打通训练闭环:深入解析自定义算子的反向传播 (Backward) 开发实战
在 AI 开发中,“能跑推理”和“能做训练”是两个完全不同的段位。对于推理,我们只需要实现 $Y = f(X)$。但对于训练,我们需要支持 PyTorch 的Autograd机制,这意味着我们要手写对应的反向算子:给定输出的梯度 $\frac{\partial L}{\partial Y}$(记为dy),计算输入的梯度 $\frac{\partial L}{\partial X}$(记为dx)和权
训练营简介 2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro

前言
在 AI 开发中,“能跑推理” 和 “能做训练” 是两个完全不同的段位。
对于推理,我们只需要实现 $Y = f(X)$。 但对于训练,我们需要支持 PyTorch 的 Autograd 机制,这意味着我们要手写对应的反向算子:给定输出的梯度 $\frac{\partial L}{\partial Y}$(记为 dy),计算输入的梯度 $\frac{\partial L}{\partial X}$(记为 dx)和权重的梯度 $\frac{\partial L}{\partial W}$(记为 dw)。
反向算子开发的核心难点在于:
-
数学推导:必须精确推导出矩阵微积分公式,一个符号错了,模型就不收敛。
-
状态保存:前向计算时的中间结果(如 Mean, Variance)需要传给反向,这涉及到显存的 Stash(暂存) 机制。
-
计算复杂度:反向计算量通常是前向的 2-3 倍(因为要算输入和权重两份梯度)。
本期文章,我们将基于之前的 RMSNorm,实战开发它的孪生兄弟 —— RMSNormGrad。
一、 核心图解:梯度的回流
如果说前向传播是水流向下游(计算 Loss),那么反向传播就是三文鱼逆流而上(分发误差)。
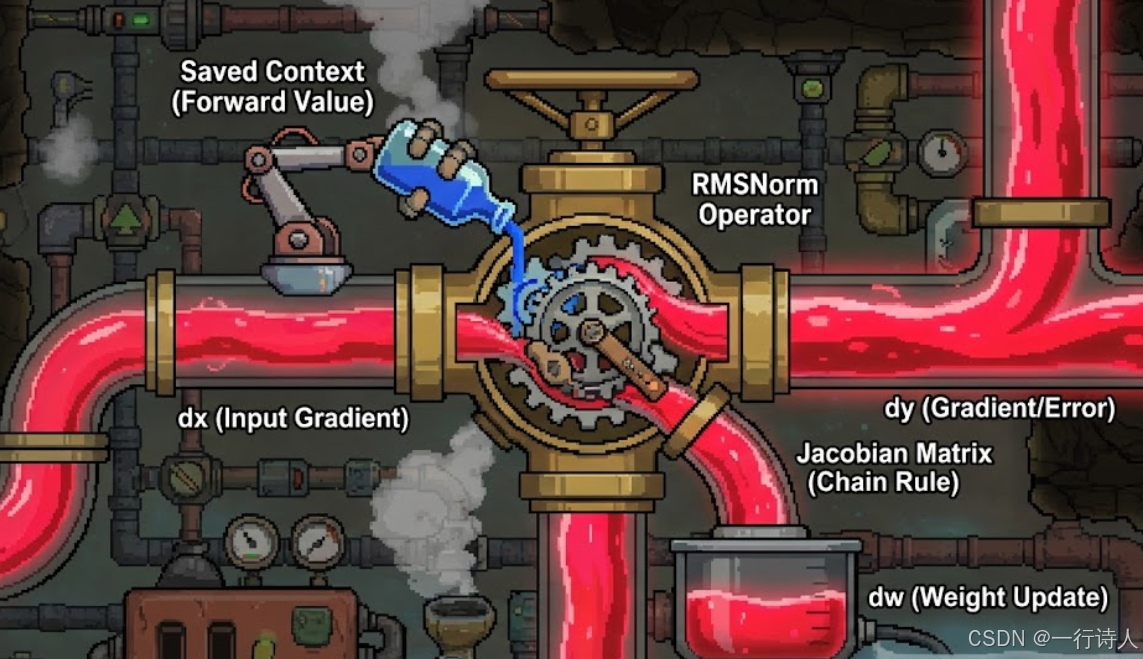
二、 数学推导:RMSNorm 的梯度
在写代码前,必须先在纸上推导。 回顾 RMSNorm 公式:
$$y = \frac{x}{RMS(x)} \cdot \gamma$$
其中 $RMS(x) = \sqrt{\frac{1}{N} \sum x^2 + \epsilon}$。
已知 $\partial L / \partial y$ (即 dy),求 $\partial L / \partial x$ (即 dx)。
根据链式法则,推导过程极其繁琐(此处省略 500 字矩阵求导过程),最终得到的工程化公式为:
$$dx = \frac{1}{RMS(x)} \left[ (dy \cdot \gamma) - x \cdot \frac{\sum (dy \cdot \gamma \cdot x)}{N \cdot RMS(x)^2} \right]$$
简化变量: 设 $rstd = \frac{1}{RMS(x)}$,这是我们在前向计算时就算出来的。 则:
$$dx = rstd \cdot \left[ (dy \cdot \gamma) - x \cdot \frac{\text{Sum}((dy \cdot \gamma) \cdot x) \cdot rstd^2}{N} \right]$$
结论:为了算 dx,我们需要:
-
dy(反向输入) -
x(前向输入) -
gamma(权重) -
rstd(前向计算的中间结果,必须保存!)
三、 Ascend C 实战:RMSNormGrad Kernel
3.1 Kernel 类定义
注意输入列表:dy, x, gamma, rstd。输出:dx。 (为了简化,暂不计算 dgamma,逻辑类似)。
class KernelRMSNormGrad {
public:
__aicore__ inline void Init(GM_ADDR dy, GM_ADDR x, GM_ADDR gamma, GM_ADDR rstd, GM_ADDR dx,
uint32_t rowLength, uint32_t numRows) {
// ... Init ...
// rstd 是 [numRows, 1] 的向量,每一行共用一个 rstd
this->rowLen = rowLength;
}
__aicore__ inline void Process() {
for (int i = 0; i < numRows; i++) {
Compute(i);
}
}
};
3.2 Compute 核心逻辑
我们需要严格按照上面的红色公式翻译代码。
__aicore__ inline void Compute(int32_t i) {
// 1. Load Data
LocalTensor<half> dyLoc = inQueueDy.DeQue<half>();
LocalTensor<half> xLoc = inQueueX.DeQue<half>();
LocalTensor<half> gammaLoc = inQueueGamma.DeQue<half>();
LocalTensor<float> rstdLoc = inQueueRstd.DeQue<float>(); // FP32 精度
LocalTensor<half> dxLoc = outQueueDx.AllocTensor<half>();
// 申请临时空间 (FP32 计算以保证精度)
LocalTensor<float> dy_gamma = tmpQueue.AllocTensor<float>();
LocalTensor<float> x_float = tmpQueue.AllocTensor<float>();
LocalTensor<float> term2 = tmpQueue.AllocTensor<float>();
// Step 1: 计算 dy * gamma
// 先把 dy, gamma 转 FP32 (省略 Cast 代码)
Mul(dy_gamma, dy_fp32, gamma_fp32, rowLen);
// Step 2: 计算 Sum(dy * gamma * x)
// 2.1 临时乘积
Mul(term2, dy_gamma, x_fp32, rowLen);
// 2.2 ReduceSum
// result 存在 term2[0]
ReduceSum(term2, term2, workLocal, rowLen);
// Step 3: 计算这一行的公共系数 factor
// factor = Sum(...) * rstd^2 / N
float sum_val = term2.GetValue(0);
float rstd_val = rstdLoc.GetValue(0); // 这一行对应的 rstd
float N = (float)rowLen;
float factor = (sum_val * rstd_val * rstd_val) / N;
// Step 4: 计算最终 dx
// dx = rstd * (dy_gamma - x * factor)
// 4.1 x * factor
Muls(x_float, x_float, factor, rowLen);
// 4.2 dy_gamma - (x * factor)
Sub(dy_gamma, dy_gamma, x_float, rowLen);
// 4.3 * rstd
Muls(dy_gamma, dy_gamma, rstd_val, rowLen);
// Step 5: Cast back to FP16 & Output
Cast(dxLoc, dy_gamma, RoundMode::CAST_RINT, rowLen);
outQueueDx.EnQue(dxLoc);
// ... Free ...
}
四、 系统级串联:PyTorch Autograd 适配
写好了 Kernel,怎么让 PyTorch 自动调用它? 我们需要在 PyTorch Adapter 中定义 Function 的 backward 静态方法。
4.1 修改 Forward 逻辑 (保存中间结果)
在执行 Forward 算子时,必须把 rstd 存下来。
// adapter.cpp (C++)
std::tuple<at::Tensor, at::Tensor> npu_rms_norm_forward(const at::Tensor& x, const at::Tensor& gamma) {
// 1. 申请 output y
auto y = at::empty_like(x);
// 2. 申请 rstd (用于反向)
// Shape: [Batch, 1]
auto rstd = at::empty({x.size(0), 1}, x.options().dtype(at::kFloat));
// 3. 调用 Forward Kernel (入参增加 rstd)
// aclopExecuteV2(..., rstd, ...);
return std::make_tuple(y, rstd);
}
4.2 定义 PyTorch Function
# rms_norm.py
class RMSNormFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, x, gamma):
# 调用 C++ 前向
y, rstd = torch.ops.myops.npu_rms_norm_forward(x, gamma)
# 【关键】保存 Tensors 给反向使用
# save_for_backward 会自动处理显存的引用计数
ctx.save_for_backward(x, gamma, rstd)
return y
@staticmethod
def backward(ctx, grad_output):
# 取出保存的 Tensor
x, gamma, rstd = ctx.saved_tensors
# 调用 C++ 反向 Kernel
dx, dgamma = torch.ops.myops.npu_rms_norm_backward(
grad_output, x, gamma, rstd
)
return dx, dgamma
五、 总结
开发反向算子是 Ascend C 开发者的**“成人礼”**。
-
思维转变:从“输入->输出”转变为“误差回传”。
-
显存权衡:为了计算梯度,我们必须在前向阶段多申请显存保存
rstd。这就是为什么训练比推理更吃显存。 -
精度至上:梯度的数值通常很小(1e-4 级别),在 Kernel 内部全程使用 FP32 计算至关重要,否则梯度消失,模型训不动。
打通了这一关,你就真正具备了**“造轮子”**的能力——不仅仅是修补别人的模型,而是可以从零创造新的算子,并让它在昇腾 NPU 上跑起来训练。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)