopK + Softmax)
这里复用了我们在第 41 期(TopK)和第 24 期(Softmax)学到的知识。
__aicore__ inline void Compute(int32_t i) {
// 1. CopyIn Scores
// scoresLoc: [tileLen, E]
DataCopy(scoresLoc, scoresGm[offset], tileLen * E);
// 2. Row-wise TopK
// 对每一行(每个Token)选出前 K 个专家
// 我们可以复用 TopK 的逻辑(Sort + Mask)
// 假设 K=2,E=8 (较小)
// 可以直接用 Sort 指令对 E 维度排序
// 注意:需要保留原始 Index,建议使用 Pack Value-Index 技巧(第 41 期)
// sortLoc: [tileLen, E] (Sorted)
Sort(sortLoc, scoresLoc, E);
// 3. Extract TopK
// 取出前 K 个的 Value 和 Index
// topkVal: [tileLen, K], topkIdx: [tileLen, K]
// 4. Softmax (Optional)
// MoE 通常对 TopK 的分数再做一次 Softmax 归一化
// 这里的 Softmax 只针对 K 个值
// exp_sum = sum(exp(topkVal))
// weights = exp(topkVal) / exp_sum
// ... Vector Softmax Logic ...
// 5. CopyOut
// 输出:
// topkIdxGm: 每个 Token 要去的专家 ID
// topkWeightGm: 对应的路由权重
DataCopy(indicesGm[offset], topkIdx, tileLen * K);
DataCopy(weightsGm[offset], topkWeights, tileLen * K);
}
3.3 关键:Token 排列 (Permutation)
算出了每个 Token 去哪(Index),下一步是物理搬运。 这是一个 Scatter 操作。
-
输入:
Tokens [T, H] -
索引:
ExpertIdx [T, K] -
输出:
ExpertTokens [E, C_e, H](其中 $C_e$ 是第 $e$ 个专家的 Token 数)
在 Ascend C 中,为了性能,我们通常不直接 Scatter,而是计算出 Permutation Indices,然后调用 Gather。 我们需要一个辅助的 Histogram (直方图) 算子来统计每个专家的 Token 数量(Count),然后做 Prefix Sum 得到每个专家的写入偏移量。
四、 进阶:Grouped Matmul (GMK)
Token 分发好后,内存里是一堆长短不一的数据块:
-
Expert 0: 100 个 Token
-
Expert 1: 5 个 Token
-
Expert 2: 0 个 Token
如果用 Padding 补齐再算,浪费极大。 Grouped Matmul 允许我们在一次 Kernel 启动中,计算多个 Shape 不同的矩阵乘法:
$$Y_0 = X_0 \times W_0$$$$Y_1 = X_1 \times W_1$$
...
Ascend C 实现思路:
-
Multi-Core Task Distribution:Host 侧根据每个专家的负载(Token 数),动态分配 AI Core。
-
负载重的 Expert 分给多个 Core。
-
负载轻的 Expert 几个合并给一个 Core。
-
-
Kernel 内循环:每个 Core 拿到任务列表(Task List),循环调用
Matmul高阶 API。-
mm.SetIntrinShape(M_i, N, K):这里的 $M_i$ 是动态变化的(即 Token 数)。
-
// 伪代码:Grouped Matmul Kernel
__aicore__ void GroupedMatmul(GM_ADDR* x_list, GM_ADDR* w_list, int32_t* m_list, ...) {
int32_t task_id = GetTaskId();
int32_t m = m_list[task_id]; // 获取当前专家的 Token 数
if (m == 0) return; // 空转专家直接跳过
// 动态配置 Matmul
Matmul<...> mm;
mm.SetIntrinShape(m, N, K);
mm.SetTensorA(x_list[task_id]);
mm.SetTensorB(w_list[task_id]);
mm.IterateAll(output_list[task_id]);
}
五、 总结
MoE 是 AI 算力效率的极致体现,也是算子开发最复杂的场景之一。
-
Routing:本质是 TopK + Softmax。
-
Dispatch:本质是 Histogram + Sort + Gather。
-
Compute:本质是动态 Shape 的 Grouped Matmul。
掌握了这一套组合拳,你就有能力去优化 DeepSeek、Mixtral 等最前沿的稀疏大模型,在算力受限的时代杀出重围。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)